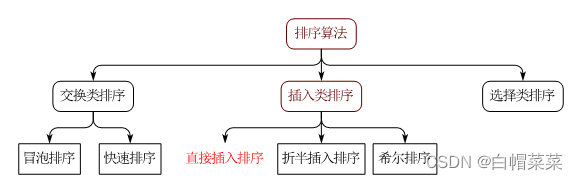
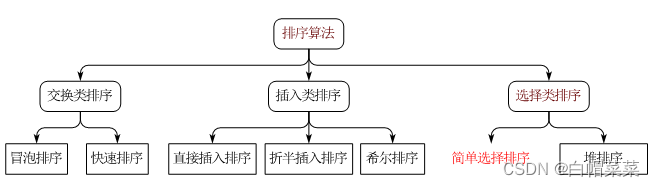
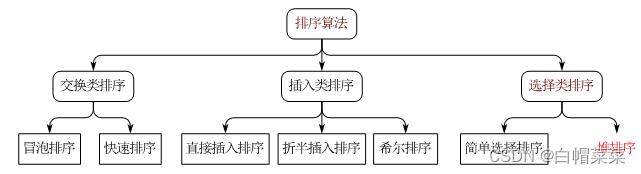
目录
16 排序算法
16.1 交换排序原理及实战
16.1.1 冒泡排序原理
16.1.2 冒泡排序实战
16.1.3 快速排序原理*
16.1.4 快速排序实战
16.2 插入排序原理及实战
16.2.1 插入排序原理
16.2.2 直接插入排序实战
OJ作业
16.3 选择排序的原理及实战
16.3.1 简单选择排序原理
16.3.2 简单选择排序实战
16.3.3 堆排序原理*
16.3.4 堆排序实战
16.4 归并排序的原理及实战
16.4.1 归并排序原理
16.4.2 归并排序实战
所有排序算法的时间与空间复杂度汇总
OJ作业
16.5 排序算法真题实战
16.5.1 2016年43题
16.5.2 2016年42题
16 排序算法
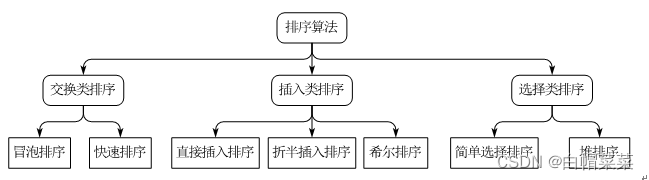
16.1 交换排序原理及实战
16.1.1 冒泡排序原理
Bubble Sort基本思想:从后往前,两两比较相邻的元素,若A[j-1]>A[j],交换次序,得到的结果是:最小的元素交换到了待排序列的第一个位置,下一趟冒泡时,前一趟确定的最小元素不参与比较。循环结束条件是:直到不出现交换。这样最多做n-1趟冒泡就能排好序。
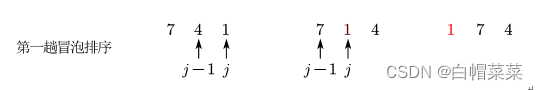
动画网站:“https://www.cs.usfca.edu/~galles/visualization/ComparisonSort.html”。
16.1.2 冒泡排序实战
首先我们通过随机数生成10个元素,通过随机数生成,我们可以多次测试排序算法是否正确,然后打印随机生成后的元素顺序,然后通过冒泡排序对元素进行排序,然后再次打印排序后的元素顺序。
代码(动态分配的顺序表)
| #include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef int ElemType;
typedef struct SSTable {
ElemType *elem;
int TableLen;
} SSTable;
void Init_ST(SSTable &ST, int len) {
ST.TableLen = len;
srand(time(NULL));
ST.elem = (ElemType *) malloc(sizeof(ElemType));
for (int i = 0; i < len; i++) {
ST.elem[i] = rand() % 100;
}
}
void Print_ST(SSTable ST) {
for (int i = 0; i < ST.TableLen; i++) {
printf("%3d", ST.elem[i]);
}
printf("\n");
}
void swap(SSTable &A, int j) {
ElemType b = A.elem[j - 1];
A.elem[j - 1] = A.elem[j];
A.elem[j] = b;
}
void Bubble_Sort(SSTable &A) {//往往需要两层循环
for (int i = 0; i < A.TableLen - 1; i++) {
int flag = 1;
for (int j = A.TableLen - 1; j > i; j--) {
if (A.elem[j] < A.elem[j - 1]) {
swap(A, j);
flag = 0;
}
}
if (flag) {
return;
}
}
}
int main() {
SSTable ST;
Init_ST(ST, 10);
Print_ST(ST);
Bubble_Sort(ST);
Print_ST(ST);
return 0;
} |
时间复杂度和空间复杂度
外循环和内循环以及判断和交换元素的时间开销[n(n-1)]/2,平均时间复杂度O()。平均的空间复杂度就是在交换元素时那个临时变量所占的内存空间,因为只是用了2个循环变量以及1到2个标志和交换等的中间变量,这个与待排序的记录个数无关,空间复杂度O(1);
【注意】:
使用动态数组的结构体不需要使用“*”符号,因为这是顺序表。动态分配要申请空间,并且只用为elem申请空间。为elem申请空间一定要 * 数组的长度。
16.1.3 快速排序原理*

分治思想:找到数组中的一个分割值(一般选择第一个元素作为分割值),定义i、j将数组中所有比分割值小的放在其左边,大的放右边,这样数组一分为二,这样只用排列前一半数组和后一半数组,复杂度减半。不断递归,最终分割只剩最后一个元素时排序完成。
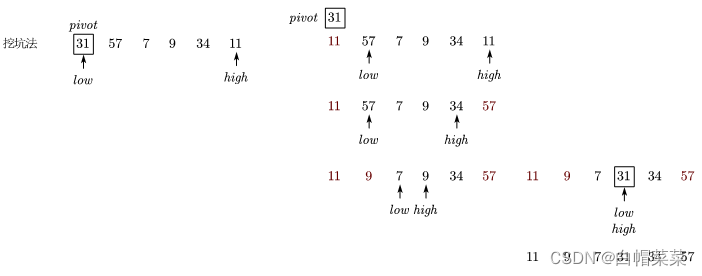
挖坑法:
