







Abstract
背景: 当test和train使用相同的伪造类型时,detector具有卓越的性能,但是推广到未知的deepfake的能力仍然有限
总结:当前的detector面对未知方法的泛化性差
motivation: an ideal detector classifies any face that contains anomalies not found in real faces as fake,
检测器将那些包含真实面部所没有的异常的面部分类为fake,也就是说检测器应该去学习real face的一致性,而不是学习训练集中的fake patterns,尤其是学习到的fake patterns不一定适用于未知的伪造方法
论文解决办法:
- Real Appearance Modeling (RAM):从被轻微干扰的面部中恢复原来的面部,以此来学习真实的面部外观
- Face Disturbance:产生被扰动的人脸,同时保留原始信息以进行恢复,有助于模型学习真实的人脸的细粒度外观
一、Introduction
以前的工作:通过引导detector识别specific deepfake patterns(例如:boundaries in swapped faces、inconsistency、frequency anomalies、movement anomalies)来解决deepfake检测问题
但是,当它们遇到由新算法生成的deepfake时,性能会显著下降,原因是不同的deepfake算法会生成不同的fake patterns,模型在训练集上学习到的fake patterns不足以适用于所有的deepfake
虽然不同的deepfake存在不同的fake patterns,但是real face 保持一致性的外观,最好是学习真实面孔的外观来验证其真实性,而不是学习深度伪造模式来识别假视频,一个面部如果表现出在真实的面部中找不到的模式,理想的分类器会将其归类为假面孔
如何学习real face的一致性:在像素级预测真实的人脸,提出了:
- Real Appearance Modeling (RAM):从受干扰的人脸中恢复相应的原始人脸
对于RAM任务,Deepfakes不能用作训练数据,因为它们的原始身份或姿态被改变,并且使得能够预测的必要信息丢失。
- Face Disturbance:disturb real faces to pseudo-fakes as training data
在Face Disturbance产生的扰动人脸中,原始信息大部分被保留。
图片可以看作是由Texture and Structure组成的,因此Face Disturbance包含两部分:
-
纹理扰动(Texture Disturbance):纹理扰动通过扰动局部纹理产生纹理不一致的异常。选择局部扰动而非全局扰动的原因在于:真实纹理的分布是多样的,全局修改可能无法有效制造异常。而在面部不同区域之间形成不一致的纹理本身就是一种异常。因此,纹理扰动被设计用来生成这样的不一致性。
-
结构扰动(Structure Disturbance):结构扰动通过覆盖面部关键区域(包括面部特征和边界)来扰动结构。这些区域是面部结构的重要组成部分。具体的覆盖方法是将周围的纹理复制并平铺到被扰动区域,以确保原始纹理保持完整。
无监督学习:RAM使用由Face Disturbance产生的干扰人脸作为输入,原始人脸作为预测目标,在训练中,真实面部和被扰动面部用作输入,要求检测器既能够区分被扰动的面部,又能够恢复其真实外观。
RAM通过以下方式引导detector恢复结构和纹理异常:
