







目录
本章目标
本章主要是学习单元测试框架
untittest,这里的单元测试指的是对最小的软件设计单元(模块)进行的测试验证,在UI自动测试里,这些单元测试主要针对的是UI界面的功能进行的自动化测试.这里的unittest并不是java里的unit单元测试框架!
- unittest框架解析
- 批量处理脚本
- unittest断言
- HTML报告生成
- 异常捕捉和错误截图
- 数据驱动
unittest框架解析
unittest是python的单元测试框架,主要作用如下:
- 提供用例的组织和执行
当我们的测试用例比较庞大时就需要考虑用例的组织和执行顺序,unittest就可以帮助我们!
- 提供丰富的比较方法
我们用例执行结束后要通过比较用例执行的实际结果和预期结果(断言),从而确定用例是否顺利通过!
例如判断相等/不相等,包含/不包含,True/False
- 提供丰富的日志
当测试用例执行失败时可以清晰的抛出和保存用例执行失败的原因!日志提供了丰富的执行结果:用例总执行时间,失败用例数,成功用例数
unittest里的四个重要概念:
- Test Fixture
对一个测试环境的搭建和销毁就是一个
fixture,主要通过setUp()和tearDown()覆盖方法实现!
setUP():对测试环境的搭建,比如获取浏览器驱动,数据库建立连接初始化等等tearDown(): 对测试环境的销毁,比如关闭浏览器,关闭数据库的连接,清楚数据库中的数据等
- Test Case
Test Case的实例就是一个测试用例.测试用例就是完整的一个测试流程,包括测试环境的搭建(setUp),实现测试过程的代码,环境的还原(tearDown).一个测试用例就是一个测试单元,可以对某个测试功能进行验证!
- Test Suite
一个功能的验证往往需要多个测试用例,可以把多个测试用例集合在一起执行,这个就产生了测试套件TestSuite的概念。Test Suit测试套件用来将多个测试用例组装在一起
- Test Runner
测试的执行也是非常重要的一个概念,在unittest框架中,通过TextTestRunner类提供的run()方法来执行test suite/test case。
unittest框架测试脚本示例:
# 导入unittest框架
import unittest
from selenium import webdriver
import time
