







BitNet b1.58 2B4T 技术报告解析
1. 引言
BitNet b1.58 2B4T 是首个开源的、原生的 1 位大型语言模型(LLM),拥有 20 亿参数规模。该模型在包含 4 万亿个标记的语料库上进行了训练,并在涵盖语言理解、数学推理、编码能力和对话能力的基准测试中进行了严格评估。结果表明,BitNet b1.58 2B4T 在性能上与类似大小的领先开源、全精度 LLM 相当,同时在计算效率方面具有显著优势,包括大幅减少内存占用、能源消耗和解码延迟。为了便于进一步研究和采用,该模型权重通过 Hugging Face 发布,并提供了针对 GPU 和 CPU 架构的开源推理实现。
2. 背景知识
开源大型语言模型(LLMs)在推动先进 AI 能力的普及、促进创新和使能自然语言处理、代码生成和视觉计算等多领域研究方面发挥了关键作用。然而,部署和推理所需的大量计算资源限制了它们的更广泛应用。现有的 1 位 LLMs 要么是应用于预训练全精度模型的后训练量化(PTQ)方法,可能导致性能显著下降;要么是原生 1 位模型(从 1 位权重开始训练),但规模相对较小,尚未能匹配更大、全精度模型的能力。
3. 研究方法
3.1 架构
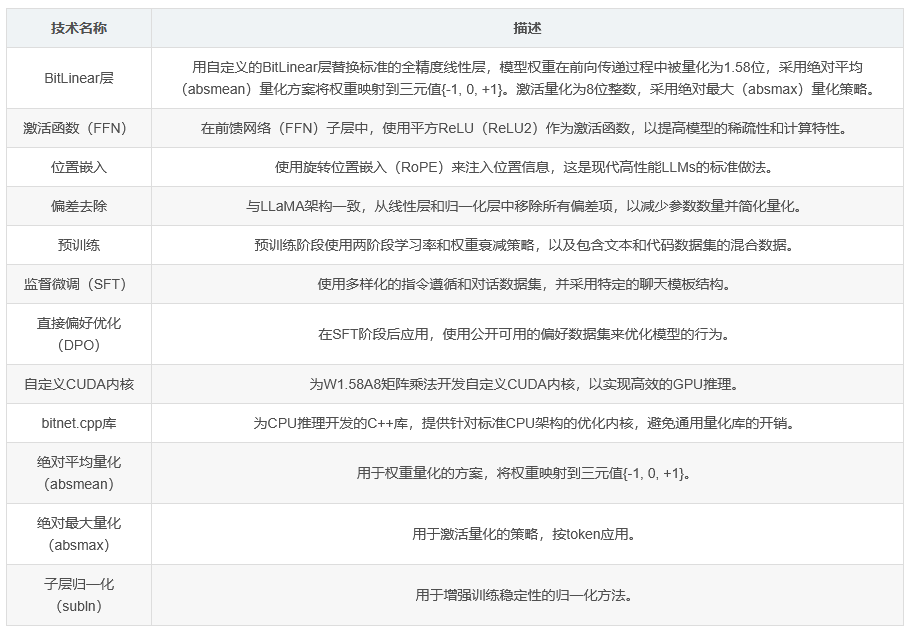
BitNet b1.58 2B4T 的架构基于标准的 Transformer 模型,但进行了多项修改以适应 1 位范式:
-
BitLinear 层:用自定义的 BitLinear 层替换标准的全精度线性层。在这些层中,模型权重在前向传递过程中被量化为 1.58 位,通过绝对平均(absmean)量化方案将权重映射到三元值 {-1, 0, +1}。激活量化为 8 位整数,采用绝对最大(absmax)量化策略。
-
其他技术:集成了激活函数(FFN)使用平方 ReLU(ReLU2)、旋转位置嵌入(RoPE)和去除偏差等技术。
3.2 训练
训练过程包括三个阶段:大规模预训练、监督微调(SFT)和直接偏好优化(DPO):
-
预训练:使用两阶段学习率和权重衰减策略,以及包含文本和代码数据集的混合数据。
-
监督微调(SFT):使用多样化的指令遵循和对话数据集,并采用特定的聊天模板结构。
-
直接偏好优化(DPO):在 SFT 阶段后应用,使用公开可用的偏好数据集来优化模型的行为。
4. 实验
4.1 评估基准
BitNet b1.58 2B4T 在多个基准测试中进行了评估,包括语言理解与推理、世界知识、阅读理解、数学与代码、指令遵循和对话等。
4.2 主要结果
BitNet b1.58 2B4T 在资源效率方面表现出显著优势,其非嵌入内存占用和解码期间的估计能源消耗远低于所有评估的全精度模型。在任务性能方面,BitNet b1.58 2B4T 在多个基准测试中表现出色,与全精度模型相比具有竞争力。
4.3 与后训练量化模型的比较
BitNet b1.58 2B4T 与使用标准 INT4 方法量化的 Qwen2.5 1.5B 模型相比,在保持更低内存需求的同时,性能优于量化模型。
4.4 与其他 1 位模型的比较
BitNet b1.58 2B4T 在与其他 1 位模型的比较中表现出色,不仅超越了较小的原生 1 位模型,还超越了参数数量更大的后训练量化模型。
5. 关键结论
BitNet b1.58 2B4T 证明了在训练过程中直接进行极端量化的可行性,并在性能与全精度模型相当的同时,显著降低了计算需求。这为在资源受限环境中部署强大的语言模型提供了可能,有望普及先进 AI 能力。
6. 未来方向
-
扩展模型规模:研究原生 1 位 LLMs 的扩展特性,训练更大规模的模型。
-
硬件协同设计:开发针对现有硬件的高度优化内核,并设计专门针对 1 位计算的硬件加速器。
-
支持更长序列长度:扩展模型可处理的最大序列长度,以改进长文档处理和复杂问题解决任务的性能。
-
多语言能力:扩展预训练语料库并适应多语言。
-
多模态集成:探索 1 位原则在多模态架构中的应用。
-
理论理解:深入研究 1 位训练的理论基础。
7. 关键技术


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









