






把毕设的部分内容写一写,复习一下,并且也给有需要的人一些参考(文章最下面还有一些处理好的数据可供下载使用)
目录
0.项目简介
内容如下:
用SVM对睡眠脑电进行分类,特征提取计算了结合小波分解的脑电节律波的七种熵特征,预处理部分用的带通滤波,数据使用的是Fpz-Cz单导联信号,实现起来不难,思路也简单,这里可以给各位需要做这方面课程设计的人一个完整的工作参考(内容肯定是不太够的,保个底,然后自己得再多做点工作)
1.数据库和数据导入
Sleep-EDF Database Expanded v1.0.0 (physionet.org)
这个是包含197例睡眠脑电图的数据集,数据为EDF格式。属于开放数据,不需要凭证申请
数据库简介
以*PSG.edf为后缀的文件是包含EEG(来自Fpz-Cz和Pz-Oz电极位置),EOG(只有水平),下颌肌EMG和事件标记的整夜多睡眠睡眠记录。
另外:SC* PSG.edf类型文件(请参阅“睡眠录像带研究(sleep cassette)”)通常还包含口鼻呼吸和直肠体温。
*Hypnogram.edf文件包含与PSG对应的睡眠模式的注释。包括睡眠阶段W,R,S1、S2、S3、S4,Movement time(身体移动时间)和?(未评分)。所有催眠图都是由训练有素的技术人员(根据催眠图文件名中的第八个字母来区分)手动评分,是基于Fpz-Cz / Pz-Oz脑电图,而不是C4-A1 / C3-A2脑电图。

点击download the ZIP file即可下载

上图是一些用于查看EDF文件的软件和工具,前两个软件自己用过比较好用。EDFbrower用于查看整个脑电信号会好一些。
我是使用Polyman提取注释文件的,导出为文本文件。
下载地址:

上图是下载解压后的睡眠盒式磁带采集的数据文件和对应的注释文件的形式 ,-PSG是数据文件,-Hypnogram是注释文件。
怎么将注释文件导出为文本文件可以参考下面这个文章,按步骤来非常详细
(34条消息) 阅读EDF文件及其注释的软件—— Polyman_polyman是什么软件_手可摘葫芦的博客-CSDN博客
数据文件可以直接使用MATLAB自带的函数edfread(‘file_name’)来导入
test = edfread('SC4001E0-PSG.edf');
First_column = test(:,1);
double_data = cell2mat(table2array(First_column));
上面代码是示例。导入到matlab里面的test是timetable形式的数据,第二行代码是选取第一个导联也就是Fpz-Cz导联的数据,第三行代码就是将其转换为double形数据。
