







 文章详细介绍了如何使用Java实现正规式到非确定有限自动机(NFA)的转换,利用Thompson算法和算符优先级处理正则表达式,包括生成后缀形式的正则式、栈的运算以及构造NFA类的过程。通过逆波兰式处理运算优先级,简化了运算过程,最后给出了具体的代码实现和输出示例。
文章详细介绍了如何使用Java实现正规式到非确定有限自动机(NFA)的转换,利用Thompson算法和算符优先级处理正则表达式,包括生成后缀形式的正则式、栈的运算以及构造NFA类的过程。通过逆波兰式处理运算优先级,简化了运算过程,最后给出了具体的代码实现和输出示例。
编译原理Java实现正规式生成NFA(利用算符优先级实现Thompson算法)
文章目录
前言:
该部分代码属于仓库当中part03的部分,使用的语言为Java
由于代码比较多,文件数量也较多,因此先介绍一下不同的文件的功能:
其他文件是一些结构代码,方便进行数据的处理和面向对象,
源码已上传至Github,地址Cheesheep/CompilingTheory-Exp2-LexicalAnalysiz: read the regula expression to generate NFA (github.com)
代码位于仓库的part03的文件夹内
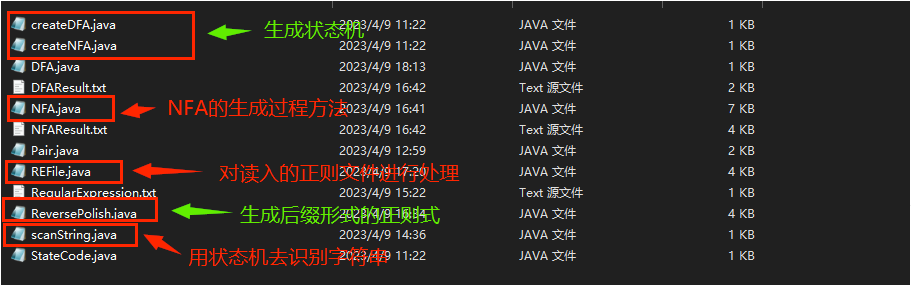
程序代码入口:
生成对应的NFA需要运行createNFA的Java类,在该类会调用REFIle类来对读入的文件进行处理。
这里给出一些正规式的输入示例
a(b|aa)*b
a*b
0(1|00)
a*b(b|(ab)*c)ca
a*b(b|(ab)*c)*ca
a*b(b|(db)*c|css*e)
((0|1)(010|11)*) | ((0|101)*)*
第二个正规式输出样例如下:
Reverse to PostFix: a*b-
K= {A, B, C, D, E, F}; Σ={a, b};
f(A, a)= {B}, f(B, ε)= {A, D}, f(E, b)= {F}, f(C, ε)= {A, D}, f(D, ε)= {E}, ;
C; Z={F}
实现和输出代码:
输出代码以及格式如下:
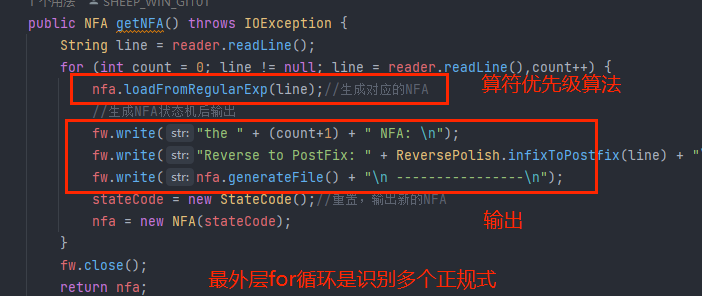
主要的运算逻辑代码都在loadFromRegularExp()里面。
1. 生成后缀形式的正则式
通过正则式计算NFA,如果仅仅使用条件语句,无疑是非常困难的,如何高效地使用面向对象来解决这个复杂的问题呢,这里就可以用到算符优先级的方法来实现,也就是Thompson算法。
说到算符优先级, 那么就不得不提到逆波兰式,机器是如何去计算那些四则运算的呢,较为常用的就是将中缀表达式转换成后缀表达式。
为什么要转换成后缀表达式呢,这样是为了让机器更容易去识别运算的优先级,像中缀表达式,由于括号,加法乘法的优先级不同,很容易导致运算顺序的不一致。
如:5 + 4 * (3 - 2)
放在后面的式子往往会先被运算,为了更好地让电脑知道怎么去计算,我们就手动将其转化成后缀表达式
结果为:5432-*+
这样就可以很轻松地进行运算了,因为运算的顺序已经排列好了。
这里就不展开阐述逆波兰式的思路了,接下来按照它的思路去给正规式转换成后缀形式的正规式。
这里举个正规式例子
正规式:a(b|aa)*b 增加连接符:a-(b|a-a)*-b 转换后:abaa-|*b--
1.1 增加连接符
看到上面转换的过程中,中间比四则运算多了一步“增加连接符”,是因为正规式当中的连接符号是不存在的,例如aa,实际上是两个字母对应的NFA的连接。
所以为了方便编写代码,我们要先将正规式处理一下
判断是否需要加连接符也很简单,源码如下:
