






- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
- 语言环境:Python3.8
- 编译器:Jupyter Lab
- 深度学习环境:
- tensorflow==2.18.0+cuda
目录
1. 导入数据
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler,LabelEncoder
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Activation,Dropout
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.optimizers import Adam
from sklearn.metrics import classification_report,confusion_matrix,r2_score,mean_absolute_error,mean_absolute_percentage_error,mean_squared_errordata = pd.read_csv("weatherAUS.csv")
df = data.copy()
data.head()
data.describe()
data.dtypes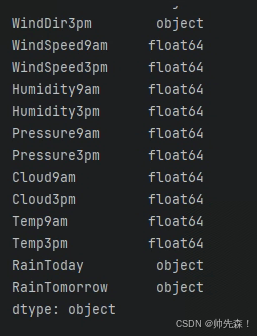
data['Date'] = pd.to_datetime(data['Date'])
data['Date']
data['year'] = data['Date'].dt.year
data['Month'] = data['Date'].dt.month
data['day'] = data['Date'].dt.day
data.head()
data.drop('Date',axis=1,inplace=True)
data.columns
2. 探索是数据分析(EDA)
2.1 数据相关性探索
plt.figure(figsize=(15,13))
# data.corr()表示了data中两个变量之间的相关性
ax = sns.heatmap(data_numeric.corr(), square=True, annot=True, fmt='.2f')