提取数据和对应注释的步骤就是上面这些,记得自己命名好一点(如:EEG_1,EEG_2……),免得后续工作麻烦。
AASM标准
我们使用的数据库是基于R&K标准的,睡眠阶段分为W,REM,S1、S2、S3、S4,在AASM标准里,S3和S4是合并为一个阶段。对于阶段的判定,AASM标准以30s采样时间的脑电为一帧进行划分(对于该数据库而言,采样频率是100Hz,即3000样本点为一帧)。
下面是一个详细的解读,建议各位花点时间学一学。
【微课】美国睡眠医学学会EEG睡眠分期:最详入门解读 (sohu.com)
在上面数据库介绍说到,*Hypnogram.edf文件包含与PSG对应的睡眠模式的注释。包括睡眠阶段W,REM,S1、S2、S3、S4,Movement time(身体移动时间)和?(未评分)。那么我们在处理注释文件的时候,要注意合并一下S3和S4(你用R&K标准的话就不用),并且去除Movement time 和?阶段。注释文件里每一行记录了某个阶段的总持续时间,是30s的倍数。
处理好后可以使用txtread('文件名')读取,也可以不写代码像下面这样:
在主页点击“导入数据”

选择你自己处理好的注释txt文件
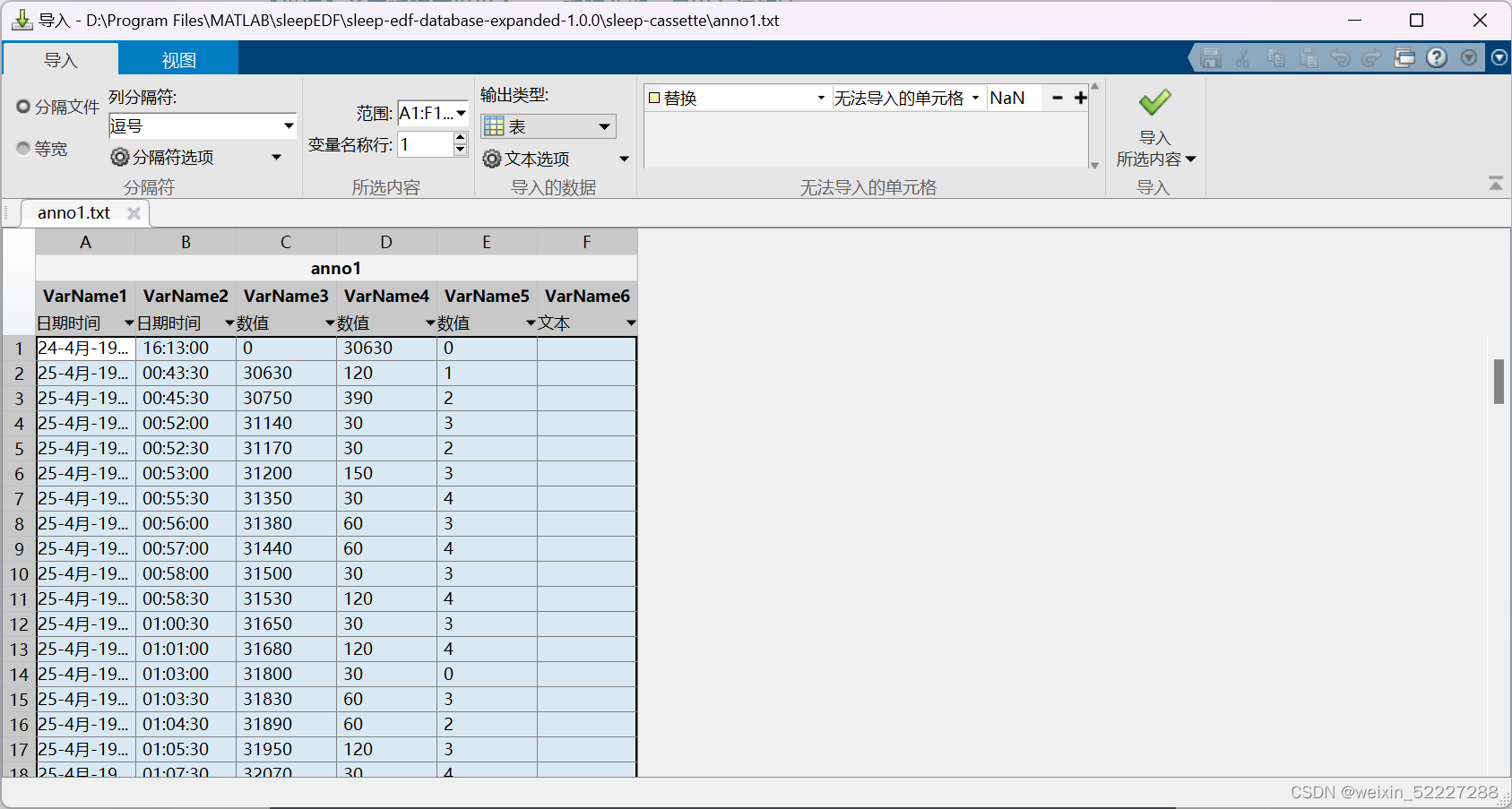
选择你想要的数据,输出类型改为“数值矩阵” ,然后导入即可。
接下来,下面是20个受试者的脑电分割代码
我这里把脑电命名为EEG_‘i’(如EEG_1,EEG_2……),注释文件命名为anno‘i’。
%根据注释分割分类
W = [];
N1 = [];
N2 = [];
N3 = [];
REM = [];
other = [];
for i = 1:20
current_num = 1;
a = length(eval(['anno',num2str(i)]));
for j = 1:a
label = eval(['anno',num2str(i),'(','j',',','3',')']);
duration = eval(['anno',num2str(i),'(','j',',','2',')'])/30; %包含30s的个数
if label == 0
current_num_local = current_num - 1;
for k = 1:duration
W = [W , eval(['EEG_',num2str(i),'(','current_num',':','current_num_local','+','k','*','3000',')'])];
current_num = current_num + 3000;
end
