







目录
Linux,MySQL,finalshell都安装好啦!开干!
(1)先启动虚拟机,然后打开远程连接finalshell
(2)输入mysql -u root -p,连接到Linux中的MySQL数据库。就可以在这上面操作Linux-MySQL啦(我是这么理解的)
1索引概述
索引 (index)是帮助MysQL高效获取数据的数据结构(有序)。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
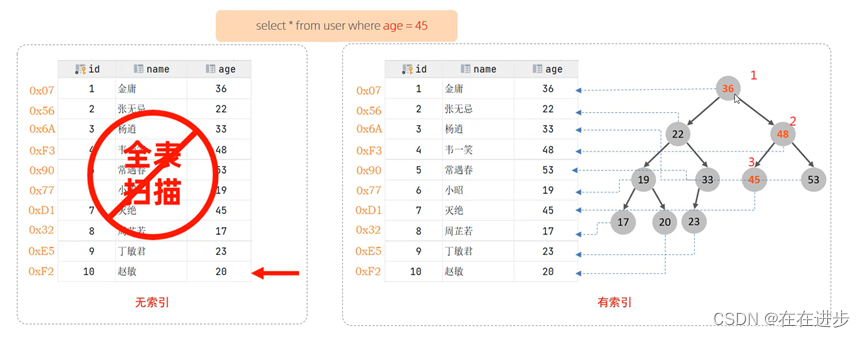
(1)无索引情况:就需要从第一行开始扫描,一直扫描到最后一行,我们称之为全表扫描,性能很低。
(2)有索引情况:如果我们针对于这张表建立了索引,假设索引结构就是二叉树(存储结构),那么也就意味着,会对age这个字段建立一个二叉树的索引结构。此时我们在进行查询时,只需要扫描三次就可以找到数据了,极大的提高的查询的效率。
优缺点:

2索引结构
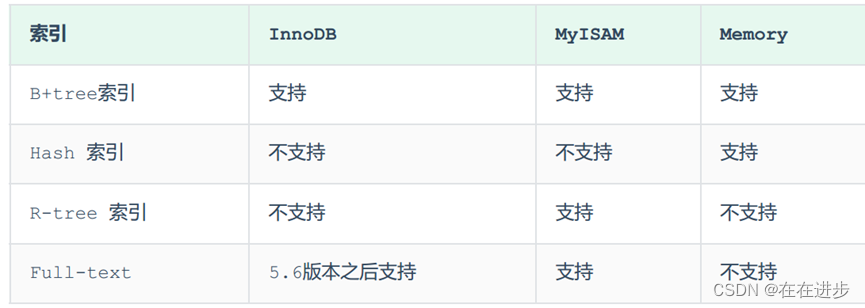
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的索引结构,主要包含以下几种:
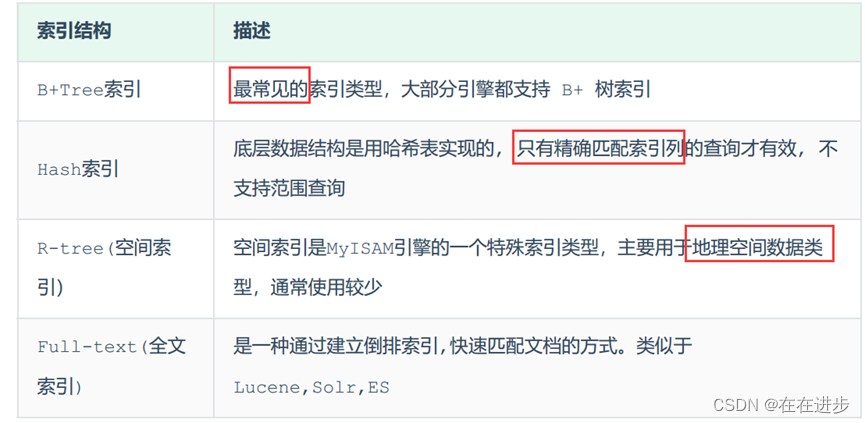
上述是MySQL中所支持的所有的索引结构,接下来,我们再来看看不同的存储引擎对于索引结构的支持情况:
2.1 B-Tree(多路平衡查找树)
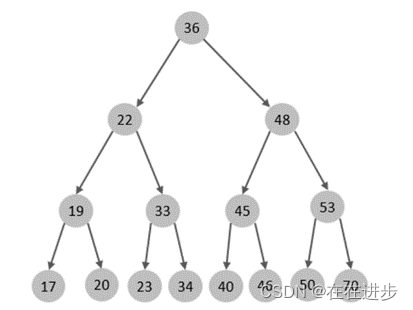
普通的二叉树(理想情况):
普通的二叉树(最糟糕情况——顺序插入):
如果主键是顺序插入的,则会形成一个单向链表,结构如下。

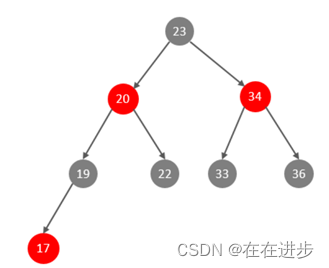
通过红色树来解决上面这个平衡问题,因为红黑树是自平衡的二叉树:
那这样即使是顺序插入数据,最终形成的数据结构也是一颗平衡的二叉树,结构如下。但是红黑树也有缺点:大数据量情况下,层级较深,检索速度慢。
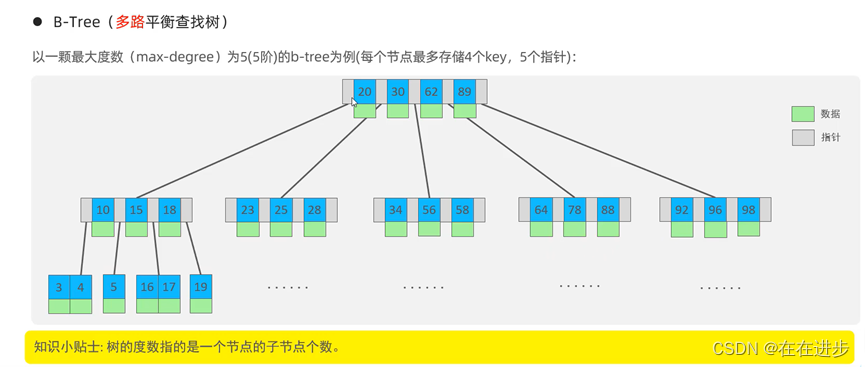
所以,在MySQL的索引结构中,并没有选择二叉树或者红黑树,而选择的是B+Tree,
数据结构可视化网(www.cs.usfca.edu)
https://www.cs.usfca.edu/~galles/visualization/BTree.html
随着插入,中间节点往上移。
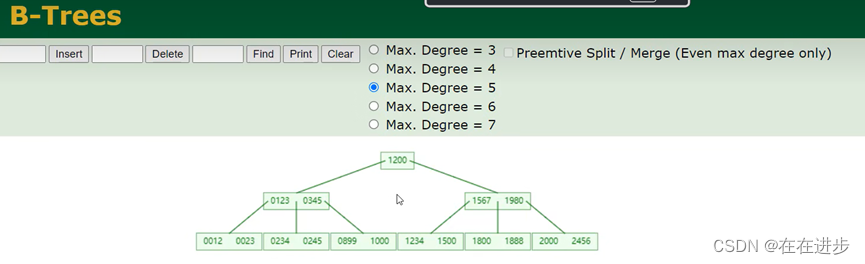
2.2 B+Tree
B+Tree是B-Tree的变种 ,B+Tree中所有的节点都会出现在叶子节点。
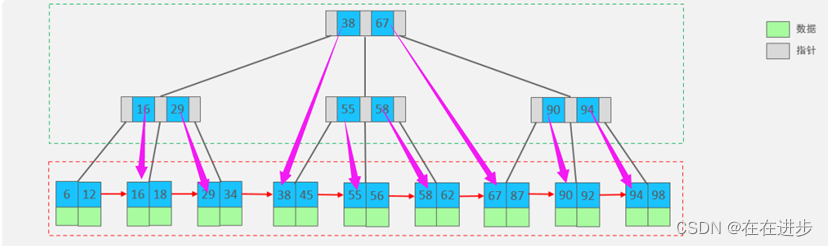
最终我们看到,B+Tree 与 B-Tree相比,B+Tree主要有以下三点区别:
(1)所有的数据都会出现在叶子节点。
(2)叶子节点形成一个单向链表。
(3)非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的。
2.3 hash
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。