取一个pivot,我们取第一个元素。将low作为一个坑位,从high向前找,比pivot小的high拿过来放在low坑里,同时high作为一个坑位。再从low向后找,比pivot大的low拿过来放在high坑里,同时low作为一个坑位。直到low=high,将pivot放在最后的low位置。这样比pivot小的都在它的左边,比pivot大的都在它的右边,再继续对左右两侧进行递归。
动画网站:“https://www.cs.usfca.edu/~galles/visualization/ComparisonSort.html”。
16.1.4 快速排序实战
代码(动态分配的顺序表)
| #include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <string.h>
typedef int ElemType;
typedef struct SSTable {
ElemType *elem;
int TableLen;
} SSTable;
void Init_ST(SSTable &ST, int len) {
ST.elem = (ElemType *) malloc(sizeof(ElemType) * ST.TableLen);
ST.TableLen = len;
srand(time(NULL));
for (int i = 0; i < ST.TableLen; i++) {
ST.elem[i] = rand() % 100;
}
}
void Print_ST(SSTable ST) {
for (int i = 0; i < ST.TableLen; i++) {
printf("%3d", ST.elem[i]);
}
printf("\n");
}
//快排的核心函数,时间复杂度O(n) //挖坑法
int partition(ElemType *A, int low, int high) {
ElemType pivot = A[low]; //第一个元素为分割值
while (low < high) {
while (low < high && A[high] >= A[low]) { //从后往前遍历,找到一个比分割值小的
high--;
}
A[low] = A[high];//把比分隔值小的那个元素,放到A[low]
while (low < high && A[low] <= pivot) { //从前往后遍历,找到一个比分割值大的
low++;
}
A[high] = A[low]; //把比分隔值大的那个元素,放到A[high]
}
A[low] = pivot;
return low; //返回分隔值所在的下标
}
void Quick_Sort(ElemType *A, int low, int high) {
if (low < high) {
int pivot = partition(A, low, high); //左边的元素都比分割点小,右边的比分割点大
Quick_Sort(A, low, pivot - 1); //O(log n)
Quick_Sort(A, pivot + 1, high); //O(log n)
}
}
int main() {
SSTable ST;
Init_ST(ST, 10);
// ElemType A[10] = {64, 94, 95, 79, 69, 84, 18, 22, 12, 78};
// memcpy(ST.elem, A, sizeof(A));
Print_ST(ST);
Quick_Sort(ST.elem, 0, 9);
Print_ST(ST);
return 0;
} |
时间复杂度和空间复杂度
假如每次快速排序数组都被平均地一分为二,那么可以得出QuickSort递归的次数是log2n,第一次partition遍历次数为n,分成两个数组后,每个数组遍历n/2次,加起来还是n,因此时间复杂度是O(nlog2n),因为计算机是二进制的,所以在复试面试回答复杂度或与人交流时,提到复杂度时一般直接讲O(nlogn),而不带下标2。快速排序最差的时间复杂度为什么是n2呢?因为数组本身从小到大有序时,如果每次我们仍然用最左边的数作为分割值,那么每次数组都不会二分,导致递归n次,所以快速排序最坏时间复杂度为n2。当然,为了避免这种情况,有时会首先随机选择一个下标,先将对应下标的值与最左边的元素交换,再进行partition操作,从而极大地降低出现最坏时间复杂度的概率,但是仍然不能完全避免。
因此,快排的最好和平均时间复杂度是O(),最差是O()。空间复杂度是O(),因为递归的次数是log2n,而每次递归的形参都是需要占用空间的。
16.2 插入排序原理及实战
16.2.1 插入排序原理
直接插入排序(简单插入排序):首先将第一个数视为有序序列,然后把后面9个数视为要依次插入的序列。

动画网站:“https://www.cs.usfca.edu/~galles/visualization/ComparisonSort.html”。
16.2.2 直接插入排序实战