elseif label == 1
current_num_local = current_num - 1;
for k = 1:duration
N1 = [N1 , eval(['EEG_',num2str(i),'(','current_num',':','current_num_local','+','k','*','3000',')'])];
current_num = current_num + 3000;
end
elseif label == 2
current_num_local = current_num - 1;
for k = 1:duration
N2 = [N2 , eval(['EEG_',num2str(i),'(','current_num',':','current_num_local','+','k','*','3000',')'])];
current_num = current_num + 3000;
end
elseif label == 3 || label == 4
current_num_local = current_num - 1;
for k = 1:duration
N3 = [N3 , eval(['EEG_',num2str(i),'(','current_num',':','current_num_local','+','k','*','3000',')'])];
current_num = current_num + 3000;
end
elseif label == 5
current_num_local = current_num - 1;
for k = 1:duration
REM = [REM , eval(['EEG_',num2str(i),'(','current_num',':','current_num_local','+','k','*','3000',')'])];
current_num = current_num + 3000;
end
else
current_num_local = current_num - 1;
for k = 1:duration
other = [other , eval(['EEG_',num2str(i),'(','current_num',':','current_num_local','+','k','*','3000',')'])];
current_num = current_num + 3000;
end
end
end
end分割得到五阶段数据,数量如下:

直到这里,对数据的分割处理以及按照注释把数据归类就完成了。
2.信号去噪