# 继承TestCase这个类就会使用unittest框架来组织测试用例!
class Baidu1(unittest.TestCase):
def setUp(self) -> None: # 覆盖setUP方法,测试环境搭建!
print('---setUp---')
self.driver = webdriver.Chrome() # 获取到浏览器驱动
self.url = "http://www.baidu.com/" #测试的web链接
self.driver.maximize_window() # 浏览器最大化!
time.sleep(3)
def tearDown(self) -> None: # 覆盖tearDown方法,测试环境销毁!
print('---tearmDown---')
self.driver.quit() # 关闭浏览器,释放驱动!
# 测试用例
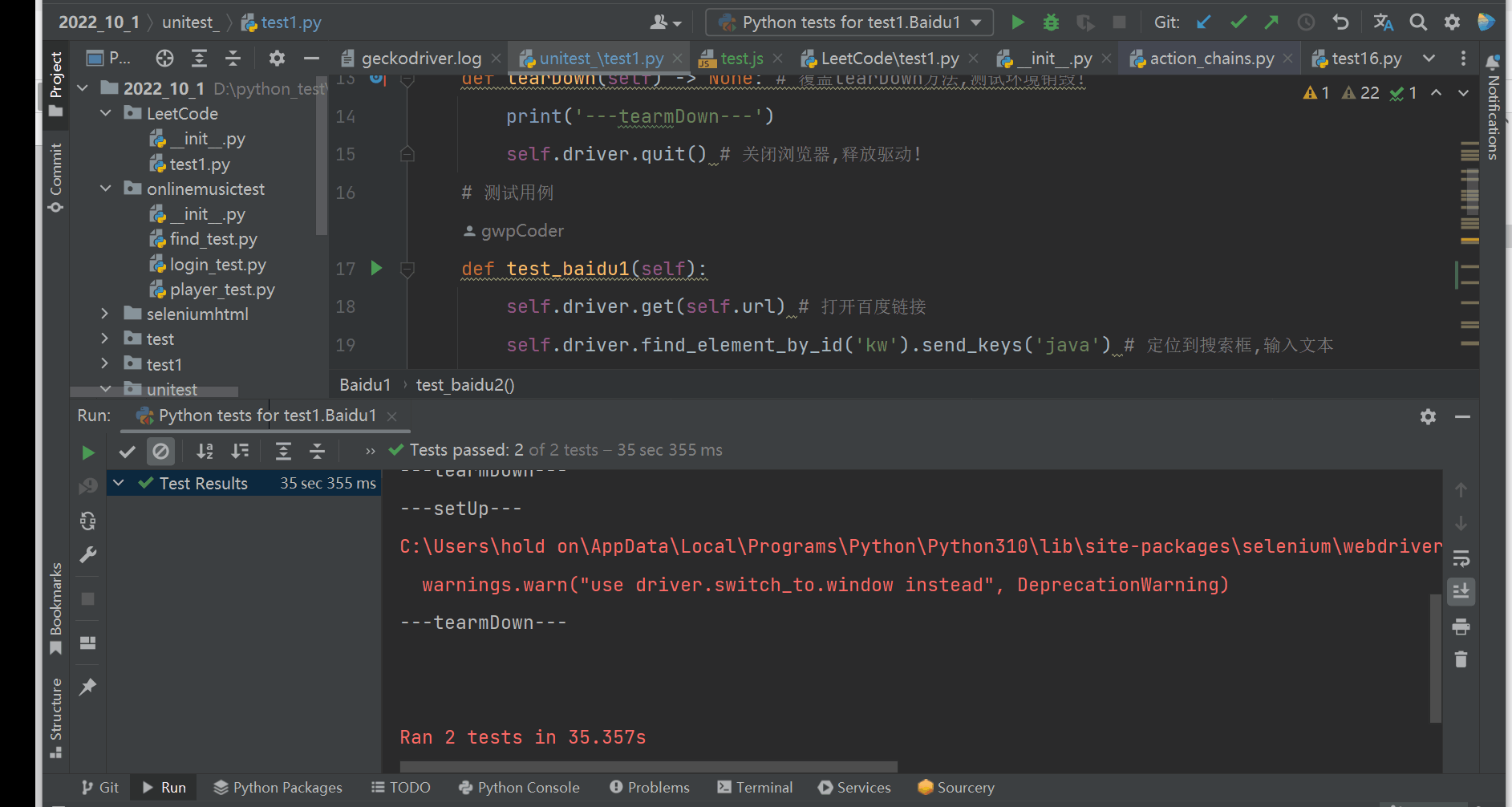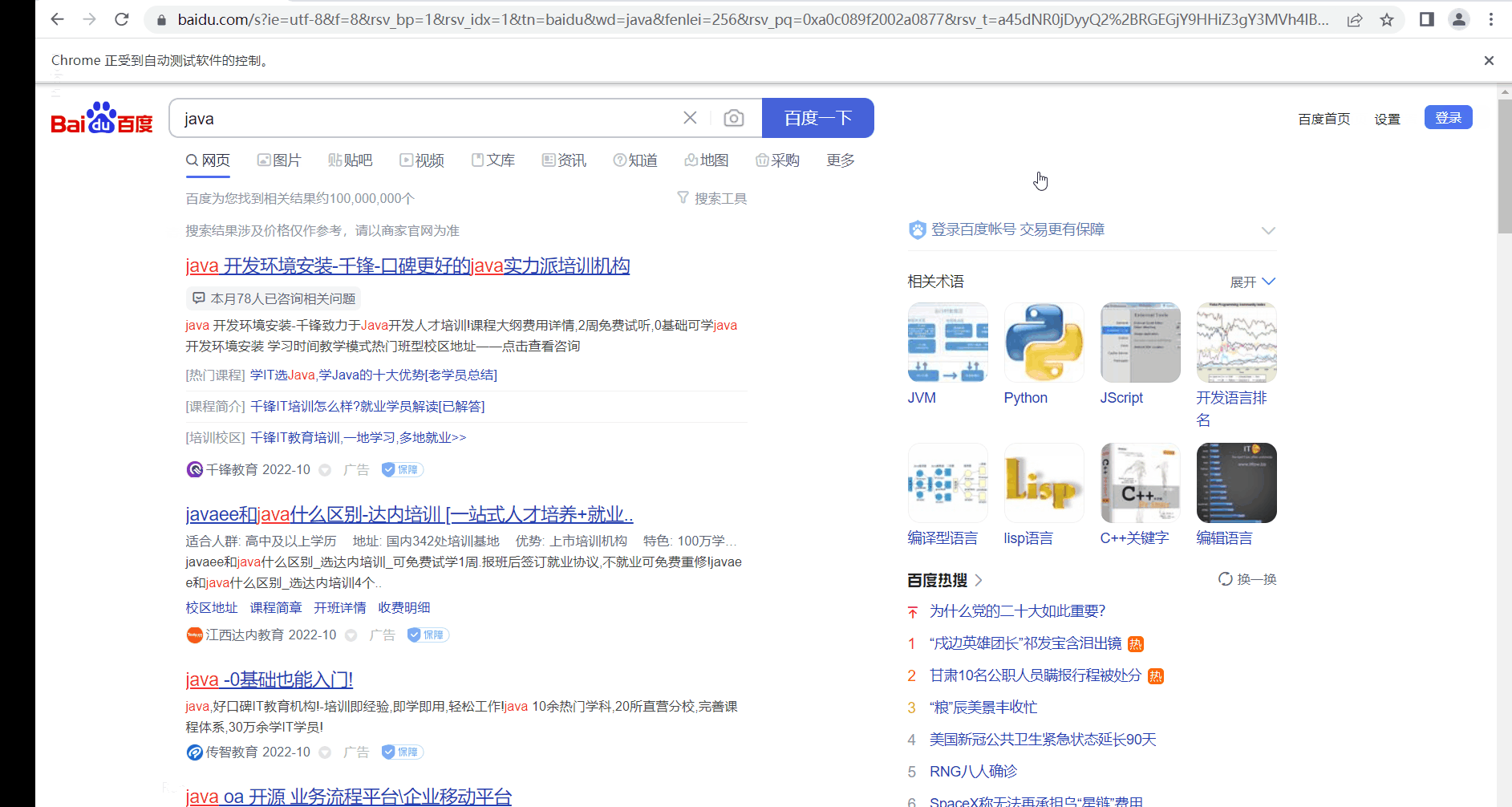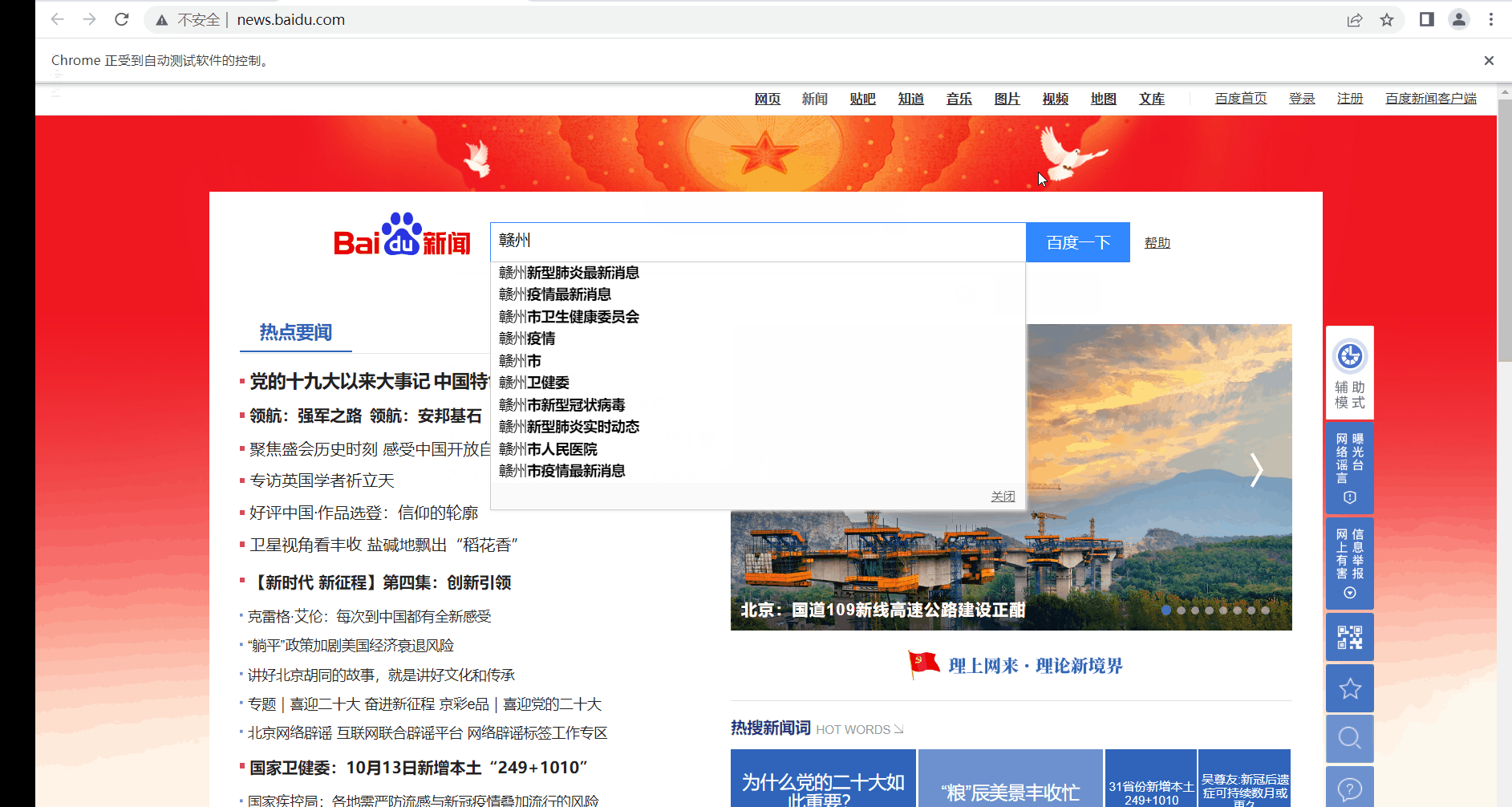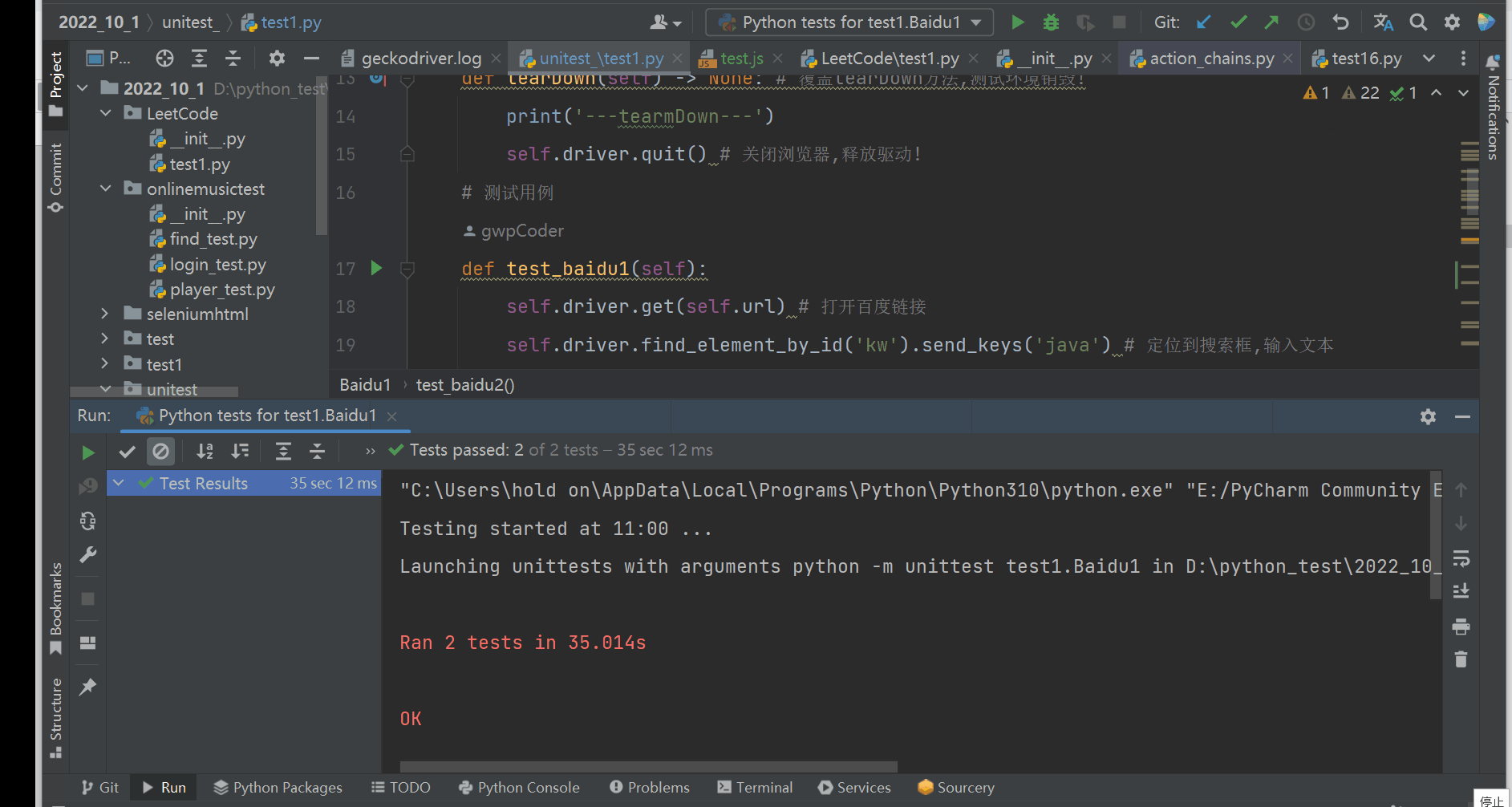
def test_baidu1(self):
self.driver.get(self.url) # 打开百度链接
self.driver.find_element_by_id('kw').send_keys('java') # 定位到搜索框,输入文本
time.sleep(2)
self.driver.find_element_by_id('su').click() # 定位到搜索按钮点击!
time.sleep(3)
def test_baidu2(self):
self.driver.get(self.url) # 重新打开百度链接!
self.driver.find_element_by_link_text('新闻').click() # 打开新闻导航地址
time.sleep(2)
for window in self.driver.window_handles:
self.driver.switch_to_window(window)
if window.title =='百度新闻——海量中文资讯平台':
break
self.driver.find_element_by_name('word').send_keys('赣州')
