






1。找到megacorpone.com 的子域并找到相对应的IP地址
第一步:wget www.megacorpone.com #下载该网站的首页文件
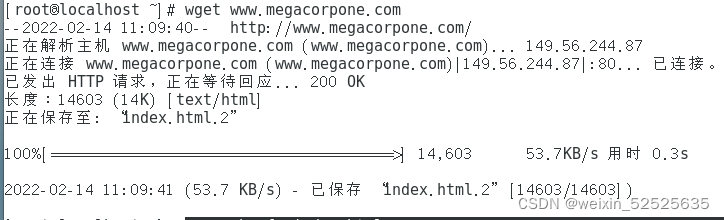
第二步:grep "href" index.html #过滤超链接关键字
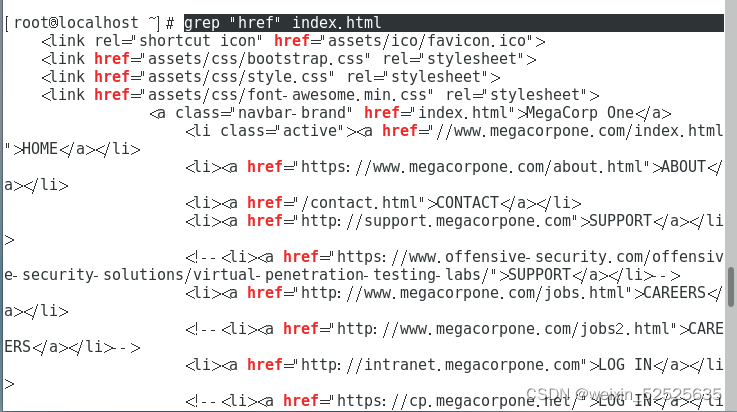
第三步:grep "href=" index.html | grep "\.megacorpone" | grep -v "www\.megacorpone\.com" | head #过滤“href=”字段在index.html文件中,并将结果给到过滤出带.megacorpone的行在给到不显示带"www.megacorpone"的行,最后读取出来结果。
**通过这种逻辑的方式减少我们的数据,并在每次操作中按顺序进行较小的缩减,我们处于数据最常见的周期**
awk -F设置多个字符的分隔符,与Cut不同,后者方式简单但只允许使用单字符分隔符
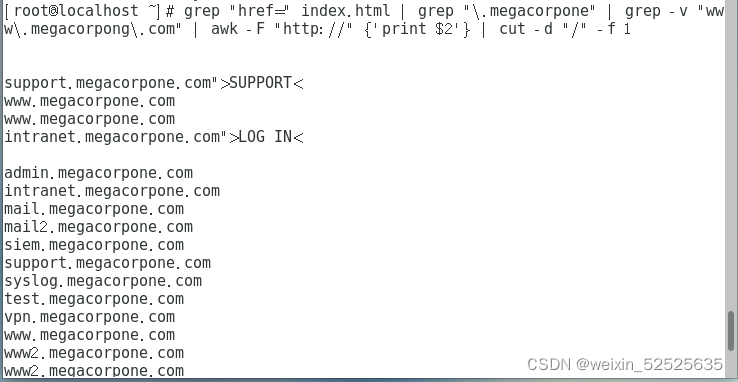
第四步:grep "href=" index.html | grep "\.megacorpone" | grep -v "www\.megacorpong\.com" | awk -F "http://" {'print $2'} | cut -d "/" -f 1
第五步:grep -o '[^/]*\.megacorpone\com' index.html | sort -u > list.txt
![]()
#grep -o 逐行输出匹配的内容,支持正则表达式
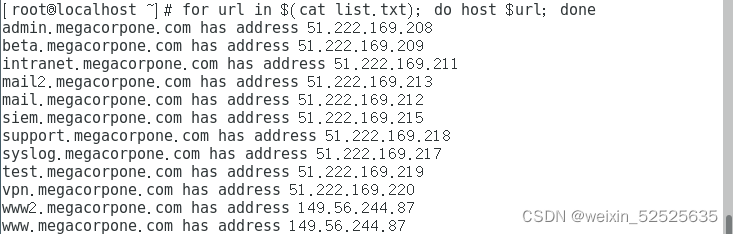
第六步:for url in $(cat list.txt); do host $url; done

















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