补充数据结构只是,当遇到hash冲突的解决方法:
1、开放定址法:我们在遇到哈希冲突时,去寻找一个新的空闲的哈希地址。
(1)线性探测法
当我们的所需要存放值的位置被占了,我们就往后面一直加1并对m取模直到存在一个空余的地址供我们存放值,取模是为了保证找到的位置在0~m-1的有效空间之中。
(2)平方探测法(二次探测)
当我们的所需要存放值的位置被占了,会前后寻找而不是单独方向的寻找。
2、再哈希法:同时构造多个不同的哈希函数,等发生哈希冲突时就使用第二个、第三个……等其他的哈希函数计算地址,直到不发生冲突为止。虽然不易发生聚集,但是增加了计算时间。
3、链地址法:将所有哈希地址相同的记录都链接在同一链表中。
4、建立公共溢出区:将哈希表分为基本表和溢出表,将发生冲突的都存放在溢出表中。
Hash树特点:
(1) Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,< ,...)
(2)无法利用索引完成排序操作
(3)查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引
思考题:为什么InnoDB存储引擎选择使用B+tree索引结构?
(1)相对于二叉树,层级更少,搜索效率高;
(2)对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低;
(3)相对Hash索引,B+tree支持范围匹配及排序操作;
3索引分类
3.1MySQL中分4类
在MySQL数据库,将索引的具体类型主要分为以下几类:主键索引、唯一索引、常规索引、全文索引。

3.2 InnoDB存储引擎分两类(SQL优化中重要)
而在在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:聚集索引和二级索引/辅助索引/非聚集索引。

聚集索引选取规则:
(1)如果存在主键,主键索引就是聚集索引。
(2)如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
(3)如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
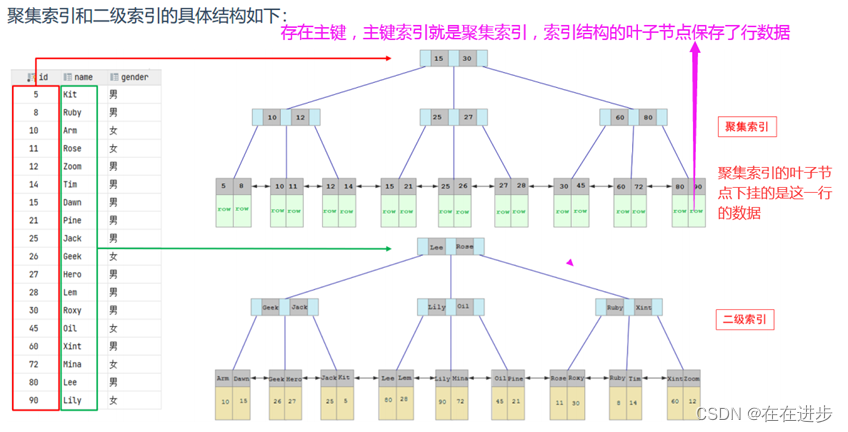
除开聚集索引,其他都是二级索引。索引的叶子节点下挂的是该字段值对应的主键值。
lnnoDB主键索引的B+tree高度为多高呢?
假设:一行数据大小为1k,,一页中可以存储16行这样的数据。InnoDB的指针占用6
个字节的空间,主键即使为bigint,占用字节数为8。
(1)高度为2:
n * 8+(n +1)*6=16*1024,算出n约为1170(每一行的节点个数)
1171*16=18736
(2)高度为3:
1171 * 1771 * 16= 21939856
(发现InnoDB存储就算存储2000多万个记录数,也才3层,检索效率很高)
4索引语法
4.1创建和查看索引
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name, . .. ) ;
SHOW INDEX FROM table_name ;
案例:按照下列的需求,完成索引的创建
1. name字段为姓名字段,该字段的值可能会重复,为该字段创建索引。
2. phone手机号字段的值,是非空,且唯一的,为该字段创建唯一索引。
3.为profession、age、status创建联合索引。
4.为email建立合适的索引来提升查询效率。
演示:
(1)新建itcast数据库,并在其中准备两个表格:
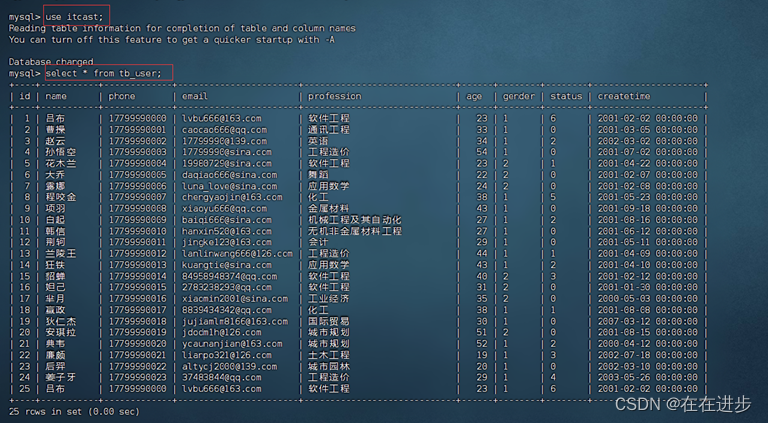
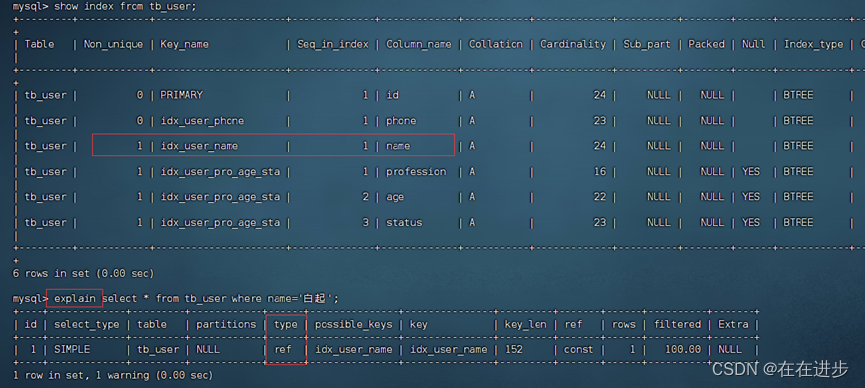
(2)查询tb_user表的索引情况,

在分号之前加上\G,可以转置展示。
(3)完成:1. name字段为姓名字段,该字段的值可能会重复,为该字段创建索引。
输入创建索引语句:create index idx_user_name on tb_user(name);

