






目录
6)、Map、List、Set他们的下面有哪些线程安全类和线程不安全的类
7)、Collections和Collection有什么区别?
8.1)、jdk1.7版本的ConcurrentHashMap
8.2)、jdk1.8版本的ConcurrentHashMap
9)、HashMap、HashTable和ConcurrentHashMap的区别
10)、线程安全集合类CopyOnWriteArrayList
1)、Java中集合的框架图
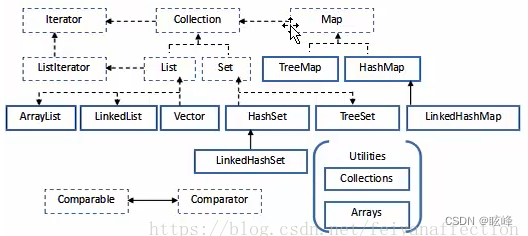
2)、常用集合的分类
Collection 接口(单列集合)
├——-List 接口:元素按进入先后有序保存,可重复
│—————-├ LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全
│—————-├ ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全
│—————-└ Vector 接口实现类 数组, 同步, 线程安全
│ ———————-└ Stack 是Vector类的实现类
└——-Set 接口: 仅接收一次,不可重复,并做内部排序
├—————-HashSet 使用hash表(数组)存储元素
│————————LinkedHashSet 链表维护元素的插入次序
└ —————-TreeSet 底层实现为二叉树,元素排好序
Map 接口 键值对的集合 (双列集合)
├———Hashtable 接口实现类, 同步, 线程安全
├———HashMap 接口实现类 ,没有同步, 线程不安全-
│—————–├ LinkedHashMap 双向链表和哈希表实现
│—————–└ WeakHashMap
├ ——–TreeMap 红黑树对所有的key进行排序
└———IdentifyHashMap
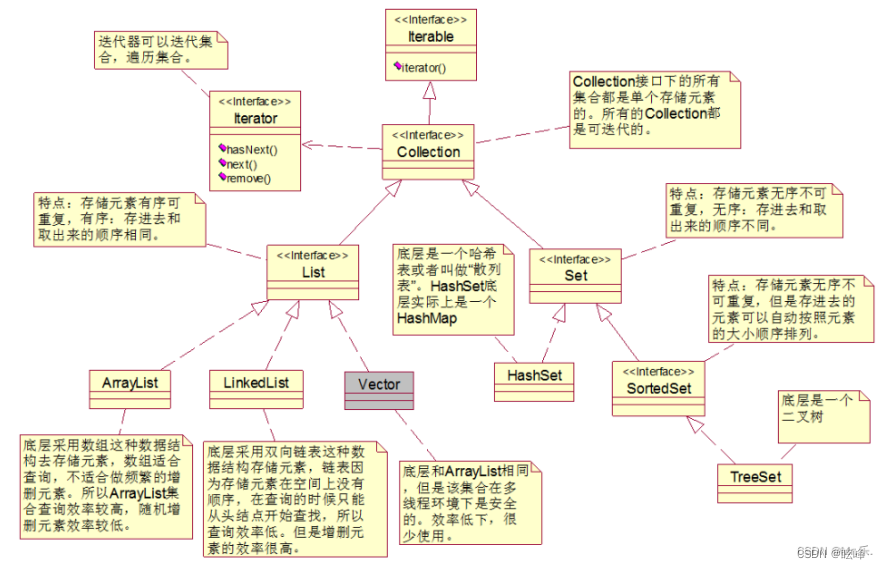
3)、List接口详解
list是java中的一个结合接口,它继承自Collection。list集合的特点是存储的元素有序可重复,存进去和取出来的顺序相同。它有三个实现类,分别是ArrayList、LinkedList、Vector,其中ArrayList是最常用的一个。
//list接口
public interface List<E> extends Collection<E> {
}
//ArrayList类
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
}
//LinkedList类
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable{
}
//Vector类
public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
}3.1)ArrayList集合类
ArrayList是基于动态数组的数据结构,是连续存储的。它是线程不安全的。
我们可以构造一个ArrayList,添加一个元素,看一下其容量。最终的结果是容量:10,大小:1,如果我们ArrayList构造函数的手没有设置初始化的容量大小,在没有添加任何元素的时候,其初始容量是0,只有当我们添加第一个元素的时候,才会初始化容量为10。
/例子
ArrayList<String> list = new ArrayList<>();
Integer length = getCapacity(list);
int size = list.size();
System.out.println("容量: " + length);
System.out.println("大小: " + size);
//ArrayList类
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
//1,首先是默认初始值的大小:
private static final int DEFAULT_CAPACITY = 10;,
//2,接着是一个默认的空对象数组:
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//3,然后是ArrayList 实际数据存储的一个数组:
transient Object[] elementData;
//4,elementData 的大小:
private int size;
//有参构造
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
//无参构造
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;//使用的是默认大小
}
}(1)、ArrayList的扩容机制
ArrayList的每次扩容都是原有容量的1.5倍。
//接下来,我们进行构造一个ArrayList 对象,同样调用的是无参构造函数。然后往里面添加11个对象,看起容量会如何进行动态扩展。最终结果,容量:15,大小:11
ArrayList<String> list = new ArrayList<>();
for (int i = 1; i <= 11; i++) {
list.add("value" + i);
}
Integer length = getCapacity(list);
int size = list.size();
System.out.println("容量: " + length);
System.out.println("大小: " + size);
//要清楚其扩容机制,我们需要跟进去,看一下其add 方法,
public boolean add(E e) {
//① ensureCapacityInternal方法名的英文大致是“确保内部容量”,size表示的是执行添加之前的元素个数,并非ArrayList的容量,容量应该是数组elementData的长度。ensureCapacityInternal该方法通过将现有的元素个数与数组的容量比较。看如果需要扩容,则扩容。
//②是将要添加的元素放置到相应的数组中。
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
//看一下ensureCapacityInternal方法的实现:
private void ensureCapacityInternal(int minCapacity) {
DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}
//判断elementData这个数组是否为空,如果为空,就让默认大小10与传过来的minCapacity比较,找打一个最大的
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
//根据传入的最小需要容量minCapacity来和数组的容量长度对比,如果minCapacity大于或等于数组容量,则需要进行扩容。
if (minCapacity - elementData.length > 0) // 如果其元素个数大于其容量,则进行扩容。
grow(minCapacity);
}
//具体扩容流程:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length; // 原来的容量
int newCapacity = oldCapacity + (oldCapacity >> 1); // 新的容量,原来容量的1.5倍。
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0) // 如果大于ArrayList 可以容许的最大容量,则设置为最大容量。
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity); // 最终利用Arrays.coppy 进行扩容,生成一个1.5倍元素的数组。(即例子中的15个元素的数组。)
