






目录
4、String、StringBuffer和String Builder的区别及使用场景?
3)、HashMap在JDK1.7和JDK1.8中有哪些不同?HashMap的底层实现
10)、在使用HashMap的时候,用String作为key有什么好处?
11、请你说说hashCode()和equals()的区别,为什么重写equals()就要重写hashcod()?
12、ConcurrentHashMap原理,jdk7和jdk8的区别?
14、为什么要使用克隆?如何实现对象克隆?深拷贝和浅拷贝的区别是什么?
19、以“HashSet”如何检查重复为例子来说明为什么要有HashCode?
6、Java虚拟机堆中的新生代,为什么要分为Eden区和Survivor区?而且为什么要设置两个Survivor区?
1)、Java.lang.StackOverflowError
2)、Java.lang.OutOfMemoryError:Java heap space
3)、Java.lang.OutOfMemoryError:GC overhead limit exceeded
4)、Java.lang.OutOfMemoryError:Direct buffer memory
5)、Java.lang.OutOfMemoryError:unable to crea te new native thread
6)、Java.lang.OutOfMemoryError:Metaspace
8)、为什么我们调用 start() 方法时会执行 run() 方法,为什么我们 不能直接调用 run() 方法?
2、Spring的对象默认是单例的还是多例的? 单例bean存不存在线程安全问题呢?
一、Java
1、ArrayList和LinkedList有什么区别?
(1)、ArrayList是实现了基于动态数组的数据结构,是连续存储的;LinkedList是基于链表的数据结构,存储在分散的内存中。
(2)、当随机访问List时(get和set操作),ArrayList比LinkedList的效率更高,因为LinkedList是线性的数据存储方式,所以需要移动指针从前往后一次查找。LinkedLIst要移动指针。ArrayList:基于数组,需要连续内存、随机访问快(指根据下标访问)、尾部插入、删除性能可以,其它部分插入、删除都会移动数据,因此性能会低、可以利用cpu缓存,局部性原理。LinkedList:基于双向链表,无需连续内存、随机访问慢(要沿着链表遍历)、头尾插入删除性能高、占用内存多
(3)、对于新增和删除操作add和remove,LinkedList比较占优势,因为ArrayList要移动数据。
(4)、从利用效率来看,ArrayList自由性较低,因为它需要手动的设置固定大小的容量,但是它使用比较方便,只需要创建,然后添加数据,通过调用下标进行使用;而LinkedList自由性较高,能够动态的随数据量的变化而变化,但是它不便于使用。
扩容机制:因为数组长度固定,超出长度存储数据时需要新建数组,然后将老数组的数据拷贝到新数组,如果不是尾部插入数据还会涉及到元素的移动(往后复制一份,插入新元素),使用尾插法并指定初始容量可以极大提升性能,甚至超过LinkedList(需要创建大量的node对象)
不适合查询:需要逐一遍历,遍历LinkedList必须使用iterator不能使用for循环,因为每次for循环体内通过get(i)取得某一元素时都需要对list重新进行遍历,性能消耗极大。另外不要试图使用IndexOf等返回元素索引,并利用其进行遍历,使用indexOf对list进行了比较遍历,当结果为空时会遍历整个列表。
//1,首先是默认初始值的大小:
private static final int DEFAULT_CAPACITY = 10;,
//2,接着是一个默认的空对象数组:
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//3,然后是ArrayList 实际数据存储的一个数组:
transient Object[] elementData;
//4,elementData 的大小:
private int size;我们构造一个ArrayList,添加一个元素,看一下其容量。最终的结果,容量:10,大小:1,可以看出。也就是说如果ArrayList 构造函数中如果没有设置初始化的容量大小,在没有添加有元素的时候,其初始化容量是0,只有当添加第一个元素的时候,才会初始化容量才会设置成10.
ArrayList<String> list = new ArrayList<>();
Integer length = getCapacity(list);
int size = list.size();
System.out.println("容量: " + length);
System.out.println("大小: " + size);ArrayList 扩容机制
//接下来,我们进行构造一个ArrayList 对象,同样调用的是无参构造函数。然后往里面添加11个对象,看起容量会如何进行动态扩展。最终结果,容量:15,大小:11
ArrayList<String> list = new ArrayList<>();
for (int i = 1; i <= 11; i++) {
list.add("value" + i);
}
Integer length = getCapacity(list);
int size = list.size();
System.out.println("容量: " + length);
System.out.println("大小: " + size);
//要清楚其扩容机制,我们需要跟进去,看一下其add 方法,
public boolean add(E e) {
//① ensureCapacityInternal方法名的英文大致是“确保内部容量”,size表示的是执行添加之前的元素个数,并非ArrayList的容量,容量应该是数组elementData的长度。ensureCapacityInternal该方法通过将现有的元素个数与数组的容量比较。看如果需要扩容,则扩容。
//②是将要添加的元素放置到相应的数组中。
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
//看一下ensureCapacityInternal方法的实现:
private void ensureCapacityInternal(int minCapacity) {
DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}
//判断elementData这个数组是否为空,如果为空,就让默认大小10与传过来的minCapacity比较,找打一个最大的
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
//根据传入的最小需要容量minCapacity来和数组的容量长度对比,如果minCapacity大于或等于数组容量,则需要进行扩容。
if (minCapacity - elementData.length > 0) // 如果其元素个数大于其容量,则进行扩容。
grow(minCapacity);
}
//具体扩容流程:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length; // 原来的容量
int newCapacity = oldCapacity + (oldCapacity >> 1); // 新的容量,原来容量的1.5倍。
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0) // 如果大于ArrayList 可以容许的最大容量,则设置为最大容量。
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity); // 最终利用Arrays.coppy 进行扩容,生成一个1.5倍元素的数组。(即例子中的15个元素的数组。)
}
//ArrayList 的内部实现,其实是用一个对象数组进行存放具体的值,然后用一种扩容的机制,进行数组的动态增长。其扩容机制可以理解为,如果元素的个数,大于其容量,则把其容量扩展为原来容量的1.5倍。规则:
ArrayList()会使用长度为零的数组
ArrayList(int initialCapacity)会使用指定容量的数组
public ArrayList(Collection<? extends E> c)会使用c的大小作为数组容量
add(Object o)首次扩容为10,再次扩容为上次容量的1.5倍
addAll(Collection c)没有元素时,扩容为Math.max(10,实际元素个数),有元素时为Math.max(原容量1.5倍, 实际元素个数)
2、==和equals的区别?
1)、对于==,比较的是值是否相等
如果作用于基本数据类型的变量,则直接比较其存储的 值是否相等,
如果作用于引用类型的变量,则比较的是所指向的对象的地址是否相等。
其实==比较的不管是基本数据类型,还是引用数据类型的变量,比较的都是值,只是引用类型变量存的值是对象的地址
2)、对于equals方法,比较的是是否是同一个对象
首先,equals()方法不能作用于基本数据类型的变量,
另外,equals()方法存在于Object类中,而Object类是所有类的直接或间接父类,所以说所有类中的equals()方法都继承自Object类,在没有重写equals()方法的类中,调用equals()方法其实和使用==的效果一样,也是比较的是引用类型的变量所指向的对象的地址,不过,Java提供的类中,有些类都重写了equals()方法,重写后的equals()方法一般都是比较两个对象的值,比如String类。
equals比较的是两个对象值是否相等,如果没有被重写,比较的是对象的引用地址是否相同;
==用于比较基本数据类型的值是否相等,或比较两个对象的引用地址是否相等;
//基本数据类型的比较
int num1 = 10;
int num2 = 10;
System.out.println(num1 == num2); //true
//引用数据类型的比较
String s1 = "chance";
String s2 = "chance";
System.out.println(s1 == s2); //true
System.out.println(s1.equals(s2)); //true
//String类中==与equals的比较
String s3 = new String("chance");
String s4 = new String("chance");
System.out.println(s3 == s4); //false
System.out.println(s3.equals(s4)); //true
//非String类中==与equals类型的比较
Scanner scanner = new Scanner(System.in);
Scanner scanner2 = new Scanner(System.in);
System.out.println(scanner.equals(scanner2)); //false
Scanner sc = scanner;
System.out.println(scanner.equals(sc)); //true3、final的用法和作用
1、修改类:表示类是不可以被继承的
2、修饰方法:表示方法不可被子类覆盖,但是可以重载
3、修饰变量:表示变量一旦被赋值就不可以更改它的值
修饰基本类型数据和引用类型数据:如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象,但是引用的值是可变的。
public class Test1 {
public static void main(String[] args) {
final int a = 10;
a = 4;//非法
final int[] arr = {1,2,3,4};
arr[2] = -2;//合法
arr = null;//非法,对arr不能重新赋值
final Person p = new Person(25);
p.setAge(23);//合法
p = null;//非法
}
}
@Data
class Person{
private int age;
public Person(int age) {
this.age = age;
}
}4、修改参数:参数在整个方法内不允许被修改
对于final修饰的成员变量而言,一旦有了初始值就不能被重新赋值,如果既没有在定义成员遍历时指定初始值,也没有在初始化块,构造器中为成员变量指定初始值,那么这个成员变量的值将一直是系统默认分配的0、'\u0000'、false或者是null,那么这个成员变量就失去了存在的意义,所以java语法规定:final修饰的成员变量必须由程序员显示的指定初始值。final修饰IDE实例变量,要么在定义该实例变量时指定初始值,要么在普通初始化块或构造器中为该实例变量指定初始值。
但要注意的是,如果普通初始化块已经为某个实例变量指定了初始值,则不能再在构造器中为该实例变量指定初始值;final修饰的类变量,要么在定义该变量时指定初始值,要么在静态初始化块中为该类变量指定初始值。 实例变量不能在静态初始化块中指定初始值,因为静态初始化块是静态成员,不可以访问实例变量;类变量不能在普通初始化块中指定初始值,因为类变量在类初始化阶段已经被初始化了,普通的初始化块不能为其重新赋值。 系统不会为局部变量进行初始化,所以局部变量必须由程序员显示的初始化。因此使用final修饰局部变量时,既可以在定义时指定默认值,也可以不指定默认值。如果final修饰的局部变量在定义是没有指定默认值,则可以在后面的代码中对该final变量赋初始值,但只能一次,不能重复赋值;如果final修饰的局部变量在定义时已经指定默认值,则后面代码中不能再对该变量赋值。
4、String、StringBuffer和String Builder的区别及使用场景?
String是final修饰的,不可变,每次操作都会产生新的String对象
String Buffer和StringBuilder都是在原对象上操作,每次操作并不产生新的未使用对象
String Buffer是线程安全的,String Builder是线程不安全的
StringBuffer方法都是synchronized修饰的
性能:StringBuilder > StringBuffer > String
场景:经常需要改变字符串内容时使用后面两个,优先使用StringBuilder,多线程使用共享变量时使用StringBuffer
5、重载和重写的区别?
1)、重写
发生在父子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符大于等于父类,如果父类方法访问修饰符为private则子类就不能重写该方法。其实就是在子类中把父类本身有的方法重新写一遍所以在方法名,参数列表,返回类型(除过子类中方法的返回值是父类中方法返回值的子类时)都相同的情况下, 对方法体进行修改或重写。
public class Father {
public static void main(String[] args) {
// TODO Auto-generated method stub
Son s = new Son();
s.sayHello();
}
public void sayHello() {
System.out.println("Hello");
}
}
class Son extends Father{
@Override
public void sayHello() {
// TODO Auto-generated method stub
System.out.println("hello by ");
}
}2)、重载
发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同,重载对返回类型没有要求,可以相同也可以不同,但不能通过返回类型是否相同来判断重载。
public class Father {
public static void main(String[] args) {
// TODO Auto-generated method stub
Father s = new Father();
s.sayHello();
s.sayHello("wintershii");
}
public void sayHello() {
System.out.println("Hello");
}
public void sayHello(String name) {
System.out.println("Hello" + " " + name);
}
}6、List和Set的区别
List:有序,按对象进入的顺序保存对象,可重复,允许多个null元素对象,可以使用Iterator取出所有元素,再逐一遍历,还可以使用get(int index)获取指定下标的元素。和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变
Set:无序,不可重复,最多允许有一个Null元素对象,取元素时只能用Iterator接口取得所有元素,再逐一遍历各个元素。检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
7、请你说说HashMap和Hashtable的区别
1)、区别
(1)、线程安全: HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过 synchronized 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!);
(2)、效率: 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
(3)、对Null key 和Null value的支持: HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛NullPointerException。
(4)、初始容量大小和每次扩充容量大小的不同 : ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
(5)、底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
2)、HashMap 的实现原理
HashMap概述: HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashMap的数据结构: 在Java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
HashMap 基于 Hash 算法实现的
-
当我们往Hashmap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
-
存储时,如果出现hash值相同的key,此时有两种情况。(1)如果key相同,则覆盖原始值;(2)如果key不同(出现冲突),则将当前的key-value放入链表中
-
获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
-
理解了以上过程就不难明白HashMap是如何解决hash冲突的问题,核心就是使用了数组的存储方式,然后将冲突的key的对象放入链表中,一旦发现冲突就在链表中做进一步的对比。
3)、HashMap在JDK1.7和JDK1.8中有哪些不同?HashMap的底层实现
jdk1.8之前:
在Java中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,但插入和删除容易;所以我们将数组和链表结合在一起,发挥两者各自的优势,使用一种叫做拉链法的方式可以解决哈希冲突。
JDK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。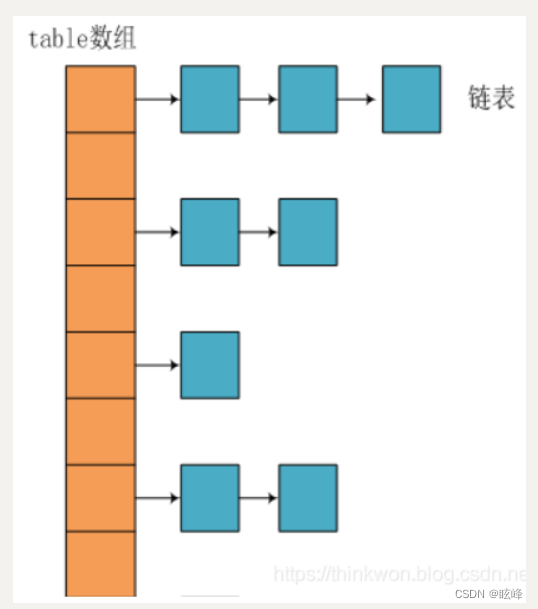
jdk1.8之后:
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时且数组的大小为64以上,才将链表转化为红黑树,以减少搜索时间。

DK1.7 VS JDK1.8 比较
JDK1.8主要解决或优化了一下问题:
-
resize 扩容优化
-
引入了红黑树,目的是避免单条链表过长而影响查询效率,红黑树算法请参考
-
解决了多线程死循环问题,但仍是非线程安全的,多线程时可能会造成数据丢失问题。

4)、HashMap的put方法的具体流程?
当我们put的时候,首先计算 key的hash值,这里调用了 hash方法,hash方法实际是让key.hashCode()与key.hashCode()>>>16进行异或操作,高16bit补0,一个数和0异或不变,所以 hash 函数大概的作用就是:高16bit不变,低16bit和高16bit做了一个异或,目的是减少碰撞。按照函数注释,因为bucket数组大小是2的幂,计算下标index = (table.length - 1) & hash`,如果不做 hash 处理,相当于散列生效的只有几个低 bit 位,为了减少散列的碰撞,设计者综合考虑了速度、作用、质量之后,使用高16bit和低16bit异或来简单处理减少碰撞,而且JDK8中用了复杂度 O(logn)的树结构来提升碰撞下的性能。
putVal方法执行流程图

5)、put()方法,1.7与1.8有何不同?
HashMap是懒惰创建数组的,首次使用才创建数组
计算索引(桶下标)
如果桶下标没人占用,创建Node占位返回
如果桶下标已经有人占用:已经是TreeNode走红黑树的添加或更新逻辑、是普通Node,走链表的添加或更新逻辑,如果链表长度超过树化阈值,走树化逻辑
返回前检查容量是否超过阈值,一旦超过进行扩容
不同:
链表插入节点时,1.7是头插法;1.8是尾插法
1.7是大于等于阈值且没有空位时才扩容,而1.8是大于阈值就扩容
1.8在计算Node索引时,会优化
6)、加载因子为何默认是0.75f
在空间占用与查询时间之间取得较好的权衡
大于这个值,空间节省了,但链表就会较长影响性能
小于这个值,冲突减少了,但扩容就会更频繁,空间占用多
7)、多线程下会有什么问题?
扩容死链(1.7)、数据错乱(1.7、1.8)
key能否为null,作为key的对象有什么要求?
HashMap的key可以为null,但Map的其他实现则不然
作为key的对象,必须实现hashCode和equals,并且key的内容不能修改(不可变)
String对象的hashCode()如何设计的,为啥每次乘的是31
目标是达到较为均匀的散列效果,每个字符串的hashCode足够独特
①.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
②.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
8)、HashMap的扩容操作是怎么实现的
①.在jdk1.8中,resize方法是在hashmap中的键值对大于阀值时或者初始化时,就调用resize方法进行扩容;
②.每次扩展的时候,都是扩展2倍;
③.扩展后Node对象的位置要么在原位置,要么移动到原偏移量两倍的位置。
在putVal()中,我们看到在这个函数里面使用到了2次resize()方法,resize()方法表示的在进行第一次初始化时会对其进行扩容,或者当该数组的实际大小大于其临界值值(第一次为12),这个时候在扩容的同时也会伴随的桶上面的元素进行重新分发,这也是JDK1.8版本的一个优化的地方,在1.7中,扩容之后需要重新去计算其Hash值,根据Hash值对其进行分发,但在1.8版本中,则是根据在同一个桶的位置中进行判断(e.hash & oldCap)是否为0,重新进行hash分配后,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上。
9)、HashMap是怎么解决哈希冲突的?
答:在解决这个问题之前,我们首先需要知道什么是哈希冲突,而在了解哈希冲突之前我们还要知道什么是哈希才行;
1、什么是哈希?
Hash,一般翻译为“散列”,也有直接音译为“哈希”的,这就是把任意长度的输入通过散列算法,变换成固定长度的输出,该输出就是散列值(哈希值);这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
所有散列函数都有如下一个基本特性:根据同一散列函数计算出的散列值如果不同,那么输入值肯定也不同。但是,根据同一散列函数计算出的散列值如果相同,输入值不一定相同**。
2、什么是哈希冲突?
当两个不同的输入值,根据同一散列函数计算出相同的散列值的现象,我们就把它叫做碰撞(哈希碰撞)。
HashMap的数据结构
在Java中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,但插入和删除容易;所以我们将数组和链表结合在一起,发挥两者各自的优势,使用一种叫做链地址法的方式可以解决哈希冲突:

这样我们就可以将拥有相同哈希值的对象组织成一个链表放在hash值所对应的bucket下,但相比于hashCode返回的int类型,我们HashMap初始的容量大小DEFAULT_INITIAL_CAPACITY = 1 << 4(即2的四次方16)要远小于int类型的范围,所以我们如果只是单纯的用hashCode取余来获取对应的bucket这将会大大增加哈希碰撞的概率,并且最坏情况下还会将HashMap变成一个单链表,所以我们还需要对hashCode作一定的优化
hash()函数
上面提到的问题,主要是因为如果使用hashCode取余,那么相当于参与运算的只有hashCode的低位,高位是没有起到任何作用的,所以我们的思路就是让hashCode取值出的高位也参与运算,进一步降低hash碰撞的概率,使得数据分布更平均,我们把这样的操作称为扰动,在JDK 1.8中的hash()函数如下:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);// 与自己右移16位进行异或运算(高低位异或)
}
这比在JDK 1.7中,更为简洁,相比在1.7中的4次位运算,5次异或运算(9次扰动),在1.8中,只进行了1次位运算和1次异或运算(2次扰动);
JDK1.8新增红黑树

过上面的链地址法(使用散列表)和扰动函数我们成功让我们的数据分布更平均,哈希碰撞减少,但是当我们的HashMap中存在大量数据时,加入我们某个bucket下对应的链表有n个元素,那么遍历时间复杂度就为O(n),为了针对这个问题,JDK1.8在HashMap中新增了红黑树的数据结构,进一步使得遍历复杂度降低至O(logn);
总结
简单总结一下HashMap是使用了哪些方法来有效解决哈希冲突的:
1. 使用链地址法(使用散列表)来链接拥有相同hash值的数据; 2. 使用2次扰动函数(hash函数)来降低哈希冲突的概率,使得数据分布更平均; 3. 引入红黑树进一步降低遍历的时间复杂度,使得遍历更快;
10)、在使用HashMap的时候,用String作为key有什么好处?
HashMap内部实现是通过key的hashCode来确定value的存储位置,因为字符串是不可变的,所以当创建字符串时,它的hashCode被缓存下来的,不需要再次计算,所以相比于其他对象更快。
8、HashMap是线程安全的吗?如果不是该如何解决?
HashMap是非线程安全的,在多线程环境下,多个线程同时触发HashMap的改变时,有可能会发生冲突。所以,在多线程环境下不建议使用HashMap。想要使用线程安全的HashMap,一共有三种办法:
使用Hashtable、
使用Collections将HashMap包装成线程安全的HashMap、
使用ConcurrentHashMap,其中第三种方式最为高效,是我们最推荐的方式。
Hashtable: HashMap和Hashtable都是典型的Map实现,而Hashtable是线程安全的。虽然这算是一个可选方案,但却是不推荐的方案。因为Hashtable是一个古老的API,从Java 1.0开始就出现了,它的同步方案还不成熟、性能不好,甚至官方都给出了不推荐使用的建议。
Collections: Collections类中提供了synchronizedMap()方法,可以将我们传入的Map包装成线程同步的Map。除此以外,Collections还提供了如下三类方法来返回一个不可变的集合,这三类方法的参数是原有的集合对象,返回值是该集合的“只读”版本。通过Collections提供的三类方法,可以生成“只读”Map。 emptyMap():返回一个空的不可变的Map对象。 singletonMap():返回一个只包含指定键值对的不可变的Map对象。 unmodifiableMap() :返回指定Map对象的不可变视图。
ConcurrentHashMap: ConcurrentHashMap是线程安全且高效的HashMap,并且在JDK 8中进行了升级,使其在JDK 7的基础上进一步降低了锁的粒度,从而提高了并发的能力。 在JDK 7中ConcurrentHashMap的底层数据结构为“数组+链表”,但是为了降低锁的粒度,JDK7将一个Map拆分为若干子Map,每一个子Map称为一个段。多个段之间是相互独立的,而每个段都包含若干个槽,段中数据发生碰撞时采用链表结构解决。在并发插入数据时,ConcurrentHashMap锁定的是段,而不是整个Map。因为锁的粒度是段,所以这种模式也叫“分段锁”。另外,段在容器初始化的时候就被确定下来了,之后不能更改。而每个段是可以独立扩容的,各个段之间互不影响,所以并不存在并发扩容的问题。 在JDK8中ConcurrentHashMap的底层数据结构为“数组+链表+红黑树”,但是为了进一步降低锁的粒度,JDK8取消了段的设定,而是直接在Map的槽内存储链表或红黑树。并发插入时它锁定的是头节点,相比于段头节点的个数是可以随着扩容而增加的,所以粒度更小。引入红黑树,则是为了在冲突剧烈时,提高查找槽内元素的效率。
9、Java反射详解篇
1)、反射概述
java程序在运行时操作类中的属性和方法的机制,称为反射机制。
一个关键点:运行时
一般我们在开发程序时,都知道自己具体用了什么类,直接创建使用即可。但当你写一些通用的功能时没办法在编写时知道具体的类型,并且程序跑起来还会有多种类型的可能,则需要在运行时动态的去调用某个类的属性和方法,这就必须使用反射来实现。
例子说明:
Father f = new Children();编译时变量f 为Father类型,运行时为Children类型;
public void demo(Object obj){ // 不知道调用者传什么具体对象 ……}
编译时demo方法参数类型为Object,一般有两种做法:
第一种做法是知道参数类型有哪几种情况,可以使用instanceof运算符进行判断,再利用强制类型转换将其转换成其运行时类型的变量即可。
第二种做法是编译时根本无法预知该对象和类可能属于哪些类,程序只依靠运行时信息动态的来发现该对象和类的真实信息,这就必须使用反射。
那反射是怎么做到在运行时获取类的属性和方法的呢?
理解类的加载机制的应该知道,当java文件编译成.class文件,再被加载进入内存之后,JVM自动生成一个唯一对应的Class对象,这个Class是一个具体的类,这个Class类就是反射学习的重点。反射的操作对象就是这个Class类,通过Class类来获取具体类的属性和方法。
2)、Class类
Class 类是用于保存类或接口属性和方法信息的类,就是保存类信息的类,它类名称就叫 Class。
2.1、理解Class类
Class类和构造方法源码:
public final class Class<T> implements java.io.Serializable,
GenericDeclaration,
Type,
AnnotatedElement {
private Class(ClassLoader loader) {
// Initialize final field for classLoader. The initialization value of non-null
// prevents future JIT optimizations from assuming this final field is null.
classLoader = loader;
}
}简单分析下Class类:
-
Class类和String类都是被final关键字修饰的类,是不可以被继承的类;
-
Class类支持泛型T,也就是说在编写程序时可以做到:反射 + 泛型;
-
Class类实现了序列化标记接口Serializable,既是Class类可以被序列化和反序列化;
-
Class类不能被继承,同时唯一的一个构造器还是私有的,因为设计之初就是让JVM在类加载后传入ClassLoader对象来创建Class对象(每个类或接口对应一个JVM自动生成Class对象),开发人员只是调用Class对象,并没有直接实例化Class的能力。
Class对象的创建是在加载类时由 Java 虚拟机以及通过调用类加载器中的defineClass 方法自动构造的,关于类的加载可以通过继承ClassLoader来实现自定义的类加载器,本文着重讲反射,在此不展开讲类加载相关知识。
2.2、获取Class对象的三种方式
方式一:常用方式,Class.forName("包名.类名")
public static void main(String[] args) {
// 方式一:全限定类名字符串
Class<?> childrenClass = null;
try {
childrenClass = Class.forName("com.yty.fs.Children");
// 包名.类名
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
// 获取类名称
System.out.println("全限定类名="+childrenClass.getName());
}
//执行结果:全限定类名=com.yty.fs.Children方式二:每个类下的静态属性 class,类名.class
public static void main(String[] args) {
// 方式二:每个类下的静态属性 class
Class<Children> childrenClass = Children.class;
System.out.println("类名称="+childrenClass.getSimpleName());
}
//执行结果:类名称=Children方式三:每个类最终都继承了Object,Object类下的getClass()
public static void main(String[] args) {
// 方式三:Object类下的getClass()
Children children = new Children();
Class<?> childrenClass3 = children.getClass();
System.out.println("类所在包="+childrenClass3.getPackage());
}
//执行结果:类所在包=package com.example.boot_redis01.leetcode三种方式简单对比:
-
方式一通过全限定类名字符串既可以获取,其他两种方式都要导入类Children才可以;
-
方式二获取的Class不需要强转即可获得指定类型Class,其他两种方式获得的都是未知类型Class<?>;
-
方式三通过实例化对象的Object中的方法获取,其他两种都不需要实例化对象。
怎么选:
-
有全限定类名字符串,没有具体的类可以导入的只能选方式一;
-
有具体类导入没有实例化对象的使用方式二;
-
作为形参使用的使用方式三,通过形参引用来获取Class。
案例一:构造方法、成员变量和成员方法的获取和使用
Children类:
public class Children {
public String testString; //测试用
private int id;
private String name;
// 无参构造方法
public Children() {
System.out.println("====无参构成方法被调用");
}
// 多个参数构造方法
public Children(int id, String name) {
this.id = id;
this.name = name;
}
// default构造方法--测试
Children(String name, int id){
this.id = id;
this.name = name;
}
// 受保护构造方法--测试
protected Children(int id) {
this.id = id;
}
// 私有构造方法--测试
private Children(String name) {
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Children{ id=" + id + ", name=" + name + "}";
}
public void printName(){
System.out.println("====printName--"+this.name);
}
public void printName(String name){
this.name = name;
System.out.println("====printName--"+this.name);
}
private void demoTest(){
System.out.println("====demoTest--执行了");
}
}Demo1测试类:
/** * 案例一:构造方法、成员变量和成员方法的获取和使用 */
public class Demo1 {
public static void main(String[] args) throws Exception {
Class<?> chilrenClass = Class.forName("com.yty.fs.Children");
// 1.构造方法操作
// 1.1.获取所有构造方法
// System.out.println("1.构造方法操作\n1.1.所有构造方法");
Constructor<?>[] declaredConstructors = chilrenClass.getDeclaredConstructors();
for (Constructor constructor : declaredConstructors){
System.out.println(constructor.toString());
// Constructor类的toString已重写
}
// 1.2.获取所有public构造方法
// System.out.println("1.2.所有public构造方法");
Constructor<?>[] constructors = chilrenClass.getConstructors();
for(Constructor constructor : constructors){
System.out.println(constructor.toString());
}
// 1.3.获取无参构造方法
Constructor<?> onParamConstructor = chilrenClass.getConstructor();
//参数类型为null,表示无参
System.out.println("1.3.无参构造方法:\n"+onParamConstructor.toString());
// 实例化对象
Object o = onParamConstructor.newInstance();
if(o instanceof Children){
Children children = (Children)o;
children.setId(111);
children.setName("myName");
System.out.println(o.toString());// Children类重写了toString
}
// 1.4.获取单个私有构造方法
// 指定了私有构造方法的参数类型,所以只会获取到一个构造方法
Constructor<?> privateConstructor = chilrenClass.getDeclaredConstructor(String.class);
System.out.println("1.4.单个私有构造方法:\n"+privateConstructor.toString());
//私有构造方法需要取消访问权限检查,否则报异常:IllegalAccessExceptionw
privateConstructor.setAccessible(true);
Object obj = privateConstructor.newInstance("myName");
System.out.println(o.toString());
// 2.字段操作(成员变量)
// 2.1.获取所有成员变量
System.out.println("2.字段操作(成员变量)\n2.1.获取所有成员变量");
Field[] declaredFields = chilrenClass.getDeclaredFields();
for (Field declaredField : declaredFields){
// 获取fieldName
System.out.println(declaredField.getName());
}
// 2.2.获取所有公共成员变量
System.out.println("2.2.获取所有公共成员变量");
Field[] fields = chilrenClass.getFields();
for (Field field : fields){
// 获取fieldName
System.out.println(field.getName());
}
// 2.3.获取单个公共成员变量
System.out.println("2.3.获取单个公共成员变量");
Field field = chilrenClass.getField("testString");
Object o1 = chilrenClass.getConstructor().newInstance();
field.set(o1,"yty");
Object o1_1 = field.get(o1);
// 获取fieldName
System.out.println("成员变量名-值:"+field.getName()+"="+o1_1.toString());
// 2.4.获取单个私有成员变量
System.out.println("2.4.获取单个私有成员变量");
Field field2 = chilrenClass.getDeclaredField("name");
//私有成员变量需要取消访问权限检查,否则报异常:IllegalAccessExceptionw
field2.setAccessible(true);
Object o2 = chilrenClass.getConstructor().newInstance();
field2.set(o2,"myName");
Object o2_2 = field2.get(o2);
// 获取fieldName
System.out.println("成员变量名-值:"+field2.getName()+"="+o2_2.toString());
// 3.方法操作(成员方法)
// 3.1.获取所有方法(成员方法)
System.out.println("3.方法操作(成员方法)\n3.1.获取所有方法--不会获取父类的方法");
Method[] declaredMethods = chilrenClass.getDeclaredMethods();
for (Method method : declaredMethods){
// 获取方法名
System.out.println(method.getName());
}
// 3.2.获取所有公共方法 S
// ystem.out.println("3.2.获取所有公共方法--会获取父类的方法");
Method[] methods = chilrenClass.getMethods();
for (Method method : methods){
// 获取方法名
System.out.println(method.getName());
}
// 3.3.获取单个公共方法
System.out.println("3.3.获取单个公共方法\n3.3.1.获取单个公共方法--无参方法");
Method printName = chilrenClass.getMethod("printName");
//方法名称
System.out.println(printName);
System.out.println("3.3.2.获取单个公共方法--有参方法");
Method printName2 = chilrenClass.getMethod("printName",String.class);
//方法名称,参数类型
System.out.println("参数个数:"+printName2.getParameterCount());
// 遍历所有参数信息
Parameter[] parameters = printName2.getParameters();
for (int i=0;i<printName2.getParameterCount();i++){
Parameter param = parameters[i];
if(param.isNamePresent()){
System.out.println("第"+ (i+1) +"个参数信息");
System.out.println("参数类型="+param.getType());
System.out.println("参数名称="+param.getName());
}
}
// 使用有参方法
Object o3 = chilrenClass.getConstructor().newInstance();
printName2.invoke(o3,"myName");
//传入参数值、执行方法
// 3.4.获取单个私有方法
System.out.println("3.4.获取单个私有方法");
Method demoTest = chilrenClass.getDeclaredMethod("demoTest");
// 使用私有无参方法
Object o4 = chilrenClass.getConstructor().newInstance();
demoTest.setAccessible(true);
demoTest.invoke(o4);
}
}10、什么是java序列化?什么情况下需要序列化?
序列化就是一种用来处理对象流的机制。将对象的内容流化,将流化后的对象传输与网络之间。
序列化是通过实现serializable接口,该接口没有需要实现的方法,implement Serializable只是为了标注该对象是可被序列化的,使用一个输出流(FileOutputStream)来构造一个ObjectOutputStream对象,接着使用ObjectOutputStream对象的writeObject(Object Object)方法就可以将参数的obj对象到磁盘,需要恢复的时候使用输入流。
序列化是将对象转换为容易传输的格式的过程。
一般程序在运行时,产生对象,这些对象随着程序的停止而消失,但我们想将某些对象保存下来,这时,我们就可以通过序列化将对象保存在磁盘,需要使用的时候通过反序列化获取到。
对象序列化的最主要目的就是传递和保存对象,保存对象的完整性和可传递性。
比如通过网络传输或者把一个对象保存成本地一个文件的时候,需要使用序列化。
11、请你说说hashCode()和equals()的区别,为什么重写equals()就要重写hashcod()?
hashCode()方法主要用途是获取哈希码,equals()主要用来比较两个对象是否相等。二者之间有两个约定,如果两个对象相等,他们必须有相同的哈希码;但如果两个对象的的哈希码相同,它们却不一定相等。也就是说,equals()比较两个对象相等时hashCode()一定相等,hashCode()相等的两个对象equals()不一定相等。
Object类提供的equals()方法默认是用==来进行比较的,也就是说只有两个对象是同一个对象时才能返回相等的结果。而实际的业务中,我们通常的需求是若两个不同的对象它们的内容相同的,就认为它们相等。鉴于这种情况,Object类中的equals()方法的默认实现是没有实用价值的,所以通常都要重写。由于hashCode()和equals()具有联动关系,所以equals()方法重写时,通常也要将hashcode()方法进行重写,使得这两个方法时钟满足相关的规定。
12、ConcurrentHashMap原理,jdk7和jdk8的区别?
HashTable采用的是在所有的方法上加了一个synchronized锁,synchronized是一个全局锁,ConcurrentHashMap采用的分段锁
1)、jdk1.8currentHashMap
(1)、数据结构:synchronized+CAS+Node+红黑树,Node的val和next都用volatile修饰,保证可见性,查找替换赋值操作都是用CAS
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
(2)、锁:锁链表的head节点,不影响其他元素的读写,效率更高,扩容时,阻塞所有的读写操作,并发扩容
读操作无锁:Node的val和next使用volatile修饰,读写线程对变量互相可见
数组用volatile修饰,保证扩容时被读线程感知
(3)、在JDK1.8中,放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
jdk7的ConcurrentHashMap底层结构是Segment数组,可以在初始化的时候指定Segment数组的长度,并且不可变。而Segment继承了ReentrantLock,它存储数据的实现与HashMap很像。也就是说jdk7的ConcurrentHashMap可以看成是由线程安全的HashMap组成的一个map数组,数组的长度决定了支持的最大的并发量。
jdk8的ConcurrentHashMap的底层结构与HashMap又一样了,底层是一个Node的数组,而通过对Node数组以CAS方式实现扩容和对Node数组的每个元素的synchronized保证ConcurrentHashMap整体的线程安全。
jdk8在链表数组结构上进行了优化,与HashMap在jdk8的优化一样,当链表长度达到8的时候会把链表转成红黑树,能够提高查找性能。