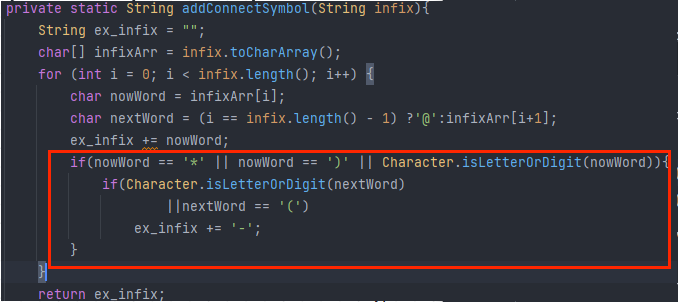
也是逐个遍历当前的正则式的字符,然后如果当前字符nowWord是’*‘或’)‘或Unicode字符(数字字母和一些特殊字母),
则判断下一个字符nextWord是否是’(‘或者UniCode字符,是则说明需要连接。)
1.2 设置算符优先级
接着是设置算符的优先级方便运算,这里经过判断后,直接得出优先级顺序应当如下:
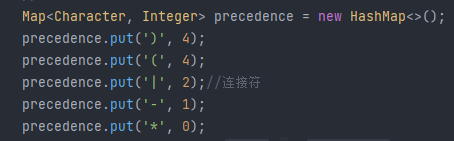
使用map,这样方便 if 语句用containsKey()判断是否是操作符
1.3 for循环生成后缀表达式
大概思路如下
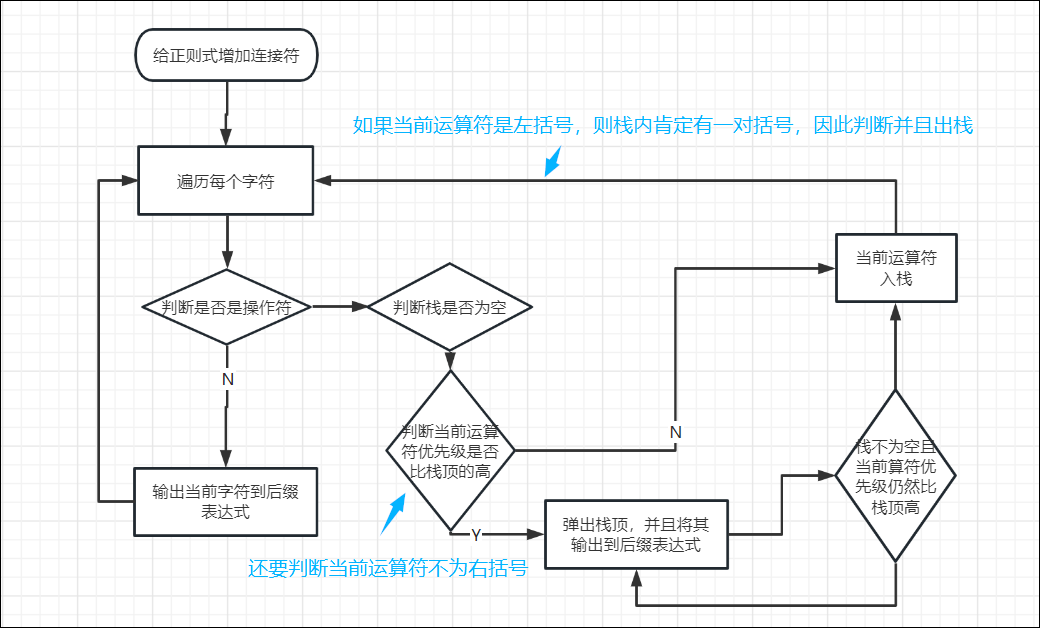
除了正常根据操作符优先级判断由于括号运算比较特殊,所以需要多加一个判断,
否则出现右括号的时候,右括号前面的操作符都会被优先输出(因为右括号优先级很高,保证右括号后面的算符不会被先弹出,只有等到左括号的时候才能弹出,但是这样右括号前面的就会因为优先级较低而被先弹出,这样就矛盾了)
完整的代码如下(addConnetSymbol()上面已经给出):
public static String infixToPostfix(String infix) {
//优先级高的入栈的时候
Map<Character, Integer> precedence = new HashMap<>();
precedence.put(')', 4);
precedence.put('(', 4);
precedence.put('|', 2);//连接符
precedence.put('-', 1);
precedence.put('*', 0);
infix = infix.replaceAll(" ","");//先去掉所有空格
infix = addConnectSymbol(infix);//增加连接符
StringBuilder postfix = new StringBuilder();
char nowWord; //nowWord是当前字符,last是当前栈顶的字符
for (int i = 0; i < infix.length();i++) {
nowWord = infix.charAt(i);
if(precedence.containsKey(nowWord)){
//判断是否是操作符
if(operatorStack.isEmpty())
operatorStack.push(nowWord);
else if (precedence.get(nowWord) > precedence.get(operatorStack.peek())
&& nowWord != '(') {//特殊的,如果是右括号则前面的暂不处理
//如果下一个操作符的优先级较高,
// 则要将当前栈的操作符输出直到空或者当前优先级更高
do {
postfix.append(operatorStack.pop());
} while (!operatorStack.isEmpty() &&
precedence.get(nowWord) > precedence.get(operatorStack.peek()));
//这里会有可能将()入栈,是为了方便用算符优先级表示
operatorStack.push(nowWord);
}
else{
operatorStack.push(nowWord);
}
if(nowWord == ')')
{
//清除 ( )
operatorStack.pop();
operatorStack.pop();
}
}else {
//是字母或者数字则直接输出
