






三、C++编译
前面给大家演示了如何从写C++代码到编译代码再到执行代码的全过程。这个过程中非常重要的编译环节,被我们一个按钮或者一个ctrl+F7快捷键就给带过了。其实这个环节非常重要,如果你非常了解这个环节,你开发源代码就会更加自信和清醒,而不是迷迷糊糊,摸棱两可……
下图直观描述了从源代码到计算机执行完毕的各个大环节:
内容实在多,图上没位置了,这里就继续说明上图。上图的1234是几个大步骤。1是我们的开发环境,你的代码就是在这个平台上书写、调试、编译、执行。。。等等
上图2是我们在1中开发的代码。这4行代码的功能就是把一个数字3存储到内存。但是A是我们人类能看懂的英文文字、数字3、一些符号,比如分号、小括号、花括号等等。那cpu可是看不懂这些呀,所以我们要把A编译成D2,因为cpu可以看懂D2,cpu就可以执行了D2了,执行完毕就可以完成我们人类的任务:写个3到内存。本部分重点讲3这个过程,就是如何编译的。
那我们再讲点题外的东西,以便我们对整体流程有一个认识。那就是后面的4,4说的就是cpu是如何执行D2的。我们说了D2是可执行二进制指令,也就是机器码(machine code),这些机器码先按照字节为单位加载到内存,就是E,当然E会很长很长,上图我就画了2个内存单位。加载完毕后就逐个单元地送到CPU。CPU只是一些电路(当然这个电路会及其复杂,cpu又称芯片,要不怎么芯片被卡脖子呢),它功能其实非常简单,它只会从内存读取数据、往内存中写入数据。当内存的这些指令数据送到CPU后,这些指令0101,就是高电平低电平的意思,那这些不同的特殊组合的高低电平流就会引起cpu中的晶体管打开或关闭,也就是引起不同的电路,不同的电路又会产生不同的输出结果,不同的输出结果指的是不同的高低电平的输出,也就是有序的0101序列的输出,而输出就是输出到内存。而内存上不同序列的0101又和人类认识的符号相对应。于是输出就又能映射成人类理解的东西,比如屏幕上的一行字,比如声卡输出的一段音频等等人类的东西。
具体到我们上图的例子,cpu输出的结果就是在内存的某个内存单元里面存了个3。那cpu具体是如何执行F的呢?我们看4.1,4.1中的H就是部分机器码,都是0101,我们看不懂,没关系,我先把这0101转化为16进制,就是J,J我们还看不懂,那我们把J在转化成K(这个过程叫优化,比如全部是0的就是空行的意思,也就是啥也不用做,所以可以删除了。关于优化环境我们后面还要单独拿出来演示),K还是看不懂,那我们把K再转化为L和M。L和M我们人类认识吧,这就是汇编语言,至少里面mov是move的意思,是我们人类的tocken,呵呵。。其中L的意思启动和结束的意思,仅仅是M这行代码是我们人类的任务:mov一个数字3到内存的后面表示的那个内存地址里面。这才是我们人类任务执行完毕的整个流程。
看似已经洋洋洒洒写了很多了,其实这个流程也是只是个大概。上图中每个箭头都表示从这一步到下一步的意思,其实每步还有很多很多的细节。本小节,我们只把步骤3——编译,拿出来展开讲解。
1、明确几个概念
我们的文本代码.cpp需要转化成.exe可执行程序,cpu才可以执行。
从.cpp到.exe的过程,我们就笼统的叫做编译,其实这个过程是需要经过下面4个子过程的:
(1)预处理(Preprocess):从.cpp变成.i文件。是处理一些预处理语句。
(2)编译(compile):从.i文件到.obj文件,也就是汇编码。这一步是编译的核心。这一步还要分很多个子环节,也是本部分的难道和重点。
(3)汇编(Assemble):将编译环节生成的汇编码转化为二进制码,也就是机器码。
(4)链接(Link):将机器码转化为.exe文件。其实如果你源文件没有引用其他文件或库之类的,就像上图的示例中的源代码,啥也没有,那其实到汇编就结束,汇编后的机器码就可以放cpu上执行了。但事实上,我们不会写上例中那么无聊的代码,至少我们要写一个在屏幕上打印个hello world啥的。那在屏幕上打印东西都已经不是那么简单了,此时你写的源代码就需要引入头文件啥的,那此时生成的机器码还没法放cpu上执行,因为这些文件里面有引用其他文件的代码,而且其他文件代码cpu也不知道,所以就没法执行。所以此时你还得进行链接link。尤其是我们在实际项目开发过程中,我们不仅会有很多引用,我们还会有很多.cpp文件。compile只是对每个.cpp文件分别进行编译,分别生成每个文件的.obj文件。汇编过程也仅仅是从汇编语句转化为机器指令。此时各个文件都还是零散的,文件之间的联系还是没有建立的。那此时就非常有必要再有个链接器把我们这些所有的文件都链接起来。所以,一般情况下我们的源代码编译完毕后都是要进行链接的,链接完毕后才是.exe文件——可执行程序文件,cpu才可以执行。
所以,平时我们经常说的编译其实预处理+编译+汇编+链接,其实就是build,build=preprocess+compile+assembel+link。如果你的源代码简单到无聊,那你可能就不需要link了,但一定得预处理和编译和汇编才能执行。也所以有时为了理解上的简单,我们经常把编译直接分两步:编译+链接,此时你要知道这个编译指的预处理+编译+汇编这几个环节的。
- 此外,这里还得梳理几个概念:
(1)编译器是把我们每个.cpp文件都分别编译成独立的.obj文件,所以在这个过程中每个.cpp文件都是一个翻译单元(translation unit),一个翻译单元生成一个obj文件。
在C++中,文件翻译单元是指一个.cpp文件以及它包含的所有头文件组合到一起形成的单独编译单元。每个.cpp文件在编译时都会生成一个翻译单元。例如,假设你有一个名为main.cpp的源文件和一个名为utils.h的头文件。main.cpp包含#include "utils.h"。在编译main.cpp时,utils.h中的所有内容也会被插入到main.cpp中,形成一个翻译单元,然后这个翻译单元会被编译成可执行文件或对象或库代码。
在这个例子中,main.cpp和utils.h组合在一起形成了一个翻译单元,utils.cpp是另一个翻译单元。在编译时,每个.cpp文件都会独立编译成一个对象文件或库或可执行程序。最后,链接器会将这些对象文件和库文件和可执行文件合并成最终的一个可执行文件。
(2)C++是不关心文件名的,不像Java语法,你的类名和你的文件名得一样、你得文件夹层次要和你的package一样。但是C++不一样:在于C++中,文件只是提供给编译器源代码的一种方式。文件名只负责告诉编译器你给它的是什么类型的文件、以及这种类型文件编译器应该如何处理它。比如你给编译器一个.cpp的文件,编译器就把这个文件当作C++文件进行处理;当你给编译器一个.C或者.H文件,编译器会把.C文件当成C语言文件进行处理,而不是当作C++文件进行处理,同时把.H文件当作头文件进行处理。这些都是默认的约定。当然你也可以更改,比如你给编译器一个.abcdef文件,那你就得再告诉编译器这种文件你按照C++文件进行处理,也是可以的。
(3)文件是指一组相关数据的有序集合,这个数据集的名称叫做文件名。例如源程序文件(.cpp)、目标文件(.obj)、可执行文件(.exe)、库文件(头文件)等。文件通常是驻留在外部介质(如磁盘等)上的,在使用时才调入内存中来,这就是为什么对文件操作时需要打开和关闭的原因。
在C++语言中,文件是一个流的概念。头文件fstream定义了三个类型:
ifstream:从一个给定文件读取数据;
ofstream:向一个给定文件写入数据;
fstream:读写给定文件。
类型的操作和cin、cout一样,可以用IO操作符(<<和>>)来读写文件,也可以用getline函数读取一整行数据。
(4)在 C++ 程序中,符号(例如变量或函数名称)可以在其范围内进行任意次数的声明。 但是,一个符号只能被定义一次。 这就是“单一定义规则”(ODR)。
这些概念是我们理解后面的基础,目前我能想到的就是这么。下面我们就展开编译的4个子过程,详细聊:
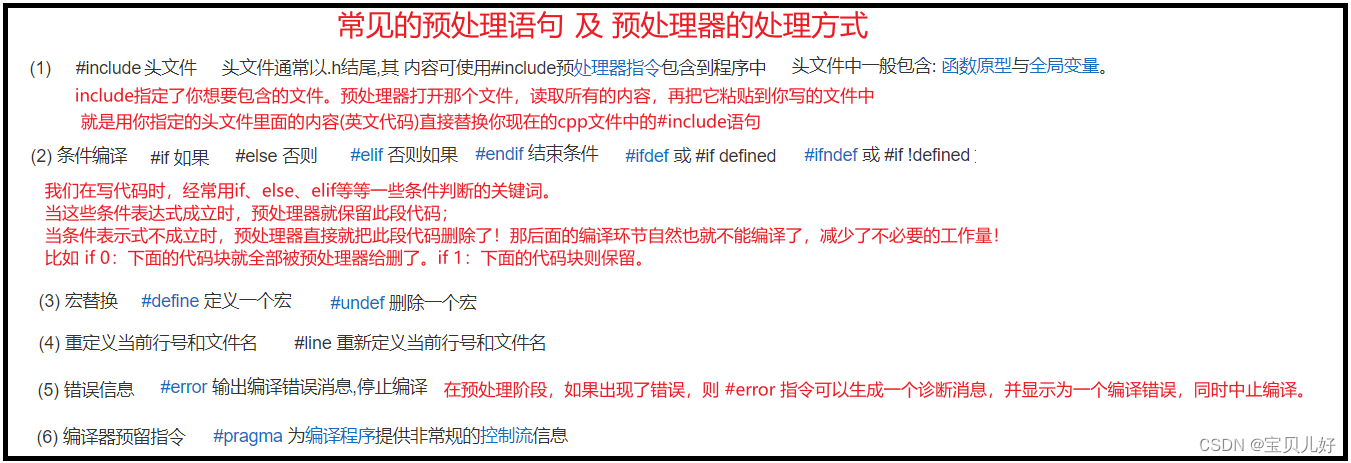
2、预处理(Preprocess):
编译器中进行预处理操作(Preprocess)的是预处理器(Preprocessor), 也是第一个上场的程序。预处理器(Preprocessor)是对C++程序源代码进行简单替换和增删的一个操作。
预处理不对程序的源代码进行解析,仅仅是替换或删除某些代码块而已。所以预处理完毕后文件(.i文件)还是一个字符串文件,就是还是都是英文单词和数字那样的字符文件。
那么预处理是如何进行增删替换的呢?当然就是人为给它定义一些规则,符号规则就增删替换。
那也所以,预处理的工作流程就是:逐行遍历.cpp文件中的所有代码行,遇到预处理语句时,根据规则增删。
那么哪些是预处理语句?哪些是要替换的?用谁替换?哪些又是删除的?