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
plt.show()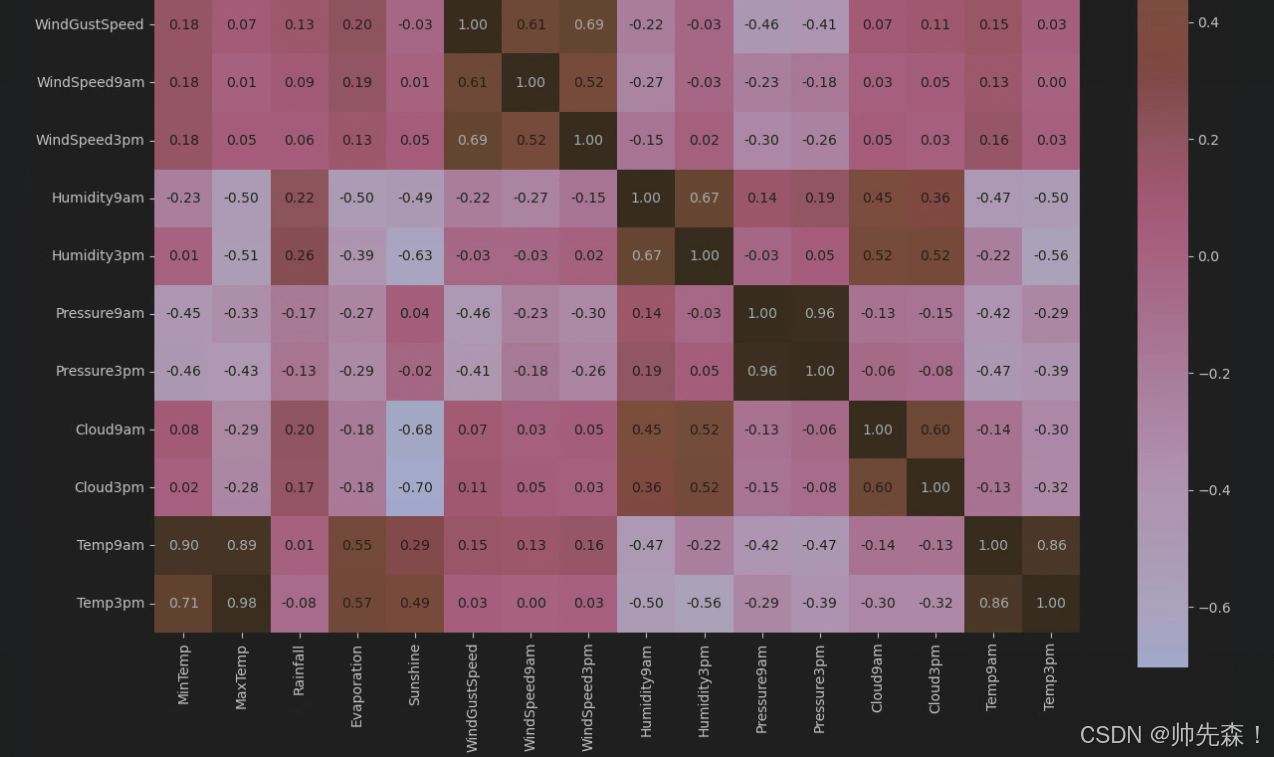 2.2 是否会下雨
2.2 是否会下雨
sns.set(style='darkgrid')
plt.figure(figsize=(4,3))
sns.countplot(x='RainTomorrow',data=data)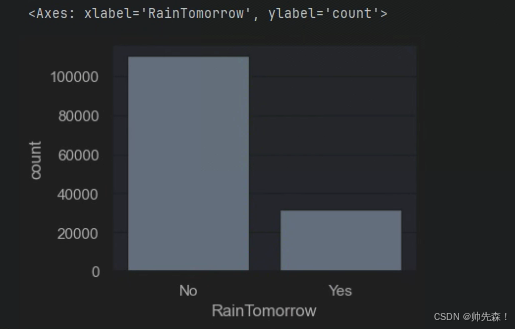
plt.figure(figsize=(4,3))
sns.countplot(x='RainToday',data=data)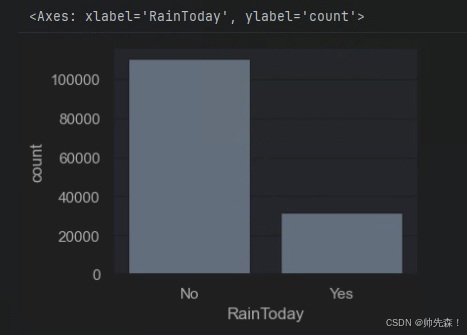
x = pd.crosstab(data['RainTomorrow'],data['RainToday'])
x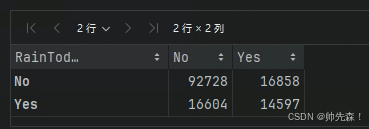
y = x/x.transpose().sum().values.reshape(2,1)*100
y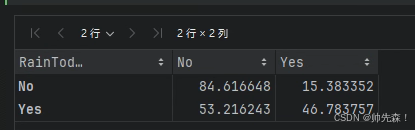
y.plot(kind='bar',figsize=(4,3),color=['red','blue'])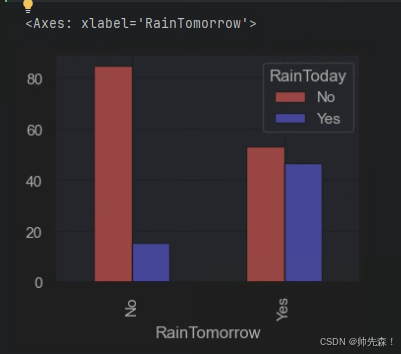
2.3 地理位置与下雨的关系
x = pd.crosstab(data['Location'],data['RainToday'])
# 获取每个城市下雨天数和非下雨天数的百分比
y = x/x.transpose().sum().values.reshape(-1,1)*100
# 按每个城市的雨天百分比排序
y = y.sort_values(by='Yes',ascending=True)
color = ['#cc6699','#006699','#006666','#862d86','#ff9966']
y.Yes.plot(kind='barh',figsize=(15,20),color=color)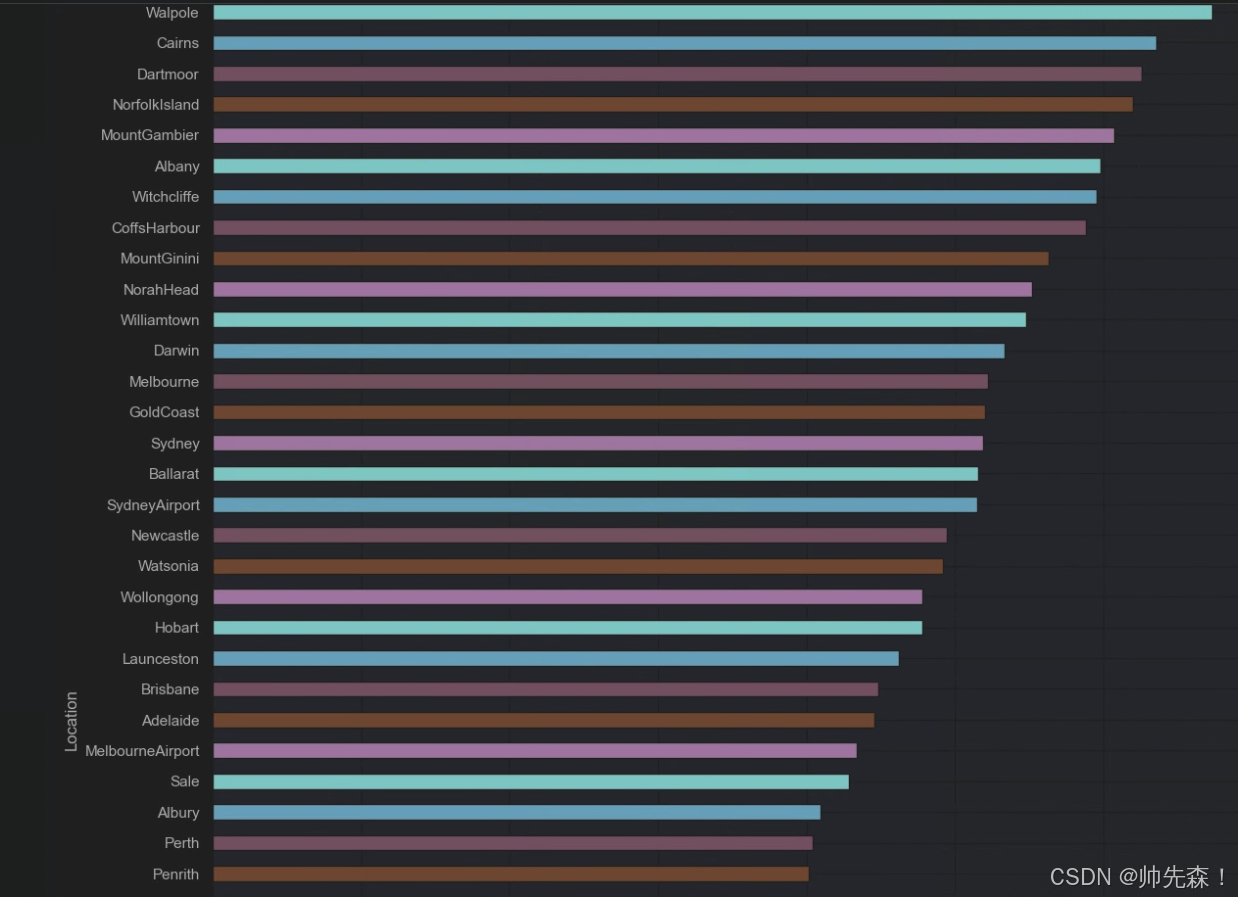
