






4.1_1 串的定义和基本操作
1、串的定义
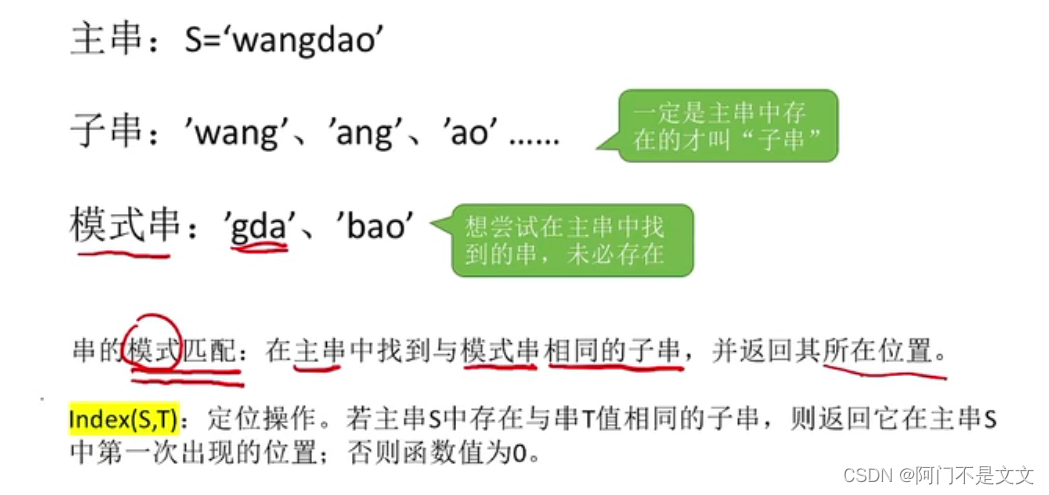
- 子串:串中任意个连续的字符组成的子序列
- 主串:包含子串的串
- 字符在主串中的位置:字符在串中的序号
- 字串在主串中的位置:字串的第一个字符在主串中的位置
- 空串 != 空格串,空格串中的每个空格字符占1个字节,也就是8个比特位
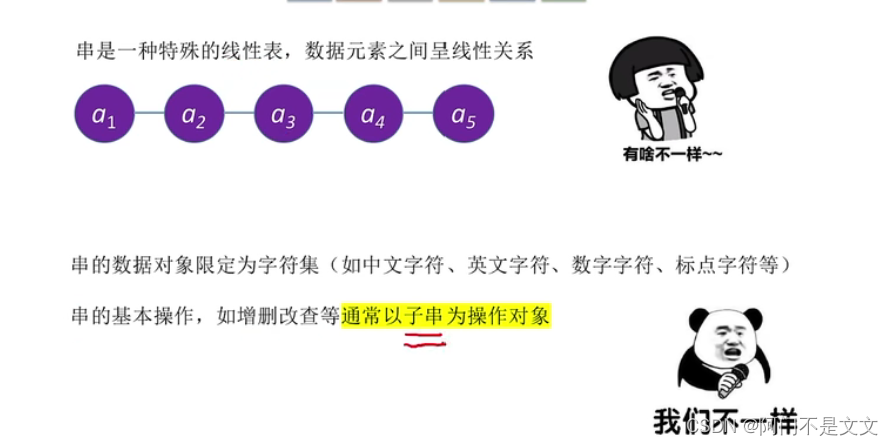
- 串和线性表:串是一种特殊的线性表,数据元素之间呈线性关系
2、串的基本操作

用StrCompare(S, T)比较时,abandon<aboard,因为第三个字符"a"<“o” ,如果前缀与短串相同时,长串更大:abstract < abstraction
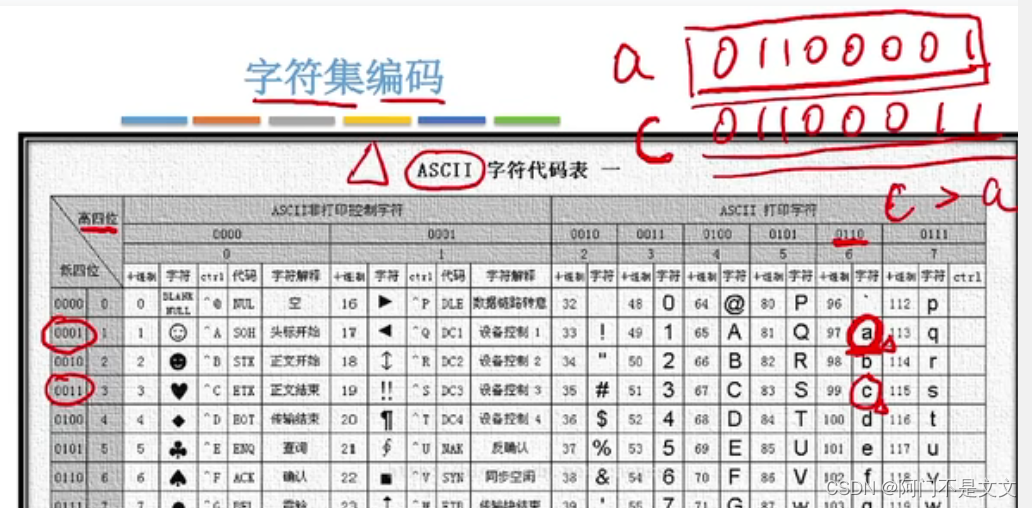
3、字符集编码

先读高四位,再读第四位
3、知识回顾与重要考点

4.1_2 串的存储结构
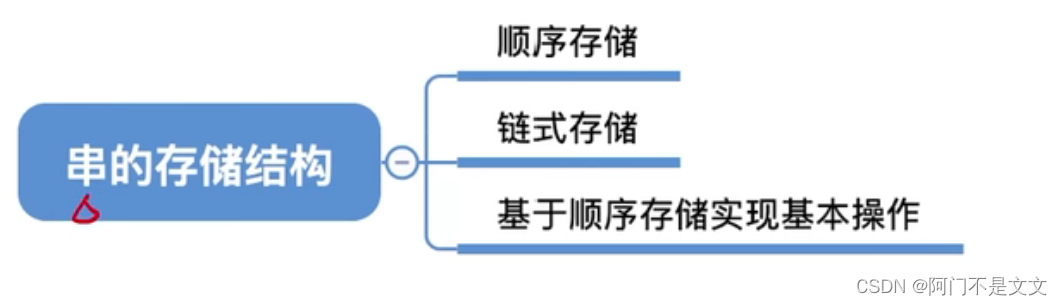
把线性表中的ElemType改成char
