









原题链接
leet hot 100-2
49. 字母异位词分组
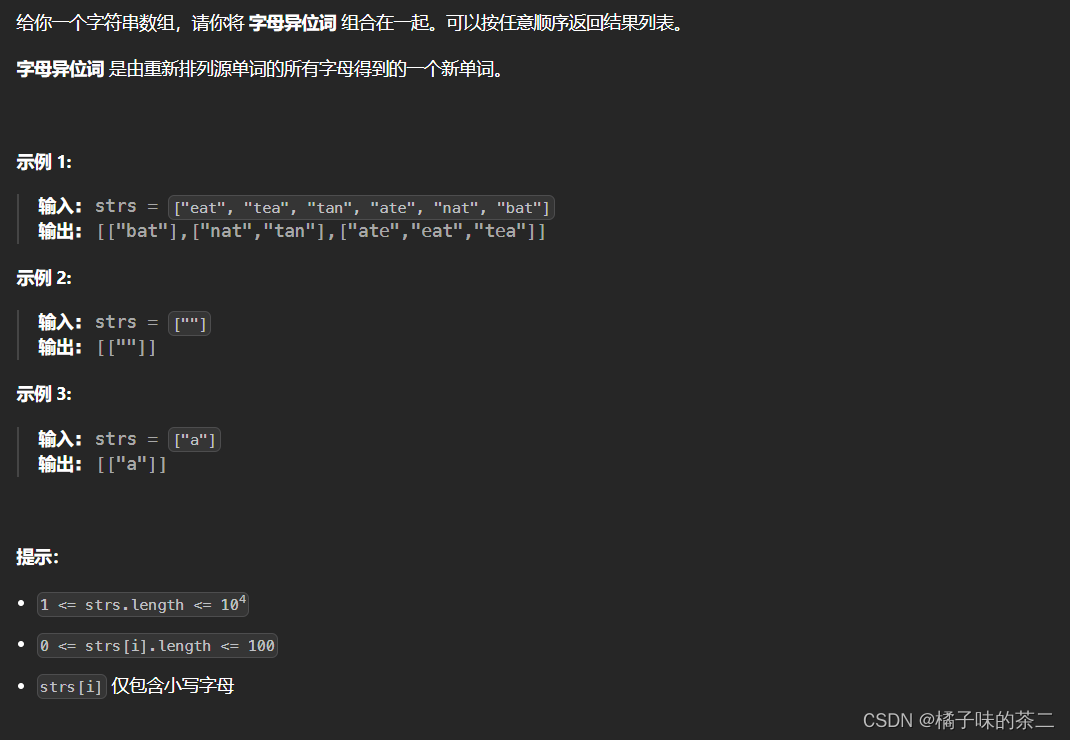
思路
要求把含有相同字母的放到一起,我们可以遍历每一个字符串 将他们重新排序,将排序完是一样的字符串放在一起 用无序容器存放起来 然后遍历这个无序map容器将排序后相同的值放在一起。时间复杂度O(n) 空间复杂度(n)
代码
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string ,vector<string>> ans;
for(int i = 0;i<strs.size() ;i++)
{
string s = strs[i];
sort(s.begin() ,s.end());
ans[s].push_back(strs[i]);
}
vector<vector<string>> res;
for(auto a:ans)
{
res.push_back(a.second);
}
return res;
}
};














 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









