







《YaRN: Efficient Context Window Extension of Large Language Models》论文讲解
一、研究背景
大型语言模型(LLM)在众多自然语言处理(NLP)任务中发挥着关键作用,但其在训练过程中确定的最大序列长度(上下文窗口)限制了模型的性能。能够通过少量微调(或无需微调)动态扩展上下文窗口变得越来越重要。论文聚焦于基于 Transformer 的 LLM 的位置编码方案,尤其是旋转变换位置编码(RoPE),并指出现有方法在超出训练时的上下文窗口长度时泛化能力不足。
二、研究方法
-
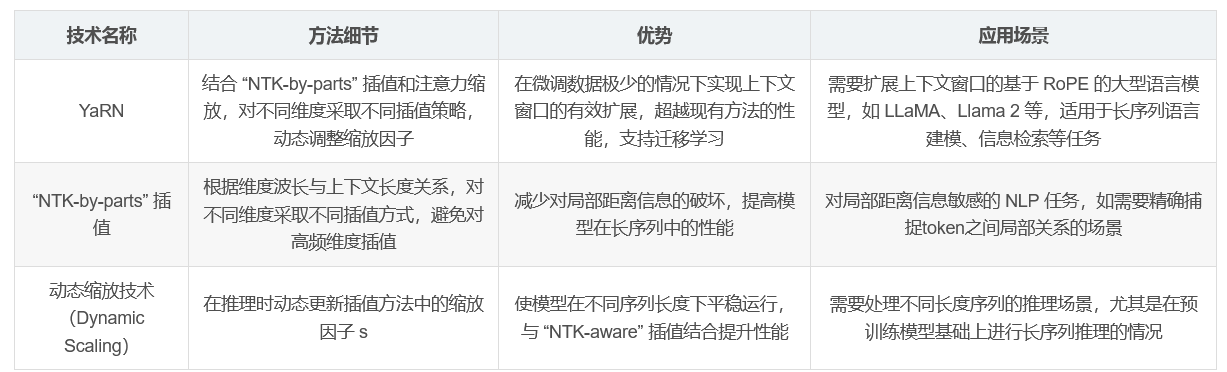
YaRN 方法介绍 :YaRN 是一种改进的 RoPE 扩展方法,通过结合 “NTK-by-parts” 插值和注意力缩放技术,在微调数据量极少的情况下(约 0.1% 的原始预训练数据)就能实现上下文窗口的有效扩展。
-
RoPE 编码原理 :RoPE 将隐藏层的神经元视为复向量空间,通过旋转操作将查询向量和键向量与相对位置信息关联起来,但直接扩展 RoPE 的序列长度会导致性能下降。
-
位置插值方法演进 :
-
位置插值(PI) :通过修改 RoPE 公式,在预训练模型的基础上进行微调,以实现上下文窗口扩展,但存在对短上下文性能影响等问题。
-
“NTK-aware” 插值 :为解决 PI 方法在插值过程中丢失高频信息的问题,通过改变基底 b 来分散插值压力,但存在部分维度插值值超出边界等问题。
-
“NTK-by-parts” 插值 :根据不同维度的波长与上下文长度的关系,对不同维度采取不同的插值策略,避免对高频维度的插值,减少对局部距离信息的破坏。
-
-
动态缩放技术(Dynamic Scaling) :在推理过程中动态更新插值方法中的缩放因子 s,使模型在不同序列长度下能更平稳地运行,与 “NTK-aware” 插值结合形成 “Dynamic NTK” 插值。
三、实验设计
-
训练设置 :对 Llama 2 的 7B 和 13B 参数模型进行扩展,使用 AdamW 优化器,学习率为 2×10−5,在 PG19 数据集上进行微调,分别设置扩展因子 s 为 16 和 32 进行训练。
-
评估指标 :
-
困惑度(Perplexity) :使用滑动窗口方法计算长文档的困惑度,评估模型在不同上下文窗口长度下的语言建模性能。
-
密钥检索任务(Passkey Retrieval) :衡量模型在大量无意义文本中检索简单密钥(五位数字)的能力,评估模型对长序列中特定信息的获取能力。
-
标准化基准测试 :采用 Hugging Face Open LLM Leaderboard 上的四个公共基准测试(ARC-Challenge、HellaSwag、MMLU、TruthfulQA),比较不同上下文窗口扩展方法对模型性能的影响。
-
四、关键结论
-
上下文窗口扩展效果 :YaRN 方法在仅使用约 0.1% 的原始预训练数据进行微调的情况下,成功实现了 Llama 2 模型上下文窗口的扩展,将有效的上下文大小扩展到 128k,并且在扩展后的上下文窗口范围内模型性能表现良好,困惑度持续下降。
-
与现有方法对比 :相较于 PI 和 “NTK-aware” 方法,YaRN 在长序列语言建模性能、密钥检索任务以及标准化基准测试中均展现出更优异的性能,且在微调和非微调场景下均超越了以往的所有方法。
-
迁移学习能力 :YaRN 支持在训练时使用比数据集长度更高的扩展因子 s,通过从 s=16 到 s=32 的迭代扩展,证明了其在计算资源受限情况下高效的迁移学习能力,能够在较短的训练数据上进行微调并成功泛化到更长的上下文长度。
五、技术总结
论文提出了一种名为 YaRN 的上下文窗口扩展方法,通过结合 “NTK-by-parts” 插值和注意力缩放技术,有效地解决了现有 RoPE 扩展方法中存在的问题,实现了在少量微调数据下的高效上下文窗口扩展,并在多个评估指标上取得了优于现有方法的性能。
六、核心技术表格汇总



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