(因为InnoDB引擎默认是BTree)
(4)完成:2. phone手机号字段的值,是非空,且唯一的,为该字段创建唯一索引。
是非空,且唯一的就要加上关键字UNIQUE。
输入创建索引语句:create unique index idx_user_phone on tb_user(phone);
但是报错了:

猜想是原本的数据库中已经有重复不唯一的两个电话phone了,所以不能满足unique条件。
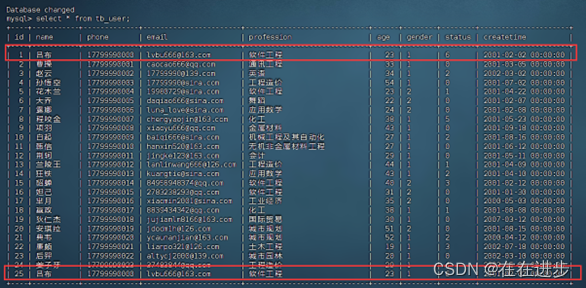
利用DELETE FROM表名[WHERE条件],删除重复的数据:
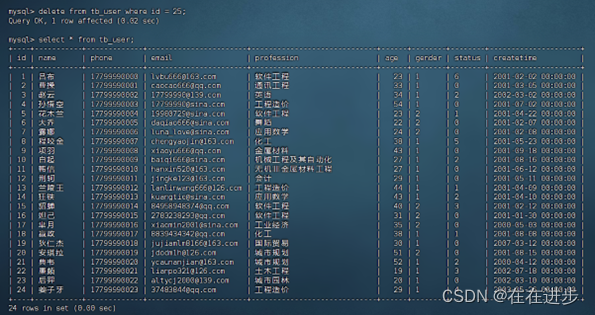
现在输入:CREATE UNIQUE INDEX idx_user_phone ON tb_user(phone);
就能成功创建索引:

(5)完成:3.为profession、age、status创建联合索引。
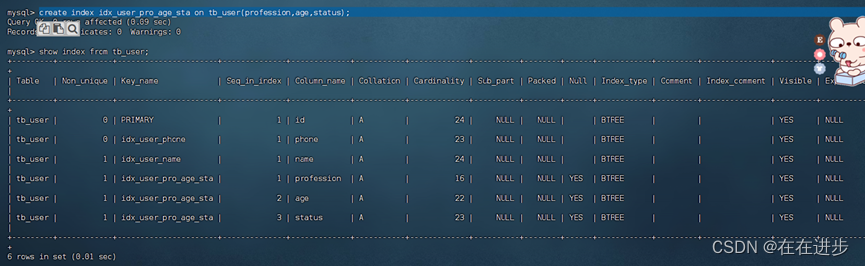
输入:create index idx_user_pro_age_sta on tb_user(profession,age,status);
注意,在联合索引中,字段顺序有讲究的,后面说
(6)完成:4.为email建立合适的索引来提升查询效率。
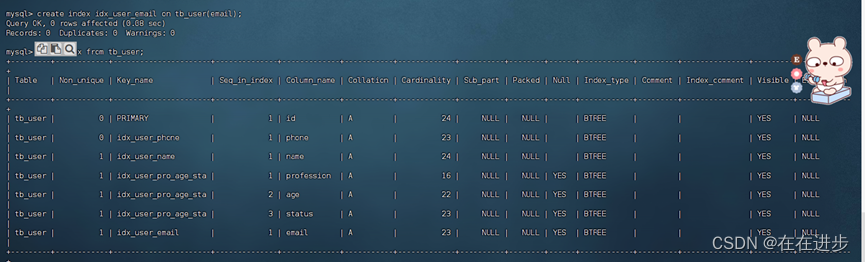
4.2删除索引
DROP INDEX index_name ON table_name ;
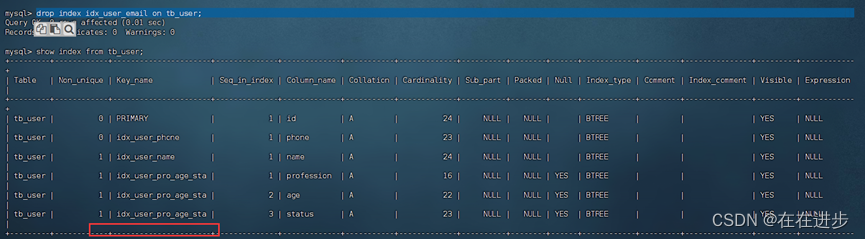
如:删除emai的索引
输入:drop index idx_user_email on tb_user;
5 SQL性能分析
5.1 查看执行频次
SQL优化的主要是查询select语句。MySQL 客户端连接成功后,通过 show [session | global] status 命令可以提供服务器状态信息。
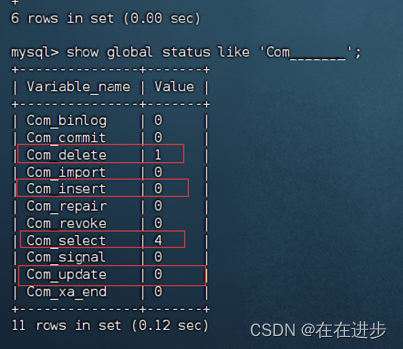
通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:-- session 是查看当前会话;-- global是查询全局数据;
SHOW GLOBAL STATUS LIKE 'Com_______';
输入:show global status like 'Com_______';(7个_)
5.2慢查询日志
借助慢查询日志,来定位SQL执行效率比较低的语句,从而对这类上SQL语句进行优化。
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有 SQL语句的日志。
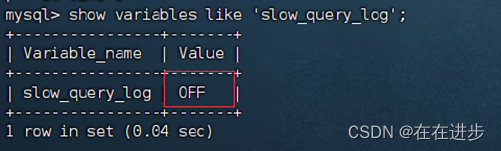
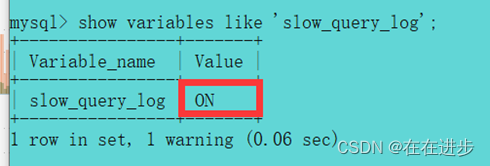
MySQL的慢查询日志默认没有开启,我们可以查看一下系统变量 slow_query_log。
输入:show variables like 'slow_query_log';发现默认没有开启。
但是我Windows中的mysql是开启状态呢。
开启慢查询日志,利用Linux中的vi编辑器!
在Linux路径而不是mysql路径,输入:vi /etc/my.cnf;
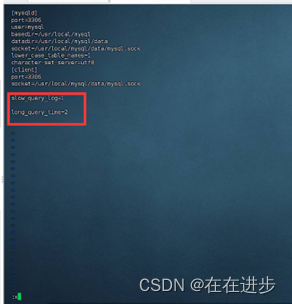
然后按i进入输入状态,按esc退出输入,尾部:x保存并退出,vi操作不是很熟练,后面可能要补一下Linux方面的知识。
输入:systemctl restart mysqld 重新启动mysql,但是我这报错是为啥?

