






分组案例一:
import numpy as np
import pandas as pd
import time
from datetime import datetime
df2=pd.read_csv(r"E:\拜师\14100_HM数据科学库课件\14100_HM数据科学库课件\day05\code\starbucks_store_worldwide.csv")
df2.head() # 星巴克训练数据

df2.columns

要求统计中国各个城市的店铺数量
df2.loc[df2[‘Country’]==‘CN’,‘City’].value_counts() # .loc[]的布尔索引,再分组统计

案例二:字符串提取及时间序列分组的两种方法
df=pd.read_csv(r"E:\拜师\14100_HM数据科学库课件\14100_HM数据科学库课件\datasourse\911\911.csv")
df.head()
# 简要信息: 911报警的数据集,要求统计不同时间的不同报警类型,报警类型信息在title中,以冒号分割,需要提取冒号前内容,且time为字符串格式,需要转化。

df.title

- 首先提取冒号前的报警类型,可以用正则表达式,这里用的更通用的方法,用index方法。
df[‘title_new’]=df.title.apply(lambda x : x[ : x.index(’:’)])
df

- 方法一:新建列,将时间转化为时间格式,提取年月。
df[‘time_month’]=df.timeStamp.apply(lambda x : datetime.strptime(x,’%Y-%m-%d %H:%M:%S’).month)
df[‘time_year’]=df.timeStamp.apply(lambda x : datetime.strptime(x,’%Y-%m-%d %H:%M:%S’).year)
df[[‘time_year’,‘time_month’]]

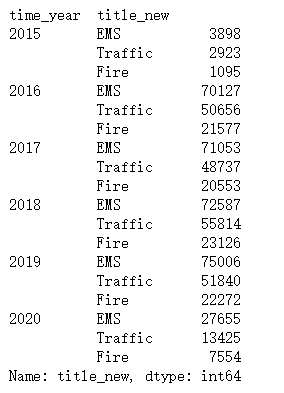
- 用time_year分组对新建的title_new统计。
df2=df.groupby(‘time_year’)[‘title_new’].value_counts()
df2
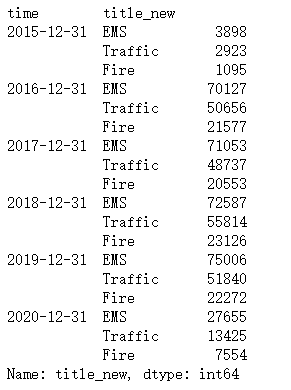
- 方法二:用to_datetime转化格式,再用pd.resample方法
#pd.to_datetime,转化为时间格式
df[‘time’]=pd.to_datetime(df.timeStamp)
#把时间设置为index,然后用pd.resample,可以进行快速分类
df.set_index(‘time’,inplace=True)
df.resample(‘Y’).title_new.value_counts()















 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