2.4 湿度和压力对下雨的影响
plt.figure(figsize=(8,6))
sns.scatterplot(data=data,x='Pressure9am',y='Pressure3pm',hue='RainTomorrow')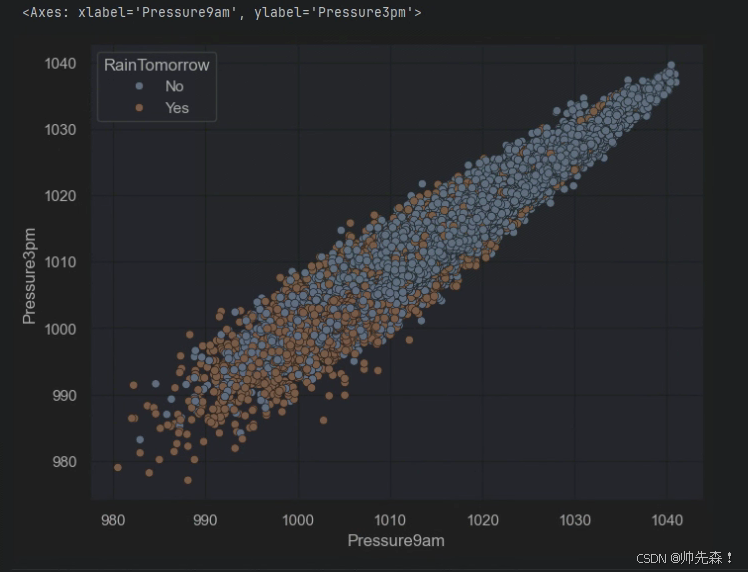
plt.figure(figsize=(8,6))
sns.scatterplot(data=data,x='Humidity9am',y='Humidity3pm',hue='RainTomorrow')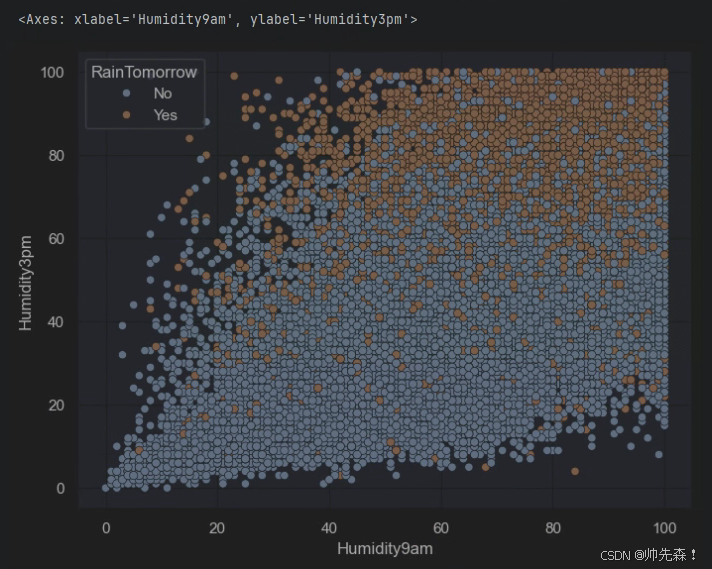
2.5 气温对下雨的影响
plt.figure(figsize=(8,6))
sns.scatterplot(data=data,x='MaxTemp',y='MinTemp',hue='RainTomorrow')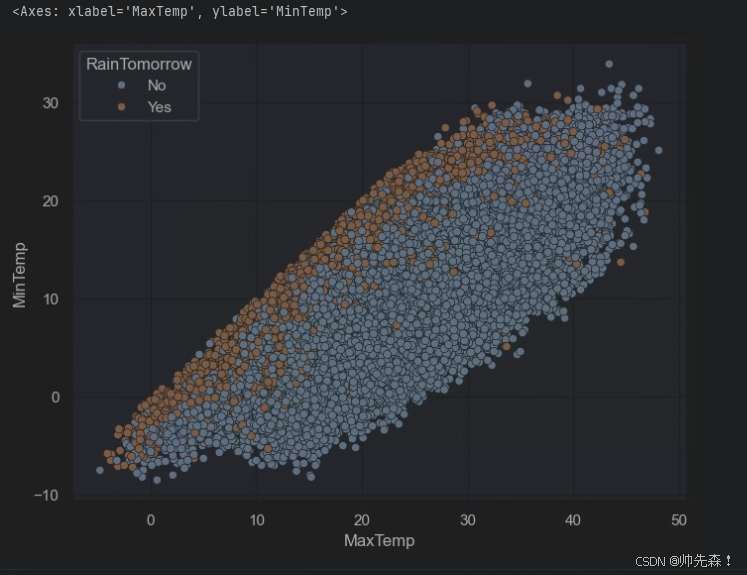
3. 数据预处理
3.1 处理缺失值
data.isnull().sum()/data.shape[0]*100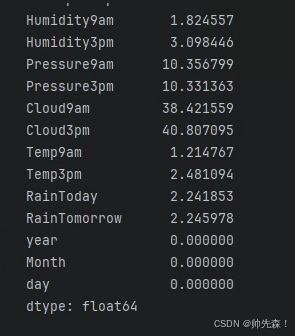
# 在该列中随机选择数进行填充
lst = ['Evaporation', 'Sunshine','Cloud9am', 'Cloud3pm']
for col in lst:
fill_list = data[col].dropna()
data[col] = data[col].fillna(pd.Series(np.random.choice(fill_list,size=len(data.index))))
s = (data.dtypes == "object")
object_cols = list(s[s].index)
object_cols
# inplace=True: 直接修改原对象,不创建副本
# data[i].mode()[0] 返回频率出现最高的选项,众数
for i in object_cols:
data[i].fillna(data[i].mode()[0],inplace=True)
t = (data.dtypes == "float64")