芭比Q了,路径不一样(安装方式不一样)。

课的:cd /var/lib/mysql;
我的:cd /usr/local/mysql/data;
5.3profile详情(慢日志不行可以用这个)
输入:select @@have_profiling;查看。。。

开启之后,查看目前的指令执行耗时情况:
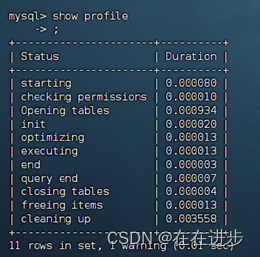
执行一系列SQL之后再次查看当前执行SQL语句耗时情况:show profiles;
可以看到根据主键id查询,比二级索引name查询要快十倍!
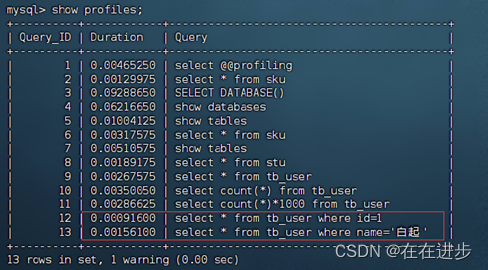
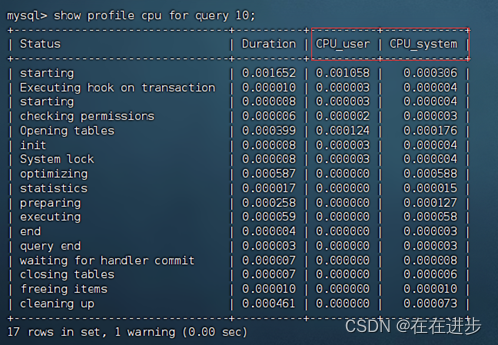
查看指定语句的耗费在哪些操作中:show profile for query 10;

还可以查询CPU耗费情况:show profile cpu for query 10;
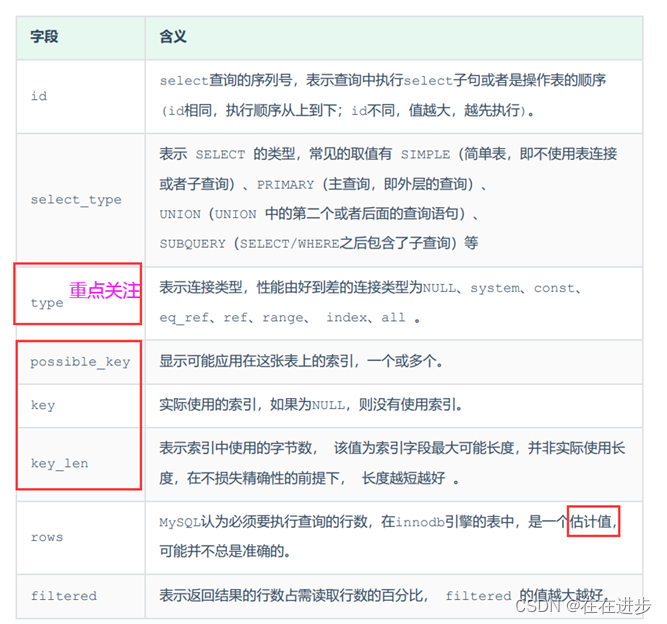
5.4 explain(重要)
通过时间来判断SQL语句的性能比较粗略,用explain可以查看SQL执行计划,一般通过explain来判断SQL性能。

在select前加上explain或desc就可以查询这个SQL语句的执行计划。

Explain 执行计划中各个字段的含义:
创建多表:
create table student(
id int auto_increment primary key comment '主键ID',
name varchar(10) comment '姓名',
no varchar(10) comment '学号'
) comment '学生表';
insert into student values (null, '黛绮丝', '2000100101'),(null, '谢逊', '2000100102'),(null, '殷天正', '2000100103'),(null, '韦一笑', '2000100104');
create table course(
id int auto_increment primary key comment '主键ID',
name varchar(10) comment '课程名称'
) comment '课程表';
insert into course values (null, 'Java'), (null, 'PHP'), (null , 'MySQL') , (null, 'Hadoop');
create table student_course(
id int auto_increment comment '主键' primary key,
studentid int not null comment '学生ID',
courseid int not null comment '课程ID',
constraint fk_courseid foreign key (courseid) references course (id),
constraint fk_studentid foreign key (studentid) references student (id)
)comment '学生课程中间表';
insert into student_course values (null,1,1),(null,1,2),(null,1,3),(null,2,2),(null,2,3),(null,3,4);

