






首先介绍一下集合:
集合是一种容器
在此之前,先复习一下数组:是对象,指定存储空间,空间连续,长度不可变;有索引,查找方便
不方便之处:长度不可变,超出时就要重新创建数组;插入元素慢,删除慢
为什么我们需要有集合?
实际开发中数据数量是变化的,所以我们需要一些可动态增长的容器来保存数据,并且我们对数据的保存逻辑可能各种各样,于是就有了各种各样的数据结构,Java中对于各种数据结构的实现,就是我们用到的集合。
总之:集合就是以不同的结构特征存储数据-----操作:增删改查
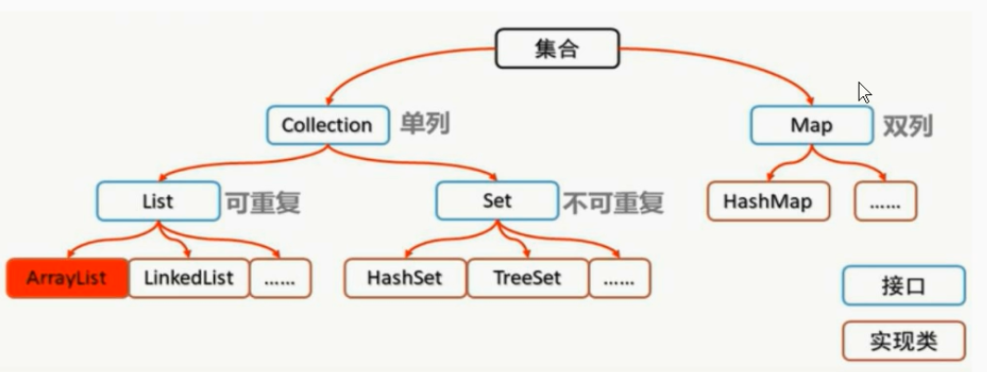
我们需要学习的是四个接口,八个实现类(初步学习)
list:LinkedList、Arraylist
set:Hashset、Treeset
map:HashMap、TreeMap、HashTable
Collection接口
一些常用方法(这些方法是实现了collection接口的类都拥有的,即都可以使用这些常用方法)
Collection<String>c=newArrayList<>();
c.add("a");//向集合中添加元素
c.addAll(a);//向集合中添加另外一个集合的所有元素,这个集合只要实现了collection就可以作为参数
c.clear();//清空集合
c.remove("a");//删除集合元素中第一个"a"元素
c.contains("a");//判断集合中是否有“a”元素
c.isEmpty();//判断集合中有无元素
c.size();//获取已有元素个数
c.toArray();//返回一个object类型数组
String[] a=c.toArray(newString(c.size()));//通过此方式可以将集合返回指定类型的数组
c.remove(c1);//将c中包括c1的部分删掉
c.containsAll(c1);//c中包含c1的所有元素则返回true
c.retainAll(c1);//在c只保留两个集合都有的元素,即相交的元素,c中元素改变时,返回true
List接口
1.ArrayList
底层实现是数组结构,查询快,中间添加删除慢
构造方法:
无参构造时,底层数组初始长度是10,有参数时,初始长度为参数大小
ArrayList <String> list=new ArrayList<>(20);
注:我们创建Arraylist对象后,源码底层其实还未创建数组,只有当我们使用add方法往数组中添加元素时,才会创建数组
常用的方法:
alist.add(0,"d");//向指定位置插入数据
alist.get(0);//获取指定位置元素
alist.indexof("b");//返回b元素在集合中第一次出现的位置索引
alist.remove(1);//根据索引删元素,并返回这个元素
alist.set(1,"A");//替换指定位置元素add()方法添加元素到集合的过程
调用add()添加元素时,先要检测底层数组是否还能放得下,如果可以,直接将元素添加到末尾,如果不可以,源码底层调用grow方法,会创建一个新的数组,将原来的数组内容复制过来。
数组扩容,grow方法,创建新的数组,新数组长度为原数组1.5倍
removeRange(a,b)方法
删除a到b索引的元素,包括前面,不包括后面
这个方法不同的是,他是用protected关键字修饰的,只能在本包中或者其所在类(ArrayList)的子类中调用,因为我们不能在util包中建立并使用这个方法,所以我们只能通过创建一个继承了Arraylist的类来调用此方法使用,如下:

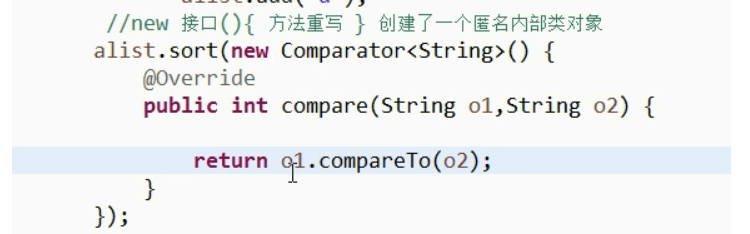
sort方法
对集合中元素进行排序,具体按照什么规则进行排序,我们通过创建comparator接口的匿名内部类(还可以使用lambda表达式),实现compare方法进行实现。
2.LinkedList
有索引,此类有许多如addFirst()、addLast()、removeFirst()、removelast()、push()等对末尾或头部增删的方法,若是将这些方法合理运用便可实现栈、队列的操作。
LinkedList<String>llist=newLinkedList<>();
list.add("a");每添加一个元素,变创建一个新的节点node对象,将新节点地址赋给上一个结点的next,链接起来。
底层有一个node节点类
list.get(2);需要注意的是,在linkedlist类中,获取指定索引的元素时,与数组不同的是,我们需要从头或尾结点一个个来进行查询,底层查找时index<(size/2)时从头开始找,否则从尾开始找。
3.Vector
底层也是数组实现,但它是线程安全的。














 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