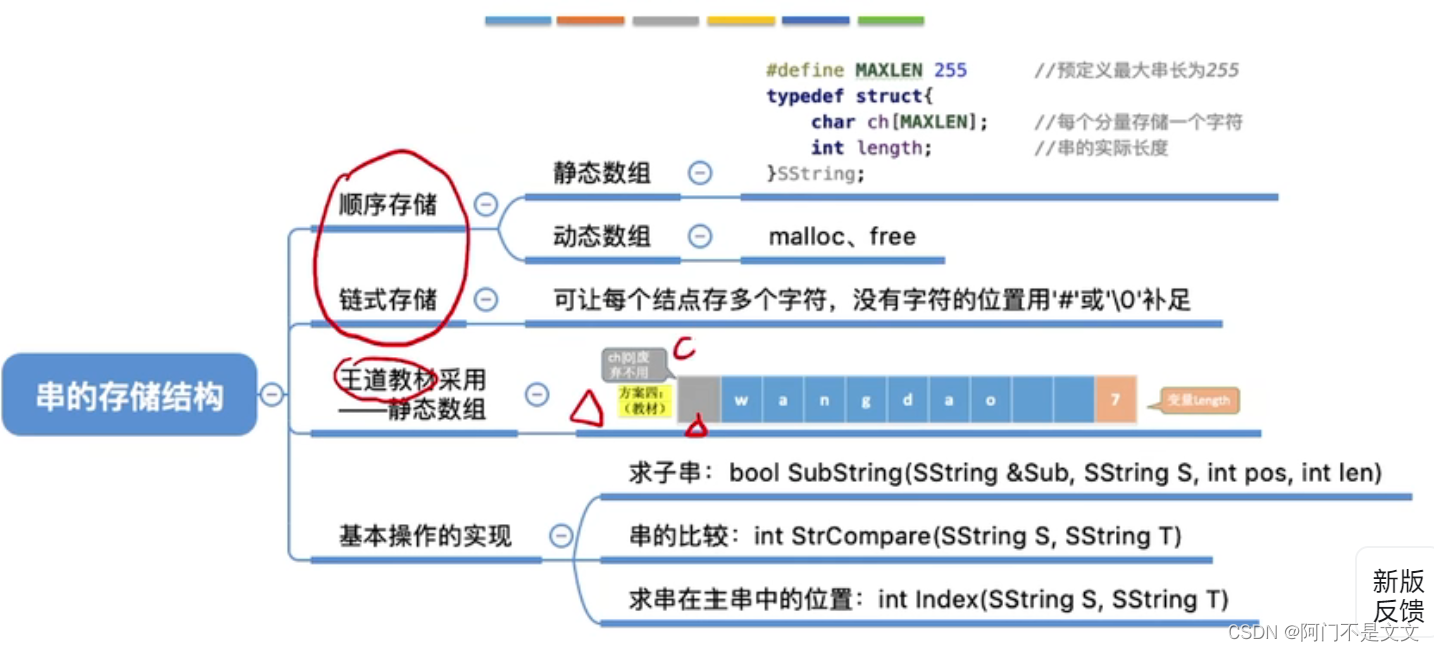
1、串的顺序存储
静态数组实现:
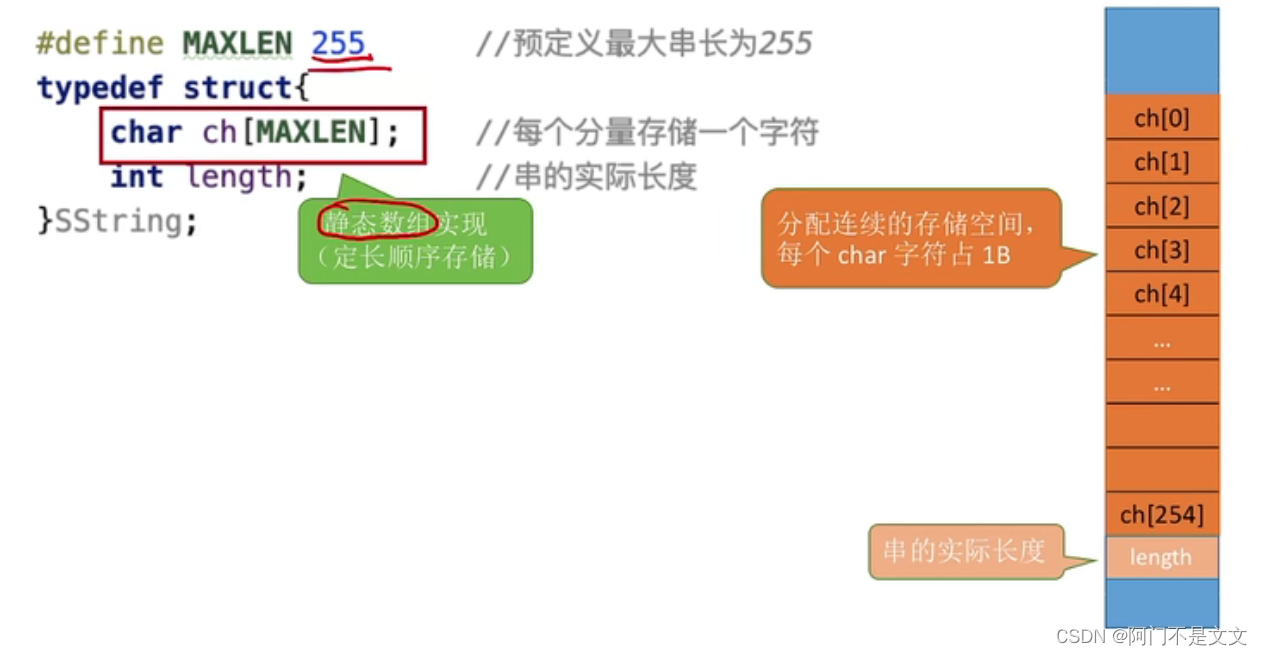
动态数组实现:

计算串的长度:
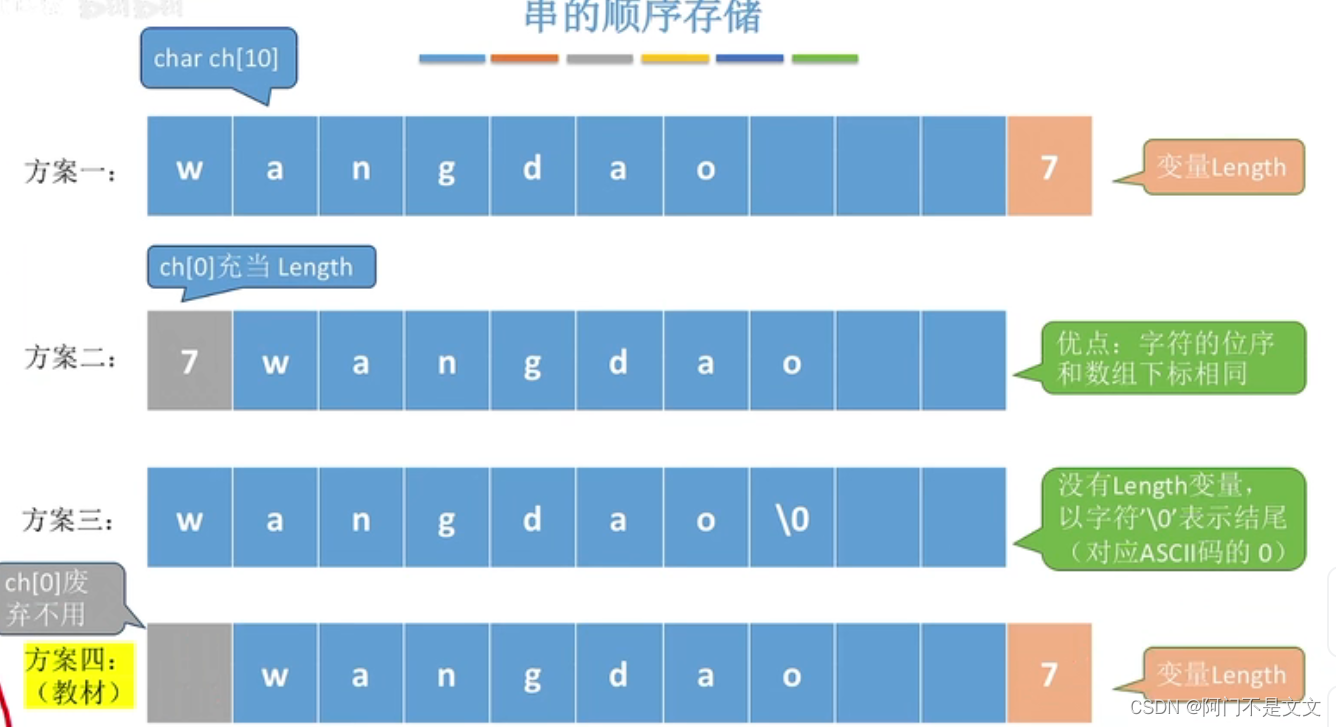
- 方案一:字符的位序=数组下标+1
- 方案二:字符的位序=数组下标,但ch[0]占1B,也就是8bit,只能表示0~255的数字范围
- 方案三:最后放置\0,那么计算长度的时候,就要遍历到\0
- 方案四:方案一和二的结合,从ch[1]开始访问
2、串的链式存储
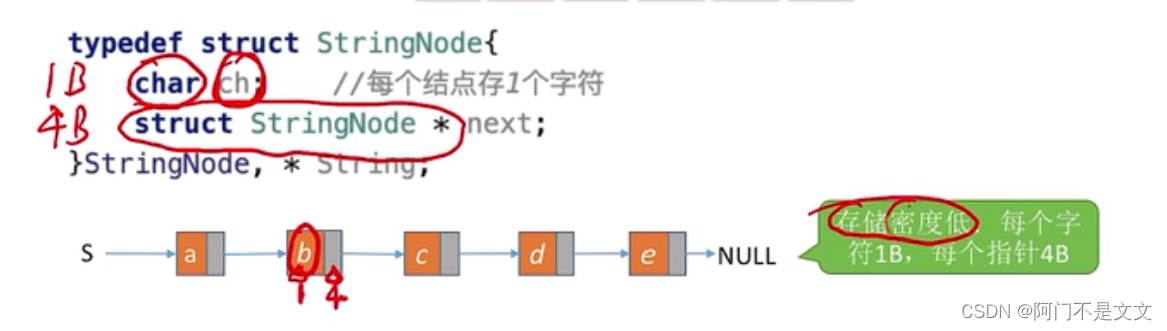
- char占1B,指针占4B,故存储密度低(实际有用信息所占比例非常小)
- 解决方法:每个结点存多个字符
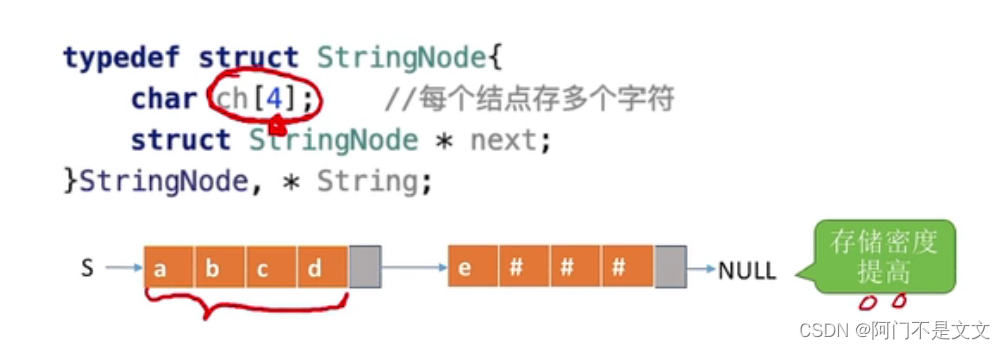 某些地方存不满也可以用些特殊字符来存储,如*或\0
某些地方存不满也可以用些特殊字符来存储,如*或\0
3、基本操作的实现
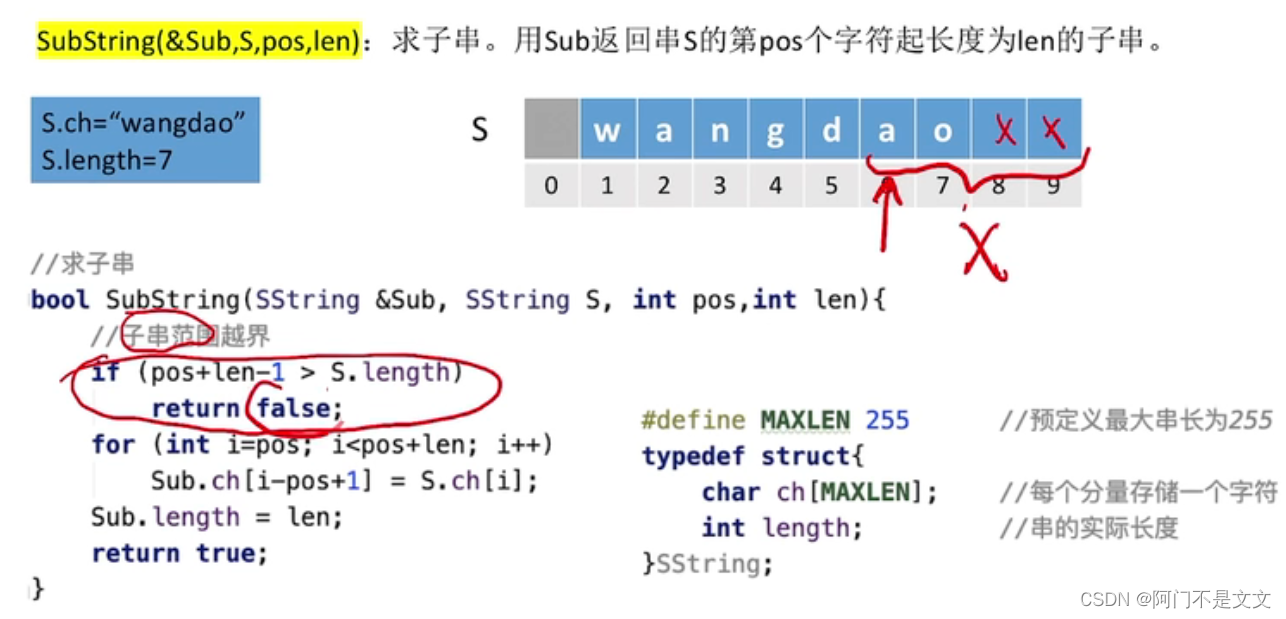