- 结构异常:利用未扰动的面部区域作为参考,恢复被扰动区域的结构。
- 纹理异常:基于面部外部区域的纹理恢复内部区域的纹理。
贡献总结:
- Real Appearance Modeling:
- Face Disturbance
二、Related Work
2.1 Deepfake Detection
早期的工作利用生物学特征,例如失真的瞳孔 [11]、心跳频率 [12] 和异常的头部姿态 [13],进行深度伪造检测。
近年来,许多研究将深度伪造检测视为一个二分类任务,重点在于检测特定的深度伪造模式。例如,[14] 探讨了浅层网络中的中尺度特征,这些特征包含丰富的信息;[15] 则引入注意力机制结合了 RGB 和纹理特征。[6,16] 使用离散余弦域的高频信息作为补充模态。
另一个方向是使用代理任务进行预训练,以学习能够识别deepfake视频的高级表示。这种代理任务的例子包括唇读[8]和视听对比学习[17,18]。
最近,无监督学习对象MAE [19]被引入深度伪造检测[20,21]。MAE主要通过遮掩输入图像的一部分,然后训练模型恢复这些被遮掩的区域,在深度伪造检测中,MAE 的输入是被遮掩的面部图像,而恢复目标是完整的原始面部图像。由于遮掩的区域信息丢失,恢复任务可能存在多个合理的解决方案,例如在不同光照条件或背景下恢复不同细节,这种特性被称为“病态问题”(ill-posed problem),即问题缺乏唯一解。
RAM 的输入是扰动后的面部图像(例如,通过人为扰乱结构或纹理生成的“伪伪造”样本),目标是恢复图像的真实外观(未被扰动的原始图像)。相比 MAE,RAM 中的扰动是人为可控的,且每个扰动图像对应唯一的恢复目标,因此不存在不确定性,也不是一个病态问题。
与MAE相比,RAM在监督检测器以模拟真实的面部外观方面更细粒度。
2.2 Pseudo-fakes for Deepfake Detection
一些研究 [1,2,4,22–24] 提议构建Pseudo-fakes进行训练。由于伪伪造样本中引入的伪造模式是可控的,检测器可以准确地学习先验模式。例如,[1] 引入模糊到面部内部以复制清晰度不一致;[2,4,22] 混合两个具有相似面部标志的面部以生成纹理不一致。此外,[23,24] 通过增强技术在单个面部内产生不一致性,从而实现良好的泛化性能。
尽管这些方法在面部交换(face swap)深度伪造上表现出色,但当面对由重演算法 [25,26] 或扩散模型 [27] 生成的深度伪造时,其性能会下降,因为这些伪造类型中纹理不一致不再是主要伪造特征。
三、Method
3.1 Face Disturbance
Pseudo-fakes方法的局限性:
之前的方法主要通过引入**纹理不一致性(texture inconsistency)**来生成Pseudo-fakes。这种方法模拟的是 面部交换型深度伪造(face swap deepfakes) 的常见模式,但其在reenactment deepfakes上表现不佳,原因在于reenactment deepfakes通常保持纹理的完整性,引入Structure Disturbance
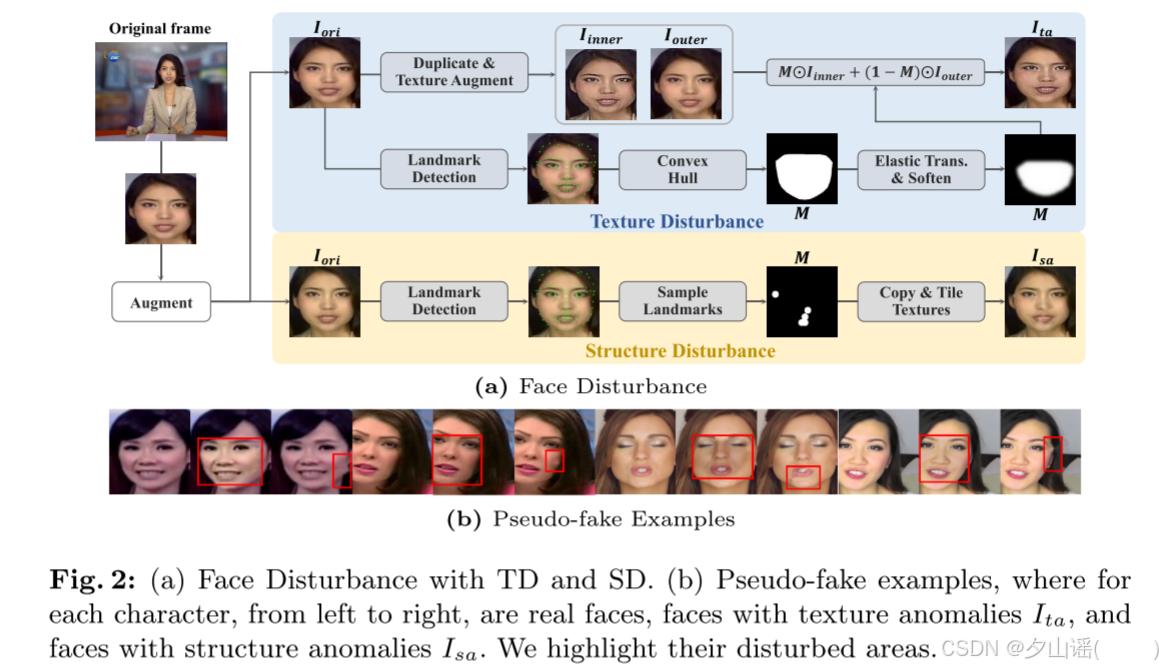
3.1.1 Texture Disturbance
目标:produce texture anomalies,产生纹理异常
检测texture anomalies的依据:人脸的真实纹理具有多样性,因此需要一个参考区域,作为标准,用来判断其他区域的纹理是否异常。
现有方法:
- Face Blending:using two face,将两张人脸进行混合
SBI不是使用1张人脸吗?