Java 8 数组(Node) +( 链表 Node | 红黑树 TreeNode ) 以下数组简称(table),链表简称(bin) 初始化,使用 cas 来保证并发安全,懒惰初始化 table 树化,当 table.length < 64 时,先尝试扩容,超过 64 时,并且 bin.length > 8 时,会将链表树化,树化过程 会用 synchronized 锁住链表头 put,如果该 bin 尚未创建,只需要使用 cas 创建 bin;如果已经有了,锁住链表头进行后续 put 操作,元素 添加至 bin 的尾部 get,无锁操作仅需要保证可见性,扩容过程中 get 操作拿到的是 ForwardingNode 它会让 get 操作在新 table 进行搜索 扩容,扩容时以 bin 为单位进行,需要对 bin 进行 synchronized,但这时妙的是其它竞争线程也不是无事可 做,它们会帮助把其它 bin 进行扩容,扩容时平均只有 1/6 的节点会把复制到新 table 中 size,元素个数保存在 baseCount 中,并发时的个数变动保存在 CounterCell[] 当中。最后统计数量时累加 即可
2)、jdk1.7concurrentHashMap
(1)、数据结构:ReentrantLock+Segment+HashEntry,一个Segment中包含一个HashEntry数组,每个HashEntry又是一个链表结构
(2)、元素查询:第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部
(3)、锁:Segment分段锁Segment继承了ReentrantLock,锁定操作的Segment,其他的Segment不受影响,并发度为segment个数,可以通过构造函数指定,数组扩容不会影响到其他的segment
get方法无需加锁,volatile保证
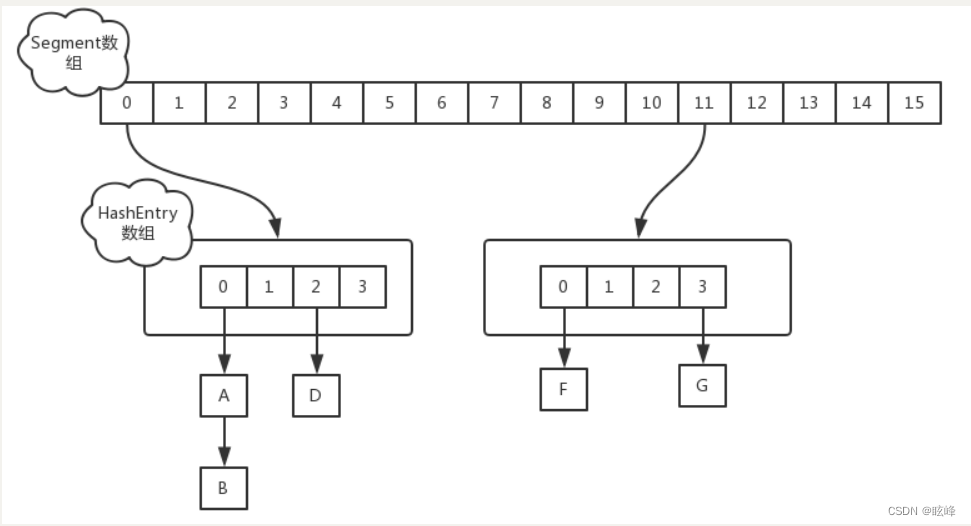
该类包含两个静态内部类 HashEntry 和 Segment ;前者用来封装映射表的键值对,后者用来充当锁的角色;
Segment 是一种可重入的锁 ReentrantLock,每个 Segment 守护一个HashEntry 数组里得元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 锁。Segement数组在创建以后它的大小是不会改变的,改变的只是HashEntry数组的大小,当大小大于阈值0.75以后。对于currentHashMap1.7来说一调用的构造方法,它的数组就被创建了,但是currentHashMap1.8是在第一次放入元素的时候,底层数组才会被创建

它维护了一个 segment 数组,每个 segment 对应一把锁 优点:如果多个线程访问不同的 segment,实际是没有冲突的,这与 jdk8 中是类似的 缺点:Segments 数组默认大小为16,这个容量初始化指定后就不能改变了,并且不是懒惰初始化

可以看到 ConcurrentHashMap 没有实现懒惰初始化,空间占用不友好 其中 this.segmentShift(移位属性) 和 this.segmentMask(掩码属性) 的作用是决定将 key 的 hash 结果匹配到哪个 segment 例如,根据某一 hash 值求 segment 位置,先将高位向低位移动 this.segmentShift 位

13、什么是字节码?采用字节码有什么好处?
1)、JDK > JRE > JVM
jdk是java的开发环境,jre是java程序的运行环境,jvm它是整个java实现跨平台的最核心的部分,所有的java程序会首先被编译为.class的类文件,这种类文件可以在虚拟机上执行。
也就是说class并不直接与机器(windows操作系统)的操作系统相对应,而是经过虚拟机简介与操作系统交互,而虚拟机将程序解释给本地系统执行。
只有jvm还不能成class的执行,因为在解释class的时候jvm需要调用解释所需要的类库lib,而jre包含lib类库。
jvm屏蔽了与具体操作系统平台相关的信息,使得java程序只需在java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。
2)、字节码
JVM:一种能够运行Java字节码(Java bytecode)的虚拟机。
字节码:字节码是已经经过编译,但与特定机器码无关,需要解释器转译后才能成为机器码的中间代码。
Java字节码:是Java虚拟机执行的一种指令格式。
字节码就是经过java的编译器(javac前端编译器)编译成java虚拟机可以执行的一种指令代码(java字节码),然后再经过java的解释器把字节码解释给机器操作系统去执行。

3)、采用字节码的好处
java语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了语言可移植性的特点。所以java程序运行时比较高效,而且,由于字节码并不专门针对一种特定的机器,因此,java程序无需重新编译便可在多种不同的计算机上运行。
14、为什么要使用克隆?如何实现对象克隆?深拷贝和浅拷贝的区别是什么?
(1)、为什么要克隆?
想对一个对象进行复制,又想保留原有的对象进行接下来的操作,这个时候就需要克隆了。
(2)、如何实现克隆?
实现Cloneable接口,重写clone方法
实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深克隆。
Beautils,apache和Spring都提供了bean工具,只是这都是浅克隆
(3)、深拷贝和浅拷贝区别是什么?
浅拷贝:仅仅克隆基本类型变量,不克隆引用类型变量

深克隆:既克隆基本类型变量,又克隆引用类型变量

博客:https://www.jianshu.com/p/8747bc5406b2
实例化对象有哪几种方式
new、clone()、通过反射机制创建、序列化和反序列化
15、请说说你对Java集合的了解
java中的集合类分为4大类,分别由4个接口来代表,它们是Set、list、Queue、Map。其中Set、List、Queue都继承自Collection接口。Set代表无序的、元素不可重复的集合。List代表有序的、元素可以重复的集合。Queue代表先进先出(FIFO)队列。Map代表具有映射关系(key-value)的集合。
Java提供了众多集合的实现类,它们都是这些接口的间接或直接的实现类,其中比较常用的有:HashSet、TreeSet、ArrayList、LinkedList、ArrayQueue、HashMap、TreeMap等。上述的集合类的接口或实现,都位于java.util包下,这些实现大多数都是非线程安全的。虽然非线程安全,但是这些类的性能较好。如果需要使用线程安全的集合类,则可以利用Collections工具类,该工具类提供的synchronizedXXX()方法,可以将这些集合类包装成线程安全的集合类。java.util包下的集合类中,也有少数的线程安全的集合类,例如Vector、HashTable,他们都是非常古老的API。虽然它们是线程安全的额,但是性能很差,已经不推荐使用了。从JDK1.5开始,并发包下新增了大量高效的并发的容器,这些容器按照实现机制可以分为三类:
第一类是以降低锁粒度来提高并发性能的容器,它们的类名以Concurrent开头,如ConcurrentHashMap。
第二类是采用写时复制技术实现的并发容器,它们的类名以CopyOnWrite开头,如CopyOnWriteArrayList
第三类是采用Lock实现的阻塞队列,内部创建两个Condition分别用于生产者和消费者接口的等待,这些类都实现了BlockingQueue接口,如ArrayBlockingQueue。
16、HashMap是线程安全的吗?如果不是该如何解决?
HashMap是非线程安全的,在多线程环境下,多个线程同时触发HashMap的改变时,有可能会发生冲突。所以,在多线程环境下不建议使用HashMap。想要使用线程安全的HashMap,一共有三种办法:
使用Hashtable、
使用Collections将HashMap包装成线程安全的HashMap、
使用ConcurrentHashMap,其中第三种方式最为高效,是我们最推荐的方式。
Hashtable: HashMap和Hashtable都是典型的Map实现,而Hashtable是线程安全的。虽然这算是一个可选方案,但却是不推荐的方案。因为Hashtable是一个古老的API,从Java 1.0开始就出现了,它的同步方案还不成熟、性能不好,甚至官方都给出了不推荐使用的建议。
Collections: Collections类中提供了synchronizedMap()方法,可以将我们传入的Map包装成线程同步的Map。除此以外,Collections还提供了如下三类方法来返回一个不可变的集合,这三类方法的参数是原有的集合对象,返回值是该集合的“只读”版本。通过Collections提供的三类方法,可以生成“只读”Map。 emptyMap():返回一个空的不可变的Map对象。 singletonMap():返回一个只包含指定键值对的不可变的Map对象。 unmodifiableMap() :返回指定Map对象的不可变视图。
ConcurrentHashMap: ConcurrentHashMap是线程安全且高效的HashMap,并且在JDK 8中进行了升级,使其在JDK 7的基础上进一步降低了锁的粒度,从而提高了并发的能力。 在JDK 7中ConcurrentHashMap的底层数据结构为“数组+链表”,但是为了降低锁的粒度,JDK7将一个Map拆分为若干子Map,每一个子Map称为一个段。多个段之间是相互独立的,而每个段都包含若干个槽,段中数据发生碰撞时采用链表结构解决。在并发插入数据时,ConcurrentHashMap锁定的是段,而不是整个Map。因为锁的粒度是段,所以这种模式也叫“分段锁”。另外,段在容器初始化的时候就被确定下来了,之后不能更改。而每个段是可以独立扩容的,各个段之间互不影响,所以并不存在并发扩容的问题。 在JDK8中ConcurrentHashMap的底层数据结构为“数组+链表+红黑树”,但是为了进一步降低锁的粒度,JDK8取消了段的设定,而是直接在Map的槽内存储链表或红黑树。并发插入时它锁定的是头节点,相比于段头节点的个数是可以随着扩容而增加的,所以粒度更小。引入红黑树,则是为了在冲突剧烈时,提高查找槽内元素的效率。
17、请说说static修饰符的用法
java类中包含了成员变量、方法、构造器、初始化和内部类(包括接口、枚举)5种成员,static关键字可以修饰除了构造器之外的其他四种成员。
static关键字修饰的成员被称为类成员,类成员属于整个类,不属于单个对象。static关键字有一条非常重要的规则,即类成员不能访问实例成员,因为类成员属于类的,类成员的作用域比实例成员的作用域更大,很容易出现类成员初始化完成时,但实例成员还没被初始化,这时如果类成员访问实例成员就会引起大量错误。
static修饰的部分会和类同时加载。被static修饰的成员先于对象存在,因此,当一个类加载完毕,即使没有创建对象也可以去访问static修饰的部分。静态方法中没有this关键词,因为静态方法是和类同时加载的,而this是随着对象的创建存在的。静态比对象优先存在。也就是说,静态可以访问静态,但静态不能访问非静态而非静态可以访问静态。
18、实现单点登录的三种方式
出现的原因
在早期的互联网业务中,一般是使用单一服务器模式。但随着互联网的飞速发展,互联网用户的体量不断增大,单一服务器模式存在单点性能压力,无法扩展,以及单点失效等问题,已经不适合如今的互联网业务了,因此更多的,我们现在一般采用分布式微服务的架构来搭建项目。分布式的项目架构大致如下:

采用分布式的架构后,为了避免出现用户在一个模块登录后,访问别的模块时还需要重新登录的问题,我们需要使用单点登录(single sign on SSO)的模式来实现用户登录功能,这样用户只需要在一个模块登录后,访问其他模块就无需重复登录了。一般来说,实现单点登录主要有以下三种方式:
session广播机制实现
在用户登录了一个模块后,这个模块的服务器会将用户的登录信息保存在本机的session中,然后通过session的广播机制,将这台服务器session中的内容复制到其他模块所在服务器的session中,这样其他的模块也就得到了用户的登录信息,用户在访问其他模块时就不需要重复登录了。
但这种模式会多次复制session中的内容,造成用户数据的冗余存储,因此并不推荐使用这种方式实现单点登录。
使用cookie+redis实现
用户在项目的任意一个模块登录后,该模块会将用户的登录信息放到redis和cookie中。
1)、系统会先将用户的登录信息存入redis中,其在redis 的key值是生成的唯一值(可以包含IP、用户id、UUID等值),value值存放用户的登录信息。
2)、然后系统会将这名用户在redis中的key值存入该用户的cookie中,用户每次访问任意模块时都会带着这个cookie。
3)、用户在访问其他模块发送请求时,都会带着客户端的cookie进行请求,而客户端的cookie已经存入了该用户在redis中的key值,这样其他模块在处理用户的请求时,可以先获取用户cookie中的key值,然后拿着这个key值到redis中进行查询,如果在redis中能查询到该用户相应的登录信息,就说明该用户已登录,就不需要用户进行重复登陆了。
使用token实现
token是按照一定规则生成的字符串,字符串中可以包含用户信息。开发人员可以自行定制这个生成规则,也可以使用提供好的生成规则(如使用JWT自动生成包含用户信息的字符串)。
1)、用户在项目的某个模块进行登录后,系统会按照一定的规则生成字符串,把用户登录之后的信息包含到这个生成的字符串中,然后系统可以将这个字符串返回,主要有两种返回方式:可以把字符串通过cookie返回;可以把字符串通过地址栏返回。
2)、这样用户在访问其他的模块时,每次访问的地址栏都会带着生成的字符串(或者 cookie 中带着生成的字符串),被访问模块就可以获取地址栏中的生成字符串(或者获取 cookie 中的生成字符串),然后根据字符串获取用户信息,如果可以获取到用户的登录信息,说明该用户已登录,用户就不需要重复登录了。
1)、jwt与token的区别
token和jwt都是用来访问资源的令牌凭证,需要验证来确定身份信息。
Token:服务端验证客户端发送过的Token时,还需要查询数据库或者缓存获取用户信息,然后验证Token是否有效。
Jwt:将Token和Payload加密后存储于客户端,服务端只需要使用秘钥解密进行校验(校验也是JWT自己实现的)即可,不需要查询或者减少查询数据库,因为JWT自包含了用户信息和加密的数据。因此减少了需要查询数据库的需要
2)、Token
token的验证机制流程
用户输入账户和密码信息请求服务器;服务器验证用户信息,返回用户一个token值;客户端存储token值,在每次请求都提交token值;服务器根据token验证用户信息,验证通过后返回请求结果;token必须要在每次请求时传递给服务端,都保存在header中。
3)、JWT
jwt是什么?
JWT是一种用于双方之间传递安全信息的简洁的、URL安全的表述性声明规范。JWT作为一个开放的标准(RFC 7519),定义了一种简洁的,自包含的方法用于通信双方之间以Json对象的形式安全的传递信息。因为数字签名的存在,这些信息是可信的,JWT可以使用HMAC算法或者是RSA的公私秘钥对进行签名。
jwt的结构
jwt会生成一个类似于字符串的一串数字,包括三个部分,每个部分之间使用"."隔开。三个部分分别是Header(头部)、Payload(负载)、Signature(签名)。顺序是header.payload.signature
jwt的认证流程

用户输入用户名密码登录,服务端认证成功后,会返回给客户端一个JWT;客户端将token保存到本地;当用户希望访问一个受保护的路由或者资源的时候,需要请求头的Authorization字段中使用Bearer模式添加JWT。
JWT的详细了解:不会吧,不会吧,不会还有人看了这篇文章还不精通JWT吧_钱难有~的博客-CSDN博客
19、以“HashSet”如何检查重复为例子来说明为什么要有HashCode?
对象加入HashSet时,HashSet会计算对象的HashCode值来判断对象加入的位置,看该位置是否有值,如果没有、HashSet会假设它没有出现过,但是如果有值,这时就会调用equals方法来比较两个对象是否真的相同,如果两者相同,HashSet就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样就大大减少了equals的次数,相应的就大大提高了执行速度。
如果两个对象相同,则HashCode一定是相同的
两个对象相等,对两个对象分别调用equals方法都返回true
两个对象有相同的hashCode值,它们也不一定是相等的
因此,equals()方法被覆盖过,则HashCode方法也必须被覆盖
HashCode()的默认行为是对堆上的对象产生独特值,如果没有重写HashCode(),则该class的两个对象无论如何都不会相等
20、Java集合的快速失败机制“fail-fast”?
是java集合的一种错误检测机制,当多个线程对集合进行结构上的改变的操作时,有可能会产生fail-fast机制。
例如:假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会抛出ConcurrentModificationException异常,从而产生fail-fast机制。
原因:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个modCount变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hahsNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodeCount值,是的话就返回遍历;否则跑出异常,终止遍历。
解决办法:在遍历过程中,所有涉及到改变MODCOunt值得地方全部加上synchronized。
使用CopyOnWriteArrayList来替换ArrayList。
21、获取Class对象有几种方式
调用某个对象的getClass()方法、调用某个类的class属性来获取对应的Class对象、使用Class类中的forName()静态方法。
二、JVM
1、jvm的内存结构

1)、pc寄存器
什么是程序计数器(PC寄存器)?
PC寄存器是用来存储指向下一条指令的地址,由执行引擎读通过指令地址读取下一条指令。 在java虚拟机中每个线程都有自己的PC寄存器,是线程私有的,生命周期与线程的生命周期一致。
为什么使用程序计数器记录当前线程的执行地址?
由于CPU需要不停地切换各个线程,那么切换回来以后,我们需要通过PC寄存器中的指令地址明确从哪里继续执 行。jvm的字节码解释器就需要通过改变PC寄存器的值来明确下一条应该执行什么样的字节码指令。
由于Java虚拟机的多线程是通过线程轮流切换、分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器都只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
存器的值来明确下一条应该执行什么样的字节码指令。
为了能够准确的记录各个线程正在执行的当前字节码指令的地址,将每一个线程都分配一个PC寄存器,这样一来各个线程间就可以独立计算,不会相互干扰。
2)、虚拟机栈

java虚拟机栈也叫作java栈,每一个线程在创建时都会创建一个虚拟机栈,其内部保存着一个个的栈帧,对应着一 次次的java方法的调用。
在java虚拟机中每个线程都有自己的栈,栈中的数据都是以栈帧的格式存在的,栈帧是一个内存区块,是一个数据集,维持着方法执行过程中的各种数据信息
每个栈帧中都存储着 局部变量表 操作数栈 动态链接 方法返回地址 一些附加信息
虚拟机栈不存在GC垃圾回收,但是会出现Error
JVM为何选择基于栈的指令集架构?
由于Java的跨平台性,java虚拟机的指令都是根据栈(栈指的是栈帧中的操作数栈)来设计的,由于不同平台的 CPU架构不同,不能设计为基于寄存器的。
局部变量表
局部变量表定义为一个数字数组,主要用于存储方法参数和定义在方法体内的局部变量,局部变量表所需的容量是在编译期确定下来的,在运行期间是不会改变的,局部变量表中的变量只在当前方法调用中有效,当方法调用结束后,随着栈帧的销毁,局部变量表也会被销毁。
操作数栈
操作数栈,主要用于保存计算过程中的中间结果,同时作为计算过程中变量临时的存储空间。操作数栈所需的最大深度在编译期就定义好了,刚开始方法的操作栈是空的。栈是可以通过链表和数组实现的,我们的操作数栈是通过数组实现的。但是操作数栈并非可以采用访问索引的方式,来进行数据访问,只能通过传统的入栈和出栈操作完成数据访问。
动态连接
动态链接(指向运行时常量池的方法引用):每个栈帧内部都包含一个指向运行时常量池中该栈帧所属方法的引 用。

方法返回地址

在Java虚拟机规范中,对这个内存区域规定了两类异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;如果Java虚拟机栈容量可以动态扩展,当栈扩展时无法申请到足够的内存会抛出OutOfMemoryError异常。
3)、堆
存在GC,也存在Error == > 堆是垃圾回收器执行垃圾回收的重点区域
一个JVM实例只存在一个堆内存,堆也是java内存管理的核心区域。java堆区在JVM启动的时候就被创建,其内存大小也就确定了。堆内存的大小是可以通过参数调节的。在方法结束后,堆中的对象实例不会立马被移除,仅仅在垃圾收集的时候才会被移除。
堆空间的划分
堆区进一步细分的话分为:年轻代(YongGen)和老年代(OldGen),其中年轻代又可以划分为Eden空间、Survivor0空间和Survivor1空间。

对象在堆中的存放过程

过程描述:
①通常来说,new的新对象会放在Eden区
②当Eden满的时候会触发第一次YoungGC,通过可达性分析算法判断对象是否为垃圾,若为垃圾则被垃圾回收器 回收,然后剩余的对象将进入幸存者区(to区:谁为空则为to),此时年龄计数器为1 ③当Eden区再次满的时候再次触发YoungGC,此时垃圾回收器回收Eden区和幸存者区的垃圾(幸存者区被动触发 垃圾回收,并且幸存者区只能被动触发,即使满了也不会主动触发YoungGC),剩余对象(Eden区和幸存者from 区)进入幸存者to区,各个对象的年龄计数器加一
④当幸存者区的对象的年龄计数器达到阈值(默认为15,可通过参数设置)时,该对象进入老年代
注意:Yang GC :只有Eden区满的才会触发,幸存者区满的时候不会触发
4)、方法区
Hotspot虚拟机中方法区的变化:

jdk1.6及之前:有永久代(permanent generation),静态变量放在永久代上
jdk1.7:有永久代,但已经逐步“去永久代”,字符串常量池、静态变量移出,保存在堆中
jdk1.8及之后:无永久代,类型信息、字段、方法、常量保存在本地内存的元空间,但字符串常量池、静态变量仍在堆中
永久代为什么被元空间替代?
1.为永久代设置空间大小很难确定
2.对永久代调优很困难
方法区的垃圾收集主要是:常量池中废弃的常量和不再使用类型
2、什么是类加载器?类加载器有哪些?
类加载器就是把类文件加载到虚拟机中,也就是说通过一个类的全限定名来获取描述该类的二进制字节流。
jdk自带有三个类加载器:bootstrap ClassLoader(系统类加载器)、ExtClassLoader(扩展类加载器)、APPClassLoader(应用程序类加载器)
BootstrapClassLoader是ExtClassLoader的父类加载器,默认负责加载%JAVA_HOME%lib下的jar包和class文件
ExtClassLoader是AppClassLoader的父类加载器,负责加载%JAVA_HOME%/lib/ext文件夹下的jar包和class类。
APPClassLoader是自定义加载器的父类,负责加载classpath下的类文件。系统类加载器,线程上下文加载器
继承ClassLoader实现自定义类加载器,如果想要满足java虚拟机的双亲委派机制的话,需要执行自定义类的加载器的父类为AppClassLoader
3、什么是双亲委派机制?

双亲委派机制的优点:
可以防止内存中出现多份同样的字节码,如果没有双亲委派模型而是由各个类加载器字形加载的话,如果用户编写了一个java.lang.Object同名类放在classpath中,多个类加载器都去加载这个类到内存,系统中将会出现多个不同的Object类,那么类之间的比较结果及类的唯一性将无法保证,而且如果不使用这种双亲委派模型将会给虚拟机的安全带来隐患。所以,要让类对象进行比较有意义,前提是他们要被同一个类加载器加载。
主要是为了安全性,避免用户自己编写的类动态替换java的一些核心类,比如String
同时也避免了类的重复加载,因为jvm中区分不同的类,不仅仅是根据类名,相同的class文件被不同的ClassLoader加载的就是不同的两个类。
沙箱安全机制(了解):对java核心源码的保护,如自定义string类
在java虚拟机中表示两个class对象是否为同一个类的两个必要条件
1.类的完整类名必须一致,包括包名
2.加载这个类的ClassLoader必须相同
使用线程上下文类加载器可以打破双亲委派机制:深入理解Java类加载器(2):线程上下文类加载器_Dave888Zhou的博客-CSDN博客_java 上下文类加载器
4、java中的对象
1)、创建对象的步骤
-
判断对象对应的类是否加载、链接、初始化
-
为对象分配内存(如果内存规整,采用指针碰撞的方式;如果内存不规整,虚拟机需要维护一个列表,使用空闲列表的方式分配)
-
处理并发安全问题(采用CAS配上失败重试保证更新的原子性,每个线程预先分配一块TLAB)
-
初始化分配到的空间(所有属性设置默认值,保证对象实例字段在不赋值时可以直接使用)
-
设置对象的对象头
-
执行init方法进行初始化
2)、对象的内存布局
HotSpot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。不同位的计算机,占用的字节大小也是不同的。

对象头又分为MarkWord和Class对象指针:
MarkWord(标记字段)
用于存储对象自身的运行时数据, 如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等。
锁状态标志以及锁升级的过程
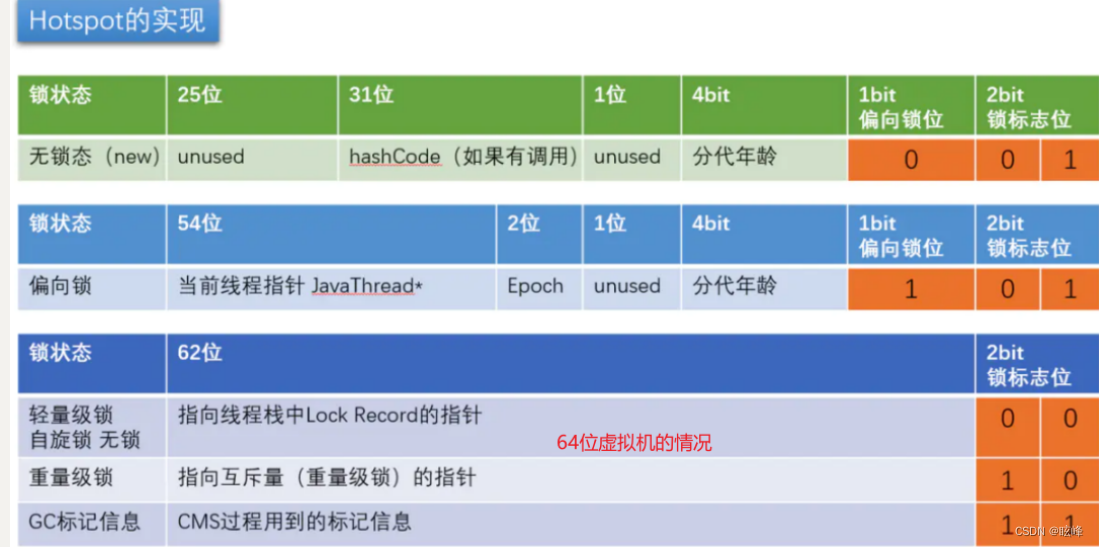
-
初期锁对象刚创建时,还没有任何线程来竞争,对象的Mark Word是下图的第一种情形,这偏向锁标识位是0,锁状态01,说明该对象处于无锁状态(无线程竞争它)。
-
当有一个线程来竞争锁时,先用偏向锁(偏向锁Biased Locking:Java6引入的一项多线程优化,偏向锁,顾名思义,它会偏向于第一个访问锁的线程,如果在运行过程中,同步锁只有一个线程访问,不存在多线程争用的情况,则线程是不需要触发同步的,这种情况下,就会给线程加一个偏向锁。 如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,JVM会消除它身上的偏向锁,将锁恢复到标准的轻量级锁),表示锁对象偏爱这个线程,这个线程要执行这个锁关联的任何代码,不需要再做任何检查和切换,这种竞争不激烈的情况下,效率非常高。这时Mark Word会记录自己偏爱的线程的ID,把该线程当做自己的熟人
-
当有两个线程开始竞争这个锁对象,情况发生变化了,不再是偏向(独占)锁了,锁会升级为轻量级锁,两个线程公平竞争,哪个线程先占有锁对象并执行代码,锁对象的Mark Word就执行哪个线程的栈帧中的锁记录。
-
如果竞争的这个锁对象的线程更多,导致了更多的切换和等待,JVM会把该锁对象的锁升级为重量级锁,这个就叫做同步锁,这个锁对象Mark Word再次发生变化,会指向一个监视器对象,这个监视器对象用集合的形式,来登记和管理排队的线程
Class对象指针
用于存储对象的类型指针,该指针指向它的类元数据,JVM通过这个指针确定对象是哪个类的实例
数组长度
如果对象是一个Java数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是从数组的元数据中无法确定数组的大小。
实例数据
接下来实例数据部分是对象真正存储的有效信息,也既是我们在程序代码里面所定义的各种类型的字段内容,无论是从父类继承下来的,还是在子类中定义的都需要记录下来。
对齐填充
对齐填充并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说就是对象的大小必须是8字节的整数倍。
3)、对象的分配
一般在java程序中,new的对象是分配在堆空间中的,但是实际的情况是,大部分的new对象会进入堆空间中,而并非是全部的对象,还有另外两个地方可以存储new的对象,我们称之为栈上分配以及TLAB(其实也是在堆上)。
堆
往堆中分配对象的话,优先分配在Eden区,对象比较大的话直接分配到老年代(尽量避免程序中出现过多的大对象),存活时间长的对象分配到老年代;动态对象年龄判断(如果Survivor区中相同年龄的所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象可以直接进入老年代,无需等到MaxTenuringThreshold中要求的年龄)。如果对象在Eden出生经过第一次MinorGC后仍然存活,并且能被Survivor容纳的话,将被移动到Survivor空间中,并将对象年龄设为1。对象没在Survivor区中熬过一次MinorGC,年龄就增加1岁,当它的年龄增加到一定程度,就会被晋升到老年代。
栈
栈上分配:针对那些作用域不会逃逸出方法的对象,在分配内存时不再将对象分配在堆内存中,而是将对象属性打散后分配在栈(线程私有的,属于栈内存)上,这样,随着方法的调用结束,栈空间的回收就会随着将栈上分配的打散后的对象回收掉,不再给GC增加额外的无用负担,从而提升应用程序的整体性能。
小对象(一般几十个byte),在没有逃逸分析情况下,可以直接分配在栈上、直接分配在栈上,可以自动回收,减轻GC压力、大对象或者逃逸分析无法在栈上分配
栈上分配需要一定的前提:
开启逃逸分析(-XX:DoEscapeAnalysis)逃逸分析的作用就是分析对象的作用域是否会逃逸出方法之外,在server虚拟机模式下可以开启
开启标量替换(-XX:+EliminateAllocations)标量替换的作用是允许将对象根据属性打散后分配在栈上,比如若一个对象拥有两个字段,会将这两个字段视为局部变量进行分配。默认该配置为开启。
TLAB(线程本地分配内存)
对象分配在堆上,而堆是一个全局共享的区域,当多个线程同一时刻操作堆内存分配对象空间时,就需要进行同步,而同步带来的效果就是对象分配效率变差(尽管JVM采用了CAS的形式处理分配失败的情况),但是对于存在竞争激烈的分配场合仍然会导致效率变差。
JVM默认开启了TLAB功能,也可以使用-XX:+UseTLAB显示开启、VM提供了-XX:PrintTLAB参数打开跟踪TLAB的使用情况、-XX:TLABSize通过该参数指定分配给每一个线程的TLAB空间大小。
需要TLAB的原因:就是提高对象在堆上的分配效率而采用的一种手段,就是给每个线程分配一小块私有的堆空间,即TLAB是一块线程私有的堆空间(实际上是Eden区中划出的)。
=============
如果开启栈上分配,JVM会先进行栈上分配,如果没有开启栈上分配或不符合条件的则会进行TLAB分配,如果TLAB分配不成功,再尝试Eden区分配,如果对象满足了直接进入老年代的条件,那就直接分配在老年代。
针对哪些作用域不会逃逸出方法的对象,在分配内存时不再将对象分配在堆内存中,而是将对象属性打散后分配在栈上,这样,随着方法的调用结束,栈空间的回收就会随着将栈上分配的打散后的对象回收掉,不再给gc增加额外的无用负担,从而提升应用程序整体的性能。
3)、对象的访问定位
对象的访问定位有两种方式:直接指针和句柄池访问
直接指针
java堆对象的布局中就必须考虑如何放置访问类型数据的相关信息,reference中存储的直接就是对象地址

句柄池访问
java堆中将会划分出一块内存来作句柄池,reference中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据的具体各自的地址信息。

5、为什么jvm的堆区要分代呢?不分代不行吗?
分代是为了优化GC,虽然不分代Java虚拟机也是可以工作的,但是不分代的话每次GC都要整堆扫描,时间长、效率低。而分代之后,只需要将新生的对象放入新生代的Eden区,而大部分对象都是朝生夕死的,所以大部分的对象在新生代的Eden区就被回收了。对于垃圾回收算法来说,每一种算法都有自己的优缺点,分代之后我们就可以根据每个区域的特点来使用最佳的垃圾回收算法,比如新生代采用复制算法,老年代采用标记清除/整理算法。
6、Java虚拟机堆中的新生代,为什么要分为Eden区和Survivor区?而且为什么要设置两个Survivor区?
如果没有survivor区的话,只有Eden区和老年代,当新生代发生GC的时候,Eden区中未被回收的对象就会被复制到老年代,这样的话老年代很快就满了,而老年代满了是要触发FullGC的,效率太低,耗时长。因为新生代的对象大部分都是朝生夕死的,所以最优的算法是复制算法,而复制算法是需要有一半的空间是空闲的,如果只有一个Survivor的话,很快就满了,而survivor区中的对象晋升到老年代的话,需要存活15次GC才能升到老年代,它每满一次就要GC,太频繁了,所以设置成两个。
7、垃圾回收器
查看默认的垃圾收集器:-XX:+PrintCommandLineFlags
默认的垃圾收集器有哪些
串行回收器:Serial、Serial Old
并行回收器:ParNew、Parallel Scavenge、Parallel Old
并发回收器:CMS、G1
部分参数预先说明
DefNew--------------Default New Generation
Tenured--------------Old
ParNew--------------Parallel New Generation
PSYoungGen---------Parallel Scavenge
ParOldGen-----------Parallel Old Generation
新生代串行回收器(Serial)
一个单线程的收集器,在进行垃圾收集的时候,必须暂停其他所有的工作线程直到它收集结束
串行收集器是最古老,最稳定以及效率高的收集器,只使用一个线程去回收但其在进行垃圾收集过程中可能会产生较长的停顿(Stop-The-World状态)。虽然在收集垃圾过程中需要暂停其他所有工作线程,但是它简单高效,对于限定单个CPU环境来说,没有线程交互的开销可以获得最高的单线程垃圾收集效率,因此Serial拉机器依然是java虚拟机运行在Client模式下默认的新生代垃圾收集器。
对应的JVM参数是:-XX:+UseSerialGC
开启后会使用:Serial(Yong区用)+Serial Old(Old区用)的收集器组合
表示:新生代、老年代都会使用串行回收收集器,新生代使用复制算法,老年代使用标记-整理算法

总结:这种垃圾收集器大家了解,现在已经不用串行了。而且在限定单核CPU才可以用,现在都不是单核额了。
对于交互较强的应用而言,这种垃圾收集器是不能接收的。一般在Javaweb应用程序中是不会采用串行垃圾收集器的。
新生代并行GC(ParNew)
使用多线程进行垃圾回收,在垃圾收集时,会Stop-the-World暂停其他所有的工作线程直到它收集结束。
ParNew收集器其实就是Serial收集器新生代的并行多线程版本,最常见的应用场景是配合老年代的CMS GC工作,其余的行为和Serial收集器完全一样,ParNew垃圾收集器在垃圾收集过程中同样要暂停所有其他的工作线程。它是很多java虚拟机运行在Server模式下新生代的默认垃圾收集器。
常用对应JVM参数:-XX:UseParNewGC 启用ParNew收集器,只影响新生代的收集,不影响老年代
开启上述参数后,会使用:ParNew(Young区用)+SerialOld的收集器的组合,新生代使用复制算法,老年代采用标记-整理算法
但是,ParNew+Tenured这样的搭配,Java8已经不再被推荐
备注:-XX:ParallelGCThreads限制线程数量,默认开启和CPU数目相同的线程数

新生代并行回收GC(Parallel)/(Parallel Scavenge)
Parallel Scavenge收集器类似ParNew也是一个新生代垃圾收集器,使用复制算法,也是一个并行的多线程的垃圾收集器,俗称吞吐量优先收集器。一句话:串行收集器在新生代和老年代并行化
它重点关注的是:
可控制的吞吐量(Thoughput=运行用户代码时间/(运行用户代码时间+垃圾收集时间),也即比如程序运行100分钟,垃圾收集时间一分钟,吞吐量即使99%)。高吞吐量意味着高效利用CPU的时间,它多用于在后台运算而不需要太多交互的任务。
自适应调节策略也是ParallelScavenge收集器与ParNew收集器的一个重要区别。(自适应调节策略:虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间(-XX:MaxGCPauseMillis)或最大的吞吐量。
常用JVM参数:-XX:ParallelGCThreads=数字N,表示启动多少个GC线程。cpu>8,N=5/8,CPU<8 N= 实际个数

在程序吞吐量优先的应用场景中,Parallel收集器和Parallel Old收集器的组合,在Server模式下的内存回收性能很不错。在Java8中,默认是此垃圾收集器。
老年代串行回收GC(Serial Old)/(Serial MSC)

老年代并行GC(Parallel Old)/(Parallel MSC)

老年代并发标记清除GC(CMS)
CMS是一种以获取最短回收停顿时间为目标的收集器。它第一次实现了让垃圾收集器线程与用户线程同时工作。
适合用在互联网站或者B/S系统的服务器上,这类应用尤其重视服务器的响应速度,希望系统停顿时间最短。CMS非常适合堆内存大、CPU核数多的服务器端应用,也是GC出现之前大型应用的首选收集器。
开启该收集器的JVM参数:-XX:UseConcMarkSweepGC 开启该参数后会自动将-XX:UseParNewGC打开
开启该参数后,使用ParNew(Young区用)+CMS(Old区用)+Serial Old的收集器组合,SerialOld将作为CMS出错的后备收集器
CMS采用标记-清除算法,并且也会造成STW。
原理