脑电信号的有效频段是0.3-45Hz,此处可以使用带通滤波器进行简单处理即可。
在MATLAB的APP里找到滤波器设计工具,按照下图设计即可(Fs按数据集采样频率):
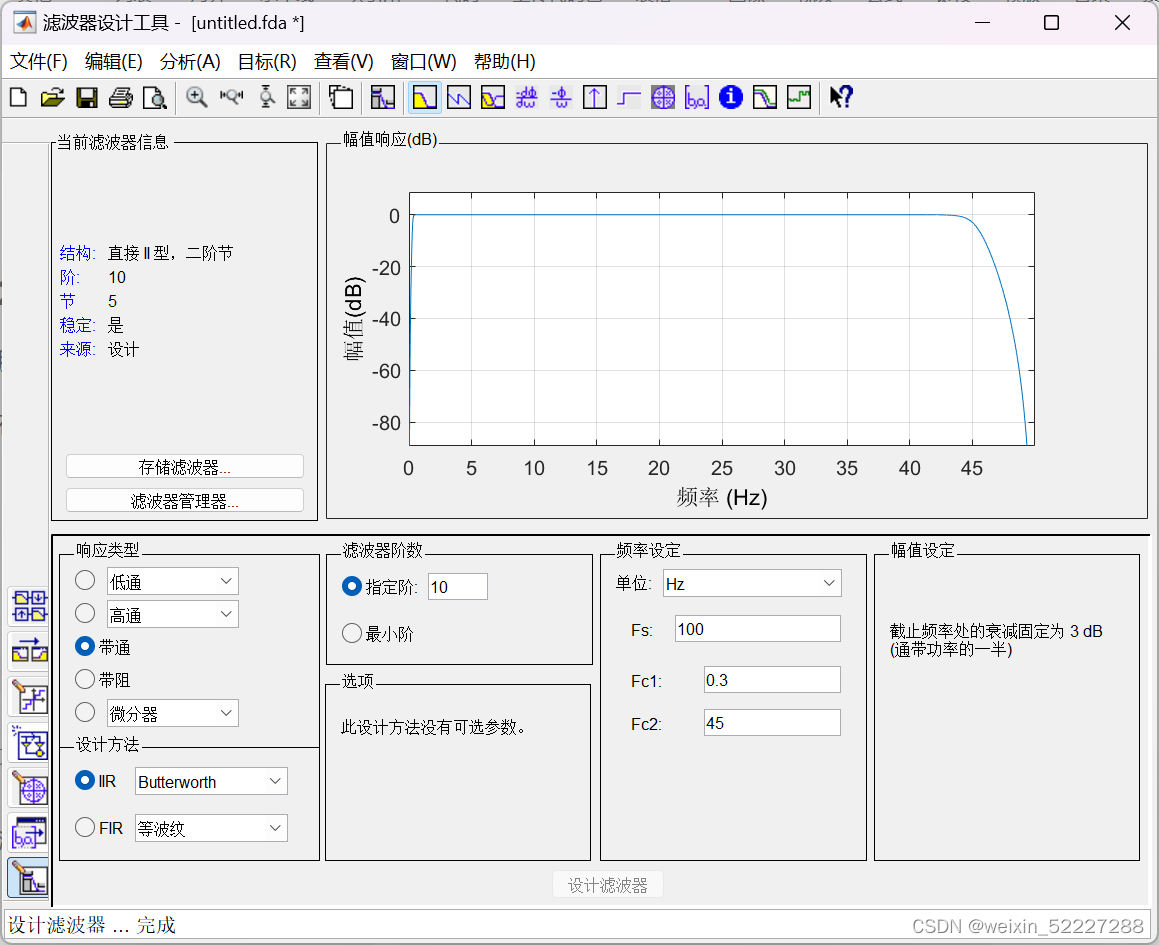
导出滤波器代码
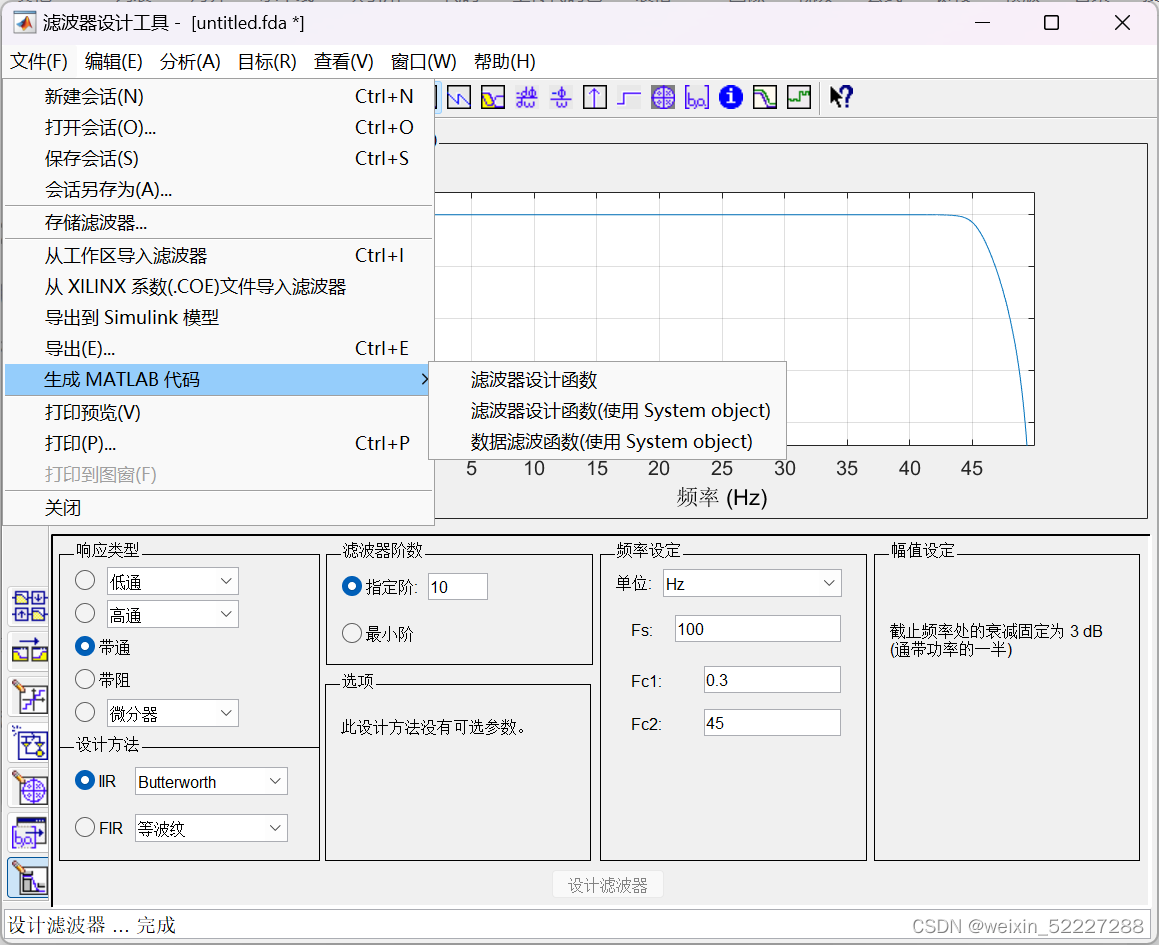
就生成如下形式的代码:
function Hd = untitled
%UNTITLED 返回离散时间滤波器对象。
% MATLAB Code
% Generated by MATLAB(R) 9.12 and Signal Processing Toolbox 9.0.
% Generated on: 19-Jun-2023 19:57:12
% Butterworth Bandpass filter designed using FDESIGN.BANDPASS.
% All frequency values are in Hz.
Fs = 100; % Sampling Frequency
N = 10; % Order
Fc1 = 0.3; % First Cutoff Frequency
Fc2 = 45; % Second Cutoff Frequency
% Construct an FDESIGN object and call its BUTTER method.
h = fdesign.bandpass('N,F3dB1,F3dB2', N, Fc1, Fc2, Fs);
Hd = design(h, 'butter');
% [EOF]使用生成的滤波器进行去噪:
denoise_data = filter('滤波器名',待滤波信号);
%用上面的滤波器举例,data是一个信号向量
denoise_data = filter(untitled,data);有需要的可以带通滤波后加上小波去噪,效果更好,这里我也不是很熟悉就免得误人子弟了。
3.计算信号熵、能量
3.1 小波分解
脑电信号主要是由五种常见的节律波组成的,详情可学习该文章:
你的五种脑电波: α波、β波、γ波、δ波和θ波 - 知乎 (zhihu.com)
δ波——频率0-4Hz
θ波——频率4-8Hz
α波——频率8-13Hz
β波——频率12-40Hz
γ波——频率40-100Hz(没有用到这个)
小波分解常用于分离不同频段的信号,将所需频段的小波系数提取进行重构,得到目标频段的分离信号。
每层小波分解得到高频细节系数Dn和低频近似系数An,以五层分解为例子,由下图所示:
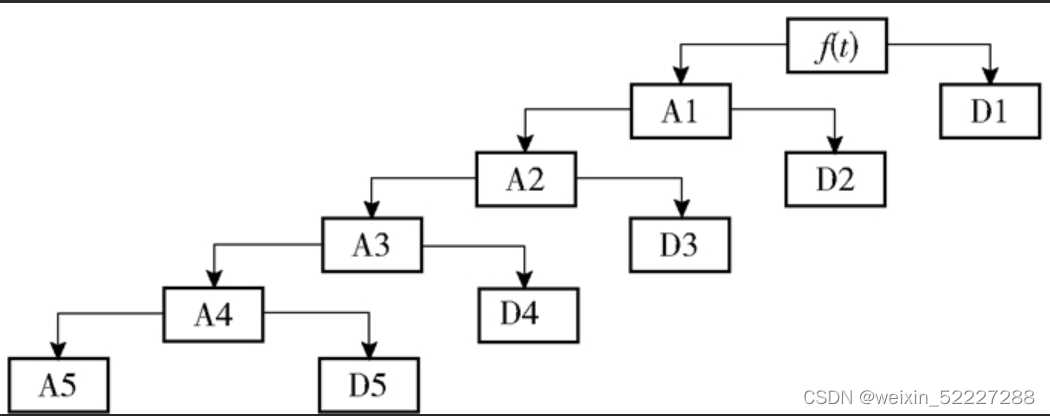