代码(动态分配的顺序表)
| #include <stdio.h>
#include<stdlib.h>
#include <time.h>
typedef int ElemType;
typedef struct SSTable {
ElemType *elem;
int TableLen;
} SSTable;
void Init_ST(SSTable &ST, int len) {
ST.elem = (ElemType *) malloc(sizeof(ElemType) * len);
ST.TableLen = len;
srand(time(NULL));
for (int i = 0; i < ST.TableLen; i++) {
ST.elem[i] = rand() % 100;
}
}
void Print_ST(SSTable ST) {
for (int i = 0; i < ST.TableLen; i++) {
printf("%3d", ST.elem[i]);
}
printf("\n");
}
void Insert_Sort(ElemType *A, int n) {
int i, j, insertVal;
for (i = 1; i < n; i++) {
insertVal = A[i];
for (j = i - 1; j >= 0 && A[j] > insertVal; j--) {
A[j + 1] = A[j];
}
A[j + 1] = insertVal;
}
}
int main() {
SSTable ST;
Init_ST(ST, 10);
Print_ST(ST);
Insert_Sort(ST.elem, ST.TableLen);
Print_ST(ST);
return 0;
} |
时间复杂度和空间复杂度
随着有序序列的不断增加,插入排序比较的次数也会增加,插入排序的执行次数也是从1加到N-1,总运行次数为N(N-1)/2,时间复杂度依然为O()。因为未使用额外的空间(额外空间必须与输入元素的个数N相关),所以空间复杂为O(1)。如果数组本身有序,那么就是最好的时间复杂度O(n)。
因此,直接插入排序的最好和平均时间复杂度是O(),空间复杂为O(1)。
OJ作业
Description
读取10个整型数据12 63 58 95 41 35 65 0 38 44,然后通过冒泡排序,快速排序,插入排序,分别对该组数据进行排序,输出3次有序结果,每个数的输出占3个空格
Sample Input 1
12 63 58 95 41 35 65 0 38 44
Sample Output 1
0 12 35 38 41 44 58 63 65 95
0 12 35 38 41 44 58 63 65 95
0 12 35 38 41 44 58 63 65 95
代码(动态分配的顺序表)
| #include <stdio.h>
#include <stdlib.h>
typedef int ElemType;
typedef struct SSTable {
ElemType *elem;
int TableLen;
} SSTable;
void Init_ST(SSTable &ST) {
ST.TableLen = 10;
ST.elem = (ElemType *) malloc(sizeof(ElemType) * ST.TableLen);
for (int i = 0; i < ST.TableLen; i++) {
scanf("%d", &ST.elem[i]);
}
}
void Print_ST(SSTable ST) {
for (int i = 0; i < ST.TableLen; i++) {
printf("%3d", ST.elem[i]);
}
printf("\n");
}
//冒泡排序
void swap(ElemType &i, ElemType &j) {
ElemType t = i;
i = j;
j = t;
}
void Bubble_Sort(ElemType *A, int n) {
for (int i = 0; i < n - 1; i++) {
int flag = 1;
for (int j = n - 1; j > i; j--) {
if (A[j] < A[j - 1]) {
swap(A[j], A[j - 1]);
flag = 0;
}
}
if (flag) {
return;
}
}
}
//快排
int partition(ElemType *A, int low, int high) {
int pivot = A[low];
while (low < high) {
while (low < high && A[high] >= pivot) {
high--;
}
A[low] = A[high];
while (low < high && A[low] <= pivot) {
low++;
}
A[high] = A[low];
