







为了可以更加快速的可以使用Hadoop,便写了这篇文章,想尝试自己配置一下的可以参考从零开始配置Hadoop,图文手把手教你,定位错误
资源
1.两台已经配置好的hadoop
2.xshell+Vmware
链接:https://pan.baidu.com/s/1oX35G8CVCOzVqmtjdwrfzQ?pwd=3biz
提取码:3biz
--来自百度网盘超级会员V4的分享
两台虚拟机用户名和密码均为
root
123456
1.更改网络配置
1.打开虚拟机
打开我们下载好的两台虚拟机
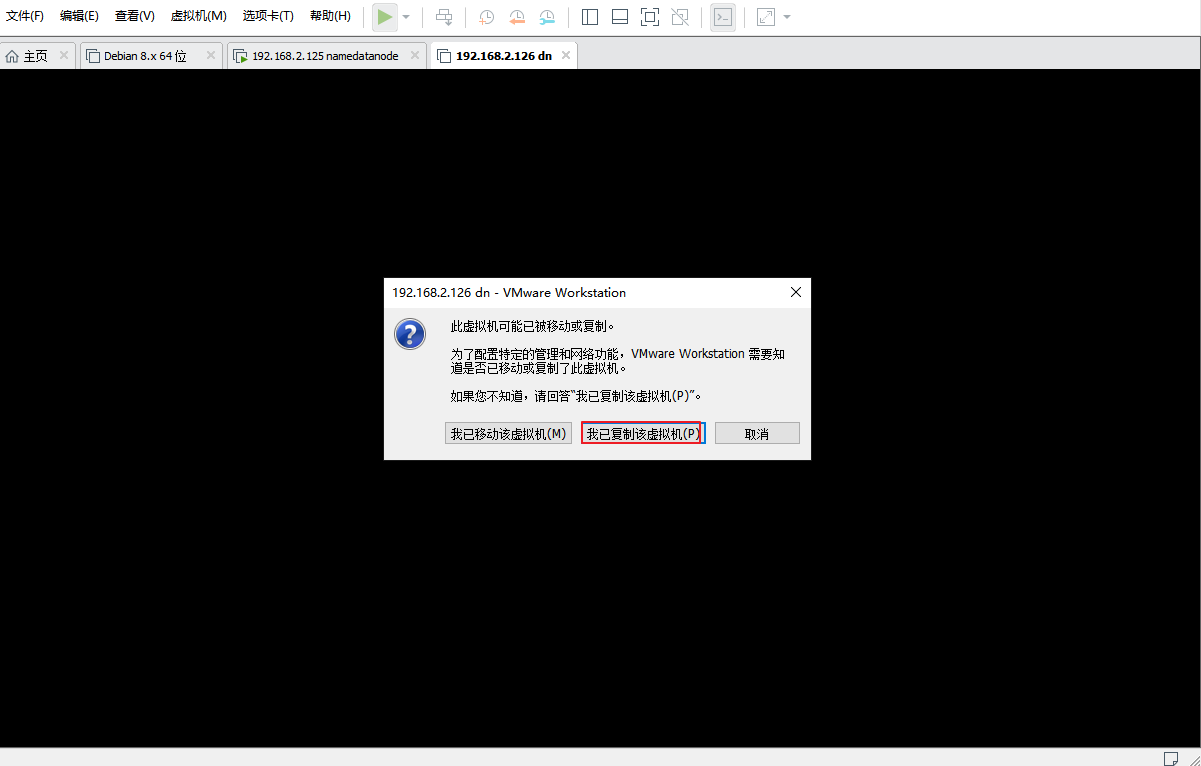