根据本课题只需要4层分解,使用db4小波,对于采样频率为100Hz的信号有如下形式:
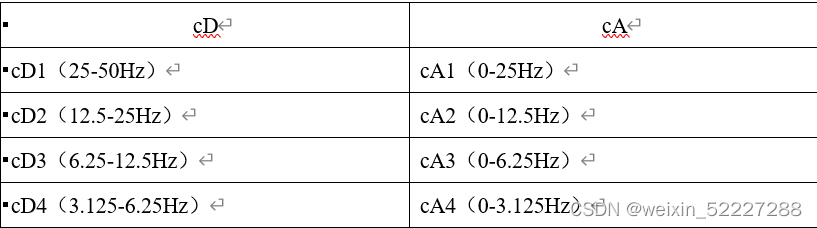
cD2对应的是beta波,cD3对应的是alpha波,cD4对应的是theta波,cA4对应delta波,将其系数进行重构,得到对应频段的节律波。(没有完全吻合频段,有更高要求可以自行学习小波包分解重构)
%小波分解
[C,L]=wavedec(data,4,'db4'); % db4小波4级分解;
%小波重构,输入[系数类型,上面得到的C,L,小波类型,对应层数]
D2 = wrcoef('d',C,L,'db4',2);
D3 = wrcoef('d',C,L,'db4',3);
D4 = wrcoef('d',C,L,'db4',4);
A4 = wrcoef('a',C,L,'db4',4);没看懂的可以看看这个:
(34条消息) 小波变换db4进行四层分解及其信号重构—matlab分析及C语言实现_db4小波_Mint-V的博客-CSDN博客
3.2 能量
这里的能量只是简单的各个样本点的均值平方和:

计算节律波信号的能量,并且以beta波能量为分母,得到其它三种的比值能量值,合并得到7维的特征向量。
3.3 熵
近似熵:度量信号中产生新模式概率的大小;首先定义包含了N个数据点时间序列[u(1), u(2), … , u(N)]。
设定窗口长度m用于信号切分,生成一组维数为m的向量:x(1),x(2),…,x(N-m+1)。其中:
![]() 定义x(i)和x(j)的距离d[x(i),x(j)]为其元素差值最大的一个,即:
定义x(i)和x(j)的距离d[x(i),x(j)]为其元素差值最大的一个,即:
![]() 给定阈值r对每一个2步骤中距离小于r的数目和它与距离总数N-m的比值,有:
给定阈值r对每一个2步骤中距离小于r的数目和它与距离总数N-m的比值,有:
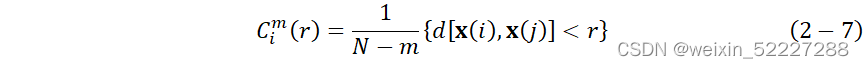 将3所得求对数,再求其对所有i的平均值,记作:
将3所得求对数,再求其对所有i的平均值,记作:
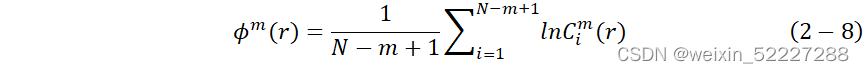 维数加1并重复步骤2-5
维数加1并重复步骤2-5
近似熵:
![]() 样本熵:是近似熵的改进,会求与自身的近似以及先求平均再取对数,具有更好的一致性。
样本熵:是近似熵的改进,会求与自身的近似以及先求平均再取对数,具有更好的一致性。
模糊熵:跟近似熵和样本熵类似,表达的目的也类似,是前两者的改进,通过引入模糊隶属函数,使得阈值分割产生改进,不再以0或1这么绝对的概念评价。
