







大家好!我是霖hero
大家知道目前最火的手游是哪个嘛,没错,就是王者荣耀,这款手游想必大家都听过或者玩过吧,里面有106个英雄,几百个英雄皮肤,今天我来手把手教你们把几百个皮肤都爬取下来。
目录
Python基础
我们先来讲一些Python基础知识,一是待会可能会用到这些Python基础知识,方便Python基础差的同学更好地理解,二是为了巩固基础,我们一直学下去,一定要回头看一看,回顾回顾基础。
基础好的可以直接跳过这一节。
Python内置函数zip
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象。
语法格式为:
zip([iterable, ...])具体示例代码如下:
a=[1,2,3,4,5]
b=['一','二','三','四','五']
c=zip(a,b)
for ab in c:
print(ab)运行结果为:
(1, '一')
(2, '二')
(3, '三')
(4, '四')
(5, '五')我们使用了zip()函数将两个列表的元素一一对应地组合成一个个元组,到这来,聪明的同学就发现了,我们可以使用zip()函数将皮肤名和对应的皮肤链接组合成一个个元组,这样更方便调用。
注意:如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
Python推导式
推导式是从一个或者多个迭代器快速创建序列的一种方法。它可以将循环和条件判断结合,从而避免冗长的代码。
列表推导式
语法格式如下:
[表达式 for item in 可迭代对象]
[表达式 for item in 可迭代对象 if 条件判断]具体示例1代码如下:
#没使用推导式
a=[]
for i in range(1,4):
a.append(i)
print(a)
#使用推导式
b=[i for i in range(1,4)]
print(b)运行结果为:
[1, 2, 3]
[1, 2, 3]具体示例2代码如下:
#没使用推导式时代码如下:
a=[]
for i in range(1,4):
if(i!=2):
a.append(i)
print(a)
#使用推导式后代码如下:
b=[i for i in range(1,4) if i!=2]
print(b)运行结果为:
[1, 3]
[1, 3]通过上面两个示例,很明显可以发现,使用推导式大大缩短了我们的代码行,而且显得我们代码比较专业。
字典推导式
字典推导式生成的是字典对象,其语法格式为:
{key:value for 迭代变量 in 可迭代对象}具体示例代码如下:
list = ['I','am','superman']
dict= {key: value for value,key in enumerate(list)}
print(dict)运行结果为:
{'I': 0, 'am': 1, 'superman': 2}这里我们使用了字典推导式,将列表中的元素按照其位置来组合成一个字典。
集合推导式
集合推导式是自带去重功能的推导式
语法格式为:
{表达式 for 迭代变量 in 可迭代对象 if 条件表达式}具体示例代码如下:
set = {i**2 for i in range(3)}
print(set)运行结果为:
{0, 1, 4}细心的同学可以发现,各种推导式主要是外面的括号不同,其他的都大同小异,所以只要记住一个,其他的都不成问题。
Python中'r'、'b'、'u'、'f'
我们在编写代码的时候,有时会在字符串前面加一些字符,例如:r、b、u、f等,那么加这些字符有什么用呢,接下来我会简单地讲解。
字符串前加'r'
其作用是去除转义字符
例如:
str1= 'Superman\n'
str2= r'Superman\n'
print(str1)
print(str2)运行结果为:
Superman
Superman\n我们知道\n表示换行,第二行代码中,我们在字符串前面加了个'r',则\n仅仅表示为一个反斜杠和字母n。
以r开头的字符,我们常用于正则表示式。
字符串前加'u'
作用是对字符串进行unicode编码。
一般英文字符在使用各种编码下,基本都可以正常解析,所以一般不带u;
但中文必须表明所需编码,否则一旦编码转换就会出现乱码。
字符串前加'f'
以'f'开头表示在字符串内支持大括号内的python表达式,相当于format函数的简写。
例如:
name='superman'
print(f'I am {name}')
print('I am {}'.format(name))运行结果为:
I am superman
I am superman字符串前加'b'
字符串前加'b'表示这是一个 bytes 对象,一般用在网络编程中,因为服务器和浏览器只认bytes 类型数据。
在Python3中,bytes和str的互相转换方式如下:
str.encode('utf-8')
bytes.decode('utf-8')好了,Python的一些基础知识就讲解到这里了,接下来,我们正式进入主题——爬取王者荣耀英雄皮肤。
爬取前分析
Ajax分析
首先我们打开王者荣耀官网,点击英雄资料,我们可以看到王者荣耀英雄的头像,如下图所示:
然后打开开发者工具,切换到XHR过滤选项卡,然后点击Rreview,查看一下有没有Ajax请求,因为我个人觉得获取数据信息,最简单的就是从Ajax请求中获取,所以一般情况下都优先查看有没有Ajax请求,没有的话,我们再考虑使用正则表达式或者XPath来获取数据信息。
经过简单的寻找,我们发现有Ajax请求,如下图所示:
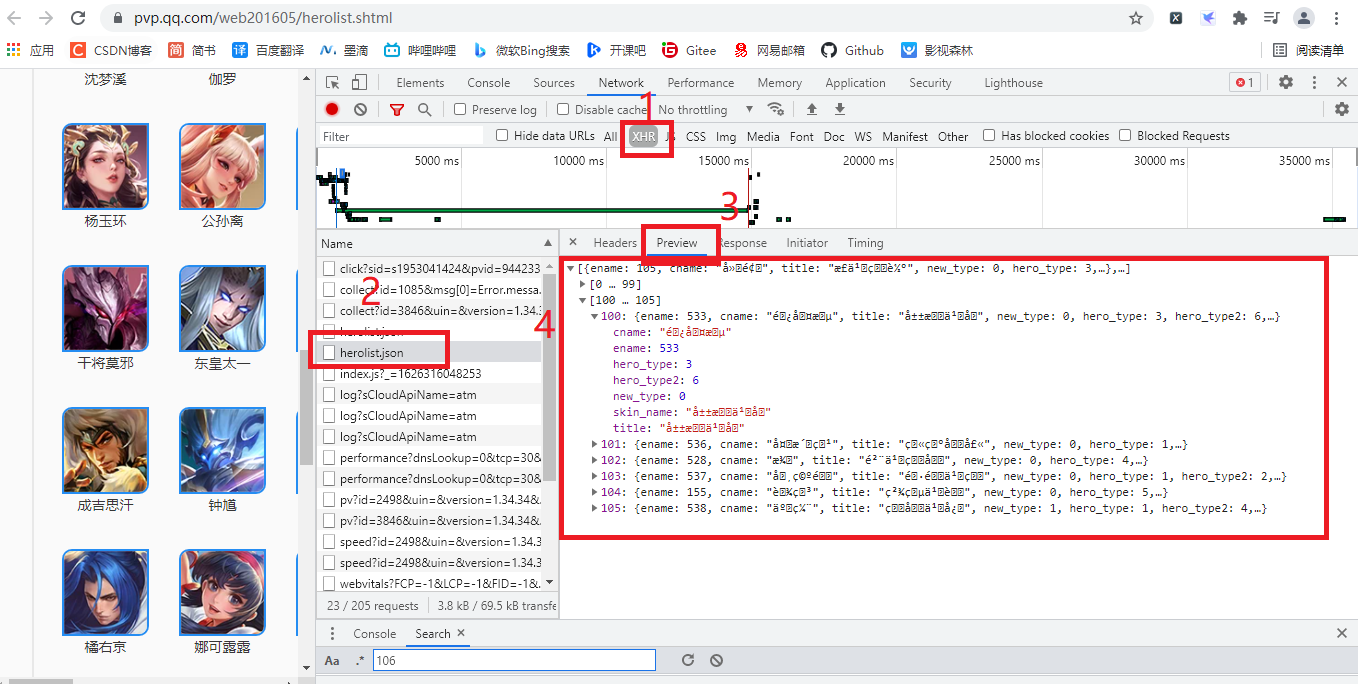
有人可能会说下面这些东西是什么,会不会一种反爬虫的方法:
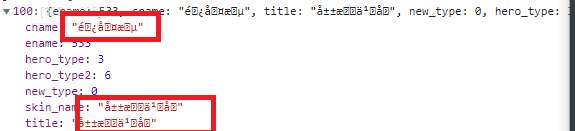
cname、skin_name、title这三个属性,我们可以从英文的角度翻译,可以知道它们分别表示英雄名,皮肤名和标题。我们先不用管它是不是一种反爬虫的手段,先尝试一下按照Ajax分析法来获取这些信息,
主要代码如下所示:
response=requests.get(url,headers=headers)
json=response.json()
for i in json:
#获取皮肤id
nameid=i.get('ename')
#获取英雄名
name=i.get('cname')
print(name)运行结果如下图:

从英雄名字可见,刚才在Ajax请求中那些乱码我们可以简单理解为只是在请求中显示为乱码,和我们获取到的数据影响不大。
在Ajax请求中的数据对我们有用的数据是英雄名字(根据英雄皮肤名来创建文件夹)和英雄id(用来构造英雄页面的链接和皮肤图片链接),有人可能说英雄皮肤名也对我们有用啊,经过观察发现在Ajax请求中,英雄皮肤名有一些是缺少的,例如:瑶。所以我们需要从另一个地方来获取英雄皮肤名。
英雄页面分析
我们随便点击几个英雄的头像,观察它们对应的URL链接区别:
夏洛特页面URL链接:https://pvp.qq.com/web201605/herodetail/536.shtml
云缨页面URL链接:https://pvp.qq.com/web201605/herodetail/538.shtml
