






一、Python连接数据库:
例题12-2:Python查询MySQL数据表记录
代码如下:
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='user',
password='password',
db='database',
charset='utf8')
cur = conn.cursor() # 定义游标
strSQL = "select * from S"
cur.execute(strSQL) # 执行SQL语句
rows = cur.fetchall() # 获取游标所有行记录,返回元组变量
print("学号\t\t\t姓名\t\t年龄")
print("--------------------------------------------")
for r in rows: # 遍历元组
print("%s\t%s\t\t%s" % (r[0], r[1], r[2]))
# 用完,立即关闭对象,先关游标,再关连接
cur.close()
conn.close()
运行结果:

例题12-3: Python更新MySQL数据表记录
代码如下:
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='user',
password='password',
db='database',
charset='utf8')
cursor = conn.cursor() # 获取一个光标
try:
sql = 'insert into S(SNo, Sname, Age, Sex, dtBirthDate) values(%s,%s,%s,%s,%s);'
data = [('19140618', '刘逸群', 21, 'm', '2001-4-22')]
cursor.executemany(sql, data) # 拼接并执行sql语句
conn.commit() # 涉及写操作要注意提交
print("数据插入成功!影响行数:", cursor.rowcount)
except pymysql.Error as e:
conn.rollback()
print("插入错误!错误信息:", e.args[1])
cursor.close()
conn.close() # 关闭光标和连接
运行结果:

插入后数据为:
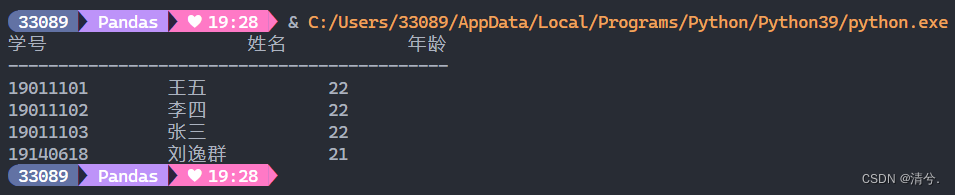
例题12-4: 将股票交易数据(Excel格式)成批插入数据库
代码如下:
import numpy as np
import xlrd
import pymysql
from datetime import datetime
from xlrd import xldate_as_tuple
import time
stock = xlrd.open_workbook("股票日交易数据20120425.xls")
sheet = stock.sheet_by_index(0)
rows = sheet.nrows
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='user',
password='password',
db='database',
charset='utf8')
# 创建游标对象
cur = conn.cursor()
# 开始事务
conn.begin()
start = 0
for i in np.arange(1, rows):
if(start == 0):
start = time.time()
row = sheet.row_values(i)
cStockNo = row[1].strip()
vcStockName = row[2]
# 交易日期
sCell = row[3]
date = datetime(*xldate_as_tuple(sCell, 0))
cDay = date.strftime('%Y-%m-%d')
mOpen = str(row[4])
mHigh = str(row[5])
mLow = str(row[6])
mClose = str(row[7])
dcRate = str(row[8])
iVol = str(row[9])
mm = str(row[10])
dcChange = str(row[11])
sql = "select cStockNo from smStock where cStockNo='"+cStockNo+"'"
cur.execute(sql) # 检查该股票信息是否已经在表中
n = cur.rowcount # 执行查询语句,返回的记录行数
if n == 0: # 若不在股票基本信息表中,则插入股票基本信息
sql = "insert into smStock(cStockNo,vcStockName)"
sql = sql + " values('"+cStockNo+"','"+vcStockName+"')"
cur.execute(sql) # 执行SQL语句
sql = "insert into trDay(cStockNo,cDay,mOpen,mHigh, mLow,"
sql = sql + "mClose,iVol,mm,dcChange,dcRate) values('"
sql = sql + cStockNo+"','"+cDay+"',"+mOpen+","+mHigh+","
sql = sql + mLow + "," + mClose+","+iVol+","+mm+","
sql = sql + dcChange+","+dcRate + ")"
cur.execute(sql)
try:
conn.commit() # 数据更新,最后一次性提交,否则不会保存到数据库中
print("一次性全部导入成功!")
except pymysql.Error as e:
conn.rollback()
print("导入失败!错误信息:", e.args[1])
cur.close()
conn.close()
运行结果:
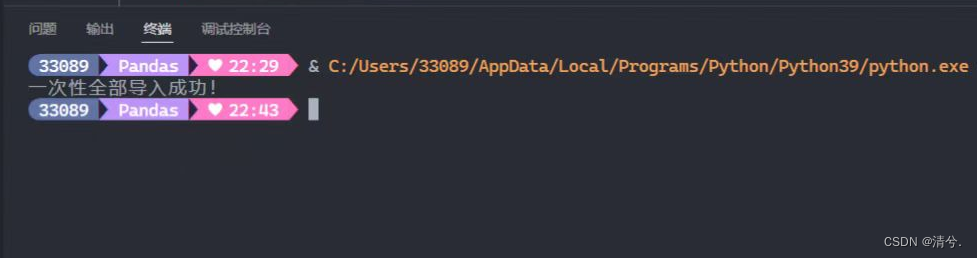
插入后数据:

二、读取数据库中的数据及 DataFrame 的数据访问:
例题13-1-1:询股票代码为sh600006的交易日期、收盘价,显示3条记录
代码如下:
from sqlalchemy import create_engine # 主要用于建立数据库连接引擎
import pandas as pd # 这个库,可以对数据库进行读写操作
connStr = "mysql+pymysql://user:password@127.0.0.1:3306/database?charset=utf8"
engine = create_engine(connStr) # 数据连接引擎
sql = "select cDay,mClose from trDay where cStockNo ='sh600001' limit 6,3"
trDay = pd.read_sql(sql, con=engine) # 返回为DataFrame对象
print(trDay.values) # trDay.values 为二维数组
print("返回记录行数:", trDay.shape[0])
运行结果:

例题13-1-2:查询股票代码为sh600001的交易数据并查看DataFrame的属性
代码如下:
from sqlalchemy import create_engine
import pandas as pd
connStr = "mysql+pymysql://user:password@127.0.0.1:3306/database?charset=utf8"
engine = create_engine(connStr) # 数据连接引擎
sql = "select cDay,mClose from trDay where cStockNo ='sh600001' limit 6,3"
trDay = pd.read_sql(sql, con=engine) # 返回 DataFrame 对象
i = 0
for row in trDay.values: # dataFrame.values 为二维数组
i = i+1
print(i, row[0], row[1])
# print(trDay['mClose']) # 单列所有行的访问
# print(trDay['mClose'][0:2]) # 单列多行的访问
运行结果:
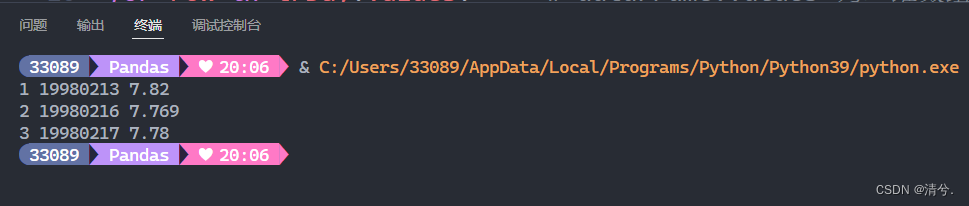
例题13-2:通过对象DataFrame,获取多列多行数据
代码如下:
from sqlalchemy import create_engine
import pandas as pd
connStr = "mysql+pymysql://user:password@127.0.0.1:3306/database?charset=utf8"
engine = create_engine(connStr) # 数据连接引擎
sql = "select cDay,mOpen,mHigh,mLow,mClose from trDay where cStockNo='SH600006'"
# 东风汽车(SH600006) 日交易数据
trDay = pd.read_sql(sql, con=engine)
# 将查询结果直接保存为excel文件
trDay.to_excel('trDay.xlsx')
print(trDay[['cDay', 'mOpen', 'mHigh', 'mLow', 'mClose']][:3]) # 前3行
运行结果: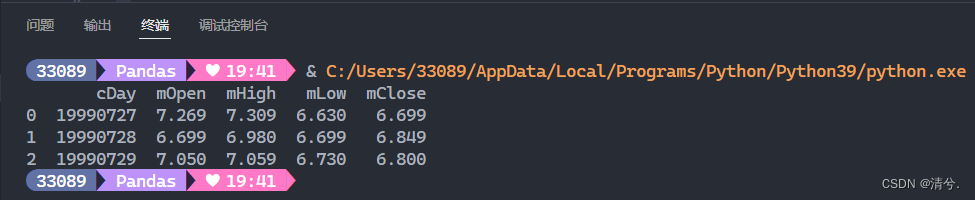
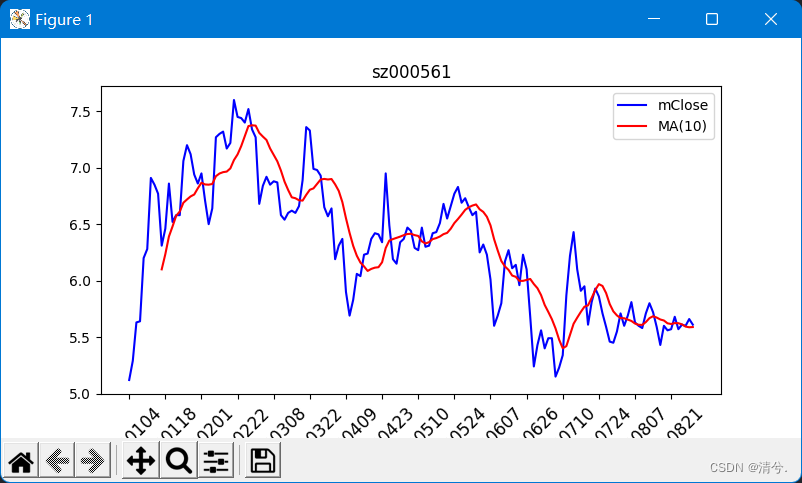
例题13-3:利用DataFrame,直接绘制股票价格趋势图、移动平均
代码如下:
from sqlalchemy import create_engine
import matplotlib.pyplot as plt
import pandas as pd
# 数据连接引擎
connStr = "mysql+pymysql://user:password@127.0.0.1:3306/database?charset=utf8"