上面是预处理原理,下面我们看看预处理的实操过程: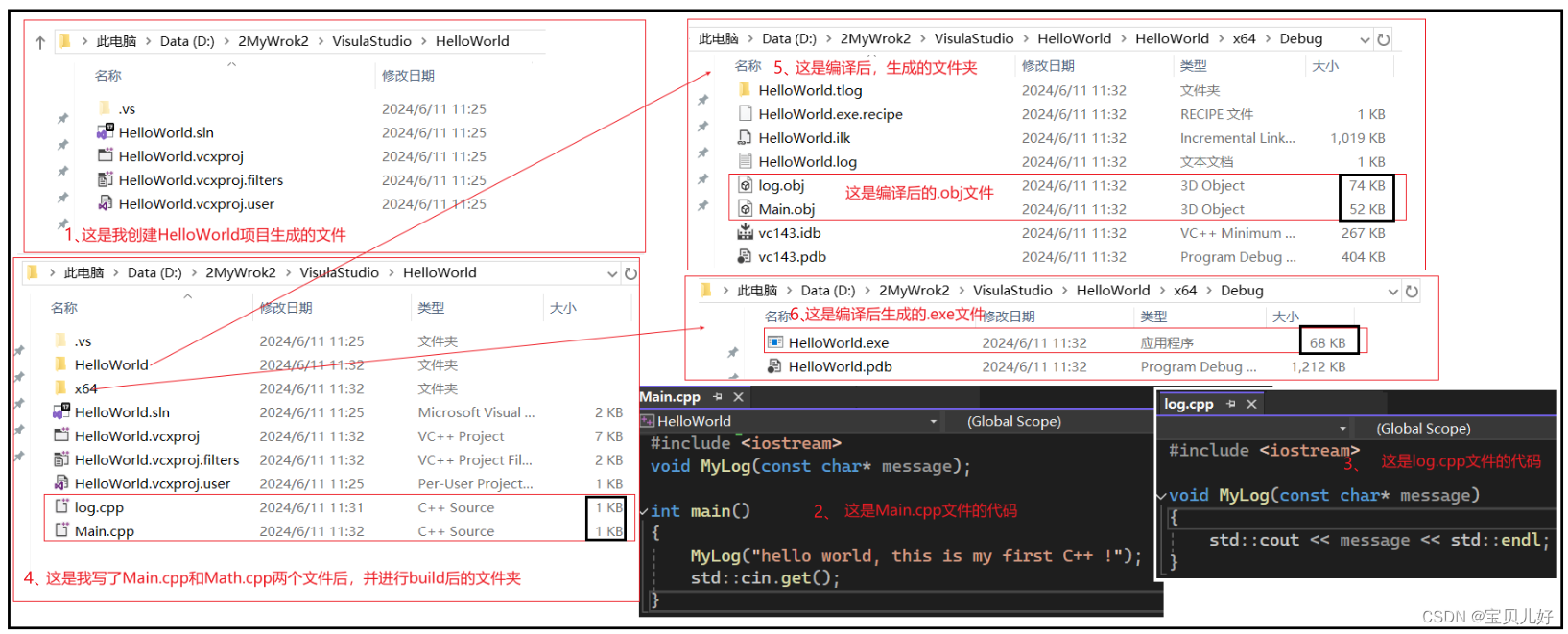
从上图可以看出我们的.cpp文件只有1k,但是build完毕后竟然有几十k,原因就是编译器进行了预处理。
我们对比一下有预处理语句的cpp文件和无预处理语句的cpp文件,编译后的差别: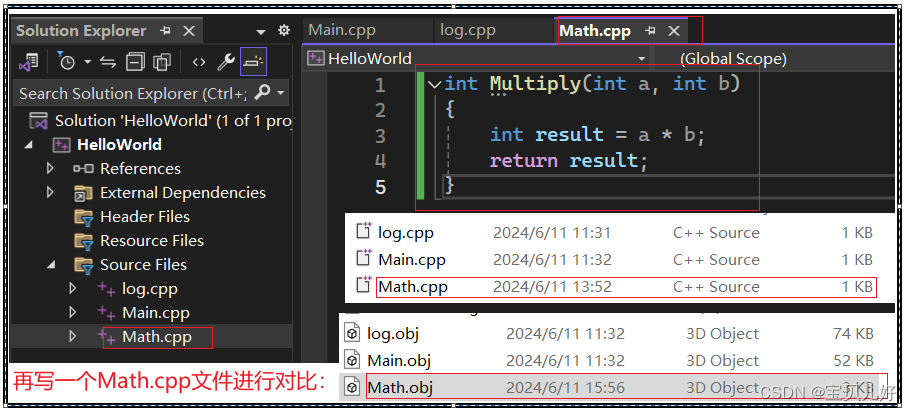
那么预处理到底是不是简单的替换和删除呢?看下面例子:
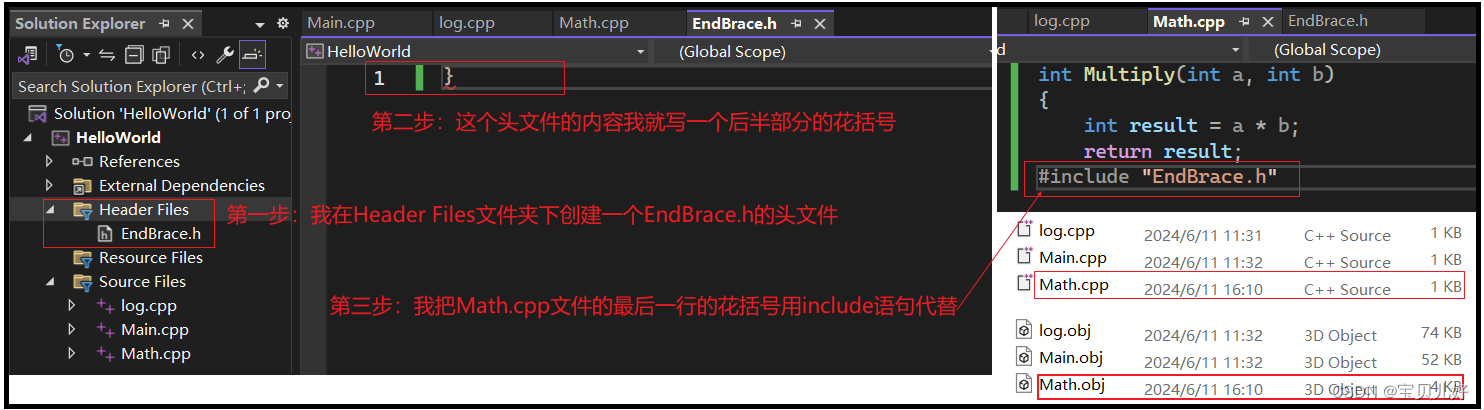
为啥Math.cpp编译后没大多少啊?因为仅仅是从EndBrace.h文件中复制了一个后花括号而已。就是我前面说的,预处理仅仅是复制粘贴一些文本而已。这里就是把.h文件中的字符}复制到Math.cpp中的include那行位置上而已,或者说就是替换了include那行而已。那到底是不是你说的啊?我们看看生成的预处理文件.i文件就能证明了: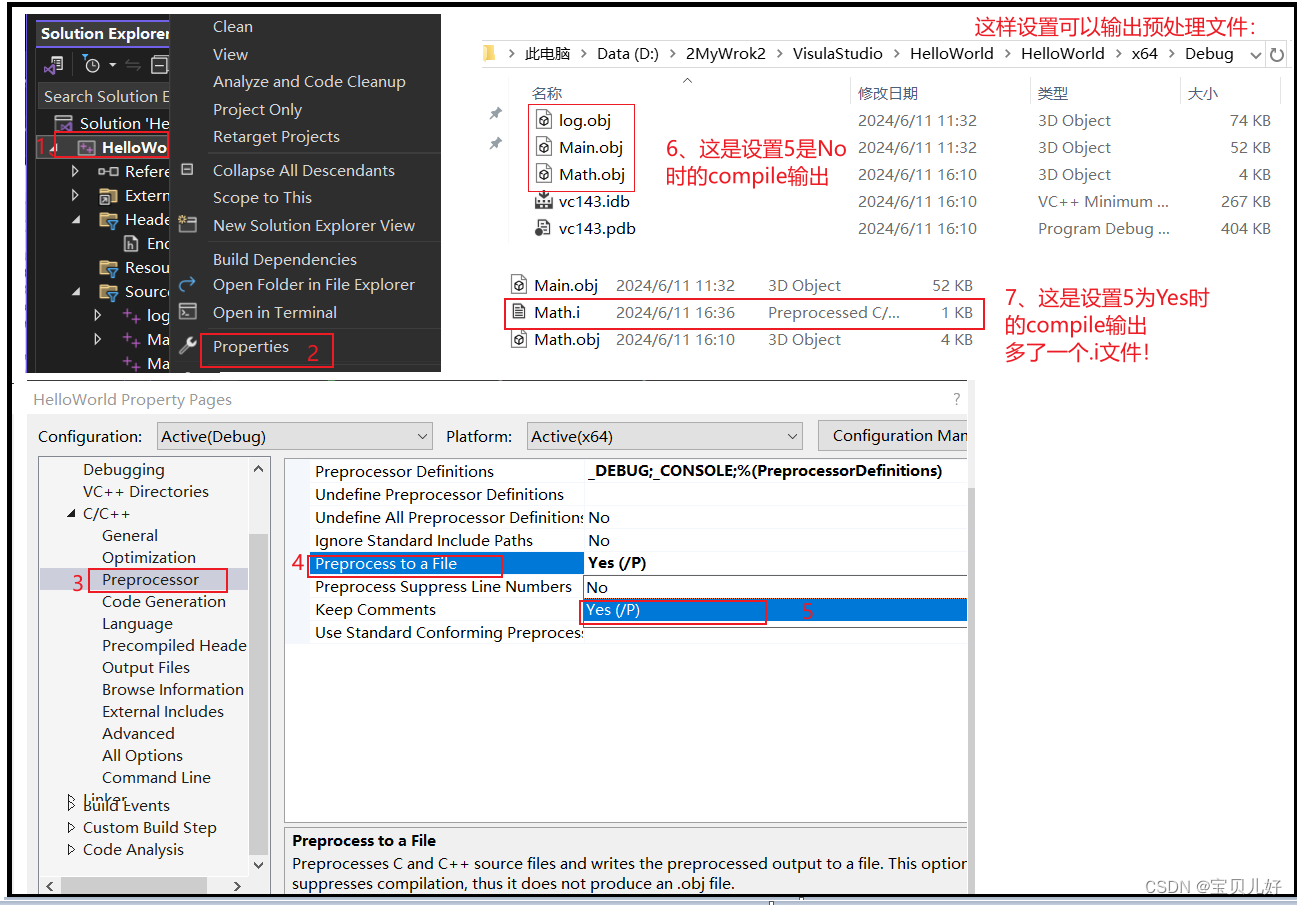
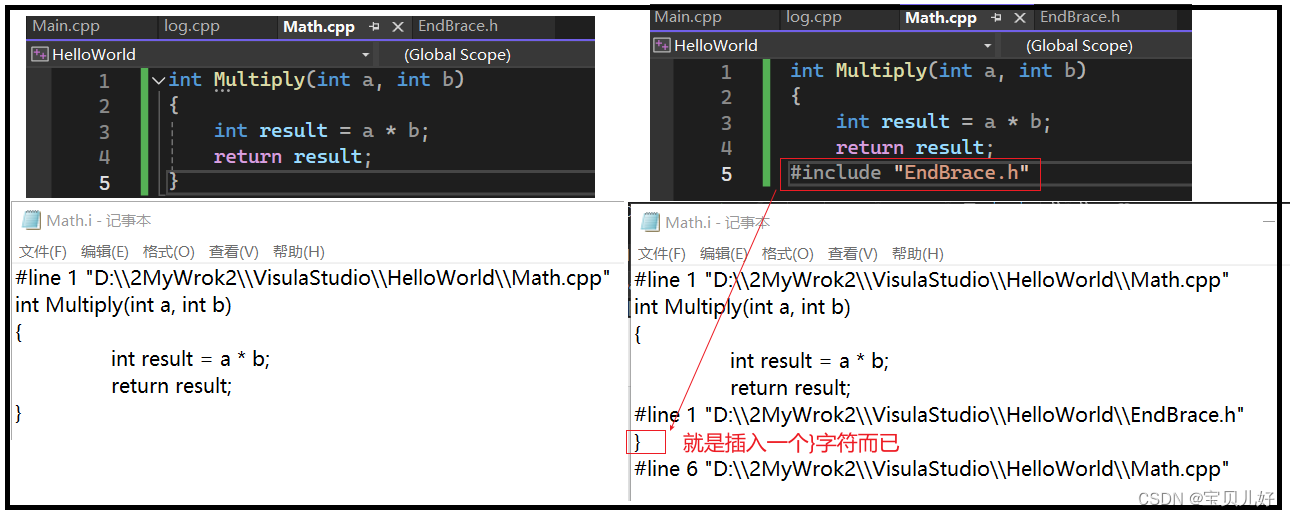
可见是不是就是仅仅是用头文件中的}替换了源文件中include那行代码,就是一个删除并替换的动作。下面我们再看看其他情况下的.i文件是不是也是按照前面说的规则生成的: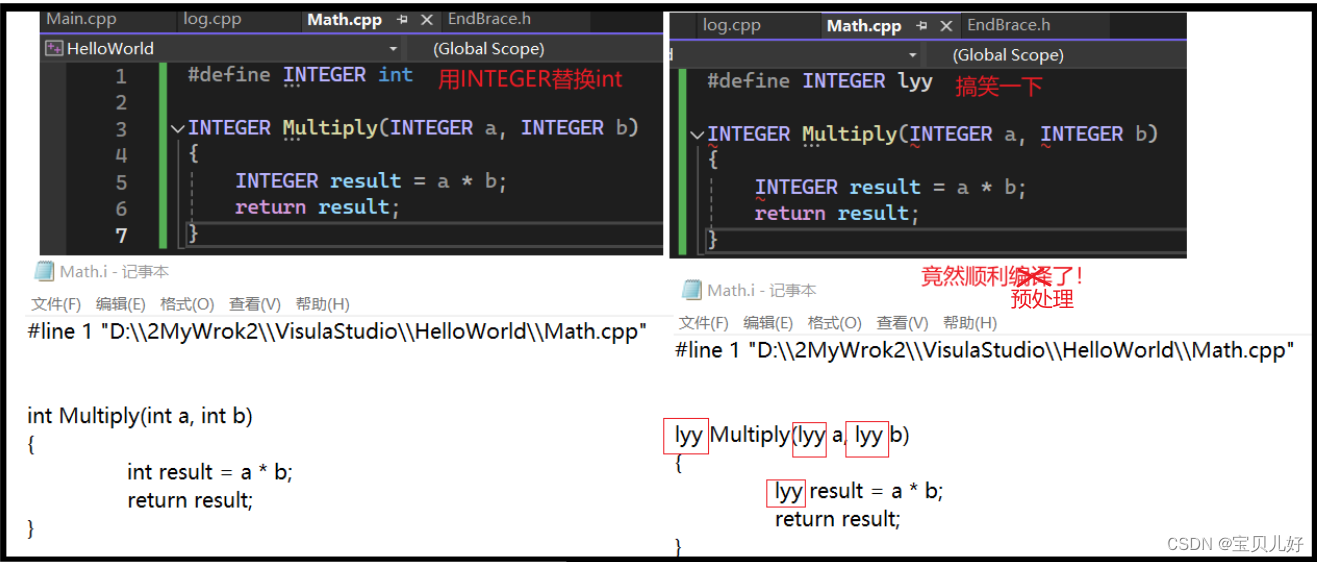
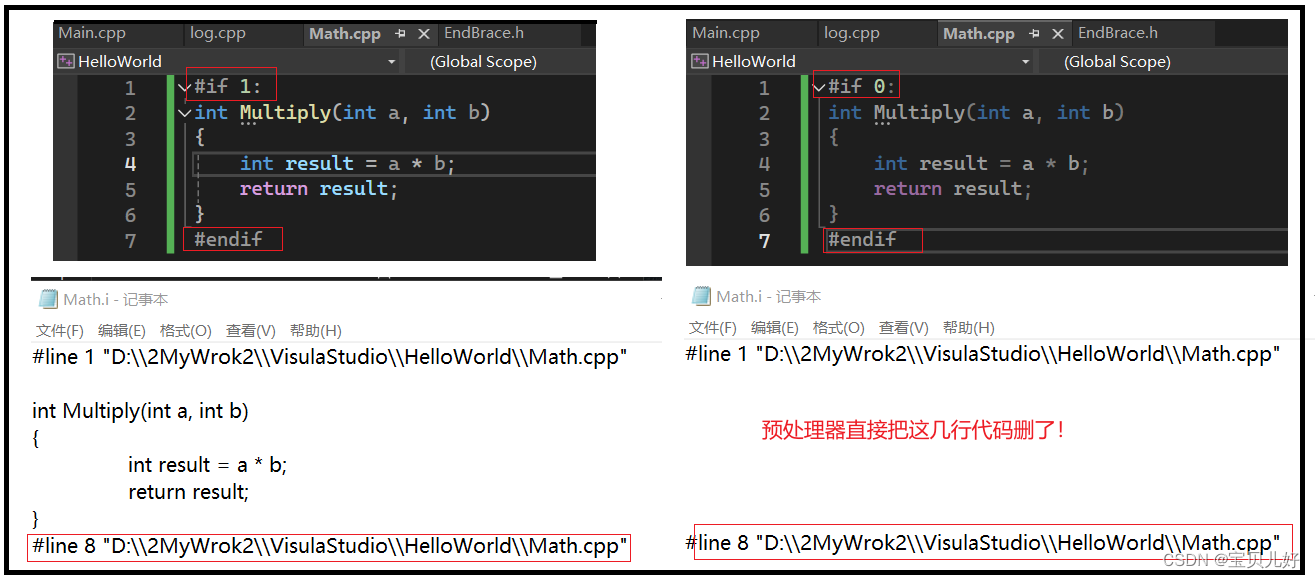
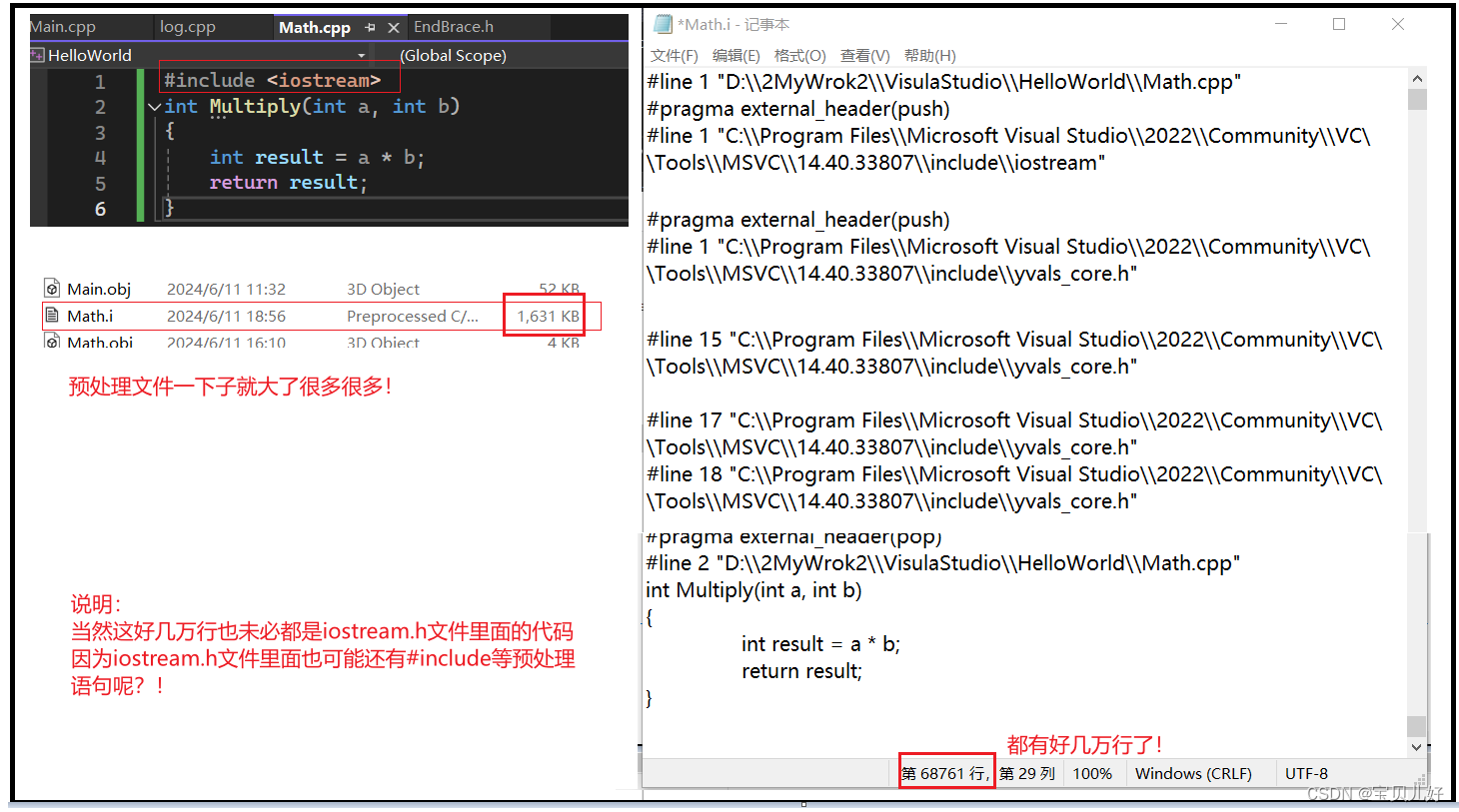
可见,在预处理过程中主要就是,处理源代码中的预处理语句:引入头文件(替换)、去除注释(删除)、处理所有的条件编译指令(该删除的删除,不该的留下),宏的替换(替换),添加行号(添加),保留所有的编译器指令(添加)。
以上就是预处理,下面我们看更核心部分:
3、编译(Compile)
编译环节最难理解,我只讲流程和原理以及实现效果,具体的实现代码,大家可以参考:一般通过程序员 - 简书 这篇博文,作者层层递进,写得非常非常好。