time.sleep(2)
self.driver.find_element_by_xpath('//*[@id="s_btn_wr"]').click()
time.sleep(2)
#滑动到低端!
js = 'var j = document.documentElement.scrollTop=10000'
self.driver.execute_script(js)
time.sleep(3)
#滑动到顶端
js = 'var j = document.documentElement.scrollTop=0'
self.driver.execute_script(js)
time.sleep(3)
def baidu3(self):
self.driver.get('http://baidu.com/')
self.driver.find_element_by_partial_link_text('hao').click()
time.sleep(2)
if __name__=='__main__':
unittest.main() # unittest框架提供了全局的main方法
这里
unittest提供了全局的main方法,main方法中会将test_开头的方法进行组织,然后调用main方法就可以执行所有的以test_开头的方法!
新窗口,无法定位元素
注意事项
当我们在当前页面的基础上开了一个新的窗口页面,我们如果要对新的窗口元素进行定位,我们需要将窗口更新,才能定位到新的窗口元素
# 进行窗口定位之前要time.sleep() 保证窗口已经跳转过来!
for handle in self.driver.window_handles:
self.driver.switch_to_window(handle) # 转换到新的窗口!
if hanle.title =='新窗口title':
break # 定位到窗口就退出循环!
#进行新窗口元素的定位!
批量执行脚本
但我们需要扩展新的功能测试或者测试用例时,我们需要把多个测试用例组织在一起执行,我们可以通过
unittest中的测试套件Test Suite进行测试用例的组织
假设我们编写了2个文件test1.py和test2.py我们如何同时执行这2个文件呢?
test1.py
# 导入unittest框架
import unittest