engine = create_engine(connStr)
sql = "select cDay,mClose from trDay where cStockNo ='sz000561' and cDay>'20130101' and cDay<'20130830' order by cDay"
# 烽火电子日收盘价格
trDay = pd.read_sql(sql, con=engine)
plt.figure(figsize=(8, 4), dpi=80)
trDay['mClose'].plot(title="sz000561", color='b')
trDay['mClose'].rolling(10).mean().plot(
color='r') # 10天移动平均
rows = trDay.shape[0]
# 步长为10
d = trDay['cDay'][0:rows:10]
plt.xticks(range(0, rows, 10), d, rotation=45, fontsize=12) # 旋转45度
plt.legend(['mClose', 'MA(10)'])
plt.show()
运行结果:
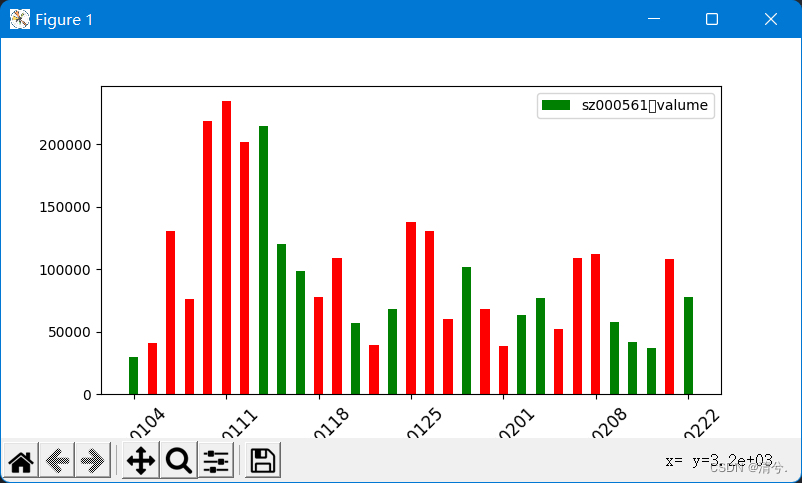
例题13-4:利用对象DataFrame,直接绘制股票成交量条形图
代码如下:
from sqlalchemy import create_engine
import matplotlib.pyplot as plt
import pandas as pd
connStr = "mysql+pymysql://user:password@127.0.0.1:3306/database?charset=utf8"
engine = create_engine(connStr)
sql = "select cDay,mOpen,mClose,iVol from trDay where cStockNo ='sz000561' and cDay between '20130102' and '20130222' order by cDay"
# 烽火电子日收盘价格
trDay = pd.read_sql(sql, con=engine)
plt.figure(figsize=(8, 4), dpi=80)
# 颜色列表
c = []
for index, row in trDay.iterrows():
if (row['mClose'] >= row['mOpen']):
# 收盘价不低于开盘价,则红色
c.append('red')
else:
# 绿色
c.append('green')
plt.bar(trDay['cDay'], trDay['iVol'], width=0.5, color=c)
rows = trDay.shape[0]
d = trDay['cDay'][0:rows:5]
plt.xticks(range(0, rows, 5), d, rotation=45, fontsize=12) # 旋转45度
plt.legend(['sz000561:valume'])
plt.show()
运行结果:
三、Pandas读写文本文件:
例题13-6-1:使用read_csv读取“深指日交易数据.csv”
代码如下:
import pandas as pd
data = pd.read_csv('深指日交易数据.csv', encoding='gbk')
# print(type(data)) # <class 'pandas.core.frame.DataFrame'>
print('使用read_csv读取的交易数据表的长度为:', len(data)) # 输出:9
# print(data.columns) # 返回所有的列名对象,相当于字典的键名
# 默认把第0行,作为列名
i = 0
for row in data.values: # 显示所有行记录
i = i+1
print(i, row[0], row[1], row[2], row[3], row[4], row[5])
运行结果:

例题13-6-2:使用to_csv存储“深指日交易数据.csv”
代码如下:
import pandas as pd
import os
order = pd.read_csv('深指日交易数据.csv', encoding='gbk')
print('写入文本文件前目录内文件列表为:\n', os.listdir('c:/qun1/tmp'))
# 将order以csv格式存储
order.to_csv('c:/qun1/tmp/orderInfo.csv', sep=';', index=False)
print('写入文本文件后目录内文件列表为:\n', os.listdir('c:/qun1/tmp'))
运行结果:

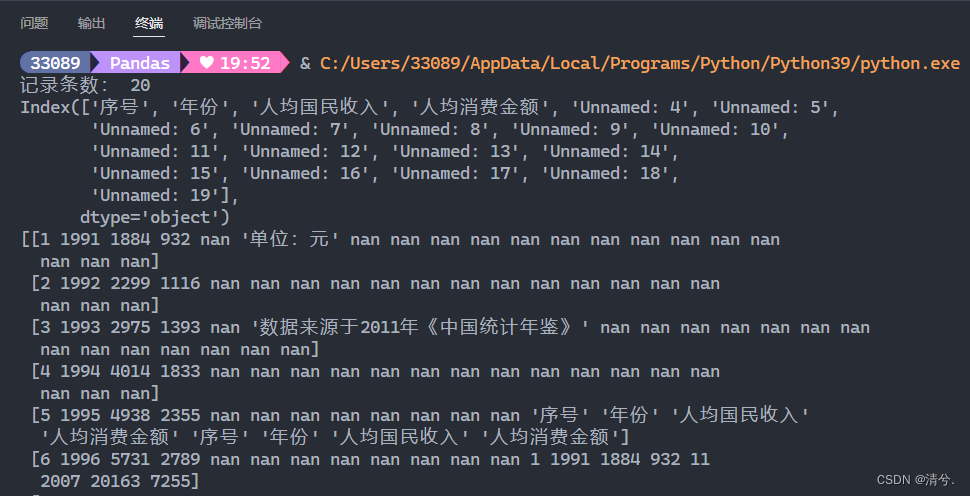
例题13-8:使用read_excel读取文件“人均国民收入.xls”
代码如下:
import pandas as pd
F = '人均国民收入.xls'
data = pd.read_excel(F, '收入与消费')
data = pd.read_excel(F, 0) # 也可sheet 索引
print('记录条数:', len(data))
# 返回所有的列名对象,相当于字典的键名 ,
# 默认把第0行,作为列名
print(data.columns)
print(data.values) # 返回所有的行
运行结果:
例题13-9:使用to_excel写文件(*.xlsx)
代码如下:
import pandas as pd
import os
user = pd.read_excel('users.xlsx') # 读取user.xlsx文件
print('写入excel文件前目录内文件列表为:\n', os.listdir('c:/qun1/tmp'))
user.to_excel('c:/qun1/tmp/userInfo.xlsx')
print('写入excel文件后目录内文件列表为:\n', os.listdir('c:/qun1/tmp'))
运行结果:

例题13-10-1:Pandas的数据帧(DataFrame)按列名排序的方法
代码如下:
import matplotlib.pyplot as plt
import pandas as pd
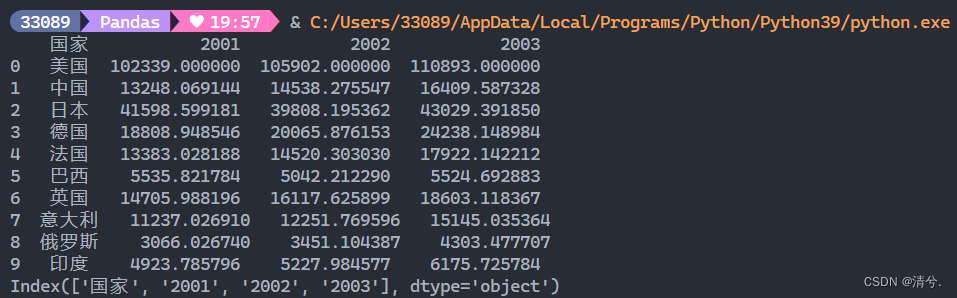
wb = pd.read_excel('各国GDP(2001-2011).xls')
d = wb.iloc[0:11, 0:4] # [行号,列号],d为'pandas.core.frame.DataFrame'
print(d)
print(d.columns)
s = d.sort_values(by='国家', ascending=True) # 对列名“国家”按升序
print(s)
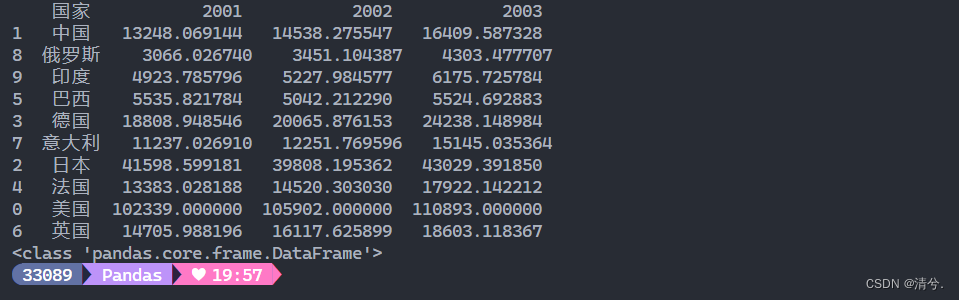
s = d.sort_values(by='2001', ascending=False) # 对列名“2001”按降序
print(type(s))
运行结果:
第一次排序:
第二次排序:
例题13-10-2:通过条形图迭代绘制2000-2011年GDP最大的10个国家变化
代码如下:
import matplotlib.pyplot as plt
import pandas as pd
import imageio
# 设置中文显示
plt.rcParams['font.sans-serif'] = 'SimHei'
wb = pd.read_excel('各国GDP(2001-2011).xls')
# 行 0:11,列:0:12
d = wb.iloc[0:11, 0:12]
plt.figure(figsize=(6, 4), dpi=120)
# 打开交互模式
plt.ion()
image_list = []
# 年份:2001年->2011年
for i in range(1, 12):
w = str(d.columns[i]) # w 为年份
s = d.sort_values(by=w, ascending=True) # 按年份数据排升序
# 第 i 列年份 ,前11个国家数据
x = s.iloc[:, i]
# 国家名称
y = s.iloc[:, 0]
c = list(map(lambda x: 'red' if x == '中国' else 'blue', y))
plt.clf() # 清除画布
plt.title('各国历年GDP动态条形图(单位:亿美元)', fontsize=12)
plt.barh(y, x, height=0.6, color=c) # 横放条形图函数 barh
for a, b in zip(x, y):
plt.text(a+0.6, b, '%.0f' % a, fontsize=12)
plt.legend([w+'年'], fontsize=12)
# 隔1秒,停止一下
plt.pause(1)
plt.savefig('temp.png')
image_list.append(imageio.imread('temp.png'))
# 关闭交互模式
plt.ioff()
imageio.mimsave('bar_test.gif', image_list, duration=1)
运行结果:

总结
学会了Python连接数据库并利用Pandas分析数据,为今后学习提供了很大帮助。















 1999
1999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