编译阶段就是进行记号化和解析,就是把英文C++语言转化为可执行目标代码的过程。整个过程如下: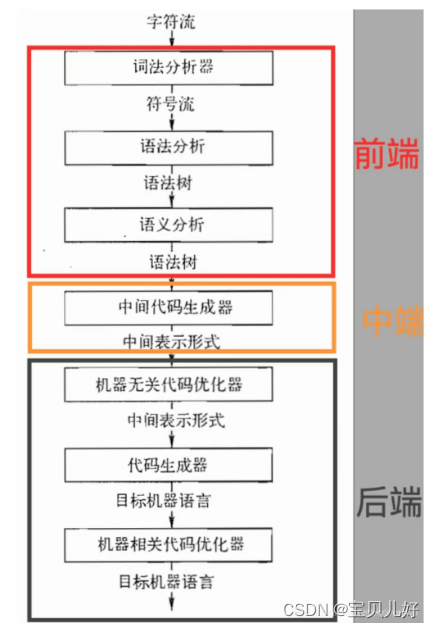
(1)词法分析(lexical Analysis):
这一步也称编译的第一步,由词法分析器完成。词法分析器先读取预处理完毕后的源代码字符流,然后根据事先预定义好的词法规则集(通常称为词法规格说明或词法规则表),将其分隔成最小单元,也就是逐个识别出Token:
所以词法分析器的工作原理是:
一是扫描(Scanning):逐字符读入源程序,遇到空白、注释等非有效字符时跳过,遇到有效字符则保留。
有效字符是:关键词keywords、标识符identifiers(比如变量名、函数名、类型、结构体标签、枚举成员等的名称)、常量constant(比如整型常量、浮点型常量、字符常量、字符串、枚举常量等)、运算符operators(关系运算符、辑运算符、位运算符、赋值运算符等等)、分隔符(用于标记语句或表达式边界或组织程序结构的符号,比如小括号、大括号、中括号、逗号分号冒号点箭头井号注释符号、斜杠、双斜杠等等)。
二是识别(Recognize and Generation):一旦识别出合法的连续字符序列,就映射到对应的Token类别上。比如“if”识别为关键字token,“123”识别为整型常量token,"="识别为赋值运算符token等等。并且还要生成对应的Token,这个Token就包含了类型、值等信息结构,以供语法分析阶段使用。
三是错误处理(Error Handing):当遇到不符合预期的输入时,词法分析器要能够报告错误,一边程序员定位错误和修复错误。
具体真正自己写一个词法分析器的技术实现方式,网上有大量的参考资料,比如用正则表达式、DFA或NFA(有限状态机) 等等都可以参考。
小结:本步的输入是预处理后的.i文件,也就是string;输出是Tokens(词法单元)。这些Tokens对应计算机来说都是有明确意义的符号。
(2)语法分析(Syntax Analysis):
