







目录
1.安装JDK(1.8)
先删除虚拟机内自带的java
在根目录下创建文件夹用于存放安装包
mkdir package
赋予文件夹权限
chmod 777 package/
下载好JDK通过xhell上传至虚拟机中
解压jdk1.8到根目录下jdk文件夹
tar -zxvf jdk-8u351-linux-x64.tar.gz -C /jdk/
编辑配置文件
vim /etc/profile

export JAVA_HOME=/jdk/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
使配置文件生效
source /etc/profile
检查配置文件是否生效
java –verison

修改bashrc文件
export JAVA_HOME=/java/java1.8
export PATH=$JAVA_HOME/bin:$PATH
2.关闭防火墙
查看防火墙状态
systemctl status firewalld

关闭防火墙
systemctl stop firewalld
开机禁用防火墙
systemctl disable firewalld

3.添加用户
useradd hadoop
passwd hadoop

修改主机名
hostnamectl set-hostname hadoop1
4.关闭SElinux
查看selinux状态
getenforce
临时打开
setenforce 1
临时关闭
setenforce 0

永久关闭
vim /etc/sysconfig/selinux

5.配置节点域名解析
vim /etc//hosts

6.安装Hadoop
创建hadoop文件夹
赋予hadoop文件夹最高权限
chmod 777 hadoop
下载hadoop到package并解压到hadoop文件夹下
tar -zxvf /package/hadoop-3.1.3.tar.gz -C hadoop/
配置环境变量
vim/etc/profile.d/my_env.sh
# HADOOP_HOME
export HADOOP_HOME=/hadoop/hadoop-3.1.3
export HADOOP_CONF_FILE=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使配置生效
source /etc/profile
修改~/.bashrc文件
vim~/.bashrc

export JAVA_HOME=/jdk/jdk1.8
export PATH=$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin:$PATH
export HADOOP_PREFIX=/hadoop/hadoop-3.1.3
使配置生效
source ~/.bashrc
检查配置
hadoop version

7.编写Hadoop的配置文件
编写core-site.xml
cd hadoop-3.1.3/etc/hadoop/
vim core-site.xml
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/hadoop3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
编写hdfs-site.xml
vim hdfs-site.xml
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9868</value>
</property>
</configuration>
编写
vim yarn-site.xml
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
编写vim mapred-site.xml
vim mapred-site.xml
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
写从节点主机名
vim workers
hadoop1
hadoop2
hadoop3
8.复制三台虚拟机并修改信息
关机,克隆另外两台虚拟机,并修改其中的内容
hostnamrctl set-hostname hadoop2
vim /etc/sysconfig/network-scripts/ifcfg-ens33
这里修改的信息,要与之前在/etc/hosts文件中的内容相符

第三台和第二台操作一样
9.配置免密登录
三台都做
vim /etc/ssh/sshd_config
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
生成密钥(三台都做)连续回车就行
ssh-keygen -t rsa

将自己的公钥写入认证文件
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
连接其他两台虚拟机将其他两台也写(以其中一台为例)
ssh root@hadoop2 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
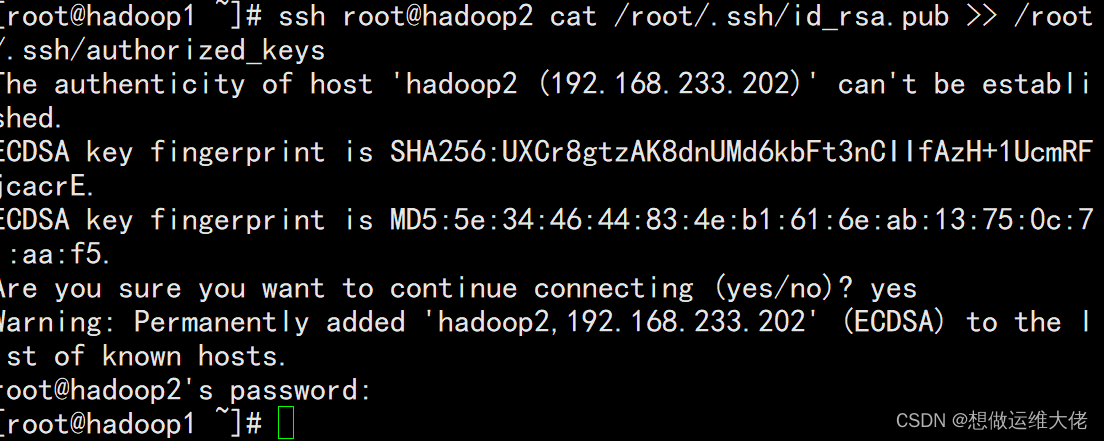
查看认证文件内容
cat ~/.ssh/authorized_keys

查看known_hosts中的主机列表
vim ~/.ssh/known_hosts

将认证文件复制到其他主机
scp ~/.ssh/authorized_keys root@hadoop2:~/.ssh/authorized_keys

10.Hadoop集群启动
cd /hadoop/hadoop-3.1.3/etc/hadoop/
hdfs namenode -format

在系统配置文件里填写如下代码
vim /etc/profile
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
使配置生效
source /etc/profile
10.启动hadoop
启动节点
start-dfs.sh
start-yarn.sh
jps查看启动进程


















 952
952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