from selenium import webdriver
import time
# 继承TestCase这个类就会使用unittest框架来组织测试用例!
class Baidu1(unittest.TestCase):
def setUp(self) -> None: # 覆盖setUP方法,测试环境搭建!
print('---setUp---')
self.driver = webdriver.Chrome() # 获取到浏览器驱动
self.url = "http://www.baidu.com/" #测试的web链接
self.driver.maximize_window() # 浏览器最大化!
time.sleep(3)
def tearDown(self) -> None: # 覆盖tearDown方法,测试环境销毁!
print('---tearmDown---')
self.driver.quit() # 关闭浏览器,释放驱动!
# 测试用例
def test_baidu1(self):
self.driver.get(self.url) # 打开百度链接
self.driver.find_element_by_id('kw').send_keys('java') # 定位到搜索框,输入文本
time.sleep(2)
self.driver.find_element_by_id('su').click() # 定位到搜索按钮点击!
time.sleep(3)
def test_baidu2(self):
self.driver.get(self.url) # 重新打开百度链接!
self.driver.find_element_by_link_text('新闻').click() # 打开新闻导航地址
time.sleep(2)
for window in self.driver.window_handles:
self.driver.switch_to_window(window)
if window.title =='百度新闻——海量中文资讯平台':
break
self.driver.find_element_by_name('word').send_keys('赣州')
time.sleep(2)
self.driver.find_element_by_xpath('//*[@id="s_btn_wr"]').click()
time.sleep(2)
#滑动到低端!