id相同,执行顺序从上到下; 但是这里不是一个sc连接两个吗?
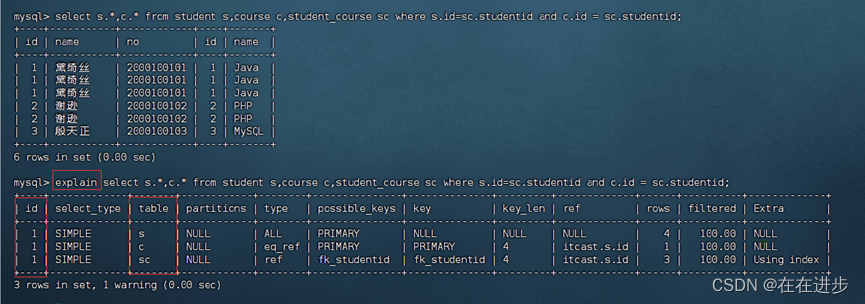
id不同,值越大,越先执行:
案例:查询选修了MySQL课程的学生
最先执行c表,找到MySQL的课程id
然后执行sc,找到这个课程id对应的学生id
然后执行s,找到学生id对应的学生信息。
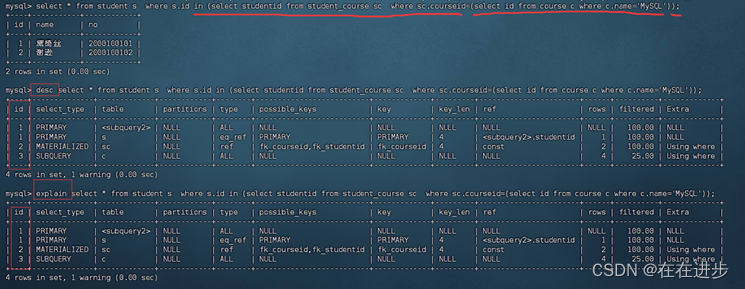
type表示连接类型:
性能由好到差的连接类型为NULL、system、const、eq_ref、ref、range、 index、all。
(1)All全表扫描是性能最差的,null是最好的,但是一般不可能优化到null,null表示不调用任何表。如select ‘A’; 连接类型就为null。
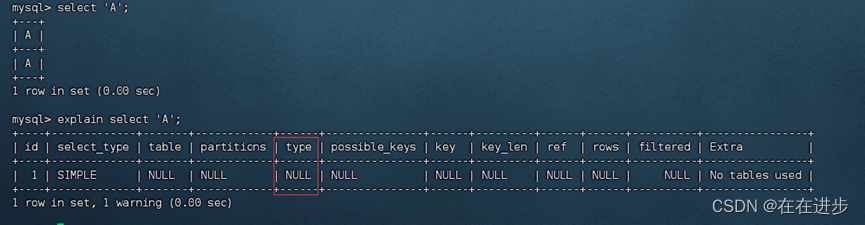
(2)使用主键/唯一索引进行查询,类型就是const。
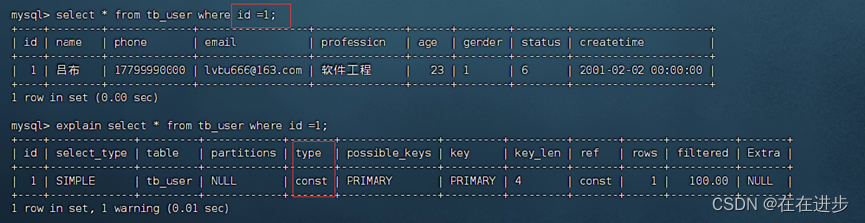
(3)如果使用非唯一索引进行查询,类型就是ref。
6索引使用原则
6.1验证索引效率
6.1.1先准备数据
数据下载链接:https://pan.baidu.com/s/1N2wkOOn5Dvo0w9XUrUFCHA?pwd=hhhh
提取码:hhhh
创建表
CREATE TABLE `tb_sku` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '商品id',
`sn` varchar(100) NOT NULL COMMENT '商品条码',
`name` varchar(200) NOT NULL COMMENT 'SKU名称',
`price` int(20) NOT NULL COMMENT '价格(分)',
`num` int(10) NOT NULL COMMENT '库存数量',
`alert_num` int(11) DEFAULT NULL COMMENT '库存预警数量',
`image` varchar(200) DEFAULT NULL COMMENT '商品图片',
`images` varchar(2000) DEFAULT NULL COMMENT '商品图片列表',
`weight` int(11) DEFAULT NULL COMMENT '重量(克)',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`category_name` varchar(200) DEFAULT NULL COMMENT '类目名称',
`brand_name` varchar(100) DEFAULT NULL COMMENT '品牌名称',
`spec` varchar(200) DEFAULT NULL COMMENT '规格',
`sale_num` int(11) DEFAULT '0' COMMENT '销量',
`comment_num` int(11) DEFAULT '0' COMMENT '评论数',
`status` char(1) DEFAULT '1' COMMENT '商品状态 1-正常,2-下架,3-删除',
PRIMARY KEY (`id`) USING BTREE
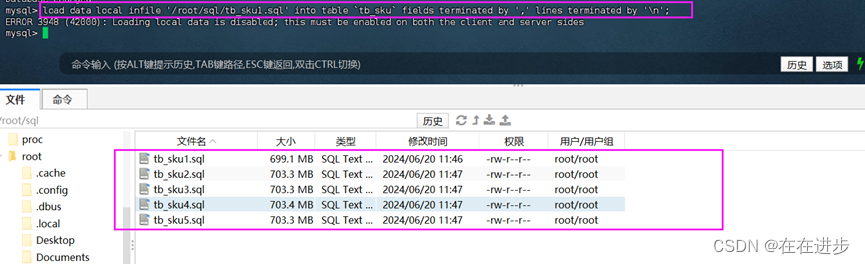
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品表';导入数据:先进100w的数据分成5部分,通过finalshell上传到root/sql中。然后输入下面语句导入sql数据,但是结果显示报错。
load data local infile '/root/sql/tb_sku1.sql' into table `tb_sku` fields terminated by ',' lines terminated by '\n';
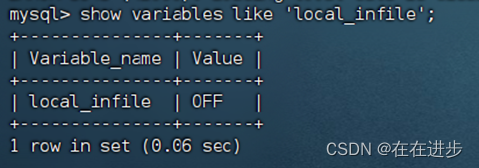
解决这个问题:
查看是否开启加载本地文件 show variables like 'local_infile';
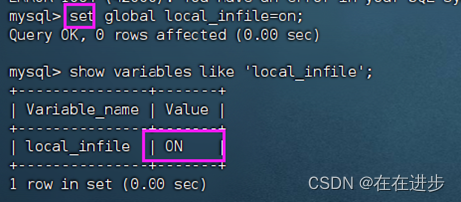
开启全局本地文件设置 set global local_infile=on;
还报错:说访问限制,请求被拒绝。

解决方法是使用下列命令重新登录MySQL:(注意不是在原来的mysql中,而是重新开一个标签,重新登录mysql)
mysql -u root -p --local-infile
![]()
成功导入大量数据200万数据:怕卡顿,我就输入一部分数据吧

6.1.2验证效率
果然是大量数据:
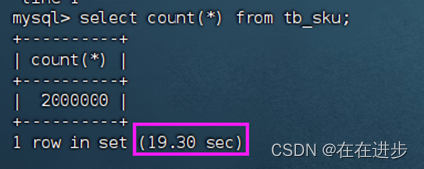
利用主键(聚集索引)进行查询:发现还是挺快的,几乎秒出
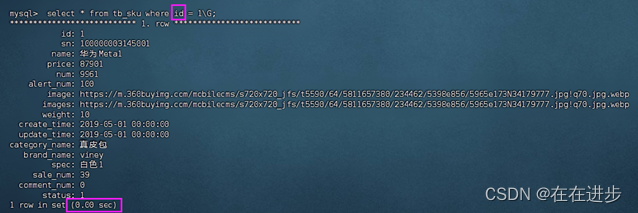
但是利用sn(没有索引)查询:发现很慢,时间要18.6秒
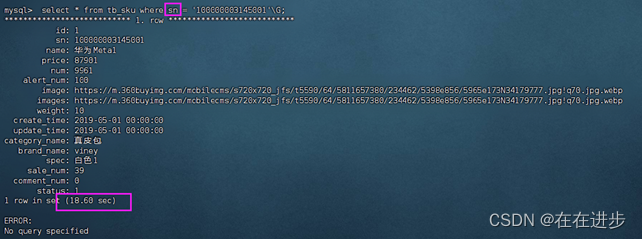
所以为了提升sn查询效率,就可以新建索引(空间换时间):
因为有200万数据,索引新建索引页要很久,40多秒
create index idx_sku_sn on tb_sku(sn) ;