postfix.append(nowWord);
}
}
while (!operatorStack.isEmpty()){
postfix.append(operatorStack.pop());
}
//去掉多余的括号并且输出
return postfix.toString().replaceAll("[()]","");
}
实例输出结果如下:
RegularExpression:
a (b|a a )* b
ReversePolish:
abaa-|*b--
2. 使用栈实现运算
首先来讲如何利用栈结构来实现运算
没错这一个部分也需要用到栈,足以见得数据结构的重要性
流程图如下:
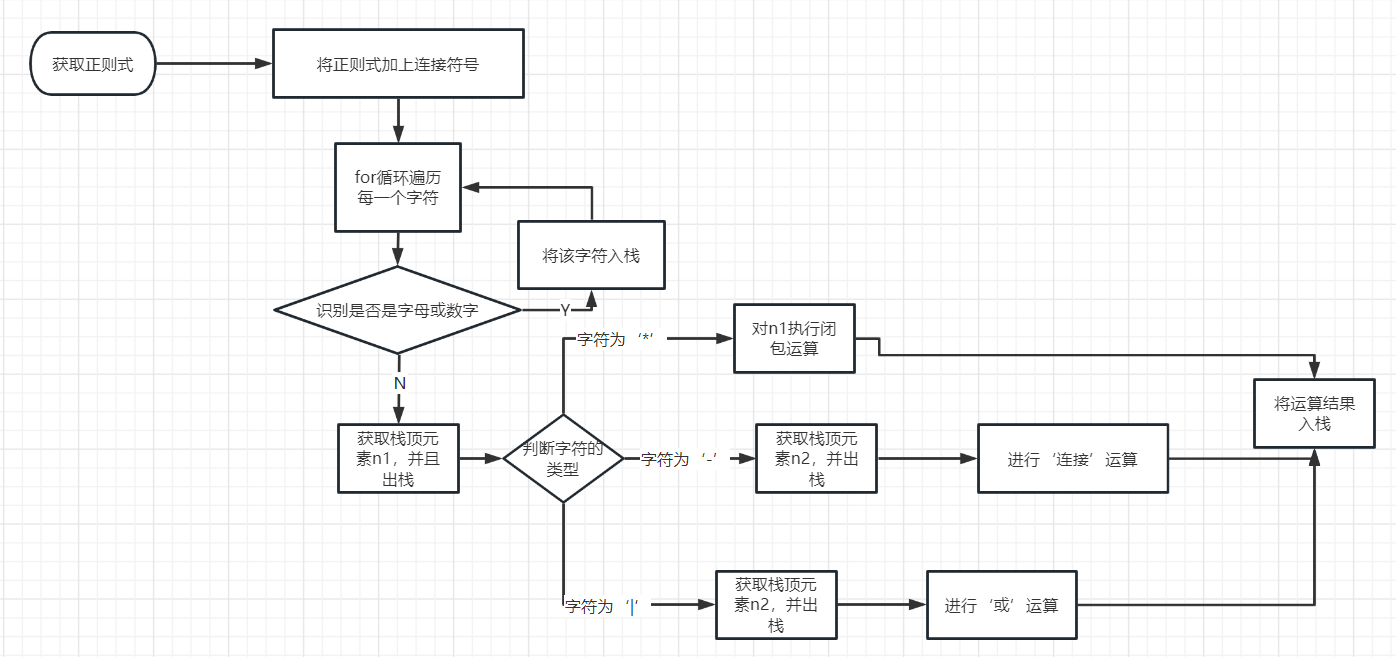
对正则式加上连接符号处理后,就可以开始识别了。
主要分为两种情况:
- 当前字符是数字或者字母,Java当中可以使用Character类的
isLetterOrDigit()方法来判断 - 如果不是上述情况,视为操作符,然后进行switch判断
在switch方法当中对不同的操作符进行不同的运算。
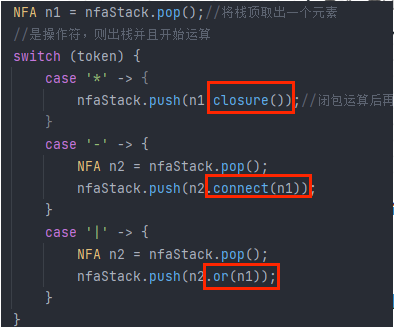
如图,思路很清晰也很简单,具体的操作符运算细节这里暂不展开
for循环代码如下:
for(int i=0; i<postfix_RE.length(); ++i) {
char token = postfix_RE.charAt(i);
if (Character.isLetterOrDigit(token)) {
//是Unicode则生成一个NFA并且入栈
nfaStack.push(create(token));
}else {
NFA n1 = nfaStack.pop();//将栈顶取出一个元素
//是操作符,则出栈并且开始运算
switch (token) {
case '*' -> {
nfaStack.push(n1.closure());//闭包运算后再放回去
}
case '-' -> {
NFA n2 = nfaStack.pop();
nfaStack.push(n2.connect(n1));
}
case '|' -> {
NFA n2 = nfaStack.pop();
nfaStack.push(n2.or(n1));
}
}
}
}
for循环结束后,取出当前的栈顶元素就可以获得我们需要的NFA了。
3. 构造NFA类
在说明了主要思路之后,接下来只需要把NFA给构造出来,即用面向对象的思想,即可按我们的需要输出状态机NFA了。
3.1 如何存放和表示状态转换表
在得到NFA后,输出如下:
Reverse to PostFix: a*b-
K= {A, B, C, D, E, F}; Σ={a, b};
f(A, a)= {B}, f(B, ε)= {A, D}, f(E, b)= {F}, f(C, ε)= {A, D}, f(D, ε)= {E}, ;
C; Z={F}
按照输出的内容以及实际需要,DFA类的成员数据如下:
String RegularExpression;
int startState;
int endState;
char epsilon = 'ε';
StateCode stateCode;
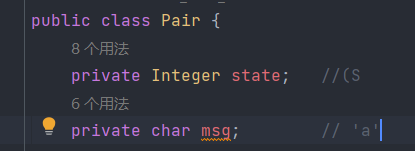
// => (S,a) -> {A, B} 可能有多个状态,所以用list
HashMap<Pair, ArrayList<Integer>> transferMat = new HashMap<>();
//记录所有产生的状态如A、B等