选择我已复制
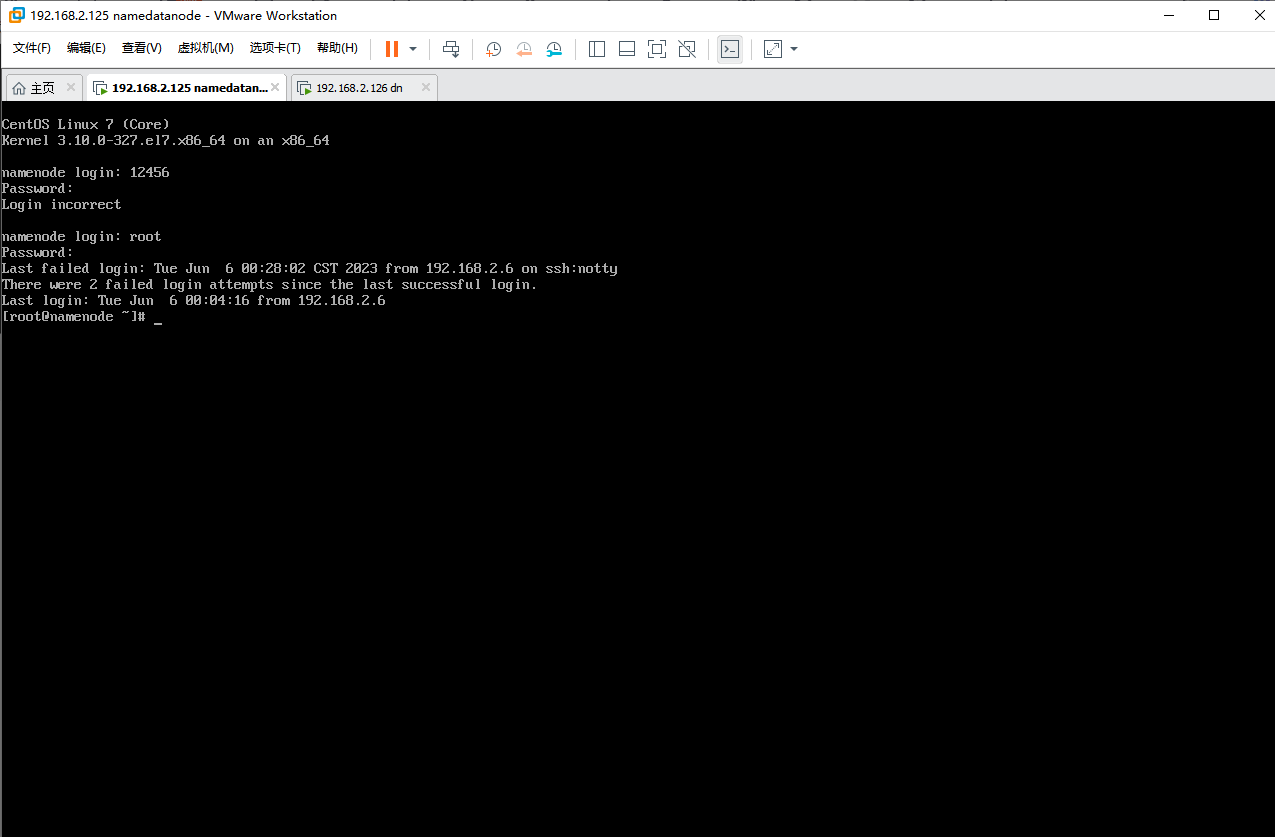
输入用户名和密码后,我们已经成功进入
2.寻找空闲地址
现在我们回到windows先去寻找两个空闲网络,win+R 输入smd接着在windows命令行窗口输入
ipconfig
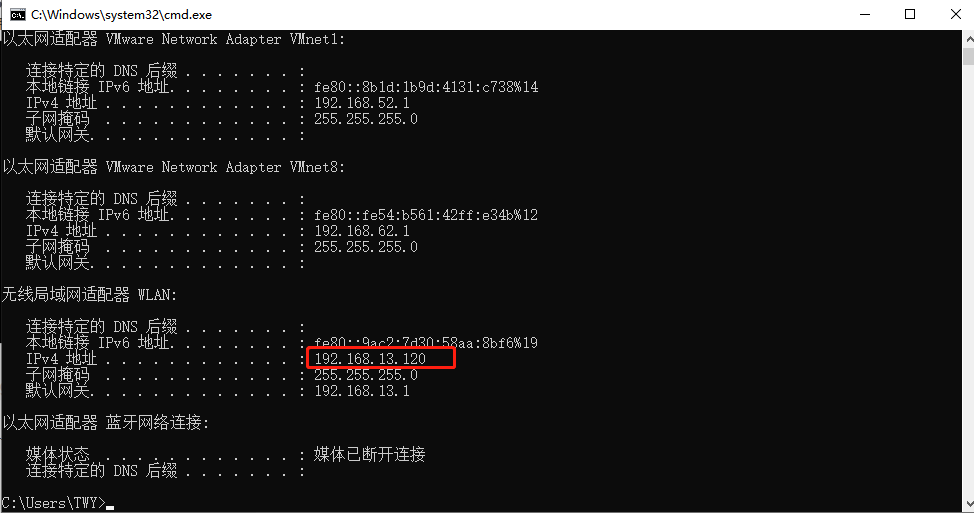
我们随便找两个靠后的,一个分配给namenode一个给datanode
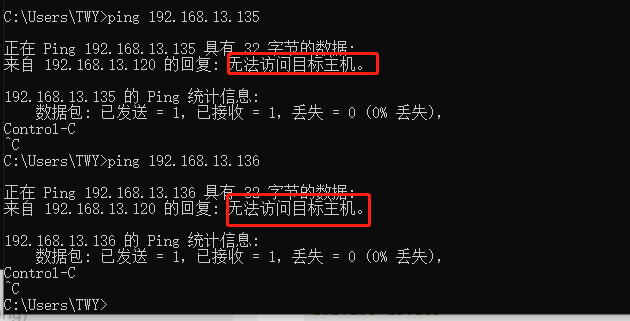
192.168.13.135
