






原标题:高手不得不知的Java集合List的细节
写在前面
作为Android开发者,Java集合可能是开发中最常使用的类之一了。但很多人可能跟我一样,对Java集合只停留在“使用”的层面上,而对其的实现、原理如何只是略知一二,所以有时可能忽略了一些小细节。这些细节可能对项目的整体性能影响不大,但我觉得,要成为一个好的程序员,必须要精益求精,对代码性能“锱铢必较”。
举个例子,各位在创建ArrayList实例时有没有想过到底要不要指定其初始容量?指定了会怎样?不指定又会怎样?如果你跟博主我有同样的困惑,那么本文一定能给你个满意的答案!
正文
这篇文章是关于Java集合之一的List的,但不妨先祭上一张经典的Java集合框架图,先大概了解下Java集合整体的框架:
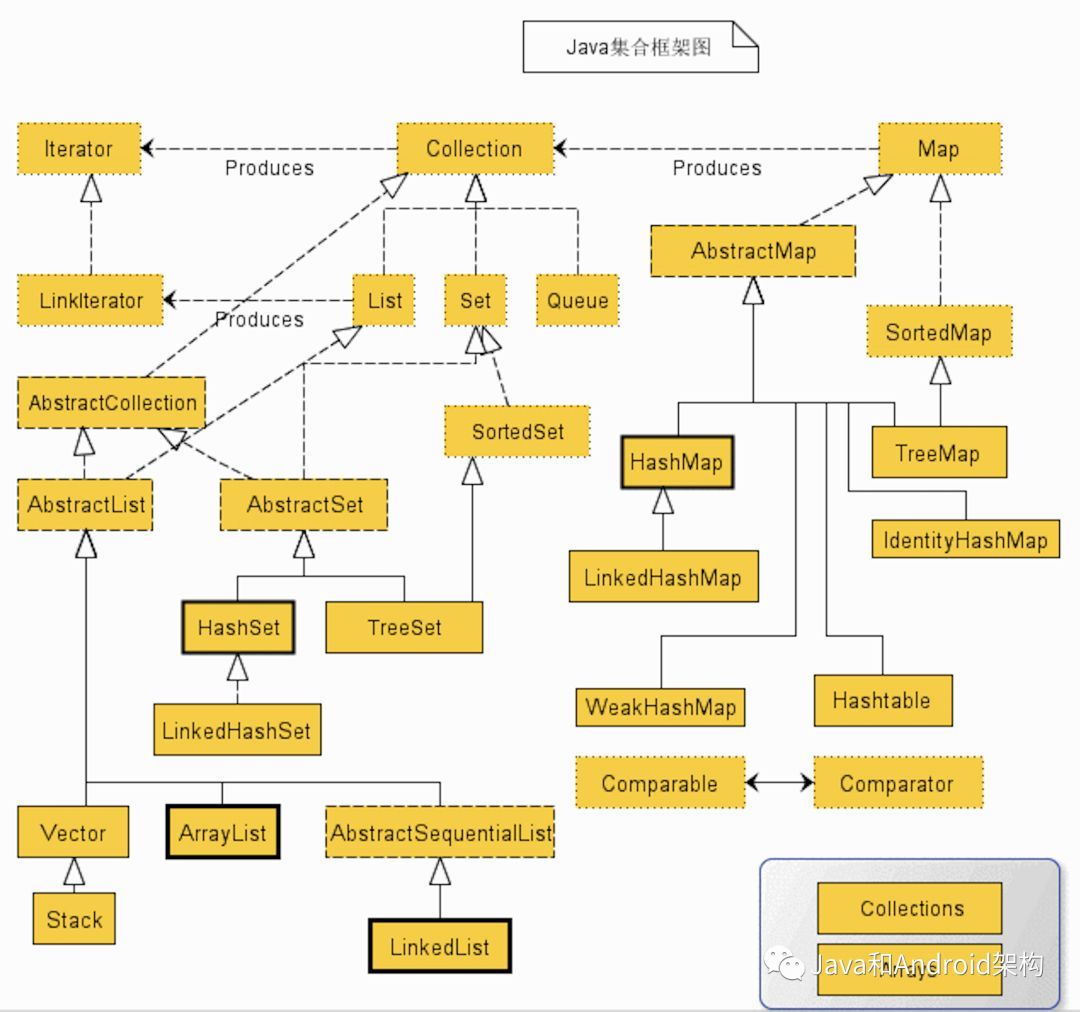
图2.1 Java集合框架
如果之前没见过图2.1的童鞋紧张了,这么多类呀!别慌,图2.1很多是接口和抽象类,并且我们常使用的集合类也就那么几个,我们只关心我们经常使用的即可,不常用的就暂时忽略,等用到了再看就行了。
好了,上面关于Java集合List的类不多,我整理了下:
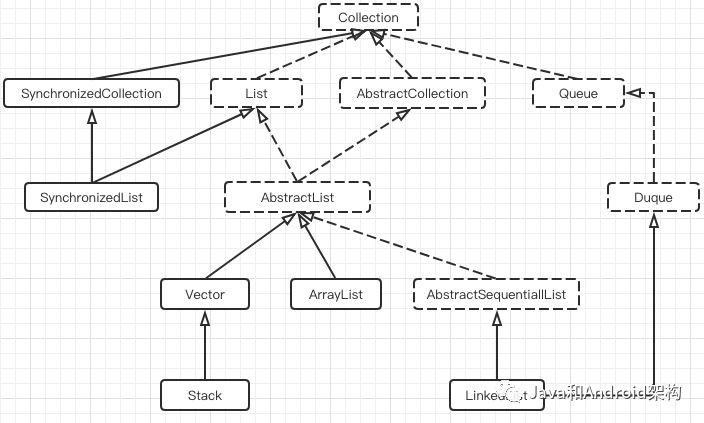
图2.2 List继承关系图
从图2.2可以看到,我们经常使用的Arrayist、LinkedList继承的关系挺复杂的,但继承的都是接口或抽象类。而Collection和List是接口,Collection接口定义了集合的通用方法,和List接口是在Collection基础上补充了专属于List的通用方法。我们什么时候使用抽象类?很多情况是为子类提供共同的方法实现或属性时会使用抽象类。所以就不难理解AbstractColection和AbstractList的作用了,当然,你也可以继承于它们实现自己的List,而这是题外话了,这里就不加讨论了,下面我们进入正题吧。
本文将介绍下面List子类的一些细节:
ArrayList
Vector和Stack
LinkedList
SynchronizedList
ArrayLIst的细节
细节1:ArrayList基于数组实现,访问元素效率快,插入删除元素效率慢
ArrayList是基于数组实现的,这个似乎不是什么秘密了,但为了文章的完整性,还是要介绍下。ArrayList内部维护一个数组elementData,用于保存列表元素,基于数组的数组这数据结构,我们知道,其索引元素是非常快的:
publicE get(intindex){
if(index >= size)
thrownewIndexOutOfBoundsException(outOfBoundsMsg(index));