}
A[low] = pivot;
return low;
}
void Quick_Sort(ElemType *A, int low, int high) {
if (low < high) {
int pivot = partition(A, low, high);
Quick_Sort(A, low, pivot - 1);
Quick_Sort(A, pivot + 1, high);
}
}
//插入排序
void Insert_sort(ElemType *A, int n) {
int i, j, insertVal;
for (i = 1; i < n; i++) {
insertVal = A[i];
for (j = i - 1; j >= 0 && A[j] > insertVal; j--) {
A[j + 1] = A[j];
}
A[j + 1] = insertVal;
}
}
int main() {
SSTable ST;
Init_ST(ST);
Bubble_Sort(ST.elem, ST.TableLen);
Print_ST(ST);
Quick_Sort(ST.elem, 0, ST.TableLen - 1);
Print_ST(ST);
Insert_sort(ST.elem, ST.TableLen);
Print_ST(ST);
return 0;
} |
16.3 选择排序的原理及实战
16.3.1 简单选择排序原理
简单选择排序(选择排序):循环找出数组中的最小元素,交换到前面位置。

动画网站:“https://www.cs.usfca.edu/~galles/visualization/ComparisonSort.html”。
16.3.2 简单选择排序实战
代码(动态分配的顺序表)
| #include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef int ElemType;
typedef struct SSTable {
ElemType *elem;
int TableLen;
} SSTable;
void Init_ST(SSTable &ST, int len) {
ST.TableLen = 10;
ST.elem = (ElemType *) malloc(sizeof(ElemType) * ST.TableLen);
srand(time(NULL));
for (int i = 0; i < len; i++) {
ST.elem[i] = rand() % 100;
}
}
void Print_ST(SSTable ST) {
for (int i = 0; i < ST.TableLen; i++) {
printf("%3d", ST.elem[i]);
}
printf("\n");
}
void swap(ElemType &i, ElemType &j) {
int t = i;
i = j;
j = t;
}
void Selection_Sort(ElemType *A, int n) {
int i, j, min;
for (i = 0; i < n - 1; i++) {
min = i;
for (j = i + 1; j < n; j++) {
if (A[j] < A[min]) {
min = j;
}
}
if (min != i) {
swap(A[min], A[i]);
}
}
}
int main() {
SSTable ST;
Init_ST(ST, 10);
Print_ST(ST);
Selection_Sort(ST.elem, ST.TableLen);
Print_ST(ST);
return 0;
} |
时间复杂度和空间复杂度
选择排序虽然减少了交换次数,但是循环比较的次数依然和冒泡排序的数量是一样的,都是从1加到N-1,总运行次数为N(N-1)/2。我们忽略循环内语句的数量,因为我们在计算时间复杂度时,主要考虑与N有关的循环,如果循环内交换得多,例如有5条语句,那么最终得到的无非是5n2;循环内交换得少,例如有2条语句,那么得到的就是2n2,但是时间复杂度计算是忽略首项系数的,因此最终还是O()。因为未使用额外的空间(额外空间必须与输入元素的个数N相关),所以空间复杂为O(1)。另外考研初试问时间复杂度,直接写最终结果即可,不用分析过程,除非清晰说明需要给出计算过程,或者分析过程(但是目前一直都没有这个要求)。
因此,选择排序的时间复杂度为O()。空间复杂为O(1)。
16.3.3 堆排序原理*
堆(Heap):能将层次建树的二叉树中每个元素对应到数组下标的数据结构。堆是计算机科学中的一种特殊的树状数据结构。满足以下特性,“给定堆中任意结点P和C,若P是C的父结点,则P的值≤(或≥)C的值”。最后一个父元素的下标是N/2-1;如果父结点的下标是dad,那么父结点对应的左子结点的下标值是2*dad+1。
最小堆(小根堆或小顶堆)(minheap):父结点的值≤子结点的值;