然后再次执行相同的SQL语句,再次查看SQL的耗时。
sn有了索引之后就快很多了:提升的量级不是一个数量级的

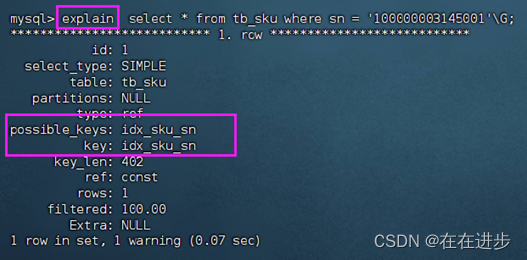
用explain获取SQL执行的信息,发现是用到了索引的:
explain select * from tb_sku where sn = '100000003145001'\G;
6.2最左前缀法则
如果索引了多列(联合索引:一个索引关联了多个字段),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将会部分失效(后面的字段索引失效)
以tb_user2为例:之前案例为这个表创建了联合索引
3.为profession、age、status创建联合索引。
输入:create index idx_user_pro_age_sta on tb_user2(profession,age,status);
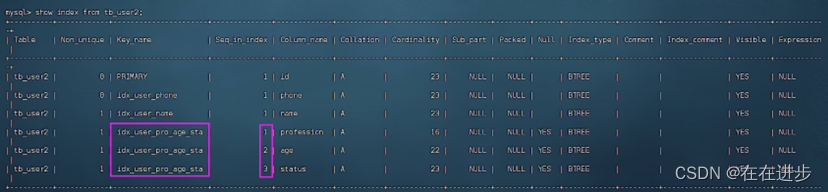
最左前缀使用法则就是:
若要用这个联合索引,则必须保证最左的profession这第一个字段值必须存在。如果跳过age则age后面的status的索引将会失效。
输入:explain select * from tb_user2 where profession='软件工程' and age=31 and status='0';
发现
(1)跳过age发现下面两个代码key_len一样,即status的索引失效了。
explain select * from tb_user2 where profession='软件工程' and status='0';
explain select * from tb_user2 where profession='软件工程'
(2)当最左侧的profession没了,就不能走索引了。key为null
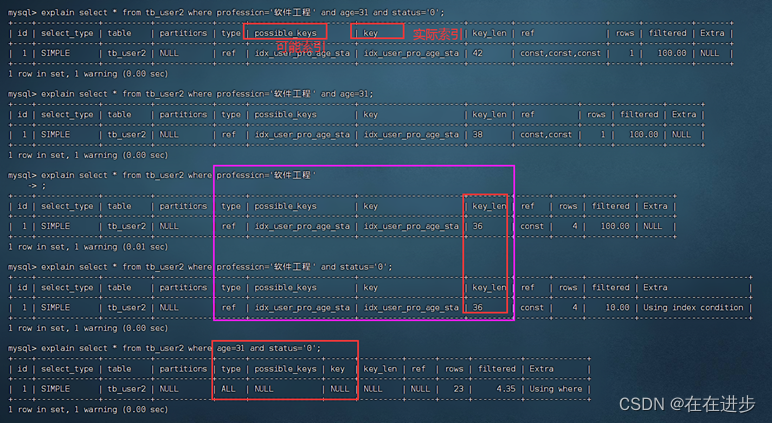
(3)最左前缀法则是指创建联合索引时,(profession,age,status),最左侧的profession必须在,位置在哪里没有关系,索引下面两行代码效果相同。
explain select * from tb_user2 where profession='软件工程' and age=31 and status='0';
explain select * from tb_user2 where age=31 and status='0' and profession='软件工程';
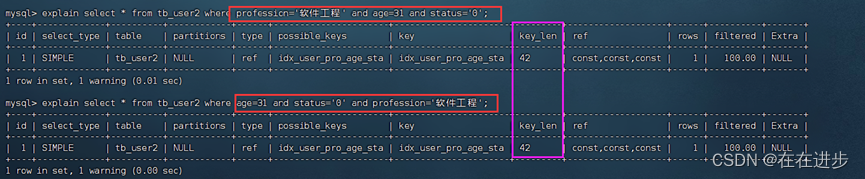
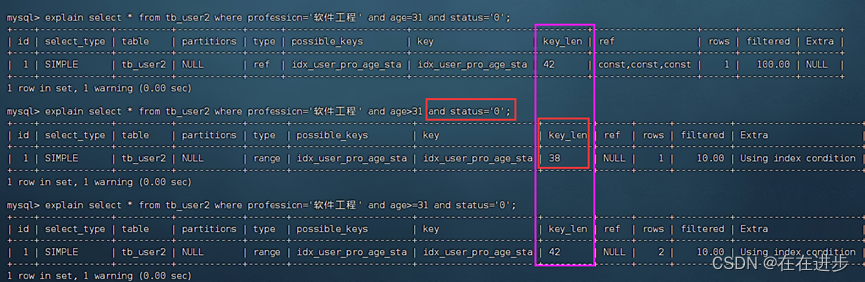
6.3范围查询法则
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效。
如下图所以,当age用>时,status索引失效,使用>=时不会失效。
6.4索引列运算——索引失效
不要在要索引的列上进行运算操作,这个字段的索引将失效。
如正常可以用索引idx_user_phone:
explain select * from tb_user2 where phone='17799990015';
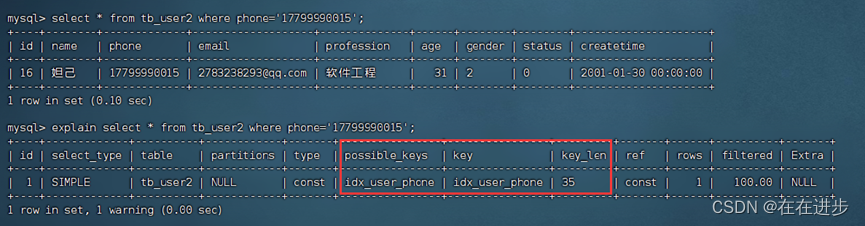
但是当对phone进行了列运算(截取substring),索引就失效了:
explain select * from tb_user2 where substring(phone,10,2)=15;
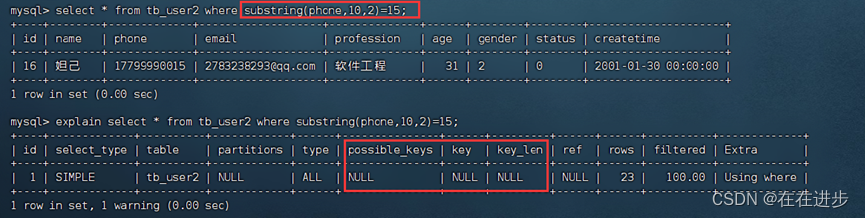
6.5字符串不加引号——索引失效
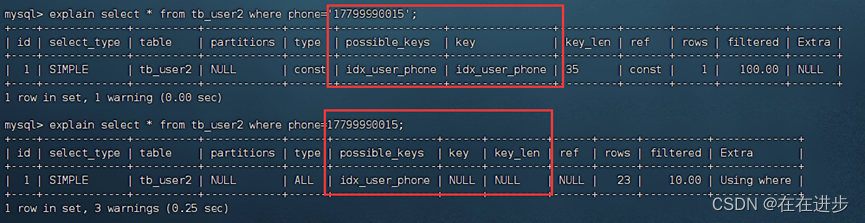
字符串类型字段使用时,不加引号,索引将失效。
如下面代码虽然查询结果与加引号一样,但是phone的索引就失效了:
explain select * from tb_user2 where phone=17799990015;
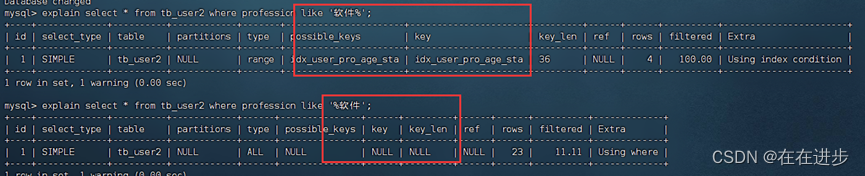
6.6模糊查询——索引失效
如果仅仅是尾部模糊匹配like,索引不会失效。
如果是头部模糊匹配,索引失效。
6.7 or连接的条件
用or分割开的条件, 如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
如下面的案例,id虽然有索引,但是or连接的age没有索引,那么整个都不会用到索引:
explain select * from tb_user2 where id=10 or age = 23;
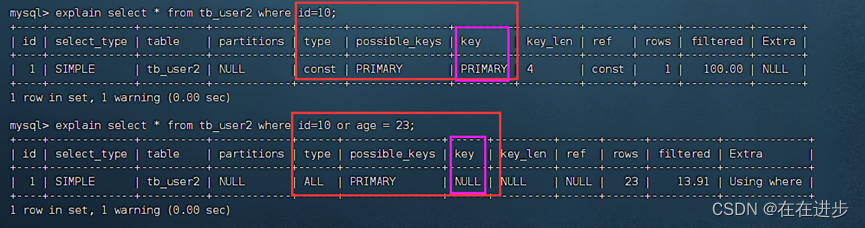
但是如果id和phone都有索引,那么or连接两个索引都会用到,and连接只用主键索引。
explain select * from tb_user2 where id=10 or phone='17799990015';
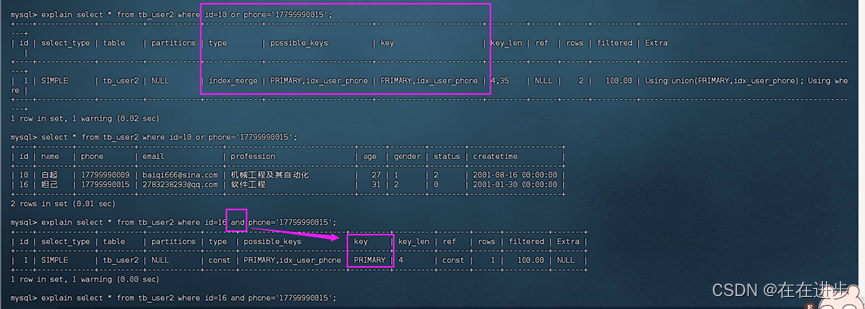
6.8数据分布影响
如果MySQL评估使用索引比全表更慢,则不使用索引。
案例:
查询部分数据:select * from tb_user2 where phone>'17799990015';
查询全部数据:select * from tb_user2 where phone>'17799990000';
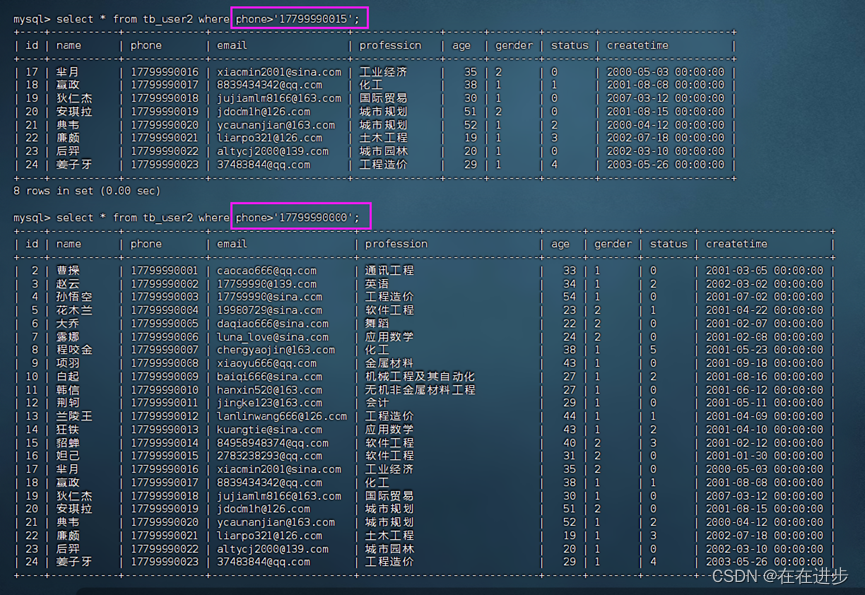
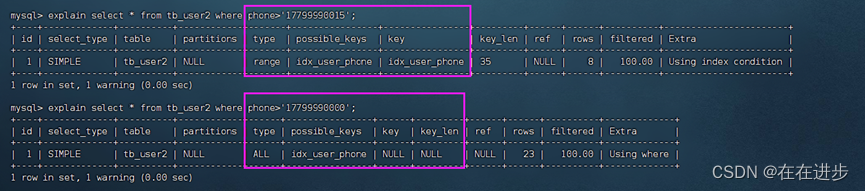
当走索引也是查询出的是全部数据时,索引就会失效,直接全表扫描。
6.9 SQL提示
先创建3个索引
create index idx_user_age on tb_user2(age);
create index idx_user_email on tb_user2(email);
create index idx_user_pro on tb_user2(profession);
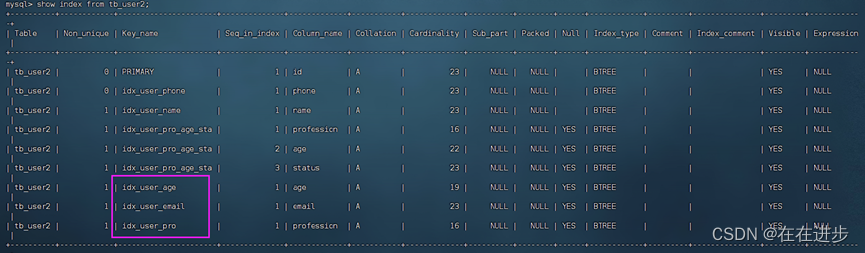
SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示(人为指定的索引)来达到优化操作的目的。
6.9.1 use index
建议MySQL使用哪一个索引完成此次查询(仅仅是建议,mysql内部还会再次进 行评估)。
explain select * from tb_user2 use index(idx_user_pro) where profession = '软件工程';
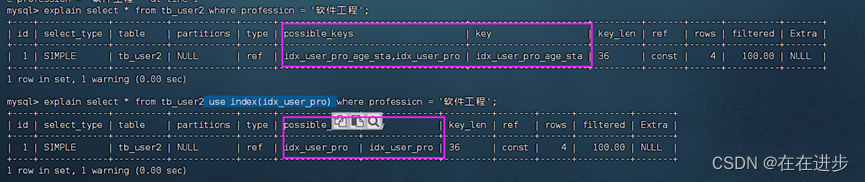
6.9.2 ignore index
ignore index:忽略指定的索引。
explain select * from tb_user2 ignore index(idx_user_pro) where profession = '软件工程';