return(E) elementData[index]; // 索引无需遍历,效率非常高!
}
publicE set(intindex, E element){
if(index >= size)
thrownewIndexOutOfBoundsException(outOfBoundsMsg(index));
E oldValue = (E) elementData[index];
elementData[index] = element; // 索引无需遍历,效率非常高!
returnoldValue;
}
可以看到,get、set直接根据索引获取了目标元素,中间不用做任何的遍历操作,效率是非常快的。但是对于插入和删除操作效率就不太理想了:
public void add( intindex, E element) {
if( index> size || index< 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg( index));
ensureCapacityInternal(size + 1); //先判断是否需要扩容
System.arraycopy(elementData, index, elementData, index+ 1, //把 index后面的元素都向后偏移一位
size - index);
elementData[ index] = element;
size++;
}
从插入操作的源码可以看到,插入前,要先判断是否需要扩容(扩容后面会讲,这里先跳过),然后把Index后面的元素都偏移一位,这里的偏移是需要把元素复制后,再赋值当前元素的后一索引的位置。显然,这样一来,插入一个元素,牵连到多个元素,效率自然就低了。再来看看删除操作:
public E remove( intindex) {
if( index>= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg( index));
modCount++;
E oldValue = (E) elementData[ index];
intnumMoved = size - index- 1;
if(numMoved > 0) {
//把 index后面的元素向前偏移一位,填补删除的元素
System.arraycopy(elementData, index+ 1, elementData, index,
numMoved);
}
elementData[--size] = null; //clear to let GC doits work
returnoldValue;
}
同样,删除一个元素,需要把index后面的元素向前偏移一位,填补删除的元素,也是牵连了多个元素。所以大家在使用时要谨慎了!