求子串,用Sub返回串S的第pos个字符起长度为len的子串
比较两个串的大小:

定位操作:

3、知识回顾与重要考点
*4.2_1 串的朴素模式匹配算法
1、什么是模式匹配
2、思路
用k来记录当前检查的子串起始位置,只要有一个字符和模式串相应字符不同,就可以停止检查当前子串,直接检查下一个,若都相同,则返回k
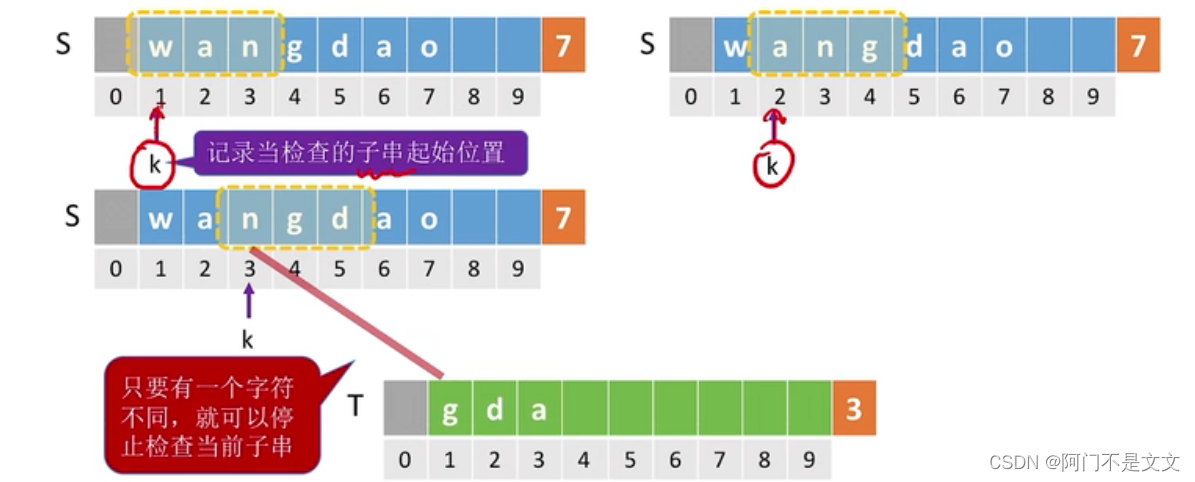
3、代码
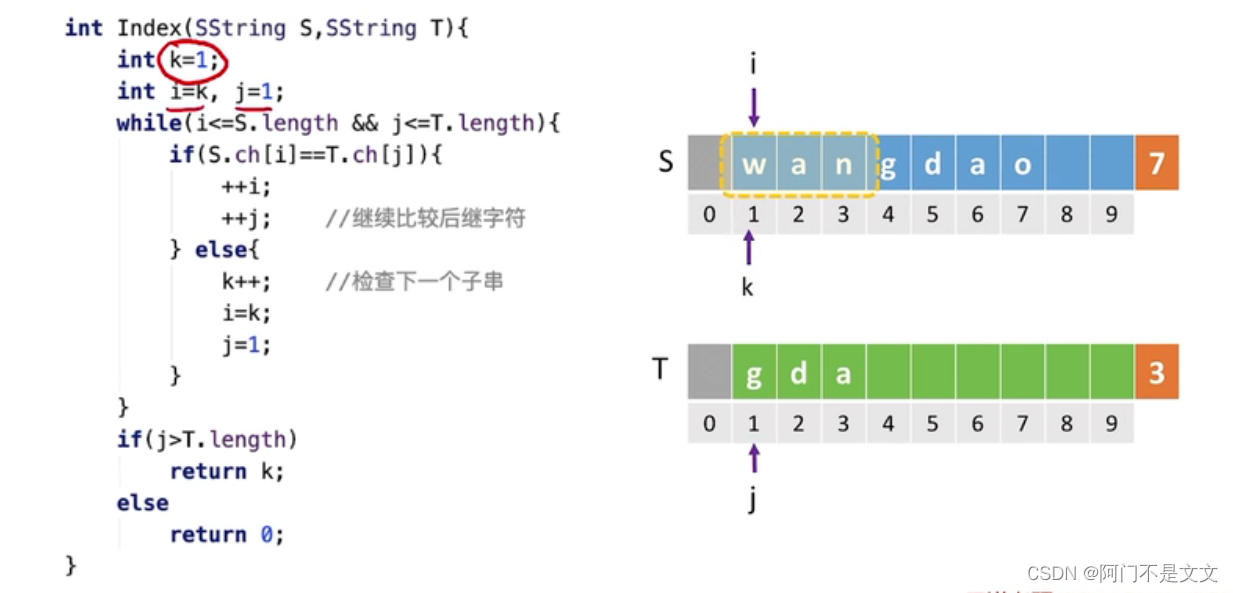
- 用i和j分别指向主串和模式串
- 若主串的子串和模式串相应字符相等且i和j都没有超出,那么i和j都往右移
- 若主串的子串和模式串相等,那么j=1,回到第一个,i继续往下走,i++
- 循环完毕,若不仅相等而且j超出了,则返回k
- 若i超过了主串,j并没有超出,也就是i此时没有存在字符了,故返回0
4、课本代码
没有用k,而是用i和j的关系,比如i=3、j=1时不匹配,那么i=3-1+2=4
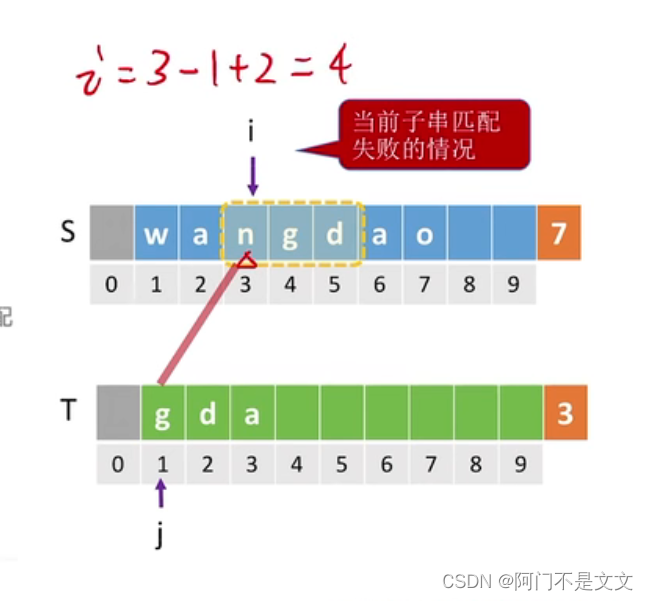

5、最坏时间复杂度