js = 'var j = document.documentElement.scrollTop=10000'
self.driver.execute_script(js)
time.sleep(3)
#滑动到顶端
js = 'var j = document.documentElement.scrollTop=0'
self.driver.execute_script(js)
time.sleep(3)
def baidu3(self):
self.driver.get('http://baidu.com/')
self.driver.find_element_by_partial_link_text('hao').click()
time.sleep(2)
if __name__=='__main__':
unittest.main() # unittest框架提供了全局的main方法
test2.py
from selenium import webdriver
import unittest
import time
from selenium.webdriver.common.action_chains import ActionChains
class test2(unittest.TestCase): # 继承 TestCase
def setUp(self) -> None:
# 测试环境搭建
print('--test2.setUp--')
self.driver = webdriver.Chrome() #获取驱动
self.url = 'https://fanyi.baidu.com/?aldtype=16047#auto/zh' # 百度翻译的url!
def tearDown(self) -> None:
#测试环境销毁
print('--test2.tearDown--')
self.driver.quit()
#测试用例!
def test_baidu1(self):
self.driver.get(self.url) # 打开百度翻译url!
self.driver.maximize_window() # 窗口最大化!
self.driver.find_element_by_id('baidu_translate_input').send_keys('unittest') # 定位到翻译搜索框
time.sleep(3)
# 定位到弹出的广告!
self.driver.find_element_by_xpath('//*[@id="app-guide"]/div/div/div[2]/span').click()
time.sleep(2)
self.driver.find_element_by_id('translate-button').click() # 定位到翻译按钮
time.sleep(3)
# 定位到翻译结果框!
test = self.driver.find_element_by_xpath('/html/body/div[1]/div[2]/div/div/div[1]/div[2]/div[1]/div[2]/div/div/div[1]/p[2]').text
print('unitest:',test)
def test_baidu2(self):
self.driver.get(self.url)
# 定位到弹出的广告!
self.driver.find_element_by_xpath('//*[@id="app-guide"]/div/div/div[2]/span').click()
time.sleep(2)
p = self.driver.find_element_by_xpath('/html/body/div[1]/div[1]/div/div/div/div[1]/div/span') # 定位到文档翻译
# 将鼠标移动到该位置!
ActionChains(self.driver).move_to_element(p).perform()
time.sleep(2)
# 然后定位到上传文档按钮!
self.driver.find_element_by_xpath('//*[@id="header"]/div/div/div/div[1]/div/span').click()
time.sleep(3)
if __name__ == '__main__':
unittest.main()

- addTest()
TestSuite类中的
addTest方法可以把不同类的测试用例方法组织到测试套件中,但是这里的addTest方法一次只能添加一个测试用例方法
这里的不足就是每次只能添加一个方法到套件中,并且要该方法的类导入
构造测试套件
makeSuite()和TestLoader的应用
- makeSuite()
在
unittest框架中提供了makeSuite()方法,makeSuite可以将测试用例类内的测试用例case组成套件TestSuite
unittest调用makeSuite传入类名即可!
- TestLoader()
TestLoader用于创建类和模块的测试套件,一般的情况下,使TestLoader().loadTestsFromTestCase(TestClass)来加载测试类。
下面就是组织成测试套件的3种方式
import unittest
from unitest_ import test1
from unitest_ import test2
def createsuite():
# addTest # 向测试套件里添加测试用例!
# suite = unittest.TestSuite()
# suite.addTest(unitest_.test1.Baidu1('test_baidu1'))
# suite.addTest(unitest_.test1.Baidu1('test_baidu2'))
# suite.addTest(unitest_.test2.test2('test_baidu1'))
# suite.addTest(unitest_.test2.test2('test_baidu2'))
# return suite
# makeSuite 通过addTest()方法,将一个类的的测试用例通过makeSuite添加
# suite = unittest.TestSuite()
# suite.addTest(unittest.makeSuite(test1.Baidu1))
# suite.addTest(unittest.makeSuite(test2.test2))
# return suite
#通过TestLoader将测试用例组织成测试套件!
#先加载
s1 = unittest.TestLoader().loadTestsFromTestCase(test1.Baidu1)
s2 = unittest.TestLoader().loadTestsFromTestCase(test2.test2)
suite = unittest.TestSuite([s1,s2])
return suite
if __name__=='__main__':
suit = createsuite()
runner = unittest.TextTestRunner(verbosity=2)
runner.run(suit)
上面的3种只能导入一个类,当我们不用一个
.py测试类,我们只需要导入一个方法该如何操作呢?
discover()的引用
discover是通过递归的方式到其子目录中从指定的目录开始, 找到所有测试模块并返回一个包含它们
对象的TestSuite,然后进行加载与模式匹配唯一的测试文件,discover参数分别为discover(dir,pattern,top_level_dir=None)
import unittest
from unitest_ import test1
from unitest_ import test2
def createsuite():
discover = unittest.defaultTestLoader.discover('../test1',pattern='test*.py',top_level_dir=None)
print(discover)
return discover
if __name__=='__main__':
suit = createsuite()
runner = unittest.TextTestRunner(verbosity=2)
runner.run(suit)
用例的执行顺序
unittest框架默认加载测试用例的顺序是根据ASCII码的顺序,数字与字母的顺序为: 0~ 9 ,A~ Z,a~z 。所以,TestAdd类会优先于TestBdd类被发现,test_aaa()方法会优先于test_ccc()被执行。对于测试
目录与测试文件来说,unittest框架同样是按照这个规则来加载测试用例。
addTest()方法按照增加顺序来执行
忽略用例执行
我们通过
unittest下的一个注解实现测试用例的忽略功能!
