







MAGI-1论文解读
一、论文概述
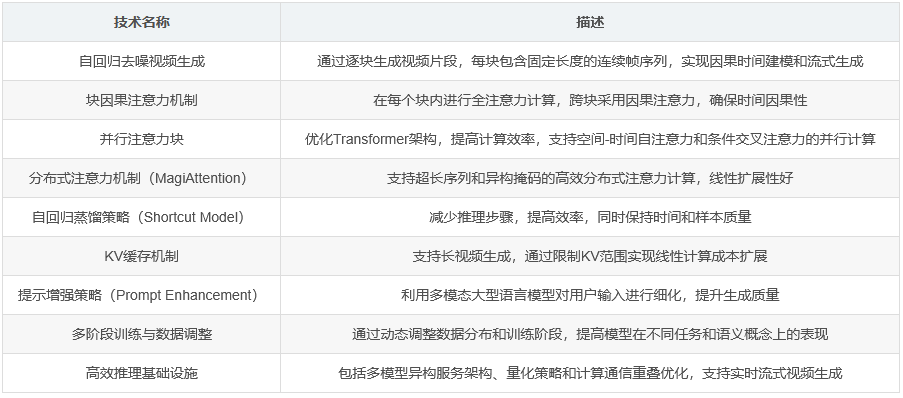
MAGI-1是一种新型的自回归视频生成模型,具有240亿参数,可处理长达4百万个token的上下文。该模型基于扩散模型,通过自回归的方式逐块生成视频片段,能够实现文本到视频、图像到视频和视频续写等多种任务。
二、研究背景与动机
随着视频成为人类沟通和机器理解的主要媒介,对高质量生成模型的需求日益增长。现有扩散模型在处理视频时,通常采用全局条件去噪架构,这种架构要求同时处理整个时间序列,忽略了时间数据的因果结构,导致其不适合于流式传输、实时交互等场景。
三、研究方法
3.1 自回归去噪视频生成模型
MAGI-1采用基于流匹配的训练目标,每个视频块被赋予独立的高斯噪声,噪声级随时间单调递增。模型训练时,每个块的噪声级被约束为严格递增,从而实现因果时间建模。该模型使用基于Transformer的架构,支持双向空间和因果时间去噪。
3.2 模型架构创新
MAGI-1引入了块因果注意力机制和并行注意力块,优化了Transformer架构,使其更适合自回归建模。模型采用QK归一化和分组查询注意力(GQA),以提高训练稳定性和减少内存消耗。
3.3 训练策略
MAGI-1的训练分为多个阶段,逐步提高数据分辨率和视频长度。在训练过程中,通过动态调整数据分布,加强模型在语义对齐和物理合理性交互等较难任务上的表现。
四、实验和评估
4.1 评估方法
论文采用内部指标和公共基准测试对MAGI-1进行评估,重点关注图像到视频生成任务的提示保真度、时间连贯性和主体完整性。
4.2 关键结论
MAGI-1在VBench-I2V和Physics-IQ基准测试中取得显著改进,尤其在合成复杂运动、保持语义对齐和模拟物理合理交互方面表现出色。该模型证明了其在高质量生成性能和实时适用性之间的桥梁作用。
五、基础设施创新
5.1 分布式注意力机制(MagiAttention)
MagiAttention是为超长自回归上下文定制的分布式注意力机制,支持灵活的注意力掩码,并针对长序列进行了优化。
5.2 训练与推理基础设施
论文详细介绍了为MAGI-1开发的训练和推理基础设施,包括用于高效训练的分布式打包和填充策略,以及用于实时流式视频生成的多模型异构服务架构。
六、限制与未来工作
尽管MAGI-1在生成质量和低延迟推理方面表现出色,但其架构紧密耦合,存在推理延迟瓶颈和优化冲突等问题。未来的工作将探索解耦设计,并进一步提升模型的可控性和生成质量。
核心技术汇总

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