- n为主串长度,m为模式串长度,那么主串里面要检索(n-m+1)个模式串
- 如果主串中每一个字符都和模式串对不上,这时每次就遍历了m个字符
- 故时间复杂度为O(n-m+1) *m = O(nm)
4.2_2 KMP算法(上)
朴素模式匹配算法,扫描的指针i,在最坏情况的时候,前进m步,后退m-1步,再前进m步,再后退m-1步。。。针对这一情况,KMP算法做出了相应改进
1、思路
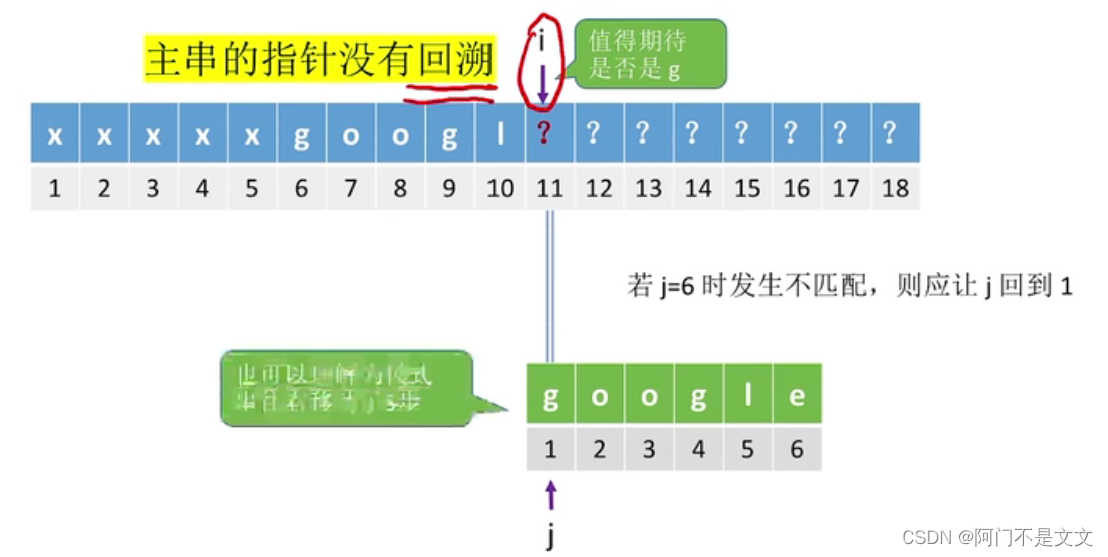
- 比如在j=6的时候发生不匹配,那么这时候i的值不变,让j的值回到1,那么此时主串的指针没有回溯
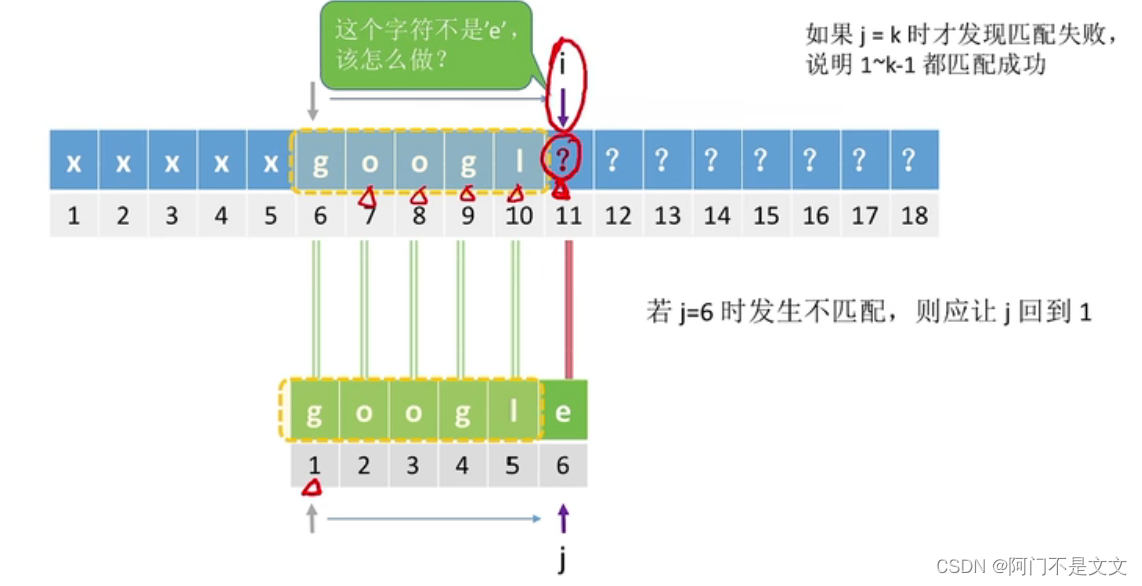
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
- 如果j=5时发生不匹配,也就是说主串的第9个位置不是l,但这个位置还有可能为o,故让j=2,回到2继续检查
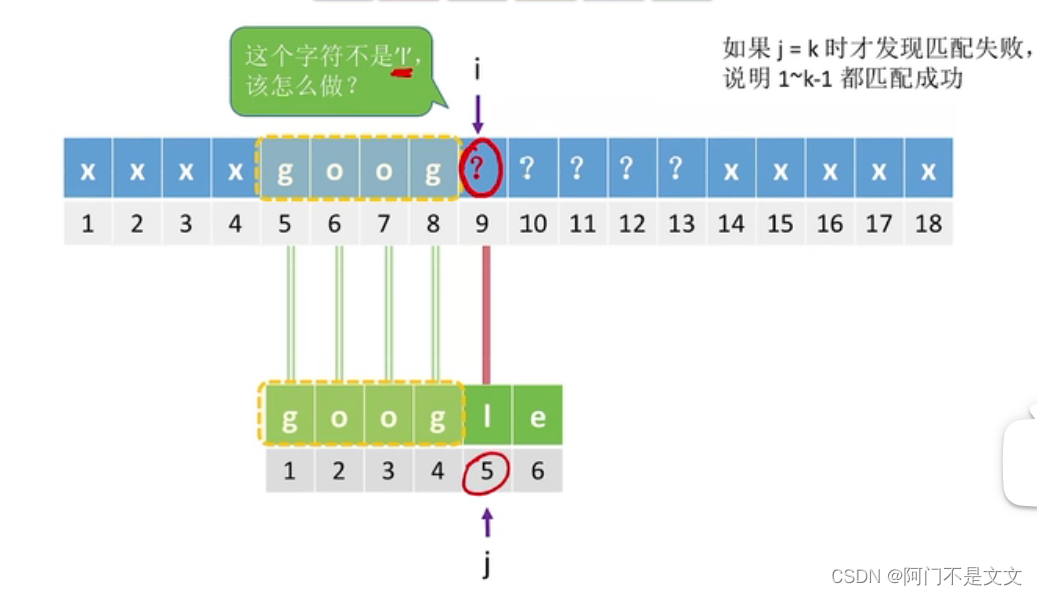
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