192.168.13.136
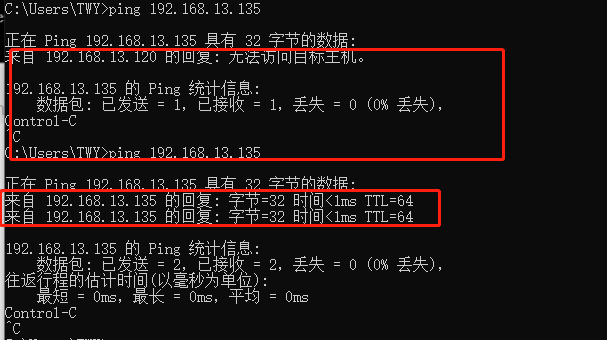
并去ping一下,如果出现无法访问该主机,说明改IP地址空缺,我们可以使用
3.分配空闲地址
Namenode
配置ifcfg-eno16777736,坚持一下,马上就可以复制了
cd /etc/sysconfig/network-scripts
ls

编辑网络配置文件
vi ifcfg-eno16777736
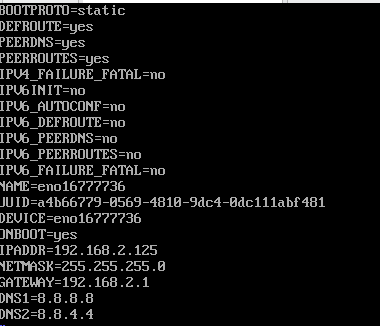
里面有东西的哈,如果没有请检查是不是打错了