}
//ArrayList 的内部实现,其实是用一个对象数组进行存放具体的值,然后用一种扩容的机制,进行数组的动态增长。其扩容机制可以理解为,如果元素的个数,大于其容量,则把其容量扩展为原来容量的1.5倍。3.2)、LinkedList集合类
LinkedList是基于链表的数据结构,存储在分散的内存中。
对于新增和删除操作add和remove,LinkedList是比较占优势的,因为ArrayList要移动数据。LinkedList适用于要头尾操作或插入指定位置的场景,它同样是线程不安全的。
LinkedList中将添加的数据封装成一个Node对象,然后加入到链表中。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
public LinkedList() { //无参
}
public LinkedList(Collection<? extends E> c) {//有参
this();
addAll(c);
}
}
3.3)、Vector集合类
Vector的底层也是一个数组结构,它的初始容量是10,每次扩容是原有容量的2倍,Vector中所有的方法都是线程同步的,都带有synchronized关键字,是线程安全的。但是效率比较低,使用比较少。vector有四个构造函数,通过无参的来调用有参的构造函数创建一个初始容量为10的数组来存储数据。
public Vector() {
this(10);
}//使用指定的初始容量和等于0的容量增量构造一个空向量。
public Vector(int initialCapacity)//构造一个空向量,使其内部数据数组的大小,其标准容量增量为零。
public Vector(Collection<? extends E> c)//构造一个包含指定 collection 中的元素的向量
public Vector(int initialCapacity,int capacityIncrement)//使用指定的初始容量和容量增量构造一个空的向量
//vector的添加方法
public synchronized boolean add(E e)
//vector的删除方法
public synchronized E remove(int index)4)、Map接口详解
Map是用来存储键值对的集合,它和Collection没有继承关系,interface Map<K,V>:K(key)键,V(value)值。将键值映射到值的对象,不能出现重复的键,每个键最多可以映射到一个值。
4.1)、HashMap集合类
HashMap是基于哈希表的Map接口的非同步实现,是线程不安全的。
(1)、HashMap的底层数据结构
在jdk1.8之前使用的是“数组+链表”的底层数据结构。
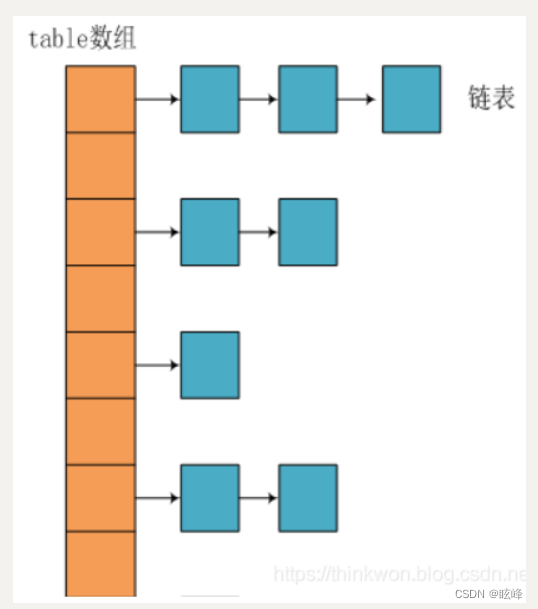
jdk1.8之后使用的是“数组+链表+红黑树”的底层数据结构。HashMap中将链表转为红黑树的前提是当链表长度大于阈值(默认为8)时且数组的大小为64以上,提高搜索效率。链表的查找性能是 O(n),而使用红黑树是 O(logn)。

(2)、HashMap的重要属性及用途
1)、size:HashMap已经存储的节点个数;
2)、threshold:扩容阈值,当HashMap的个数达到该值,触发扩容;初始化时的容量,在我们新建HashMap对象时threshold还会被用来存初始化时的容量;HashMap直到我们第一次插入节点时,才会对table进行初始化,避免不必要的空间浪费;
3)、loadFactor:负载因子,扩容阈值=容量*负载因子
(3)、HashMap的容量及对Null的支持
HashMap默认的初始化大小为16,之后每次扩充,容量变为原来的2倍;
HashMap中,null可作为键,这样的键只有一个,可以有一个或多个键所对应的值为null;
(4)、HashMap的插入流程