num_cols = list(t[t].index)
num_cols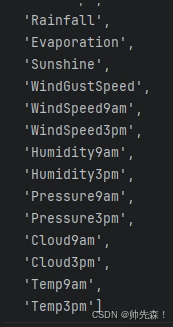
# .median() 中位数
for i in num_cols:
data[i].fillna(data[i].median(),inplace=True)
data.isnull().sum()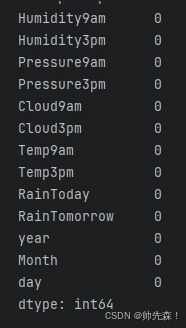
3.2 构建数据集
label_encoder = LabelEncoder()
for i in object_cols:
data[i] = label_encoder.fit_transform(data[i])
X = data.drop(['RainTomorrow','day'],axis=1).values
y = data['RainTomorrow'].values
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.25,random_state = 101)
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)4. 构建模型
4.1 搭建神经网络
model = Sequential()
model.add(Dense(units=24,activation='tanh'))
model.add(Dense(units=18,activation='tanh'))
model.add(Dense(units=23,activation='tanh'))
model.add(Dropout(0.5))
model.add(Dense(units=12,activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(1,activation='sigmoid'))
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
model.compile(loss = 'binary_crossentropy',
optimizer=optimizer,
metrics="accuracy")
early_stop = EarlyStopping(monitor = 'val_loss',