四步过程:
初始标记(CMS initial Mark)
并发标记(CMS concurrent mark+)和用户线程一起:进行GC Roots跟踪的过程,和用户线程一起工作,不需要暂停工作线程,主要标记过程,标记全部对象
重新标记(CMS remark):为了修正在并发标记期间,因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,仍然需要暂停所有的工作线程。由于并发标记时,用户线程依然运行,因此在正式清理前,再做修正
并发清除(CMS concurrent sweep)和用户线程一起:清除GC Roots不可达对象,和用户线程一起工作,不需要暂停工作线程。基于标记结果,直接清理对象。由于耗时最长的并发标记和并发清除过程中,垃圾收集器可以和用户在一起并发工作,所以总体上来看CMS收集器的内存回收和用户线程一起并发地执行。
优点
并发收集低停顿
缺点
并发执行,对CPU资源压力大:
由于并发进行,CMS在收集与应用线程会同时增加对堆内存的占用,也就是说,CMS必须要在老年代堆内存用尽之前完成垃圾回收,否则CMS回收失败时,将触发担保机制,串行老年代收集器将会以STW的方式进行一次GC,从而造成较大停顿时间
采用的标记清除算法会导致大量碎片:
标记清除算法无法整理空间碎片,老年代空间会随着应用时长被逐步耗尽,最后将不得不通过担保机制对堆内存进行压缩。CMS也提供了参数-XX:CMSFullGCsBeForeCOmpaction(默认0,即每次都进行内存整理)来指定多少次CMS收集之后,进行一次压缩的Full GC。
如何选择

G1收集器
底层原理
区域化内存划片Region,整体编为了一些不连续的内存区域,避免了全内存区的GC操作
核心思想是将整个堆内存区域分成大小相同的子区域(Region),在JVM启动时会自动设置这些子区域的大小,在堆的使用上,G1并不要求对象的存储一定是物理上连续的只要逻辑上连续即可,每个分区也不会固定地为某个代服务,可以按需在年轻代和老年代之间切换。启动时可以通过参数-XX:G1HeapRegionSize=n可指定分区大小(1MB-32MB,且必须是2的幂),默认将整堆分为2048个分区。
大小范围在1MB-32MB,最多能设置2048个区域,也能够支持的最大内存为:32MB*2048MB=64内存
回收步骤
针对Eden区进行收集,Eden区耗尽后会被触发,主要是小区域收集+形成连续的内存块,避免内存碎片
Eden区的数据移动到Survivor区,加入出现Survivor区空间不够,Eden区数据会晋升到Old区
Survivor区的数据移动到新的Survivor区,不会数据晋升到Old区
最后Eden区收拾干净了,GC结束,用户的应用程序继续执行

8、判断对象存活的方式
引用计数法
就是让每个对象保存一个整型的引用计数器属性。用于记录对象被引用的情况。对于一个对象A,只要有任何一个对象引用了A,则A的引用计数器就加1;当引用失效时,引用计数器就减1。只要对象A的引用计数器的值为0,即表示对象A不可能再被使用,可进行回收。
可达性分析法
可达性分析算法是以根对象集合(GC Roots)为起始点,按照从上至下的方式搜索被根对象集合所连接的目标对象是否可达。使用可达性分析算法后,内存中的存活对象都会被根对象集合直接或间接连接着,搜索所走过的路径称为引用链。如果目标对象没有任何引用链相连,则是不可达的,就意味着该对象已经死亡,可以标记为垃圾对象。在可达性分析算法中,只有能够被根对象集合直接或间接连接的对象才是存活对象。

哪些对象可以作为GCRoots
虚拟机栈(栈针中的局部变量区,也叫做局部变量表)
方法区中的类静态属性引用的对象
方法区中常量引用的对象
本地方法栈中N(Native方法)引用的对象
可达性算法中的不可达对象并不是立即死亡的,对象拥有一次自我拯救的机会。对象被系统宣告死亡至少要经历两次标记过程:第一次是经过可达性分析算法发现没有与GCROOTs相连接的引用链;第二次是在由虚拟机自动建立的FInalizer队列中判断是否需要finalize()方法。
当对象编程不可达时,GC会判断该对象是否覆盖了finalize()方法,若未覆盖,则直接将其回收。否则,若对象未执行过finalize()方法,将其放入F-Queue队列,由一低优先级线程执行该队列中对象的finalize()方法。执行finalize()方法完毕后,GC会再次判断该对象是否可达,若不可达,则进行回收,否则,对象“复活”。
9、垃圾回收算法
复制算法
将活着的内存空间分为两块,每次只使用其中一块,在垃圾回收时将正在使用的内存中的存活对象复制到未被使用的内存那种,之后清除正在使用的内存中的所有对象,交换两个内存角色,最后完成垃圾回收。
优点:实现简单、运行高效;复制过去保证空间的连续性,不会出现“碎片”问题。
缺点:需要两倍的空间
标记整理算法
第一阶段和标记清除算法一样,从根节点开始标记所有被引用对象,第二阶段将所有存活对象压缩到内存的一端,按顺序排放,之后,清理边界外所有的空间。
标记清除算法
当堆中的有效内存空间被耗尽的时候,就会停止整个程序,然后进行两项工作:
标记:Collector从引用根节点开始遍历,标记所有被引用的对象。一般是在对象的Header中记录为可达对象。
清除:Collector对堆内存从头到尾进行线性的遍历,如果发现某个对象在其Header中没有标记为可达对象,则将其回收。
缺点:效率不算高、在进行GC的时候,需要停止整个应用程序,导致用户体验差,这种方式清理出来的空闲内存时不连续的,产生内存碎片。需要维护一个空闲列表。
10、什么是Stop The World?
STW是指GC事件发生过程中,会产生应用程序的停顿,在停顿期间整个应用程序都会被暂停,没有任何响应,这 个停顿就被称为STW。
例如:在可达性分析算法中枚举根节点(GC Roots)会导致所有java执行线程停顿。
因为它的分析工作必须在一个能够保证一致性的快照中进行。如果在分析过程对象的引用关系还在不断的变化,则 分析结果的准确性就得不到保证。
一致性是指:整个分析期间整个执行系统看起来像被冻结在某个时间点上。
STW的发生与哪款GC无关,所有的GC都会存在这个事件。是Java虚拟机在后台自动发起和执行的,在用户不可兼 得情况下,将所有线程停止的。
11、OOM的概念
1)、Java.lang.StackOverflowError
StackOverflowError:栈溢出错误,如果一个线程所需要用到栈的大小>配置允许最大的栈大小,那么jvm就会抛出StackOverflow。
出现StackOverflowError的原因一般出现这个问题是因为程序里有死循环或递归调用所产生的。
public class StackOverflowErrorDemo {
public static void main(String[] args) {
stackOverflowError();
}
private static void stackOverflowError() {
stackOverflowError();
}
} public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
//死循环
int i=0;
while (true){
i++;
Log.i("ruxing","i="+i);
}
}
//递归
private void add(int i){
i++;
Log.i("ruxing","i="+i);
add(i);
}
}以递归为例,详解程序:1)启动MainActivity,会创建一个线程,同时创建一个栈内存。2)调用add()方法的时候,会对add()方法进行压栈操作,将add()运行期数据的数据集保存到栈帧中。3)add()递归调用时,都会产生一个新的栈帧区块,这是就会连续的产生新的栈帧区块。4)当栈内存超过系统配置的栈内存,就会出现java.lang.StackOverflowError异常。
2)、Java.lang.OutOfMemoryError:Java heap space
查阅官网得知产生 java.lang.OutOfMemoryError: Java heap space 错误的原因, 很多时候, 就类似于将 XXL 号的对象,往 S 号的 Java heap space 里面塞。其实清楚了原因, 就很容易解决对不对? 只要增加堆内存的大小, 程序就能正常运行. 另外还有一些比较复杂的情况, 主要是由代码问题导致的:
超出预期的访问量/数据量。 应用系统设计时,一般是有 “容量” 定义的, 部署这么多机器, 用来处理一定量的数据/业务。 如果访问量突然飙升, 超过预期的阈值, 类似于时间坐标系中针尖形状的图谱, 那么在峰值所在的时间段, 程序很可能就会卡死、并触发 java.lang.OutOfMemoryError: Java heap space 错误。
内存泄露(Memory leak). 这也是一种经常出现的情形。由于代码中的某些错误, 导致系统占用的内存越来越多. 如果某个方法/某段代码存在内存泄漏的, 每执行一次, 就会(有更多的垃圾对象)占用更多的内存. 随着运行时间的推移, 泄漏的对象耗光了堆中的所有内存, 那么 java.lang.OutOfMemoryError: Java heap space 错误就爆发了。
3)、Java.lang.OutOfMemoryError:GC overhead limit exceeded
OutOfMemoryError是java.lang.VirtualMachineError的子类,当JVM资源利用出现问题时抛出,更具体地说,这个错误是由于JVM花费太长时间执行GC且只能回收很少的堆内存时抛出的。 根据Oracle官方文档,默认情况下,如果Java进程花费98%以上的时间执行GC,并且每次只有不到2%的堆被恢复,则JVM抛出此错误。换句话说,这意味着我们的应用程序几乎耗尽了所有可用内存,垃圾收集器花了太长时间试图清理它,并多次失败。
在这种情况下,用户会体验到应用程序响应非常缓慢,通常只需要几毫秒就能完成的某些操作,此时则需要更长的时间来完成,这是因为所有的CPU正在进行垃圾收集,因此无法执行其他任务
4)、Java.lang.OutOfMemoryError:Direct buffer memory
5)、Java.lang.OutOfMemoryError:unable to crea te new native thread
6)、Java.lang.OutOfMemoryError:Metaspace
错误的主要原因, 是加载到内存中的 class 数量太多或者体积太大。
解决办法:增加Metaspace 的大小(-XX:MaxMetaspaceSize=512m)
12、内存溢出和内存泄漏
内存溢出
javadoc中对OutOfMemoryError的解释是,没有空闲内存,并且垃圾收集器也无法提供更多的内存
指程序申请内存时,没有足够的内存供申请者使用,或者说,给了你一块存储int类型数据的存储空间,但是你却存储long类型的数据,那么结果就是内存不够用,此时就会报错OOM,即所谓的内存溢出,简单来说就是自己所需要使用的空间比我们拥有的内存大内存不够使用所造成的内存溢出。
内存泄漏
严格来说,只有对象不会再被程序用到了,但是GC又不能回收他们的情况,才叫内存泄漏。
尽管内存泄漏并不会立刻引起程序崩溃,但是一旦发生内存泄漏,程序中的可用内存就会被逐步蚕食,直至耗尽所有内存,最终出现OutOfMemory异常,导致程序崩溃。
是指程序在申请内存后,无法释放已申请的内存空间就造成了内存泄漏,一次内存泄漏似乎不会有大的影响,但内存泄漏堆积后的后果就是内存溢出
注意:这里的存储空间并不是指物理内存,而是虚拟内存大小,这个虚拟内存大小取决于磁盘交换区设定的大小。
造成内存泄漏的8种情况 1.静态集合类:静态的集合因为静态的对象的生命周期和JVM是一样的,所以会导致内存泄漏 2.单例模式:单例的实例对象肯定是静态的,所有如果单例的实例对象持有外部对象的引用,也会导致内存泄漏 3.内部类持有外部类 4.各种连接,比如数据库连接,网络连接,IO连接等等。 5.变量不合理的作用域 6.不要去改变hashset这种集合中的对象的hash值 7.缓存泄漏:当你把数据存放在hashmap这种内存结构中,很容易出现内存泄漏、如果你使用WeakHashMap,那么除了WeakHashMap没有别的引用指向对象的时候,对象会被回收掉。 8.监听器和回调
13、请讲下G1垃圾回收器
G1收集器开创了收集器面向局部收集的设计思路和基于Region的内存布局形式。在G1收集器出现之前的所有其他收集器,垃圾收集的目标范围要么是整个新生代,要么就是整个老年代,再要么就是整个Java堆。而G1跳出了这个限制,它可以面向堆内存任何部分来组成回收集进行回收,衡量标准不再是它属于那个分代,而是哪块内存中存放的垃圾数量最多,回收收集最大,这就是G1收集器的Mixed GC模式。
G1也仍是遵循分代收集理论设计的,但其堆内存的布局与其他收集器有非常明显的差异:G1不再坚持固定大小以及固定数量的分代区域划分,而是把连续的java堆划分为多个大小相等的独立区域(Region),每一个Region都可以根据需要,扮演新生代的Eden空间、Survivor空间或者老年代空间。此外,还有一类专门用来存储大对象的特殊区域(Humongous Region)。G1认为只要超过了Region一半的对象即可判定为大对象。而对于那些超过了整个Region容量的超级大对象,将会被存放在N个连续的Humongous Region之中,G1的大多数行为都把Humongous Region作为老年代的一部分来看待。更具体的处理思路是,让G1收集器去跟踪各个Region里面的垃圾堆积的“价值”大小,价值即回收所获得的空间大小以及回收所需时间的经验值,然后在后台维护一个优先级列表,每次根据用户设定允许的收集停顿时间,优先处理回收价值收集最大的Region,这也就是“Garbage First"名字的由来。G1收集器的运作过程大致可划分为以下4个步骤:初始标记、并发标记、最终标记、筛选回收。其中,初始标记和最终标记阶段仍然需要停顿所有的线程,但是耗时很短。
G1与CMS的对比:G1从整体来看是基于标记整理算法实现的收集器,但从局部上看又是基于标记复制算法实现的。无论如何,这两种算法都意味着G1运作期间不会产生内存空间碎片,垃圾收集完成之后能提供规整的可用内存。比起CMS,G1的弱项也可以列举出不少。例如在用户程序运行过程中,G1无论是为了垃圾收集产生的内存占用还是程序运行时的额外执行负载都要比CMS要高。G1与CMS的选择:目前在小内存应用中CMS的表现大概率仍然要会优先于G1,而在大内存应用上G1则大多能发挥其优势,这个优劣势的Java堆容量平衡点通常在6GB至8GB之间。
14、请说一下GC的可达性分析法
当前主流的商用程序语言的内存管理子系统,都是通过可达性分析算法来判定对象是否存活的。这个算法的基本思路就是通过一系列称为“GC Roots”的根对象作为起始节点集,从这些节点开始,根据引用关系向下搜索,搜索过程所走过的路径称为“引用链”,如果某个对象到GC Roots间没有任何引用链相连,或者用图论的话来说就是从GC Roots到这个对象不可达时,则证明此对象是不可能再被使用的。
在Java技术体系里面,固定可作为GC Roots的对象包括以下几种:
-
在虚拟机栈中引用的对象,譬如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等;
-
在方法区中类静态属性引用的对象,譬如Java类的引用类型静态变量;
-
在方法区中常量引用的对象,譬如字符串常量池里的引用;
-
在本地方法栈中引用的对象;
-
JVM内部的引用,如基本数据类型对应的Class对象,常驻的异常对象,以及系统类加载器;
-
所有被同步锁持有的对象;
-
反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
真正宣告一个对象死亡,至少要经历两次标记过程:
第一次标记:
如果对象在进行可达性分析后发现没有与GC Roots相连接的引用链,那它将会被第一次标记,随后进行一次筛选,筛选的条件是此对象是否有必要执行finalize()方法。假如对象没有覆盖finalize()方法,或者finalize()方法已经被虚拟机调用过,那么虚拟机将这两种情况都视为“没有必要执行”。反之,该对象将会被放置在一个名为F-Queue的队列之中,并在稍后由一条由虚拟机自动建立的、低调度优先级的Finalizer线程去执行它们的finalize()方法。
第二次标记:
稍后,收集器将对F-Queue中的对象进行第二次小规模的标记。如果对象要在finalize()中成功拯救自己——只要重新与引用链上的任何一个对象建立关联即可,譬如把自己(this)赋值给某个类变量或者对象的成员变量,那在第二次标记时它将被移出“即将回收”的集合。如果对象这时候还没有逃脱,那基本上它就真的要被回收了。 finalize()方法是对象逃脱死亡命运的最后一次机会,需要注意的是,任何一个对象的finalize()方法都只会被系统自动调用一次,如果对象面临下一次回收,它的finalize()方法不会被再次执行。另外,finalize()方法的运行代价高昂,不确定性大,无法保证各个对象的调用顺序,如今已被官方明确声明为不推荐使用的语法。
15、说说类的实例化过程
在JVM中,对象的创建遵循如下过程: 当JVM遇到一条字节码new指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那必须先执行相应的类加载过程。 在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需内存的大小在类加载完成后便可完全确定,为对象分配空间的任务实际上便等同于把一块确定大小的内存块从Java堆中划分出来。 内存分配完成之后,虚拟机必须将分配到的内存空间都初始化为零值,如果使用了TLAB的话,这一项工作也可以提前至TLAB分配时顺便进行。这步操作保证了对象的实例字段在Java代码中可以不赋初始值就直接使用,使程序能访问到这些字段的数据类型所对应的零值。 接下来,虚拟机还要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的GC分代年龄等信息。这些信息存放在对象的对象头之中。根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。 在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了。但是从Java程序的视角看来,对象创建才刚刚开始——构造函数,即Class文件中的<init>()方法还没有执行,所有的字段都为默认的零值,对象需要的其他资源和状态信息也还没有按照预定的意图构造好。 一般来说,new指令之后会接着执行<init>()方法,按照程序员的意愿对对象进行初始化,这样一个真正可用的对象才算完全被构造出来。</init></init>
16、BIO、NIO、AIO的区别
BIO:同步并阻塞,服务实现模式为一个连接对应一个线程,即客户端发送一个连接,服务端要有一个线程来处理。如果连接多了,线程数量不够,就只能等待,即会发生阻塞。
NIO:同步非阻塞,服务实现模式是一个线程可以处理多个连接,即客户端发送的连接都会注册到多路复用器上,然后进行轮询连接,有I/O请求就处理。
AIO:异步非阻塞,引入了异步通道,采用的是proactor模式,特点是:有效的请求才启动线程,先有操作系统完成再通知服务端
17、JVM的一些常用参数
Jps:基础工具、查看JAVA进程PID,jps命令用来查看所有Java进程,每一行就是一个java进程信息。jps仅查找当前用户的Java进程,而不是当前系统中的所有进程,要显示其他用户的还只能用ps命令。
-l:如果是以class方式运行,会显示进程的主类main.class的全名,如果是jar包方式运行的,就会输出jar包完整路径名
-v:输出传递给jvm参数,v表示虚拟机
-V:大写v,表示通过文件传递给JVM的参数
-q:只输出进程id
jinfo:可以用来查看Java进程运行的JVM参数
jinfo ${PID}:查看某个JAVA进程中,JVM的参数值是什么
jinfo -flags ${PID}:如果不加JVM的参数话,默认查看jvm中所有被修改过的值
虚拟机的参数可以通过这个命令查看:java -XX:+PrintFlagsFinal -version | grep manageable
jstat:主要是对Java应用程序的资源和性能进行实时的命令行监控,包括了对heap size和垃圾回收状况的监控
类装载信息:jstat -class ${PID}
GC相关的情况:jstat -gc ${PID}
jstack:查看某个Java进程内的线程堆栈信息
三、Juc
1、并发、并行、串行的区别
串行在时间上不可能发生重叠,前一个任务没搞定,下一个任务就只能等着
并行在时间上是重叠的,两个任务在同一时刻互不干扰的同时执行
并发允许两个任务彼此干扰。统一时间点、只有一个任务运行,交替执行
2、请说说JUC
JUC是java.util.concurrent的缩写,这个包是JDK1.5提供的并发包,包内主要提供了支持并发操作的各种工具。这些工具大致分为如下5类:原子类、锁、线程池、并发容器、同步工具。
1.原子类从JDK1.5开始,并发包下提供了atomic子包,这个包中的原子操作类提供了一种用法简单、性能高效、线程安全地更新一个变量的方式。在atomic包里一共提供了17个类,属于4中类型的原子更新方式,分别是原子更新基本类型、原子更新引用类型、原子更新属性、原子更新数组。
2.锁从JDK1.5开始并发包中新增了Lock接口以及相关实现类用来实现锁功能,它提供了与synchronized关键字类似的同步功能,只是在使用时需要显示地获取锁和释放锁。虽然它缺少了隐式获取释放锁的便捷性,但是却拥有了多种synchronized关键字所不具备的同步特性,包括:可中断获取锁、非阻塞地获取锁、可超时地获取锁。
3.线程池 从JDK 1.5开始,并发包下新增了内置的线程池。其中,ThreadPoolExecutor类代表常规的线程池,而它的子类ScheduledThreadPoolExecutor对定时任务提供了支持,在子类中我们可以周期性地重复执行某个任务,也可以延迟若干时间再执行某个任务。此外,Executors是一个用于创建线程池的工具类,由于该类创建出来的是带有无界队列的线程池,所以在使用时要慎重。
4.并发容器 从JDK 1.5开始,并发包下新增了大量高效的并发的容器,这些容器按照实现机制可以分为三类。第一类是以降低锁粒度来提高并发性能的容器,它们的类名以Concurrent开头,如ConcurrentHashMap。第二类是采用写时复制技术实现的并发容器,它们的类名以CopyOnWrite开头,如CopyOnWriteArrayList。第三类是采用Lock实现的阻塞队列,内部创建两个Condition分别用于生产者和消费者的等待,这些类都实现了BlockingQueue接口,如ArrayBlockingQueue。
5.同步工具 从JDK 1.5开始,并发包下新增了几个有用的并发工具类,一样可以保证线程安全。其中,Semaphore类代表信号量,可以控制同时访问特定资源的线程数量;CountDownLatch类则允许一个或多个线程等待其他线程完成操作;CyclicBarrier可以让一组线程到达一个屏障时被阻塞,直到最后一个线程到达屏障时,屏障才会打开,所有被屏障拦截的线程才会继续运行。
3、线程
1)、创建线程的方式
1、继承 Thread 类;
步骤
-
定义一个Thread类的子类,重写run方法,将相关逻辑实现,run()方法就是线程要执行的业务逻辑方法
-
创建自定义的线程子类对象
-
调用子类实例的star()方法来启动线程
public class MyThread extends Thread {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " run()方法正在执行...");
}
}
public class TheadTest {
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.start();
System.out.println(Thread.currentThread().getName() + " main()方法执行结束");
}
}2、实现 Runnable 接口;
步骤
-
定义Runnable接口实现类MyRunnable,并重写run()方法
-
创建MyRunnable实例myRunnable,以myRunnable作为target创建Thead对象,该Thread对象才是真正的线程对象
-
调用线程对象的start()方法
public class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " run()方法执行中...");
}
}
public class RunnableTest {
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
thread.start();
System.out.println(Thread.currentThread().getName() + " main()方法执行完成");
}
}3、实现 Callable 接口;
步骤
-
创建实现Callable接口的类myCallable
-
以myCallable为参数创建FutureTask对象
-
将FutureTask作为参数创建Thread对象
-
调用线程对象的start()方法
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() {
System.out.println(Thread.currentThread().getName() + " call()方法执行中...");
return 1;
}
}
public class CallableTest {
public static void main(String[] args) {
FutureTask<Integer> futureTask = new FutureTask<Integer>(new MyCallable());
Thread thread = new Thread(futureTask);
thread.start();
try {
Thread.sleep(1000);
System.out.println("返回结果 " + futureTask.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " main()方法执行完成");
}
}4、使用 Executors 工具类创建线程池
Executors提供了一系列工厂方法用于创先线程池,返回的线程池都实现了ExecutorService接口。
主要有newFixedThreadPool,newCachedThreadPool,newSingleThreadExecutor,newScheduledThreadPool,后续详细介绍这四种线程池
public class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " run()方法执行中...");
}
}
public class SingleThreadExecutorTest {
public static void main(String[] args) {
ExecutorService executorService = Executors.newSingleThreadExecutor();
MyRunnable runnableTest = new MyRunnable();
for (int i = 0; i < 5; i++) {
executorService.execute(runnableTest);
}
System.out.println("线程任务开始执行");
executorService.shutdown();
}
}5、说一下 runnable 和 callable 有什么区别?
相同点
-
都是接口
-
都可以编写多线程程序
-
都采用Thread.start()启动线程
主要区别
-
Runnable 接口 run 方法无返回值;Callable 接口 call 方法有返回值,是个泛型,和Future、FutureTask配合可以用来获取异步执行的结果
-
Runnable 接口 run 方法只能抛出运行时异常,且无法捕获处理;Callable 接口 call 方法允许抛出异常,可以获取异常信息
注:Callalbe接口支持返回执行结果,需要调用FutureTask.get()得到,此方法会阻塞主进程的继续往下执行,如果不调用不会阻塞。
2)、java是怎么保证线程安全的
java保证线程安全的方式有很多,其中较为常用的有三种,按照资源类型占用情况由轻到重排列,这三种保证线程安全的方式分别是原子类、volatile、锁。
jdk从1.5开始提供了juc.atomic包,这个包的原子操作类提供了一种用法简单、性能高效、线程安全地更新一个变量的方式。在atomic包里一共提供了17个类,按功能可以归纳为4中类型的原子更新方式,分别是原子更新基本类型、原子更新引用类型、原子更新属性、原子更新数组。无论哪种类型都要遵循“比较和替换”规则,即比较更新的值是否等于期望值,如果是则更新;如果不是则失败。
volatile是轻量级的synchronized,它在多处理器开发中保证了共享变量的“可见性”,从而可以保证单个变量读写时的线程安全。可见性问题是由多处理器核心的缓存导致的,每个核心均有各自的缓存,而这些缓存均要与内存进行同步。volatile具有如下的内存语义:当写一个volatile变量时,该线程本地内存中的共享变量值会被立刻刷新到主内存;当读一个volatile变量时,该线程本地内存会被置为无效,迫使线程直接从主内存中读取共享变量。
原子类和volatile只能保证单个共享变量的线程安全,锁则可以保证临界区内的多个共享变量的线程安全,java中加锁的方式有两种,分别是synchronized关键字和Lock接口。synchronized是比较早期的API,在设计之初没有考虑到超时机制、非阻塞形式以及多个条件变量。若想通过升级的方式让它支持这些相对复杂的功能,则需要大改它的语法结构,不利于兼容旧代码。因此jdk的开发团队在1.5新增了Lock接口,并通过lock支持了上述的功能,即:支持响应中断、支持超时机制、支持非阻塞的方式获取锁、支持多个条件变量(阻塞队列)。
实现线程安全的方式有很多,除了上述三种方式之外,还有如下几种方式:
1、无状态设计 线程安全问题是由多线程并发修改共享变量引起的如果在并发环境中没有设计共享变量,则自然就不会出现线程安全问题了。这种代码实现可以称作“无状态实现”,所谓状态即使指共享变量。
2、不可变设计 如在并发环境中不得不设计共享变量,则应该优先考虑共享变量是否为只读的,如果是只读场景就可以将共享变量设计为不可变的,这样自然也不会出现线程安全问题了。具体来说,就是在变量前加final修饰符,使其不可被修改,如果变量时引用类型,则将其设计为不可变类型(参考String类型)
3、并发工具juc包提供了几个有用的并发工具类,一样可以保证线程安全:
-Semaphore:就是信号量,可以控制同时访问特定资源的线程数量。
-CountDownLatch:允许一个或多个线程等待其他线程操作完成。
-CyclicBarrier:让一组线程到达一个屏障时被阻塞,直到最后一个线程到达屏障时,屏障才会打开,所有被屏障拦截的线程才会继续运行。
4、本地存储 我们也可以考虑使用ThreadLocal存储变量,ThreadLocal可以很方便地为每一个线程单独存一份数据,也就是将需要并发访问的资源复制成多份。这样一来,就可以避免多线程访问共享变量了,他们访问的是自己独占的资源,它从根本上隔离多个线程之间的数据共享。
3)、说说你了解的线程同步方式
java主要通过加锁的方式实现线程同步。而锁有两种,分别是synchronized和Lock。
synchronized可以加载三个不同的位置,对应三种不同的使用方式,这三种方式的区别是锁对象不同:1.加在普通方法上,则锁是当前的实例(this)2.加在静态方法上,则锁是当前类的Class对象。3.加载代码块上,则需要在关键字后面的小括号里,显示指定一个对象作为锁对象。不同的锁对象,意味着不同的锁粒度,所以我们不应该无脑地将它加载方法前了事,尽管通常这可以解决问题。而是应该根据要锁定的范围,准确的选择锁对象,从而准确地确定锁的粒度,降低锁带来的性能开销。synchronized是比较早期的API,在设计之初没有考虑到超时机制、非阻塞形式,以及多个条件变量。若想通过升级的方式让synchronized支持那些相对复杂的功能,则需要大改它的语法结构,不利于兼容旧代码。
Lock支持的功能包括:支持响应中断、支持超时机制、支持以非阻塞的方式获取锁、支持多个条件变量(阻塞队列)。
synchronized采用“CAS+MarkWord”实现,为了性能的考虑,并通过锁升级机制降低锁的开销。在并发环境中,synchronized会随着多线程竞争的加剧,按照如下步骤逐步升级:无锁、偏向锁、轻量级锁、重量级锁。
Lock则采用“CAS+volatile”实现,其实现的的核心是AQS。AQS是线程同步器,是一个线程同步的基础框架,它基于模板方法模式。在具体的Lock实例中,锁的实现是通过继承AQS来实现的,并且可以根据锁的使用场景,派生出公平锁、不公平锁、读锁、写锁等具体的而实现。
3)、线程的状态
线程的状态分类
线程通常有五种状态:创建、就绪、运行、阻塞和死亡状态
1、新建状态(New):新创建了一个线程对象
2、就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start方法。该状态的线程位于可运行线程池中,变得可运行,等待获取CPU的使用权。
3、运行状态(Running):就绪状态的线程获取了CPU,执行程序代码
4、阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入到就绪状态,才有机会转到运行状态。
5、死亡状态(Dead):线程执行完了或者因异常退出了run方法,该线程结束生命周期。