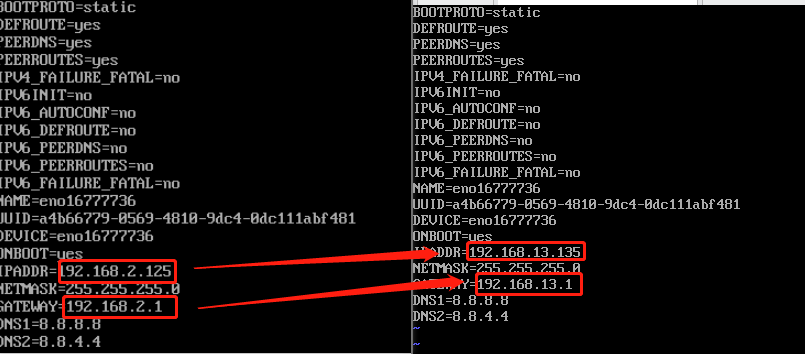
修改IP和网关
ip就是我们刚刚找的空地址
Namenode:192.168.13.135
Datanode:192.168.13.136(下一台这样改)
网关:两台机器的网关都是一样的
右边是修改完成后
刷新网络配置
service network restart

很明显,没有配置好之前是无法访问,配置好之后就可以回复了
Datanode
参考上面
配置ifcfg-eno16777736
编辑网络配置文件
修改IP和网关
这次的ip是
Namenode:192.168.13.135