细节2:ArrayList支持快速随机访问
什么是随机访问?我们不防先来看看ArrayList的类定义:
publicclassArrayList extendsAbstractList
implementsList, RandomAccess, Cloneable, java.io.Serializable
看到RandomAccess了吗,这个就是支持快速随机访问的标记,我们再点进去看看其源码:
/**
* ...
*
It isrecognized that the distinction between random andsequential
* access isoften fuzzy. Forexample, some List implementations
* provide asymptotically linear access times ifthey gethuge, but constant
* access times inpractice. Such a List implementation
* should generally implement this interface. As a rule of thumb, a
* List implementation should implement this interface if,
* fortypical instances of the class, this loop:
*
* for( inti= 0, n=list.size(); i < n; i++)
* list. get(i);
*
* runs faster than this loop:
*
* for(Iterator i=list.iterator(); i.hasNext(); )
* i. next();
*
* ...
*/
publicinterface RandomAccess {
}
额,是一个接口,没有任何的属性或方法定义。其实它只是一个标记,继承于它就相当于告诉别人,我支持快速随机访问,上面代码我特意留下部分的注释说明,其中关键的部分在说,通常情况下,使用索引访问的效率比使用迭代器访问的效率快!
我们把目光暂时转移到Collections类下,其中有很多基于是否有继承于RandomAccess的List做不同的算法选择判断,我们来看其中的二分查找算法:
publicstatic int binarySearch( List<?extends Comparable <?super T>> list, T key) {
if( listinstanceofRandomAccess || list.size()
// 当List实现了RandomAccess或小于一定阀值时,使用索引二分查找算法
returnCollections.indexedBinarySearch( list, key);
else
returnCollections.iteratorBinarySearch( list, key);
}
所以快速随机访问是针对于Collections中的方法而言的(其他类是否也有?欢迎大神们补充),支持快速随机访问时,就选择索引访问,效率会很快。
另外,从上面的二分查找算法我们又能得到一个提高效率的小细节:我们知道List是提供了IndexOf和lastIndexOf方法来检索元素的,它们分别是从头和尾开始,一个一个比较的,那么显然,使用Collections#binarySearch在大多数情况效率会比
IndexOf和lastIndexOf更快~
细节3:大多数情况下,我们都应该指定ArrayList的初始容量
如果说上面所介绍的细节大部分童鞋都知道,那这个细节相信很多人都不知道,包括在看源码之前的我。在讲为什么之前,我们需要先来了解ArrayList的扩容机制。
ArrayList每次扩容至少为原来容量大小的1.5倍,其默认容量是10,当你不为其指定初始容量时,它就会创建默认容量大小为10的数组:
// 默认最小容量
privatestaticfinalintDEFAULT_CAPACITY = 10;
// 空数组
privatestaticfinalObject[] EMPTY_ELEMENTDATA = {};
// 默认容量空数组,可以理解为一个标记
privatestaticfinalObject[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 指定最小容量创建列表
publicArrayList(intinitialCapacity){
if(initialCapacity > 0) {
this.elementData = newObject[initialCapacity];
} elseif(initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else{
thrownewIllegalArgumentException( "Illegal Capacity: "+
initialCapacity);
}
}
// 创建默认空列表
publicArrayList(){
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; // 默认容量空数组
}
我们经常使用ArrayList的默认构造函数来创建实例,等等,不是说不指定初始容量会创建默认容量大小为10的数组吗?但这里只赋值了空数组。是的,还记得我们上面分析的add源码有个扩容操作吗?如果使用默认构造函数来创建实例,在第一次添加元素时,就会进行扩容,扩容到默认容量10的数组:
// 每次添加元素都会调用
privatevoidensureCapacityInternal(intminCapacity){