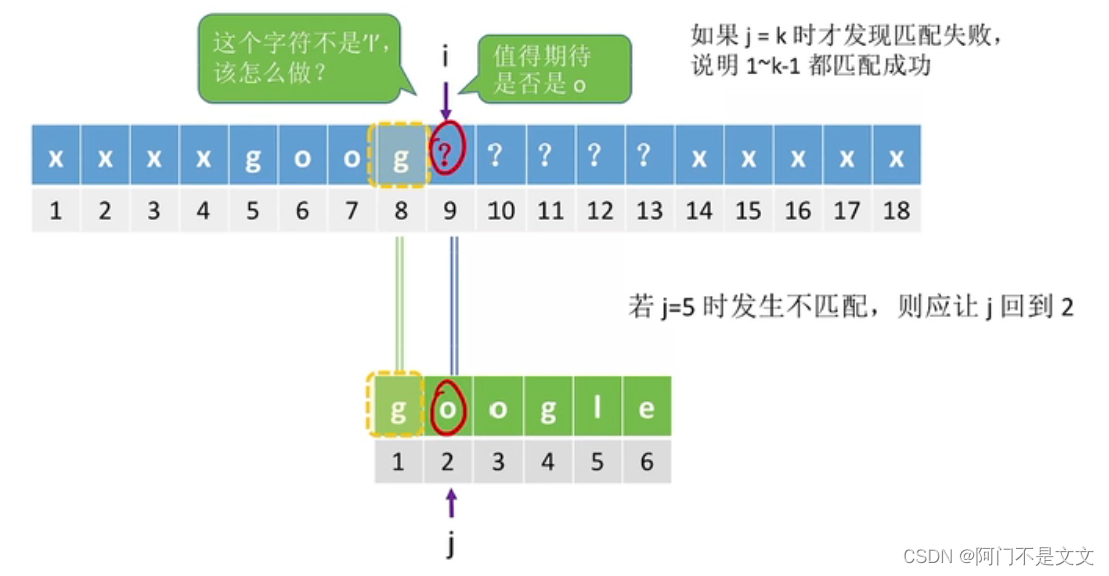
- 总结:
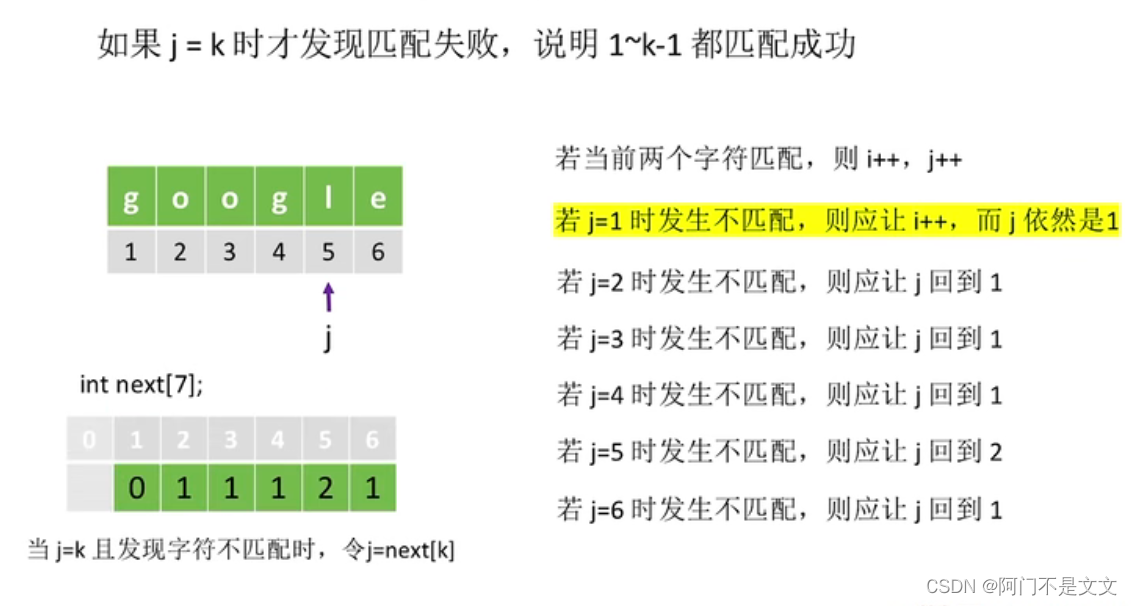
在发生不匹配的时候,每个j都对应着相应的返回地点,这里用next数组来保存这些地点,到时候不匹配时则直接调用即可
2、KMP算法代码(没有包含next数组由来)

4.2_3 KMP算法(下)—求next数组
next数组:当模式串的第j个字符匹配失败时,令模式串跳到next[j]再继续匹配
1、思路
当j=6时匹配失败:
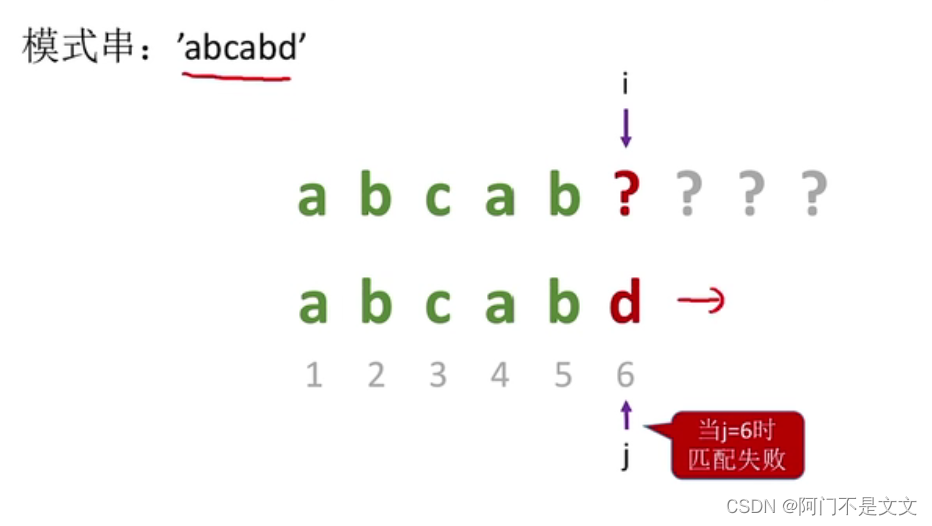
那么模式串就一直往右移,直到主串和模式串右字符串能够对上
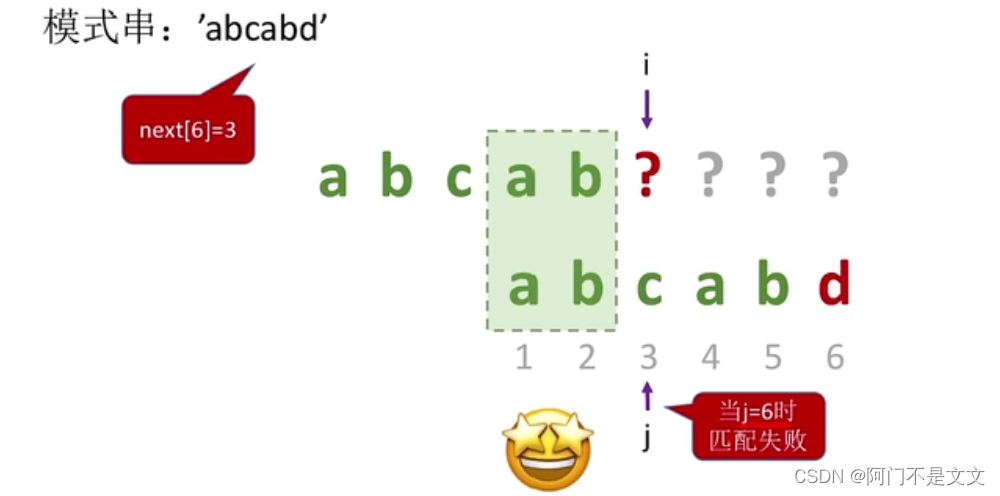
移动了3位,即next[6]=3
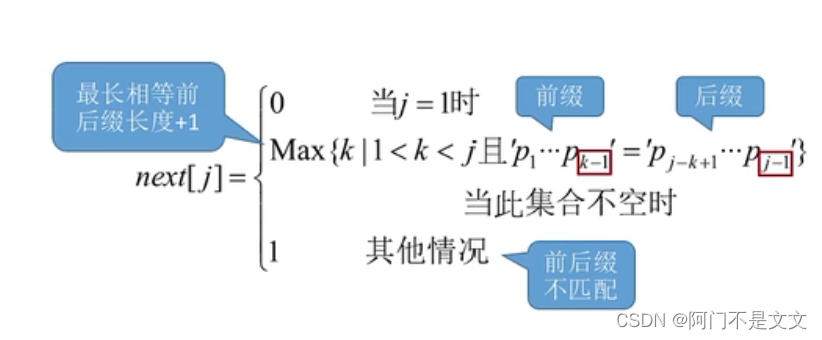
- 串的前缀:包含第一个字符,且不包含最后一个字符的子串
- 串的后缀:包含最后一个字符,且不包含第一个字符的子串
- 规律:当第j个字符匹配失败,由前1~j-1个字符组成的串即为S,则:next[j]=S的最长相等前后缀+1
