







在上篇文章我们学习了MySQL进阶——SQL性能分析,这篇文章我们学习MySQL进阶——索引。
索引
索引是一种有序的数据结构,能让MySQL高效获取数据。
在没使用索引时,查询语句是进行全局扫描,例如:执行select * from user where Age=30时,MySQL会查找是否满足Age等于30的数据,在这期间即使找到满足条件的数据,也会一直查找下去,直到查找完所有数据。

在上面的例子中,需要查找9条数据才返回最终的查询结果。
为Age字段创建索引后,会通过某种索引结构来维护Age数据,例如通过二叉树数据结构来维护Age数据,如下图所示:

当使用索引后,只要找到满足Age等于30的数据就会停止继续往下查找,并返回Age等于30的数据,也就是只需要查找4次即可返回查询结果。
「索引优点:」
-
提高数据检索效率,降低数据库的IO成本;
-
通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗
「索引缺点:」
-
索引列也需要占用空间;
-
索引大大提高了查询效率,但同时也降低更新表的速度,如对表进行增删改时,效率会降低;
索引结构
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的结果,主要有以下四种索引结构:
-
B+Tree索引:最常见的索引类型,大部分引擎都支持B+树索引;
-
Hash索引:底层数据结构是用哈希表实现的,但只有精确匹配索引列的查询才有效,不支持范围查询,只有Memory存储引擎支持该索引;
-
R-tree空间索引:MyISAM引起的一个特殊索引,主要用于地理空间数据类型;
-
Full-text全文索引:通过建立倒排索引,快速匹配文档的方式,类似于Lucene,Solr,ES,Memory存储引擎不支持该索引;
MySQL索引数据结构对经典的B+Tree进行了优化,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。
为什么InnoDB存储引擎选择使用B+Tree索引结构?
-
相对于二叉树,层级更少,搜索效果高;
-
对于B-Tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低;
-
相对Hash索引,B+Tree支持范围匹配及排序操作;
索引分类
索引主要有以下四种类型:
| 分类 | 说明 | 关键字 |
|---|---|---|
| 主键索引 | 对于表中主键创建的索引,只能有一个,默认自动创建 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复,可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据,可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值,可以有多个 | FULLTEXT |
在InnoDB存储引擎中,根据索引的存储形式可以分为以下两种:
-
聚集索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据,有且只有一个;
-
二级索引:将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键,可以存在多个;
聚集索引选取规则:
-
如果存在主键,则主键索引就是聚集索引;
-
如果不存在主键,将使用第一个唯一索引作为聚集索引;
-
如果不存在主键、唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引;
索引操作
查看索引
查看索引语法格式如下:
SHOW INDEX FROM 表名;
示例代码如下:
SHOW INDEX FROM UserTable;
运行结果如下:
 查看索引
查看索引
这里我们的UserTable表的主键是ID,所以MySQL会自动创建主键索引,其索引结构BTREE。
注意:当我们创建的数据表没有主键、索引时,查看索引返回的结果为空。
创建索引
创建索引语法格式如下:
CREATE [UNIQUE | FULLTEXT] INDEX 索引名 ON 表名 (表字段,...) ;
示例代码如下:
CREATE INDEX name_idx ON UserTable (UserName);
CREATE UNIQUE INDEX email_idx ON UserTable (Email);
CREATE INDEX UserName_Phone_Occupation_idx ON UserTable (UserName,Phone,Occupation);
SHOW INDEX FROM UserTable;
运行结果如下:
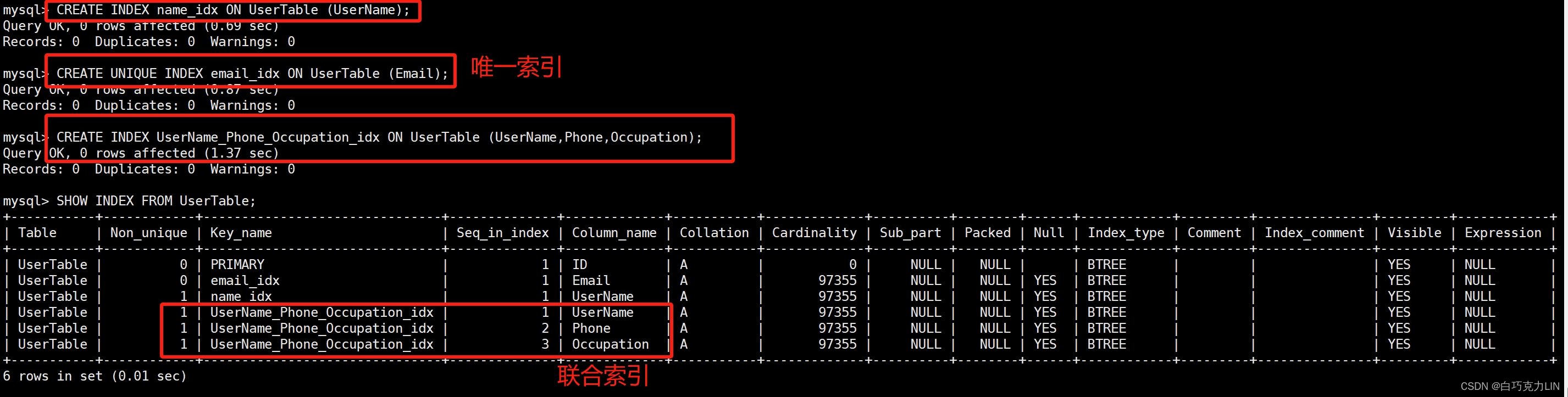
注意:
-
当我们创建索引时,只添加了一个表字段,就会形成单列索引;
-
当我们创建索引时,添加多个表字段,就会形成联合索引;
在多条件查询时,建议创建联合索引。
前缀索引
有时候索引字段的数据长度很长,这会让索引变得很大,查询时浪费大量的磁盘IO,影响查询效率。这时就可以为该字段设置前缀索引,也就是为该字段的一部分创建索引,其语法格式如下:
create index 索引名 ON 表名 (字段(前n个字符))
示例代码如下:
create index idx_UserName ON UserTable (UserName(2));
如下图所示:

这样就为UserName字段的前两个字符创建了索引。
前缀的长度可以根据索引的选择性来决定,而选择性是指不重复的索引值和数据表的数据总数的比值,选择性越高则查询效率越高,获取选择性语法格式如下:
select count(distinct 字段)/count(*) from 表名;
select count(distinct substring(字段,开始下标,截取的长度))/count(*) from 表名;
示例代码如下:
select count(distinct Phone)/count(*) from UserTable;
select count(distinct substring(Phone,1,3))/count(*) from UserTable;
如下图所示:
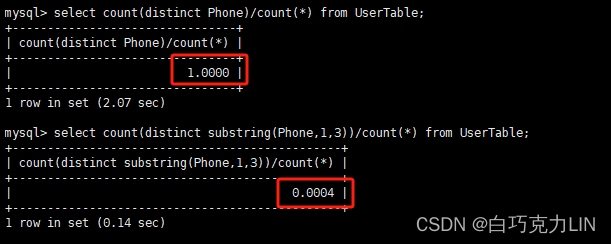
唯一索引的选择性是1,是最好的索引选择性,性能也是最好的。
删除索引
删除索引语法格式如下:
DROP INDEX 索引名 ON 表名;
示例代码如下:
DROP INDEX name_idx ON UserTable;
SHOW INDEX FROM UserTable;
运行结果如下:

这样就成功删除了name_idx索引了。
索引效率
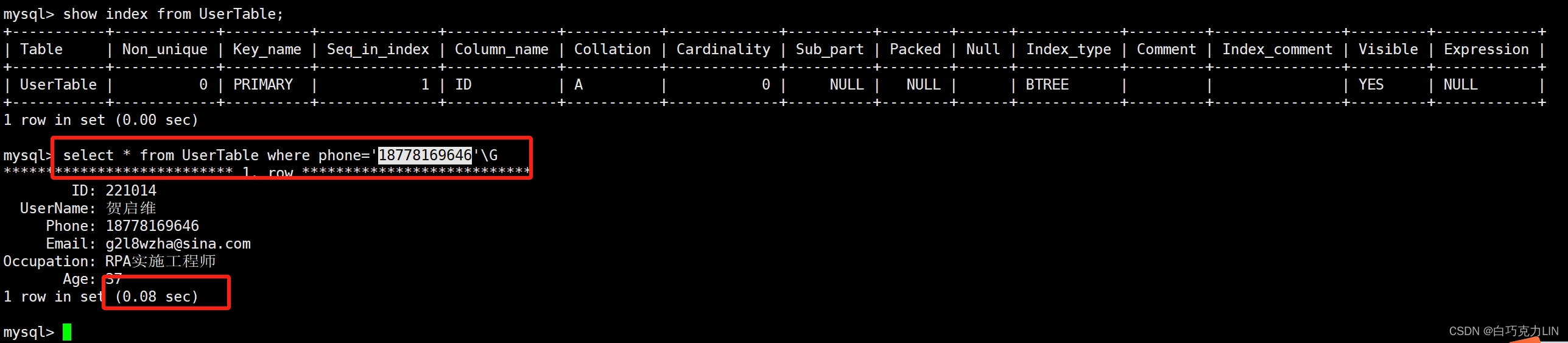
在二十多万数据中,不使用索引时,查询手机号为18778169646的数据用了0.08秒,如下图所示:
为手机号phone设置索引后,查询手机号为18778169646的数据用时不到0.01秒,如下图所示:
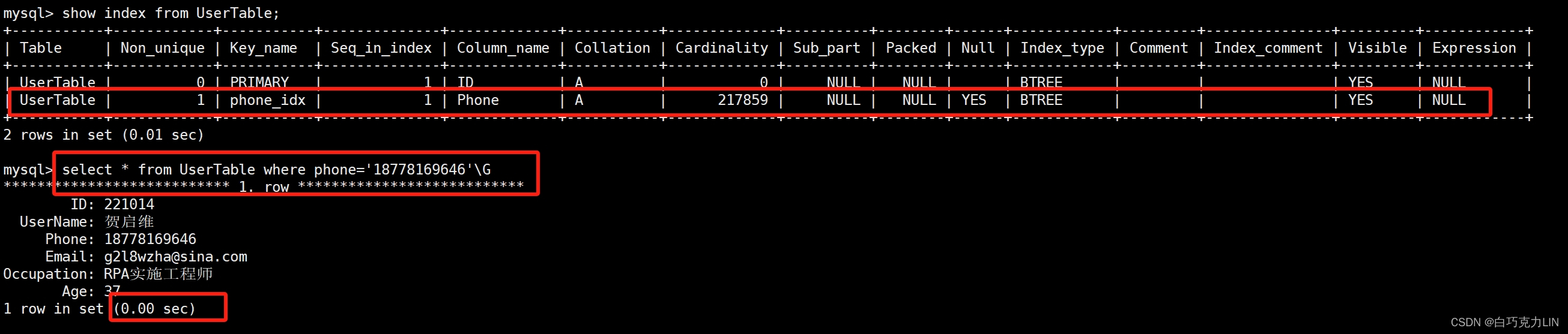
对比发现,当我们使用索引后,查询效率大大提升。
好了,MySQL进阶——索引就学到这里了。
公众号:白巧克力LIN
该公众号发布Python、数据库、Linux、Flask、Django、自动化测试、Git、算法、前端、服务器等相关文章!
- END -
















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