if(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 如果为默认容量空数组的话,添加元素时,至少扩容到默认最小容量
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
privatevoidensureExplicitCapacity(intminCapacity){
modCount++;
// overflow-conscious code
if(minCapacity - elementData.length > 0) // 大于当前容量就扩容
grow(minCapacity);
}
// 扩容
privatevoidgrow(intminCapacity){
// overflow-conscious code
intoldCapacity = elementData.length;
intnewCapacity = oldCapacity + (oldCapacity >> 1); // 1.5倍原来大小
// 先尝试扩容到1.5倍原来容量的大小,如果比用户指定的大,那么就扩容1.5倍
// 否则扩容用户指定的
if(newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if(newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
所谓“扩容”就是创建一个长度更大的数组,再把旧数组的元素全部赋值到新数组。显然,这个操作效率也是不理想的。虽然使用默认构造函数创建的实例,在第一次添加元素的扩容并没有元素复制,但还是要另外创建一个数组,并且是大小为10的数组,可能你并不需要这么大的数组,可能是3,可能是5,那么我们为何不一开始就指定其容量呢?
指定初始容量的方法也很简单,我们使用带int参数的构造函数就可以了:
// 指定最小容量创建列表
publicArrayList(intinitialCapacity){
if(initialCapacity > 0) {
this.elementData = newObject[initialCapacity];
} elseif(initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else{
thrownewIllegalArgumentException( "Illegal Capacity: "+
initialCapacity);
}
}
或者有童鞋会说,使用ensureCapacity指定容量也行,其实不然,为何ensureCapacity对容量大小有限制:
// 指定最小容量
publicvoidensureCapacity(intminCapacity){
intminExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
// 指定最小容量成功的情况
// 1.使用 new ArrayList() 创建实例并添加元素前,指定容量大小不能小于默认容量10
// 2.列表已存在元素,指定容量大小不能小于当前容量大小
if(minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
所以讲到这,相信大家有答案了,为什么创建ArrayList要指定其初始容量?显然我们是不希望它进行耗时的扩容操作,并且能在我们预知的情况下尽量使用大小刚刚好的列表,而不浪费任何资源。那么我们可以得到以下经验:
都不应该使用默认构造函数创建实例,以免自动扩容到默认最小容量(10)
当列表容量确定,应该指定容量的方式创建实例
当列表容量不确定时,可以预估我们将有会多少元素,指定稍大于预估值的容量
Vector和Stack的细节
Vector和Stack我们几乎是不使用的了,所以并不打算用大篇幅来介绍,我们大概了解下就可以了。但我们可以探索下他们为何不受待见,从而引以为戒。
细节1:Vector也是基于数组实现,同样支持快速访问,并且线程安全
因为跟ArrayList一样,都是基于数组实现,所以ArrayList具有的优势和劣势Vector同样也有,只是Vector在每个方法都加了同步锁,所以它是线程安全的。但我们知道,同步会大大影响效率的,所以在不需要同步的情况下,Vector的效率就不如ArrayList了。所以我们在不需要同步的情况下,优先选择ArrayList;而在需要同步的情况下,也不是使用Vector,而是使用SynchronizedList(后面讲到)。你看,Vector处于一个很尴尬的地步。但我个人觉得,Vector被遗弃的最大原因不在于它线程同步影响效率——因为这毕竟能在多线程环境下使用——而在于它的扩容机制上。
细节2:Vector的扩容机制不完善
Vector默认容量也是10,跟ArrayList不同的是,Vector每次扩容的大小是可以指定的,如果不指定,每次扩容原来容量大小的2倍:
protectedObject[] elementData; // 元素数组
protectedintelementCount; // 元素数量
protectedintcapacityIncrement; // 扩容大小
publicVector(intinitialCapacity, intcapacityIncrement){
super();
if(initialCapacity < 0)
thrownewIllegalArgumentException( "Illegal Capacity: "+
initialCapacity);
this.elementData = newObject[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
publicVector(intinitialCapacity){
this(initialCapacity, 0); // 默认扩容大小为0,那么扩容时会增大两倍