ArrayList<Integer> stateList = new ArrayList<>();
//转移信息如a,b等小写字母或者数字
ArrayList<Character> msgList = new ArrayList<>();
-
RegularExpression:存储输入的正则式
-
statrStae、endState:表示起始和终止状态,分别对应的是输出的最后一行的两个输出,Z={终止状态}
-
stateCode:主要用于生成新的状态
注意:这里的state都是用Integer来表示,这样方便存储,
在需要输出的时候,再调用函数按自定的规则映射成相应的字母。
-
transferMat:存放所有的状态迁移,即输出的 f(A,a)={B}
-
stateList:对应输出当中的K里面的内容
-
msgList:转移条件,对应输出的 Σ={a, b}
-
Pair:用于存放单个状态转移内容,由起始状态和转移条件组成
有了以上的内容之后,就可以开始进行数据存储和运算了。
3.2 如何进行闭包、连接等运算
刚开始去思考这些算法的时候,会觉得很抽象,思路都很难理清,代码难以下手,因此要先理清思路。
画图是个很好的方法,很形象。
这里一共有四个操作,除了前面提到的连接,闭包,或运算外,还有一个用于创建新的状态。
给出具体的实现方法,并稍微进行讲解。
-
create():
根据输入的字符创建一个新的状态机,这个状态机只需要两个节点,分别是起始和终止节点。
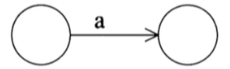
a就是我们的输入字符
private NFA create(char msg) { //a NFA nfa = new NFA(this.stateCode); generateNewState(nfa);//生成新状态 nfa.msgList.add(msg); nfa.addEdge(nfa.startState, nfa.endState, msg);//增加一个状态的转移到transMat当中 return nfa; } -
connect():对应连接符 ‘-’
该方法会用到自身作为实例,以及传入一个nfa进行连接,用到四个节点的操作:

中间通过空字符ε进行连接,那几个collect方法是将两个nfa的数据拼接起来并且赋给这个新的nfa
private NFA connect(NFA other) { //r1 o r2 连接符:‘-’ //r1.connect(r2) NFA nfa = new NFA(this.stateCode); nfa.startState = this.startState; nfa.endState = other.endState; nfa.transferMat = this.collectTransferMat(other.transferMat); nfa.stateList = this.collectStateList(other.stateList); nfa.msgList = this.collectMsgList(other.msgList); //生成连接的边 nfa.addEdge(this.endState, other.startState, epsilon); return nfa; } -
or():对应或运算符 ‘ | ’
或操作需要生成四条新的连接边,并且会生成两个新的状态:
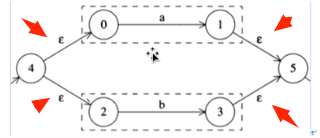
如图,分别生成两个新的状态作为起始和终止节点,并且用相应的四条边连接起来。
