







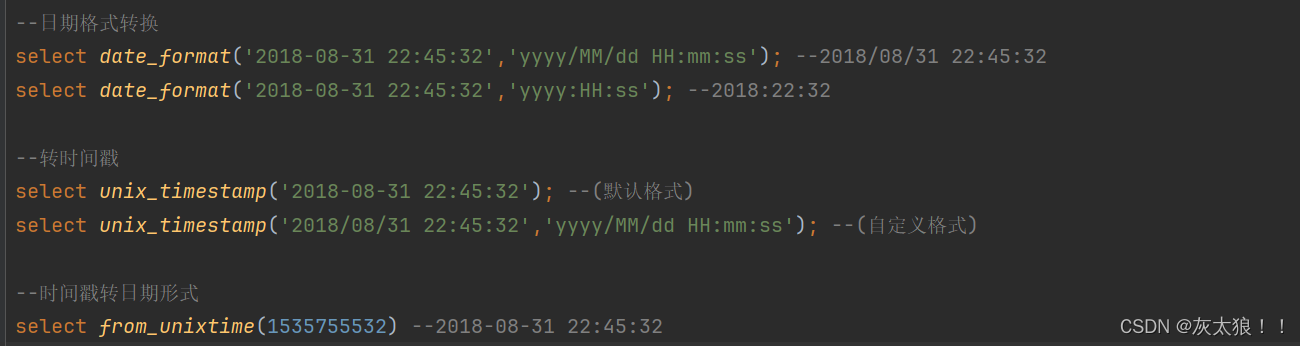
一、日期相关
date_formate、unix_timestamp、from_unixtime用法:
二、开窗函数相关
lag()、lead()用法:
lag()窗口函数返回分区中当前行之前行(可以指定第几行)的值。 如果没有行,则返回null。
lead()窗口函数返回分区中当前行后面行(可以指定第几行)的值。 如果没有行,则返回null。
三、关键字相关
hive关键字执行顺序