多尺度熵:基于样本熵提出,使用不同大小的尺度s切分样本。
排列熵:测量的是相邻数据点的不同排列模式。
功率谱熵:统计能量在各频段分布的复杂度。
包络熵:将复杂的信号(或模式)进行分解,以求出局部信号的频率特性。
这几个熵值都是用来表征信号序列复杂程度的无量纲指标,熵值越大代表信号复杂度越大,在这里指包含信号的各个频率的多少。因此也包含着不同睡眠阶段的区别信息。
有关熵值的计算代码我是在网上购买的(数学能力太差了),大家可以根据自己情况选择,链接在下面:
特征提取(熵特征指标) | 工具箱文档 (khsci.com)
由此计算原信号和节律波信号的七种熵,合并得到35维特征向量(可以在最下面下载该数据)。
至此,特征就计算完毕了。
4.SVM分类器
LIBSVM是一个由台湾大学林智仁(Lin Chih-Jen)教授等开发的SVM模式识别与回归的软件包,使用简单,功能强大。
关于如何下载和使用可看这两篇文章:
(34条消息) 在Matlab中使用LIBSVM(函数参数的使用说明)_libsvmread_原点qiang的博客-CSDN博客
(34条消息) MATLAB libsvm 安装和使用_qq:843375677的博客-CSDN博客
把这个工具包装好那就是一行代码的事了嘿嘿嘿嘿嘿
%% 整理数据并生成对应标签(自己根据数据量改)
Label1 = ones(1,1664); %N1
Label2 = 2*ones(1,2000); %N2
Label3 = 3*ones(1,2000); %N3
Label4 = 4*ones(1,2000); %REM
Label5 = 5*ones(1,2500); %W
%自己根据自己的特征命名改括号内容,记得要与上面对应
Data = [fea_n1;fea_n2;fea_n3;fea_rem;fea_w];
Label = [Label1,Label2,Label3,Label4,Label5];
Label = Label';
%% 划分训练集和测试集;
%随机打乱样本顺序,达到随机选择训练测试样本的目的;括号内是总数据量。
Nums = randperm(10164);
train_data = Data(Nums(1:5000),:);
test_data = Data(Nums(5001:end),:);
train_label = Label(Nums(1:5000));
test_label = Label(Nums(5001:end));
%归一化到(0,1)之间;
[train_data,ps] = mapminmax(train_data',0,1);
test_data = mapminmax('apply',test_data',ps);