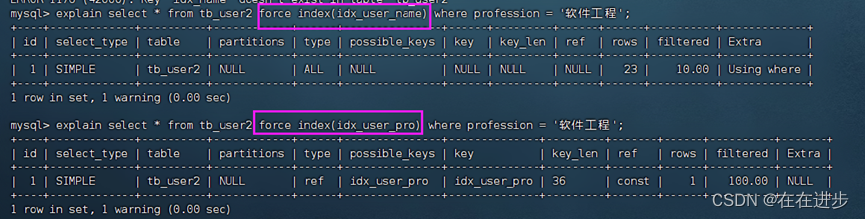
6.9.3 force index
强制使用指定索引:虽然结果会离谱
explain select * from tb_user2 force index(idx_user_name) where profession = '软件工程';
6.10 覆盖索引
尽量使用覆盖索引,减少select *(很容易出现回表查询,性能会降低)。
覆盖索引:
查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到(不需要回表查询) 。
案例:
先删除一些索引:
drop index idx_user_age on tb_user2;
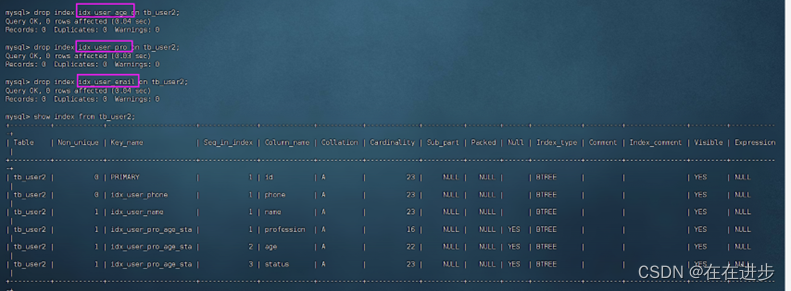
不需要回表查询意思就是,在二级索引中直接查询到了所需要需要的数据(覆盖索引)。
要回表查询就是二级索引下面的叶子结点没有name这个字段,要去检查聚集索引(要查询的字段超出了覆盖索引的范围)。
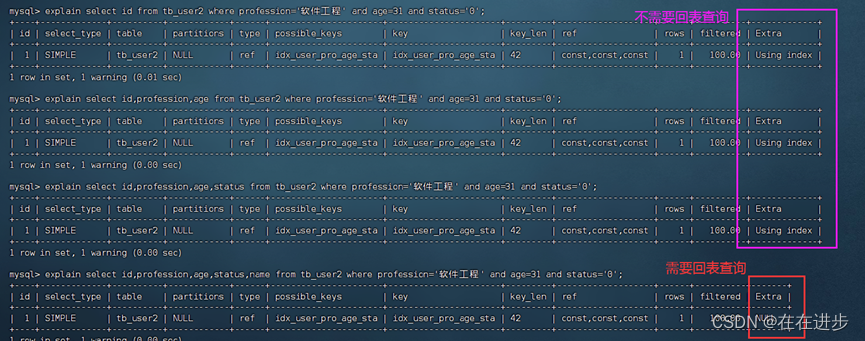
思考题:
一张表, 有四个字段(id, username, password, status), 由于数据量大, 需要对
以下SQL语句进行优化, 该如何进行才是最优方案:
select id,username,password from tb_user where username ='itcast';
答案:
针对于 username, password建立联合索引,
sql为: create index idx_user_name_pass on tb_user(username,password);
这样可以使得上述的SQL语句在查询的过程中避免出现回表查询。
6.11前缀索引
当字段类型为字符串(varchar,text,longtext等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO, 影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
count(distinct substring(email,1,5))/count(*)为截取email前5个字符的选择性,选择性=1是最准确的:select count(distinct substring(email,1,5))/count(*) from tb_user2;
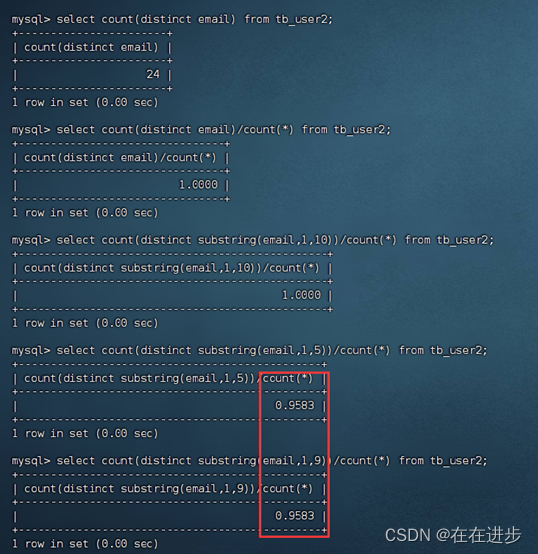
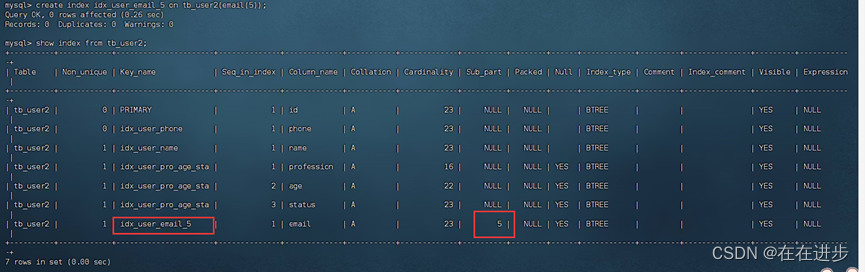
分析为tb_user表的email字段,建立长度为5的前缀索引(选择性比较高)。
create index idx_user_email_5 on tb_user2(email(5));
email(5)表示给email字段取5个前缀。
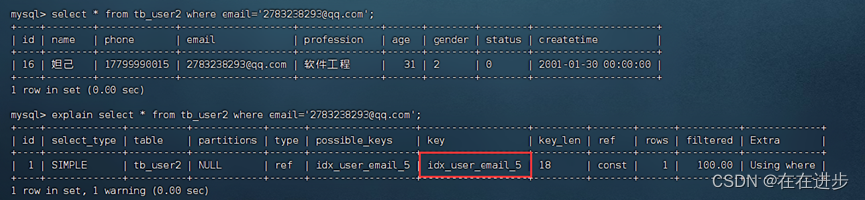
再查询email就用上这个前缀索引了:
explain select * from tb_user2 where email='2783238293@qq.com';
6.12单列索引与联合索引
单列索引:即一个索引只包含单个列。
联合索引:即一个索引包含了多个列。
使用单列索引的案例:
explain select * from tb_user2 where phone='17799990010' and name='韩信';
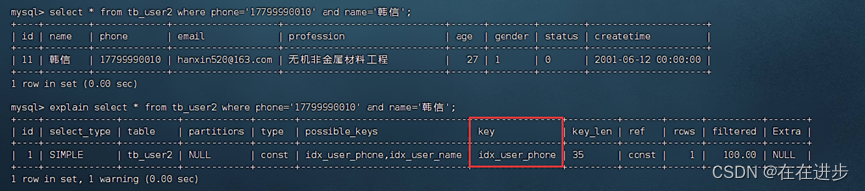
使用多列索引的案例:
(1)创建联合索引:
create unique index idx_user_phone_name on tb_user2(phone,name);
因为phone本来就是唯一的,索引联合索引页应该是唯一的。
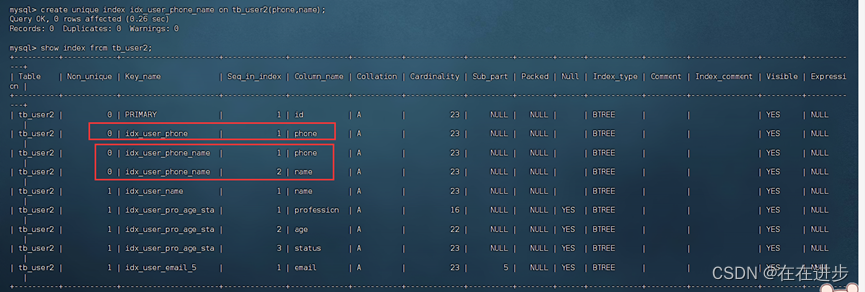
(2)发现使用联合索引不用进行回表查询
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
explain select id,phone,name from tb_user2 use index(idx_user_phone_name) where phone='17799990010' and name='韩信';