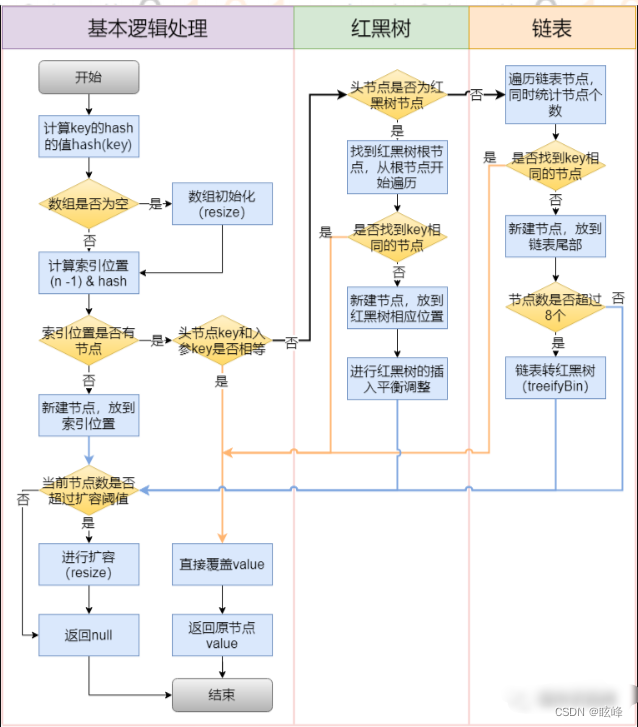
①.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
②.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
(5)、HashMap扩容(resize)流程
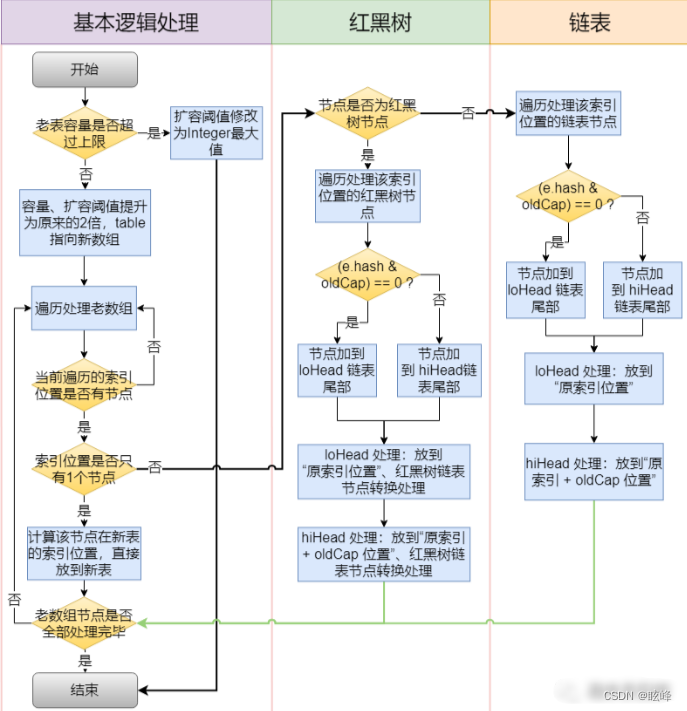
(6)、jdk1.8主要解决或优化了HashMap中的哪些问题
1)、底层数据结构从“数组+链表”改成了“数组+链表+红黑树”,主要是优化了hash冲突较严重时,链表过程的查找性能O(n)->O(logn);
2)、计算table初始容量的方式发生了改变,老的方式是从1开始不断向左进行移位运算, 直到找到大于等于入参容量的值;新的方式则是通过“5个移位+或等于运算”来计算;
// JDK 1.7.0
public HashMap(int initialCapacity, float loadFactor) {
// 省略
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
// ... 省略
}
// JDK 1.8.0_191
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}3)、优化了hash值的计算方式,老的通过4次位运算,5次异或运算(9次扰动),新的只是简单的让高16位参与了运算;
4)、扩容时插入方式从“头插法”改成“尾插法”,避免了并发下的死循坏;
5)、扩容时计算节点在新表的索引位置方式从“h & (length-1)”改成“hash & oldCap”,性能可能提升不大,但设计更巧妙、更优雅。

4.2)、HashTable集合类
HashTable是一个线程安全的集合类,它的内部方法基本都经过synchronized关键字的修饰;在HashTable中只要put进去的键值只要有一个为null,直接抛出NullPointerException异常;HashTable默认的初始大小为11,之后每次扩充,容量变为原来的2n+1倍,另外,HashTable基本被淘汰,不要在代码中使用它。
public synchronized V get(Object key) {
// ...
}
public synchronized V put(K key, V value) {
// ...
}4.3)、TreeMap集合类
TreeMap的底层是通过红黑树实现的。可以指定比较器(Comparator比较器),通过重写compare方法来自定义排序;如果没有指定比较器,TreeMap默认是按key的升序排序(如果key没有实现Comparable结构,则会抛出异常),是非线程安全的。
(1)、Comparable和Comparator的比较
①Comparable是排序接口,一个类实现了Comparable接口,意味着“该类支持排序”;Comparator是比较器,我们可以实现该接口,自定义比较算法,创建一个“该类的比较器”来进行排序。
②Comparable相当于“内部比较器”,而Comparator相当于“外部比较器”。
③Comparable的耦合性更强,Comparator的灵活性和扩展性更优。
④Comparable可以用作类的默认排序算法,而Comparator则用于默认排序不满足时,提供自定义排序。
5)、Set接口详解
set和list都是继承自Collection接口;往set里面放入的元素是无序的,不可重复的,重复的元素会被覆盖掉(注意:元素虽然是无序放入的,但是元素在set中的位置是由该元素的HashCode决定的,其位置是固定的,加入Set的Object必须定义equals()方法,另外list支持for循坏,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为它无序,无法用下标来取得想要的值)。