- Partial Augmentation:using one face,使用同一张面部图像,通过图像增强技术扰乱内区域或外区域的纹理,制造局部的纹理异常。
优势:
- 保留了原始面部的身份信息。
- 避免检测器过拟合于训练集中特定的身份特征,提升了泛化能力
texture disturbance过程
texture disturbance方法:类似于局部增强,通过输入图像的内区域和外区域的不一致纹理来创建纹理异常
- 输入图像 I o r i I_{ori} Iori被复制为两个版本: I i n n e r I_{inner} Iinner 和 I o u t e r I_{outer} Iouter,分别表示内区域(面部)和外区域(背景)
- 其中一个图像会被增强(augmented),增强包括颜色、亮度和清晰度的变动。
- 两个图像
I
i
n
n
e
r
I_{inner}
Iinner和
I
o
u
t
e
r
I_{outer}
Iouter 使用一个掩码
M
M
M 进行融合:
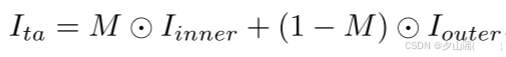
- ⊙ 是Hadamard乘积(逐元素相乘)
- I t a I_{ta} Ita 是最终融合生成的具有纹理异常的图像
- Mask的生成与处理:
- 使用landmark detector检测面部关键点
- 计算面部区域的凸包(convex hull),作为初始掩码𝑀
- introduce random deformations to M using a 2D elastic transformation:通过引入随机变形来改变面部区域的形状
- soften M from a binary mask into a soft mask with Gaussian Blur:原本的二值掩膜(即只有 0 和 1 的掩膜)会通过高斯模糊处理,使得掩膜边缘更加平滑、自然,使得融合后的图像 I t a I_{ta} Ita边界自然。
3.1.2 Structure Disturbance
目标:在保持纹理完整的前提下,针对结构元素(如面部边界、眼睛、嘴巴等)引入结构异常,从而补充纹理异常
扰动面部结构:
- 面部结构的关键元素包括面部边界和特征(眼睛、嘴巴等),而这些特征往往可以通过面部关键点(landmarks)定位。
- 为了不破坏原始纹理,使用复制和拼贴操作将周围的纹理填充到某些关键点附近的区域内。
- 通过这种方式:原始的纹理得以保留;被填充区域的原始结构被消除,从而形成异常。
Structure Disturbance过程
- 对输入面部图像 I o r i I_{ori} Iori ,首先检测其面部关键点。
- 随机选取部分关键点,并在这些关键点周围绘制圆形掩码𝑀 来定义扰动区域。
- 避免选择对称位置的关键点,从而使检测器可以利用对称区域的结构信息进行学习。
- 使用Fast Marching Method 将周围区域的纹理复制并拼贴到掩码区域,消除原始区域的结构信息,从而形成异常。