Datanode:192.168.13.136(这个)
网关:两台机器的网关都是一样的
刷新网络配置


4.Xshell连接(软件已提供,方便可以复制)
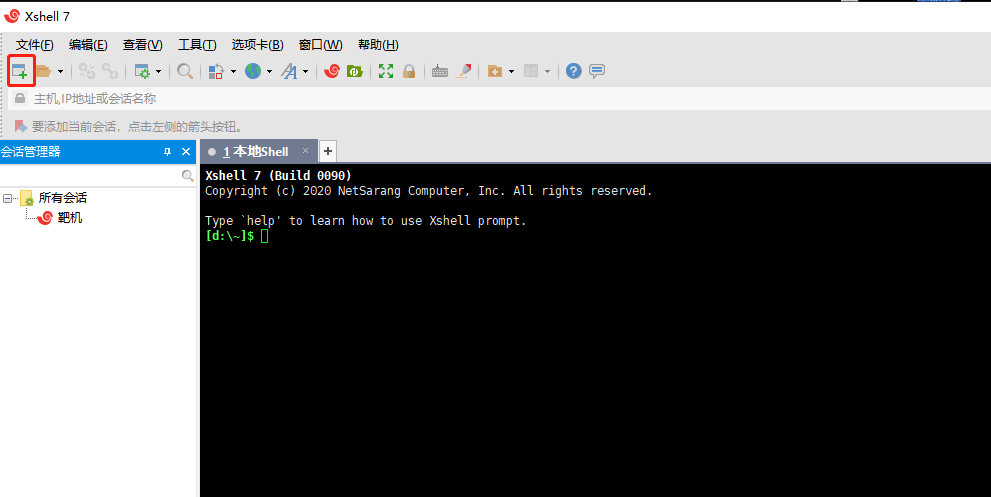
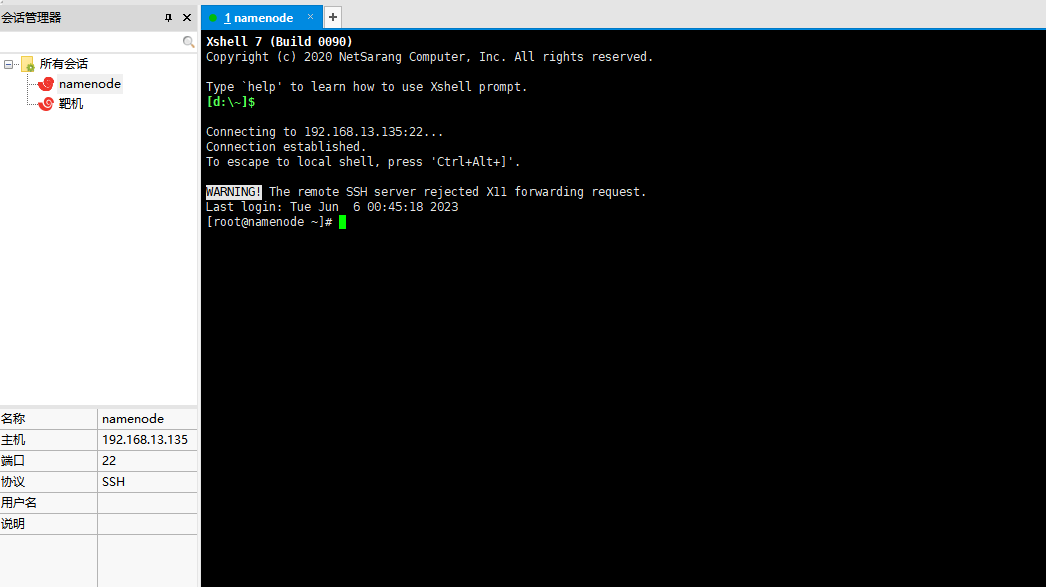
添加第一台
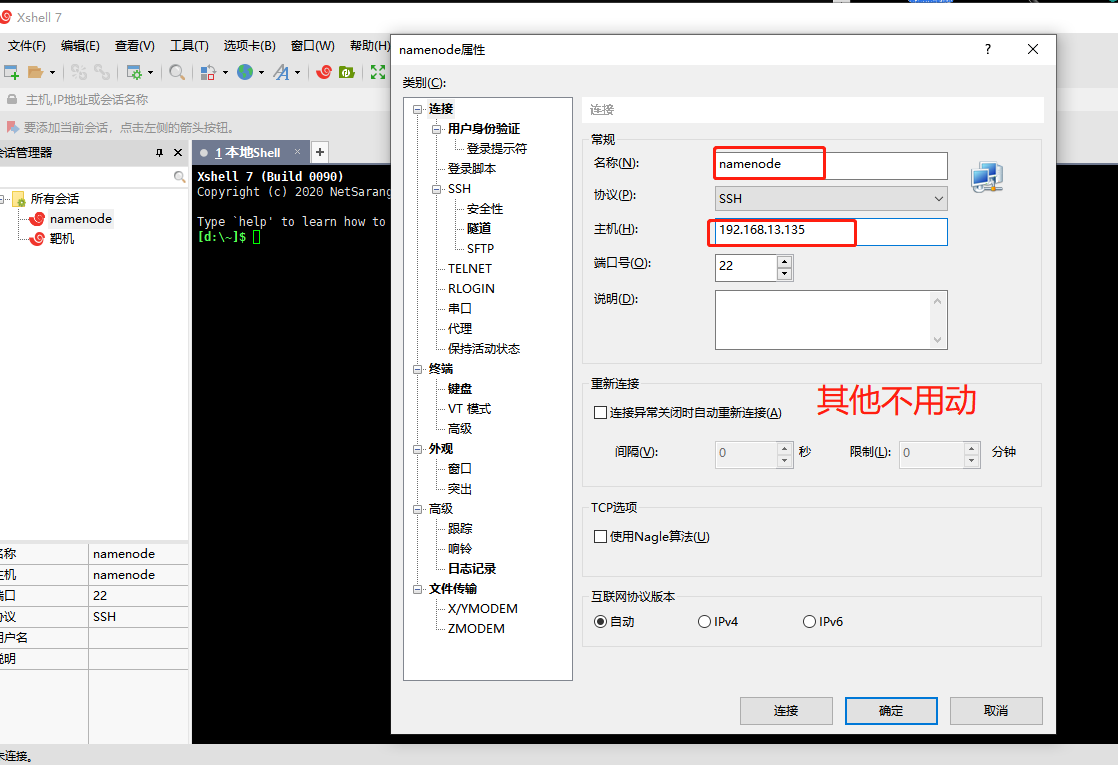
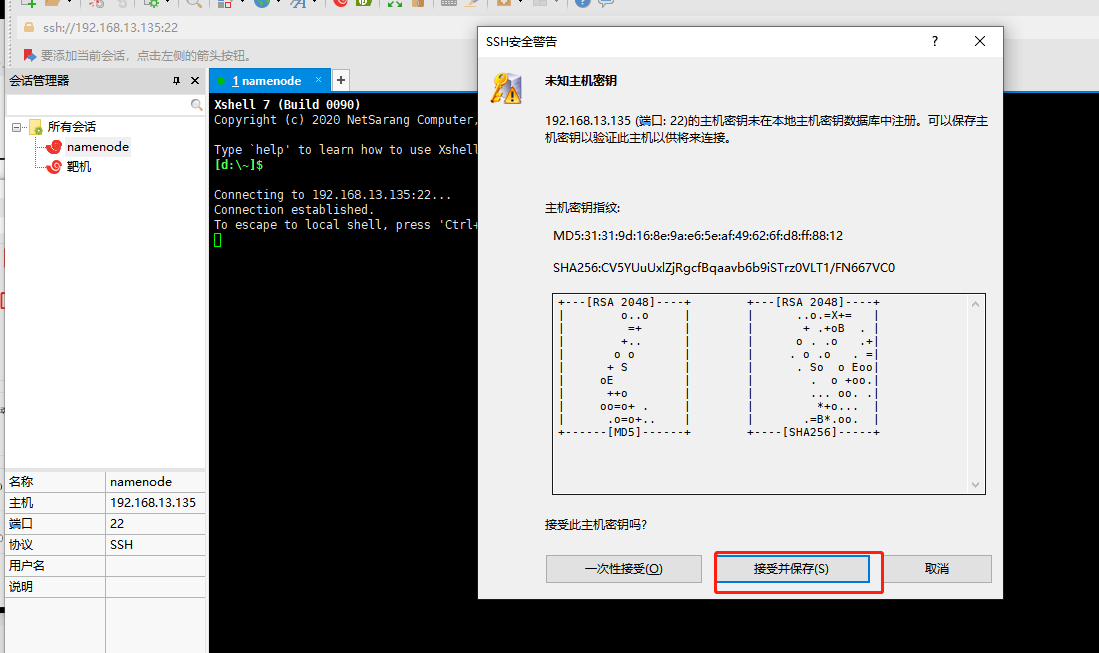
输入账号root和密码123456就可以连接成功