@unitest.skip('忽略用例的注释')
运行结果
unittest断言
自动化的测试中, 对于每个单独的case来说,一个case的执行结果中, 必然会有期望结果与实际结果, 来判断该case是通过还是失败, 在unittest 的库中提供了大量的实用方法来检查预期值与实际值, 来验证case的结果, 一般来说, 检查条件大体分为等价性, 逻辑比较以及其他, 如果给定的断言通过, 测试会继续执行到下一行的代码, 如果断言失败, 对应的case测试会立即停止或者生成错误信息( 一般打印错误信息即可) ,但是不要影响其他的case执行。
unittest 的单元测试库提供了标准的xUnit 断言方法。下面是一些常用的断言:
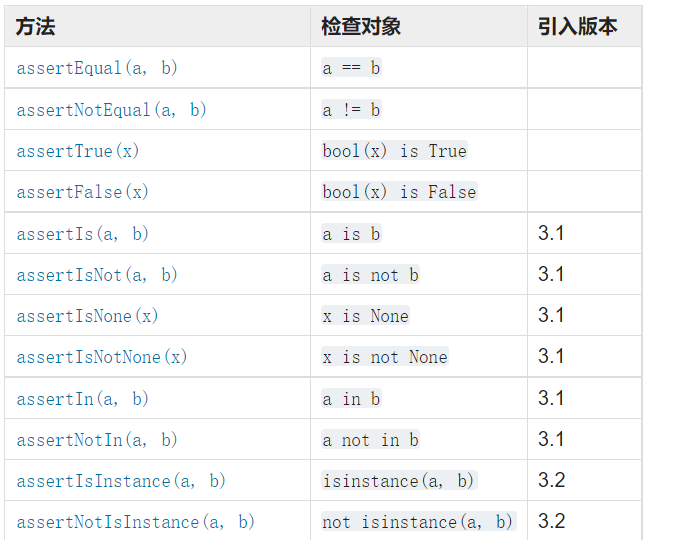
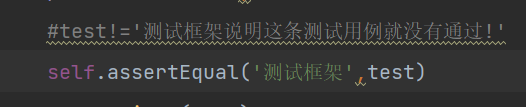
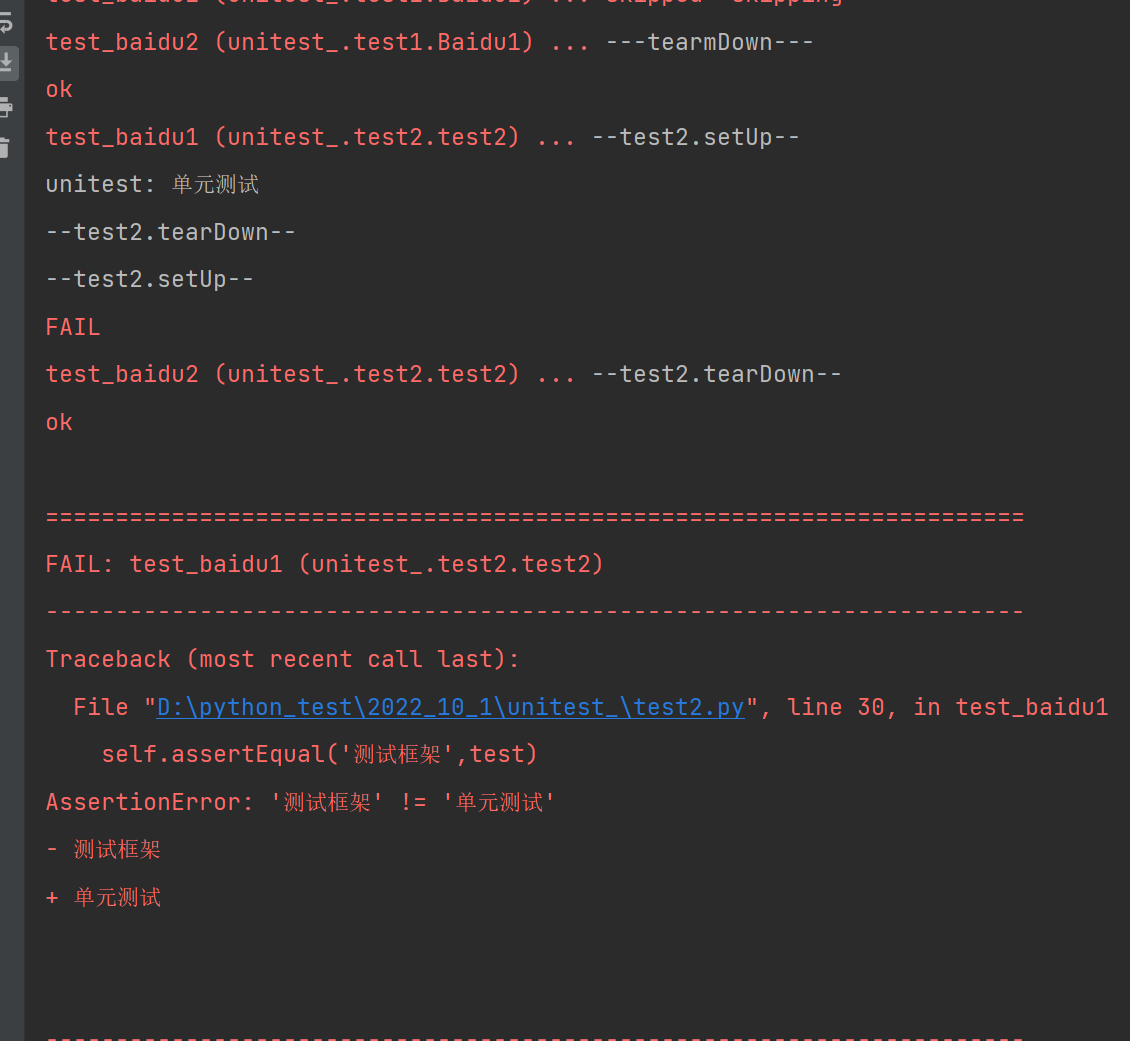
我们期待的结果是测试框架但是实际结果test是单元测试,那就说明这条测试用例没有通过!