阻塞状态又分为三种情况
(1)、等待阻塞:运行的线程执行wait方法,该线程会释放占用的所有资源,JVM会吧该线程放入“线程池”中,进入这个状态后,是不能自动唤醒的,必须依靠其他线程调用notify或notifyAll方法才能被唤醒,wait是Object类的方法。
(2)、同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入“锁池”中。
(3)、其他阻塞:运行的线程执行sleep或join方法,或者发出I/O请求时,JVM会把该线程置为阻塞状态。当sleep状态超时、join等待线程终止或者超时、或者IO处理完毕时,线程重新转入就绪状态。sleep是Thread类的方法。
4)、两种调度模型
分时调度模型和抢占式调度模型
(1)、分时调度模型是指让所有的线程轮流获得 cpu 的使用权,并且平均分配每个线程占用的 CPU 的时间片这个也比较好理解。
(2)、Java虚拟机采用抢占式调度模型,是指优先让可运行池中优先级高的线程占用CPU,如果可运行池中的线程优先级相同,那么就随机选择一个线程,使其占用CPU。处于运行状态的线程会一直运行,直至它不得不放弃 CPU。
线程的调度策略
线程调度器选择优先级最高的线程运行,但是,如果发生以下情况,就会终止线程的运行:
(1)线程体中调用了 yield 方法让出了对 cpu 的占用权利
(2)线程体中调用了 sleep 方法使线程进入睡眠状态
(3)线程由于 IO 操作受到阻塞
(4)另外一个更高优先级线程出现
(5)在支持时间片的系统中,该线程的时间片用完
与线程同步以及线程调度相关的方法
(1)、wait():使一个线程处于等待(阻塞)状态,并且释放所持有的对象的锁。
(2)、sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此方法要处理InterruptedException异常
(3)、notify():唤醒一个处于等待状态的线程,当然在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒那个线程,而且与优先级无关
(4)、notifyAll():唤醒所有处于等待状态的线程,该方法并不是将对象的锁给所有线程,而是让它们竞争,只有获得锁的线程才能进入就绪状态。
5)、什么是线程死锁
死锁是指两个或两个以上的进程(线程)在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,他们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程(线程)称为死锁进程(线程)。 多个线程同时被阻塞,他们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
6)、形成死锁的四个必要条件是什么
互斥条件:线程(进程)对于锁分配到的资源具有排它性,即一个资源只能被一个线程(进程)占用,直到被该线程(进程)释放。
请求与保持条件:一个线程(进程)因请求被占用资源而发生阻塞时,对已获得的资源保持不放。
不剥夺条件:线程(进程)已获得的资源在未使用完之前不能被其他线程强行剥夺,只能自己使用完毕后才释放资源。
循坏等待条件:当发生死锁时,所等待的线程必定会形成一个环路,造成永久阻塞。
7)、线程的run()和start()有什么区别?
每个线程都是通过某个特定Thread对象所对应的方法run()来完成其操作的,run()方法称为线程体。通过调用Thread类的start()方法来启动一个线程。start()方法用于启动线程,run()方法用于执行线程的运行时代码。run()可以重复调用,而start()只能调用一次。
start()方法来启动一个线程,真正实现了多线程运行。调用start()方法无需等待run方法体代码执行完毕,可以直接继续执行其它的代码;此时线程是处于就绪状态,并没有运行。然后通过次Thread类调用方法run()来完成其运行状态,run()方法运行结束,此线程终止。然后CPU再调度其它线程。
run()方法时本线程里的,只是线程里的一个函数,而不是多线程的。如果直接调用run(),其实就相当于是调用了一个普通函数而已,直接调用run()方法必须等待run()方法执行完毕才能执行下面的代码,所以执行路径还是只有一条,根本就没有线程的特征,所以在多线程执行时要使用start()方法而不是run()方法。
8)、为什么我们调用 start() 方法时会执行 run() 方法,为什么我们 不能直接调用 run() 方法?
new一个Thread,线程进入了新建状态。调用start()方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。start()会执行线程的相应准备工作,然后自动执行run()方法的内容,这时真正的多线程工作。而直接执行run()方法,会把run方法当成一个main线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
总结:调用start()方法可启动线程并使线程进入就绪状态,而run方法只是Thread的一个普通方法调用,还是在主线程里执行。
9)、Java 中用到的线程调度算法是什么?
计算机通常只有一个CPU,在任意时刻只能执行一条机器指令,每个线程只有获得CPU的使用权才能执行命令。所谓多线程的并发运行,其实是从宏观上看,各个线程轮流获得CPU的使用权,分别执行各自的任务。在运行池中,会有多个处于就绪状态的线程在等待CPU,JAVA虚拟机的一项任务就是负责线程的调度,线程调度是指按照特定机制为多个线程分配CPU的使用权。
有两种调度模型:分时调度模型和抢占式调度模型。
>分时调度模型是指让所有的线程轮流获得CPU的使用权,并且平均分配每个线程占用的CPU的时间片 >抢占式调度模型,是指优先让可运行池中优先级高的线程占用CPU,如果可运行池中的线程优先级相同,那么就随机选择一个线程,使其占用CPU。处于运行状态的线程会一直运行,直至它不得不放弃CPU。
10)、线程的调度策略
线程调度器选择优先级最高的线程运行,但是,如果发生以下情况,就会终止线程的运行:
>线程体重调用了yield方法让出了对CPU的占用权利 > >线程体重调用了sleep方法使线程进入睡眠状态 > >线程由于IO操作受到阻塞 > >另外一个更高优先级线程出现 > >在支持时间片的系统中,该线程的时间片用完
11)、什么是线程调度器和时间分片
线程调度器是一个操作系统任务,它负责为Runnable状态的线程分配CPU时间,一旦我们创建一个线程并启动它,它的执行便依赖于线程调度器的实现。
时间分片是指将可用的CPU时间分配给可用的RUnnable线程的过程。分配CPU时间可以基于线程优先级或者线程等待的时间。
线程调度并不受Java虚拟机控制,所以由应用程序来控制它是更好的选择
12)、请说说对多线程的理解
进程:是资源分配的最小单位,一个进程可以有多个线程,多个线程共享进程的堆和方法区资源,不共 享栈、程序计数器 线程:是任务调度和执行的最小单位,线程并行执行存在资源竞争和上下文切换的问题
线程是操作系统调度的最小单元,它可以让一个进程并发地处理多个任务,也叫轻量级进程。所以,在一个进程里面可以创建多个线程。由于共享资源,处理器便可以在这些线程之间快速切换,从而让使用者感觉这些线程在同时执行。总的来说,操作系统可以同时执行多个任务,每个任务就是一个进程。进程可以同时执行多个任务,每个任务就是个线程。一个程序运行之后至少有一个进程,而一个进程可以包含多个线程,但至少要包含一个线程。使用多线程会给开发人员带来显著的好处。
13)、Java是怎么保证线程安全的
java保证线程安全的方式有很多种,其中较为常用的三种,按照资源类型占用情况由轻到重排列,这三种保证线程安全的方式分别是:原子类、volatile、锁
jdk从1.5开始提供了juc.atomic包,这个包的原子操作类提供了一种用法简单、性能高效、线程安全地更新一个变量的方式。
volatile是轻量级的synchronized,它在处理器开发中保证了共享变量的可见性,从而可以保证单个变量读写时的线程安全。
原子类和volatile只能保证单个共享变量的线程安全。锁则可以保证临界区内多个共享变量的线程安全,java加锁的方式有两种,分别是synchronized关键字和Lock接口。
4、说说synchronized的用法及原理
用法
synchronized可以作用在三个不同的位置,对应三种不同的使用方式,这三种方式的区别是锁对象不同。不同的锁对象,意味着不同的锁粒度,所以我们不应该无脑地将它加在方法前了事,尽管通常这可以解决问题。而是应该根据要锁定的范围,准确的选择锁对象,从而准确地确定锁的粒度,降低锁带来的性能开销。1. 作用在静态方法上,则锁是当前类的Class对象。 2. 作用在普通方法上,则锁是当前的实例(this)。 3. 作用在代码块上,则需要在关键字后面的小括号里,显式指定一个对象作为锁对象。
原理:
synchronized的底层是采用Java对象头来存储锁信息的,并且还支持锁升级。
锁升级过程
1、开始,没有任何线程访问同步块,此时同步块处于无锁状态。
2、然后,线程1首先访问同步块,它以CAS的方式修改Mark Word,尝试加偏向锁。由于此时没有竞争,偏向锁加锁成功,此时Mark Word里存储的是线程1的ID。
3、然后,线程2开始访问同步块,它以CAS的方式修改Mark Word,尝试加偏向锁。由于此时存在竞争,所以偏向锁加锁失败,于是线程2会发起撤销偏向锁的流程(清空线程1的ID),于是同步块从偏向线程1的状态恢复到了可以公平竞争的状态
4、然后,线程1和线程2共同竞争,它们同时以CAS方式修改Mark Word,尝试加轻量级锁。由于存在竞争,只有一个线程会成功,假设线程1成功了。但线程2不会轻易放弃,他认为线程1很快就能执行完毕。执行权很快会落到自己头上,于是线程2继续自旋加锁。
5、最后,如果线程1很快执行完,则线程2就会加轻量级锁成功,锁不会晋升到重量级状态。也可能是线程1执行时间较长,那么线程2自旋一定次数后它就会放弃自旋,并发起锁膨胀的流程。届时,锁被线程2修改为重量级锁,之后线程2进入阻塞状态。而线程1重复加锁或解锁时,CAS操作都会失败,此时它就会释放锁并唤醒等待的线程。总之,在锁升级的机制下,锁不会一步到位变为重量级锁,而是根据竞争情况逐步升级的。在竞争小的时候,只需以较小的代价加锁,直到竞争加剧,才是用重量级锁,从而减小了加锁带来的开销。
博客:synchronized的锁升级过程(java中的锁)_郑..方..醒的博客-CSDN博客_java synchronized锁升级
博客:synchronized的锁升级过程(java中的锁)_郑..方..醒的博客-CSDN博客_java synchronized锁升级
5、说说对AQS的理解
AQS(AbstractQueueSynchronizer)是队列同步器,是用来构建锁的基础框架,Lock实现类都是基于AQS实现的。AQS是基于模板方法模式进行设计的,所以锁的实现需要继承AQS并重写它指定的方法。AQS内部定义了一个FIFO的队列来实现线程的同步,同时还定义了同步状态来记录锁的信息。AQS的模板方法,将管理同步状态的逻辑提炼出来形成标准流程,这些方法主要包括:独占式获取同步状态、独占式释放同步状态、共享式获取同步状态、共享式释放同步状态。以独占式获取同步状态为例,它的大致流程是:1.尝试以独占方式获取同步状态。2.如果状态获取失败,则将当前从加入同步队列。3.自旋处理同步状态,如果当前线程位于队头,则唤醒它并让它出队,否则使其进入阻塞状态。
其中,有些步骤无法在父类确定,则提炼成空方法留待子类实现。例如,第一步的尝试操作,对于公平锁和非公平锁来说就不一样,所以子类在实现时需要按照场景各自实现这个方法。 AQS的同步队列,是一个双向链表,AQS则持有链表的头尾节点。对于尾节点的设置,是存在多线程竞争的,所以采用CAS的方式进行修改。对于头节点设置,则一定是拿到了同步状态的线程才能处理,所以修改头节点不需要采用CAS的方式。 AQS的同步状态,是一个int类型的整数,它在表示状态的同时还能表示数量。通常情况下,状态为0时表示无锁,状态大于0时表示锁的重入次数。另外,在读写锁的场景中,这个状态标志既要记录读锁又要记录写锁。于是,锁的实现者就将状态表示拆成高低两部分,高位存读锁、低位存写锁。
同步状态需要在并发环境下修改,所以需要保证其线程安全。由于AQS本身就是锁的实现工具,所以不适合用锁来保证其线程安全,因为如果你用一个锁来定义另一个锁的话,那干脆直接用synchronized算了。实际上,同步状态是被volatile修饰的,该关键字可以保证状态变量的内存可见性,从而解决了线程安全问题。
6、Java中哪些地方使用AQS?
java提供的API中使用CAS的地方有很多,比较典型的使用场景有原子类、AQS、并发容器。
对于原子类,以AtomicInteger为例,它的内部提供了诸多原子操作的方法。如原子替换整数值、增加指定的值、加1,这些方法的底层便是采用操作系统提供的CAS原子指令来实现的。
对于AQS,在向同步队列的尾部追加节点时,它首先会以CAS的方式尝试一次,如果失败,则进入自旋状态,并反复以CAS的方式进行尝试。此外。在以共享方式释放同步状态时,它也是以CAS方式对同步状态进行修改的。
对于并发容器,以ConcurrentHashMap为例,它的内部多次使用了CAS操作。在初始化数组时,它会以CAS的方式修改初始化状态,避免多个线程同时进行初始化。在执行put方法初始化头节点时,它会以CAS的方式将初始化好的头节点设置到指定槽的首位,避免多个线程同时设置头节点。在数组扩容时,每个线程会以CAS方式修改任务序列号来争抢扩容任务,避免和其他线程产生冲突。在执行get方法时,它会以CAS的方式获取头指定槽的头节点,避免其他线程同时对头节点做出修改。
CAS的实现离不开操作系统原子指令的支持,java中对原子指令的支持,java中对原子指令封装的方法几种在Unsafe中,包括:原子替换引用类型、原子替换int型整数、原子替换long型整数。这些方法都有四个参数:var1、var2、var4、var5,其中var1代表要操作的对象,var2代表要替换的成员变量,var4代表期望的值,var5代更新的值。
public final native boolean compareAndSwapObject(Object var1,long var2,Object var4,Object var5); public final native boolean compareAndSwapObject(Object var1,long var2,int var4,int var5); public final native boolean compareAndSwapObject(Object var1,long var2,long var4,long var5);
7、synchronized和Lock有什么区别
lock是一个接口,而synchronized是java的一个关键字
synchronized在发生异常时会自动释放占有的锁,因此不会出现死锁,支持可重入、不可中断、非公平;
而lock发生异常时,不会主动释放占有的锁,必须手动来释放锁,可能引起死锁的发生,支持可重入、可中断(lock等待锁过程中可以用interrup来中断等待)、公平。Lock可以提高多个线程进行读操作的效率、还可以通过trylock来知道有没有获取锁,而synchronized不能。
8、CAS
CAS(compare and swap),比较并交换。可以解决多线程并行情况下使用锁造成性能损耗的一种机制.CAS 操作包含三个操作数—内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。一个线程从主内存中得到num值,并对num进行操作,写入值的时候,线程会把第一次取到的num值和主内存中num值进行比较,如果相等,就会将改变后的num写入主内存,如果不相等,则一直循环对比,知道成功为止。
CAS产生
在修饰共享变量的时候经常使用volatile关键字,但是volatile值有可见性和禁止指令重排(有序性),无法保证原子性。虽然在单线程中没有问题,但是多线程就会出现各种问题,造成现场不安全的现象。所以jdk1.5后产生了CAS利用CPU原语(不可分割,连续不中断)保证现场操作原子性。
CAS应用
在JDK1.5 中新增java.util.concurrent(JUC)就是建立在CAS之上的。相对于对于synchronized这种锁机制,CAS是非阻塞算法的一种常见实现。所以JUC在性能上有了很大的提升。
比如AtomicInteger类,AtomicInteger是线程安全的的,下面是源码
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}进入unsafe看到do while自循环,这里的自循环,就是在 判断预期原值 如果与原来的值不符合,会再循环取原值,再走CAS流程,直到能够把新值赋值成功。
CAS优点
cas是一种乐观锁的思想,而且是一种非阻塞的轻量级的乐观锁,非阻塞式是指一个线程的失败或者挂起不应该影响其他线程的失败或挂起的算法。
CAS缺点
1、循环时间长开销大,占用CPU资源。如果自旋锁长时间不成功,会给CPU带来很大的开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。 2、只能保证一个共享变量的原子操作。当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。 3、ABA问题
CAS的底层原理
是一个自旋锁和unsafe类。
unsafe类
是CAS的核心类,由于Java方法无法直接访问底层系统,需要通过本地(native)方法来访问,Unsafe相当于一个后门,基于该类可以直接操作特定内存的数据。Unsafe类存在于sun.misc包中,其内部方法操作可以像C的指针一样直接操作内存,因为Java中CAS操作的执行依赖于Unsafe类的方法。
注意Unsafe类中的所有方法都是native修饰的,也就是说Unsafe类中的方法都直接调用操作系统底层资源执行相应任务。
2 变量valueOffset,表示该变量值在内存中的偏移地址,因为Unsafe就是根据内存偏移地址获取数据的。
3 变量value用volatile修饰,保证了多线程之间的内存可见性。
CAS是什么
CAS的全称为Compare-And-Swap,它是一条CPU并发原语。
它的功能是判断内存某个位置的值是否为预期值,如果是则更改为新的值,这个过程是原子的。
CAS并发原语体现在JAVA语言中就是sun.misc.Unsafe类中的各个方法。调用UnSafe类中的CAS方法,JVM会帮我们实现出CAS汇编指令。这是一种完全依赖于硬件的功能,通过它实现了原子操作。再次强调,由于CAS是一种系统原语,原语属于操作系统用语范畴,是由若干条指令组成的,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说CAS是一条CPU的原子指令,不会造成所谓的数据不一致问题。(原子性) 
UnSafe.getAndAddInt()源码解释:
var1 AtomicInteger对象本身。 var2 该对象值得引用地址。 var4 需要变动的数量。 var5是用过var1,var2找出的主内存中真实的值。 用该对象当前的值与var5比较: 如果相同,更新var5+var4并且返回true, 如果不同,继续取值然后再比较,直到更新完成。
假设线程A和线程B两个线程同时执行getAndAddInt操作(分别跑在不同CPU上) :
1、Atomiclnteger里面的value原始值为3,即主内存中Atomiclnteger的value为3,根据JMM模型,线程A和线程B各自持有一份值为3的value的副本分别到各自的工作内存。 2、线程A通过getIntVolatile(var1, var2)拿到value值3,这时线程A被挂起。 3、线程B也通过getintVolatile(var1, var2)方法获取到value值3,此时刚好线程B没有被挂起并执行compareAndSwapInt方法比较内存值也为3,成功修改内存值为4,线程B打完收工,一切OK。 4、这时线程A恢复,执行compareAndSwapInt方法比较,发现自己手里的值数字3和主内存的值数字4不一致,说明该值己经被其它线程抢先一步修改过了,那A线程本次修改失败,只能重新读取重新来一遍了。 5、线程A重新获取value值,因为变量value被volatile修饰,所以其它线程对它的修改,线程A总是能够看到,线程A继续执行compareAndSwaplnt进行比较替换,直到成功。
底层汇编
Unsafe类中的compareAndSwapInt,是一个本地方法,该方法的实现位于unsafe.cpp中。
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x)
UnsafeWrapper("Unsafe_CompareAndSwaplnt");
oop p = JNlHandles::resolve(obj);
jint* addr = (jint *)index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e))== e;
UNSAFE_END
//先想办法拿到变量value在内存中的地址。
//通过Atomic::cmpxchg实现比较替换,其中参数x是即将更新的值,参数e是原内存的值。
小结
CAS指令
CAS有3个操作数,内存值V,旧的预期值A,要修改的更新值B。
当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
一个变量简单的读取和赋值操作是原子性的,将一个变量赋值给另外一个变量不是原子性的。
Java内存模型(JMM)仅仅保障了变量的基本读取和赋值操作是原子性的,其他均不会保证的。如果想要使某段代码块要求具备原子性,就需要使用 synchronized 关键字、并发包中的 Lock 锁、并发包中 Atomic 各种类型的原子类来实现,即上面我们提到的四种方案都是可行的。
而 volatile 关键字修饰的变量,恰恰是不能保障原子性的,仅能保障可见性和有序性。
java.util.concurrent.atomic 并发包下的所有原子类都是基于 CAS 来实现的。
CAS------》UNSafe------》CAS底层思想------》ABA-------》原子引用更新------》如何规避ABA问题
1)、ABA问题
CAS需要在操作值的时候,检查下值有没有发生变化,如果没有发生变化则更新, 但是可能会有这样一个情况,如果一个值原来是A,在CAS方法执行之前,被其他线程修改为了B,然后又修改回成A, 此时CAS方法执行之前,检查的时候发现它的值并没有发生变化,但实际却变化了,这就是【CAS的ABA】问题。

原子引用
volatile不保证原子性,为解决原子性使用了AtomicInteger原子整型,解决了基本类型运算操作的原子性的问题,那我们自定义的实体类或者基本数据类型都要保证原子性呢?使用AtomicReference原子引用
@Getter
@Setter
@AllArgsConstructor
@ToString
class User{
private String name;
private int age;
}
public class AtomicReferenceDemo {
public static void main(String[] args) {
User zs = new User("zs", 22);
User ls = new User("ls", 22);
AtomicReference<User> userAtomicReference = new AtomicReference<>();
userAtomicReference.set(zs);
System.out.println(userAtomicReference.compareAndSet(zs, ls)+"\t"+userAtomicReference.get().toString());
System.out.println(userAtomicReference.compareAndSet(zs, ls)+"\t"+userAtomicReference.get().toString());
}
}AtomicStampedReference版本号原子引用:原子引用 + 新增一种机制,那就是修改版本号(类似时间戳),它用来解决ABA问题。
2)、ABA问题的解决
ABA问题程序演示及解决方法演示:
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicReference;
import java.util.concurrent.atomic.AtomicStampedReference;
public class ABADemo {
/**
* 普通的原子引用包装类
*/
static AtomicReference<Integer> atomicReference = new AtomicReference<>(100);
// 传递两个值,一个是初始值,一个是初始版本号
static AtomicStampedReference<Integer> atomicStampedReference = new AtomicStampedReference<>(100, 1);
public static void main(String[] args) {
System.out.println("============以下是ABA问题的产生==========");
new Thread(() -> {
// 把100 改成 101 然后在改成100,也就是ABA
atomicReference.compareAndSet(100, 101);
atomicReference.compareAndSet(101, 100);
}, "t1").start();
new Thread(() -> {
try {
// 睡眠一秒,保证t1线程,完成了ABA操作
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 把100 改成 101 然后在改成100,也就是ABA
System.out.println(atomicReference.compareAndSet(100, 2019) + "\t" + atomicReference.get());
}, "t2").start();
/
try {
TimeUnit.SECONDS.sleep(2);
} catch (Exception e) {
e.printStackTrace();
}
/
System.out.println("============以下是ABA问题的解决==========");
new Thread(() -> {
// 获取版本号
int stamp = atomicStampedReference.getStamp();
System.out.println(Thread.currentThread().getName() + "\t 第一次版本号" + stamp);
// 暂停t3一秒钟
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 传入4个值,期望值,更新值,期望版本号,更新版本号
atomicStampedReference.compareAndSet(100, 101, atomicStampedReference.getStamp(),
atomicStampedReference.getStamp() + 1);
System.out.println(Thread.currentThread().getName() + "\t 第二次版本号" + atomicStampedReference.getStamp());
atomicStampedReference.compareAndSet(101, 100, atomicStampedReference.getStamp(),
atomicStampedReference.getStamp() + 1);
System.out.println(Thread.currentThread().getName() + "\t 第三次版本号" + atomicStampedReference.getStamp());
}, "t3").start();
new Thread(() -> {
// 获取版本号
int stamp = atomicStampedReference.getStamp();
System.out.println(Thread.currentThread().getName() + "\t 第一次版本号" + stamp);
// 暂停t4 3秒钟,保证t3线程也进行一次ABA问题
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
boolean result = atomicStampedReference.compareAndSet(100, 2019, stamp, stamp + 1);
System.out.println(Thread.currentThread().getName() + "\t 修改成功否:" + result + "\t 当前最新实际版本号:"
+ atomicStampedReference.getStamp());
System.out.println(Thread.currentThread().getName() + "\t 当前实际最新值" + atomicStampedReference.getReference());
}, "t4").start();
}
}9、并发容器之CopyOnWriteArrayList详解
CopyOnWriteArrayList 是什么
CopyOnWriteArrayList 是一个并发容器。有很多人称它是线程安全的,我认为这句话不严谨,缺少一个前提条件,那就是非复合场景下操作它是线程安全的。
CopyOnWriteArrayList(免锁容器)的好处之一是当多个迭代器同时遍历和修改这个列表时,不会抛出 ConcurrentModificationException。在CopyOnWriteArrayList 中,写入将导致创建整个底层数组的副本,而源数组将保留在原地,使得复制的数组在被修改时,读取操作可以安全地执行。
CopyOnWriteArrayList 的使用场景
通过源码分析,我们看出它的优缺点比较明显,所以使用场景也就比较明显。就是合适读多写少的场景。
CopyOnWriteArrayList 的缺点
-
由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致 young gc 或者 full gc。
-
不能用于实时读的场景,像拷贝数组、新增元素都需要时间,所以调用一个 set 操作后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求。
-
由于实际使用中可能没法保证 CopyOnWriteArrayList 到底要放置多少数据,万一数据稍微有点多,每次 add/set 都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种操作分分钟引起故障。
CopyOnWriteArrayList 的设计思想
-
读写分离,读和写分开
-
最终一致性
-
使用另外开辟空间的思路,来解决并发冲突
public void add(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
if (index > len || index < 0)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+len);
Object[] newElements;
int numMoved = len - index;
if (numMoved == 0)
newElements = Arrays.copyOf(elements, len + 1);
else {
newElements = new Object[len + 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index, newElements, index + 1,
numMoved);
}
newElements[index] = element;
setArray(newElements);
} finally {
lock.unlock();
}
}CopyOnWriteArrayList这是一个ArrayList的线程安全的变体,其原理大概可以通俗的理解为:初始化的时候只有一个容器,很长一段时间,这个容器数据、数量等没有发生变化的时候,大家(多个线程),都是读取(假设这段时间里只发生读取的操作)同一个容器中的数据,所以这样大家读到的数据都是唯一、一致、安全的,但是后来有人往里面增加了一个数据,这个时候CopyOnWriteArrayList 底层实现添加的原理是先copy出一个容器(可以简称副本),再往新的容器里添加这个新的数据,最后把新的容器的引用地址赋值给了之前那个旧的的容器地址,但是在添加这个数据的期间,其他线程如果要去读取数据,仍然是读取到旧的容器里的数据。

10、并发容器ThreadLocal详解
什么是ThreadLocal
多线程访问同一个共享变量的时候容易出现并发问题,特别是多个线程对一个变量进行写入的时候,为了保证线程安全,一般使用者在访问共享变量的时候需要进行额外的同步措施才能保证线程安全性。ThreadLocal是除了加锁这种同步方式之外的一种保证一种规避多线程访问出现线程不安全的方法,当我们在创建一个变量后,如果每个线程对其进行访问的时候访问的都是线程自己的变量这样就不会存在线程不安全问题。
当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
package test;
public class ThreadLocalTest {
static ThreadLocal<String> localVar = new ThreadLocal<>();
static void print(String str) {
//打印当前线程中本地内存中本地变量的值
System.out.println(str + " :" + localVar.get());
//清除本地内存中的本地变量
localVar.remove();
}
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
//设置线程1中本地变量的值
localVar.set("localVar1");
//调用打印方法
print("thread1");
//打印本地变量
System.out.println("after remove : " + localVar.get());
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
//设置线程1中本地变量的值
localVar.set("localVar2");
//调用打印方法
print("thread2");
//打印本地变量
System.out.println("after remove : " + localVar.get());
}
});
t1.start();
t2.start();
}
}下面是运行后的结果:

Thread、ThreadLocal、ThreadLocalMap有什么关系?
原理
每一个Thread对象均含有一个ThreadLocalMap类型的成员变量threadLocals,它存储本地线程中所有ThreadLocal对象及其对应的值。
ThreadLocalMap由一个个Entry对象构成
entry继承自WeakReference<ThreadLocal<?>>,一个Entry由ThreadLocal对象和Object构成,由此可见,Entry的key是ThreadLocal对象,并且是一个弱引用。当没有指向key的强引用后,该key就会被垃圾收集器回收。
当执行set方法时,ThreadLocal首先会获取当前线程对象,然后获取当前线程的ThreadLocalMap对象。再以当前ThreadLocal对象为key,将值存储进ThreadLocalMap对象中。
get方法执行过程类似。ThreadLocal首先会获取当前线程对象,然后获取当前线程的ThreadLocalMap对象。再以当前ThreadLocal对象为key,获取对应的value。
由于每一条线程均含有各自私有的ThreadLocalMap容器,这些容器相互独立互不影响,因此不会存在线程安全性问题,从而也无需使用同步机制来保证多条线程访问容器的互斥性。

首先 ThreadLocal 是一个泛型类,保证可以接受任何类型的对象。
因为一个线程内可以存在多个 ThreadLocal 对象,所以其实是 ThreadLocal 内部维护了一个 Map ,这个 Map 不是直接使用的 HashMap ,而是 ThreadLocal 实现的一个叫做 ThreadLocalMap 的静态内部类。而我们使用的 get()、set() 方法其实都是调用了这个ThreadLocalMap类对应的 get()、set() 方法
最终的变量是放在了当前线程的 ThreadLocalMap 中,并不是存在 ThreadLocal 上,ThreadLocal 可以理解为只是ThreadLocalMap的封装,传递了变量值。

在ThreadLocalMap里面采用的是开放寻址法。
应用场景
1、在进行对象跨层传递的时候,使用ThreadLocal可以避免多次传递,打破层次间的约束
2、线程间数据隔离
3、进行事务操作,用于存储线程事务信息
4、数据库连接,Session回话管理
spring框架在事务开始时会给当前线程绑定一个Jdbc Connection,在整个事务过程都是使用该线程绑定的connection来执行数据库操作,实现了事务的隔离性。Spring框架里面就是用ThreadLocal来实现这种隔离的。
为什么ThreadLocalMap中的key要设计为弱引用?
Thread可能需要长时间运行(如线程池中的线程),如果key不再使用,需要在内存不足(GC)时释放其占用的内存。
但GC仅是让key的内存释放,后续还要根据key是否为null来进一步释放值的内存,释放时机有:
获取key发现null key,ThreadLocal在获取key 的时候,不同于其他的,如果没有的话,他会放一个key进去。
set key时,会使用启发式扫描,清除临近的null key,启发次数与元素个数,是否发现null key有关
remove时(推荐),因为一般使用ThreadLocal时都要把它作为静态变量,因此GC无法回收。
ThreadLocal内存泄漏原因,如何避免


ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用引用他,那么系统GC的时候,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话(比如正好用在线程池),这些key为null的Entry的value就会一直存在一条强引用链。
虽然弱引用,保证了key指向的ThreadLocal对象能被及时回收,但是v指向的value对象是需要ThreadLocal调用get、set时发现key为null时才会去回收整个entry、value,因此弱引用不能100%保证内存不泄漏。我们要在不使用某个ThreadLocal对象后,手动调用remove方法来删除它,尤其是在线程池中,不仅仅是内存泄漏的问题,因为线程池中的线程是重复使用的,意味着这个线程的ThreadLocalMap对象也是重复使用的,如果我们不手动调用remove方法,那么后面的线程就有可能获取到上个线程遗留下来的value值,造成bug。
博客:ThreadLocal的内存泄露?什么原因?如何避免? - 知乎
ThreadLocal原理,内存泄漏问题,怎么解决 - Lucky小黄人^_^ - 博客园
ThreadLocal的内存泄漏问题

可以看到,Entry继承自WeakReference<ThreadLocal<?>>,``Entry的 key是ThreadLocal对象引用,这个引用是一个弱引用。当没指向 key 的强引用后,该key就会被垃圾收集器回收。
在ThreadLocalMap中,entry的key是弱引用,value仍然是一个强引用。当某一条线程中的ThreadLocal使用完毕,没有强引用指向它的时候,这个key指向的对象就会被垃圾收集器回收,从而这个key就变成了null;所以entry就变成了(null, value), 而entry 和 value 都是强引用,并且只要entry还在,value就一直存在。所以如果我们不手动清理掉这些键为空的entry, 在线程执行完毕之前,这个entry就一直处于内存泄漏的状态。线程生命周期越长,内存泄漏的就越多。
ThreadLocal内存泄漏的解决办法
每次操作set、get、remove操作时,会相应调用 ThreadLocalMap 的三个方法,ThreadLocalMap的三个方法在每次被调用时 都会直接或间接调用一个 expungeStaleEntry() 方法,这个方法会将key为null的 Entry 删除,从而避免内存泄漏。

那么问题又来了,如果一个线程运行周期较长,而且将一个大对象放入LocalThreadMap后便不再调用set、get、remove方法仍然有可能key的弱引用被回收后,引用没有被回收,此时该仍然可能会导致内存泄漏。
这个问题确实存在,没办法通过ThreadLocal解决,而是需要程序员在完成ThreadLocal的使用后要养成手动调用remove的习惯,从而避免内存泄漏。
11、并发容器之BlockingQueue详解
什么是阻塞队列?阻塞队列的实现原理是什么?如何使用阻塞队列来实现生产者-消费者模型?
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。
这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。
阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
JDK7 提供了 7 个阻塞队列。分别是:
ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。
PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
DelayQueue:一个使用优先级队列实现的无界阻塞队列。
SynchronousQueue:一个不存储元素的阻塞队列。
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
Java 5 之前实现同步存取时,可以使用普通的一个集合,然后在使用线程的协作和线程同步可以实现生产者,消费者模式,主要的技术就是用好,wait,notify,notifyAll,sychronized 这些关键字。而在 java 5 之后,可以使用阻塞队列来实现,此方式大大简少了代码量,使得多线程编程更加容易,安全方面也有保障。
BlockingQueue 接口是 Queue 的子接口,它的主要用途并不是作为容器,而是作为线程同步的的工具,因此他具有一个很明显的特性,当生产者线程试图向 BlockingQueue 放入元素时,如果队列已满,则线程被阻塞,当消费者线程试图从中取出一个元素时,如果队列为空,则该线程会被阻塞,正是因为它所具有这个特性,所以在程序中多个线程交替向 BlockingQueue 中放入元素,取出元素,它可以很好的控制线程之间的通信。
阻塞队列使用最经典的场景就是 socket 客户端数据的读取和解析,读取数据的线程不断将数据放入队列,然后解析线程不断从队列取数据解析。
12、锁
公平锁和非公平锁
公平锁:是指多个线程按照申请锁的顺序来获取锁,类似排队打饭,先来后到。
非公平锁:是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁,在高并发的情况下,有可能会造成优先级反转或者饥饿现象。
并发包中ReentrantLock的创建可以指定构造函数的boolean类型来得到公平锁或非公平锁,默认是非公平锁。
区别:就是很公平,在并发环境中,每个线程在获取锁时会先查看此锁维护的等待队列。如果为空,或者当前线程是等待队列的第一个,就占有锁,否则就会加入到等待队列中,以后会按照FIFO的规则从队列中取到自己。
非公平锁比较粗鲁,上来就直接尝试占有锁,如果尝试失败,就再采用类似公平锁那种方式。
java ReentrantLock而言:通过构造函数指定该锁是否是公平锁默认是非公平锁,非公平锁的优点在于吞吐量比公平锁大
对于synchronized而言,也是一种非公平锁。
可重入锁
指的是同一线程外层函数获得锁以后,内存递归函数仍然能获取该锁的代码,在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。
也即是说,线程可以进入任何一个它已经拥有的锁同步着的代码块。
Synchronized和ReentrantLock就是一个典型的可重入锁。
package cn.atguigu.interview.study.thread;
class Phone{
public synchronized void sendSms() throws Exception{
System.out.println(Thread.currentThread().getName()+"\tsendSms");
sendEmail();
}
public synchronized void sendEmail() throws Exception{
System.out.println(Thread.currentThread().getName()+"\tsendEmail");
}
}
/**
* Description:
* 可重入锁(也叫做递归锁)
* 指的是同一先生外层函数获得锁后,内层敌对函数任然能获取该锁的代码
* 在同一线程外外层方法获取锁的时候,在进入内层方法会自动获取锁
*
* 也就是说,线程可以进入任何一个它已经标记的锁所同步的代码块
*
* @author veliger@163.com
* @date 2019-04-12 23:36
**/
public class ReenterLockDemo {
/**
* t1 sendSms
* t1 sendEmail
* t2 sendSms
* t2 sendEmail
* @param args
*/
public static void main(String[] args) {
Phone phone = new Phone();
new Thread(()->{
try {
phone.sendSms();
} catch (Exception e) {
e.printStackTrace();
}
},"t1").start();
new Thread(()->{
try {
phone.sendSms();
} catch (Exception e) {
e.printStackTrace();
}
},"t2").start();
}
}
package cn.atguigu.interview.study.thread;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
class Phone implements Runnable {
private Lock lock = new ReentrantLock();
@Override
public void run() {
get();
}
private void get() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "\tget");
set();
} finally {
lock.unlock();
}
}
private void set() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "\tset");
} finally {
lock.unlock();
}
}
}
/**
* Description:
* 可重入锁(也叫做递归锁)
* 指的是同一先生外层函数获得锁后,内层敌对函数任然能获取该锁的代码
* 在同一线程外外层方法获取锁的时候,在进入内层方法会自动获取锁
* <p>
* 也就是说,线程可以进入任何一个它已经标记的锁所同步的代码块
*
* @author veliger@163.com
* @date 2019-04-12 23:36
**/
public class ReenterLockDemo {
/**
* Thread-0 get
* Thread-0 set
* Thread-1 get
* Thread-1 set
*
* @param args
*/
public static void main(String[] args) {
Phone phone = new Phone();
Thread t3 = new Thread(phone);
Thread t4 = new Thread(phone);
t3.start();
t4.start();
}
}自旋锁
是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
package com.systop.lsf.spike.leecode;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicReference;
public class SpinLockDemo {
//原子引用线程
AtomicReference<Thread> atomicReference = new AtomicReference<>();
public void myLock(){
Thread thread = Thread.currentThread();
System.out.println(Thread.currentThread().getName()+"\t come in 智子眩");
while(!atomicReference.compareAndSet(null,thread)){
}
}
public void myUnlock(){
Thread thread = Thread.currentThread();
atomicReference.compareAndSet(thread,null);
System.out.println(Thread.currentThread().getName()+"\t invoked myUnlock 智子眩");
}
public static void main(String[] package com.systop.lsf.spike.leecode;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicReference;
public class SpinLockDemo {
//原子引用线程
AtomicReference<Thread> atomicReference = new AtomicReference<>();
public void myLock(){
Thread thread = Thread.currentThread();
System.out.println(Thread.currentThread().getName()+"\t come in 智子眩");
while(!atomicReference.compareAndSet(null,thread)){
}
}
public void myUnlock(){
Thread thread = Thread.currentThread();
atomicReference.compareAndSet(thread,null);
System.out.println(Thread.currentThread().getName()+"\t invoked myUnlock 智子眩");
}
public static void main(String[] args) {
SpinLockDemo spinLockDemo = new SpinLockDemo();
new Thread(()->{
spinLockDemo.myLock();
try{
TimeUnit.SECONDS.sleep(5);
}catch (Exception e){
e.printStackTrace();
}
spinLockDemo.myUnlock();
},"AA").start();
try{
TimeUnit.SECONDS.sleep(1);
}catch (Exception e){
e.printStackTrace();
}
new Thread(()->{
spinLockDemo.myLock();
spinLockDemo.myUnlock();
},"BB").start();
}
}args) {
SpinLockDemo spinLockDemo = new SpinLockDemo();
new Thread(()->{
spinLockDemo.myLock();
try{
TimeUnit.SECONDS.sleep(5);
}catch (Exception e){
e.printStackTrace();
}
spinLockDemo.myUnlock();
},"AA").start();
try{
TimeUnit.SECONDS.sleep(1);
}catch (Exception e){
e.printStackTrace();
}
new Thread(()->{
spinLockDemo.myLock();
spinLockDemo.myUnlock();
},"BB").start();
}
}读锁和写锁
独占锁:指该锁一次只能被一个线程所持有。对ReentrantLock和synchronized而言都是独占锁
共享锁:指该锁可被多个线程所持有。
对ReentrantReadWriteLock其读锁是共享锁,其写锁是独占锁
读锁的共享锁可保证并发读是非常高效的,读写、写读,写写的过程是互斥的。
/**
* 资源类
*/
class MyCaChe {
/**
* 保证可见性
*/
private volatile Map<String, Object> map = new HashMap<>();
private ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock();
/**
* 写
*
* @param key
* @param value
*/
public void put(String key, Object value) {
reentrantReadWriteLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "\t正在写入" + key);
//模拟网络延时
try {
TimeUnit.MICROSECONDS.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "\t正在完成");
} finally {
reentrantReadWriteLock.writeLock().unlock();
}
}
/**
* 读
*
* @param key
*/
public void get(String key) {
reentrantReadWriteLock.readLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "\t正在读取");
//模拟网络延时
try {
TimeUnit.MICROSECONDS.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
Object result = map.get(key);
System.out.println(Thread.currentThread().getName() + "\t正在完成" + result);
} finally {
reentrantReadWriteLock.readLock().unlock();
}
}
public void clearCaChe() {
map.clear();
}
}
/**
* Description:
* 多个线程同时操作 一个资源类没有任何问题 所以为了满足并发量
* 读取共享资源应该可以同时进行
* 但是
* 如果有一个线程想去写共享资源来 就不应该有其他线程可以对资源进行读或写
* <p>
* 小总结:
* 读 读能共存
* 读 写不能共存
* 写 写不能共存
* 写操作 原子+独占 整个过程必须是一个完成的统一整体 中间不允许被分割 被打断
*
* @author veliger@163.com
* @date 2019-04-13 0:45
**/
public class ReadWriteLockDemo {
public static void main(String[] args) {
MyCaChe myCaChe = new MyCaChe();
for (int i = 1; i <= 5; i++) {
final int temp = i;
new Thread(() -> {
myCaChe.put(temp + "", temp);
}, String.valueOf(i)).start();
}
for (int i = 1; i <= 5; i++) {
int finalI = i;
new Thread(() -> {
myCaChe.get(finalI + "");
}, String.valueOf(i)).start();
}
}
}13、常用的并发工具类有哪些?
public class CyclicBarrierDemo {
public static void main(String[] args) {
CyclicBarrier cyclicBarrier=new CyclicBarrier(7,()->{
System.out.println("召唤神龙");
});
for (int i = 1; i <=7; i++) {
final int temp = i;
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"\t 收集到第"+ temp +"颗龙珠");
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
},String.valueOf(i)).start();
}
}
}①. 在 Java 中 CycliBarriar 和 CountdownLatch 有什么区别?
CountDownLatch与CyclicBarrier都是用于控制并发的工具类,都可以理解成维护的就是一个计数器,但是这两者还是各有不同侧重点的:
-
CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;CountDownLatch强调一个线程等多个线程完成某件事情。CyclicBarrier是多个线程互等,等大家都完成,再携手共进。
-
调用CountDownLatch的countDown方法后,当前线程并不会阻塞,会继续往下执行;而调用CyclicBarrier的await方法,会阻塞当前线程,直到CyclicBarrier指定的线程全部都到达了指定点的时候,才能继续往下执行;
-
CountDownLatch方法比较少,操作比较简单,而CyclicBarrier提供的方法更多,比如能够通过getNumberWaiting(),isBroken()这些方法获取当前多个线程的状态,并且CyclicBarrier的构造方法可以传入barrierAction,指定当所有线程都到达时执行的业务功能;
-
CountDownLatch是不能复用的,而CyclicLatch是可以复用的。
semaPhore
Semaphore 就是一个信号量,它的作用是限制某段代码块的并发数。Semaphore有一个构造函数,可以传入一个 int 型整数 n,表示某段代码最多只有 n 个线程可以访问,如果超出了 n,那么请等待,等到某个线程执行完毕这段代码块,下一个线程再进入。由此可以看出如果 Semaphore 构造函数中传入的 int 型整数 n=1,相当于变成了一个 synchronized 了。
** Semaphore(信号量)-允许多个线程同时访问:** synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。
14、阻塞队列
阻塞队列,顾名思义,首先它是一个队列,而一个阻塞队列在数据结构中所起的作用大致如图所示:

当阻塞队列是空时,从队列中获取元素的操作将会被阻塞. 当阻塞队列是满时,往队列中添加元素的操作将会被阻塞. 同样 试图往已满的阻塞队列中添加新圆度的线程同样也会被阻塞,知道其他线程从队列中移除一个或者多个元素或者全清空队列后使队列重新变得空闲起来并后续新增.
BlockingQueue核心方法

1、抛出异常 当阻塞队列满时,再往队列里面add插入元素会抛IllegalStateException: Queue full 当阻塞队列空时,再往队列Remove元素时候回抛出NoSuchElementException 2、特殊值 插入方法,成功返回true 失败返回false 移除方法,成功返回元素,队列里面没有就返回null 3、一直阻塞 当阻塞队列满时,生产者继续往队列里面put元素,队列会一直阻塞直到put数据or响应中断退出 当阻塞队列空时,消费者试图从队列take元素,队列会一直阻塞消费者线程直到队列可用. 4、超时退出 当阻塞队列满时,队列会阻塞生产者线程一定时间,超过后限时后生产者线程就会退出
好处
在多线程领域:所谓阻塞,在某些情况下会挂起线程(即线程阻塞),一旦条件满足,被挂起的线程优惠被自动唤醒
为什么需要使用BlockingQueue
好处是我们不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,因为BlockingQueue都一手给你包办好了
在concurrent包 发布以前,在多线程环境下,我们每个程序员都必须自己去控制这些细节,尤其还要兼顾效率和线程安全,而这会给我们的程序带来不小的复杂度.