}
publicVector(){
this( 10); // 默认容量为10
}
publicsynchronizedvoidensureCapacity(intminCapacity){
if(minCapacity > 0) {
modCount++;
ensureCapacityHelper(minCapacity);
}
}
privatevoidensureCapacityHelper(intminCapacity){
// overflow-conscious code
if(minCapacity - elementData.length > 0) // 大于当前容量就扩容
grow(minCapacity);
}
privatevoidgrow(intminCapacity){
// overflow-conscious code
intoldCapacity = elementData.length;
intnewCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity); // 默认扩容两倍
if(newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if(newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
另外需要提醒注意的是,不像ArrayList,如果是用Vector的默认构造函数创建实例,那么第一次添加元素就需要扩容,但不会扩容到默认容量10,只会根据用户指定或两倍的大小扩容。所以使用Vector时指不指定扩容大小都很尴尬:
如果容量大小和扩容大小都不指定,开始可能会频繁地进行扩容
如果指定了容量大小不指定扩容大小,以2倍的大小扩容会浪费很多资源
如果指定了扩容大小,扩容大小就固定了,不管数组多大,都按这大小来扩容,那么这个扩容大小的取值总有不理想的时候
从Vector我们也可以反观ArrayList设计巧妙的地方,这也许是Vector存在的唯一价值了哈哈。
细节3:Stack继承于Vector,在其基础上扩展了栈的方法
Stack我们也不使用了,它只是添加多几个栈常用的方法(这个LinkedList也有,后面讨论),简单来看下它们的实现吧:
// 进栈
publicE push(E item){
addElement(item);
returnitem;
}
// 出栈
publicsynchronizedE pop(){
E obj;
intlen = size();
obj = peek();
removeElementAt(len - 1);
returnobj;
}
publicsynchronizedE peek(){
intlen = size();
if(len == 0)
thrownewEmptyStackException();
returnelementAt(len - 1);
}
LinkedList的细节
再来看看我们熟悉的LinkedList的细节~
细节1:LinkedList基于链表实现,插入删除元素效率快,访问元素效率慢
LinkedList内部维护一个双端链表,可以从头开始检索,也可以从尾开始检索。同样的,得益于链表这一数据结构,LinkedList在插入和删除元素效率非常快。
插入元素只需新建一个node,再把前后指针指向对应的前后元素即可:
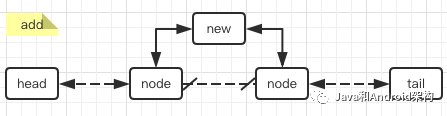
图2.3.1 插入元素
// 链尾追加
voidlinkLast(E e){
finalNode l = last;
finalNode newNode = newNode<>(l, e, null);
last = newNode;
if(l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
// 指定节点前插入
voidlinkBefore(E e, Node succ){
// assert succ != null;
// 插入节点,succ为Index的节点,可以看到,是插入到index节点的前一个节点
finalNode pred = succ.prev;
finalNode newNode = newNode<>(pred, e, succ);
succ.prev = newNode;
if(pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
publicvoidadd(intindex, E element){
checkPositionIndex(index);
if(index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
同样,删除元素只要把删除节点的链剪掉,再把前后节点连起来就搞定了:
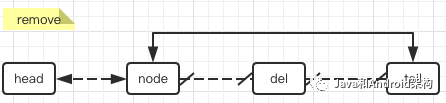
图2.3.2 删除元素
E unlink(Node x){
// assert x != null;
finalE element = x.item;
finalNode next = x.next;
finalNode prev = x.prev;
if(prev == null) {
// 链头
first = next;
} else{
prev.next = next;
x.prev = null;
}
if(next == null) {
// 链尾
last = prev;
} else{
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
returnelement;
}
publicE remove(intindex){
checkElementIndex(index);
