






这里主要是通过搭建一个yolo,实现在仿真中识别椎筒。
基于yolov5的识别算法
安装anaconda
这个我之前写过,链接
安装好后注意额外禁用一个conda默认环境:
conda config --set auto_activate_base false
然后再去安装一下自己用的比较熟悉的代码IDE,比如vscode或者pycharm

数据集制作
新建文件夹VOCData并进入,里面新建images(存放原始jpg文件),Annotations(存放标注图片后的内容).其他文件先不要管!

收集实际数据
rosbag record <camera_topic>
解析bag包
sudo apt - get install ros-noetic-image-view
rosrun image_view extract_images image:=<your topic>
rosbag play <bag file>
这里提供其他的一些工具程序.
1.将bag话题数据转换为png文件(也需要播放bag)
#!/usr/bin/env python
import rospy
from sensor_msgs.msg import Image
from cv_bridge import CvBridge
import cv2
class ImageSaver:
def __init__(self):
self.bridge = CvBridge()
self.last_save_time = rospy.Time(0)
self.save_interval = rospy.Duration(1.0) # 1秒间隔
self.image_counter = 0
# 订阅图像话题
self.image_sub = rospy.Subscriber(
'/camera/image_raw',
Image,
self.image_callback,
queue_size=1
)
rospy.loginfo("Image saver started. Saving images every 1 second.")
def image_callback(self, msg):
current_time = rospy.Time.now()
# 检查是否达到保存时间间隔
if (current_time - self.last_save_time) >= self.save_interval:
try:
# 转换图像格式
cv_image = self.bridge.imgmsg_to_cv2(msg, "bgr8")
# 生成文件名 (包含时间戳和计数器)
timestamp = current_time.to_sec()
filename = f"image_{timestamp:.6f}_{self.image_counter:04d}.png"
# 保存图像
cv2.imwrite(filename, cv_image)
rospy.loginfo(f"Saved image: {filename}")
# 更新时间和计数器
self.last_save_time = current_time
self.image_counter += 1
except Exception as e:
rospy.logerr(f"Error saving image: {e}")
if __name__ == '__main__':
rospy.init_node('image_saver')
ImageSaver()
rospy.spin()
2.将视频转为png
## 方法1:
import cv2
# 打开视频文件
cap = cv2.VideoCapture('video1.mp4')
# 设置保存图片的文件夹路径
folder = 'frames/'
# 读取并保存每一帧
count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame_name = folder + f'frame_{count:04d}.jpg' # 设置保存文件名,例如 frame_0000.jpg
cv2.imwrite(frame_name, frame) # 保存图片文件
count += 1
# 释放资源
cap.release()
3.修改文件扩展,按照顺序重新排序
import os
# 配置参数(修改此处)
folder_path = "./images" # 文件夹路径
old_ext = ".png" # 原文件扩展名(带点,如 ".jpg")
new_ext = ".png" # 新文件扩展名(带点,如 ".png")
# 切换到目标文件夹
os.chdir(folder_path)
# 获取所有指定扩展名的文件(不区分大小写)
files = [f for f in os.listdir() if f.lower().endswith(old_ext.lower())]
# 按文件名字母顺序排序
files.sort()
# 批量重命名
for i, old_name in enumerate(files, start=1):
# 拆分文件名和扩展名(处理可能的大写扩展名)
name, ext = os.path.splitext(old_name)
new_name = f"{i}{new_ext}" # 生成新文件名
os.rename(old_name, new_name) # 重命名
print(f"重命名:{old_name} -> {new_name}")
print(f"完成!共重命名 {len(files)} 个文件")
下载labelimg标注软件:
pip install labelimg
终端输入labelimg进入标注软件

点view选择自动保存模式,然后选择文件夹位置

默认格式是xml(即是pascalVOC),也可以改成yolo。
接着就是愉快的标注时间(标注和图片下一张等应该是有键盘快捷键的):
Ctrl + s | 保存 |
| Ctrl + d | Copy the current label and rect box |
| Space | 标记当前图片已标记 |
| w | 创建一个矩形 |
| d | 下一张图片 |
| a | 上一张图片 |

标注结束后,划分数据集以及配置文件修改
在VOC文件夹下新建一个split_train_val.py并运行:
python split_train_val.py
这是为了划分训练集、验证集、测试集
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.9 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
生成一个ImageSets/Main文件,其中包含:

由于保存的是xml格式,这里再对格式进行一下转换,成yolo能看懂的格式
新建一个xml_to_yolo.py文件
这里会生成labels和dataSet_path文件夹,注意修改路径。其中labels存放yolo能看懂的格式,dataSet_path存放数据集的txt文件,主要是test.txt,train.txt,val.txt这三个转换后的文件。
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["red", "blue", "yellow"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def get_image_extension(image_id):
"""获取图像文件的真实后缀"""
# 方法1: 从XML文件中读取filename标签
try:
xml_path = os.path.join('./Annotations/', f'{image_id}.xml')
tree = ET.parse(xml_path)
root = tree.getroot()
filename = root.find('filename').text
_, ext = os.path.splitext(filename)
if ext:
return ext # 返回带点的后缀,如.jpg
except:
pass
# 方法2: 检查images目录下的文件
image_dir = './images/'
for ext in ['.jpg', '.jpeg', '.png', '.bmp', '.JPG', '.JPEG', '.PNG', '.BMP']:
if os.path.exists(os.path.join(image_dir, f'{image_id}{ext}')):
return ext
# 默认返回.jpg
return '.jpg'
def convert_annotation(image_id):
in_file = open('./Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('./labels/'):
os.makedirs('./labels/')
if not os.path.exists('./ImageSets/Main'):
os.makedirs('./ImageSets/Main')
image_ids = open('./ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
if not os.path.exists('./dataSet_path/'):
os.makedirs('./dataSet_path/')
# 这行路径不需更改,这是相对路径
list_file = open('dataSet_path/%s.txt' % image_set, 'w')
for image_id in image_ids:
# 获取真实后缀并写入
ext = get_image_extension(image_id)
list_file.write(f'./images/{image_id}{ext}\n')
convert_annotation(image_id)
list_file.close()
回到yolov5文件夹下,
在data文件下新建一个myvoc.yaml

需要书写的是:
train: /home/cyun/Documents/formular_ws/VOCData/dataSet_path/train.txt
val: /home/cyun/Documents/formular_ws/VOCData/dataSet_path/val.txt
# number of classes
nc: 3
# class names
names: ["red", "yollow", "blue"]
这里我自己的数据集所用的是:

到此为止,数据集的相关内容就完全做好了。
配置环境
安装nvidia驱动
sudo ubuntu-drivers devices
sudo ubuntu-drivers autoinstall
nvidia-smi
安装cuda
这里推荐11.8的版本,安装教程请参考之前写的即可.
配置python环境
接下来正式开始:
下载好yolov5
下载网址:https://github.com/ultralytics/yolov5
我们先建立一个conda的虚拟python环境
conda create -n yolov5 python=3.8
conda activate yolov5
cd yolov5
pip install -r -requirements.txt
# 注意,需要适应自己的cuda的版本,如果是cuda-11.8的话,执行完后再重新安装一下
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
这样之后:
接下来就按照它的readme执行就好了:
注意,需要先下载一个weights权重文件,官方里面就有:

下载了放在yolo文件目录下。
训练模型
修改模型配置文件:
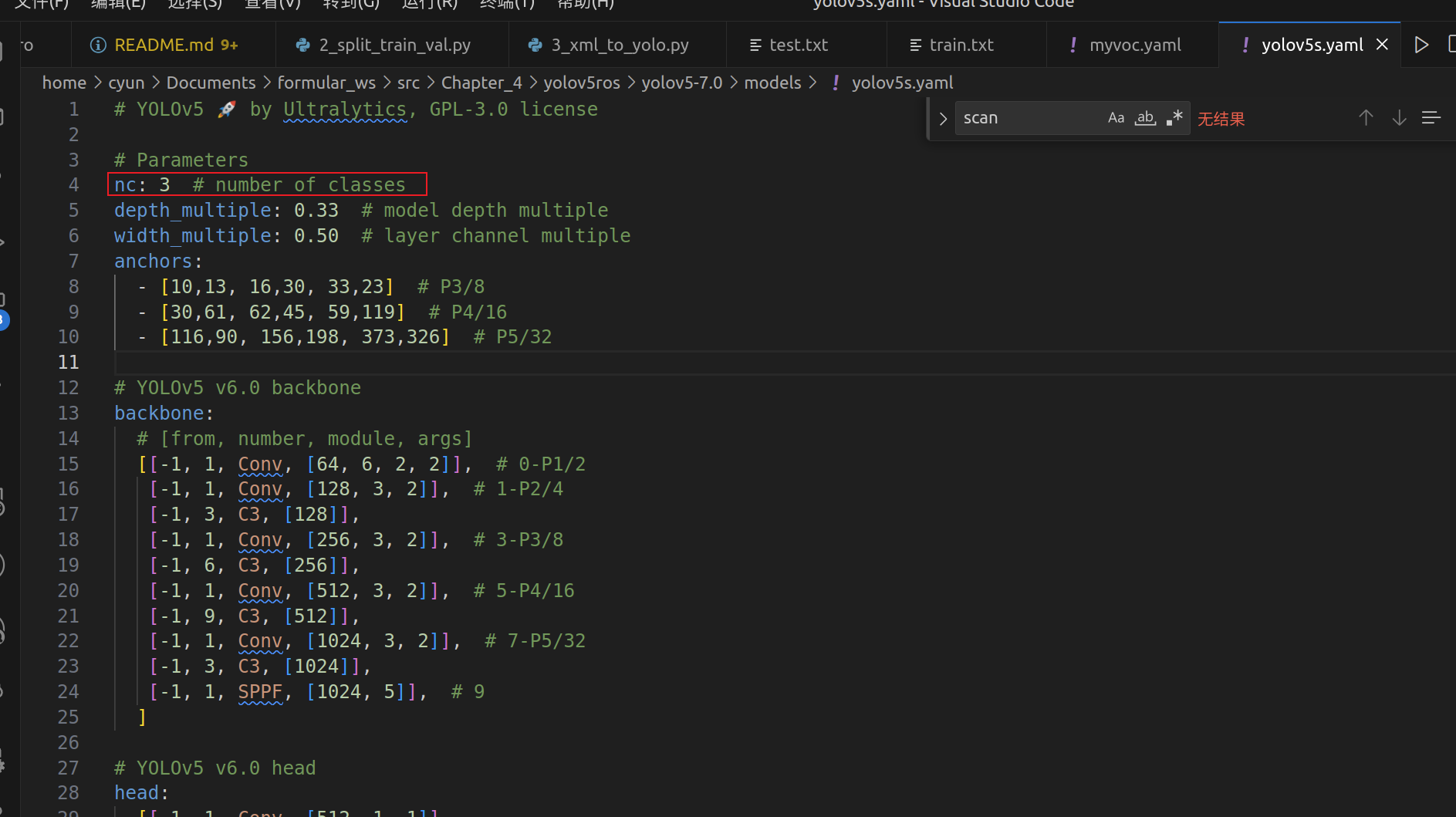
这里以yolov5s.yaml为例,打开文件