最大堆(大根堆或大顶堆)(maxheap):父结点的值≥子结点的值。
根结点(rootnode):堆中最顶端的结点。根结点本身没有父结点(parentnode)。
假设我们有3,87,2,93,78,56,61,38,12,40共10个元素,将这10个元素采用层次建树法建成一棵完全二叉树,虽然只用一个数组存储元素,但是我们能将二叉树中任意一个位置的元素对应到数组下标上。
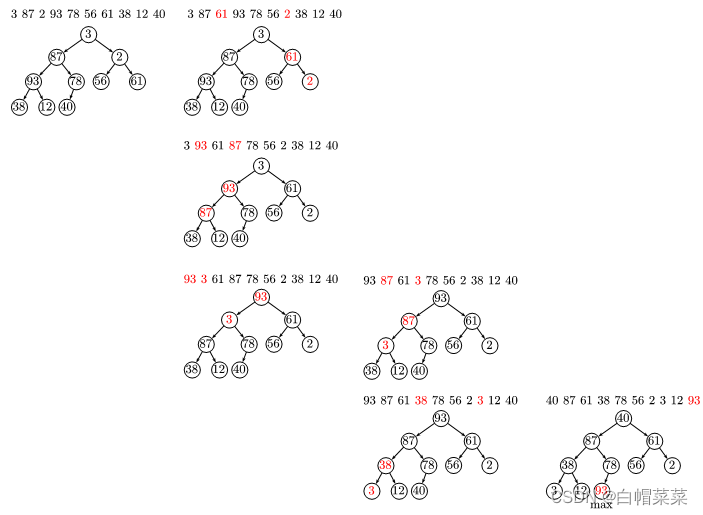
动画网站:“https://www.cs.usfca.edu/~galles/visualization/HeapSort.html”。
16.3.4 堆排序实战
代码(动态分配的顺序表)
| #include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <string.h>
typedef int ElemType;
typedef struct SSTable {
ElemType *elem;
int TableLen;
} SSTable;
void Init_ST(SSTable &ST, int len) {
ST.elem = (ElemType *) malloc(sizeof(ElemType) * ST.TableLen);
ST.TableLen = len;
srand(time(NULL));
for (int i = 0; i < ST.TableLen; i++) {
ST.elem[i] = rand() % 100;
}
}
void Print_ST(SSTable ST) {
for (int i = 0; i < ST.TableLen; i++) {
printf("%3d", ST.elem[i]);
}
printf("\n");
}
//堆排序
void swap(ElemType &i, ElemType &j) {
ElemType t = i;
i = j;
j = t;
}
//某一子树调整为大根堆
void AdjustDown1(ElemType *A, int adjloc, int len) {
int dad = adjloc;//父亲的下标
int son = dad * 2 + 1;
while (son < len) {
if (son + 1 < len && A[son] < A[son + 1]) {//左孩子<右孩子
son++;//拿值大的元素
}
if (A[dad] < A[son]) {//父结点 < 大的孩子结点
swap(A[dad], A[son]);
dad = son;//son作为新的dad,验证往后的子树是否符合大根堆
son = dad * 2 + 1;
} else {
break;
}
}
}
void Heap_Sort(ElemType *A, int len) {
//调整为大根堆
for (int i = len / 2 - 1; i >= 0; i--) {
AdjustDown1(A, i, len);
}
swap(A[0], A[len-1]);
for (int j = len - 1; j > 1; j--) {
AdjustDown1(A, 0, j);//调整的位置是根节点,调整的个数是j个
swap(A[j-1], A[0]);
}
}
int main() {
SSTable ST;
Init_ST(ST, 10);
// ElemType A[10] = {3, 87, 2, 93, 78, 56, 61, 38, 12, 40};
// memcpy(ST.elem, A, sizeof(A));
Print_ST(ST);
Heap_Sort(ST.elem, 10);
Print_ST(ST);
return 0;
} |
时间复杂度和空间复杂度
AdjustDown1函数的循环次数是log2n,也就是树的高度;Heap_Sort函数的第一个for循环了n/2次,第二个for循环了n次,总计次数是3/2nlog2n次,因此时间复杂度是O()。堆排的空间复杂度是O(1),因为没有使用与n相关的额外空间。
因此,堆排最好、最坏、平均时间复杂度都是O()。堆排的空间复杂度是O(1)。
16.4 归并排序的原理及实战
16.4.1 归并排序原理
归并排序考研默认是两两进行的排序。
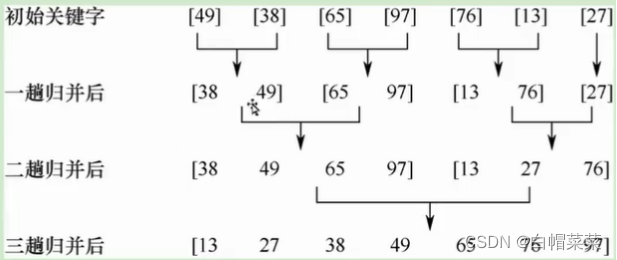
归并排序的代码时采用递归思想实现。首先,最小下标值和最大下标值相加并除以2,得到中间下标值mid,用Merge_Sort对low到mid排序,然后用Merge_Sort对mid+1到high排序。当数组的前半部分和后半部分都排好序后,使用Merge函数。
Merge函数的作用是合并两个有序数组。为了提高合并有序数组的效率,在Merge函数内定义了B[N]。首先,我们通过循环把数组A中从low到high的元素全部复制到B中,这时游标i从low开始,游标j从mid+1开始,谁小就将谁先放入数组A,对其游标加1,并在每轮循环时对数组A的计数游标k加1。
