







RND(随机网络蒸馏,Random Network Distillation)
随机网络蒸馏(RND)是一种无监督的探索奖励机制,最早由 OpenAI 在论文 “Exploration by Random Network Distillation”(2018)提出。它的核心思想是利用 预测误差 作为探索奖励,以鼓励智能体在强化学习(Reinforcement Learning, RL)任务中探索新颖的状态。 在强化学习中,智能体通常使用 外部奖励(extrinsic reward) 来学习最优策略。然而,在复杂环境(如游戏、现实世界任务)中,外部奖励可能稀疏或完全缺失。RND 提供了一种 内在奖励(intrinsic reward),使智能体能够主动探索环境,从而提高学习效率。
1. RND 的核心思想
RND 主要基于 预测误差驱动探索(prediction error-driven exploration),其核心思想如下: 训练一个固定的随机目标网络(random target network),并让智能体使用一个可训练的预测网络(trainable predictor network) 来学习目标网络的输出。 在智能体探索环境时,计算预测网络对目标网络输出的误差,并将误差作为探索奖励。 由于预测网络在常见状态下会逐渐拟合目标网络,其预测误差会变小;而在 罕见或新颖的状态 下,预测误差较大,智能体因此会倾向于探索这些状态。
2. RND 的网络结构
RND 由 目标网络 和 预测网络 组成,二者具有相同的结构:
2.1 目标网络(Target Network)
一个固定的、随机初始化的神经网络。
输入:环境状态 𝑠 𝑡(或其某种嵌入表示)。
输出:目标特征向量 𝑓 ( 𝑠 𝑡 ) 。
2.2 预测网络(Predictor Network)
结构与目标网络相同,但参数是可训练的。
输入:相同的状态 𝑠 𝑡 。
目标:学习预测目标网络的输出,即 𝑓 ^ ( 𝑠 𝑡 ) ≈ 𝑓 ( 𝑠 𝑡 )
损失函数(L2 损失):
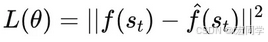
𝑓 ( 𝑠 𝑡 ) 是目标网络的输出(固定,不更新)。
𝑓 ^ ( 𝑠 𝑡 ) 是预测网络的输出(可训练)。
训练预测网络,使其最小化该损失。
探索奖励(Intrinsic Reward):
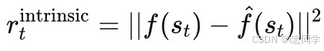
当状态 𝑠 𝑡 罕见 或 未见过 时,预测误差较大,奖励较高。
当状态 𝑠 𝑡 被反复访问时,预测网络逐渐学习目标网络的输出,预测误差变小,奖励降低。
3. RND 的工作流程
初始化目标网络(固定参数,不更新)和预测网络(可训练)。
智能体在环境中执行动作,收集状态 𝑠 𝑡 。
目标网络生成目标特征 𝑓 ( 𝑠 𝑡 ) 。
预测网络尝试预测 𝑓 ^ ( 𝑠 𝑡 ) 并计算预测误差。
预测误差作为内在奖励 𝑟 𝑡 intrinsic 提供给智能体。
预测网络使用梯度下降最小化误差,逐渐学习目标网络的映射。
智能体基于外部奖励 + 内在奖励 来更新策略,鼓励探索新状态。
4. RND与PPO的结合
RND与PPO互相结合,使得PPO 在奖励稀疏环境下更容易学习:
4.1 RND 作为 PPO 的探索机制
PPO 本身依赖 环境奖励(extrinsic reward) 进行训练,但如果奖励稀疏(如迷宫游戏),PPO 可能会卡在局部最优或无法学习。
RND 通过 内在奖励(intrinsic reward) 提供额外的探索驱动力,使智能体尝试更多新状态,提高数据效率。
结合方式: 训练 PPO 时,修改奖励函数:
图片
其中:
𝑟 𝑡 extrinsic 是 PPO 的环境奖励(来自环境)。
𝑟 𝑡 intrinsic 是 RND 提供的探索奖励(来自预测误差)。
𝜆 控制内在奖励对总奖励的影响。
4.2 RND 帮助 PPO 在奖励稀疏环境下学习
在奖励稀疏的环境中,PPO 可能很难优化策略,因为没有足够的奖励信号。
RND 提供了一个额外的奖励信号,即探索奖励,使得智能体可以在初始阶段学习更多有效的状态。
4.3 PPO 使用 RND 提供的奖励进行策略更新
PPO 仍然使用策略梯度方法进行优化,RND 只是影响 PPO 的奖励信号。
PPO 通过值函数估计带有 RND 内在奖励的总奖励,然后使用策略梯度方法更新策略。
5. RSL-RL中的实现
RND 用于 探索奖励(intrinsic reward),鼓励智能体探索环境:
代码检查是否使用了 RND:
if "rnd_cfg" in self.alg_cfg:
# check if rnd gated state is present
rnd_state = extras["observations"].get("rnd_state")
if rnd_state is None:
raise ValueError("Observations for they key 'rnd_state' not found in infos['observations'].")
# get dimension of rnd gated state
num_rnd_state = rnd_state.shape[1]
# add rnd gated state to config
self.alg_cfg["rnd_cfg"]["num_state"] = num_rnd_state
# scale down the rnd weight with timestep (similar to how rewards are scaled down in legged_gym envs)
self.alg_cfg["rnd_cfg"]["weight"] *= env.dt
self.alg.rnd 表示 PPO 是否启用了 RND:
# Intrinsic rewards (extracted here only for logging)!
intrinsic_rewards = self.alg.intrinsic_rewards if self.alg.rnd else None
PPO 训练时,会计算 外部奖励(extrinsic rewards)和内部奖励(intrinsic rewards),RND 影响策略学习。



















 1620
1620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