set检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置的改变。
5.1)、HashSet集合类
HashSet底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存元素的类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public HashSet() { //无参构造
map = new HashMap<>();//HashSet的底层是用哈希表来存储数据的,key就是要添加的对象,value是一个固定的Object对象
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
}(1)、HashSet如何实现唯一性
HashSet在存储元素的时候还先使用hash()算法函数来生成一个int类型的hashCode散列值;
然后和已经所存储的元素的hashCode值比较,如果hashCode不相等,则所存储的两个对象一定不相等,此时存储当前的新的hashCode值处的元素对象;
如果hashCode值相等,存储元素的对象还是不一定相等,此时就会调用equals()方法来判断两个对象的内容是否相等,如果内容相等,那么就是一个对象,无需存储;
如果比较的内容不相等,那么就是不同的对象,就该存储了,此时就要采用哈希的解决地址冲突算法,在当前hashCode值出类似一个新的链表,在同一个hashCode值的后面存储不同的对象,这样就保证了元素的唯一性。
5.2)、TreeSet集合详解
TreeSet的底层数据结构采用二叉树来实现,元素唯一且已经排好序;唯一性同样需要重写hashCode()和equals()方法,二叉树结构保证了元素的有序性。
根据构造方法不同,分为自然排序(无参构造)和比较器排序(有参构造),自然排序要求元素必须实现Compare接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储;比较器排序需要在TreeSet初始化的时候传入一个实现Comparator接口的比较器对象,或者采用匿名内部类的方式new一个Comparator对象,重写里面的compare()方法。
5.3)、LinkedHashSet
LinkedHashSet底层数据结构采用链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性。线程不安全,效率高。
6)、Map、List、Set他们的下面有哪些线程安全类和线程不安全的类
6.1)、Map
线程安全:ConcurrentHashMap、HashTable
线程不安全:HashMap、LinkedHashSetMap、TreeMap、WeakHashMap
6.2)、List
线程安全:Vector、Stack、CopyONWriteArrayList
线程不安全:ArrayList、LinkedList
6.3)、Set
线程安全:CopyOnWriteArraySet(底层使用CopyOnWriteArrayList,通过在插入前判断是否存在实现set不重复的效果)
线程不安全:HashSet(基于HashMap)、LinkedHashSet(基于LinkedHashMap)、TreeSet(基于TreeMap)、EnumSet
7)、Collections和Collection有什么区别?
Collection是最基本的集合接口,Collection派生了两个子接口list和set,分别定义了两种不同的存储方式。
Collections是一个包装类,它包含各种有关集合操作的静态方法(对集合的搜索、排序、线程安全化等),此类不能实例化,就像一个工具类,服务于Collection框架。
8)、线程安全集合类ConcurrentHashMap
ConCurrentHashMap是HashMap的线程安全版本,和HashMap一样,在JDK1.8中进行了比较大的优化。