动画网站:“Comparison Sorting Visualization”。
16.4.2 归并排序实战
代码(动态分配的顺序表)
| #include <stdio.h>
#define N 7
typedef int ElemType;
//归并排序
void Merge(ElemType *A, int low, int mid, int high) {
static ElemType B[N];
for (int i = low; i <= high; i++) {
B[i] = A[i];//B复制两个数组的元素
}
int i, j, k;//两两比较有序插入到A中
for (i = low, j = mid + 1, k = i; i <= mid && j <= high; k++) {
if (B[i] > B[j]) {
A[k] = B[j++];
} else {
A[k] = B[i++];
}
}
//其中一个数组有剩余,再加入到A中
while(i <= mid){
A[k++] = B[i++];
}
while(j <= high){
A[k++] = B[j++];
}
}
void Merge_Sort(ElemType *A, int low, int high) {
if (low < high) {
int mid = (low + high) / 2;
Merge_Sort(A, low, mid);//两两排序
Merge_Sort(A, mid + 1, high);//两两排序
Merge(A, low, mid, high);//合并数组
}
}
void Print(ElemType *A) {
for (int i = 0; i < N; i++) {
printf("%3d", A[i]);
}
printf("\n");
}
int main() {
ElemType A[7] = {49, 38, 65, 97, 76, 13, 27};
Merge_Sort(A, 0, 6);
Print(A);
return 0;
} |
时间复杂度和空间复杂度
MergeSort函数的递归次数是log2n,Merge函数循环了n次,因此时间复杂度是O()。归并排序的空间复杂度是O(n),因为使用了数组B,它的大小与A一样,占用n个元素的空间。
因此,归并排序最好、最坏、平均时间复杂度都是O()。归并排序的空间复杂度是O(n)。
所有排序算法的时间与空间复杂度汇总

稳定性是指排序前后,相等的元素位置是否会被交换。
复杂性是指代码编写的难度。
OJ作业
1、课时17作业1
Description
读取10个整型数据12 63 58 95 41 35 65 0 38 44,然后通过选择排序,堆排序,分别对该组数据进行排序,输出2次有序结果,每个数的输出占3个空格
Sample Input 1
12 63 58 95 41 35 65 0 38 44
Sample Output 1
0 12 35 38 41 44 58 63 65 95
0 12 35 38 41 44 58 63 65 95
| #include <stdio.h>
#include <stdlib.h>
typedef int ElemType;
typedef struct SSTable {
ElemType *elem;
int TableLen;
} SSTable;
void Init_ST(SSTable &ST, int len) {
ST.TableLen = len;
ST.elem = (ElemType *) malloc(sizeof(ElemType) * len);
for (int i = 0; i < len; i++) {
scanf("%d", &ST.elem[i]);
}
}
void Print_ST(SSTable ST) {
for (int i = 0; i < ST.TableLen; i++) {
printf("%3d", ST.elem[i]);
}
printf("\n");
}
void swap(ElemType &i, ElemType &j) {
ElemType t = i;
i = j;
j = t;
}
//选择排序
void Select_Sort(ElemType *A, int n) {
for (int i = 0; i < n - 1; i++) {
int min = i;
for (int j = i + 1; j < n; j++) {
if (A[min] > A[j]) {
min = j;
}
}
if (min != i) {
swap(A[min], A[i]);
}
}
}
//堆排序
void AdjustDown1(ElemType *A, int adloc, int n) {
int dad = adloc;
int son = dad * 2 + 1;
while (son < n) {