1. ArrayBlockingQueue
基于数组的阻塞队列实现,在ArrayBlockingQueue内部,维护了一个定长数组,以便缓存队列中的数据对象,这是一个常用的阻塞队列,除了一个定长数组外,ArrayBlockingQueue内部还保存着两个整形变量,分别标识着队列的头部和尾部在数组中的位置。
ArrayBlockingQueue在生产者放入数据和消费者获取数据,都是共用同一个锁对象,由此也意味着两者无法真正并行运行,这点尤其不同于LinkedBlockingQueue;按照实现原理来分析,ArrayBlockingQueue完全可以采用分离锁,从而实现生产者和消费者操作的完全并行运行。Doug Lea之所以没这样去做,也许是因为ArrayBlockingQueue的数据写入和获取操作已经足够轻巧,以至于引入独立的锁机制,除了给代码带来额外的复杂性外,其在性能上完全占不到任何便宜。 ArrayBlockingQueue和LinkedBlockingQueue间还有一个明显的不同之处在于,前者在插入或删除元素时不会产生或销毁任何额外的对象实例,而后者则会生成一个额外的Node对象。这在长时间内需要高效并发地处理大批量数据的系统中,其对于GC的影响还是存在一定的区别。而在创建ArrayBlockingQueue时,我们还可以控制对象的内部锁是否采用公平锁,默认采用非公平锁。
2.LinkedBlockingQueue
基于链表的阻塞队列,同ArrayListBlockingQueue类似,其内部也维持着一个数据缓冲队列(该队列由一个链表构成),当生产者往队列中放入一个数据时,队列会从生产者手中获取数据,并缓存在队列内部,而生产者立即返回;只有当队列缓冲区达到最大值缓存容量时(LinkedBlockingQueue可以通过构造函数指定该值),才会阻塞生产者队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒,反之对于消费者这端的处理也基于同样的原理。而LinkedBlockingQueue之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
作为开发者,我们需要注意的是,如果构造一个LinkedBlockingQueue对象,而没有指定其容量大小,LinkedBlockingQueue会默认一个类似无限大小的容量(Integer.MAX_VALUE),这样的话,如果生产者的速度一旦大于消费者的速度,也许还没有等到队列满阻塞产生,系统内存就有可能已被消耗殆尽了。
ArrayBlockingQueue和LinkedBlockingQueue是两个最普通也是最常用的阻塞队列,一般情况下,在处理多线程间的生产者消费者问题,使用这两个类足以。
代码
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
//测试类
public class BlockingQueueTest {
public static void main(String[] args) throws InterruptedException {
// 声明一个容量为10的缓存队列
BlockingQueue<String> queue = new LinkedBlockingQueue<String>(10);
//new了三个生产者和一个消费者
Producer producer1 = new Producer(queue);
Producer producer2 = new Producer(queue);
Producer producer3 = new Producer(queue);
Consumer consumer = new Consumer(queue);
// 借助Executors
ExecutorService service = Executors.newCachedThreadPool();
// 启动线程
service.execute(producer1);
service.execute(producer2);
service.execute(producer3);
service.execute(consumer);
// 执行10s
Thread.sleep(10 * 1000);
producer1.stop();
producer2.stop();
producer3.stop();
Thread.sleep(2000);
// 退出Executor
service.shutdown();
}
}
//生产者类
import java.util.Random;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 生产者线程
*
* @author jackyuj
*/
public class Producer implements Runnable {
private volatile boolean isRunning = true;//是否在运行标志
private BlockingQueue queue;//阻塞队列
private static AtomicInteger count = new AtomicInteger();//自动更新的值
private static final int DEFAULT_RANGE_FOR_SLEEP = 1000;
//构造函数
public Producer(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
String data = null;
Random r = new Random();
System.out.println("启动生产者线程!");
try {
while (isRunning) {
System.out.println("正在生产数据...");
Thread.sleep(r.nextInt(DEFAULT_RANGE_FOR_SLEEP));//取0~DEFAULT_RANGE_FOR_SLEEP值的一个随机数
data = "data:" + count.incrementAndGet();//以原子方式将count当前值加1
System.out.println("将数据:" + data + "放入队列...");
if (!queue.offer(data, 2, TimeUnit.SECONDS)) {//设定的等待时间为2s,如果超过2s还没加进去返回true
System.out.println("放入数据失败:" + data);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
} finally {
System.out.println("退出生产者线程!");
}
}
public void stop() {
isRunning = false;
}
}
//消费者类
import java.util.Random;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;
/**
* 消费者线程
*
* @author jackyuj
*/
public class Consumer implements Runnable {
private BlockingQueue<String> queue;
private static final int DEFAULT_RANGE_FOR_SLEEP = 1000;
//构造函数
public Consumer(BlockingQueue<String> queue) {
this.queue = queue;
}
public void run() {
System.out.println("启动消费者线程!");
Random r = new Random();
boolean isRunning = true;
try {
while (isRunning) {
System.out.println("正从队列获取数据...");
String data = queue.poll(2, TimeUnit.SECONDS);//有数据时直接从队列的队首取走,无数据时阻塞,在2s内有数据,取走,超过2s还没数据,返回失败
if (null != data) {
System.out.println("拿到数据:" + data);
System.out.println("正在消费数据:" + data);
Thread.sleep(r.nextInt(DEFAULT_RANGE_FOR_SLEEP));
} else {
// 超过2s还没数据,认为所有生产线程都已经退出,自动退出消费线程。
isRunning = false;
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
} finally {
System.out.println("退出消费者线程!");
}
}
}SynchronousQueue
一种无缓冲的等待队列,类似于无中介的直接交易,有点像原始社会中的生产者和消费者,生产者拿着产品去集市销售给产品的最终消费者,而消费者必须亲自去集市找到所要商品的直接生产者,如果一方没有找到合适的目标,那么对不起,大家都在集市等待。相对于有缓冲的BlockingQueue来说,少了一个中间经销商的环节(缓冲区),如果有经销商,生产者直接把产品批发给经销商,而无需在意经销商最终会将这些产品卖给那些消费者,由于经销商可以库存一部分商品,因此相对于直接交易模式,总体来说采用中间经销商的模式会吞吐量高一些(可以批量买卖);但另一方面,又因为经销商的引入,使得产品从生产者到消费者中间增加了额外的交易环节,单个产品的及时响应性能可能会降低。
声明一个SynchronousQueue有两种不同的方式,它们之间有着不太一样的行为。公平模式和非公平模式的区别:
如果采用公平模式:SynchronousQueue会采用公平锁,并配合一个FIFO队列来阻塞多余的生产者和消费者,从而体系整体的公平策略;
但如果是非公平模式(SynchronousQueue默认):SynchronousQueue采用非公平锁,同时配合一个LIFO队列来管理多余的生产者和消费者,而后一种模式,如果生产者和消费者的处理速度有差距,则很容易出现饥渴的情况,即可能有某些生产者或者是消费者的数据永远都得不到处理。
SynchronousQueue没有容量
与其他BlcokingQueue不同,SynchronousQueue是一个不存储元素的BlcokingQueue
每个put操作必须要等待一个take操作,否则不能继续添加元素,反之亦然.
/**
* Description
* 阻塞队列SynchronousQueue演示
*
* @author veliger@163.com
* @version 1.0
* @date 2019-04-13 13:49
**/
public class SynchronousQueueDemo {
public static void main(String[] args) {
BlockingQueue<String> blockingQueue = new SynchronousQueue<>();
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + "\t put 1");
blockingQueue.put("1");
System.out.println(Thread.currentThread().getName() + "\t put 2");
blockingQueue.put("2");
System.out.println(Thread.currentThread().getName() + "\t put 3");
blockingQueue.put("3");
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "AAA").start();
new Thread(() -> {
try {
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "\t" + blockingQueue.take());
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "\t" + blockingQueue.take());
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "\t" + blockingQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "BBB").start();
}
}15、AQS
是什么?AbstractQueuedSynchronizer 抽象队列同步器。
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
是用来构建锁或者其它同步器组件的重量级基础框架及整个JUC体系的基石,通过内置的FIFO队列来完成资源获取线程的排队工作,并通过一个int类型变量表示持有锁的状态。

CLH:Craig、Landin and Hagersten队列,是一个单向链表,AQS中的队列是CLH变体的虚拟双向队列FIFO。
AQS能干嘛
AQS为什么是JUC内容中最重要的基石?
和AQS有关的

进一步理解锁和同步器的关系
-
锁,面向锁的使用者 - 定义了程序员和锁交互的使用层APl,隐藏了实现细节,你调用即可
-
同步器,面向锁的实现者 - 比如Java并发大神DougLee,提出统一规范并简化了锁的实现,屏蔽了同步状态管理、阻塞线程排队和通知、唤醒机制等。
能干嘛?
加锁会导致阻塞 - 有阻塞就需要排队,实现排队必然需要有某种形式的队列来进行管理
解释说明
抢到资源的线程直接使用处理业务逻辑,抢不到资源的必然涉及一种排队等候机制。抢占资源失败的线程继续去等待(类似银行业务办理窗口都满了,暂时没有受理窗口的顾客只能去候客区排队等候),但等候线程仍然保留获取锁的可能且获取锁流程仍在继续(候客区的顾客也在等着叫号,轮到了再去受理窗口办理业务)。
既然说到了排队等候机制,那么就一定会有某种队列形成,这样的队列是什么数据结构呢?
如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是CLH队列的变体实现的,将暂时获取不到锁的线程加入到队列中,这个队列就是AQS的抽象表现。它将请求共享资源的线程封装成队列的结点(Node),通过CAS、自旋以及LockSupportpark)的方式,维护state变量的状态,使并发达到同步的控制效果。
AQS源码体系-上
Provides a framework for implementing blocking locks and related synchronizers (semaphores, events, etc) that rely on first-in-first-out (FIFO) wait queues. This class is designed to be a useful basis for most kinds of synchronizers that rely on a single atomic int value to represent state. Subclasses must define the protected methods that change this state, and which define what that state means in terms of this object being acquired or released. Given these, the other methods in this class carry out all queuing and blocking mechanics. Subclasses can maintain other state fields, but only the atomically updated int value manipulated using methods getState(), setState(int) and compareAndSetState(int, int) is tracked with respect to synchronization. AbstractQueuedSynchronizer (Java Platform SE 8 ) 提供一个框架来实现阻塞锁和依赖先进先出(FIFO)等待队列的相关同步器(信号量、事件等)。此类被设计为大多数类型的同步器的有用基础,这些同步器依赖于单个原子“int”值来表示状态。子类必须定义更改此状态的受保护方法,以及定义此状态在获取或释放此对象方面的含义。给定这些,这个类中的其他方法执行所有排队和阻塞机制。子类可以维护其他状态字段,但是只有使用方法getState()、setState(int)和compareAndSetState(int,int)操作的原子更新的’int’值在同步方面被跟踪。
有阻塞就需要排队,实现排队必然需要队列
AQS使用一个volatile的int类型的成员变量来表示同步状态,通过内置的FIFo队列来完成资源获取的排队工作将每条要去抢占资源的线程封装成一个Node,节点来实现锁的分配,通过CAS完成对State值的修改。
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
private static final long serialVersionUID = 7373984972572414691L;
* Creates a new {@code AbstractQueuedSynchronizer} instance
protected AbstractQueuedSynchronizer() { }
* Wait queue node class.
static final class Node {
* Head of the wait queue, lazily initialized. Except for
private transient volatile Node head;
* Tail of the wait queue, lazily initialized. Modified only via
private transient volatile Node tail;
* The synchronization state.
private volatile int state;
* Returns the current value of synchronization state.
protected final int getState() {
* Sets the value of synchronization state.
protected final void setState(int newState) {
* Atomically sets synchronization state to the given updated
protected final boolean compareAndSetState(int expect, int update) {
...
}AQS自身
1)、AQS的int变量 - AQS的同步状态state成员变量 private volatile int state;
state成员变量相当于银行办理业务的受理窗口状态。
-
零就是没人,自由状态可以办理
-
大于等于1,有人占用窗口,等着去
2)、AQS的CLH队列
-
CLH队列(三个大牛的名字组成),为一个双向队列
-
银行候客区的等待顾客
The wait queue is a variant of a “CLH” (Craig, Landin, and Hagersten) lock queue. CLH locks are normally used forspinlocks. We instead use them for blocking synchronizers, butuse the same basic tactic of holding some of the controlinformation about a thread in the predecessor of its node. A"status" field in each node keeps track of whether a threadshould block. A node is signalled when its predecessorreleases. Each node of the queue otherwise serves as aspecific-notification-style monitor holding a single waiting thread. The status field does NOT control whether threads aregranted locks etc though. A thread may try to acquire if it isfirst in the queue. But being first does not guarantee success;it only gives the right to contend. So the currently releasedcontender thread may need to rewait. To enqueue into a CLH lock, you atomically splice it in as new tail. To dequeue, you just set the head field. 本段文字出自AbstractQueuedSynchronizer内部类Node源码注释 等待队列是“CLH”(Craig、Landin和Hagersten)锁队列的变体。CLH锁通常用于旋转锁。相反,我们使用它们来阻止同步器,但是使用相同的基本策略,即在其节点的前一个线程中保存一些关于该线程的控制信息。每个节点中的“status”字段跟踪线程是否应该阻塞。当一个节点的前一个节点释放时,它会发出信号。否则,队列的每个节点都充当一个特定的通知样式监视器,其中包含一个等待线程。状态字段并不控制线程是否被授予锁等。如果线程是队列中的第一个线程,它可能会尝试获取。但是,第一并不能保证成功,它只会给人争取的权利。因此,当前发布的内容线程可能需要重新等待。
小总结
-
有阻塞就需要排队,实现排队必然需要队列
-
state变量+CLH变种的双端队列
AbstractQueuedSynchronizer内部类Node源码

AQS源码深度解读
从ReentrantLock开始解读AQS,Lock接口的实现类,基本都是通过聚合了一个队列同步器的子类完成线程访问控制的。
public class ReentrantLock implements Lock, java.io.Serializable {
private static final long serialVersionUID = 7373984872572414699L;
/** Synchronizer providing all implementation mechanics */
private final Sync sync;
/**
* Base of synchronization control for this lock. Subclassed
* into fair and nonfair versions below. Uses AQS state to
* represent the number of holds on the lock.
*/
abstract static class Sync extends AbstractQueuedSynchronizer {

16、volatile
它是java虚拟机提供的轻量级同步机制:保证可见性、不保证原子性、禁止指令重排。
JMM内存模型之可见性
JMM(Java内存模型Java Memory Model,简称JMM)本身是一种抽象的概念并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。
JMM关于同步的规定:
-
线程解锁前,必须把共享变量的值刷新回主内存
-
线程加锁前,必须读取主内存的最新值到自己的工作内存
-
加锁解锁是同一把锁
由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),工作内存是每个线程的私有数据区域,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝的自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量,各个线程中的工作内存中存储着主内存中的变量副本拷贝,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成,其简要访问过程如下图:
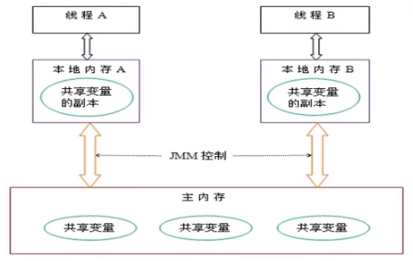
可见性的代码验证说明
import java.util.concurrent.TimeUnit;
/**
* 假设是主物理内存
*/
class MyData {
//volatile int number = 0;
int number = 0;
public void addTo60() {
this.number = 60;
}
}
/**
* 验证volatile的可见性
* 1. 假设int number = 0, number变量之前没有添加volatile关键字修饰
*/
public class VolatileDemo {
public static void main(String args []) {
// 资源类
MyData myData = new MyData();
// AAA线程 实现了Runnable接口的,lambda表达式
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t come in");
// 线程睡眠3秒,假设在进行运算
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 修改number的值
myData.addTo60();
// 输出修改后的值
System.out.println(Thread.currentThread().getName() + "\t update number value:" + myData.number);
}, "AAA").start();
// main线程就一直在这里等待循环,直到number的值不等于零
while(myData.number == 0) {}
// 按道理这个值是不可能打印出来的,因为主线程运行的时候,number的值为0,所以一直在循环
// 如果能输出这句话,说明AAA线程在睡眠3秒后,更新的number的值,重新写入到主内存,并被main线程感知到了
System.out.println(Thread.currentThread().getName() + "\t mission is over");
}
}可见性
通过前面对JMM的介绍,我们知道各个线程对主内存中共享变量的操作都是各个线程各自拷贝到自己的工作内存进行操作后再写回到主内存中的。
这就可能存在一个线程AAA修改了共享变量X的值但还未写回主内存时,另外一个线程BBB又对主内存中同一个共享变量X进行操作,但此时A线程工作内存中共享变量x对线程B来说并不可见,这种工作内存与主内存同步延迟现象就造成了可见性问题
volatile不保证原子性
原子性指的是什么意思?
不可分割,完整性,也即某个线程正在做某个具体业务时,中间不可以被加塞或者被分割。需要整体完整要么同时成功,要么同时失败。
volatile不保证原子性案例演示:
class MyData2 {
/**
* volatile 修饰的关键字,是为了增加 主线程和线程之间的可见性,只要有一个线程修改了内存中的值,其它线程也能马上感知
*/
volatile int number = 0;
public void addPlusPlus() {
number ++;
}
}
public class VolatileAtomicityDemo {
public static void main(String[] args) {
MyData2 myData = new MyData2();
// 创建10个线程,线程里面进行1000次循环
for (int i = 0; i < 20; i++) {
new Thread(() -> {
// 里面
for (int j = 0; j < 1000; j++) {
myData.addPlusPlus();
}
}, String.valueOf(i)).start();
}
// 需要等待上面20个线程都计算完成后,在用main线程取得最终的结果值
// 这里判断线程数是否大于2,为什么是2?因为默认是有两个线程的,一个main线程,一个gc线程
while(Thread.activeCount() > 2) {
// yield表示不执行
Thread.yield();
}
// 查看最终的值
// 假设volatile保证原子性,那么输出的值应该为: 20 * 1000 = 20000
System.out.println(Thread.currentThread().getName() + "\t finally number value: " + myData.number);
}
} 
如何解决原子性?
1、加synchronized
2、使用我们juc下的AtomicInteger
指令重排

volatile指令重排案例2
观察下面程序:
public class ReSortSeqDemo{
int a = 0;
boolean flag = false;
public void method01(){
a = 1;//语句1
flag = true;//语句2
}
public void method02(){
if(flag){
a = a + 5; //语句3
}
System.out.println("retValue: " + a);//可能是6或1或5或0
}
}多线程环境中线程交替执行method01()和method02(),由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。
禁止指令重排小总结
volatile实现禁止指令重排优化,从而避免多线程环境下程序出现乱序执行的现象
先了解一个概念,内存屏障(Memory Barrier)又称内存栅栏,是一个CPU指令,它的作用有两个:
保证特定操作的执行顺序, 保证某些变量的内存可见性(利用该特性实现volatile的内存可见性)。 由于编译器和处理器都能执行指令重排优化。如果在指令间插入一条Memory Barrier则会告诉编译器和CPU,不管什么指令都不能和这条Memory Barrier指令重排序,也就是说通过插入内存屏障禁止在内存屏障前后的指令执行重排序优化。内存屏障另外一个作用是强制刷出各种CPU的缓存数据,因此任何CPU上的线程都能读取到这些数据的最新版本。
对volatile变量进行写操作时,会在写操作后加入一条store屏障指令,将工作内存中的共享变量值刷新回到主内存。
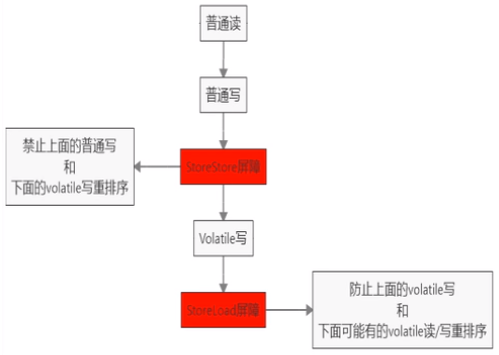
对Volatile变量进行读操作时,会在读操作前加入一条load屏障指令,从主内存中读取共享变量。
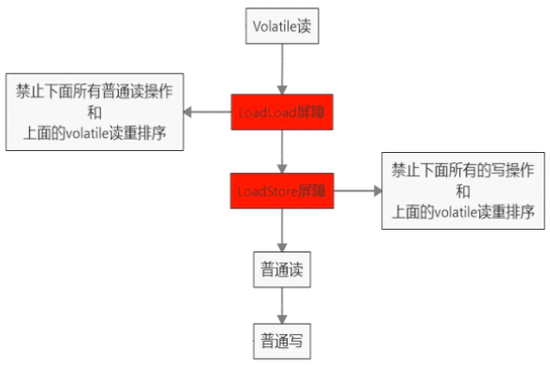
线性安全性获得保证
工作内存与主内存同步延迟现象导致的可见性问题 - 可以使用synchronized或volatile关键字解决,它们都可以使一个线程修改后的变量立即对其他线程可见。
对于指令重排导致的可见性问题和有序性问题 - 可以利用volatile关键字解决,因为volatile的另外一个作用就是禁止重排序优化。
17、sleep、wait、join、yield
锁池:所有需要竞争同步锁(synchronized)的线程都会放在锁池中,比如当前对象的锁已经被其中一个线程得到,则其他线程需要在这个锁池进行等待,当前面的线程释放同步锁后锁池中的线程去竞争同步锁,当某个线程得到后会进入到就绪队列中进行等待CPU的资源分配。
等待池:当我们调用wait()方法后,线程会放到等待池中,等待池的线程是不会去竞争同步锁。只有调用了notify()或notifyAll()后等待池中的线程才会开始去竞争锁,notify()是随机从等待池中选出一个线程放到锁池中,而notifyAll()是将等待池中的所有线程放到锁池中。
区别:
1、sleep是Thread类的静态本地方法,wait则是Object类的本地方法
2、sleep方法不会释放lock,但是wait会释放,而且会加入到等待队列中
//sleep就是把CPU的执行资格和执行权释放出去,不再运行此线程,当一定时间结束后再取回CPU资源,参与CPU的调度,获取到CPU资源后就可以继续运行了。而如果sleep时该线程持有锁,那么sleep不会释放这个锁,而是把锁带着进入了冻结状态,也就是说其他需要这个锁的线程根本不可能获取到这个锁,也就是无法执行程序。如果在睡眠期间其他线程调用了这个线程的interrupt方法,那么这个线程也会抛出interruptexception异常返回,这点和wait是一样的。
3、yield()执行后线程直接进入就绪状态,马上释放了CPU的执行权,但是依然保留了CPU的执行资格,所以有可能CPU下次进行线程调度还会让这个线程获取到执行权继续执行。
4、join()执行后线程进入阻塞状态,例如在线程B中调用线程A的join(),那线程 B会进入到阻塞队列,直到线程A结束或中断状态。
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(3000);
}catch (Exception e){
e.printStackTrace();
}
System.out.println("22222222");
}
});
t1.start();
t1.join();
//这行代码必须要等t1全部执行完毕,才会执行
System.out.println("11111");
}18、线程池
为什么要用线程池
1、降低资源的消耗;提高线程利用率,降低创建和销毁线程的消耗
2、提高响应速度;任务来了,直接有线程可用可执行,而不是先创建线程,再执行
3、提高线程的可管理性;线程是稀缺资源,使用线程池可以统一分配调优监控。
线程池的七大核心参数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler){
}
/**
int corePoolSize, 核心线程数;线程池创建好以后就准备就绪的线程数量,就等待来接受异步任务去执行。这些线程创建后并不会消除,而是一种常驻线程。
int maximumPoolSize,最大线程数量,控制资源并发。它与核心线程数相对应,表示最大允许被创建的线程数,比如当前任务较多,将核心线程数都用完了,还无法满足需求时,此时就会创建新的线程,但是线程池内线程总数不会超过最大线程数。
long keepAliveTime,存活时间,表示超出核心线程数之外的线程的空闲存活时间,也就是核心线程不会消除,但是超出核心线程数的部分线程如果空闲一定的时间则会被消除,我们可以通过setKeepAliveTime来设置空闲时间。
TimeUnit unit,时间单位
BlockingQueue<Runnable> workQueue, 阻塞队列,如果任务有很多,就会将目前多的任务放在队列里面,只要有线程空闲,就会去队列里面取出新的任务继续执行。假设我们现在核心线程都已经被使用,还有任务进来则全部放入队列,直到整个队列被放满但任务还在继续进入则会开始创建新的线程。
ThreadFactory threadFactory,线程的创建工厂
RejectedExecutionHandler handler,如果队列满了,按照我们指定的拒绝策略,拒绝执行任务
**/线程池的工作顺序
/**
工作顺序:
1、线程池创建,准备好core数量的核心线程,准备接受任务
1.1、core满了,就将再进来的任务放入阻塞队列中,空闲的core就会自己去阻塞队列获取任务执行
1.2、阻塞队列满了,就直接开新线程执行,最大只能开到max指定的数量
1.3、max都执行好了,Max-core数量空闲的线程会在keepAliveTime指定的时间后自动销毁,最终保持core的大小
1.4、如果线程数开到了max数量,还有新任务进来,就会使用reject指定的拒绝策略进行处理
2、所有的线程创建都是由指定的factory创建的
*/ 
线程池中的拒绝策略
等待队列也已经排满了,再也塞不下新的任务了同时,线程池的max也到达了,无法接续为新任务服务,这时我们需要拒绝策略机制合理的处理这个问题。
(1)、AbortPolicy(默认):直接抛出RejectedException异常阻止系统正常运行
(2)、CallerRunPolicy:“调用者运行”一种调节机制,该策略既不会抛弃任务,也不会抛出异常
(3)、DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交
(4)、DiscardPolicy:直接丢弃任务,不予任何处理也不抛出异常,如果允许丢失,这是最好的拒绝策略。
以上内置策略均实现了RejectExecutionHandler接口
线程池中实际用哪个

线程池中阻塞队列的作用?为什么是先添加队列而不是先创建最大线程?
为什么要使用阻塞队列而不是普通队列?
1、一般的队列只能保证作为一个有限长度的缓冲区,如果超出了缓冲的长度,就无法保留当前的任务了,阻塞队列通过阻塞可以保留住当前想要继续入队的任务。
阻塞队列可以保证任务队列中没有任务时阻塞获取任务的线程,使得线程进入了wait状态,释放cpu资源。
阻塞队列自带阻塞和唤醒的功能,不需要额外处理,无任务执行时,线程池利用阻塞队列的take方法挂起,从而保持核心线程的存活、不至于一直占用CPU资源
2、在创建新线程的时候,是要获取全局锁的,这个时候其他的就得阻塞,影响了整体新能。
//就好比一个企业里面有10个(core)正式工的名额,最多找10个正式工,要是任务超过正式工任务(task>core)的情况下,工厂领导(线程池)不是首先扩招工人,还是这10人,但是任务可以稍微积压一下,即先放到队列去(代价低)。10个正式工慢慢干,迟早会干完的,要是任务还在继续增加,超过正式工的加班忍耐极限了(队列满了),就的招外包帮忙了(注意是临时工)要是正式工加上外包还是不能完成任务,那新来的任务就会被领导拒绝了(线程池的拒绝策略)。
如果不采用队列的方式的话,来一个任务就创建一个线程,那执行完以后就会面临被回收,那么就会频繁的创建和销毁线程,这个不是线程池的初衷。把任务放到队列中代价比较小。最大线程数是为了应对峰值。
public void execute(Runnable command) {
if (command == null) //不能是空任务
throw new NullPointerException();
//如果还没有达到corePoolSize,则添加新线程来执行任务
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
//如果已经达到corePoolSize,则不断的向工作队列中添加任务
if (runState == RUNNING && workQueue.offer(command)) {
//线程池已经没有任务
if (runState != RUNNING || poolSize == 0)
ensureQueuedTaskHandled(command);
}
//如果线程池不处于运行中或者工作队列已经满了,但是当前的线程数量还小于允许最大的maximumPoolSize线程数量,则继续创建线程来执行任务
else if (!addIfUnderMaximumPoolSize(command))
//已达到最大线程数量,任务队列也已经满了,则调用饱和策略执行处理器
reject(command); // is shutdown or saturated
}
}
private boolean addIfUnderCorePoolSize(Runnable firstTask) {
Thread t = null;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
//更改几个重要的控制字段需要加锁
try {
//池里线程数量小于核心线程数量,并且还需要是运行时
if (poolSize < corePoolSize && runState == RUNNING)
t = addThread(firstTask);
} finally {
mainLock.unlock();
}
if (t == null)
return false;
t.start(); //创建后,立即执行该任务
return true;
}
private Thread addThread(Runnable firstTask) {
Worker w = new Worker(firstTask);
Thread t = threadFactory.newThread(w); //委托线程工厂来创建,具有相同的组、优先级、都是非后台线程
if (t != null) {
w.thread = t;
workers.add(w); //加入到工作者线程集合里
int nt = ++poolSize;
if (nt > largestPoolSize)
largestPoolSize = nt;
}
return t;
} 博客:Java 阻塞队列--BlockingQueue - 北极猩球 - 博客园
线程池execute()和submit()的区别
execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;
submit()方法用于提交需要返回值的任务。线程池会返回一个Future类型的对象,通过这个Future对象可以判断任务是否执行成功,并且可以通过
20、线程池中线程复用的原理
线程池将线程和任务进行解耦,线程就是线程、任务是任务,摆脱了之前通过Thread创建线程时的一个线程必须对应一个任务的限制。
在线程池中,同一个线程可以从阻塞队列中不断获取新任务来执行,其核心原理在于线程池对Thread进行了封装,并不是每次执行任务都会调用Tread.start()来创建新线程,而是让每个线程去执行一个“循环任务”,在这个“循环任务”中不停检查是否有任务需要被执行,如果有则直接执行,也就是调用任务中的run方法,将run方法当成一个普通方法执行,通过这种方式只使用固定的线程就将所有任务的run方法串联起来。
21、说说对守护线程的理解
守护线程是什么?
守护线程:为所有非守护线程提供服务的过程;任何一个守护线程都是整个JVM中所有非守护线程的保姆;
守护线程类类似于整个进程的一个默默无闻的小喽啰;它生死无关重要,却依赖整个进程而运行;哪天其他线程结束了,没有要执行的了,程序就结束了,理都没理守护线程,就把它中断了;
注意:由于守护线程的终止是自身无法控制的,因此千万不要把IO、File等重要操作逻辑分给它;因为它不靠谱。
守护线程的作用是什么?还有它的应用场景
举例:GC垃圾回收线程就是一个经典的守护线程,当我们的程序中不再有任何运行的Thread,程序就不会再产生垃圾,垃圾回收器也就无事可做,所以当垃圾回收线程是JVM上仅剩的线程时,垃圾回收线程会自动离开。它始终在低级别的状态中运行,用于实时监控和管理系统中的可回收资源。
场景一:为其他线程提供服务支持的情况;
场景二:或者在任何情况下,程序结束时,这个线程必须正常且立刻关闭,就可以作为守护线程来使用;反之,如果一个正在执行某个操作的线程必须要正确地关闭掉否则就会出现的后果的话,那么这个线程就不能是守护线程,而是用户线程。通常都是些关键的事务,比方说,数据库录入或者更新,这些操作都是不可中断的。
thread.setDaemon(true)必须在thread.start()之前设置,否则会跑出一个illegalThreadStateException异常。你不能把正在运行的常规线程设置为守护线程。
在Daemon线程中产生的新线程也是Daemon的
守护线程不能用于去访问固有资源,比如读写操作或者计算逻辑。因为它会在任何时候甚至在一个操作的中间发生中断。
22、并发的三大特性
并行、并发、串行的区别
并发:多个任务在同一个CPU核上,按细分的时间片轮流执行,从逻辑上来看那些任务是同时执行。两个队列一个咖啡机
并行:单位时间内,多个处理器或多核处理器同时处理多个任务,是真正意义上的同时进行。两个队列两个咖啡机
串行:有n个任务,由一个线程按顺序执行。由于任务、方法都在一个线程执行所以不存在线程不安全情况,也就不存在临界区的问题。一个队列一个咖啡机
并发允许两个任务彼此干扰。统一时间点、只有一个任务运行,交替执行


原子性
原子性是指在一个操作中CPU不可以在中途暂停然后再调度,即不被中断操作,要不全部执行完成,要不都不执行。就好比转账,从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元,往账户B加上1000元。2个操作必须全部完成。
private long count = 0;
public void calc(){
count++;
}
1、将count从主内存读到工作内存中的副本中
2、+1的运算
3、将结果写入工作内存
4、将工作内存的值刷回主存(什么时候刷入由操作系统决定,不确定的)
那程序中原子性是指的最小的操作单元,比如自增操作,它本身其实并不是原子性操作,分了三步的,包括读取变量的原始值、进行加1操作、写入工作内存。所以在多线程中,有可能一个线程还没有自增完,可能才执行到第二步,另一个线程就已经读取了值,导致结果错误。那如果我们能保证自增操作是一个原子性操作,那么就能保证其他线程读取到的一定是自增后的数据。
如何保证原子性
通过 synchronized 关键字保证原子性。 通过 Lock保证原子性。 通过 CAS保证原子性。
可见性
当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看到修改的值。