这里就把nc设置成自己的类别数目就好了。
开始训练,训练的代码:
python train.py --weights yolov5s.pt --cfg models/yolov5s.yaml --data data/myvoc.yaml --epoch 200 --batch-size 8 --img 640 --device 0
如果是cpu,那就--device cpu
python detect.py --weights runs/train/exp/weights/best.pt --source ../source/test.png
python detect.py --source 0 # webcam 自带摄像头
file.jpg # image 图片
file.mp4 # video 视频
path/ # directory
path/*.jpg # glob
'https://youtu.be/NUsoVlDFqZg' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
然后就能识别了,其中…/ 代表当前目录的上一级目录
注意,训练时或者训练后可以利用 tensorboard 查看训练可视化:
在yolov5文件夹下,运行
tensorboard --logdir=runs
测试推理
然后进行识别的测试,能识别即可。
python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
list.txt # list of images
list.streams # list of streams
'path/*.jpg' # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
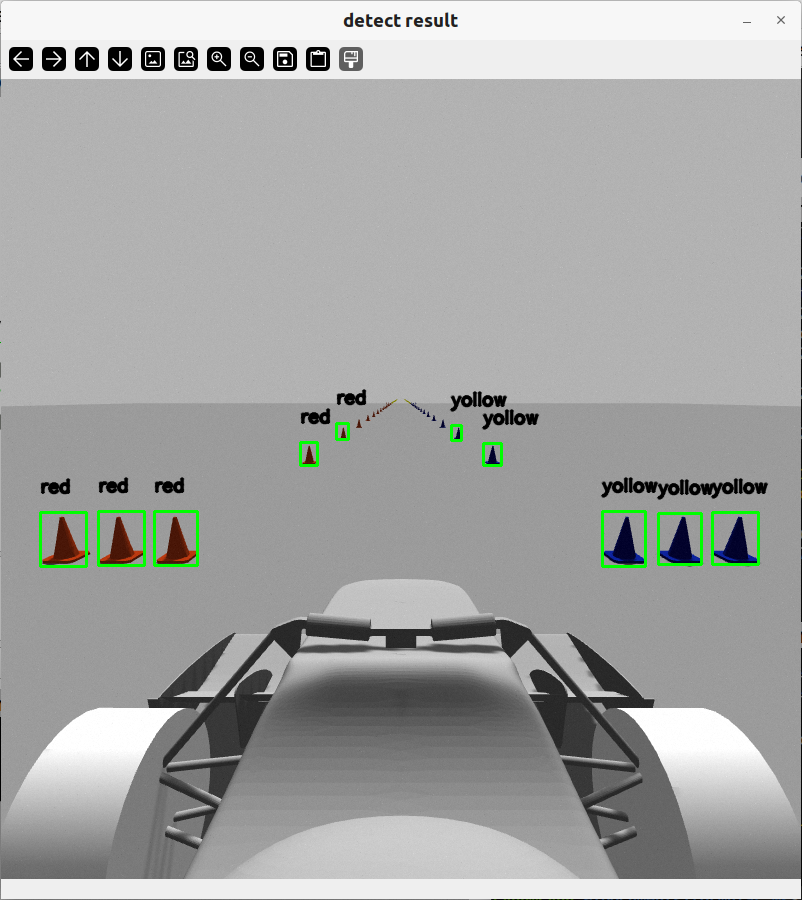
识别效果



















 1637
1637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