这是编译的第二步,由语法分析器完成。语法分析器通常是在词法分析器之后执行。所以其输入就是词法单元(Token)。
语法分析器要实现:
一是检查代码是否符号语法规则。如果不符合语法规则,语法分析器就抛出语法错误。错误处理和调试技巧是语法分析器的一个重要功能。如果在语法分析阶段发现了错误,语法分析器要能够准确定位错误并抛出清晰的错误信息,这样程序员才能够快速定位和修复错误。
二是将词法单元(Tokens)转化为语法树(Abstract Syntax Tree, AST)。语法树是编译器的一个重要数据结构,它将代码的语法结构以树的形式表示出来。如何将代码的语法结构以树的形式表示出来?可以自上而下top-down(递归下降算法)或者自下而上bottom-up(移进-归约的方式)两种方法。这两种方法各有优缺点。
不管哪种方法都有对应的一些实现算法。但是不管你看哪种算法,你都得清楚这两个概念,这两个概念是理解这些算法的关键:
a、终结符:是指不再被分解的符号,也就是语法树上的叶子节点。比如变量名、数字、运算符等token。
b、非终结符:是指可以被分解为其他符号的符号,也就是语法树上的非叶子节点。比如表达式、语句、函数、类等token。
所以自上而下的语法分析器中的递归下降算法(Recursive Descent Parser)就是每个非终结符对应一个函数,该函数只负责该非终结符所对应的语法规则。例如:
意思就是所有的非终结符(也是单个的token)都已经说到最底层了。那语法树就就是一串token了。语法树就是把一个代码块(token串)给串联起来,比如下图示例: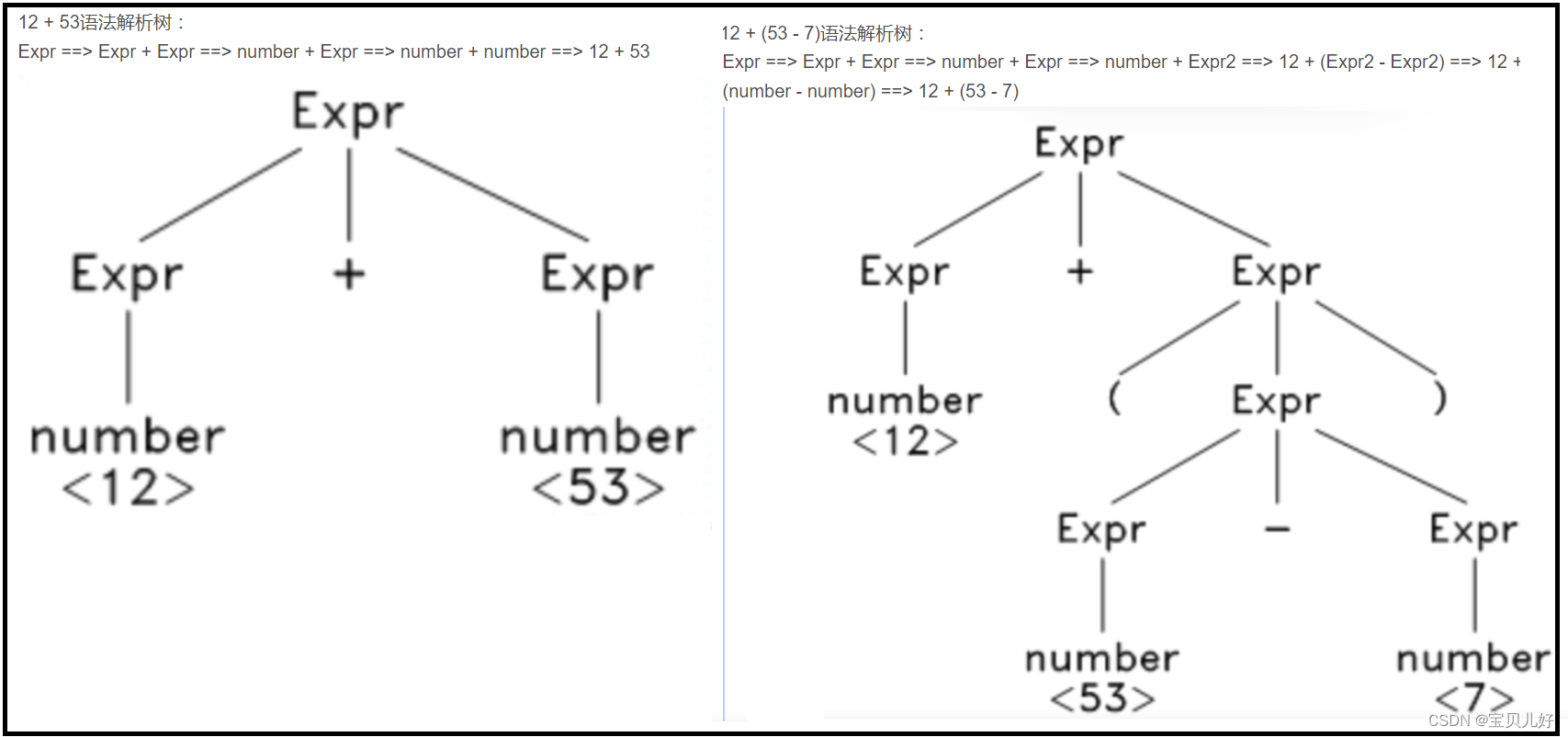
那我们上面的示例代码块对应的语法树就是: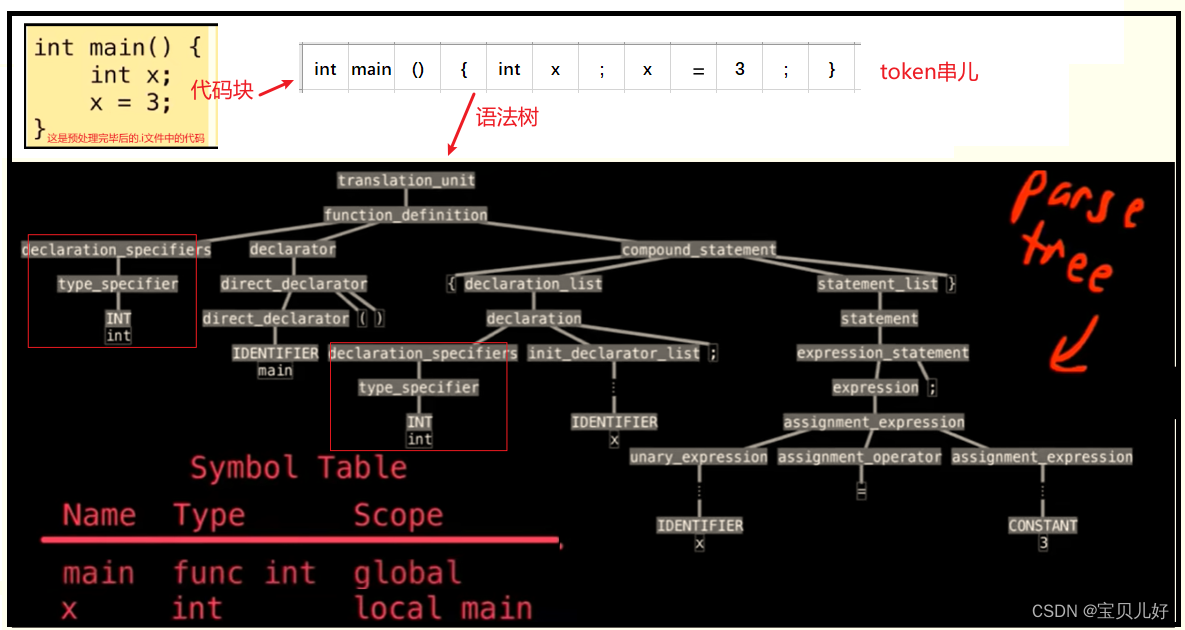
小结:我们是先规定一些文法(就是规定哪些是终结符,哪些是非终结符,并对非终结符都定义一个它自己语义的函数,比如+号有+号的函数,数字有数字的函数,小括号有小括号的函数),然后我们根据这些文法的定义,对token串进行校验与分析。如果这个token串中的token是终结符,那就是叶子节点,如果这个token是非终结符,那就递归的往下继续生成,直到叶子节点。如此便生成了一个语法树AST。