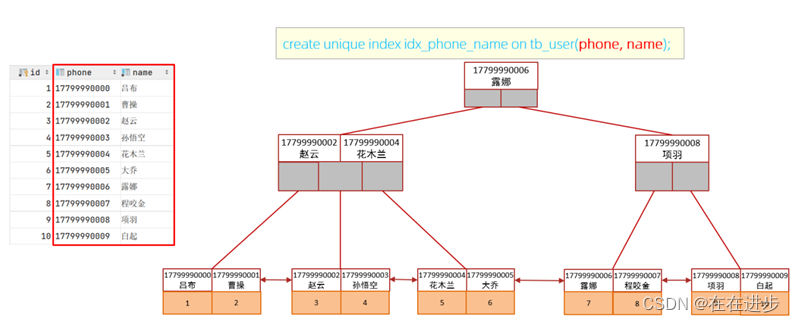
如果查询使用的是联合索引(属于二级索引,叶子节点对应主键id),
具体的结构示意图如下:
7索引设计原则
1). 针对于数据量较大,且查询比较频繁的表建立索引。
2). 针对于常作为查询条件(where),排序(order by),分组(group by)的字段建立索引。
3). 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
4). 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
5). 尽量使用联合索引(要遵循最左前缀法则),减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
6). 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
7). 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。这样有助于优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









