







 通过对淘宝用户行为数据的分析,揭示了用户在平台上的流量、行为和商品消费趋势。研究发现,用户在浏览后加购或收藏的转化率低,但独立访客的转化率较高,表明用户在购买前比较商品。此外,用户次日留存率约为40%,复购率为17.3%,建议优化推荐机制和增加用户触达策略,以提高转化和复购。商品销售中无明显爆款,商品多样化,需要关注不同象限商品的优化策略。
通过对淘宝用户行为数据的分析,揭示了用户在平台上的流量、行为和商品消费趋势。研究发现,用户在浏览后加购或收藏的转化率低,但独立访客的转化率较高,表明用户在购买前比较商品。此外,用户次日留存率约为40%,复购率为17.3%,建议优化推荐机制和增加用户触达策略,以提高转化和复购。商品销售中无明显爆款,商品多样化,需要关注不同象限商品的优化策略。
目录
一、项目描述
1.1 项目目的
总体目标:为了用户提供更精准的隐式反馈推荐,提高成交额。
通过对电商平台流量变化趋势、用户行为方向分析,探索用户使用规律,使推荐策略更好地与用户行为逻辑相匹配;通过对商品的分析,了解对商品的喜好偏向,优化商品推荐。
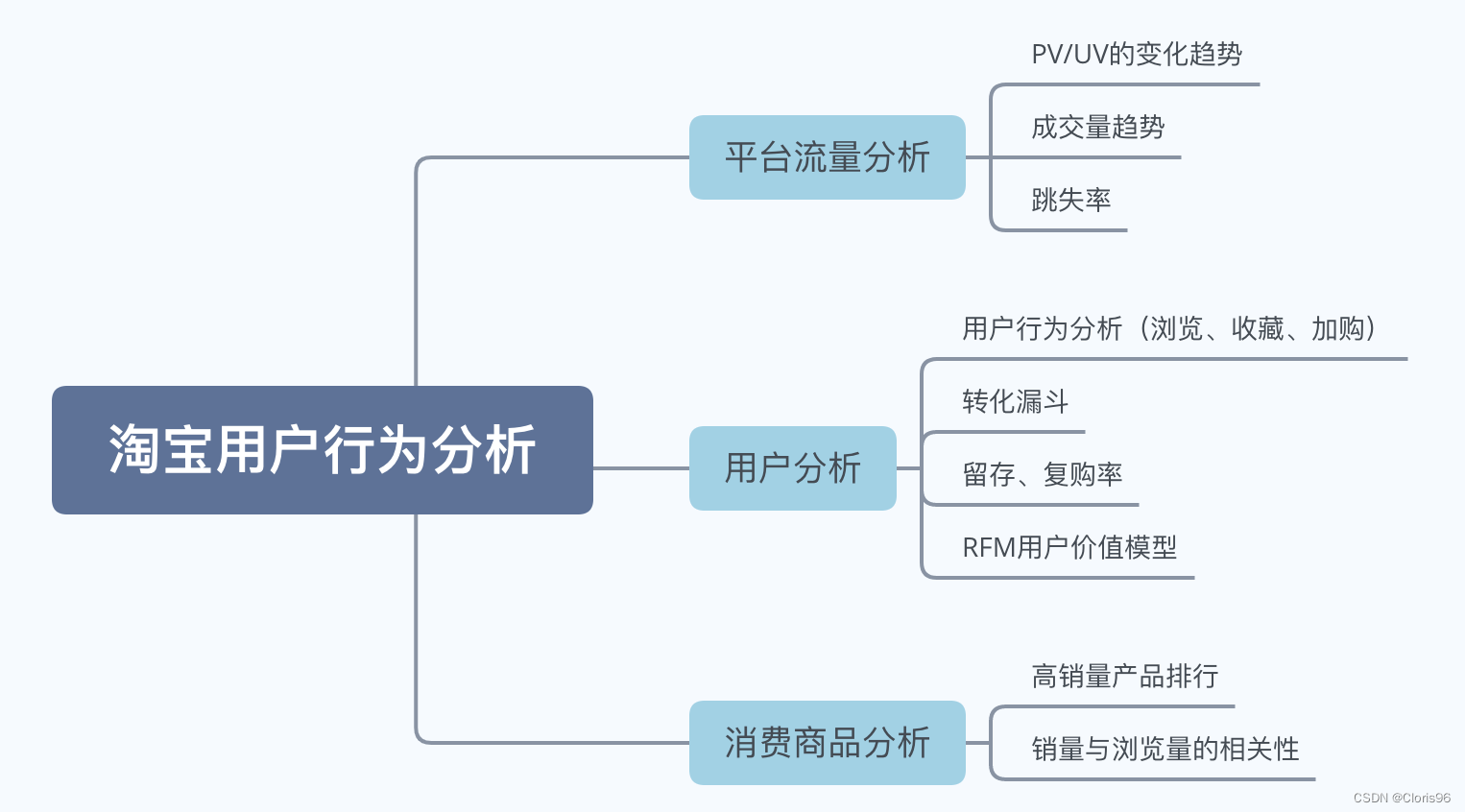
1.2 分析维度
从平台流量、用户行为、商品消费三个方向进行分析,具体维度如下:
二、项目数据
2.1 数据来源
阿里天池:https://tianchi.aliyun.com/dataset/dataDetail?dataId=649
UserBehavior是阿里巴巴提供的一个淘宝用户行为数据集,用于隐式反馈推荐问题的研究。数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。
2.2 数据说明
数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
| 列名称 |
说明 |
|---|---|
| 用户ID | 整数类型,序列化后的用户ID |
| 商品ID | 整数类型,序列化后的商品ID |
| 商品类目ID | 整数类型,序列化后的商品所属类目ID |
| 行为类型 | 字符串,枚举类型,包括('pv', 'buy', 'cart', 'fav') |
| 时间戳 | 行为发生的时间戳 |
注意到,用户行为类型共有四种,它们分别是
| 行为类型 | 说明 |
|---|---|
| pv | 商品详情页pv,等价于点击 |
| buy | 商品购买 |
| cart | 将商品加入购物车 |
| fav | 收藏商品 |
三、数据清洗
3.1 导入数据
① 创建数据库
create database if not exists sql_userbehavior② 导入下载的数据
3.2 数据清洗
① 创建子集
源数据没有主键,随机抽样10w条数据,创建新表
create table ub LIKE userbehavior;
insert into ub
select * from userbehavior order by rand() limit 100000② 删除重复值
查看是否存在重复值,结果显示并无重复值
select *
from ub
group by user_id,item_id,category_id,behavior_type,timestamp
having count(*)>1③ 缺失值处理
统计各个字段是否存在缺失值,结果显示无缺失值
select
sum(case when user_id is null then 1 else 0 end) as userid,
sum(case when item_id is null then 1 else 0 end) as itemid,
sum(case when category_id is null then 1 else 0 end) as cateid,
sum(case when behavior_type is null then 1 else 0 end) as bt,
sum(case when timestamp is null then 1 else 0 end) as date
from ub
④ 一致化处理
将时间戳转换为日期格式,并提取日期和小时数,以便后续分析使用
alter table ub add column date_time timestamp(0) NULL;
update ub
set date_time = FROM_UNIXTIME('timestamp');添加新列ubdate,将长日期转换为短日期
alter table ub add column ubdate char(10);
update ub
set ubdate = DATE_FORMAT(date_time,'%Y-%m-%d')添加新列ubtime,提取小时数
alter table ub add column ubtime int;
update ub
set ubtime = hour(date_time)⑤ 添加主键
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 8270
8270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