所以,语法分析树的作用就是让计算机理解了Token串的含义。后面只需要从叶子节点开始遍历这棵语法树,直到遍历到根节点,就是这个代码块的计算结果了!!!唉,我都出了一口。。。。
(3)语义分析(Semantic Analysis):
在语法结构正确的前提下,编译器进一步进行语义分析。语义分析是由语义分析器(semantic analyzer)完成的。
语义分析的作用:
一是上下文相关分析。比如检查类型、声明与使用是否匹配、函数调用和函数定义是否一致、作用域、访问控制信息等等,确保程序不仅结构上合法,而且在逻辑意义上也是正确的。
二是诊断错误。要尽可能地给出准确的、更多的错误信息,方便程序员定位错误。
三是中间代码生成(Internediate Code Generation)。也叫代码翻译,就是生成中间代码。而中间代码生成的过程也是对语法树AST的某种遍历。为了简化后续的优化和后端代码生成过程,编译器会生成一种与具体机器无关的中间表示形式,入三地址码、SSA形式等。
不同的编译器对中间表示的选择和设计各有不同,所以中间代码可以是一种真正的语言,也可以是由编译器的各个处理阶段共享的多个内部数据结构组成。我现在用的vs2022的中间编译文件就是.obj,你千万别尝试去打开看看,因为我尝试了,结果捯饬了好久都是编码问题,没法查看,而且把原来的打开方式也搞丢了,然而我有个每步操作就截图的习惯,所以在强迫症下,去vs2022安装文件里视图一个个文件去找那个小图标对应的程序文件,结果找到半夜眼花缭乱,唉声叹气的睡了。。。我之所以偏执的想打开是因为我看有人打开过,其实结果就是一行行0101数字,可惜我没能打开。。。 
语义分析模块是编译器中最庞大也最复杂的模块。水平有限只能探究到这里了。
总之,到此你脑子里要有一个大概流程,就是:
词法分析是让cpu明白我们人类写的.cpp文件中的每个单词、数字和标识;