if (son + 1 < n && A[son] < A[son + 1]) {
son++;
}
if (A[dad] < A[son]) {
swap(A[dad], A[son]);
dad = son;
son = dad * 2 + 1;
} else {
break;
}
}
}
void Heap_Sort(ElemType *A, int len) {
for (int i = len / 2 - 1; i >= 0; i--) {
AdjustDown1(A, i, len);
}
swap(A[0], A[len - 1]);
for (int i = len - 1; i > 1; i--) {
AdjustDown1(A, 0, i);
swap(A[i - 1], A[0]);
}
}
int main() {
SSTable ST;
Init_ST(ST, 10);
Select_Sort(ST.elem, ST.TableLen);
Print_ST(ST);
Heap_Sort(ST.elem, ST.TableLen);
Print_ST(ST);
return 0;
} |
2、课时17作业2
Description
读取10个整型数据12 63 58 95 41 35 65 0 38 44,然后通过归并排序,对该组数据进行排序,输出有序结果,每个数的输出占3个空格
Sample Input 1
12 63 58 95 41 35 65 0 38 44
Sample Output 1
0 12 35 38 41 44 58 63 65 95
| #include <stdio.h>
#define N 10
typedef int ELemType;
void Merge(ELemType *A, int low, int mid, int high) {
ELemType B[N];
for (int i = low; i <= high; i++) {
B[i] = A[i];
}
int i, j, k;
for (i = low, j = mid + 1, k = i; i <= mid && j <= high; k++) {
if (B[i] < B[j]) {
A[k] = B[i++];
} else {
A[k] = B[j++];
}
}
while (i <= mid) {
A[k++] = B[i++];
}
while (j <= high) {
A[k++] = B[j++];
}
}
void Merge_Sort(ELemType *A, int low, int high) {
if (low < high) {
int mid = (low + high) / 2;
Merge_Sort(A, low, mid);
Merge_Sort(A, mid + 1, high);
Merge(A, low, mid, high);
}
}
void Print(ELemType *A) {
for (int i = 0; i < N; i++) {
printf("%3d", A[i]);
}
printf("\n");
}
int main() {
ELemType A[N];
for (int i = 0; i < N; i++) {
scanf("%d", &A[i]);
}
Merge_Sort(A, 0, N - 1);
Print(A);
return 0;
} |
16.5 排序算法真题实战
16.5.1 2016年43题

| (1) 算法的基本设计思想 由题意知,将最小的n/2个元素放在A1中,剩下的元素放在A2中,分组结果即可满足题目。仿照快排的思想,基于枢轴将n个元素划分为两个子集。根据划分后的枢轴所处位置i分别处理: ① 若i=n/2,则分组完成,算法结束。 ② 若i<n/2,则枢轴及之前的元素属于A1,继续对i之后的元素进行划分。 ③ 若i>n/2,则枢轴及之后的元素属于A2,继续对i之前的元素进行划分。 |
| (2) 算法描述 #include <stdio.h>
int setPartition(int *A, int n) {
int low = 0, high = n - 1, pivot, flag = 1, high0 = n - 1, low0 = low;
while (flag) {//循环进行划分,直到划分成两半
while (low < high) {//快排算法
pivot = A[low];
while (low < high && A[high] >= pivot) {
high--;
}
A[low] = A[high];
while (low < high && A[low] <= pivot) {
low++;
}
A[high] = A[low];
}
A[low] = pivot;//low位置及前面是比枢轴pivot小的元素,后面是比枢轴大的元素
if (low == n / 2 - 1) {//刚好分成两半结束循环
flag = 0;
} else {