8.1)、jdk1.7版本的ConcurrentHashMap
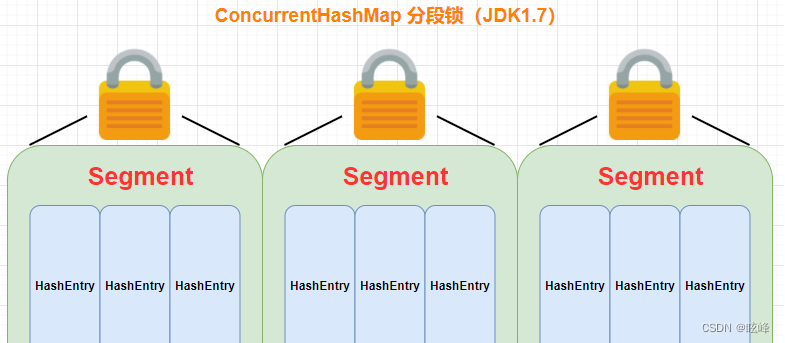
数据结构:jdk1.7下的ConcurrentHashMap中的底层数据结构为“分段的数组+链表”来实现线程的安全,分段锁(Segment,继承了ReentrantLock),如下图所示:
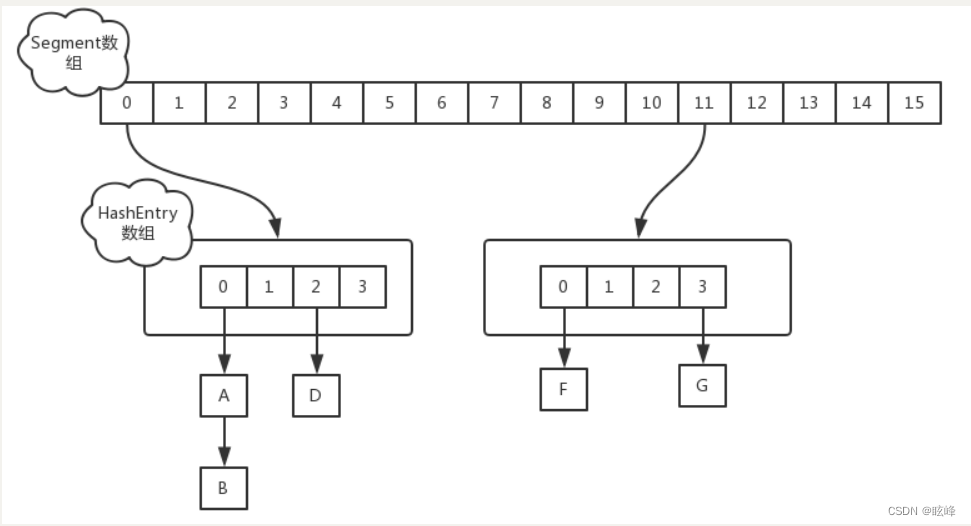
元素查询:第一次Hash定位到Segment,第二次定位到元素所在的链表的头部
锁:当有请求过来时,锁的是需要操作的那个Segment,其它的Segment不受影响;并发度为Segment的个数,可以通过构造函数指定,数组扩容不会影响到其他的Segment。
锁的粒度是基于Segment的,包含多个节点(HashEntry)。
Segment是一种可重入的锁(继承自ReentrantLock),当对HashEntry数组的数据进行修改时,必须首先获得对应的Segment锁。Segment数组在创建以后它的大小是不会改变的,改变的只是HashEntry数组的大小,当大小大于阈值0.75以后。对于ConcurrentHashMap1.7来说-调用构造方法,它的数组就被创建了,但是ConcurrentHashMap1.8是第一次放入元素的时候,底层数组才会被创建。
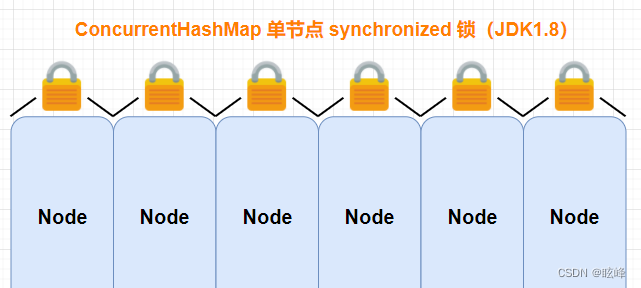
8.2)、jdk1.8版本的ConcurrentHashMap
jdk1.8下的ConcurrentHashMap中的底层数据结构和HashMap是一样的“数组+链表+红黑树”,其底层是一个Node数组,通过对Node数组以CAS的方式实现扩容和对Node数组的每个元素的synchronized来保证ConcurrentHashMap整体的线程安全。
在链表数组结构上进行了优化,和HashMap1.8的优化一样,当链表的长度达到8且数组的长度超过64的时候会把链表转为红黑树,以此来提高查找性能。
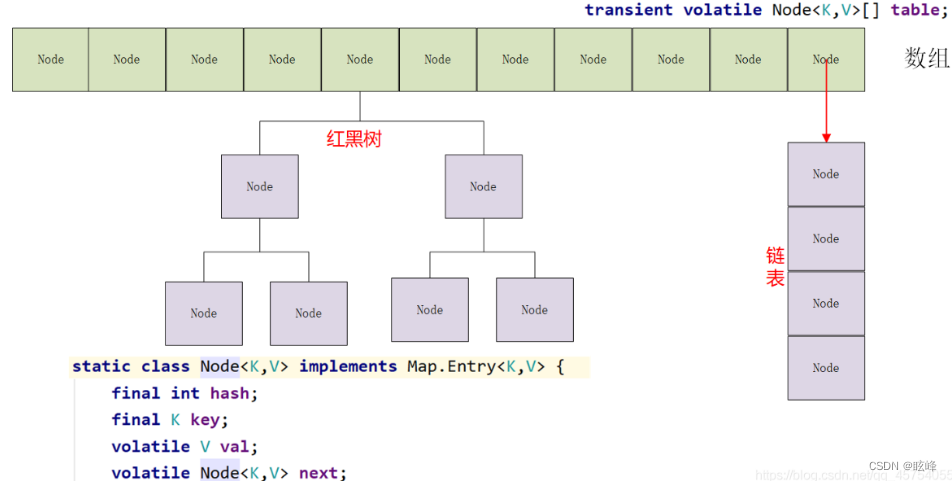
(1)、jdk1.8中ConcurrentHashMap的属性
// 散列表最大容量
private static final int MAXIMUM_CAPACITY = 1 << 30;
// 散列表默认容量
private static final int DEFAULT_CAPACITY = 16;
// 最大数组长度
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 默认并发级别 jdk1.7 之前遗留的 1.8只用于初始化
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
// 负载因子
private static final float LOAD_FACTOR = 0.75f;
// 链表树化条件
static final int TREEIFY_THRESHOLD = 8;
// 取消树化条件
static final int UNTREEIFY_THRESHOLD = 6;
// 结点树化条件
static final int MIN_TREEIFY_CAPACITY = 64;
// 线程迁移数据最小步长 控制线程迁移任务最小区间的一个值
private static final int MIN_TRANSFER_STRIDE = 16;
// 扩容用 计算扩容生成一个标识戳
private static final int RESIZE_STAMP_BITS = 16;
// 65535 标识并发扩容最大线程数量
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
// 扩容相关
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