语法分析是把这些单词数字标识连接起来,cpu明白了我们写的代码块;
语义分析就是让cpu明白我们代码块的外部的联系,比如代码中调用别的函数、或者是调用了外部文件的函数、或者引用了外部头文件等等这些"关系"。
这就是编译的过程。经过编译就生成了一颗AST树,这颗树就是我们人类代码的全部意思的另外一种表示形式。这就类似我要给对面另外一个人传达一个"我要吃饭"这个信号,我可以对他做个吃饭的动作(这个前提是他也知道这个动作是吃饭)、也可以给他传递一张小纸条,纸条上写"我要吃饭"(当然这个前提是他知道纸条是干什么的、纸条上的字得认识)、也或者我们已经约好了一个暗号,比如眨一下眼睛,我直接眨一下眼睛,对方就知道啥意思。那我们人类向cpu传递信息,也是这个道理,由于cpu和我们毫无共同背景,所以最好的信息传递方式就是约好暗号。那编译过程就是暗号的生成过程。
(4)代码优化:
代码优化属于编译器的后端技术,除了去掉一些冗余的操作,还有其他非常多的考虑,比如:
这些都考虑完毕就生成相应的汇编代码文件。这部分的原理我实在是讲不了了,下面我们只看看VS的编译器是如何优化的:
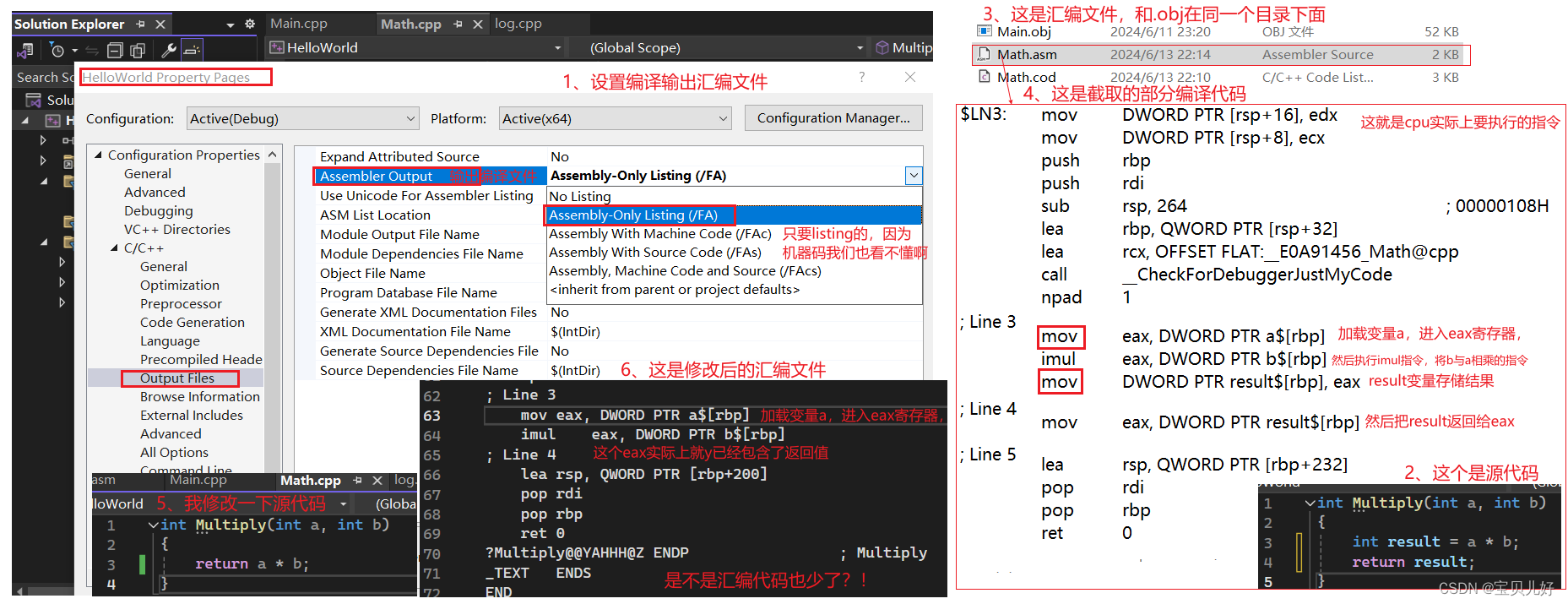
从上图可以看出源代码2和5,其汇编文件也是不同的。其中源代码2的汇编文件4里面有两个mov,就是mov了两次,那是因为我们创建了一个名为result的变量等于a*b,然后返回result,而不是直接返回a*b。这是完全不必要的,所以如果我们不把编译器设置为优化,你的代码就会很慢,因为你做了很多不必要的事情。
我们现在的编译器是debug模式,就是你源代码怎么写我就怎么编译,不会自动优化,下面我们设置为优化模式看看: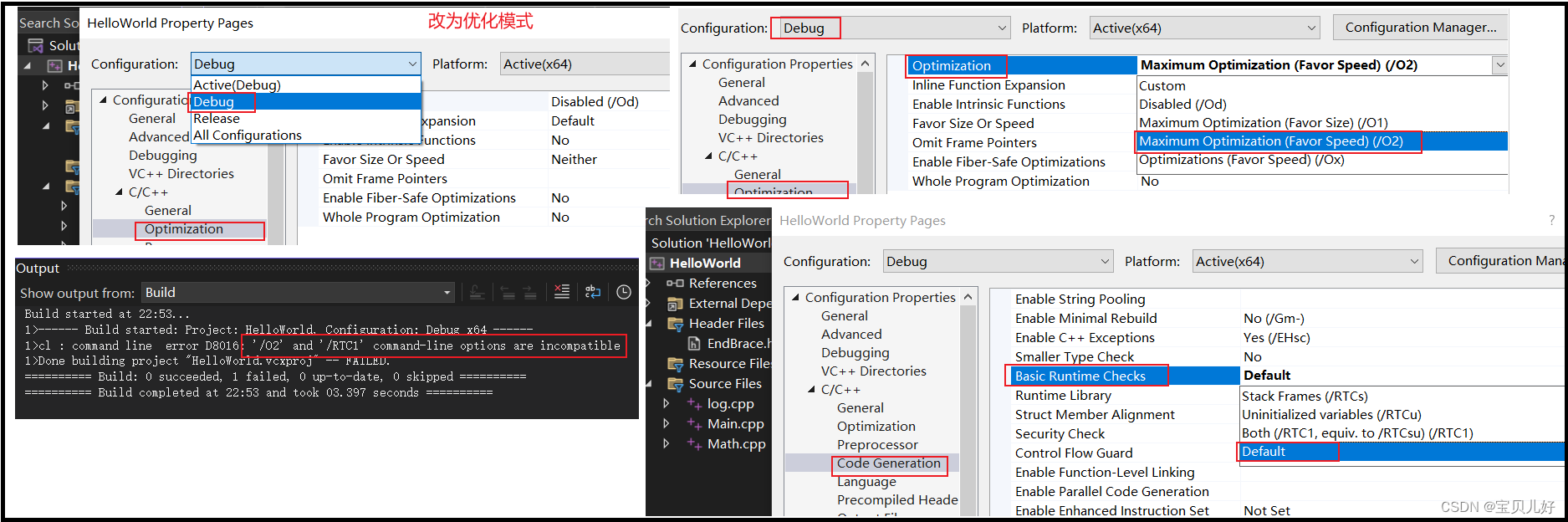
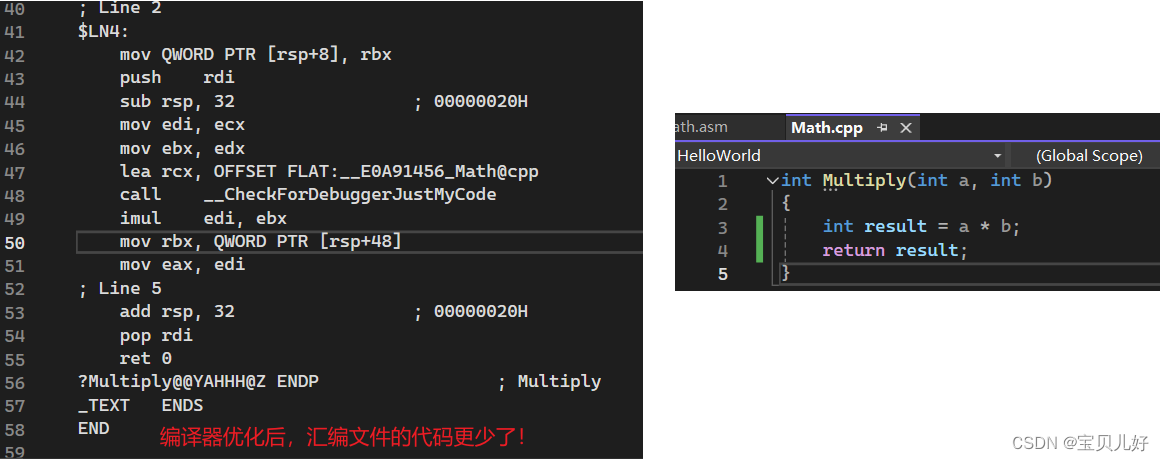
上面的词法分析、语法分析、语义分析以及优化都是编译compile阶段的内容。编译完毕后就生成相应汇编代码文件。
4、汇编(Assembler)