if (low < n / 2 - 1) {//前面的个数小于一半,继续划分,前一半作为A1
low0 = low++;//暂存本次的位置
high = high0;//将上一次循环的high0拿来
} else {//前面的个数大于一半,继续划分,后一半作为A2
low = low0;//将上一次循环的low0拿来
high0 = high--;//暂存本次的位置
}
}
}
int s1 = 0, s2 = 0;
for (int i = 0; i < n / 2; i++) {
s1 += A[i];
}
for (int i = n / 2; i < n; i++) {
s2 += A[i];
}
return s2 - s1;//返回A1和A2的差值
}
int main() {
int A[10] = {4, 1, 12, 18, 7, 13, 18, 16, 5, 15};
int different;
different = setPartition(A, 10);//初始只用写setPartition函数部分
printf("%d", different);
return 0;
} |
| (3) 平均时间复杂度和空间复杂度 平均时间复杂度是O(n),空间复杂度是O(1)。 基于该设计思想实现的算法,时间复杂度是O(n+n/2+n/4+...+n/2n-1)=O(2n)=n。 |
16.5.2 2016年42题

| (1) 算法思想 堆排序思想 定义含10个元素的大根堆H,元素值均为该堆元素类型能表示的最大数MAX。 for M中的每个元素s if(s<H的堆顶元素) 删除堆顶元素并将s插入到H中; 当数据全部扫描完毕,堆H中保存的即是最小的10个数。 进一步解析:先用A[0:9]原地建立大顶堆(注意:这里不能用小顶堆),遍历A[10:n],每个元素A[i]逐一和堆顶元素A[0]进行比较,其中11≤i≤n,如果A[i]≥堆顶元素A[0],不进行任何操作,如果该元素<堆顶元素A[0],那么就删除堆顶元素,将该元素放入堆顶,即令A[0]=A[i],然后将A[0:9]重新调整为大顶堆。最后堆A[0:9]中留存的元素即为最小的10个数。 |
| (2) 平均时间复杂度和空间复杂度 算法平均情况下的时间复杂度是O(n),空间复杂度是O(1)。 |
| #include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef int ElemType;
typedef struct SSTable {
ElemType *elem;
int TableLen;
} SSTable;
void Init_ST(SSTable &ST, int len) {
ST.TableLen = len;
ST.elem = (ElemType *) malloc(sizeof(ElemType) * ST.TableLen);
srand(time(NULL));
for (int i = 0; i < ST.TableLen; i++) {
ST.elem[i] = rand();
}
}
void Print_ST(SSTable ST) {
for (int i = 0; i < 10; i++) {
printf("% d", ST.elem[i]);
}
printf("\n");
}
//堆排序
void swap(ElemType &i, ElemType &j) {
ElemType t = i;
i = j;
j = t;
}
void AdjustDown1(ElemType *A, int adjloc, int n) {
int dad = adjloc;
int son = dad * 2 + 1;
while (son < n) {
if (son + 1 < n && A[son] < A[son + 1]) {
son++;
}
if (A[dad] < A[son]) {
swap(A[dad], A[son]);
dad = son;
son = dad * 2 + 1;
} else{
break;
}
}
}
void Heap_Sort(ElemType *A, int len) {
for (int i = len / 2 - 1; i >= 0; i--) {
AdjustDown1(A, i, len);//调整为大根堆
}
for (int i = len; i < 100000; i++) {
if (A[i] < A[0]) {
A[0]=A[i];
AdjustDown1(A, 0, len);
}
}
}
int main() {
SSTable ST;
Init_ST(ST, 100000);
Heap_Sort(ST.elem, 10);
Print_ST(ST);
return 0;
} |

























 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