// node 结点的hash 是-1 表示 当前结点是forwardingNode结点
static final int MOVED = -1; // hash for forwarding nodes
// 红黑树的代理结点
static final int TREEBIN = -2; // hash for roots of trees
// 临时保留的散列表
static final int RESERVED = -3; // hash for transient reservations
// 0x7fffffff = 31个1 用于将一个负数变成一个正数 但是不是取绝对值
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
// 系统CPu数量
static final int NCPU = Runtime.getRuntime().availableProcessors();
// 散列表
transient volatile Node<K,V>[] table;
// 扩容用的临时散列表
private transient volatile Node<K,V>[] nextTable;
// LongAdder 的baseCount
private transient volatile long baseCount;
/**
sizeCtl <0
1. -1 的时候 表示table正在初始化(有线程正在初始化 , 当前线程应该自旋等待)
2. 其他情况 表示当前map正在进行扩容 高16位表示 扩容的标识戳 , 低16位表示 扩容线程数量
sizeCtl = 0
表示创建数组 使用默认容量 16
sizeCtl >0
1. 如果table 未初始化 表示 初始化大小
2. 如果table 已经初始化 表示下次扩容的阈值
*/
private transient volatile int sizeCtl;
//扩容过程中,记录当前进度,所有线程都需要从transferIndex中分配区间任务,去执行自己的任务
private transient volatile int transferIndex;
// 0 表示 无锁 1 表示加锁
private transient volatile int cellsBusy;
// LongAdder 中的cells 数组 当baseCount发生竞争后 会创建cells 数组
// 线程会通过计算hash值 取到自己的cell中
private transient volatile CounterCell[] counterCells;
ConcurrentHashMap中的源码,例如put方法、初始化方等详解refConcurrentHashMap详解_唐芬奇的博客-CSDN博客
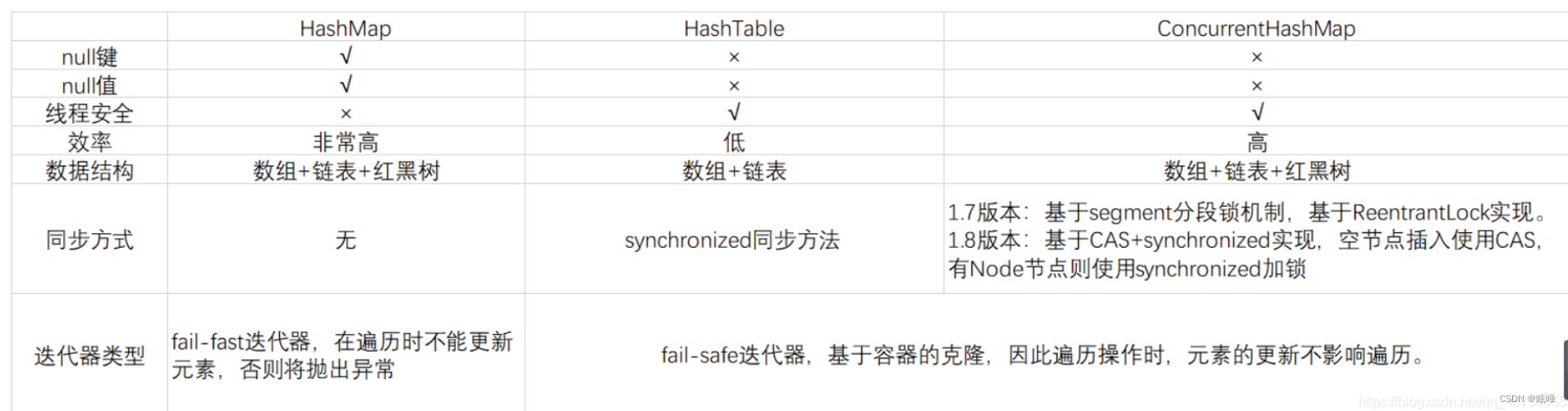
9)、HashMap、HashTable和ConcurrentHashMap的区别
10)、线程安全集合类CopyOnWriteArrayList
在进行CopyOnWriteArrayList的源码讲解之前,先看下同样实现了线程安全Vector,很多文章都说不推荐使用Vector,其主要原因是性能太差了,那性能为什么这么差呢?可以看一下Vector add和get的源码:
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
public synchronized E set(int index, E element) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}Vector的添加和读取操作都被加上了synchronized锁,当并发情况下,因为锁的存在相当于变成了单线程的操作,所以效率肯定低,同样这样的优点就是保证了数据的唯一性,不会读取到脏数据。
首先我们看一下CopyOnWriteArrayList的全局变量有哪些?