汇编代码文件进入汇编器,汇编器将汇编代码转变成二进制文件。就是生成目标机器上的代码,就是可执行二进制代码,也就是我们常说的机器码。
汇编器是将汇编代码转变成机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令。所以汇编器的汇编过程相对于编译器来讲比较简单,它没有复杂的语法,也没有语义,也不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译就可以了。所以汇编这一步也叫代码静态编译,很多资料都把这一步并入编译步骤里了。
5、链接Link
最开始我们提出翻译单元(translation unit) 这个概念时就说:
在C++中,文件翻译单元是指一个.cpp文件以及它包含的所有头文件组合到一起形成的单独的编译单元。每个.cpp文件在编译时都会生成一个翻译单元。每个.cpp文件都是一个翻译单元,一个翻译单元生成一个.exe文件。每个翻译单元之间是不交互的。
但是其实在实际开发中,即使我们只开发一个.cpp文件,这个文件里一般也会有预处理语句或函数调用等,这些都是这个文件的外部交互。再退一步讲,即使没有预处理语句或者函数调用,应用程序仍然还是得知道你的代码的入口点在哪里?换句话讲,就是你的main函数在哪里?进一步讲,实际中更多的情况是,为了解耦,我们还会特意把不同实现功能的.cpp文件放到不同的目录下,这种多个.cpp文件形成的项目,各个文件之间就更是需要交互了。
前面在语义分析时说过,语义分析就是标注这些外部联系的。就是语义分析不去真正的做外部链接这个动作,而仅仅是给你指出哪里需要链接,从哪里链接到哪里而已,就是仅仅标注出来而已。只有你调的函数存在不存在、参数对不对,语义分析器是不管的。
所以汇编完毕后生成的二进制文件,要想被执行,就也得要执行那些链接的语句,但是这些语句却还没有被真正的链接。所以链接器(Linker) 就是将二进制文件链接成一个可执行的命令,主要是把分散的数据和代码收集并合成一个单一的可加载并可执行的的文件。
链接可以发生在代码静态编译、程序被加载时以及程序执行时。
链接过程的主要工作是符号解析和重定位,直白的说就是找到每个符号和函数在哪里,并把它们连接起来。
