






目录
1.概论
以最经典的“尿不湿和啤酒”的故事来说,这个故事讲的是一家超市通过分析往期的顾客购物清单,发现很多顾客在购买尿不湿的同时也购买了啤酒,于是这家超市将啤酒和尿不湿放在了相邻的购物架上,这一奇怪的举动竟然促使尿不湿和啤酒的销售率大幅上升。
尿不湿和啤酒在直观上看很难发现其中的关联,但是经过这种数据挖掘和分析就可以将这种关系从纷乱的数据中找出来,这个找关联的过程就是关联分析。
关联分析在今天的电商和短视频平台上已经是应用广泛了,其主要应用场景如下:
(1)商品销售,分析顾客同时购买不同商品的可能从而针对性的设计商品营销策略。
(2)行为分析,根据用户在互联网上的举动,分析其潜在的行为习惯及喜好
(3)故障诊断,对于大型复杂的系统,可以通过查看过往历史数据,分析哪些故障之间存在关联性。
2.基本概念
(1)项集
令 I={i1,i2,...,id} 是数据中所有项的集合,T={t1,t2,...,tn} 是所有事务的集合。每个事务 ti 包含的项集都是 I 的子集。
在关联分析中,包含0个或者多个项的集合被称为项集。若一个项集包含k个项,则称他为k-项集。仅包含0个项的项集称为空集。
(2)关联规则
关联规则是X -> Y 这样的形式,其中X和Y是不相交的项集。
这个关联规则表示的意义是:基于历史数据,X出现了,Y同时出现的可能性很高。
(3)支持度
支持度反应了关联关系中所有项在整个数据集中出现的频繁程度,如果某个关联关系的支持度很高,关联规则可能具有普遍性。
项X的支持度定义为
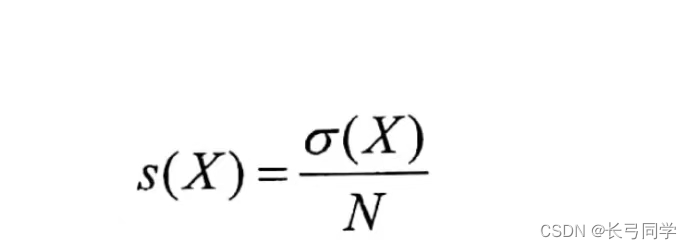
(该公式中:N为事务中事务的个数,O(X)为X在事务中出现的次数。)
形如X ->Y 的关联规则,其支持度定义为

(该公式中:O(XUY)表为X和Y同时出现的次数)
(4)置信度
置信度越高的关联规则X->Y ,说明Y在X出现的情况下出现的可能性越大,这条关联规则的可靠程度越高。
X->Y的置信度定义为:

(5)关联分析的基本步骤
1.寻找频繁项集
2.生成关联规则
4.Apriori关联分析算法
(1)寻找频繁项集
先给出一条先验原理:
定理1.若一个项集是频繁的,则它的子集一定也是频繁的
定理2.若一个项集是非频繁的项集,则它的超集(父集)一定也是非频繁的项集
Apriori关联分析算法利用定理2快速将非频繁项集找到,排除了非频繁项集,剩余的就是要寻找的频繁项集。
(2)生成关联关系
频繁项集中关联规则的数目依旧是很庞大的,所以需要利用置信度的一些性质来尽量把无效的关联关系剔除掉,从而降低关联规则生成的难度。
定理3.对于频繁k-项集Y,若规则X->Y-X 的置信度小于置信度阈值,则规则X'->Y-X' 的置信度也小于置信度阈值。即 c(X->Y)< c0,则 c(X'->Y)< c0 。
利用定理3可以将无效的关联规则快速排除,只关注满足置信度阈值的关联规则。
5.FP增长算法
FP增长(frequent pattern growth)算法将事务集编码为FP树的一种数据结构,并基于FP树来获得频繁项集。
(1)将事务编码为FP树
以下表是假设收集到的几位普通用户所关注的大V类别的信息:
(按照项出现的次数进行排序后的事务集)
| 事务ID | 项 |
| 1 | 新闻,财经,体育 |
| 2 | 新闻,养生 |
| 3 | 财经,明星 |
| 4 | 体育 |
| 5 | 新闻,财经,养生 |
| 6 | 新闻,财经,明星 |
| 7 | 新闻,明星 |
| 8 | 新闻,财经,体育 |
1.将事务1编入FP树,节点名称旁边的数字表示经过该节点事务的数目:
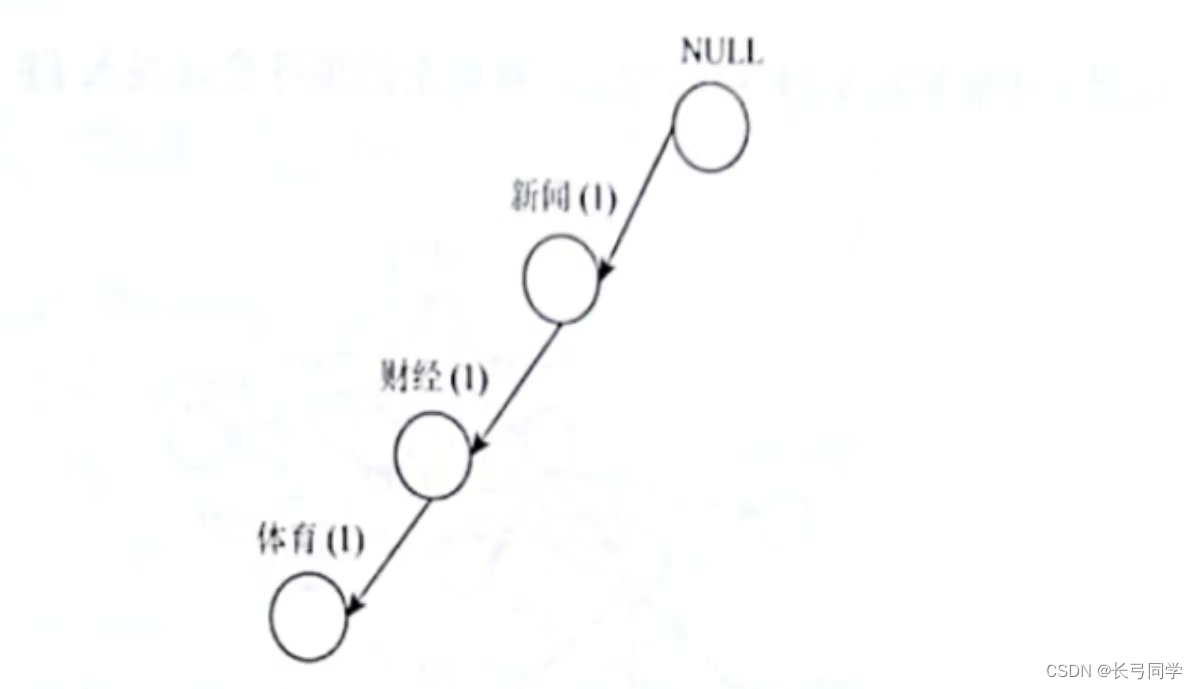
2.将事务2编入FP树
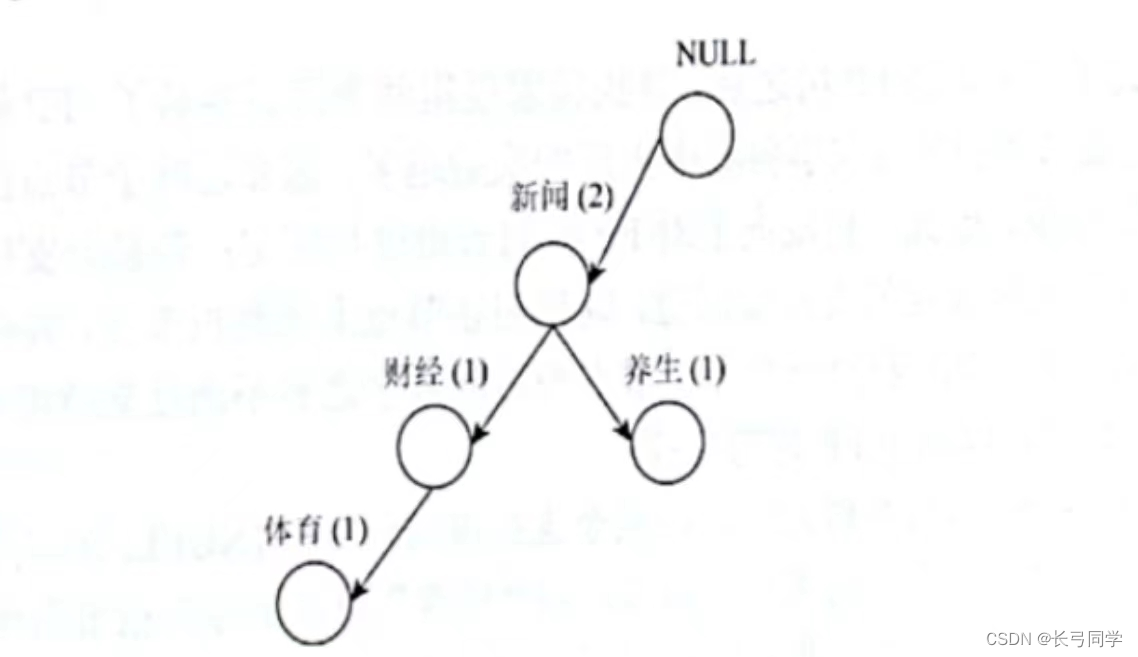
3.将事务3编入FP树,因为事务3与事务1有财经这一关联,故将其用虚线连接

4.将剩余事务按照以上规则全部编入FP树中,如下图所示:

事务集的FP树编入完毕
(2)寻找频繁项集
FP树中的任意一条路径,越靠近根节点在事务集中出现的次数越多,越靠近叶子节点的节点在事务集中出现的次数越少。
因此自底向上对FP树的节点进行判定:若某分支中出现一个节点旁边的数字满足所设定的阈值,则说明该节点上溯到根节点,其中的节点任意组成的项集都是频繁项集。
在上面所构成的FP树中,在某个支持度阈值下,我们可以找到频繁项集:{新闻,财经},{体育,财经},{新闻,体育},{新闻,财经,体育}。
6.python代码实现
(apriori关联分析代码)
from pandas as pd
from mlxtend.preprocessing import TranscactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
# 对数据集X进行编码,X为一个列表,表示整个事务合集:X列表中每个元素也是一个列表,表示每一个项集。
# 这里将数据集编码为二元形式
Encode_X=TranscactionEncoder.fit_transform(X)
X_df=pd.DataFrame(Encode_X)
# 对编码后的事务集X_df使用apriori算法生成频繁项集,support参数设置支持度阈值
frequent_itemsets=apriori(X_df,min_support=0.6)
# 从生成的频繁项集中寻找关联规则,min_threshold为置信度阈值
ass_rule=association_rules(frequent_itemsets,min_threshold=0.7)














 932
932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