verbosity
verbosity是一个选项,表示测试结果的信息复杂度,有0、1、2三个值。
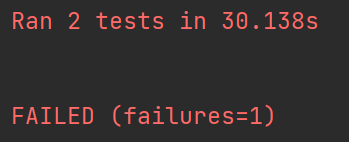
0:静默模式,只能获取总的测试数和总的执行结果,比如成功3,失败4
1:默认模式,非常类似静默模式,只是在每个成功的测试用例前面会有".“,在每个失败的测试用例前面有"F”
2:详细模式,测试结果会显示每个测试用例的所有相关的信息
verbosity=0
verbosity=1

verbosity=2
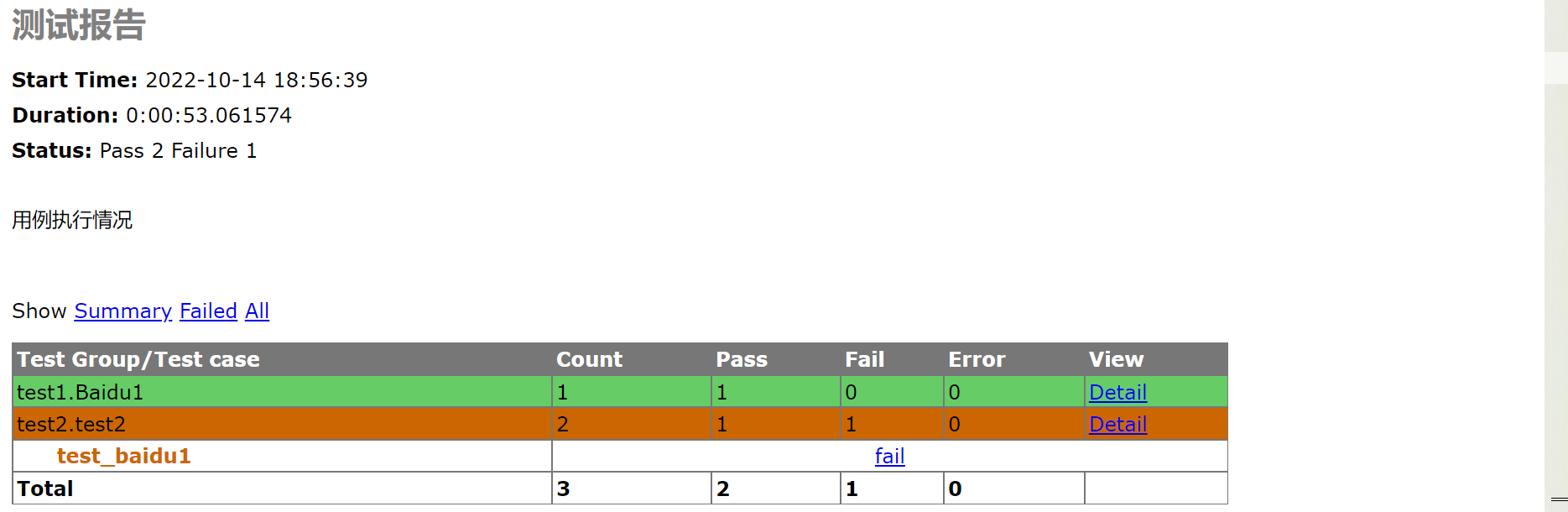
HTML报告生成
脚本执行完毕之后,还需要看到HTML报告,下面我们就通过HTMLTestRunner.py 来生成测试报告。
HTMLTestRunner支持python2.7。python3可以参见http://blog.51cto.com/hzqldjb/1590802来进行修改。
HTMLTestRunner.py文件,下载地址: http://tungwaiyip.info/software/HTMLTestRunner.html
下载后将其放在testcase目录中去或者放入...\Python27\Lib 目录下(windows)。
import HTMLTestRunner
import os
import sys
import time
import unittest
def createsuite():
discovers = unittest.defaultTestLoader.discover("../unitest_", pattern="test*.py", top_level_dir=None)
print(discovers)
return discovers
if __name__=="__main__":
# 文件夹要创建在哪里
curpath = sys.path[0]
print(sys.path)
print(sys.path[0])
# 1,创建文件夹,创建的这个文件夹干什么
if not os.path.exists(curpath+'/resultreport'):
os.makedirs(curpath+'/resultreport')
# 2,文件夹的命名,不能让名称重复
# 时间 时分秒 ——》名称绝对不会重复
now = time.strftime("%Y-%m-%d-%H %M %S", time.localtime(time.time()))
print(now)
print(time.time())
print(time.localtime(time.time()))
# 文件名
filename = curpath + '/resultreport/'+ now + 'resultreport.html'
with open(filename, 'wb') as fp:
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u"测试报告",
description=u"用例执行情况", verbosity=2)
suite = createsuite()
runner.run(suite)

异常捕捉和错误截图
用例不可能每一次运行都成功,肯定运行时候有不成功的时候。如果可以捕捉到错误,并且把错误截图保存,这将是一个非常棒的功能,也会给我们错误定位带来方便。
例如编写一个函数,关键语句为driver.get_screenshot_as_file:
def savescreenshot(self,driver,file_name):
if not os.path.exists('./image'):
os.makedirs('./image')
now=time.strftime("%Y%m%d-%H%M%S",time.localtime(time.time()))
#截图保存
driver.get_screenshot_as_file('./image/'+now+'-'+file_name)
time.sleep(1)

数据驱动
之前我们的case都是数据和代码在一起编写。考虑如下场景:需要多次执行一个案例,比如baidu搜索,分别输入中文、英文、数字等进行搜索,这时候需要编写3个案例吗?有没有版本一次运行?