2、练习:求模式串中的next数组
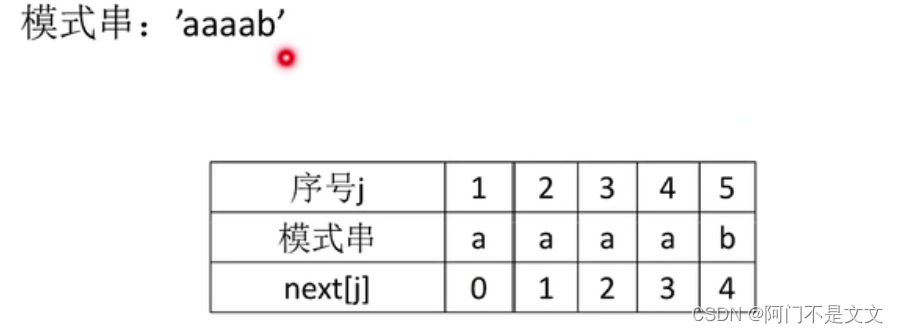
- j=1:模式串第一个就发生不匹配,那么j不变继续检查下一个字符串的第一个,next[1]=0
- j=2:模式串第二个发生不匹配,那么把这个位置的前面的所有字符拿出来:a,仅一个字符没有前后缀,故最长相等前后缀长度=0,next[2]=0+1=1
- j=1和j=2一定分别为0和1,固定不变
- j=3:模式串第3个发生不匹配,那么把这个位置的前面的所有字符拿出来:aa,前缀=后缀=a,故最长相等前后缀长度=1,next[3]=1+1=2
- j=4:模式串第4个发生不匹配,那么把这个位置的前面的所有字符拿出来:aaa,前缀=后缀=aa,最长相等前后缀长度=2,故next[4]=2+1=3
- j=5:模式串第5个发生不匹配,那么把这个位置的前面的所有字符拿出来:aaaa,前缀=后缀=aaa,最长相等前后缀长度=3,故next[5]=3+1=4
- 总结:
3、KMP算法性能分析

- 求next数组的时间复杂度:O(m)
- 求KMP算法的时间复杂度:O(n)
- KMP算法平均时间复杂度:O(m+n)