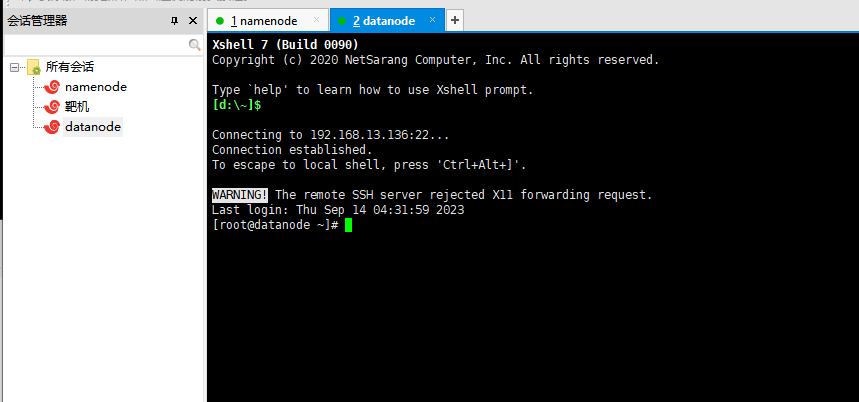
添加第二台,步骤参考上面(账号root和密码123456)
2.更改两台主机host配置
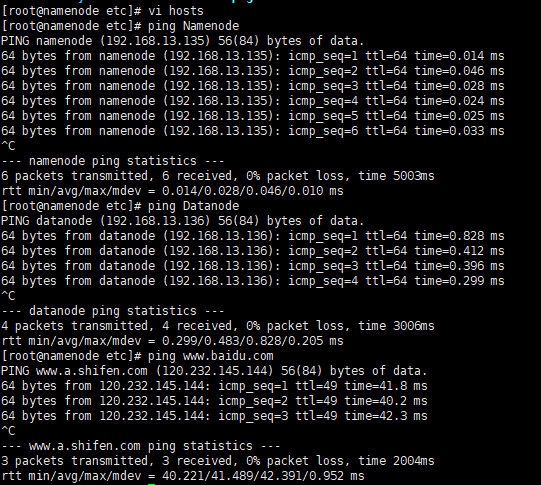
vi /etc/hosts
Namenode:192.168.13.135
Datanode:192.168.13.136

3.检验互相ping和ping外网(两台主机都要测试)
ping Namenode
ping Datanode
ping www.baidu.com
4.Hadoop启动!