train_data = train_data';test_data=test_data';
%% 搭建SVM模型和验证分类正确率
tic;
% svmtrain函数训练模型,svmpredict用于测试集预测,c和g是SVM参数
model=svmtrain(train_label,train_data,'-c 8 -g 0.8');
[ptest_y,~,~]=svmpredict(test_label,test_data,model);
%计算分类指标
Correct_Predict=zeros(1,5); %统计各类准确数量
Class_Num=zeros(1,5); %统计测试集各类数量
Conf_Mat=zeros(5); %混淆矩阵
for i=1:5164 %自己改数量
Class_Num(test_label(i))=Class_Num(test_label(i))+1;
Conf_Mat(test_label(i),ptest_y(i))=Conf_Mat(test_label(i),ptest_y(i))+1;
if ptest_y(i)==test_label(i)
Correct_Predict(test_label(i))= Correct_Predict(test_label(i))+1;
end
end
ACCs=Correct_Predict./Class_Num;
fprintf('Accuracy_N1 = %.2f%%\n',ACCs(1)*100);
fprintf('Accuracy_N2 = %.2f%%\n',ACCs(2)*100);
fprintf('Accuracy_N3 = %.2f%%\n',ACCs(3)*100);
fprintf('Accuracy_REM = %.2f%%\n',ACCs(4)*100);
fprintf('Accuracy_W = %.2f%%\n',ACCs(5)*100);
toc;
这个是我的代码,大家根据自己的数据进行微调即可,使用的是信号熵作为特征输入。
最后结果:

N1类在很多研究里分类效果都是较低的,它跟REM期很容易混淆,而且在整晚的睡眠占比很小。
下面的链接是一些实验数据,包括处理好的注释文件,滤波后的数据以及原始信号及其节律波信号熵的数据
链接:https://pan.baidu.com/s/1ByKFXFeXqrkofTjNwl_BpA
提取码:pgzz

















 6804
6804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