(1)程序报错,是编译环节报错还是链接环节报错?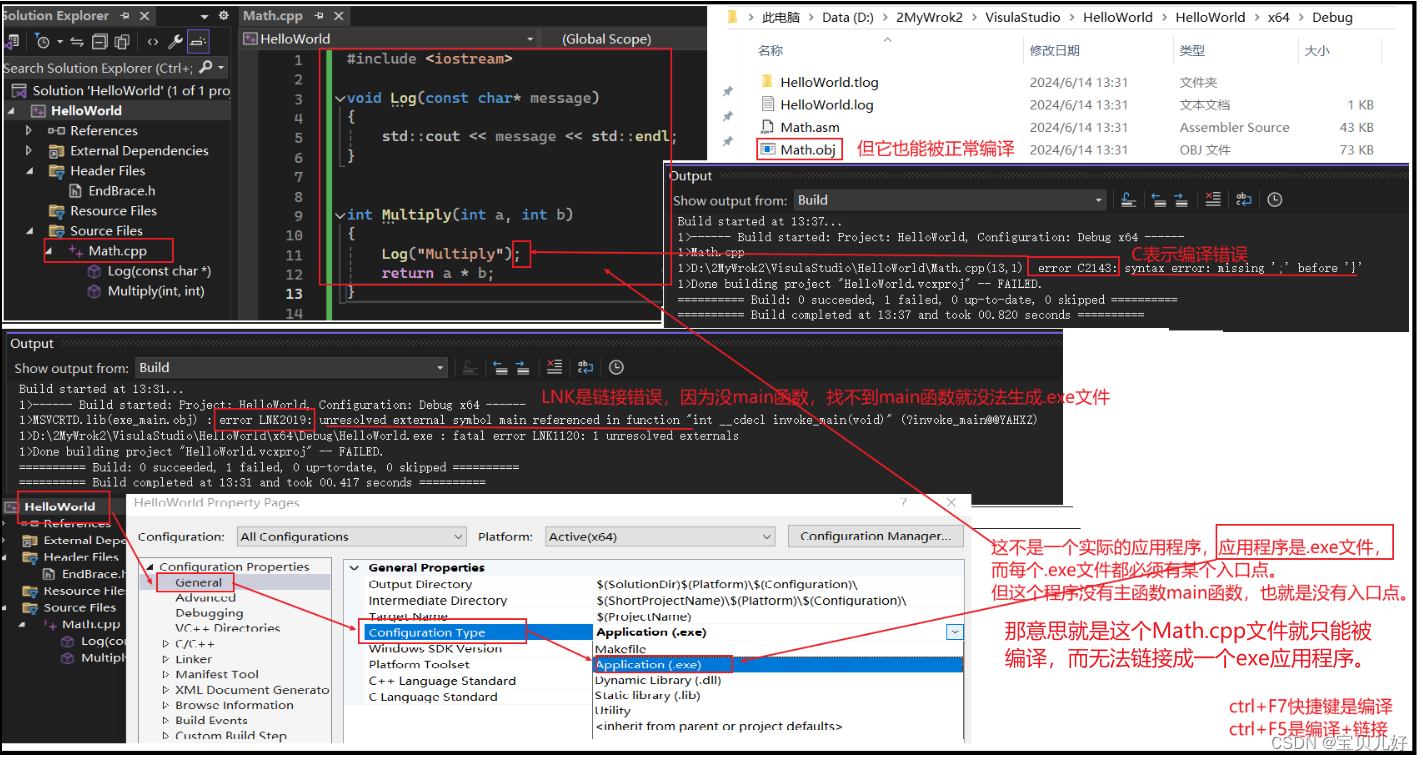
(2)文件和函数是怎样link的?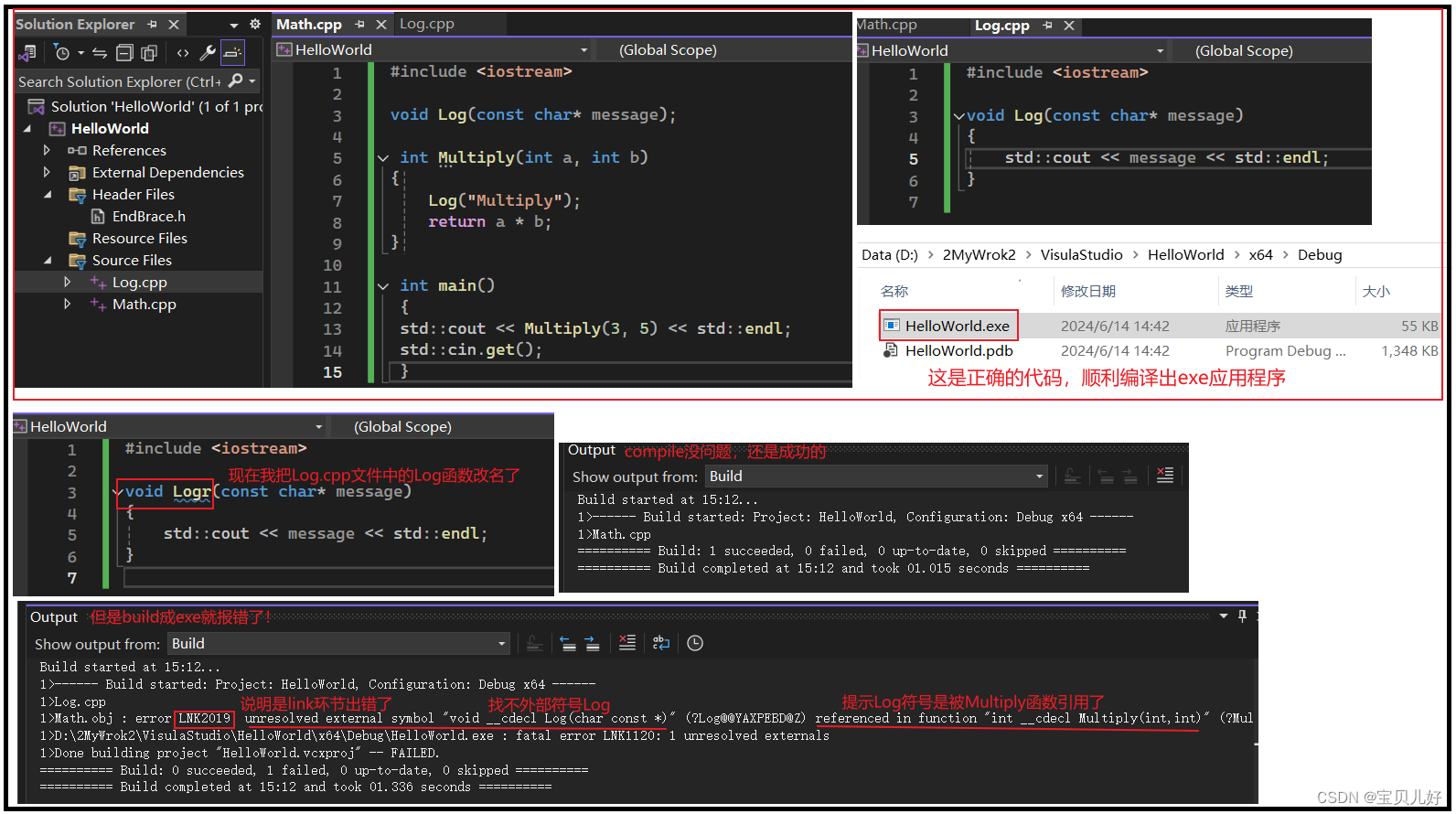
可见,link只链接需要调用的函数,不需要的函数就不会link了: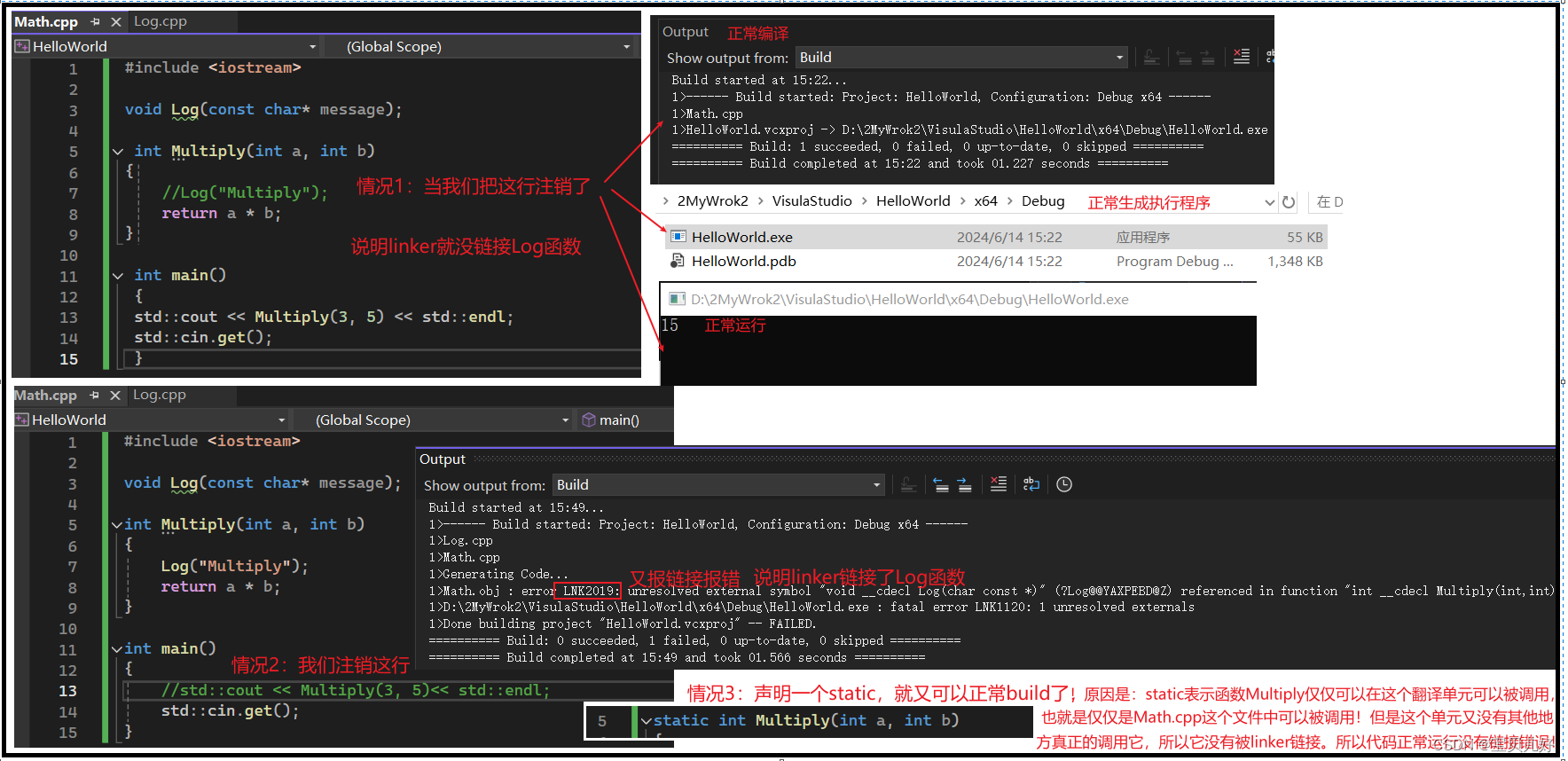
从上面的例子可以看出如果你把函数名引用错了,链接器就找不链接函数就会报错。其实同理,如果你把函数的参数、函数的返回值,只要有一个写错了,linker是都会找不到文件而报错的。所以链接是通过:函数名、参数、返回值三方面属性去寻找的。只要有一项不符合就报链接错误。
那也同理,如果存在两个函数的函数名、参数、返回值三个都相同的函数,链接器也是会报错的,因为它不知道链接哪个了。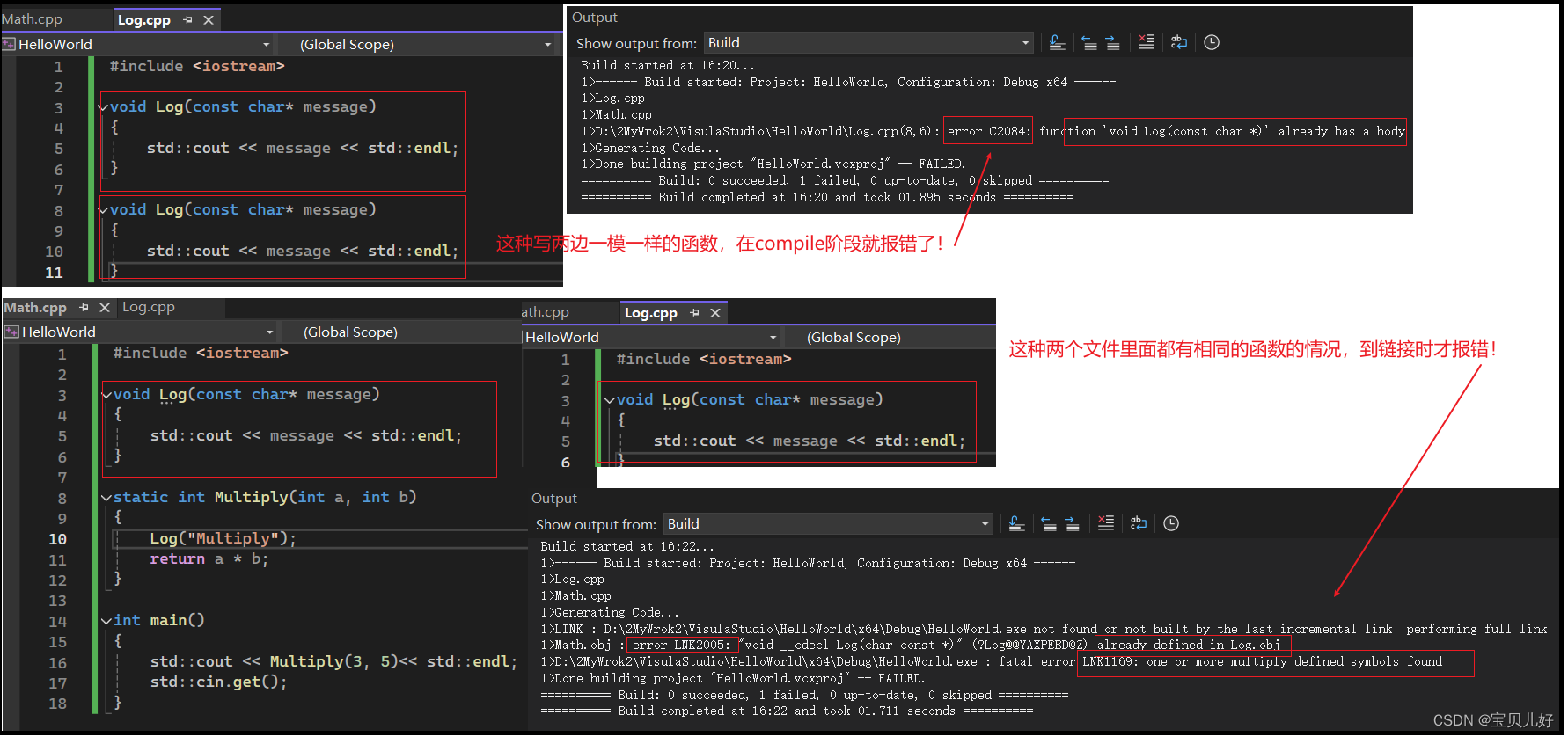
除此之外最容易引起Linker报错的就是预处理语句include了,看例子:
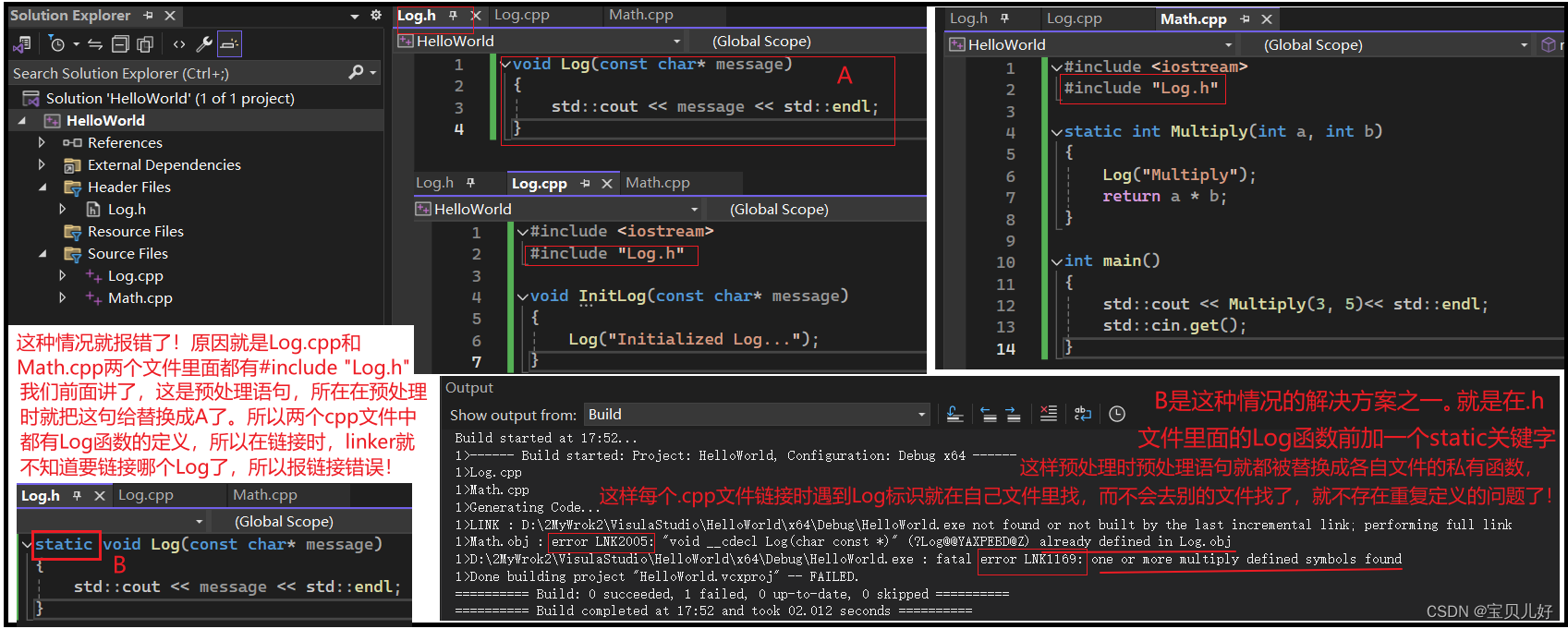
除了上图的添加static关键字方法,还有下面的inline方法:
也可以用下面这种方法规避: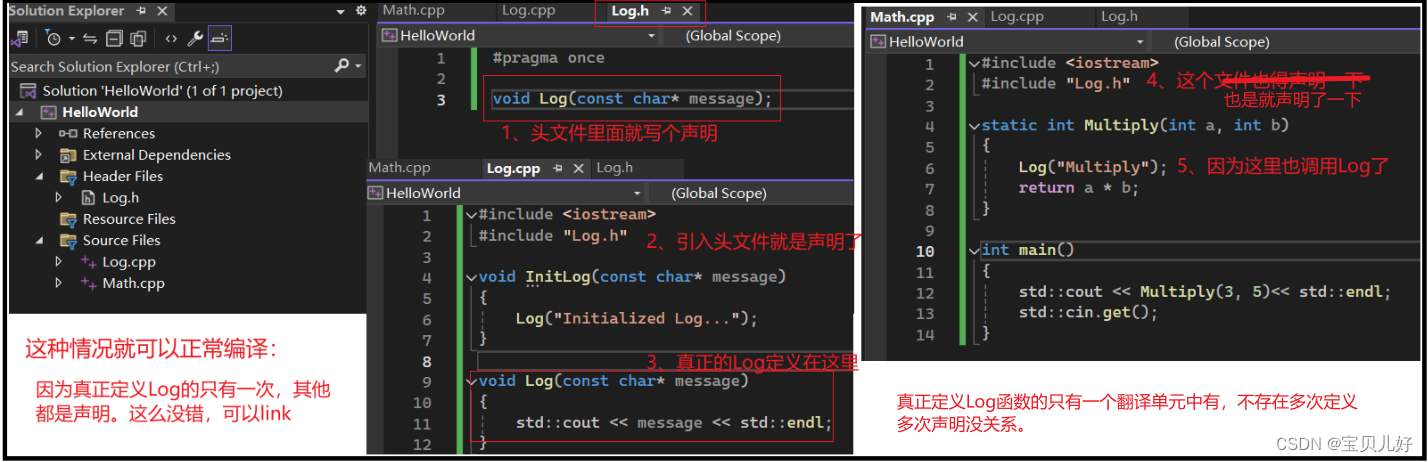
至此我们也只是讲了什么是链接、链接是如何工作的。实际上链接器Linker是要串联起我们所有的目标文件,包括代码中用到的任何其他库,比如C++运行的库、C++的标准库、平台的api等等很多其他的东西,这我们从预编译文件.i文件 和 汇编文件.asm文件中都可以窥其一斑。不同翻译单元的不同位置都可能出现链接。所以链接也是有很多类型的,比如静态链接和动态链接等等很多概念。水平有限,时间和精力也有限,这里就不继续了。















 3229
3229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