private NFA or(NFA other) { //r1 | r2 //用法: n1.or(n2) NFA nfa = new NFA(this.stateCode); //分支的起点和终点 generateNewState(nfa); //将新的两个数据都添加进去 nfa.collectTransferMat(this.collectTransferMat(other.transferMat)); nfa.collectStateList(this.collectStateList(other.stateList)); nfa.collectMsgList(this.collectMsgList(other.msgList)); //create new epsilon edge nfa.addEdge(nfa.startState, this.startState, epsilon); nfa.addEdge(nfa.startState, other.startState, epsilon); nfa.addEdge(other.endState, nfa.endState, epsilon); nfa.addEdge(this.endState, nfa.endState, epsilon); return nfa; } -
closure()闭包:对应闭包运算符: ‘ * ’
闭包只需要获取当前的nfa,并且对其进行操作,但也需要生成四条边和两个新的状态
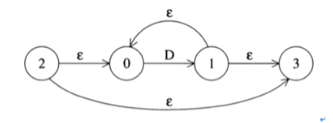
private NFA closure(){ // a* 闭包操作 NFA nfa = new NFA(this.stateCode); //create new start / end state generateNewState(nfa); nfa.collectTransferMat(this.transferMat); nfa.collectStateList(this.stateList); nfa.collectMsgList(this.msgList); //增加epsilon边缘 nfa.addEdge(this.endState,this.startState,epsilon);//回溯 nfa.addEdge(nfa.startState,this.startState,epsilon); nfa.addEdge(this.endState,nfa.endState,epsilon); nfa.addEdge(nfa.startState, nfa.endState,epsilon);//允许为空直接跳跃 return nfa; }
主要的操作和逻辑都已经介绍了,剩下一些涉及到的方法,根据方法名大致理解了操作思路即可,完整源码这里就不放出来了,可自行到GitHub查看
fa.collectMsgList(this.msgList);
//增加epsilon边缘
nfa.addEdge(this.endState,this.startState,epsilon);//回溯
nfa.addEdge(nfa.startState,this.startState,epsilon);
nfa.addEdge(this.endState,nfa.endState,epsilon);
nfa.addEdge(nfa.startState, nfa.endState,epsilon);//允许为空直接跳跃
return nfa;
}
主要的操作和逻辑都已经介绍了,剩下一些涉及到的方法,根据方法名大致理解了操作思路即可,完整源码这里就不放出来了,可自行到GitHub查看

















 1607
1607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