诸葛亮页面URL链接:https://pvp.qq.com/web201605/herodetail/190.shtml通过观察可以发现,这些URL链接只有后面的数字有变化,而这些数字正是英雄的id,所以我们可以通过英雄id来构造每一个英雄的URL链接。
老规格,打开开发者工具,查看有没有Ajax请求,经过查找发现没有Ajax请求,那么我们就要考虑使用正则表达式或者XPath来获取数据信息了。在上一步的Ajax分析中,我们已经获取到了英雄名和英雄id了,我们在英雄页面中,需要获取皮肤链接和皮肤名了。
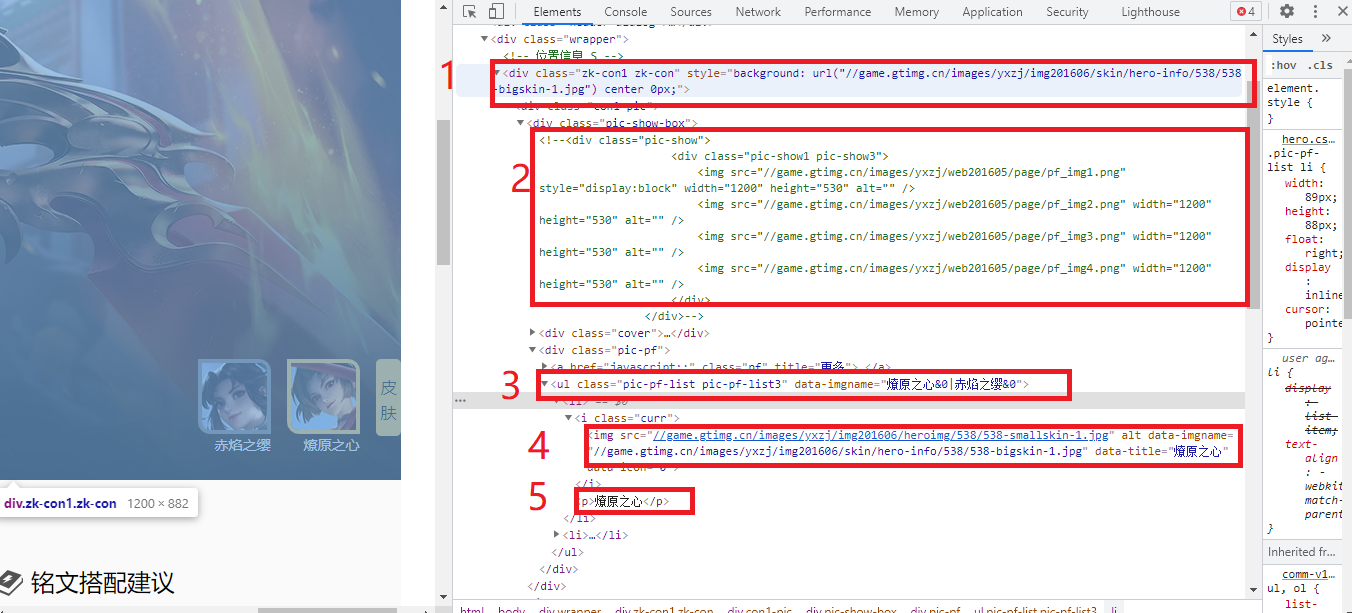
打开开发者工具发现,有不少的图片链接,很明显上图中的2、3中的URL链接并不是我们要获取的图片URL链接,那么我们打开1中的URL链接,发现该链接正是我们需要的链接:
https://game.gtimg.cn/images/yxzj/img201606/heroimg/538/538-mobileskin-1.jpg
接下来我们只需要观察这个链接的规律,根据规律来构造皮肤的URL链接
英雄:云缨
https://game.gtimg.cn/images/yxzj/img201606/heroimg/538/538-mobileskin-1.jpg #燎原之心
https://game.gtimg.cn/images/yxzj/img201606/heroimg/538/538-mobileskin-2.jpg #赤焰之缨
英雄:夏洛特
https://game.gtimg.cn/images/yxzj/img201606/heroimg/536/536-mobileskin-1.jpg #玫瑰剑士通过观察可以发现,英雄皮肤链接只有后面的:536/536-mobileskin-1.jpg有变化,其中536是英雄id,-1是图片对于的皮肤名。
既然有了规律,那么我们就可以构造图片链接的变量与之对应皮肤名组合成一个元组。爬取前分析就讲到这里,接下来我们正式开始实战。
实战演练
我们的基本爬取思路是:
-
获取英雄的部分信息,如:英雄名和id;
-
获取皮肤名和构造皮肤链接;
-
保存图片。
获取英雄部分信息
首先我们先获取英雄列表的Ajax请求,通过请求来获取英雄名和英雄id,主要的代码如下所示:
response=requests.get(url,headers=headers)
json=response.json()
for i in json:
nameid=i.get('ename')
name=i.get('cname') l
link_list=f'https://pvp.qq.com/web201605/herodetail/{nameid}.shtml'
get_data(link_list,name,nameid)首先我们通过了json()方法来获得json数据,get()方法来获取具体的数据信息,这里我们获取到了英雄名和英雄id,然后利用获取到的英雄id来构造出每个英雄页面的URL链接,再将获取到的英雄名和英雄id、URL链接传送到我们定义的get_data()方法中。这样我们的爬取的第一步就完成了。
获取英雄皮肤名与皮肤链接
在上一步我们已经获取到了英雄名、英雄id和英雄URL链接,在这一步中,我们需要利用获取到的英雄id和URL链接中来获取皮肤名和构造皮肤链接。
需要注意的是:
王者荣耀网页的源代码的head部分的编码为:gbk,如下图所示:

我们利用requests库的方法来查看默认的编码类似是什么,具体代码如下所示:
import requests
url = 'https://pvp.qq.com/web201605/herodetail/536.shtml'
response = requests.get(url)
print(response.encoding) 运行结果为:ISO-8859-1