mode = 'min',
min_delta = 0.001,
verbose = 1,
patience = 25,
restore_best_weights = True)4.2 模型训练
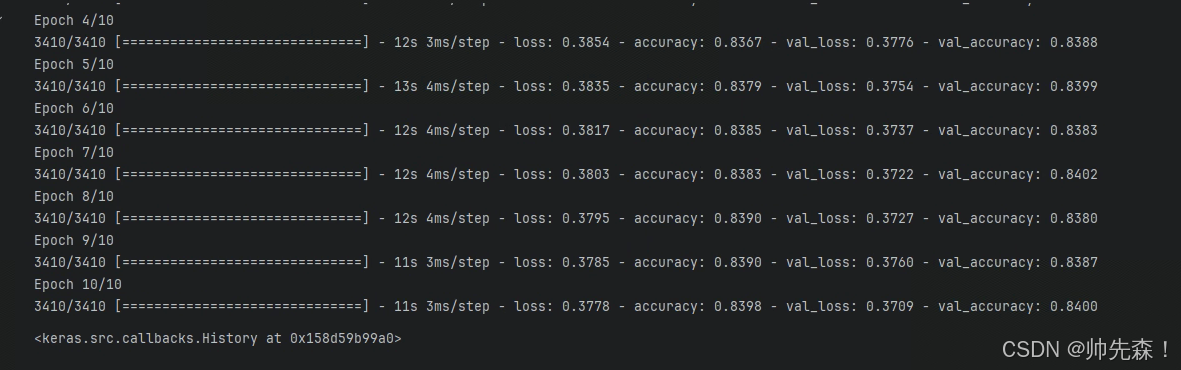
epochs = 10
model.fit(x=X_train,
y=y_train,
epochs=epochs,
batch_size=32,
validation_data=(X_test,y_test),
verbose=1,
callbacks=[early_stop]
)
4.3 结果可视化
acc = model.history.history['accuracy']
val_acc = model.history.history['val_accuracy']
loss = model.history.history['loss']
val_loss = model.history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()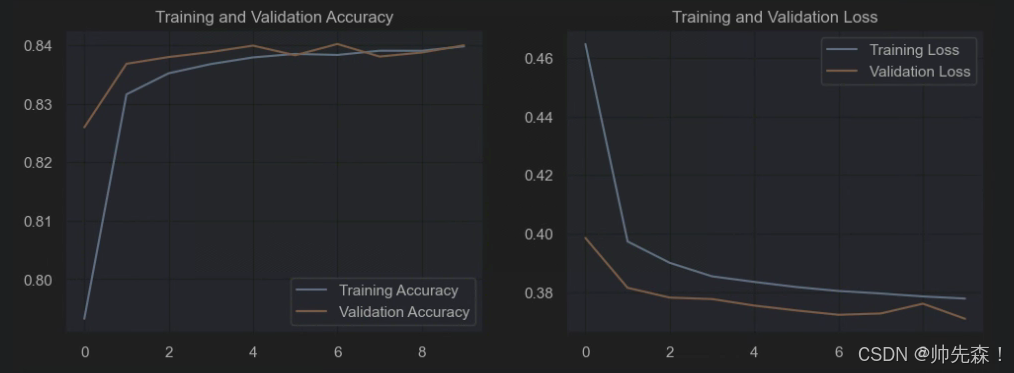
总结:
这周学习天气预测,其中主要包括EDA(Exploratory Data Analysis)探索性数据分析,使用EDA的好处有:
- 可以有效发现变量类型、分布趋势、缺失值、异常值等。
- 缺失值处理:(i)删除缺失值较多的列,通常缺失超过50%的列需要删除;(ii)缺失值填充。对于离散特征,通常将NAN单独作为一个类别;对于连续特征,通常使用均值、中值、0或机器学习算法进行填充。具体填充方法因业务的不同而不同。
- 异常值处理(主要针对连续特征)。如:Winsorizer方法处理。
- 类别合并(主要针对离散特征)。如果某个取值对应的样本个数太少,就需要将该取值与其他值合并。因为样本过少会使数据的稳定性变差,且不具有统计意义,可能导致结论错误。由于展示空间有限,通常选择取值个数最少或最多的多个取值进行展示。
- 删除取值单一的列。
- 删除最大类别取值数量占比超过阈值的列。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