四、数据的处理方法
1、想要替换数据中的null值
(如果不想要含null值的那一行数据可以直接使用where xxx not null 过略掉就可以)
--nvl()函数用于将NULL值替换为另一个值,如果是非NULL值不会改变原有数据
select nvl(null,'default value 0'); --default value 0
select nvl(null,0); --0
select nvl('not null',0); --not null
2、行列转换
2.1列转行
explode(): 用于将数组或map类型的一列拆分成多行。
lateral view :与explode()一起使用,允许在FROM子句中应用UDTF(用户定义的表生成函数),如explode(),并将结果作为虚拟表使用。
--建表
CREATE TABLE lateral_view_test(
id int,
test_value STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
--插入数据
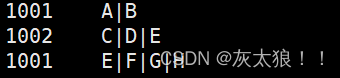
INSERT INTO TABLE lateral_view_test (id, test_value) VALUES (1001,'A|B');
INSERT INTO TABLE lateral_view_test (id, test_value) VALUES (1002,'C|D|E');
INSERT INTO TABLE lateral_view_test (id, test_value) VALUES (1001,'E|F|G|H');
--lateral view 用法示例:
--注意:其中T是lateral view生成的虚拟表的别名,split_value是切分后字段的别名
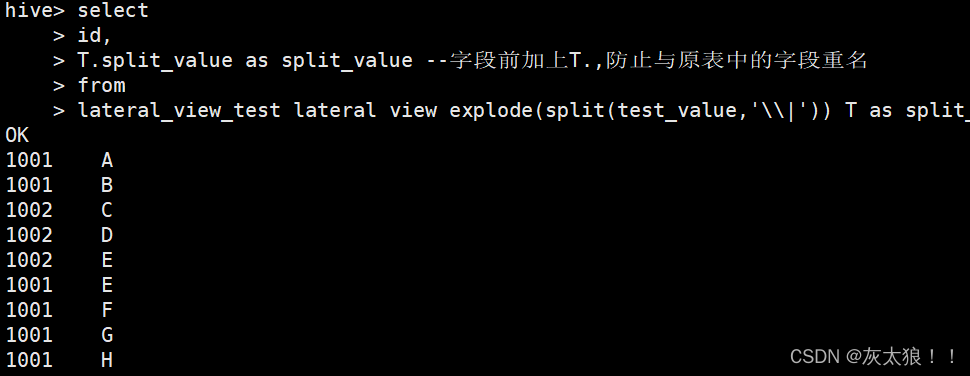
select
id,
T.split_value as split_value --字段前加上T.,防止与原表中的字段重名
from
lateral_view_test lateral view explode(split(test_value,'\\|')) T as split_value;原表数据:
lateral view 之后的数据:
2.2 行转列
方式1:case when
有一个名为sales_data的表,它记录了不同年份、不同区域和产品的销售数据:
year | region | product | sales
-----|--------|---------|------
2020 | North | A | 100
2020 | South | A | 150
2020 | North | B | 200
2020 | South | B | 250
要求:将region和product的组合转换为列,以显示每个区域每种产品在每年的销售额
SELECT
year,
SUM(CASE WHEN region = 'North' AND product = 'A' THEN sales ELSE 0 END) AS North_A,
SUM(CASE WHEN region = 'South' AND product = 'A' THEN sales ELSE 0 END) AS South_A,
SUM(CASE WHEN region = 'North' AND product = 'B' THEN sales ELSE 0 END) AS North_B,
SUM(CASE WHEN region = 'South' AND product = 'B' THEN sales ELSE 0 END) AS South_B
FROM
sales_data
GROUP BY
year;
结果展示:
year | North_A | South_A | North_B | South_B
-----|---------|---------|---------|--------
2020 | 100 | 150 | 200 | 250
方式2:collect_list:在下面的4有展示
3、替换字段中数据的部分值
regexp_replace 函数:
用于在字符串中查找与正则表达式匹配的模式,并将其替换为另一个字符串
语法:
regexp_replace(original_string, pattern, replacement_string)
--original_string:原始字符串
--pattern:正则表达式
--replacement_string:你想要替换成的值
示例:
需求:将'A12345A'变为'A12345'
select regexp_replace('A12345A', '^[A-Z]','')4、collect_list和to_json函数来将分组内的多行数据转换为JSON数组
collect_list: collect_list 是一个聚合函数,它用于将多行数据中的某个列的值收集到一个列表中。
to_json:将结构或映射转换为JSON字符串
--实例:collect_list和to_json函数来将分组内的多行数据转换为JSON数组
--1、建表插入测试数据
CREATE TABLE orders (
customer_id INT,
order_id INT,
product_name STRING,
quantity INT
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
INSERT INTO TABLE orders VALUES
(1, 101, 'Apple', 5),
(1, 102, 'Banana', 2),
(2, 103, 'Cherry', 3),
(2, 104, 'Apple', 1);
--2、表展示
customer_id | order_id | product_name | quantity
------------|----------|--------------|---------
1 | 101 | Apple | 5
1 | 102 | Banana | 2
2 | 103 | Cherry | 3
2 | 104 | Apple | 1
--3、collect_list和to_json函数来将分组内的多行数据转换为JSON数组
SELECT
customer_id,
to_json(collect_list(struct(order_id, product_name, quantity))) AS orders_json
FROM
orders
GROUP BY
customer_id;
--4、结果展示
customer_id | orders_json
------------|---------------------------------------------------------------
1 | [{"order_id":101,"product_name":"Apple","quantity":5},{"order_id":102,"product_name":"Banana","quantity":2}]
2 | [{"order_id":103,"product_name":"Cherry","quantity":3},{"order_id":104,"product_name":"Apple","quantity":1}]5、count()的几种用法
1、count()通常会和分组一起使用,求个数,count(1)代表取全部的条数,无论那一行是不是null
2、count(null)就是都不取,count(null)的值为0.
3、那count(字段名)就代表取得是该字段数据中不为null值数据的条数。
4、count(case when xxx then 1 else null end)就可以根据条件去求和。
5、count(distinct 字段)可以根据主键、或者其他字段来进行去重后的count值。
扩展:
对于第四点,sum也有类似的用法,如下:
sum(case when r=Q1_index then diff else 0 end) over(partition by sbbh) Q1
根据条件去开窗求和。
五、hive中的正则表达式
在Hive中,正则表达式是一种强大的工具,用于匹配和操作文本数据。Hive支持多种正则表达式元字符和函数,以下是对Hive中正则表达式的详细说明:
一、正则表达式元字符
1. 字面值:
- 表示一个具体的字符,如“hello”匹配字符串“hello”。
2. 字符集合:
- `[abc]`:匹配字符“a”、“b”或“c”中的任意一个。
- `[^abc]`:匹配除了“a”、“b”或“c”以外的任意字符。
3. 范围:
- `[a-z]`:匹配任意小写字母。
- `[0-9]`:匹配任意数字,等同于`\d`。
4. 量词:
- `{n}`:表示前面的字符或字符集合恰好出现n次,如“a{3}”匹配三个连续的“a”。
- `{n,}`:表示前面的字符或字符集合至少出现n次。
- `{n,m}`:表示前面的字符或字符集合出现n到m次。
5. 通配符:
- `.`:匹配任意一个字符(除了换行符)。
6. 边界符:
- `^`:匹配输入字符串的开始位置。
- `$`:匹配输入字符串的结束位置。
7. 转义字符:
- 在Hive的正则表达式中,反斜杠`\`用于转义特殊字符,如`\d`表示数字字符。
8. 特殊字符类:
- `\d`:匹配一个数字字符,等同于`[0-9]`。
- `\D`:匹配一个非数字字符,等同于`[^0-9]`。
- `\w`:匹配字母、数字、下划线,等同于`[A-Za-z0-9_]`。
- `\W`:匹配非字母、数字、下划线,等同于`[^A-Za-z0-9_]`。
二、Hive中的正则表达式函数
1. REGEXP/RLIKE:
- 用于判断一个字符串是否匹配一个正则表达式。
- 语法:`SELECT column1 FROM table1 WHERE column2 REGEXP 'pattern';`
2. REGEXP_REPLACE:
- 用于在字符串中查找与正则表达式匹配的模式,并将其替换为另一个字符串。
- 语法:`regexp_replace(original_string, pattern, replacement_string)`
3. REGEXP_EXTRACT:
- 用于从字符串中提取与正则表达式匹配的部分。
- 语法:`regexp_extract(string, pattern, index)`,其中`index`表示提取第几个匹配的子串(从1开始)。
三、正则表达式的优先级
正则表达式从左到右进行计算,并遵循优先级顺序。相同优先级的从左到右进行运算,不同优先级的运算先高后低。常见的运算符优先级从高到低包括:
- 转义符
- 量词和边界符
- 字符集合和范围
- 字面值
四、示例
- 匹配以“a”开头的字符串:`^a`
- 匹配格式为“1981-6-9”的日期:`^\d{4}-\d-\d$`
- 替换字符串“foobar”中的“oo”或“ar”为“77”:`regexp_replace('foobar','oo|ar','77')`















 3751
3751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