若两个线程在不同的CPU,那么线程1改变了i的值还没有刷新到主存,线程2又使用了i,那么这个值肯定还是之前的,线程1对变量的修改线程2没看到这就是不可见性。
//线程1
boolean stop = false;
while(!stop){
domething();
}
//线程2
stop = true;
//如果线程2改变了stop的值,线程1一定会停止吗?不一定。当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其它事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循坏下去。
如何保证可见性
通过 volatile 关键字保证可见性。 通过 内存屏障保证可见性。 通过 synchronized 关键字保证可见性。 通过Lock保证可见性。 通过 final 关键字保证可见性
有序性
虚拟机在进行代码编译时,对于哪些改变顺序之后不会对最终结果造成影响的代码,虚拟机不一定会按照我们写的代码的顺序来执行,有可能将他们重排序。实际上,对于有些代码进行重排序之后,虽然对变量的值没有造成影响,但有可能会出现线程安全问题。
int a = 0;
boolean flag = false;
public void write(){
a = 2; //1
flag = true;//2
}
public void multiply(){
if(flag){ //3
int ret = a*a;//4
}
}//write方法里的1和2做了重排序,线程1先对flag赋值为true,随后执行到线程2,热天直接计算出结果,再返回到线程1,这时候a才赋值为2,很明显迟了一步。
如何保证有序性
通过 volatile 关键字保证有序性。 通过 内存屏障保证有序性。 通过 synchronized关键字保证有序性。 通过Lock保证有序性。
四、java异常面试题
1)、Java异常架构与异常关键字
Java异常简介
Java异常是Java提供的一种识别及响应错误的一致性机制。 Java异常机制可以使程序中异常处理代码和正常业务代码分离,保证程序代码更加优雅,并提高程序健壮性。在有效使用异常的情况下,异常能清晰的回答what, where, why这3个问题:异常类型回答了“什么”被抛出,异常堆栈跟踪回答了“在哪”抛出,异常信息回答了“为什么”会抛出。
Java异常架构
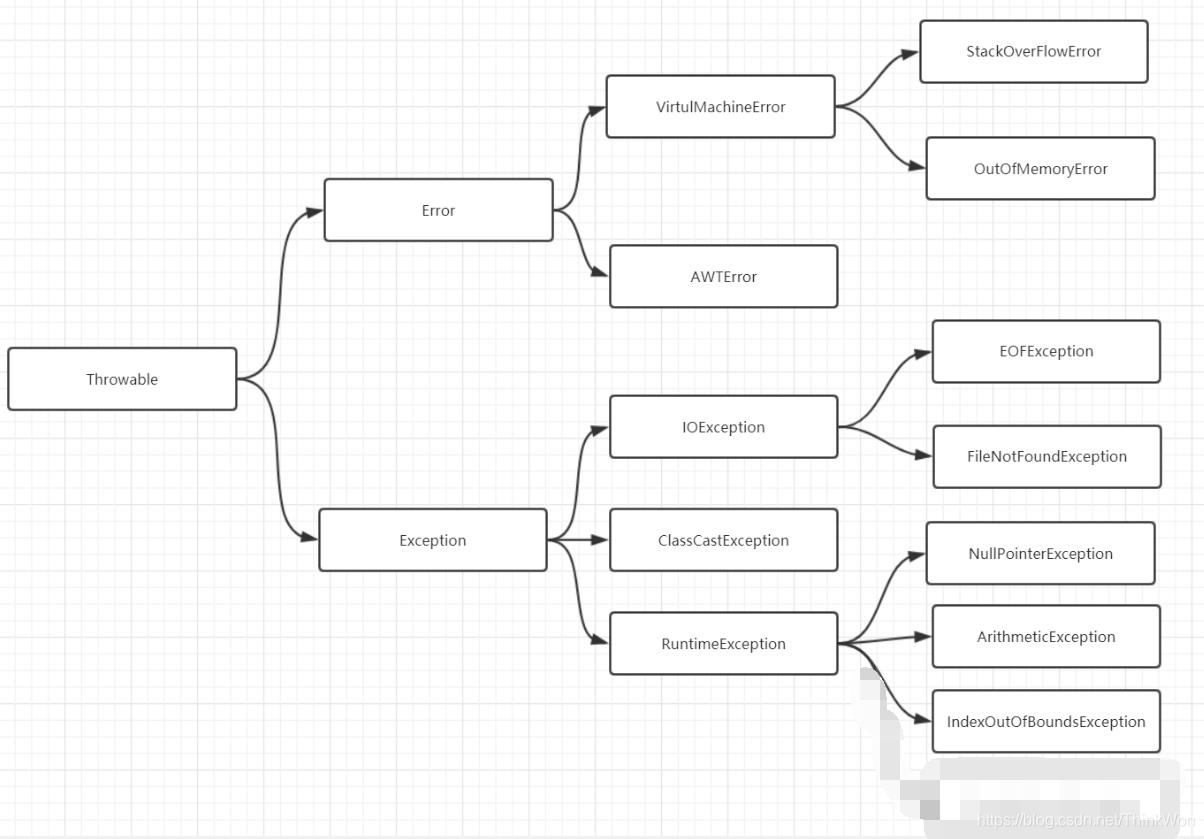
2)、Throwable
Throwable 是 Java 语言中所有错误与异常的超类。
Throwable 包含两个子类:Error(错误)和 Exception(异常),它们通常用于指示发生了异常情况。
Throwable 包含了其线程创建时线程执行堆栈的快照,它提供了 printStackTrace() 等接口用于获取堆栈跟踪数据等信息。
Error(错误)
定义:Error 类及其子类。程序中无法处理的错误,表示运行应用程序中出现了严重的错误。
特点:此类错误一般表示代码运行时 JVM 出现问题。通常有 Virtual MachineError(虚拟机运行错误)、NoClassDefFoundError(类定义错误)等。比如 OutOfMemoryError:内存不足错误;StackOverflowError:栈溢出错误。此类错误发生时,JVM 将终止线程。
这些错误是不受检异常,非代码性错误。因此,当此类错误发生时,应用程序不应该去处理此类错误。按照Java惯例,我们是不应该实现任何新的Error子类的!
Exception(异常)
程序本身可以捕获并且可以处理的异常。Exception 这种异常又分为两类:运行时异常和编译时异常。
(1)、运行时异常
定义:RuntimeException 类及其子类,表示 JVM 在运行期间可能出现的异常。
特点:Java 编译器不会检查它。也就是说,当程序中可能出现这类异常时,倘若既"没有通过throws声明抛出它",也"没有用try-catch语句捕获它",还是会编译通过。
比如:NullPointerException空指针异常、ArrayIndexOutBoundException数组下标越界异常、ClassCastException类型转换异常、ArithmeticExecption算术异常。
此类异常属于不受检异常,一般是由程序逻辑错误引起的,在程序中可以选择捕获处理,也可以不处理。虽然 Java 编译器不会检查运行时异常,但是我们也可以通过 throws 进行声明抛出,也可以通过 try-catch 对它进行捕获处理。如果产生运行时异常,则需要通过修改代码来进行避免。例如,若会发生除数为零的情况,则需要通过代码避免该情况的发生!
RuntimeException 异常会由 Java 虚拟机自动抛出并自动捕获(就算我们没写异常捕获语句运行时也会抛出错误!!),此类异常的出现绝大数情况是代码本身有问题应该从逻辑上去解决并改进代码。
(2)、编译时异常
定义: Exception 中除 RuntimeException 及其子类之外的异常。
特点: Java 编译器会检查它。如果程序中出现此类异常,比如 ClassNotFoundException(没有找到指定的类异常),IOException(IO流异常),要么通过throws进行声明抛出,要么通过try-catch进行捕获处理,否则不能通过编译。在程序中,通常不会自定义该类异常,而是直接使用系统提供的异常类。该异常我们必须手动在代码里添加捕获语句来处理该异常。
受检异常与非受检异常
Java 的所有异常可以分为受检异常(checked exception)和非受检异常(unchecked exception)。
(1)、受检异常
编译器要求必须处理的异常。正确的程序在运行过程中,经常容易出现的、符合预期的异常情况。一旦发生此类异常,就必须采用某种方式进行处理。除 RuntimeException 及其子类外,其他的 Exception 异常都属于受检异常。编译器会检查此类异常,也就是说当编译器检查到应用中的某处可能会出现此类异常时,将会提示你处理本异常——要么使用try-catch捕获,要么使用方法签名中用 throws 关键字抛出,否则编译不通过。
(2)、非受检异常
编译器不会进行检查并且不要求必须处理的异常,也就说当程序中出现此类异常时,即使我们没有try-catch捕获它,也没有使用throws抛出该异常,编译也会正常通过。该类异常包括运行时异常(RuntimeException及其子类)和错误(Error)。
Java异常关键字:
• try – 用于监听。将要被监听的代码(可能抛出异常的代码)放在try语句块之内,当try语句块内发生异常时,异常就被抛出。 • catch – 用于捕获异常。catch用来捕获try语句块中发生的异常。 • finally – finally语句块总是会被执行。它主要用于回收在try块里打开的物理资源(如数据库连接、网络连接和磁盘文件)。只有finally块,执行完成之后,才会回来执行try或者catch块中的return或者throw语句,如果finally中使用了return或者throw等终止方法的语句,则就不会跳回执行,直接停止。 • throw – 用于抛出异常。 • throws – 用在方法签名中,用于声明该方法可能抛出的异常。
(2)、Java异常处理
声明异常
通常,应该捕获那些知道如何处理的异常,将不知道如何处理的异常继续传递下去。传递异常可以在方法签名处使用 throws 关键字声明可能会抛出的异常。
注意:
非检查异常(Error、RuntimeException 或它们的子类)不可使用 throws 关键字来声明要抛出的异常。 一个方法出现编译时异常,就需要 try-catch/ throws 处理,否则会导致编译错误。 抛出异常:
如果你觉得解决不了某些异常问题,且不需要调用者处理,那么你可以抛出异常。
throw关键字作用是在方法内部抛出一个Throwable类型的异常。任何Java代码都可以通过throw语句抛出异常。
捕获异常:
程序通常在运行之前不报错,但是运行后可能会出现某些未知的错误,但是还不想直接抛出到上一级,那么就需要通过try…catch…的形式进行异常捕获,之后根据不同的异常情况来进行相应的处理。
如何选择异常类型:
可以根据下图来选择是捕获异常,声明异常还是抛出异常
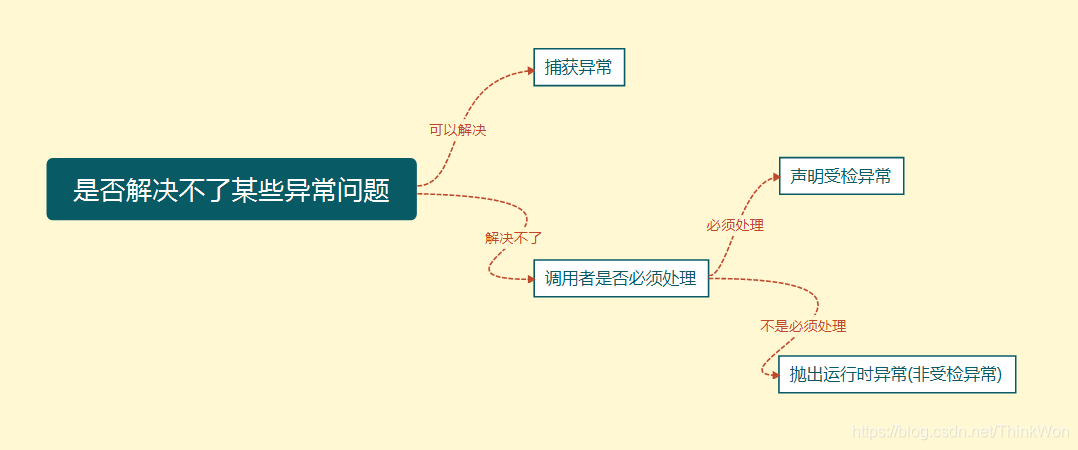
常见异常处理方式:
(1).直接抛出异常
通常,应该捕获那些知道如何处理的异常,将不知道如何处理的异常继续传递下去。传递异常可以在方法签名处使用 throws 关键字声明可能会抛出的异常。
private static void readFile(String filePath) throws IOException {
File file = new File(filePath);
String result;
BufferedReader reader = new BufferedReader(new FileReader(file));
while((result = reader.readLine())!=null) {
System.out.println(result);
}
reader.close();
}(2).封装异常再抛出
有时我们会从 catch 中抛出一个异常,目的是为了改变异常的类型。多用于在多系统集成时,当某个子系统故障,异常类型可能有多种,可以用统一的异常类型向外暴露,不需暴露太多内部异常细节。
private static void readFile(String filePath) throws MyException {
try {
// code
} catch (IOException e) {
MyException ex = new MyException("read file failed.");
ex.initCause(e);
throw ex;
}
}(3).捕获异常
在一个 try-catch 语句块中可以捕获多个异常类型,并对不同类型的异常做出不同的处理
private static void readFile(String filePath) {
try {
// code
} catch (FileNotFoundException e) {
// handle FileNotFoundException
} catch (IOException e){
// handle IOException
}
}同一个 catch 也可以捕获多种类型异常,用 | 隔开
private static void readFile(String filePath) {
try {
// code
} catch (FileNotFoundException | UnknownHostException e) {
// handle FileNotFoundException or UnknownHostException
} catch (IOException e){
// handle IOException
}
}(4).自定义异常
习惯上,定义一个异常类应包含两个构造函数,一个无参构造函数和一个带有详细描述信息的构造函数(Throwable 的 toString 方法会打印这些详细信息,调试时很有用)
public class MyException extends Exception {
public MyException(){ }
public MyException(String msg){
super(msg);
}
// ...
}(5).try-catch-finally
当方法中发生异常,异常处之后的代码不会再执行,如果之前获取了一些本地资源需要释放,则需要在方法正常结束时和 catch 语句中都调用释放本地资源的代码,显得代码比较繁琐,finally 语句可以解决这个问题。
private static void readFile(String filePath) throws MyException {
File file = new File(filePath);
String result;
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file));
while((result = reader.readLine())!=null) {
System.out.println(result);
}
} catch (IOException e) {
System.out.println("readFile method catch block.");
MyException ex = new MyException("read file failed.");
ex.initCause(e);
throw ex;
} finally {
System.out.println("readFile method finally block.");
if (null != reader) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}调用该方法时,读取文件时若发生异常,代码会进入 catch 代码块,之后进入 finally 代码块;若读取文件时未发生异常,则会跳过 catch 代码块直接进入 finally 代码块。所以无论代码中是否发生异常,fianlly 中的代码都会执行。
若 catch 代码块中包含 return 语句,finally 中的代码还会执行吗?将以上代码中的 catch 子句修改如下:
catch (IOException e) {
System.out.println("readFile method catch block.");
return;
}
调用 readFile 方法,观察当 catch 子句中调用 return 语句时,finally 子句是否执行
readFile method catch block. readFile method finally block.
可见,即使 catch 中包含了 return 语句,finally 子句依然会执行。若 finally 中也包含 return 语句,finally 中的 return 会覆盖前面的 return.
(6).try-with-resource
上面例子中,finally 中的 close 方法也可能抛出 IOException, 从而覆盖了原始异常。JAVA 7 提供了更优雅的方式来实现资源的自动释放,自动释放的资源需要是实现了 AutoCloseable 接口的类。
private static void tryWithResourceTest(){
try (Scanner scanner = new Scanner(new FileInputStream("c:/abc"),"UTF-8")){
// code
} catch (IOException e){
// handle exception
}
}Error 和 Exception 区别是什么?
Error类型的错误通常为虚拟机相关的错误,如系统崩溃,内存不足,堆栈溢出等,编译器不会对这类错误进行检测,JAVA应用程序也不应对这类错误进行捕获,一旦这类错误发生,通常应用程序会被终止,仅靠应用程序本身无法恢复
Exception类的错误是可以在应用程序中进行捕获并处理的,通常遇到这种错误,应对其进行处理,使应用程序可以继续正常执行。
运行时异常和一般异常(受检异常)区别是什么?
运行时异常包括RuntimeException类及其子类,表示JVM在运行期间可能出现的异常。Java编译器不会检查运行时异常。
受检异常是Exception中除RuntimeException及其子类之外的异常。Java编译器会检查受检异常。
RuntimeException异常和受检异常之间的区别:是否强制要求调用者必须处理此异常,如果强制要求调用者必须进行处理,那么就使用受检异常,否则就选择非受检异常(RuntimeException)。一般来讲,如果没有特殊的要求,我们建议使用RuntimeException异常。
JVM 是如何处理异常的?
在一个方法中如果发生异常,这个方法会创建一个异常对象,并转交给JVM,该异常对象包含异常名称,异常描述以及异常发生时应用程序的状态。创建异常对象并转交给JVM的过程称为抛出异常。可能一系列的方法的调用,最终才进入抛出异常的方法,这一系列方法调用的有序列表叫做调用栈。
JVM会顺着调用栈去查找看是否有可以处理异常的代码,如果有,则调用异常处理代码。当JVM发现可以处理异常的代码时,会把发生的异常传递给它。如果JVM没有找到可以处理该异常的代码块,JVM就会将该异常转交给默认的异常处理器(默认处理器为JVM的一部分),默认异常处理器打印出异常信息并终止应用程序。
throw 和 throws 的区别是什么?
Java中的异常处理除了包括捕获异常和处理异常之外,还包括声明异常和抛出异常,可以通过throws关键字在方法上声明该方法要抛出的异常,或者在方法内部通过throw抛出异常对象。
throws关键字和throw关键字在使用上的几点区别如下:
throw关键字用在方法内部,只能用于抛出一种异常,用来抛出方法或代码块中的异常,受检异常和非受检异常都可以抛出。
throws关键字用在方法声明上,可以抛出多个异常,用来标识该方法可能抛出的异常列表。一个方法用throws标识了可能抛出的异常列表,调用该方法的方法中必须包含可处理异常的代码,否则也要在方法签名中用throws声明响应的异常。
throw后面接的是异常对象,只能接一个;throws后面接的是异常类型,可以接多个,多个异常类型用逗号隔开。
throw是在方法中出现不正确情况时,手动来抛出异常,结束放的,执行了throw语句一定会出现异常,而throws是用来声明当前方法有可能会出现某种异常的,如果出现了相应的异常,将由调用者来处理,声明了异常不一定会出现异常。
final、finally、finalize 有什么区别?
final可以修饰类、变量、方法、修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表示该变量是一个常量不能被重新复制。
finally一般总用在try-catch代码块中,在处理异常的时候,通常我们会将一定要执行的代码放在finally代码块中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代码。
finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,Java中允许使用finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。
NoClassDefFoundError 和 ClassNotFoundException 区别?
NoClassDefFoundError是一个Error类型的异常,由JVM引起的,不应该尝试捕获这个异常
引起该异常的原因是JVM或者ClassLoader尝试加载某类时在内存中找不到该类的定义,该动作发生在运行期间,即编译时该类存在,但是在运行时却找不到了,可能是编译后被删除了等原因导致;
ClassNotFountException是一个受检异常,需要显示地使用try-catch对其进行捕获处理,或在方法签名中用throws关键字进行声明。当使用class.forName,ClassLoader.loadClass或ClassLoder.findSystemClass动态加载到内存你的时候,通过传入的类路径参数没有找到该类,就会抛出该异常;另一种抛出该异常的可能原因是某个类已经由一个类加载至内存中,另一个加载器又尝试去加载它。
try-catch-finally 中哪个部分可以省略?
catch可以省略。
原因:
更为严格的说法其实是:try只适合处理运行时异常,try+catch适合处理运行时异常+普通异常。也就是说,如果你只用try去处理普通异常却不加catch处理,编译是通不过的,因为编译器硬性规定,普通异常如果选择捕获,则必须用catch显示声明以便进一步处理。而运行时异常在编译时没有如此规定,所以catch可以省略,你加上catch编译器也觉得无可厚非。
理论上,编译器看任何代码都不顺眼,都觉得可能有潜在的问题,所以你即使对所有代码加上try,代码在运行期间也只不过是在正常运行的基础上加一层皮。但是你一旦对一段代码加上try,就等于显示地承诺编译器,对这段代码可能抛出的异常进行捕获而非向上抛出处理。如果是普通异常,编译器要求必须用catch捕获以便进一步处理;如果运行时异常,捕获然后丢弃并且+finally扫尾处理,或者加上catch捕获以便进一步处理。
至于加上finally,则是在不管有没有捕获异常,都要进行扫尾处理。
try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
会执行,在return前。
注意:在 finally 中改变返回值的做法是不好的,因为如果存在 finally 代码块,try中的 return 语句不会立马返回调用者,而是记录下返回值待 finally 代码块执行完毕之后再向调用者返回其值,然后如果在 finally 中修改了返回值,就会返回修改后的值。显然,在 finally 中返回或者修改返回值会对程序造成很大的困扰,C#中直接用编译错误的方式来阻止程序员干这种龌龊的事情,Java 中也可以通过提升编译器的语法检查级别来产生警告或错误。
代码:
public static int getInt() {
int a = 10;
try {
System.out.println(a / 0);
a = 20;
} catch (ArithmeticException e) {
a = 30;
return a;
/*
* return a 在程序执行到这一步的时候,这里不是return a 而是 return 30;这个返回路径就形成了
* 但是呢,它发现后面还有finally,所以继续执行finally的内容,a=40
* 再次回到以前的路径,继续走return 30,形成返回路径之后,这里的a就不是a变量了,而是常量30
*/
} finally {
a = 40;
}
return a;
}//执行结果:30
public static int getInt() {
int a = 10;
try {
System.out.println(a / 0);
a = 20;
} catch (ArithmeticException e) {
a = 30;
return a;
} finally {
a = 40;
//如果这样,就又重新形成了一条返回路径,由于只能通过1个return返回,所以这里直接返回40
return a;
}
}//执行结果:40常见的 RuntimeException 有哪些?
ClassCastException(类转换异常) IndexOutOfBoundsException(数组越界) NullPointerException(空指针) ArrayStoreException(数据存储异常,操作数组时类型不一致) 还有IO操作的BufferOverflowException异常
Java常见异常有哪些
java.lang.IllegalAccessError:违法访问错误。当一个应用试图访问、修改某个类的域(Field)或者调用其方法,但是又违反域或方法的可见性声明,则抛出该异常。
java.lang.InstantiationError:实例化错误。当一个应用试图通过Java的new操作符构造一个抽象类或者接口时抛出该异常.
java.lang.OutOfMemoryError:内存不足错误。当可用内存不足以让Java虚拟机分配给一个对象时抛出该错误。
java.lang.StackOverflowError:堆栈溢出错误。当一个应用递归调用的层次太深而导致堆栈溢出或者陷入死循环时抛出该错误。
java.lang.ClassCastException:类造型异常。假设有类A和B(A不是B的父类或子类),O是A的实例,那么当强制将O构造为类B的实例时抛出该异常。该异常经常被称为强制类型转换异常。
java.lang.ClassNotFoundException:找不到类异常。当应用试图根据字符串形式的类名构造类,而在遍历CLASSPAH之后找不到对应名称的class文件时,抛出该异常。
java.lang.ArithmeticException:算术条件异常。譬如:整数除零等。
java.lang.ArrayIndexOutOfBoundsException:数组索引越界异常。当对数组的索引值为负数或大于等于数组大小时抛出。
java.lang.IndexOutOfBoundsException:索引越界异常。当访问某个序列的索引值小于0或大于等于序列大小时,抛出该异常。
java.lang.InstantiationException:实例化异常。当试图通过newInstance()方法创建某个类的实例,而该类是一个抽象类或接口时,抛出该异常。
java.lang.NoSuchFieldException:属性不存在异常。当访问某个类的不存在的属性时抛出该异常。
java.lang.NoSuchMethodException:方法不存在异常。当访问某个类的不存在的方法时抛出该异常。
java.lang.NullPointerException:空指针异常。当应用试图在要求使用对象的地方使用了null时,抛出该异常。譬如:调用null对象的实例方法、访问null对象的属性、计算null对象的长度、使用throw语句抛出null等等。
java.lang.NumberFormatException:数字格式异常。当试图将一个String转换为指定的数字类型,而该字符串确不满足数字类型要求的格式时,抛出该异常。
java.lang.StringIndexOutOfBoundsException:字符串索引越界异常。当使用索引值访问某个字符串中的字符,而该索引值小于0或大于等于序列大小时,抛出该异常。
博客:Java异常面试题(2020最新版)_ThinkWon的博客-CSDN博客_java异常面试题
五、Mysql
1、Mysql的事务和隔离级别有哪些?
事务特性
原子性:指的是一个事务中的操作要么全部成功,要么全部失败。
一致性:指的是数据库总是从一个一致性的状态转换到另外一个一致性的状态。比如A转账给B100元,假设A只有90块,支付之前我们数据库里的数据都是符合约束的,但是如果事务执行成功了,我们的数据库数据就破坏约束了,因此事务不能成功,这里我们说事务提供了一致性的保证。
隔离性:指的是一个事务的修改在最终提交前,对其他事务是不可见的。
持久性:指的是一旦事务提交,所做的修改就会永久保存到数据库中。
如何保证事务的特性
A原子性:由undo log日志保证,它记录了需要回滚的日志信息,事务回滚时撤销已经执行成功的SQL
C一致性:由其他三大特性保证、程序代码要保证业务上的一致性
I隔离性:由MVCC来保证
D持久性:由内存+redo log来保证,mysql修改数据同时在内存和redolog记录这次操作,宕机的时候可以从redolog恢复
//InnoDB redo log写盘,InndoDB事务进入prepare状态。如果前面的prepare成功,binglog写盘,再继续将事务日志持久化到binlog,如果持久化成功,那么InnoDB事务则进入commit状态(在redo log里面写一个commit记录)。redolog的刷盘会在系统空闲时进行
Mysql的隔离级别
(1)、read uncommitted 读取未提交的内容
在这个隔离级别,所有的事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不必其他性能好多少。不能避免脏读、不可重复读、幻读。
(2)、read committed 读取提交内容
大多数数据库系统的默认隔离级别(但是不是MySQL的默认隔离级别),满足了隔离的早先定义:一个事务开始时,只能看见已经提交事务所做的改变,一个事务从开始到提交前,所做的任何数据都是不可见的,除非已经提交。可以避免脏读,但不可重复读,幻读问题仍然存在。
(3)、repeatable read 可重复读
MySQL数据库默认的隔离级别。该级别解决了read uncommitted隔离级别导致的问题。事务A在读到一条数据之后,此时事务B对该数据进行了修改并提交,那么事务A再读该数据,读到的还是原来的内容。可以避免脏读、不可重复读,但幻读问题仍然存在
(4)serializable 可串行化
该级别是最高的隔离级别。它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题,简而言之,serializable是在每个读的数据行上加锁。在这个级别,可能导致大量的超时Timeout和锁竞争Lock Contention现象。实际应用中很少使用到这个级别,但如果用户的应用为了数据的稳定性,需要强制减少并发的话,也可以选择这种隔离级别。
脏读、幻读、不可重复读概念
脏读
脏读是指一个事务读取了未提交事务执行过程中的数据。
当一个事务的操作正在多次修改数据,而在事务还未提交的时候,另外一个并发事务来读取数据了,就会导致读取到的数据并非是最终持久化之后的数据,这个数据就是脏读的数据。

不可重复读
不可重复读是指对于数据库中的某个数据,一个事务执行过程中多次查询(同一条记录)返回不同的查询结果,这就是在事务执行过程中,数据被其他事务提交修改了。
不可重复读同脏读的区别,脏读是一个事务读取到了另一未完成的事务执行过程中的数据,而不可重复读是一个事务执行过程中,另一事务提交并修改了当前事务正在读取的数据。
对于两个事务SessionA,SessionB,SessionA读取了一个字段,然后SessionB更新了该字段。之后SessionA再次读取同一个字段,值就不同了,那就意味着发生了不可重复读。

幻读
对于两个事务SessionA,SessionB,SessionA从一个表中读取了一个字段,然后SessionB在该表中插入了一些新的行。之后,如果SessionA再次读取同一表,就会多出几行。那就意味着发生了幻读。
幻读和不可重复读都是读取了另一条已经提交的事务(这点同脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。

2、MySQL用B+树作为索引结构有什么好处
二叉排序树(二叉查找树)
它在二叉树的基础上满足:任意节点的左子树上所有节点值不大于根节点的值,任意节点的右子树上所有节点值不小于根节点的值。当需要快速查找时,将数据存储在BST是一种常见的选择,因为此时查询时间取决于树高,平均时间复杂度为O(lon)。然而,二叉排序树可能长歪而变得不平衡;此时二叉排序树退化为链表,时间复杂度退化为O(n)。

二叉平衡树(ABL)
AVL树是严格的平衡二叉树,所有节点的左右子树高度差不能查过1;AVL树查找、插入和删除在平均和最坏情况下都是O(logn)。AVL实现平衡的关键在于旋转操作:插入和删除可能破坏二叉树的平衡,此时需要通过一次或多次树旋转来重新平衡这个树。当插入数据时,最多只需要1次旋转;但是当删除数据时,会导致树失衡,AVL需要维护从被删除节点到根节点这条路径上所有节点的平衡,旋转的量级为O(lgn).
由于旋转的耗时,AVL树在删除数据时效率很低;在删除操作较多时,维护平衡所需的代价可能高于其带来的好处,因此AVL实际应用并不广泛。
红黑树
与AVL树相比,红黑树的查询效率会有所下降,这时因为树的平衡性变差,高度更高。但红黑树的删除效率大大提高了,因为红黑树同时引入了颜色,当插入或删除数据时,只需要进行O(1)次数的旋转以及变色就能保证基本的平衡,不需要像AVL树进行O(lgn)次数的旋转。总的来说,红黑树的统计性能高于AVL。
因此,在实际应用中,AVL树的使用相对较少,而红黑树的使用非常广泛。例如,Java中的TreeMap使用红黑树存储排序键值对;Java8中的HashMap使用链表+红黑树解决哈希冲突问题(当冲突节点较少时,使用链表,当冲突节点较多时,使用红黑树)。
对于数据在内存中的情况(如上述的TreeMap和HashMap),红黑树的表现是非常优异的。但是对于数据在磁盘等辅助存储设备中的情况(如MySQL等数据库),红黑树并不擅长,因为红黑树长得还是太高了。当数据在磁盘中时,磁盘IO会成为最大的性能瓶颈,设计的目标应该是尽量减少IO次数;而树的高度越高,增删改查所需要的IO次数也越多,会严重影响性能。
B树
B树非叶子节点和叶子节点都存储数据,是一颗多路查找平衡树。B树查询时间复杂度不固定,与key在树中的位置有关
Hash索引
如果只查询单个值的话,hash 索引的效率非常高。但是 hash 索引有几个问题:
1)不支持范围查询;因为经过Hash函数建立索引之后,索引的顺序与原顺序无法保持一致,故不能支持范围查询。同理,也不支持使用索引进行排序。
2)Hash虽然在等值上查询效率高,但性能不稳定,因为当某个键值存在大量重复时,产生Hash碰撞,此时查询效率反而可能降低。
3)Hash不支持模糊查询以及多列索引的最左前缀匹配,因为Hash函数的值不可预测。
B+树
(1)、B+树更为矮胖,可以减少磁盘I/O的次数(查找次数等于树的深度——,而磁盘I/O是最大的时间开销。
(2)、B+树有一个最大的好处,方便扫库,B树必须用中序遍历的方法按序扫库,而B+树直接从叶子结点挨个扫一遍就完了。
(3)、B+树支持range-query(区间查询)非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
B+树更便于遍历:由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
B+树更适合基于范围的查询:B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
B树与B+树的区别
-
B树中每个节点(包括叶节点和非叶节点)都存储真实的数据,B+树中只有叶子节点存储真实的数据,非叶节点只存储键。在MySQL中,这里所说的真实数据,可能是行的全部数据(如Innodb的聚簇索引),也可能只是行的主键(如Innodb的辅助索引),或者是行所在的地址(如MyIsam的非聚簇索引)。
-
B树中一条记录只会出现一次,不会重复出现,而B+树的键则可能重复重现——一定会在叶节点出现,也可能在非叶节点重复出现。
-
B+树的叶节点之间通过双向链表链接。
-
B树中的非叶节点,记录数比子节点个数少1;而B+树中记录数与子节点个数相同。
由此,B+树与B树相比,有以下优势:
-
更少的IO次数:B+树的非叶节点只包含键,而不包含真实数据,因此每个节点存储的记录个数比B数多很多(即阶m更大),因此B+树的高度更低,访问时所需要的IO次数更少。此外,由于每个节点存储的记录数更多,所以对访问局部性原理的利用更好,缓存命中率更高。
-
更适于范围查询:在B树中进行范围查询时,首先找到要查找的下限,然后对B树进行中序遍历,直到找到查找的上限;而B+树的范围查询,只需要对链表进行遍历即可。
-
更稳定的查询效率:B树的查询时间复杂度在1到树高之间(分别对应记录在根节点和叶节点),而B+树的查询复杂度则稳定为树高,因为所有数据都在叶节点。
B+树也存在劣势:由于键会重复出现,因此会占用更多的空间。但是与带来的性能优势相比,空间劣势往往可以接受,因此B+树的在数据库中的使用比B树更加广泛。
3、MySQL索引叶子节点存放的是什么
(1)、主键索引的叶子节点存的是整行数据。
(2)非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。二级索引的叶子节点中存的是主键的值,不是原始的数据,所以二级索引找到主键的值之后,需要用该主键再去主键索引上查找一次,才能获取到最终的数据,这个过程叫做回表,这也是“二级”的含义
4、MYSQL的锁
共享锁(share lock):共享锁又称读锁
当一个事务为数据加上读锁之后,其他事务只能对该数据加读锁,而不能对数据加写锁,知道所有的读锁释放之后其他事务才能对其加持写锁。共享锁的特性主要是为了支持并发的读取数据,读取数据的时候不支持修改,避免出现重复读的问题。
排他锁(exclusive lock):排他锁又称写锁
当一个事务为数据加上写锁时,其他请求将不能在未数据加任何锁,直到该锁释放之后,其他事务才能对数据进行加锁。排他锁的目的是在数据修改时候,不允许其他人同时修改,也不允许其他人读取,避免了出现脏数据和脏读的问题。
表锁
表锁是指锁的时候锁住的是整个表,当下一个事务访问该表的时候,必须等前一个事务释放了锁才能进行对表进行访问;特点:粒度大,加锁简单,容易冲突。
行锁
行锁是指上锁的时候锁住的表的某一行或多行记录,其他事务访问同一张表时,只有被锁住的记录不能访问,其他的记录可以正常访问,特点:粒度小,加锁比锁麻烦,不容易冲突,相比表锁支持的并发要高,且会出现死锁。
记录锁
记录锁也属于行锁的一种,只不过记录锁的范围只是表中的某一条记录,记录锁是说事务在加锁后锁住的只是表的某一条记录,加了记录锁之后数据可以避免数据在查询的时候被修改的重复读问题。
页锁
页锁是Mysql中锁定粒度介于行级锁和表级锁中间的一种锁,表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。特点:开销和加锁时间介于表锁和行锁之间,会出现死锁,锁定粒度介于表锁和行锁之间,并发度一般。
间隙锁
是属于行锁的一种,间隙锁是在事务加锁后其锁住的是表记录的某一个区间,当表相邻ID之间出现空隙则会形成一个区间,遵循左开右闭原则。范围查询并且查询未命中记录,查询条件必须命中索引、间隙锁只会出现在REPEATABLE_READ(重复读)的事务级别中。
临键锁
也属于行锁的一种,并且它是INNODB的行锁默认算法,总结来说它就是记录锁和间隙锁的组合,临键锁会把查询出来的记录锁住,同时也会把该范围查询内的所有间隙空间页会锁住,再之它会把相邻的下一个区间也会锁住。
MySQL中如何解决死锁
1、如果不同的程序会并发存取多个表、尽量约定以相同的顺序访问表,可以大大降低死锁机会。
2、在同一个事务中,尽可能做到一次锁定所有的资源,减少死锁产生概率。
3、对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁来减少死锁产生的效率。
如果业务处理不好可以用分布式事务锁或者使用乐观锁。
5、MySQL中的redo log日志
InnoDB存储引擎是以页为单位来管理空间的。在真正访问页面之前,需要把在磁盘上的页缓存到内存中的Buffer pool之后才可以访问,所有的变更都必须先更新缓冲池中的数据,然后缓冲池中的脏页会以一定的频率被刷入磁盘(checkPoint机制)`,通过缓冲池来优化CPU和磁盘之间的鸿沟,这样就可以保证整体的性能不会下降太快。
checkPoint机制目的是解决以下几个问题:1、缩短数据库的恢复时间;2、缓冲池不够用时,将脏页刷新到磁盘;3、重做日志不可用时,刷新脏页。
-
当数据库发生宕机时,数据库不需要重做所有的日志,因为Checkpoint之前的页都已经刷新回磁盘。数据库只需对Checkpoint后的重做日志进行恢复,这样就大大缩短了恢复的时间。
-
当缓冲池不够用时,根据LRU算法会溢出最近最少使用的页,若此页为脏页,那么需要强制执行Checkpoint,将脏页也就是页的新版本刷回磁盘。
-
当重做日志出现不可用时,因为当前事务数据库系统对重做日志的设计都是循环使用的,并不是让其无限增大的,重做日志可以被重用的部分是指这些重做日志已经不再需要,当数据库发生宕机时,数据库恢复操作不需要这部分的重做日志,因此这部分就可以被覆盖重用。如果重做日志还需要使用,那么必须强制Checkpoint,将缓冲池中的页至少刷新到当前重做日志的位置。
-
Redo日志大小也是有限的,通过刷新策略,可以更有效的重复使用文件,不需要开辟新的空间。
-
缓冲区大小有限。数据不刷到硬盘,对于查询业务,命中率越来越小。
好处:redo日志降低了刷盘频率、redo日志占用的空间非常小
特点:redo日志是顺序写入磁盘的、事务执行过程中,redo log不断记录
组成:
(1)、重做日志的缓冲 (redo log buffer) ,保存在内存中,是易失的
参数设置:innodb_log_buffer_size:默认是16M大小,最大值是4096M,最小值为1M
查看:show variables like '%innodb_log_buffer_size%';
(2)、重做日志文件 (redo log file) ,保存在硬盘中,是持久的。
以一个更新事务为例,看一下redolog流程

第1步:先将原始数据从磁盘中读入内存中来,修改数据的内存拷贝 第2步:生成一条重做日志并写入redo log buffer,记录的是数据被修改后的值 第3步:当事务commit时,将redo log buffer中的内容刷新到 redo log file,对 redo log file采用追加写的方式 第4步:定期将内存中修改的数据刷新到磁盘中
redo log的刷盘策略:
redo log的写入并不是直接写入磁盘的,InnoDB引擎会在写redo log的时候先写redo log buffer,之后以 一定的频率 刷入到真正的redo log file 中。这里的一定频率怎么看待呢?这就是我们要说的刷盘策略。

注意,redo log buffer刷盘到redo log file的过程并不是真正的刷到磁盘中去,只是刷入到 文件系统缓存(page cache)中去(这是现代操作系统为了提高文件写入效率做的一个优化),真正的写入会交给系统自己来决定(比如page cache足够大了)。那么对于InnoDB来说就存在一个问题,如果交给系统来同步,同样如果系统宕机,那么数据也丢失了(虽然整个系统宕机的概率还是比较小的)。 针对这种情况,InnoDB给出 innodb_flush_log_at_trx_commit 参数,该参数控制 commit提交事务时,如何将 redo log buffer 中的日志刷新到 redo log file 中。它支持三种策略:
设置为0 :表示每次事务提交时不进行刷盘操作。(系统默认master thread每隔1s进行一次重做日志的同步)
设置为1 :表示每次事务提交时都将进行同步,刷盘操作( 默认值 )
设置为2 :表示每次事务提交时都只把 redo log buffer 内容写入 page cache,不进行同步。由os自己决定什么时候同步到磁盘文件。
不同策略的演示:

为1时,只要事务提交成功,redo log记录就一定在硬盘里,不会有任何数据丢失。
如果无执行期间Mysql挂了或宕机,这部分日志丢了,但是事务并没有提交,所以日志丢了也不会有损失。可以保证ACID的D,数据绝对不会丢失,但是效率最差的。
建议使用默认值,虽然操作系统宕机的概率理论小于数据库宕机的概率,但是一般既然使用了事务,那么数据的安全相对来说更重要些。