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private static final long serialVersionUID = 8673264195747942595L;
/** The lock protecting all mutators */
final transient ReentrantLock lock = new ReentrantLock();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;我们可以看到里面有两个全局变量,其中lock锁就是每次在做写操作时,锁的句柄,array就是具体存储数据的数组,注意这里的array被volatile所修饰,因此可以在并发情况下实现数据的可见性。
当用new创建了一个CopyOnWriteArrayList时,如果是使用无参的构造函数,则将array的长度默认成0,创建了一个空的数组。
public CopyOnWriteArrayList() {//无参构造
setArray(new Object[0]);
}
final void setArray(Object[] a) {
array = a;
}然后我们在使用CopyOnWriteArrayList中的add添加数据时,先使用lock锁,并获取到当前的array数组,然后对array进行copyof,新的数组的长度时之前的长度+1,这样才能存放当前新的值,将新值填充后,在替换掉旧的array数组后,释放当前锁。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); //加锁
try {
Object[] elements = getArray(); //获取array数组
int len = elements.length;//得到它的长度
Object[] newElements = Arrays.copyOf(elements, len + 1); //使用copyof方法将旧的数组在原先的长度上加1变成一个新的数组,
newElements[len] = e; //在新数组的最后把e添加进去
setArray(newElements);//替换旧的数组
return true;
} finally {
lock.unlock(); //释放锁
}
}我们使用CopyOnWriteArrayList中的remove方法删除元素时,先使用lock上锁,然后再获取当前的array数组,如果传入的index正好是最后一个索引,那么numMoved计算出来的就是0,则使用copyOf,长度进行-1去除最后一个数据。如果传入的不是最后一个,先声明一个新的array数组,数组的长度就是旧的arra的长度-1,再将0到index的数据array复制到新的array数组,然后再将index+1后的再array复制新的array数组,最后将新的array数组替换旧的,然后释放锁。
public E remove(int index) {
final ReentrantLock lock = this.lock;
lock.lock();//加锁
try {
Object[] elements = getArray();//获取到数组
int len = elements.length;//得到长度
E oldValue = get(elements, index);//获取到指定位置上的元素
int numMoved = len - index - 1; //看是不是最后一个元素
if (numMoved == 0)//如果是最后一个
setArray(Arrays.copyOf(elements, len - 1));//直接将长度-1的数组设置到array
else {//如果不是最后一个计算一下,分两部分0到index,index+1到最后,然后将新的替换旧的
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
lock.unlock();//释放锁
}
}总结:
1、当new新建一个CopyOnWriteArrayList后会生成一个数组array来存放添加的内容,如果是无参的构造函数,则array的长度为0,添加数据时再进行扩容。同时会声明一个ReentrantLock锁。
2、当进行add操作时,先进行上锁,然后对当前的array进行copyOf,并且新的长度时之前长度的+1,这样才能存放当前新的值,将新值填充后,再替换掉旧的array数组后,释放当前锁。
3、当使用get获取数据时,无需上锁,直接读取当前array数组的指定位置。
4、当使用remove时,同样先进行上锁,然后再获取当前的array数组,如果传入的index正好是最后一个,则使用copyOf,长度进行-1,否则的话先声明一个新的array数组,现将0到index的数据arraycopy至新的array数组,然后再将index+1后的再arraycopy至新的array数组,最后将新的array数组替换旧的,然后释放锁。
CopyOnWriteArrayList实现了写写隔离,但读读是可以共享的,这就有可能出现当某个数据再修改时,读进行了操作,导致读取到的还是旧的数据。还有就是每次写操作都对数组就行copy。假如数据量非常大的情况下,进行Copy消耗的资源则会进行*2,因此使用CopyOnWriteArrayList时,需要考虑下自己的数据量以及读写的频次。















 1195
1195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