python 的unittest 没有自带数据驱动功能。所以如果使用unittest,同时又想使用数据驱动,那么就可以使用DDT来完成。
DDT安装地址:https://ddt.readthedocs.io/en/latest/
在cmd命令窗口输入下面命令即可!
pip install ddt
python setup.py install
可能
pip版本不够,可以使用版本更新命令
查看当前pip版本
pip show pip
更新pip版本
python -m pip install --upgrade pip

安装成功
ddt使用方法:
参考文档:http://ddt.readthedocs.io/en/latest/
dd.ddt:
装饰类,也就是继承自TestCase的类。
ddt.data:
装饰测试方法。参数是一系列的值。
ddt.file_data:
装饰测试方法。参数是文件名。文件可以是json 或者 yaml类型。
注意,如果文件以”.yml”或者”.yaml”结尾,ddt会作为yaml类型处理,其他所有文件都会作为json文件处理。
如果文件中是列表,每个列表的值会作为测试用例参数,同时作为测试用例方法名后缀显示。
如果文件中是字典,字典的key会作为测试用例方法的后缀显示,字典的值会作为测试用例参数。
ddt.unpack:
传递的是复杂的数据结构时使用。比如使用元组或者列表,添加unpack之后,ddt会自动把元组或者列表对应到多个参数上。字典也可以这样处理。
1、传递列表、字典等数据
# get_ddt.py
import unittest
from ddt import ddt, data, unpack, file_data
# 声明了ddt类装饰器
@ddt
class MyddtTest(unittest.TestCase):
# @data方法装饰器
# 单组元素
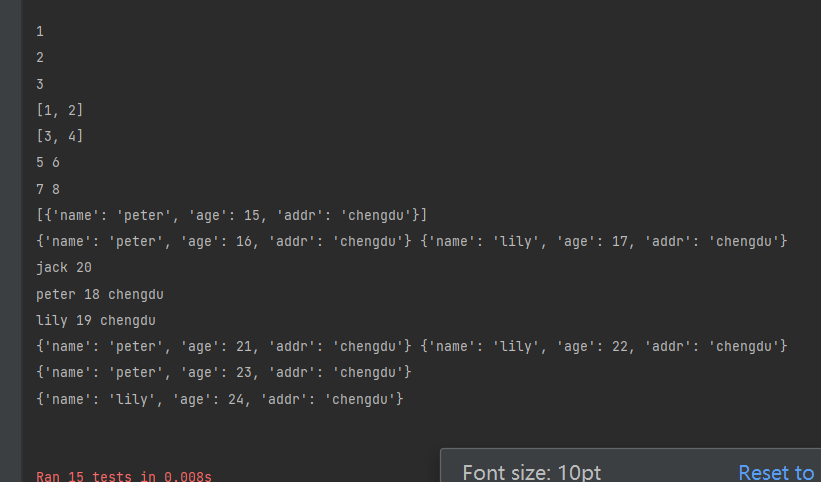
@data(1,2,3)
def test_01(self, value): # value用来接受data的数据
print(value)
# 多组数据,未拆分
@data([1,2],[3,4])
def test_02(self, value):
print(value)
# 多组数据,拆分
# @unpac拆分,相当于把数据的最外层结构去掉
@data([5,6],[7,8])
@unpack
def test_03(self, value1, value2):
print(value1, value2)
# 单个列表字典,未拆分
@data([{"name": "peter", "age": 15, "addr": "chengdu"}])
def test_04(self, value):
print(value)
# 多个列表字典,拆分
@data([{"name":"peter","age":16,"addr":"chengdu"},{"name":"lily","age":17,"addr":"chengdu"}])
@unpack
def test_05(self, value1, value2):
print(value1, value2)
# 单个字典,拆分
# @data里的数据key必须与字典的key保持一致
@data({"name":"jack","age":20})
@unpack
def test_06(self, name, age):
print(name, age)
# 多个字典, 拆分
@data({"name":"peter","age":18,"addr":"chengdu"},{"name":"lily","age":19,"addr":"chengdu"})
@unpack
def test_07(self, name, age, addr):
print(name, age, addr)
# 多个列表字典,引用数据
testdata = [{"name": "peter", "age": 21, "addr": "chengdu"}, {"name": "lily", "age": 22, "addr": "chengdu"}]
@data(testdata)
@unpack
def test_08(self, value1, value2):
print(value1, value2)
# @data(*testdata):*号意为解包,ddt会按逗号分隔,将数据拆分(不需要@unpack方法装饰器了)
testdata = [{"name":"peter","age":23,"addr":"chengdu"},{"name":"lily","age":24,"addr":"chengdu"}]
@data(*testdata)
def test_09(self, value):
print(value)
if __name__ == "__main__":
unittest.main()
2.传递json、yaml文件
3.python中使用ddt+excel读取测试数据
















 1109
1109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