FMM是一种非学习型的图像修复算法,与其他方法相比,能够生成更清晰的纹理,并减少模糊。
3.2 Real Appearance Modeling
Real Appearance Modeling(RAM) task:将由Face Disturbance产生的异常面部区域恢复到其原始外观
任务定义:
- 输入真实人脸 I o r i I_{ori} Iori,经过FD干扰后,产生具有texture anomalies的 I t a I_{ta} Ita和具有structure anomali的 I s a I_{sa} Isa
- I o r i I_{ori} Iori、 I t a I_{ta} Ita、 I s a I_{sa} Isa送到网络中用于分类和densely real appearance recovery
- pseudo-fakes are 1,real faces are 0
- 在RAM中, I t a r g e t I_{target} Itargetfor I s a I_{sa} Isa is I I I, I t a r g e t I_{target} Itargetfor I t a I_{ta} Ita is I o u t e r I_{outer} Iouter
我认为 I t a r g e t I_{target} Itargetfor I s a I_{sa} Isa is I o r i I_{ori} Iori
I t a I_{ta} Ita是从 I o u t e r I_{outer} Iouter、和 I i n n e r I_{inner} Iinner两个中导出的,因此有两个潜在的恢复目标,论文这里将目标固定为 I o u t e r I_{outer} Iouter,这允许模型使用来自 I o u t e r I_{outer} Iouter的背景纹理作为参考来恢复内部纹理,引导模型将内部纹理与外部纹理对齐。
- 将pseudo-fakes恢复为original faces的可行性在于:pseudo-fakes包含了对应original faces的所有信息,只有内部和外部人脸区域之间的变化或部分结构被破坏。
3.3 Recovery Autoencoder
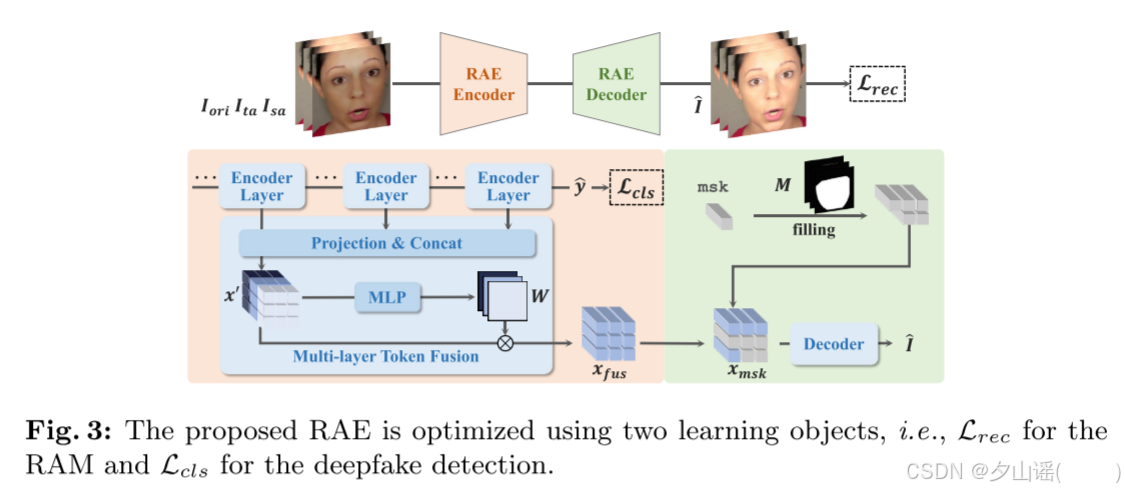
为了同时执行detection and RAM,模型框架加入了a classification head 和 a dense prediction head,命名为RAE(Recovery Autoencoder)
- Encoder:Vision Transformer Base (ViT Base)
- Decoder:eight transformer layers and a linear projection layer
- Multi-layer Token Fusion (MTF) block: extract features from both the shallow and deep encoder layers,同时从深层和浅层encoder中提取特征。