接下来的操作均在主节点进行
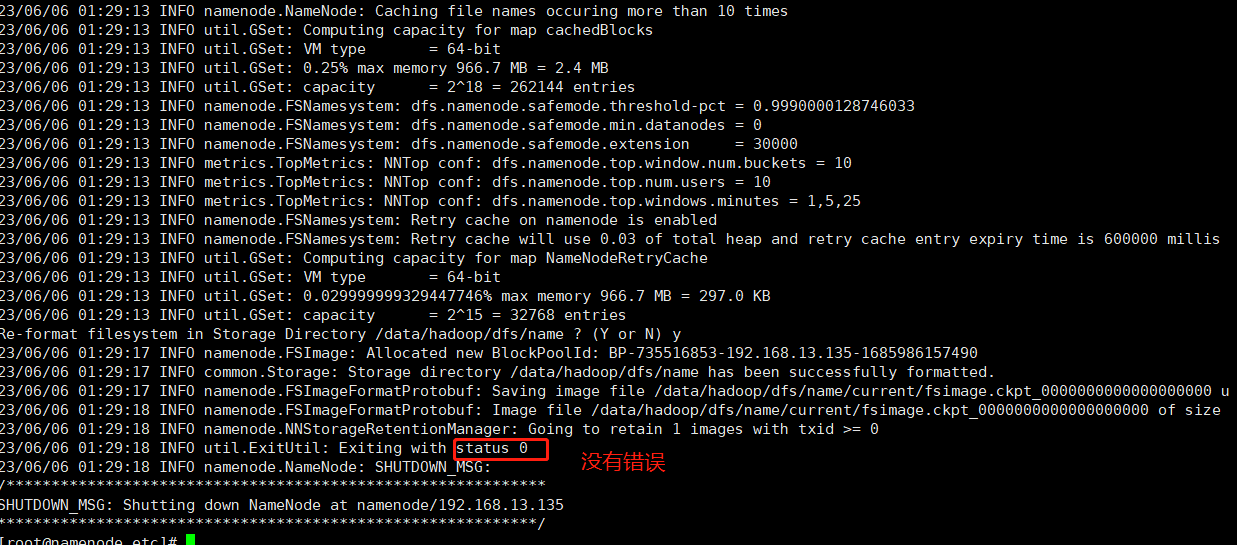
格式化集群
hdfs namenode -format
启动集群
start-all.sh
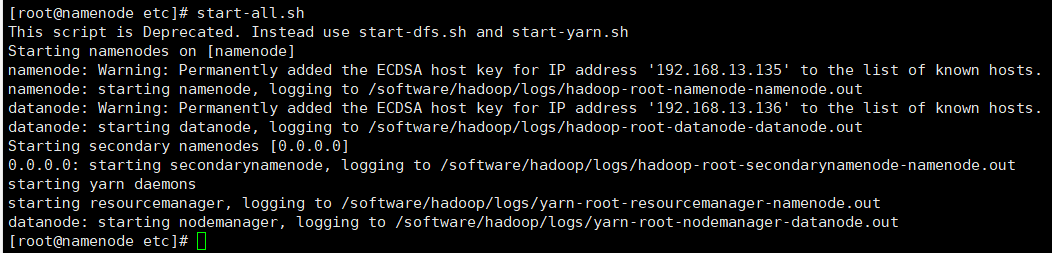
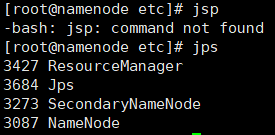
jps查看状态
jps
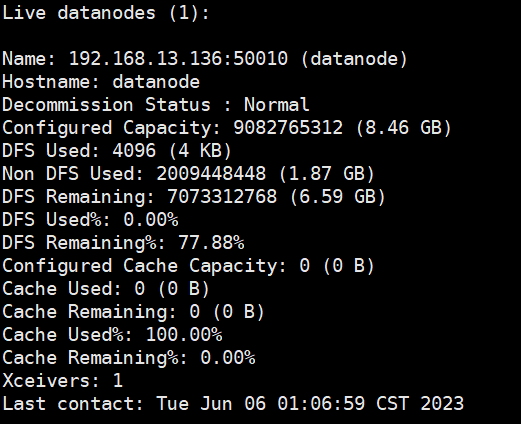
查看集群报告
hdfs dfsadmin -report
5.如果遇到报全为0的错误
1.删除两台主机“/data/hadoop”里面的内容
rm -rf /data/hadoop
2.重新格式化
hadoop namenode -format
4.启动hadoop
start-all.sh

















 4330
4330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