为0时,master thread中每1秒进行一次重做日志的fsync操作,因此实例crash最多丢失1秒钟内的事务。(master thread是负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性)。
数值0的话,是一种折中的做法,它的IO效率理论是高于1的,低于2的,这种策略也有丢失数据的风险,也无法保证D。
为2时,只要事务提交成功,redo log buffer中的内容只写入文件系统缓存(page cache)。
如果仅仅只是MySQL挂了不会有任何数据丢失,但是操作系统宕机可能会有1秒数据的丢失,这种情况无法满足ACID中的D。但是数值2肯定是效率最高的。
6、MySQL中的undo log日志
redo log是事务持久性的保证,undo log是事务原子性的保证。在事务中 更新数据 的 前置操作 其实是要先写入一个 undo log 。
理解undo log
事务需要保证 原子性 ,也就是事务中的操作要么全部完成,要么什么也不做。但有时候事务执行到一半 会出现一些情况,比如: 情况一:事务执行过程中可能遇到各种错误,比如 服务器本身的错误 , 操作系统错误 ,甚至是突然 断电 导致的错误。 情况二:程序员可以在事务执行过程中手动输入 ROLLBACK 语句结束当前事务的执行。 以上情况出现,我们需要把数据改回原先的样子,这个过程称之为 回滚 ,这样就可以造成一个假象:这个事务看起来什么都没做,所以符合 原子性 要求。
作用:回滚数据、MVCC
undo log的存储结构
(1)、回滚段与undo页
InnoDB对undo log的管理采用段的方式,也就是 回滚段(rollback segment) 。每个回滚段记录了1024 个 undo log segment ,而在每个undo log segment段中进行 undo页 的申请。 在 InnoDB1.1版本之前 (不包括1.1版本),只有一个rollback segment,因此支持同时在线的事务限制为 1024 。虽然对绝大多数的应用来说都已经够用。从1.1版本开始InnoDB支持最大 128个rollback segment ,故其支持同时在线的事务限制提高到了 128*1024 。
命令查看: show variables like 'innodb_undo_logs';
(2)、回滚段与事务
每个事务只会使用一个回滚段,一个回滚段在同一时刻可能会服务于多个事务。
当一个事务开始的时候,会制定一个回滚段,在事务进行的过程中,当数据被修改时,原始的数据会被复制到回滚段。
在回滚段中,事务会不断填充盘区,直到事务结束或所有的空间被用完。如果当前的盘区不够用,事务会在段中请求扩展下一个盘区,如果所有已分配的盘区都被用完,事务会覆盖最初的盘区或者在回滚段允许的情况下扩展新的盘区来使用。
回滚段存在于undo表空间中,在数据库中可以存在多个undo表空间,但同一时刻只能使用一个undo表空间。
当事务提交时,InnoDB存储引擎会做以下两件事情:将undo log放入列表中,以供之后的purge操作;判断undo log所在的页是否可以重用,若可以分配给下个事务使用
(3)、回滚段中的数据分类
未提交的回滚数据(uncommitted undo information)
已经提交但未过期的回滚数据(committed undo information)
事务已经提交并过期的数据(expired undo information)
类型:
insert undo log
是指在insert操作中产生的undo log。因为insert操作的记录,只对事物本身可见,对其他事务不可见(这时事务隔离性的要求),故该undo log可以在事务提交后直接删除,不需要进行purge操作。
update undo log
记录的是对delete和update操作产生的undo log。该undo log可能需要提供MVCC机制,因此不能在事务提交时就进行删除。提交时放入undo log链表,等待purge线程进行最后的删除。
undo log的生命周期
(1)、简要生命过程
只有Buffer Pool的流程:

有了Redo Log和Undo Log之后:

undo log是逻辑日志,对事务回滚时,只是将数据库逻辑地恢复到原来的样子。 redo log是物理日志,记录的是数据页的物理变化,undo log不是redo log的逆过程。
8、请说说InnoDB的MVCC
全称 Multi-Version Concurrency Control ,即多版本并发控制,逻辑是维持一个数据的多个版本,使得读写操作没有冲突。MVCC主要是为了提高数据库并发性能,用更好的方式去处理读-写冲突,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读。 它是一种用来解决读-写冲突的无锁并发控制机制。在并发读写数据库时,可以做到在读操作时不用阻塞写操作,写操作也不用阻塞读操作,提高了数据库并发读写的性能,还可以解决脏读、幻读、不可重复读等事务隔离问题,但不能解决更新丢失问题。 加分回答 InnoDB默认的隔离级别是RR(REPEATABLE READ),RR解决脏读、不可重复读、幻读等问题,使用的是MVCC。MVCC全称Multi-Version Concurrency Control,即多版本的并发控制协议。它最大的优点是读不加锁,因此读写不冲突,并发性能好。
InnoDB实现MVCC,多个版本的数据可以共存,主要基于以下技术及数据结构: 1. 隐藏列:InnoDB中每行数据都有隐藏列,隐藏列中包含了本行数据的事务id、指向undo log的指针等。 2. 基于undo log的版本链:每行数据的隐藏列中包含了指向undo log的指针,而每条undo log也会指向更早版本的undo log,从而形成一条版本链。 3. ReadView:通过隐藏列和版本链,MySQL可以将数据恢复到指定版本。但是具体要恢复到哪个版本,则需要根据ReadView来确定。所谓ReadView,是指事务(记做事务A)在某一时刻给整个事务系统(trx_sys)打快照,之后再进行读操作时,会将读取到的数据中的事务id与trx_sys快照比较,从而判断数据对该ReadView是否可见,即对事务A是否可见。
MVCC (Multiversion Concurrency Control),多版本并发控制。顾名思义,MVCC 是通过数据行的多个版本管理来实现数据库的 并发控制。 这项技术使得在InnoDB的事务隔离级别下执行 一致性读 操作有了保证换言之,就是为了查询一些正在被另一个事务更新的行,并且可以看到它们被更新之前的值,这样在做查询的时候就不用等待另一个事务释放锁。
当前读就是它读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。加锁的 SELECT,或者对数据进行增删改都会进行当前读。对于当前读InnoDB通过gap locks或next-key locks解决幻读。
快照读像不加锁的select操作就是快照读,即不加锁的非阻塞读;快照读的前提是隔离级别不是串行级别,串行级别下的快照读会退化成当前读;之所以出现快照读的情况,是基于提高并发性能的考虑,快照读的实现是基于多版本并发控制,即MVCC,可以认为MVCC是行锁的一个变种,但它在很多情况下,避免了加锁操作,降低了开销;既然是基于多版本,即快照读可能读到的并不一定是数据的最新版本,而有可能是之前的历史版本。
对于使用 InnoDB 存储引擎的表来说,它的聚簇索引记录中都包含两个必要的隐藏列。

trx_id :每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的 事务id 赋值给trx_id 隐藏列。 roll_pointer :每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到 undo日志 中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。

insert undo只在事务回滚时起作用,当事务提交后,该类型的undo日志就没用了,它占用的UndoLog Segment也会被系统回收(也就是该undo日志占用的Undo页面链表要么被重用,要么被释放)
例:
假设之后两个事务id分别为 10 、 20 的事务对这条记录进行 UPDATE 操作,操作流程如下:

每次对记录进行改动,都会记录一条undo日志,每条undo日志也都有一个 roll_pointer 属性( INSERT 操作对应的undo日志没有该属性,因为该记录并没有更早的版本),可以将这些 undo日志都连起来,串成一个链表:

对该记录每次更新后,都会将旧值放到一条 undo日志 中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被 roll_pointer 属性连接成一个链表,我们把这个链表称之为 版本链 ,版本链的头节点就是当前记录最新的值。每个版本中还包含生成该版本时对应的 事务id 。
增删改的底层操作
当我们更新一条数据,InnoDB 会进行如下操作:
加锁:对要更新的行记录加排他锁
写 undo log:将更新前的记录写入 undo log,并构建指向该 undo log 的回滚指针 roll_ptr
更新行记录:更新行记录的 DB_TRX_ID 属性为当前的事务Id,更新 DB_ROLL_PTR 属性为步骤2生成的回滚指针,将此次要更新的属性列更新为目标值
写 redo log:DB_ROLL_PTR 使用步骤2生成的回滚指针,DB_TRX_ID 使用当前的事务Id,并填充更新后的属性值
处理结束,释放排他锁
删除操作:
在底层实现中是使用更新来实现的,逻辑基本和更新操作一样,几个需要注意的点:1)写 undo log 中,会通过 type_cmpl 来标识是删除还是更新,并且不记录列的旧值;2)这边不会直接删除,只会给行记录的 info_bits 打上删除标识(REC_INFO_DELETED_FLAG),之后会由专门的 purge 线程来执行真正的删除操作。
插入操作:相比于更新操作比较简单,就是新增一条记录,DB_TRX_ID 使用当前的事务Id,同样会有 undo log 和 redo log。
MVCC的实现原理
MVCC 的实现依赖于:隐藏字段、Undo Log、Read View
什么是read view
Read View就是事务进行快照读操作的时候生产的读视图(Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的ID。
设计思路
(1)、使用 READ UNCOMMITTED 隔离级别的事务,由于可以读到未提交事务修改过的记录,所以直接读取记录 的最新版本就好了。 (2)、使用 SERIALIZABLE 隔离级别的事务,InnoDB规定使用加锁的方式来访问记录。 (3)、使用 READ COMMITTED 和 REPEATABLE READ 隔离级别的事务,都必须保证读到 已经提交了的 事务修改 过的记录。假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的,核心问题就是需要判断一下版本链中的哪个版本是当前事务可见的,这是ReadView要解决的主要问题。
这个ReadView中主要包含4个比较重要的内容,分别如下:
-
creator_trx_id ,创建这个 Read View 的事务 ID。 说明:只有在对表中的记录做改动时(执行INSERT、DELETE、UPDATE这些语句时)才会为事务分配事务id,否则在一个只读事务中的事务id值都默认为0。
-
trx_ids ,表示在生成ReadView时当前系统中活跃的读写事务的 事务id列表 。
-
up_limit_id ,活跃的事务中最小的事务 ID。
-
low_limit_id ,表示生成ReadView时系统中应该分配给下一个事务的 id 值。low_limit_id 是系统最大的事务id值,这里要注意是系统中的事务id,需要区别于正在活跃的事务ID。 注意:low_limit_id并不是trx_ids中的最大值,事务id是递增分配的。比如,现在有id为1,2,3这三个事务,之后id为3的事务提交了。那么一个新的读事务在生成ReadView时,trx_ids就包括1和2,up_limit_id的值就是1,low_limit_id的值就是4。
ReadView的规则,走聚簇索引:
有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见。 1、如果被访问版本的trx_id属性值与ReadView中的 creator_trx_id 值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。 2、如果被访问版本的trx_id属性值小于ReadView中的 up_limit_id 值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。 3、如果被访问版本的trx_id属性值大于或等于ReadView中的 low_limit_id 值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。 4、如果被访问版本的trx_id属性值在ReadView的 up_limit_id 和 low_limit_id 之间,那就需要判断一下trx_id属性值是不是在 trx_ids 列表中。 如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问。 如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。
ReadView的规则,走非聚簇索引:
当走普通索引时,判断逻辑如下:
判断被访问索引记录所在页的最大事务 Id 是否小于 ReadView 中的 m_up_limit_id(低水位),如果是则代表该页的最后一次修改事务 Id 在 ReadView 创建前以前已经提交,则必然可以访问;如果不是,并不代表一定不可以访问,道理跟走聚簇索引一样,事务 Id 大的也可能提交比较早,所以需要做进一步判断,见步骤2。
使用 ICP(Index Condition Pushdown)根据索引信息来判断搜索条件是否满足,这边主要是在使用聚簇索引判断前先进行过滤,这边有三种情况:a)ICP 判断不满足条件但没有超出扫描范围,则获取下一条记录继续查找;b)如果不满足条件并且超出扫描返回,则返回 DB_RECORD_NOT_FOUND;c)如果 ICP 判断符合条件,则会获取对应的聚簇索引来进行可见性判断。
MVCC整体操作流程
了解了这些概念之后,我们来看下当查询一条记录的时候,系统如何通过MVCC找到它:
-
首先获取事务自己的版本号,也就是事务 ID;
-
获取 ReadView;
-
查询得到的数据,然后与 ReadView 中的事务版本号进行比较;
-
如果不符合 ReadView 规则,就需要从 Undo Log 中获取历史快照;
-
最后返回符合规则的数据。
例1、 READ COMMITTED隔离级别下
READ COMMITTED :每次读取数据前都生成一个ReadView。
现在有两个 事务id 分别为 10 、 20 的事务在执行:
# Transaction 10 BEGIN; UPDATE student SET name="李四" WHERE id=1; UPDATE student SET name="王五" WHERE id=1; # Transaction 20 BEGIN; # 更新了一些别的表的记录
此刻,表student 中 id 为 1 的记录得到的版本链表如下所示:

假设现在有一个使用 READ COMMITTED 隔离级别的事务开始执行:
BEGIN; # SELECT1:Transaction 10、20未提交 SELECT * FROM student WHERE id = 1; # 得到的列name的值为'张三'
之后,我们把 事务id 为 10 的事务提交一下:
BEGIN; UPDATE student SET name="李四" WHERE id=1; UPDATE student SET name="王五" WHERE id=1; COMMIT;
然后再到 事务id 为 20 的事务中更新一下表 student 中 id 为 1 的记录:
BEGIN; # 更新了一些别的表的记录 ... UPDATE student SET name="钱七" WHERE id=1; UPDATE student SET name="宋八" WHERE id=1;
此刻,表student中 id 为 1 的记录的版本链就长这样:

然后再到刚才使用 READ COMMITTED 隔离级别的事务中继续查找这个 id 为 1 的记录,如下:
BEGIN; # SELECT1:Transaction 10、20均未提交 SELECT * FROM student WHERE id = 1; # 得到的列name的值为'张三' # SELECT2:Transaction 10提交,Transaction 20未提交 SELECT * FROM student WHERE id = 1; # 得到的列name的值为'王五
例2、 REPEATABLE READ隔离级别下
使用 REPEATABLE READ 隔离级别的事务来说,只会在第一次执行查询语句时生成一个 ReadView ,之后的查询就不会重复生成了。
比如,系统里有两个 事务id 分别为 10 、 20 的事务在执行:
BEGIN; UPDATE student SET name="李四" WHERE id=1; UPDATE student SET name="王五" WHERE id=1; # Transaction 20 BEGIN; # 更新了一些别的表的记录
此刻,表student 中 id 为 1 的记录得到的版本链表如下所示:

假设现在有一个使用 REPEATABLE READ 隔离级别的事务开始执行:
BEGIN; # SELECT1:Transaction 10、20未提交 SELECT * FROM student WHERE id = 1; # 得到的列name的值为'张三'
之后,我们把 事务id 为 10 的事务提交一下,就像这样:
BEGIN; UPDATE student SET name="李四" WHERE id=1; UPDATE student SET name="王五" WHERE id=1; COMMIT;
然后再到 事务id 为 20 的事务中更新一下表 student 中 id 为 1 的记录:
# Transaction 20 BEGIN; # 更新了一些别的表的记录 ... UPDATE student SET name="钱七" WHERE id=1; UPDATE student SET name="宋八" WHERE id=1;
此刻,表student 中 id 为 1 的记录的版本链长这样:

然后再到刚才使用 REPEATABLE READ 隔离级别的事务中继续查找这个 id 为 1 的记录,如下:
BEGIN; # SELECT1:Transaction 10、20均未提交 SELECT * FROM student WHERE id = 1; # 得到的列name的值为'张三' # SELECT2:Transaction 10提交,Transaction 20未提交 SELECT * FROM student WHERE id = 1; # 得到的列name的值仍为'张三'
如何解决幻读
接下来说明InnoDB 是如何解决幻读的。 假设现在表 student 中只有一条数据,数据内容中,主键 id=1,隐藏的 trx_id=10,它的 undo log 如下图所示。

假设现在有事务 A 和事务 B 并发执行, 事务 A 的事务 id 为 20 , 事务 B 的事务 id 为 30 。 步骤1:事务 A 开始第一次查询数据,查询的 SQL 语句如下。select * from student where id >= 1;
在开始查询之前,MySQL 会为事务 A 产生一个 ReadView,此时 ReadView 的内容如下: trx_ids=[20,30] , up_limit_id=20 , low_limit_id=31 , creator_trx_id=20 。
由于此时表 student 中只有一条数据,且符合 where id>=1 条件,因此会查询出来。然后根据 ReadView 机制,发现该行数据的trx_id=10,小于事务 A 的 ReadView 里 up_limit_id,这表示这条数据是事务 A 开 启之前,其他事务就已经提交了的数据,因此事务 A 可以读取到。
结论:事务 A 的第一次查询,能读取到一条数据,id=1。
步骤2:接着事务 B(trx_id=30),往表 student 中新插入两条数据,并提交事务。
insert into student(id,name) values(3,'王五'); insert into student(id,name) values(2,'李四');
此时表student 中就有三条数据了,对应的 undo 如下图所示:

步骤3:接着事务 A 开启第二次查询,根据可重复读隔离级别的规则,此时事务 A 并不会再重新生成ReadView。此时表 student 中的 3 条数据都满足 where id>=1 的条件,因此会先查出来。然后根据ReadView 机制,判断每条数据是不是都可以被事务 A 看到。
1)首先 id=1 的这条数据,前面已经说过了,可以被事务 A 看到。 2)然后是 id=2 的数据,它的 trx_id=30,此时事务 A 发现,这个值处于 up_limit_id 和 low_limit_id 之间,因此还需要再判断 30 是否处于 trx_ids 数组内。由于事务 A 的 trx_ids=[20,30],因此在数组内,这表示 id=2 的这条数据是与事务 A 在同一时刻启动的其他事务提交的,所以这条数据不能让事务 A 看到。 3)同理,id=3 的这条数据,trx_id 也为 30,因此也不能被事务 A 看见。

结论:最终事务 A 的第二次查询,只能查询出 id=1 的这条数据。这和事务 A 的第一次查询的结果是一样的,因此没有出现幻读现象,所以说在 MySQL 的可重复读隔离级别下,不存在幻读问题。
总结:
这里介绍了 MVCC 在 READ COMMITTD 、 REPEATABLE READ 这两种隔离级别的事务在执行快照读操作时 访问记录的版本链的过程。这样使不同事务的 读-写 、 写-读 操作并发执行,从而提升系统性能。 核心点在于 ReadView 的原理, READ COMMITTD 、 REPEATABLE READ 这两个隔离级别的一个很大不同就是生成ReadView的时机不同: READ COMMITTD 在每一次进行普通SELECT操作前都会生成一个ReadView REPEATABLE READ 只在第一次进行普通SELECT操作前生成一个ReadView,之后的查询操作都重复使用这个ReadView就好了
9、Mysql范式
是什么范式?
在关系型数据库中,关于数据表设计的基本原则、规则就称为范式。
范式的分类?
第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF)
第一范式
主要是确保数据表中么个字段的值必须具有原子性,也就是说数据表中每个字段的值为不可再次拆分的最小数据单元。
第二范式
在满足第一范式的基础上,还要满足数据表里的每一条数据记录,都是可唯一标识的。而且所有非主键字段,都必须完全依赖主键,不能只依赖主键的一部分。
第三范式
在第二范式的基础上,确保数据表中的每一个非主键字段都和主键字段直接相关,也就是说,要求数据表中的所有非主键字段不能依赖于其他非主键字段(即,不能存在非主属性A依赖于非主属性B,非主属性B依赖于主键C的情况,即存在“A-》B-》C”的决定关系)通俗的将,该规则的意思是非逐渐属性之间不能有依赖关系,必须相互独立。
10、InnoDB存储引擎的数据结构
InnoDB将数据划分为若干页,InnoDB中页的大小默认为16KB。
以页作为磁盘交互内存之间的基本单位,也就是一次最少从磁盘中读取16KB的内容到内存中,一次最少把内存中的16KB内容刷新到磁盘中。也就是说,在数据库中,不论读一行,还是读多行,都是将这些行所在的页进行加载。也就是说,数据库管理存储空间的基本单位是页,数据库I/O操作的最小单位是页,一个页中可以存储多个行记录。
记录是按照行来存储的,但是数据库的读取并不是以行为单位,否则一次读取(也就是一次I/O操作)只能处理一行数据,效率会非常低。
1、页

页结构概述
页a、页b、页c等等这页可以不在物理结构上相连,只要通过双向链表相关联即可。每个数据页中的记录会按照主键值从小到大的顺序组成一个单向链表,每个数据页都会为存储在它里边的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。
页的大小
Mysql中页的默认大小是16KB,可以通过show variables like '%innodb_page_size'命令来查看。
页的上层结构
另外在数据库中,还存在着区(Extent)、段(Segment)和表空间(Tablespace)的概念。行、页、区、段、表空间的关系如下图所示:


11、什么是索引覆盖?
如果要查询的字段都建立过索引,那么引擎会直接在索引表中查询而不会访问原始数据(否则只要有一个字段没有建立索引就会做全表扫描),
12、InnoDB存储引擎的锁的算法有三种
Record Lock(记录锁):单个行记录上的锁
Gap Lock(间隙锁):锁定一个范围,不包括记录本身
Next-key Lock:record+gap锁定一个范围,包含记录本身
13、什么是死锁?怎么解决?
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
解决死锁的方法
如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会;
在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
15、主键使用自增ID还是UUID
推荐使用自增ID,不要使用UUID。
因为在InnoDB存储引擎中,主键索引是作为聚簇索引存在的,也就是说,主键索引的B+树叶子节点上存储了主键索引以及全部的数据(按照顺序)如果主键索引是自增ID,那么只需要不断向后排列即可,如果是UUID,由于到来的ID与原来的大小不确定,会造成非常多的数据插入,数据移动,然后导致产生很多的内存碎片,进而造成插入性能的下降。
总之,在数据量大的一些情况下,用自增主键性能会好一些。关于主键是聚簇索引,如果没有主键,InnoDB会选择一个唯一键来作为聚簇索引,如果没有唯一键,会生成一个隐式的主键。
16、索引的设计原则?
1)、选择唯一索引
2)、为常作为查询条件的字段建立索引
3)、为经常需要排序、分组和联合操作的字段建立索引
4)、限制索引数目
5)、小表不建议索引
6)、尽量使用数据量少的索引
7)、删除不再使用或很少使用的索引
17、为什么InnoDB没有用一个变量来统计表的行数?
因为InnoDB的事务特性,在同一时刻表中的行数对于不同的事务而言是不一样的。
18、请说说悲观锁和乐观锁
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会等待直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。
传统的关系型数据库里面就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在操作之前先上锁。
两种锁的使用场景
乐观锁: GIT,SVN,CVS等代码版本控制管理器,就是一个乐观锁使用很好的场景,例如:A、B程序员,同时从SVN服务器上下载了code.html文件,当A完成提交后,此时B再提交,那么会报版本冲突,此时需要B进行版本处理合并后,再提交到服务器。这其实就是乐观锁的实现全过程。如果此时使用的是悲观锁,那么意味者所有程序员都必须一个一个等待操作提交完,才能访问文件,这是难以接受的。
悲观锁: 悲观锁的好处在于可以减少并发,但是当并发量非常大的时候,由于锁消耗资源、锁定时间过长等原因,很容易导致系统性能下降,资源消耗严重。因此一般我们可以在并发量不是很大,并且出现并发情况导致的异常用户和系统都很难以接受的情况下,会选择悲观锁进行。
19、什么是快照读和当前读?
快照读
就是读取的是快照数据,不加锁的简单Select都属于快照读。
当前读
就是读的是最新数据,而不是历史的数据,加锁的Select,或者对数据进行增删改都会进行当前读。
20、mysql的性能调优
Mysql优化主要分为以下四大方面:
-
设计:存储引擎,字段类型,范式与逆范式
-
功能:索引,缓存,分区分表,数据库连接池
-
架构:主从复制(主库写,从库读),读写分离,集群,负载均衡
-
合理SQL:测试,优化查询语句,经验, Explain 查看执行计划, 慢日志
mysql中优化SQL语句的话,大部分指的都是优化查询SQl语句。
sql语句中尽量避免使用or来连接条件查询数据。因为使用or会导致sql的时候进行全表查询,而不是使用索引查询。
任何地方都不要使用select * from t,用具体的字段列表代替“*”,不要返回用不到的任何字段。
在连续数值的查询中,能使用between的情况下尽量使用between,而不使用in。因为in和not in都会导致全表查询。
多张数据表关联查询的时候,使用inner join,left/right join来代替子查询,可以提高查询的效率。
在使用like进行数据表的查询是,能用单%的情况下,不建议使用双%,双%查询会导致mysql引擎放弃使用索引而进行全表扫描查询。
应尽量避免在where子句中对字段进行表达式操作、在where子句中对字段进行null值判断,否则将导致引擎放弃使用索引而进行全表扫描。
尽量使用exists代替in
1)、MySQL中如何优化慢查询
慢查询是什么?
用于记录执行时间超过某个临界值的SQL日志,用于快速定位慢查询,为我们的优化做参考。
配置项:slow_query_log可以使用show variables like ‘slow_query_log' 查看是否开启,如果状态为OFF,可以使用set GLOBAL slow_query_log = on 来开启,他会在dataDir下产生一个xxx-slow.log的文件
首先要搞明白慢的原因是什么:是查询条件没有命中索引?还是load了不需要的数据列?还是数据量太大?所以优化也是针对这三个方向来的。
(1)、可以开启慢查询日志,定位查询慢的sql,然后去分析它
开启slow_query_log:set global slow_query_log='ON';
然后我们再来查看下慢查询日志是否开启,以及慢查询日志文件的位置:

你能看到这时慢查询分析已经开启,同时文件保存在 /var/lib/mysql/atguigu02-slow.log 文件中。
修改long_query_time阈值:set long_query_time=1;
当我们设置了这两个参数以后,在执行select查询的时候,如果查询的时间大于我们设置的阈值,他就会被记录到我们的slow_query_log_file文件中。
查询当前系统中有多少条慢查询记录:SHOW GLOBAL STATUS LIKE '%Slow_queries%';
(2)、也可以用explain分析语句的执行计划,查看使用索引的情况,是不是查询没走索引,如果可以加索引解决优先采用加索引
(3)分析语句,看看是否存在了一些导致索引失效的用法,是否load了额外的数据,是否加载了许多结果中不需要的列,对语句进行分析以及重写
(4)、如果对语句的优化已经无法进行,可以参考表中的数据量是否太大,如果是的话可以进行垂直拆分或者水平拆分
在我们写select查询语句的时候可以根据一些规则来写,增加查的速度,尽量避免慢sql的出现
博客:慢查询优化方案-SQL篇-技术圈,索引与慢查询优化 - JasonJi - 博客园
21、MySQL的整体架构


MySQL整体架构可以分为三个层次:
第一层负责连接处理、授权认证、安全等等。
每个客户端连接都会在服务器进程中拥有一个线程,服务器维护了一个线程池,因此不需要为每一个新建的连接创建或者销毁线程。
当客户端连接到MySQL服务器时,服务器会对其进行认证,通过用户名和密码认证,也可以通过SSL证书进行认证。
一旦客户端连接成功,服务器会继续验证客户端是否具有执行某个特定查询的权限。
第二层负责编译并优化SQL:
这一层包括查询解析、分析、优化、缓存以及所有的内置函数。
对于SELECT语句,在解析查询前,服务器会先检查查询缓存,如果能在期货中找到对应的查询结果,则无需再进行查询解析、优化等过程,直接返回查询结果。
所有跨存储引擎的功能都在这一层实现:存储过程、触发器、视图
又分为连接池、分析器、优化器(优化sql,规定执行流程,解析规则有两种CBO、RBO)、执行器(根据优化器规定的执行流程,存储或过滤数据)

第三层是存储引擎:
存储引擎负责在MySQL中存储数据、提取数据。
存储引擎通过API与上层进行通信,这些API屏蔽了不同存储引擎之间的差异,使得这些差异对上层查询过程透明。
存储引擎不会去解析sql,不同的存储引擎之间也不会相互通信,而只是简单地响应上层服务器的请求。
22、缓冲池
MySQL5.5.5之后,InnoDB作为默认存储引擎,InnoDB是以页为单位来管理存储空间的,DBMS会将磁盘上的页面加载到内存中的Buffer Pool(优先对使用频次高的数据进行加载),SQL语句与缓冲池进行交互,减少了磁盘I/O。InnoDB缓冲池包括了数据页、索引页、插入缓冲、锁信息、自适应Hash和数据字典信息等。

1)、缓冲池的读写数据
读数据
缓冲池管理器会尽量将经常使用的数据保存起来,在数据库进行页面操作的时候,首先会判断该页面是否在缓冲池中,如果存在就直接读取,如果不存在,就会通过内存或磁盘将页面放到缓冲池中在进行读取。
写数据
首先修改缓冲池中页面的记录信息,然后数据库以一定的频率刷新到磁盘上。并不是每次发生更新操作,都会立刻进行磁盘回写(没回写前,缓冲池中被修改过的页被称为脏页),缓冲池采用一种叫做checkpoint的机制将数据会写到磁盘上。
比如,当缓冲池不够用时,需要释放一些不常用的页,此时就可以强行采用checkpoint的方式,将不常用的脏页回写到磁盘上,然后再从缓冲池将这些页释放掉。

六、Redis
1、redis中的RDB和AOF机制
RDB机制
能够在指定的时间间隔对你的数据进行快照存储,生成一个快照文件然后写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。

生成RDB文件的redis命令:SAVE、BGSAVE
执行bgsave命令时,Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到 一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
fork子进程
Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等) 数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,Linux中引入了“写时复制技术”
一般情况父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。

优点
1、整个redis数据库将只包含一个文件dump.rdb,方便持久化
2、容灾性好,方便备份
3、性能最大化,fork子进程来完成写操作,让主进程继续处理命令,所以是IO最大化。使用单独子进程来进行持久化,主进程不会进行任何IO操作,保证了redis的高性能。
4、相对于数据集大时,比AOF的启动效率更高。
缺点
1、数据安全性低。RDB是间隔一段时间进行持久化,如果持久化之间redis发生故障,会发生数据丢失。所以这种方式更适合和数据要求不严谨的时候。
2、由于RDB是通过fork子进程来协助完成数据持久化工作到的,因此,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至一秒钟。
AOF机制
以日志的形式来记录每个写操作(增量保存),将Redis执行过的所有写指令记录下来(读操作不记录), 只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
AOF持久化流程
(1)客户端的请求写命令会被append追加到AOF缓冲区内;
(2)AOF缓冲区根据AOF持久化策略[always,everysec,no]将操作sync同步到磁盘的AOF文件中;
(3)AOF文件大小超过重写策略或手动重写时,会对AOF文件rewrite重写,压缩AOF文件容量;
(4)Redis服务重启时,会重新load加载AOF文件中的写操作达到数据恢复的目的;

AOF同步频率设置
appendfsync always:始终同步,每次Redis的写入都会立刻记入日志;性能较差但数据完整性比较好
appendfsync everysec:每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。
appendfsync no:redis不主动进行同步,把同步时机交给操作系统。
优点
1、数据安全,Redis中提供了3种同步策略,即每秒同步、没修改同步和不同步。事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。而每修改同步,我们可以将其视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中。
2、通过append模式写文件,即使中途服务器宕机也不会破幻已经存在的内容,可以通过redis-check-aof工具结局数据一致性问题。
3、AOF机制的rewrite模式。定期对AOF文件进行重写,以达到压缩的目的。
缺点
1、AOF文件比RDB文件大,且恢复速度慢
2、数据集大的时候,比RDB启动效率低
3、运行效率没有RDB高
AOF文件比RDB更新频率高,优先使用AOF还原数据;AOF比RDB更安全页更大;RDB性能比AOF好;如果两个都配置了的话,优先使用AOF。
2、Redis过期键的删除策略
往redis里写的数据是怎么没了的?
redis过期键的删除策略
如果一个键是过期的,那它到了过期时间之后是不是马上就从内存中被删除呢?不是,如果不是,那过期后到底什么时候被删除呢?是个什么操作呢?
redis中三种不同的删除策略
定时删除:总结---对CPU不友好,用处理器性能换取存储空间(拿时间换空间)
惰性删除:总结--对memory不友好,用存储空间换取处理器性能(拿空间换时间)
上面两种方案都走极端-定期删除-定期抽样key,判断是否过期(存在漏网之鱼)
定时删除
Redis不可能时时刻刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后对它进行删除。
立即删除能保证内存数据的最大新鲜度,因为它保证过期键值在过期后马上被删除,其所占用的内存也会随之释放。但是立即删除对cpu是最不友好的。因为删除操作会占用CPU时间,如果刚好碰上了CPU很忙的时候,比如正在做交集或排序等计算的时候,就会给CPU造成额外的压力,让CPU心累,时时需要删除,忙死。
这会产生大量的性能消耗,同时也会影响数据的读取操作。
惰性删除
数据到达过期时间,不做处理。等下次访问该数据时,如果未过期,返回数据;返现已经过期,删除,返回不存在。
惰性删除策略的缺点是:它对内存时是最不友好的。
如果一个键已经过期,而这个键仍然保留在数据库中,那么只要这个过期键不被删除,它所占用的内存就不会释放。
在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有访问到的话,那么他们也许永远也不会被删除(除非用户手动执行FLUSHDB),我们甚至可以将这种情况看做是一种内存泄漏-无用的垃圾数据占用了大量内存,而服务器却不会自己去释放他们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息。
定期删除
定期删除处理是前两种的折中:
定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少对CPU时间的影响。
同期性轮询Redis库中的时效性数据,来用随机抽取的处理,利用过期数据占比的方式来控制删除频度。
特点1:CPU性能占用设置有峰值,检测频度可自定义设置
特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
总结:周期性抽查存储空间(随机抽查,重点抽查)
举例
redis默认每隔100ms检查,是否有过期的key,有过期key则删除。注意:redis不是每隔100ms将所有的key检查一次而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis直接进去ICU)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
定期删除策略的难点是确定删除操作执行的时长和频率:如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化成定时删除策略,以至于将CPU时间过多地消耗在删除过期键上面。如果删除操作执行得太少,或者执行的时间太短,定期删除策略又会和惰性删除束略一样,出现浪费内存的情况。因此,如果采用定期删除策略的话,服务器必须根据情况,合理地设置删除操作的执行时长和执行频率。
上述步骤都过堂了,还有漏洞吗?
-
定期删除时,从来没有被抽查到
-
惰性删除时,也从来没有被点中使用过
上述2步骤====>大量过期的key堆积在内存中,导致redis内存空间紧张或者很快耗尽
必须要有一个更好的兜底方案
内存淘汰策略登场(Redis 6.2版本)
noeviction:不会驱逐任何key(默认) volatile-lfu:对所有设置了过期时间的key使用LFU算法进行删除 volatile-Iru:对所有设置了过期时间的key使用LRU算法进行删除 volatile-random:对所有设置了过期时间的key随机删除 volatile-ttl:删除马上要过期的key allkeys-lfu:对所有key使用LFU算法进行删除 allkeys-Iru:对所有key使用LRU算法进行删除 allkeys-random:对所有key随机删除
上面总结
2*4得8 2个维度 过期键中筛选 所有键中筛选 4个方面 LRU LFU random ttl(Time To Live) 8个选项 如何配置,修改
命令 config set maxmemory-policy noeviction config get maxmemory 配置文件 - 配置文件redis.conf的maxmemory-policy参数
1)、lru算法简介
Redis的LRU了解过吗?可否手写一个LRU算法
是什么?
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的数据予以淘汰。
LRU算法的思想
设计思想
所谓缓存,必须要有读+写两个操作,按照命中率的思路考虑,写操作+读操作时间复杂度都需要为O(1) 特性要求 必须要有顺序之分,一区分最近使用的和很久没有使用的数据排序。 写和读操作一次搞定。 如果容量(坑位)满了要删除最不长用的数据,每次新访问还要把新的数据插入到队头(按照业务你自己设定左右那一边是队头) 查找快、插入快、删除快,且还需要先后排序---------->什么样的数据结构可以满足这个问题?
你是否可以在O(1)时间复杂度内完成这两种操作?
如果一次就可以找到,你觉得什么数据结构最合适?
答案:LRU的算法核心是哈希链表
编码手写如何实现LRU
本质就是HashMap + DoubleLinkedList
时间复杂度是O(1),哈希表+双向链表的结合体
(1)、巧用LinkedHashMap完成lru算法
public class LRUCacheDemo<K,V> extends LinkedHashMap<K,V> {
private int capacity;//缓存坑位
public LRUCacheDemo(int capacity){
/**
* Params:
* initialCapacity – the initial capacity 初始容量
* loadFactor – the load factor 加载因子,一般是 0.75f
* accessOrder – the ordering mode -
* true for access-order, 按照访问顺序
* false for insertion-order 按照插入插入顺序
*/
super(capacity,0.75F,true);
this.capacity = capacity;
}
/**
* LinkedHashMap自带的判断是否删除最老的元素方法,默认返回false,即不删除老数据
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return super.size() >capacity;
}
public static void main(String[] args) {
LRUCacheDemo<Object, Object> lruCacheDemo = new LRUCacheDemo<>(3);
lruCacheDemo.put(1,"a");
lruCacheDemo.put(2,"b");
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(4,"d");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(3,"c");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(5,"x");
System.out.println(lruCacheDemo.keySet());
}
}(2)、手写LRU
class LRUCache2{
//构造一个node节点作为数据载体
class Node<K, V>{//双向链表节点
K key;
V value;
Node<K, V> prev;
Node<K, V> next;
public Node() {
this.prev = this.next = null;
}
public Node(K key, V value) {
super();
this.key = key;
this.value = value;
}
}
//新的插入头部,旧的从尾部移除,构建一个虚拟的双向链表,里面安放的就是我们的Node
class DoublyLinkedList<K, V>{
Node<K, V> head;
Node<K, V> tail;
/**
* 在这个虚拟的双向链表中,有两个头尾节点用来位置的我们的真实数据node
*/
public DoublyLinkedList() {
//头尾哨兵节点
this.head = new Node<K, V>();
this.tail = new Node<K, V>();
this.head.next = this.tail;
this.tail.prev = this.head;
}
//添加一个头节点
public void addHead(Node<K, V> node) {
//让node的下一个指向head的下一个也就是tail
node.next = this.head.next;
//node的前一个指向head
node.prev = this.head;
this.head.next.prev = node;
this.head.next = node;
}
public void removeNode(Node<K, V> node) {
node.prev.next = node.next;
node.next.prev = node.prev;
node.prev = null;
node.next = null;
}
public Node<K, V> getLast() {
if(this.tail.prev == this.head)
return null;
return this.tail.prev;
}
}
private int cacheSize; //初始容量
private Map<Integer, Node<Integer, Integer>> map;
private DoublyLinkedList<Integer, Integer> doublyLinkedList;
public LRUCache2(int cacheSize) {
this.cacheSize = cacheSize;
map = new HashMap<>();
doublyLinkedList = new DoublyLinkedList<>();
}
public int get(int key) {
if(!map.containsKey(key)) {
return -1;
}
Node<Integer, Integer> node = map.get(key);
//更新节点位置,将节点移置链表头
doublyLinkedList.removeNode(node);
doublyLinkedList.addHead(node);
return node.value;
}
public void put(int key, int value) {
if(map.containsKey(key)) {
//如果map里面已经有一个相同的node了,删除原先的把新的插入到头节点
Node<Integer, Integer> node = map.get(key);
node.value = value;
map.put(key, node);
doublyLinkedList.removeNode(node);
doublyLinkedList.addHead(node);
}else {
if(map.size() == cacheSize) {//已达到最大容量了,把旧的移除,让新的进来
Node<Integer, Integer> lastNode = doublyLinkedList.getLast();
map.remove(lastNode.key);//node.key主要用处,反向连接map
doublyLinkedList.removeNode(lastNode);
}
Node<Integer, Integer> newNode = new Node<>(key, value);
map.put(key, newNode);
doublyLinkedList.addHead(newNode);
}
}
}
3、redis线程模型、单线程快的原因
为什么Redis是单线程?
这里我们强调的单线程,指的是网络请求模块使用一个线程来处理,即一个线程处理所有网络请求,其他模块仍用了多个线程。
那么为什么使用单线程呢?官方答案是:因为CPU不是Redis的瓶颈,redis的瓶颈最有可能是机器内存或者网络带宽,既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用了单线程的方案了。
但是我们使用单线程的方式是无法发挥多核CPU性能,不过我们可以通过在单机上开多个redis实例来解决这个问题。
redis4.0以后开始的多线程
不同版本的Redis是不同的,在Redis4.0之前,Redis是单线程运行的,但单线程并不代表效率低,像Nginx、Nodejs也是单线程程序,但是它们的效率并不低。
但是在Redis4.0的时候,已经开始支持多线程了,比如后台删除等功能,Redis在4.0版本中虽然引入了多线程,但是此版本的多线程只能用于大数据量的异步删除,对于非删除操作的意义并不是很大。
Redis6.0是默认禁用多线程的,但可以通过配置文件redis.conf中的io-threads-do-reads 等于 true 来开启。但是还不够,除此之外我们还需要设置线程的数量才能正确地开启多线程的功能,同样是修改Redis的配置,例如设置 io-threads 4,表示开启4个线程。
【关于线程数的设置,官方的建议是如果为4核CPU,那么设置线程数为2或3;如果为8核CPU,那么设置线程数为6.总之线程数一定要小于机器的CPU核数,线程数并不是越大越好。】
redis6.0之前为什么一直不使用多线程?
redis 使用多线程的可维护性高。多线程模型虽然在某些方面表现优异,但是它却引入了程序执行顺序的不确定性,带来了并发读写的一系列问题,增加了系统复杂度、同时可能存在线程切换、甚至加锁解锁、死锁造成的性能损耗。
Reids为什么这么快?
a.基于内存操作:Redis的所有数据都存在内存中,因此所有的运算都是内存级别的,所以它的性能比较高。
b.数据结构简单:Redis的数据结构比较简单,是为Redis专门设计的,而这些简单的数据结构的查找和操作的时间复杂度都是O(1)。
c.多路复用和非阻塞IO:Redis使用IO多路复用功能来监听多个socket连接的客户端,这样就可以使用一个线程来处理多个情况,从而减少线程切换带来的开销,同时也避免了IO阻塞操作,从而大大提高了Redis的性能。
d.避免上下文切换:因为是单线程模型,因此就避免了不必要的上下文切换和多线程竞争,这就省去了多线程切换带来的时间和性能上的开销,而且单线程不会导致死锁的问题发生。
官方使用的基准测试结果表明,单线程的Redis可以达到10W/S的吞吐量。
总结
Redis在4.0之前单线程依然快的原因:基于内存操作、数据结构简单、IO多路复用和非阻塞IO、避免了不必要的线程上下文切换。并且在Redis4.0开始支持多线程,主要体现在大数据的异步删除方面,例如:unlink key、flushdb async、flushall async等。而Redis6.0的多线程则增加了对IO读写的并发能力,用于更好的提升Redis的性能。
4、redis中的缓存雪崩、缓存穿透、缓存击穿
1)、缓存雪崩
问题描述
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存雪崩与缓存击穿的区别在于这里针对很多key缓存,前者则是某一个key正常访问
缓存雪崩是指在我们设置缓存时key采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。