- Encoder处理:
- 输入图像 I ∈ R H × W × 3 I \in \mathbb{R}^{H \times W \times 3} I∈RH×W×3输入到ViT编码器后,它会在每一层中被提取为Token序列 x l ∈ R ( N + 1 ) × D x^l \in \mathbb{R}^{(N+1) \times D} xl∈R(N+1)×D,其中:
- l ∈ { 1 , 2 , ⋯ , L } l \in \{1, 2, \cdots, L\} l∈{1,2,⋯,L}是编码器层的索引。
- L = 12 L=12 L=12表示编码器的深度。
- N 是图像块(patch)的数量。
- D 是embedding dimension
- 分类任务
- 编码器的每一层会生成一个特殊的CLS(分类)Token x L [ 0 ] x_L[0] xL[0]
- 它被输入到一个线性层和softmax操作中,生成类别概率 y ∈ R 2 {y} \in \mathbb{R}^2 y∈R2。这里的“2”类别的数量(真实/伪造)
- RAM任务:
编码器生成的其余Token x l x^l xl 会被重塑为形状 R h × w × D {R}^{h \times w \times D} Rh×w×D,其中 h = w = N h = w = \sqrt{N} h=w=N
这些Token随后输入到MTF模块进行跨层Token融合,接着送入解码器完成RAM任务。
- MTF:
- ViT有12层,直接将所有层的输出输入到MTF会导致计算开销过大。
- 选择等间隔的3层作为MTF的输入,分别提供浅层、中层和深层特征。(可能是:4、8、12),记为 x s x_s xs(浅层)、 x m x_m xm(中层)和 x d x_d xd(深层)。
- 特征对齐:在MTF中,首先将 x s x_s xs、 x m x_m xm和 x d x_d xd投影到相同的特征空间,并将它们拼接成 x ′ ∈ R S × h × w × D x' \in \mathbb{R}^{S \times h \times w \times D} x′∈RS×h×w×D,其中 S = 3 S = 3 S=3 是选定的层数。
跨层注意力机制:为了进一步融合来自不同层的结构和纹理信息,MTF使用多层感知机(MLP)预测每个Token的权重 W ∈ R S × h × w W \in \mathbb{R}^{S \times h \times w} W∈RS×h×w。这些权重通过softmax在第一个维度 S 上归一化,确保同一空间位置上各层的权重和为1。- 融合特征:利用 W W W 对跨层特征加权后生成融合Tokens x fus ∈ R h × w × D x_{\text{fus}} \in \mathbb{R}^{h \times w \times D} xfus∈Rh×w×D。
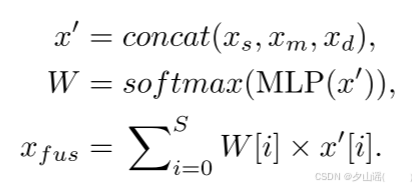