所以我们要利用requests库改变输出结果的编码,否则会出现中文乱码的情况,如下图所示:
为了避免出现上图的中文乱码,我们利用requests库来改变输出结果的编码,具体代码如下所示:
response.encoding = 'gbk'
html=response.text改变输出结果的编码后,我们开始通过构造正则表达式对象来获取英雄皮肤名,具体代码如下所示:
patterm=re.compile('<ul.*?pic-pf-list.*?data-imgname="(.*?)">.*?</ul>',re.S)
skin_namelist=re.findall(patterm,html)我们使用re.compile()方法构造了一个正则表达式对象,再使用re.findall()方法来查找多个匹配项,并返回一个列表。
获得的数据如下所示:
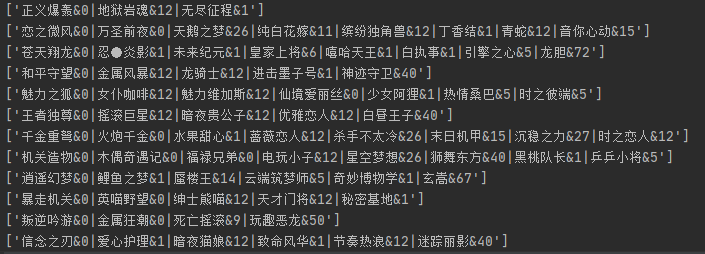
我们上面获取的初始皮肤名很显然要进行数据的处理,数据处理的主要代码如下:
for skin_name in skin_namelist:
skin=skin_name.replace('&','').replace('|','')
hero_skin=re.split('\d+',skin)
hero_skin_name=[i for i in hero_skin if i!='']
print(hero_skin_name)运行结果如下图所示:

获取完皮肤名后,接下来我们要构造皮肤URL链接,并存放在列表中,主要代码如下所示:
link_lisk=[]
for j in range(len(hero_skin_name)):
link = f'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{nameid}/{nameid}-bigskin-{j + 1}.jpg'
link_lisk.append(link)首先我们创建一个空列表来存放皮肤URL链接,然后通过英雄皮肤名的数量来增加变换构造皮肤URL链接后,接下来我们要将皮肤名和与之对应的皮肤URL链接存放在元组里面,主要代码如下所示:
link_skin_name_list = zip(link_lisk,hero_skin_name)这里我们使用了python的内置函数zip(),其传入的参数分别为皮肤URL链接和皮肤名。
好了,所有我们需要用到的数据信息都已经获取到了,接下来要开始将所有的王者荣耀英雄皮肤下载到本地文件夹中。
保存图片
在上面的步骤中,我们已经成功获取到了英雄名、英雄皮肤名和皮肤URL链接了,接下来我们开始把所有皮肤下载下来。
主要代码如下所示:
if not os.path.exists(name):
os.mkdir(name)
data=requests.get(skin_name_list[0],headers=headers).content
with open(f'{name}/{skin_name_list[1]}.jpg','wb')as f:
f.write(data)首先我们进行判断是否已经存在用英雄名作为文件名的文件夹,不存在的话,就使用os.mkdir()方法创建文件夹,其传入的参数为英雄名。再创建data变量来保存每一个皮肤URL的下载信息,最后使用write()方法,将data数据写入到文件夹中。
结果展示


好了,王者荣耀英雄皮肤图片爬取就讲到这里了,那么问题来了,你们觉得哪个英雄最厉害,哪个皮肤手感最好!!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