解决方案
(1) 构建多级缓存架构:nginx缓存 + redis缓存 +其他缓存(ehcache等)
(2) 使用锁或队列:用加锁或者队列的方式来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况
(3) 设置过期标志更新缓存:记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
(4) 将缓存失效时间分散开:比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
2)、缓存穿透
问题描述
key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会压到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。

解决方案
一个一定不存在缓存及查询不到的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
(1) 对空值缓存:如果一个查询返回的数据为空(不管是数据是否不存在),我们仍然把这个空结果(null)进行缓存,设置空结果的过期时间会很短,最长不超过五分钟
(2) 设置可访问的名单(白名单):使用bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmap里面的id进行比较,如果访问id不在bitmaps里面,进行拦截,不允许访问。
(3) 采用布隆过滤器:(布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。)
将所有可能存在的数据哈希到一个足够大的bitmaps中,一个一定不存在的数据会被 这个bitmaps拦截掉,从而避免了对底层存储系统的查询压力。
(4) 进行实时监控:当发现Redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
3)、缓存击穿
问题描述
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存击穿是指并发查同一条数据。缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期)==,由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。

解决方案
key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
(1)预先设置热门数据:在redis高峰访问之前,把一些热门数据提前存入到redis里面,加大这些热门数据key的时长
(2)实时调整:现场监控哪些数据热门,实时调整key的过期时长
(3)使用锁:
(1) 就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db。
(2) 先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX)去set一个mutex key
(3) 当操作返回成功时,再进行load db的操作,并回设缓存,最后删除mutex key;
(4) 当操作返回失败,证明有线程在load db,当前线程睡眠一段时间再重试整个get缓存的方法。
5、简述redis事务实现
redis是没有回滚机制的,要么一块执行,要不不执行
Redis事务是什么?redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令
Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。Redis事务的主要作用就是串联多个命令防止别的命令插队。
从输入Multi命令开始,输入的命令都会依次进入命令队列中,但不会执行,直到输入Exec后,Redis会将之前的命令队列中的命令依次执行。

事务的错误处理:组队中某个命令出现了报告错误,执行时整个的所有队列都会被取消。

如果执行阶段某个命令报出了错误,则只有报错的命令不会被执行,而其他的命令都会执行,不会回滚。

在执行multi之前,先执行watch key1 [key2],可以监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断
unwatch:取消 WATCH 命令对所有 key 的监视。如果在执行 WATCH 命令之后,EXEC 命令或DISCARD 命令先被执行了的话,那么就不需要再执行UNWATCH 了。
redis事务的执行流程
事务开始:MULTI命令的执行,标识着一个事务的开始。MULTI命令会将客户端状态的flags属性中打开REDIS_MULTI标识来完成的。
命令入队:当一个客户端切换到事务状态之后,服务器会根据这个客户端发送来的命令来执行不同的操作。如果客户端发送的命令为MULTI、EXEC、WATCH、DISCARD中的一个,立即执行这个命令,否则将命令放入一个事务队列里面,然后向客户端返回QUEUED回复。
如果客户端发送的命令为EXEC、DISCARD、WATCH、MULTI四个命令的其中一个,那么服务器立即执行这个命令。如果客户端发送的是四个命令以外的其他命令,那么服务器并不立即执行这个命令。首先检查此命令的格式是否正确,如果不正确,服务器会在客户端状态(redisClient)的flags属性关闭REDIS_MULTI标识,并且返回错误信息给客户端。如果正确,将这个命令放入一个事务队列里面,然后后向客户端返回QUEUED回复。事务队列是按照FIFO的方式保存入队的命令。
事务执行:客户端发送EXEC命令,服务器执行EXEC命令逻辑。
如果客户端状态的flags属性不包含REDIS_MULTI标识,或者包含REDIS_DIRTY_CAS或者REDIS_DIRTY_EXEC标识,那么就直接取消事务的执行。
否则客户端处于事务状态(flags有REDIS_MULTI标识),服务器会遍历客户端的事务队列,然后执行事务队列中的所有命令,最后将返回结果全部返回给客户端;redis不支持事务回滚机制,但是它会检查每一个事务中的命令是否错误。Redis事务不支持检查那些程序员自己逻辑错误。
WATCH命令是一个乐观锁,可以为Redis事务提供check-and-set(CAS)行为。可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行,监控一直持续到EXEC命令。
MULTI命令用于开启一个事务,它总是返回OK。MULTI执行,客户端可以继续向服务器发送任意多条命令,这些命令不会立即执行,而是被放到一个队列中,当EXEC命令被调用时,所有队列中的命令才会被执行。
EXEC执行所有事务块内的命令。返回事务块内所有命令的返回值,按命令执行的先后顺序排列。当操作被打断时,返回空值null
通过调用DISCARD,客户端可以清空事务队列,并放弃执行事务,并且客户端会从事务状态中退出。
UNWATCH命令可以取消WATCH对所有key的监控。
6、redis集群方案
1)、主从复制原理

从服务器连接主服务器,发送SYNC命令。主服务器接收到SYNC命令后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令。主服务器BGSAVE执行完成后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令。从服务器收到快照文件后丢弃所有旧数据,载入收到的快照。主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令。
从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令(从服务器初始化完成)。主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令(从服务器初始化完成后的操作)
Redis主从复制可以根据是否是全量分为全量同步和增量同步:
全量复制
1、从服务器连接主服务器,发送sync命令
2、主服务器接收到sync命令后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
3、主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
4、从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
5、主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
6、从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令。
当主从服务器之间的连接由于某些原因断开时,从服务器可以自动进行重连接。当有多个从服务器同时请求同步时,主服务器只进行一个后台存储。当连接断开又重新连上之后,一般都会进行一个完整的重新同步,但是从Redis2.8开始,只重新同步一部分也可以。
部分复制
1、复制偏移量:执行复制的双方,主从节点,分别会维护一个复制偏移量的offset
2、复制积压缓冲区:主节点内部维护了一个固定长度的、先进先出(FiFO)队列,作为复制积压缓冲区,当主从节点offset的差距过大超过缓冲区的长度时,将无法执行部分复制,只能执行全量复制。
3、服务器运行ID(runid):每个redis节点,都有其运行ID,运行ID由节点在启动时自动生成,主节点会将自己的运行ID发送给从节点,从节点会将主节点的运行ID存起来。从节点Redis断开重连时,就是根据运行ID来判断同步的进度。
如果从节点保存的runid与主节点的runid相同,说明主从节点之前同步过,主节点会继续尝试使用部分复制(到底能不能部分复制还要看offset和复制积压缓冲区的情况)。
如果从节点保存的runid与主节点现在的runid不同,说明从节点在断线前同步的redis节点并不是当前的主接地那,只能进行全量复制。
2)、哨兵模式
当主服务器中断服务后,可以将一个从服务器升级为主服务器,以便继续提供服务,但是这个过程需要人工手动来操作。 为此,Redis 2.8中提供了哨兵工具来实现自动化的系统监控和故障恢复功能。
哨兵的作用就是监控Redis系统的运行状况。它的功能包括以下两个。
(1)监控主服务器和从服务器是否正常运行。 (2)主服务器出现故障时自动将从服务器转换为主服务器。
哨兵的工作方式
每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
-
如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过
down-after-milliseconds选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN) -
如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态
-
当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)
-
在一般情况下, 每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
-
当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
-
若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
优点
-
哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
-
主从可以自动切换,系统更健壮,可用性更高。
缺点
-
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
7、Redis如何与数据库保持双写一致性
保证缓存和数据库的双写一致性,共有四种同步策略,即先更新缓存再更新数据库、先更新数据库再更新缓存、先删除缓存再更新数据库、先更新数据库再删除缓存。
先更新缓存的优点是每次数据变化时都能及时地更新缓存,这样不容易出现查询未命中的情况,但这种操作的消耗很大,如果数据需要经过复杂的计算再写入缓存的话,频繁的更新缓存会影响到服务器的性能。如果是写入数据比较频繁的场景,可能会导致频繁的更新缓存却没有业务来读取该数据。
删除缓存的优点是操作简单,无论更新的操作复杂与否,都是直接删除缓存中的数据。这种做法的缺点则是,当删除了缓存之后,下一次查询容易出现未命中的情况,那么这时就需要再次读取数据库。
那么对比而言,删除缓存无疑是更好的选择。
先删除缓存再操作数据库的话,如果第二步骤失败可能导致缓存和数据库得到相同的旧数据。
先操作数据库但删除缓存失败的话则会导致缓存和数据库得到的结果不一致。
出现上述问题后,一般采用重试机制解决,而为了避免重试机制影响主要业务的执行,一般建议重试机制采用异步的方式执行。
当我们采用重试机制之后由于存在并发,先删除缓存依然可能存在缓存中存储了旧的数据,而数据库存储了新的数据,二者数据不一致的情况。所以我们得到结论:先更新数据库、再删除缓存是影响最小的方案。如果第二步出现失败的情况,则可以采用重试机制解决问题。
博客:redis缓存更新策略方式_terry5566的博客-CSDN博客_redis数据怎么更新
博客:Redis中的几种更新策略_LG_985938339的博客-CSDN博客_更新redis数据的几种方法
8、Redis是什么?
Reids是一个使用C语言编写的,开源的高性能非关系型的键值对数据库。与传统数据库不同的是Redis的数据时存在内存中的,所以读写速度非常快。
9、Redis的优缺点?
优点:
读写性能优异,Redis能读的速度是110000/s,写的速度是81000次/s
支持数据持久化,支持AOF和RDB两种持久化方式
支持事务,Redis的所有操作都是原子性的,同时还支持对几个操作合并后的原子执行。
数据结构丰富
支持主从复制
缺点:
数据库容量受到物理内存的限制,不能用作海量数据的高性能读写。
Redis不具备自动容错和恢复功能。
主机宕机,宕机前有部分数据未能及时同步到丛集,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
Redis较难支持在线扩容,在集群容量上达到上限时在线扩容会变得很复杂。
10、为什么要用 Redis /为什么要用缓存
主要是从“高性能”和“高并发”来说。
高性能:
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在缓存中,这样下次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变之后,同步改变缓存中相应的数据即可!
高并发:
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
11、Redis有哪些数据类型
Redis主要有5种常用的数据类型,包括String、List、Set、Zset、Hash。满足大部分的使用要求。
| 数据类型 | 可以存储的值 | 操作 | 使用场景 |
|---|---|---|---|
| String | 字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作,对整数和浮点数执行自增或者自减操作 | 做简单键值对缓存 |
| List | 列表 | 从两端压入或者弹出元素,对单个或者多个元素进行修剪,只保留一个范围内的元素 | 存储一些列表类型的数据结构,类似粉丝列表、文章的评论列表之类的数据 |
| Set | 无序集合 | 添加、获取、移出单个元素,检查一个元素是否存在集合中计算交集、并集、差集从集合里面随机获取元素 | 交集、并集、差集的操作,比如交集,可以把两个人的粉丝列表整一个交集 |
| Hash | 包含键值对的无需散列表 | 添加、获取、移出单个键值对获取所有键值对,检查某个键是否存在 | 结构化的数据,比如一个对象 |
| Zset | 有序集合 | 添加、获取、删除元素根据分值范围或者成员来获取元素计算一个键的排名 | 去重但可以排序,如获取排名前几名的用户 |
数据类型的适用场景
string——适合最简单的k-v存储,类似于memcached的存储结构,短信验证 码,配置信息等,就用这种类型来存储。
hash——一般key为ID或者唯一标示,value对应的就是详情了。如商品详情, 个人信息详情,新闻详情等。
list——因为list是有序的,比较适合存储一些有序且数据相对固定的数据。如省 市区表、字典表等。因为list是有序的,适合根据写入的时间来排序,如:最新 的***,消息队列等。
set——可以简单的理解为ID-List的模式,如微博中一个人有哪些好友,set最牛的地方在于,可以对两个set提供交集、并集、差集操作。例如:查找两个人 共同的好友等
八、网络
1、Http和Https的区别
什么是HTTP协议
HTTP是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范。
客户端和服务器端之间数据传输的格式规范,格式简称为“超文本传输协议”。是一个基于请求和响应模式的、无状态的、应用层的协议,基于TCP的连接方式。
HTTP
运行在TCP之上,明文传输,客户端和服务端都无法验证对方的身份、资源消耗较少。
HTTPS
身披SSL(Secure Socket Layer)外壳的HTTP,运行于SSL上,SSL运行于TCP之上,是添加了加密和认证机制的HTTP、由于加解密处理,会消耗更多的CPU和内存资源,由于加密机制,安全性强。
2、cookie和session的区别?
存储位置不同
cookie的数据信息存在客户端浏览器上;session的数据信息存放在服务器上。
存储容量不同
单个cookie保存的数据<=4KB,一个站点一般保存20~50个Cookie;对于session来说并没有上限,但出于对服务器端的性能考虑,session内不要存放过多的东西,并且设置session删除机制。
存储方式不同
cookie中只能保管ASCII字符串,并需要通过编码方式存储为Unicode字符或者二进制数据;session中能够存储任何类型的数据。
隐私策略不同
cookie对客户端是可见的,别有用心的人可以分析存放在本地的cookie并进行cookie欺骗,所以它是不安全的;session存储在服务器上,不存在敏感信息泄漏的风险。
有效期上不同
开发可以通过设置cookie的属性,达到使cookie长期有效的效果;session依赖于名为JESSIONID的cookie,而cookieJSESIONID的过期时间默认为-1,只需关闭窗口该session就会失效,因而session不能达到长期有效的效果。
3、TCP/IP
TCP是一种面向连接的、可靠的、基于字节流的传输层通信协议,在发送数据前,通信双方必须在彼此间建立一条连接。
ACK(确认序号有效)、FIN(释放一个连接)、SYN(发起一个新连接)
三次握手

第一次握手:客户端要想服务端发起连接请求,首先客户端随机生成一个起始序号ISN(比如是100),那客户端向服务端发送的报文段包含SYN标志位(也就是SYN=1),序列号seq=100。
第二次握手:服务端收到客户端发送过来的报文后,发现SYN=1,知道这是一个连接请求,于是将客户端的起始序列号100存起来,并且随机生成一个服务端的起始序列号(比如是300)。然后给客户端回复一段报文,恢复报文包含SYN和ACK标志(也就是SYN=1,ACK=1)、序列号seq=300、确认号ack=101(客户端发过来的序列号+1)。
第三次握手:客户端收到服务端的回复后发现ACK=1并且ack=101,于是知道服务端已经收到了序列号为100的那段报文;同时发现SYN=1,知道了服务端同意了这次连接,于是就将服务端的序列号300给存下来。然后客户端再回复一段报文给服务端,报文包含ACK标志位(ACK=1)、ack=301(服务端序列号+1)、seq=101(第一次握手时发送报文是占据一个序列号的,所以这次seq就从101开始,需要注意的是不携带数据的ACK报文是不占据序列号的,所以后面第一次正式发送数据时seq还是 101)。当服务端收到报文后发现ACK=1并且ack=301,就知道客户端收到序列号为300的报文了,就这样客户端和服务端通过TCP建立了连接。
四次挥手

第一次挥手:当客户端的数据都传输完成后,客户端向服务端发出连接释放报文(当然数据没发完时也可以发送连接释放报文并停止发送数据),释放连接报文包含FIN标志位(FIN=1)、序列号seq=1101(100+1+1000,其中的1是建立连接时占的一个序列号)。需要注意的是客户端发出FIN报文段后只是不能发数据了,但是还可以正常收数据;另外FIN报文段即使不携带数据也要占据一个序列号。 第二次挥手:服务端收到客户端发的FIN报文后给客户端回复确认报文,确认报文包含ACK标志位(ACK=1)、确认ack=1102(客户端FIN报文序列号1101+1)、序列号seq=2300(300+2000)。此时服务端处于关闭等待状态,而不是立马给客户端发FIN报文,这个状态还要持续一段时间,因为服务端可能还有数据没发完。 第三次挥手:服务端将最后数据(比如50个字节)发送完毕后就向客户端发出连接释放报文,报文包含FIN和ACK标志位(FIN=1,ACK=1)、确认号和第二次挥手一样ack=1102、序列号seq=2350(2300+50)。 第四次挥手:客户端收到服务端发的FIN报文后,向服务端发出确认报文,确认报文包含ACK标志位(ACK=1)、确认号ack=2351、序列号seq=1102。注意客户端发出确认报文后不是立马释放TCP连接,而是要经过2MSL(最长报文段寿命的2倍时长)后才释放TCP连接。而服务端一旦收到客户端发出的确认报文就会立马释放TCP连接,所以服务端结束TCP连接的时间要比客户端早一些。
为什么TCP连接的时候是3次?2次不可以吗
因为需要考虑连接时丢包的问题,如果只握手2次,第二次握手时如果服务端发给客户端的确认报文段丢失,此时服务端已经准备好了收发数(可以理解服务端已经连接成功)据,而客户端一直没收到服务端的确认报文,所以客户单就不知道服务端是否已经准备好了(可以理解为客户单未连接成功),这种情况下不会给服务端发送数据,也会忽略服务端发送过来的数据。
如果是三次握手,即便发生丢包也不会有问题,比如如果第三次握手客户端发的确认ack报文丢失,服务端在一段时间内没有收到确认ack报文的话就会重新进行第二次握手,也就是服务端重发SYN报文段,客户端收到重发的报文段后会再次给服务端发送确认ack报文。
为什么TCP连接的时候是3次,关闭的时候却是4次?
因为只有在客户端和服务端都没有数据要发送的时候才能断开TCP。而客户端发出FIN报文时只能保证客户端没有数据发了,服务端还有没有数据发客户端是不知道的。而服务端收到客户端的FIN报文后只能先回复客户端一个确认报文来告诉客户端我服务端已经收到你的FIN报文了,但我服务端还有一些数据没发完,等这些数据发完了服务端才能给客户端发FIN报文(所以不能一次性将确认报文和FIN报文发给客户端,就是这里多出来了一次)。
为什么客户端发出第四次挥手的确认报文后要等2MSL的时间才能释放TCP连接?
这里同样是要考虑丢包的问题,如果第四次挥手的报文丢失,服务端没收到确认ack报文就会重发第三次挥手的报文,这样报文一去一回最长时间就是2MSL,所以需要等这么长时间来确认服务端确实已经收到了。
如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP设有一个保活计时器,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文段仍然没有反应,服务器就认为客户端除了故障,接着就关闭连接。
4、get请求和post请求的区别
| GET | POST | |
|---|---|---|
| 可见性 | 数据在URL中对所有人可见 | 数据不会显示在URL中 |
| 安全性 | 与post相比,get的安全性较差,因为所发送的数据时URL的一部分 | 安全,因为参数不会被保存在浏览器历史或web服务器日志中 |
| 数据长度 | 受限制,最长2KB | 无限制 |
| 编码类型 | application/x-www-form-urlencoded | multipart/form-data |
| 缓存 | 能被缓存 | 不能被缓存 |
5、浏览器输入URL过程
浏览器查找域名DNS的IP地址,根据ip建立TCP连接、浏览器向服务器发送HTTP请求、服务器响应HTTP请求、浏览器进行渲染。
6、进程间的通信方式
管道、信号、消息队列、信号量、共享内存
九、Spring框架
什么是Spring?
Spring是一个轻量级Java开发框架,目的是为了解决企业级应用开发的业务逻辑层和其他各层的耦合问题。Spring负责基础架构,因此Java开发者可以专注于应用程序的开发。Spring最根本的使命是解决企业级应用开发的复杂性,即简化Java开发。
1、Sring的两大核心是什么?谈一谈对IOC和AOP的理解?
spring的两大核心是:IOC(控制翻转)和AOP(面向切面编程)
谈一谈对IOC的理解
Spring 中的 IoC 的实现原理就是工厂模式加反射机制。
IOC的意思是控制反转,是指创建对象的控制权的转移,以前创建对象的主动权和时机是由自己把控的,而现在这种权利转移到Spring容器中,并由容器根据配置文件去创建实例和管理各个实例之间的依赖关系,对象与对象之间的松散耦合,也利于功能的复用。最直观的表达就是,IOC让对象的创建不用去new,可以由spring根据我们提供的配置文件自动生产,我们需要对象的时候,直接从Spring容器中获取即可。
IOC的作用
管理对象的创建和依赖关系的维护。对象的创建并不是一件简单的事,在对象关系比较复杂时,如果依赖关系需要程序员来维护的话,那是相当头疼的。
解耦,由容器去维护具体的对象
托管了类的产生过程,比如我们需要在类的产生过程中做一些处理,最直接的例子就是代理,如果有容器程序可以把这部分交给容器,应用程序则无需关心类是如果完成代理的。
Spring的IOC有三种注入方式 :构造器注入, setter方法注入, 根据注解注入
谈一谈对AOP的理解
AOP一般称为面向切面编程,作为面向对象的一种补充,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被名为“切面”,SpringAOP使用的动态代理,所谓的动态代理就是说AOP框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。
2、Spring的对象默认是单例的还是多例的? 单例bean存不存在线程安全问题呢?
在spring中的对象默认是单例的,但是也可以配置为多例。
单例bean对象对应的类存在可变的成员变量并且其中存在改变这个变量的线程时,多线程操作该bean对象时会出现线程安全问题。
原因是:多线程操作如果改变成员变量,其他线程无法访问该bean对象,造成数据混乱。
解决办法:在bean对象中避免定义可变成员变量;在bean对象中定义一个ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中。
有状态Bean:就是有实例变量的对象,可以保存数据,是非线程安全的。
无状态Bean:就是没有实例变量的对象,不能保存数据,是不变类,是线程安全的。
3、Spring框架中都用到了哪些设计模式?
工厂模式:BeanFactory就是简单工厂模式的体现,用来创建对象的实例 单例模式:Bean默认为单例模式 代理模式:Spring的AOP功能用到了JDk的动态代理和CGLIB字节码生成技术 模板方法:用来解决代码重复问题。比如RestTemplate、JMSTemplate 观察者模式:定义对象键一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知被制动更新。如Spring中listener的实现--ApplicationListener
4、Spring事务的传播行为
spring事务的传播行为说的是,当多个事务同时存在的时候,spring如何处理这些事务的行为。
require必须的/suppor支持/mandatory 强制托管/requires-new 需要新建/ not -supported不支持/never从不/nested嵌套的
① PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。
② PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。
③ PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
④ PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事务,都创建新事务。
⑤ PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
⑥ PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
⑦ PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则按REQUIRED属性执行。
5、Spring事务什么时候会失效
Spring事务的原理是AOP,进行了切面增强,那么失效的根本原因是这个AOP不起作用了!常见的情况有如下几种:
发生自调用,类里面使用this调用本类的方法,此时这个this对象不是代理类,而是UserService对象本身,解决办法很简单,让那个this变成UserService的代理类即可! 方法不是public的 数据库不支持事务 没有被spring管理 异常被吃掉,事务不会回滚
6、Spring支持几种bean的作用域
singleton:bean在每个Spring IOC容器中只有一个实例 prototype:一个bean的定义可以有多个实例 request:每次http请求都会创建一个bean,该作用域仅在基于web的SpringApplicationContext情形下有效 session:在一个HTTPSession中,一个bean定义对应一个实例。该作用域仅在基于web的SpringApplicationContext情形下有效 global-session:在一个全局的HttpSession中,一个bean定义对应一个实例。 注意:缺省的Spring bean的作用域是Singleton。使用prototype作用域需要慎重的考虑,因为频繁创建和销毁bean会带来很大的性能开销。
7、Spring自动装配bean有哪些方式?
什么是bean装配?
装配或bean装配是在Spring容器中把bean组装到一起,前提是容器需要知道bean的依赖关系,如何通过依赖注入把它们装配到一起。
什么是bean的自动装配?
在Spring框架中,在配置文件中设定bean的依赖关系是一个很好的机制,Spring容器能够自动装配相互合作的bean,这意味着容器不需要和配置,能通过bean工厂自动处理bean之间的协作。这意味着Spring可以通过向BeanFactory中注入的方式自动搞定bean之间的依赖关系。自动装配可以设置在每个bean上,也可以设定在特定的bean上。
Spring自动装配bean有哪些方式?
在Spring中,对象无需自己查找或创建与其关联的其他对象,由容器负责把需要相互协作的对象应用赋予各个对象,使用autowire来配置自动装载模式。在Spring框架xml配置中共有5种自动装配。
no:默认的方式是不进行自动装配,通过手工设置ref属性来进行装配bean
byName:通过bean的名称进行自动装配,如果一个bean的property与另一个bean的name相同,进行自动装配。
byType:通过参数的数据类型进行自动装配。
constructor:利用构造函数进行装配,并且构造函数的参数通过byType进行装配。
autodetect:自动探测,如果有构造方法,通过construct方式自动装配,否则使用byType的方式自动装配
十一、SpringMVC
1、SpringMVC的执行流程
用户发送请求到前端控制器DispatcherServlet
前端控制器DispatcherServlet收到请求后,调用HandlerMapping处理器映射器,请求获取Handle
处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给前端控制器DispatcherServlet
前端控制器DispatcherServlet调用HandlerAdapter处理器适配器
HandlerAdapter经过适配调用具体处理器(controller ,也叫后端控制器)
controller执行完返回ModelAndView
HandlerAdapter处理器适配器将controller执行结果ModelAndView返回给前端控制器DispatcherServlet
前端控制器DispatcherServlet将ModelAndView传给ViewResolver视图解析器进行解析
ViewResolver视图解析器解析后返回具体View
前端控制器DispatcherServlet对view进行渲染视图
前端控制器DispatcherServlet响应用户
1)、什么是前端控制器DispatcherServlet
Spring的MVC框架是围绕DispatcherServlet来设计的,它用来处理所有的HTTP请求和响应
2、Spring MVC怎么样设定重定向和转发的?
(1)转发:在返回值前面加"forward:",譬如"forward:user.do?name=method4"
(2)重定向:在返回值前面加"redirect:",譬如"redirect:百度一下,你就知道"
十二、Mybatis
Mybatis是什么?
mybatis是一款优秀的持久层框架,一个半ORM(对象关系映射)框架,它支持定制化SQL、存储过程以及高级映射。Mybatis避免了几乎所有的JDBC代码和手动设置参数以及获取结果集。Mybatis可以使用简单的XML或注解来配置和映射原生类型、接口和Java的POJO为数据库中的记录。
ORM是什么?
ORM(Object Relational Mapping),对象关系映射,是一种为了解决关系型数据库数据与简单对象(POJO)的映射关系的技术。简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系型数据库中。
传统JDBC开发存在的问题?
频繁创建数据库连接对象、释放,容易造成系统资源浪费,影响系统性能。可以使用连接池解决这个问题,但是使用jdbc需要自己实现连接池。
sql语句定义、参数设置、结果集处理存在硬编码。实际项目中sql语句变化的可能性较大,需要修改java代码,系统需要重新编译,重新发布。不好维护。
使用prepareStatement向占有位符号传参数存在硬编码,因为sql语句的where条件不一定,可能多也可能少,修改sql还要修改代码,系统不易维护。
结果集存在重复代码,处理麻烦。如果可以映射成java对象会比较方便。
mybatis是如何解决这些问题呢?
在mybatis-config.xml中配置数据链接池,使用连接池管理数据库连接。
将Sql语句配置在XXXmapper.xml文件中与java代码分离。
mybatis自动将java对象映射至SQL语句。
mybatis自动将SQL执行结果映射至Java对象。
Mybatis的优缺点
基于SQL语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL写在XML里,解除sql与程序代码的耦合,便于同一管理;提供XML标签,支持编写动态SQL语句,并可重用。
与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接。
很好的与各种数据库兼容
提供映射标签,支持对象与数据库的ORM字段关系映射;提供对象关系映射标签,支持对象关系组件维护。
能够与Spring很好的集成。
缺点:SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底有一定要求。
SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。
1、mybatis的一级缓存和二级缓存是什么?
mybatis的缓存分为2类,分别是一级缓存和二级缓存,一级缓存是默认开启的,它在一个sqlSession会话里面的所有查询操作都会保存到缓存中,一般来说一个请求中的所有增删改查操作都是在同一个sqlSession里面的,所以我们认为每个请求都有自己的一级缓存,如果同一个sqlSession会话中两个查询中间有一个insert、update或delete语句,那么之前查询的所有缓存都会清空。
二级缓存是全局的,也就是说;多个请求可以共用一个缓存,二级缓存需要手动开启,有2中方式配置二级缓存,
缓存会先放在一级缓存中,当sqlSession会话提交或者关闭时才会将一级缓存刷新到二级缓存中;
开启二级缓存后,用户查询时,会先在二级缓存中找,找不到再去缓存一级中找。
十三、Springboot
什么是SpringBoot?
SpringBoot是Spring开源组织下的子项目,是Spring组件一站式解决方案,主要是简化了使用Spring的难度,简省了繁重的配置,提供了各种启动器,开发者能快速上手。
SpringBoot有哪些优点?
容易上手,提升开发效率,为Spring开发提供一个更快、更广泛的入门体验。
开箱即用,原理繁琐的配置。
提供了一些列大型项目通用的非业务性功能。
没有代码生成,也不需要XML配置。
SpringBoot的核心注解
@SpringBootApplication:通常用在启动类上,申明让springboot自动给程序进行必要的配置,他也是SpringBoot的核心注解。
@SpringBootConfiguration:组合了@Configuration注解,实现配置文件的功能。
@EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项。从配置文件META-INF/spring.factories加载所有可能用到的自动配置类
@ComponentScan:Spring组件扫描功能,让SpringBoot扫描到Configuration类并把它加入到程序上下文
RestController和Controller的区别
@RestController是@Controller+@ResponseBody的结合体,如果需要返回JSON、XML或自定义mediaType内容到页面用RestController
@Controller如果需要返回到指定页面,则需要要@Controller配合视图解析器InternalResourceViewResolver才行,@Controller类中的方法可以返回String跳转到jsp、ftl、html等模板页面。
十四、SpringCloud
什么是SpringCloud?
SpringCloud是一系列框架的有序集合。它利用SpringBoot的开发便利性巧妙地简化了分布式系统基础设施的开发。SpringCloud并没有重复制造轮子,通过SpringBoot风格进行再封装屏蔽了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
SpringCloud的优点
产出于Spring大家族,可以保证后续的更新、完善。
组件丰富,功能齐全。服务拆分粒度更细,耦合度比较低,有利于资源重复利用,有利于提高开发效率。
可以更精准的制定优化服务方案,提高系统的可维护性。
SpringCloud
十五、面试中的一些其他问题
1、虚拟内存和物理内存
2、线程间的通信方式
共享内存(volatile)、消息传递(wait/notify等待通知方式)、管道流
3、浏览器url过程
4、post请求和get请求
5、了解跳表吗
跳表是链表的一个升级,是用来提高链表的查询效率的。增加了向前指针的链表叫作跳表。跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳表不进能提高搜索性能,同时也可以提高插入和删除操作的性能。
6、乐观锁和悲观锁应用场景
7、CMS与G1的区别
8、进程操作的相关指令
9、nginx
10、docker的理解、三要素(镜像、容器、仓库)
11、IO
12、聚合索引
13、泛型的了解
定义:泛型的本质是参数化类型,就是将类型由原来的具体的类型参数化,这种参数类型可以用在类、接口、方法中,分别称为泛型类、泛型接口、泛型方法。
14、mysql和redis数据一致性的问题
15、网络
16、
1、为什么要使用分布式锁
为了保证一个方法在高并发情况下的同一时间只能被同一个线程执行,在传统单体部署的情况下,可以使用Java并发处理相关的API(如ReentrantLock或synchronized)进行互斥控制。但是,随着业务发展的需要,原单体部署的系统被演化成分布式系统后,由于分布式系统多线程、多线程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题。
分布式锁的几种实现方式:redis、redLock、Redisson、consul、zookeeper
[实现分布式锁的详情] https://zhuanlan.zhihu.com/p/373006310
2、SpringBoot的启动原理
3、SpringBoot的starter场景启动器
首先,这个Starter并非什么新的技术点,基本上还是基于Spring已有功能来实现的。首先它提供了一个自动化配置类,一般命名为XXXAutoConfiguration,在这个配置类中通过条件注解来决定一个配置是否生效(条件注解就是Spring中原本就有的),然后它还会提供一些列的默认配置,也允许开发者根据实际情况自定义相关配置,然后通过类型安全的属性注入将这些配置属性注入进来,新注入的属性会代替掉默认属性。正因为如此,很多第三方框架,我们只需要引入依赖就可以直接使用了。当然,开发者也可以自定义Starter。
4、什么是CSRF攻击
CSRF代表跨站请求伪造,这是一种攻击,迫使最终用户在当前通过身份验证的Web应用程序上执行不需要的操作。CSRF攻击专门针对状态改变请求,而不是数据数据窃取,因为攻击者无法查看对伪造请求的响应。
5、Spring中的DI是什么?
IOC的一个重点就是在程序运行时,动态的向某个对象提供它所需要的其他对象,这一点是通过DI(依赖注入)来实现的,即应用程序在运行时依赖IOC容器来动态注入对象所需要的外部依赖。而Sring的DI具体就是通过反射实现注入的,反射允许程序在运行的时候动态的生成对象、执行对象的方法、改变对象的属性。














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