- RAM,从融合特征 x fus x_{\text{fus}} xfus恢复真实人脸
避免易挖掘问题:
- 输入的伪造脸和目标真实脸在未扰乱区域( 1 − M 1-M 1−M)是相同的,在扰乱区域( M M M)是相似的。如果直接将 x fus x_{\text{fus}} xfus输入解码器,模型可能倾向于简单地复制输入的伪造脸。
- 为避免这种情况,引入了可学习的msk Token来替代被扰乱区域的Tokens。
掩码策略
- 给定一个二进制mask M p a t c h M_{patch} Mpatch,将其划分为mask patches m ∈ R h × w × p × p m \in \mathbb{R}^{h \times w \times p \times p} m∈Rh×w×p×p, p p p是patch的边长
- 如果图片某个区域被扰乱,对应区域的Token会被替换为msk token
Decoder
- 替换后的Tokens x msk ∈ R h × w × D x_{\text{msk}} \in \mathbb{R}^{h \times w \times D} xmsk∈Rh×w×D 加入位置编码后输入解码器,生成重建的特征 x ^ ∈ R N × p × p × 3 \hat{x} \in \mathbb{R}^{N \times p \times p \times 3} x^∈RN×p×p×3。
- 最终,通过reshape恢复为重建图像 I ^ ∈ R H × W × 3 \hat{I} \in \mathbb{R}^{H \times W \times 3} I^∈RH×W×3,其中 H = W = N × p H = W = \sqrt{N} \times p H=W=N×p
3.4 Loss Function

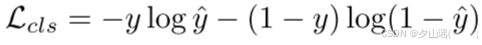
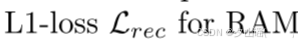
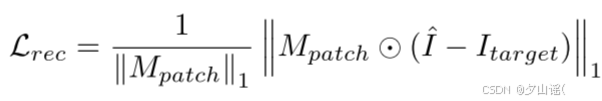
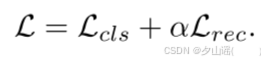

4 Experiments
4.1 Implementation Details
Dataset: FaceForensics++ (FF++), Celeb-DF v2 (CDF) , DFD , DFDC ,DFDC preview (DFDCp) , and WildDeepfake (WDF),对于DFDC,为了避免标签噪声,只使用出现一张人脸的视频。
Preprocess: 训练时,从每个视频中以相等的时间间隔提取10帧,测试时,每个视频提取32帧,使用Retinaface 裁剪面部,在每个面部周围保持15%的边缘,利用Dlib为每张脸提取81个面部标志点。
Face Disturbance Details:
- 生成 I t a I_{ta} Ita所用到的增强方式:使用RGBShift、HueSaturationValue、RandomBrightnessContrast、Downscale、Sharpen增强 I i n n e r I_{inner} Iinner、 I o u t e r I_{outer} Iouter其中的一个。
- 生成 I s a I_{sa} Isa:随机选择2到6个标志点,画圆,半径在边长的1/14到1/16之间采样
- 图像大小调整为224×224作为输入
Training Details:
- ViT Base
- SAM
- learning rate of 8e-4
- batch size of 192,96 real faces, 48 disturbed faces with texture anomalies, and 48 disturbed faces with structure anomalies
- 100 epochs
- cosine decay
- 60GB of GPU memory
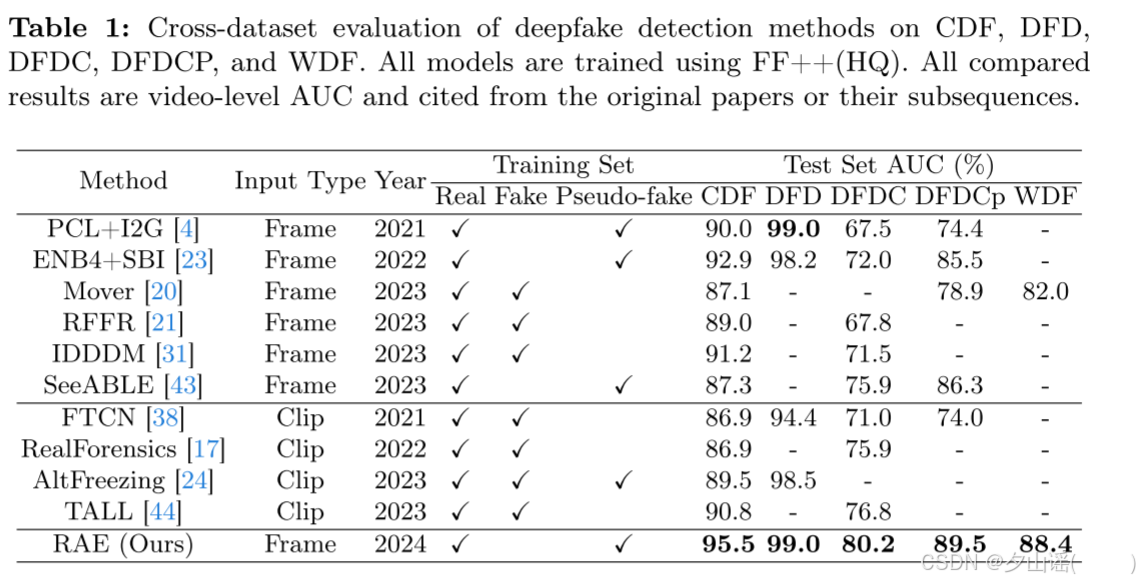
4.2 Cross-Dataset Evaluation
- trained using faces in FF++(HQ)
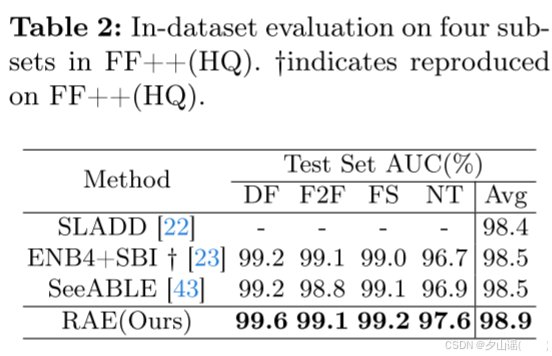
4.3 In-dataset Evaluation
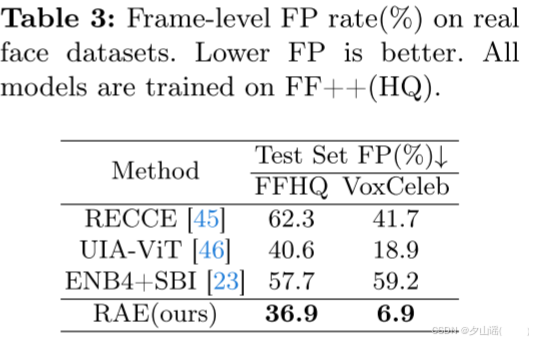
4.4 Evaluating RAE on Real Face Datasets
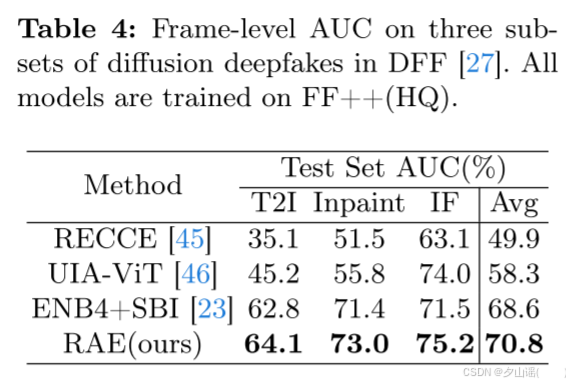
4.5 Evaluation on Diffusion Deepfakes
4.6 Ablation Study
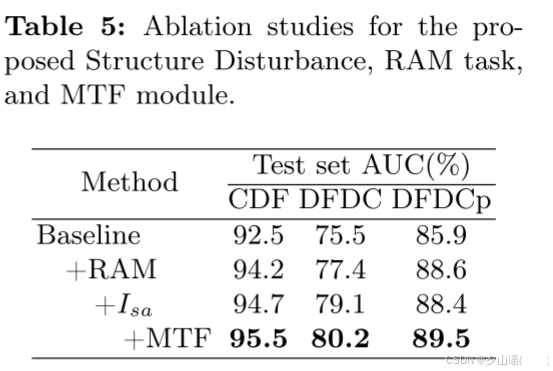
4.7 Visualization

- 每一行分别为受干扰面部、对应的原始面部、受干扰面部区域的mask以及恢复的面部
- 模型成功地恢复了大多数异常面部的扰乱区域。尽管恢复的面部并不十分清晰,但异常的模式大多被消除。
- 结构异常的恢复:对于存在结构异常的面部,扰乱区域被精细地恢复为其原始结构外观。
- 纹理异常的恢复:对于纹理异常,内部面部的纹理模式被调整为正常的外观。
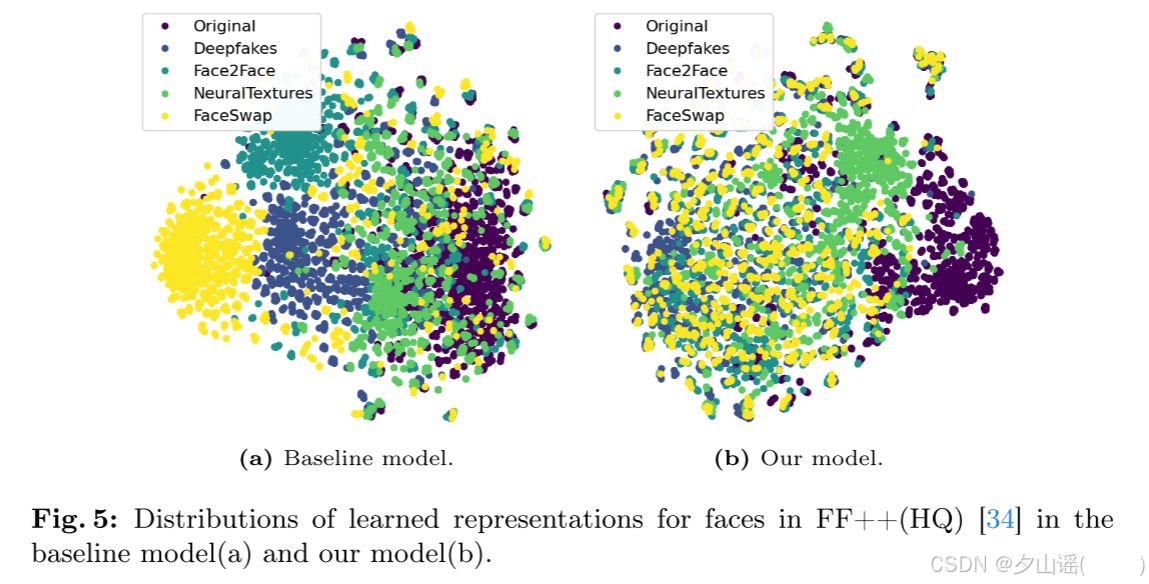
- ViT Base作为baseline,并在FF++(HQ)中使用real和fake来训练它。
- 利用训练好的RAE和baseline对FF++(HQ)的测试集进行特征提取
- baseline学习每个deepfake算法的特定特征
- RAE算法将真实的人脸聚集到一个紧凑的簇中,混合了不同类型的deepfake,证实了RAM有助于学习一般的deepfake表示,表明它是基于学习到的一般伪造模式来对deepfake进行分类。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