returnunlink(node(index));
}
但由于链表我们只知道头和尾,中间的元素要遍历获取的,所以导致了访问元素时,效率就不好了:
Node node( intindex) {
//使用了二分法
if( index< (size >> 1)) { //如果索引小于二分之一,从first开始遍历
Node x= first;
for( inti = 0; i < index; i++)
x= x.next;
returnx;
} else{ //如果索引大于二分之一,从 last开始遍历
Node x= last;
for( inti = size - 1; i > index; i--)
x= x.prev;
returnx;
}
}
public E get( intindex) {
checkElementIndex( index);
returnnode( index).item;
}
所以,LinkedList和ArrayList刚好是互补的,所以具体场景,应考虑哪种操作最频繁,从而选择不同的List来使用。
细节2:LinkedList可以当作队列和栈来使用
不知大家有没注意到在图2.2中,LinkedList非常“特立独行地”继承了Deque接口,而Deque又继承于Queue接口,这队列和栈的方法定义就是在这些接口中定义的,而LinkedList实现其方法,使自身具备了队列的栈的功能。
当作队列(先进先出)使用:
// 进队
publicbooleanofferFirst(E e){
addFirst(e);
returntrue;
}
// 出队
publicE pollLast(){
finalNode l = last;
return(l == null) ? null: unlinkLast(l);
}
当作栈(后进又出)来使用:
// 进栈
publicvoidpush(E e){
addFirst(e);
}
// 出栈,如果为空列表,会抛出异常
publicE pop(){
returnremoveFirst();
}
SynchronizedList的细节
在Collections类中提供了很多线程线程的集合类,其实他们实现很简单,只是在集合操作前,加一个锁而已。
细节1:SynchronizedList继承于SynchronizedCollection,使用装饰者模式,为原来的List加上锁,从而使List同步安全
先来看下SynchronizedCollection的定义:
staticclassSynchronizedCollection implementsCollection, Serializable{
privatestaticfinallongserialVersionUID = 3053995032091335093L;
finalCollection c; // 装饰的集合
finalObject mutex; // 锁
SynchronizedCollection(Collection c) {
this.c = Objects.requireNonNull(c);
mutex = this;
}
SynchronizedCollection(Collection c, Object mutex) {
this.c = Objects.requireNonNull(c);
this.mutex = Objects.requireNonNull(mutex);
}
}
可以看到,可以指定一个对象作为锁,如果不指定,默认就锁了集合了。
再来看下我们关注的SynchronizedList:
staticclassSynchronizedList
extendsSynchronizedCollection
implementsList {
final List list;
SynchronizedList(List list) {
super( list);
this. list= list;
}
SynchronizedList(List list, Object mutex) {
super( list, mutex);
this. list= list;
}
...
publicE get(intindex){
synchronized (mutex) { returnlist.get(index);}
}
publicE set(intindex, E element){
synchronized (mutex) { returnlist. set(index, element);}
}
publicvoidadd(intindex, E element){
synchronized (mutex) { list.add(index, element);}
}
publicE remove(intindex){
synchronized (mutex) { returnlist.remove(index);}
}
...
}
想不到SynchronizedList的实现是如此简单,上面的源码想必不用我多说了。
写在最后
关于我们经常使用的List的细节到此就介绍完了,如果上面我有言论有误或不严谨的,欢迎大家指正;如果有另外一些细节我没谈及到的,也欢迎大神们补充。
最后,我们来做一次总结:
ArrayList和LinkedList适用于不同使用场景,应根据具体场景从优选择
根据ArrayList的扩容机制,我们应该开始就指定其初始容量,避免资源浪费
LinkedList可以当作队列和栈使用,当然我们也可以进一步封装
尽量不使用Vector和Stack,同步场景下,使用SynchronizedList替代
想快速提升Java技能吗?快加入我们的知识星球吧,如下:返回搜狐,查看更多
责任编辑:














 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