4、知识回顾与重要考点

4.2_4 KMP算法的进一步优化—nextval数组
1、KMP算法存在的问题1
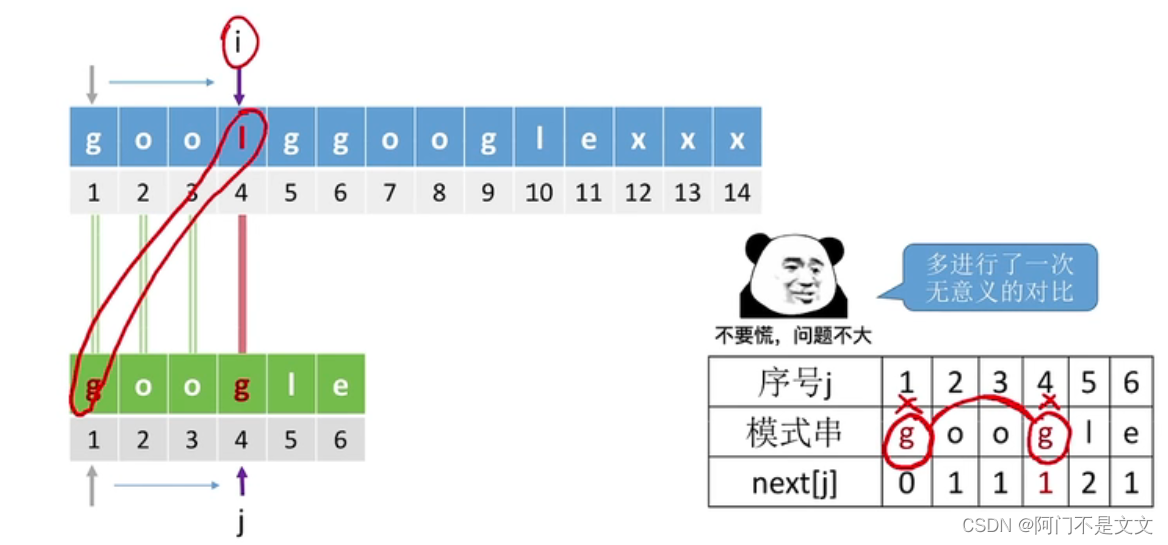
- 比如上图,j=4时,不匹配,next[j]=1
- j=4的时候,已经和g不匹配了,j再回到1,也和g不匹配,这样就进行了依次无意义的对比
- 故这种情况可以让next[4]=next[1]=0,i++
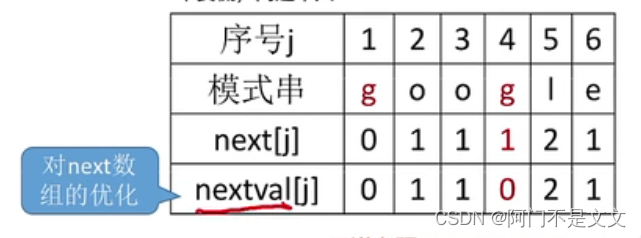
用nextval[j]来替代next[j]
2、KMP算法存在的问题2
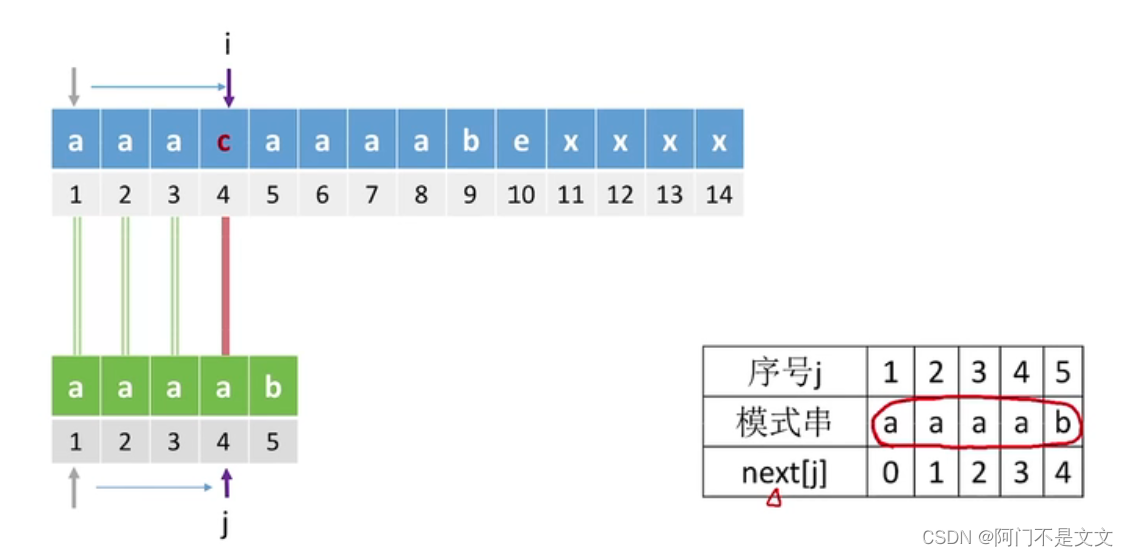
比如上图,再模式串j=4的地方发现不匹配,那么按照next数组,就会返回3(i=4,j=3)
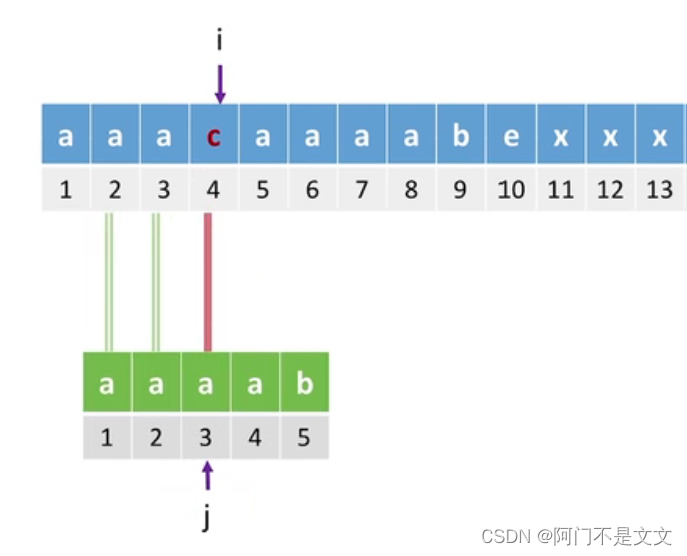
不匹配,再返回2(i=4,j=2),还不匹配,再返回1
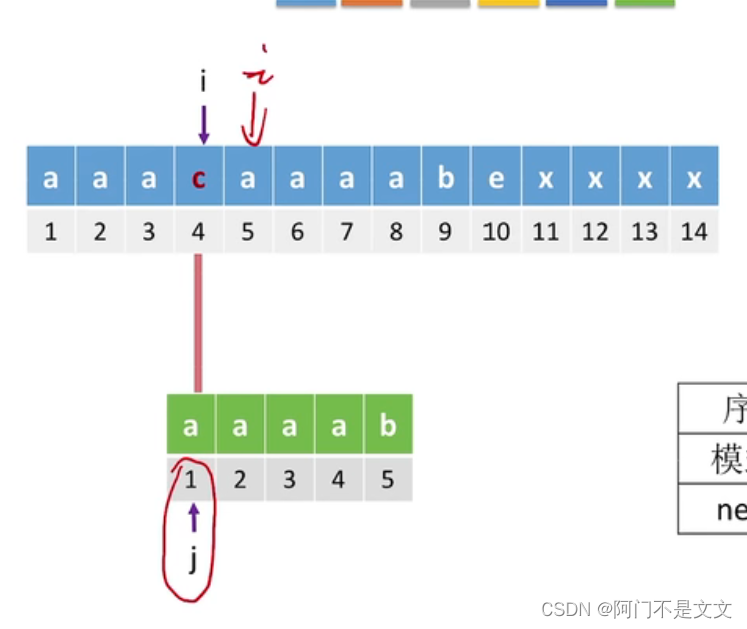
- 可以看出这一系列操作都是没有什么意义的,因为i=4的时候已经和a不匹配了,j再移到前面去和a比较是毫无意义的
- 可以推出j=4时的nextval的值可以直接和next[1]一样为0
- 故要求所有的nextval的值,最好从最左边开始,next[1]=0赋给j=2,再赋给j=3…再赋给j=4
- 又因为j=5时的字符为b,和前面的不一样,故还按照next数组的来,为4
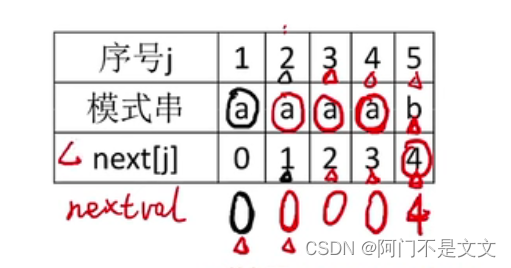
3、KMP算法考点总结

- 如果题目让我们求nextval数组,那么就先手算出next数组,再让nextval[1]=0,再往下求后面字符的nextval
- if(T.ch[next[j]]==T.ch[j]) //如果j位置的字符和j要返回位置的字符相等
- nextval[j]=nextval[next[j]] //那么j位置的nextval值就等于j要返回到字符的nextval值
- nextval[j]=next[j] //否则,就按照原来的next数组来决定返回的位置














 1647
1647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









