







一、模型概述
BitNet b1.58-2B-4T 是由微软研究院开发的首个开源的原生 1 位大规模语言模型(LLM),具有约 20 亿参数规模。该模型在 4 万亿个标记的语料库上进行了训练,展示了原生 1 位 LLM 在性能上可以与同规模的领先开源全精度模型相媲美,同时在计算效率(内存、能耗、延迟)方面具有显著优势。
1.1 模型特点
-
架构:基于 Transformer,采用了 BitNet 框架的修改层(BitLinear)。
-
量化策略:使用原生 1.58 位权重和 8 位激活(W1.58A8),权重在前向传播中被量化为三元值 {-1, 0, +1},激活值被量化为 8 位整数。
-
训练方式:从零开始训练,而非后训练量化。
-
性能表现:在多个基准测试中表现优异,与同规模的全精度模型相比具有竞争力。
1.2 模型版本
-
microsoft/bitnet-b1.58-2B-4T:包含优化的 1.58 位权重,适用于高效推理。
-
microsoft/bitnet-b1.58-2B-4T-bf16:包含 BF16 格式的主权重,仅用于训练或微调。
-
microsoft/bitnet-b1.58-2B-4T-gguf:包含 GGUF 格式的模型权重,适用于 CPU 推理。
二、技术细节
2.1 架构设计
BitNet b1.58-2B-4T 的架构基于 Transformer,但进行了以下修改:
-
BitLinear 层:用于实现 1 位量化。
-
Rotary Position Embeddings (RoPE):用于处理位置信息。
-
Squared ReLU (ReLU²):在 FFN 层中使用平方 ReLU 激活函数。
-
Subln 归一化:采用子层归一化。
-
无偏置项:线性层和归一化层中均无偏置项。
2.2 量化方法
-
权重量化:使用绝对均值量化(absmean quantization)将权重量化为 {-1, 0, +1}。
-
激活量化:使用绝对最大值量化(absmax quantization)将激活值量化为 8 位整数。
2.3 训练阶段
BitNet b1.58-2B-4T 的训练分为三个阶段:
-
预训练:在公共文本/代码和合成数学数据上进行大规模训练,采用两阶段学习率和权重衰减计划。
-
监督微调(SFT):在指令遵循和对话数据集上进行微调,使用求和损失聚合和特定超参数调整。
-
直接偏好优化(DPO):通过偏好对与人类偏好对齐。
2.4 Tokenizer
该模型使用 LLaMA 3 的 Tokenizer,词汇表大小为 128,256。
三、性能表现
3.1 效率优势
BitNet b1.58-2B-4T 在内存占用、延迟和能耗方面表现出显著优势:
-
内存占用:非嵌入部分仅为 0.4GB,远低于其他同规模模型。
-
延迟:在 CPU 解码时,延迟仅为 29ms。
-
能耗:估计能耗为 0.028J,显著低于其他模型。
3.2 基准测试结果
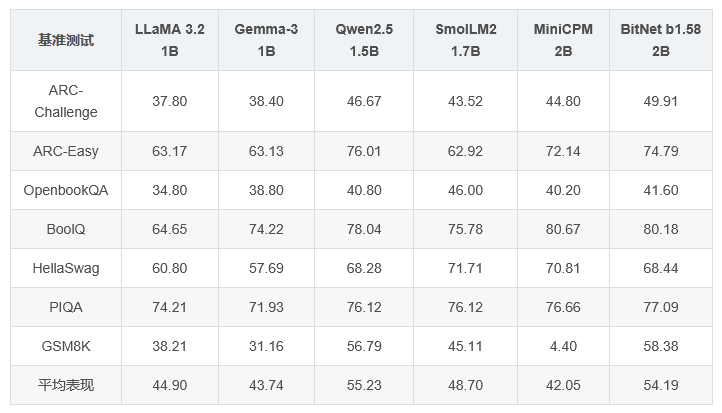
BitNet b1.58-2B 在多个基准测试中表现优异,以下为部分关键结果:
四、使用方法
4.1 使用 transformers 库
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "microsoft/bitnet-b1.58-2B-4T"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16)
messages = [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "How are you?"}
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
chat_input = tokenizer(prompt, return_tensors="pt").to(model.device)
chat_outputs = model.generate(**chat_input, max_new_tokens=50)
response = tokenizer.decode(chat_outputs[0][chat_input['input_ids'].shape[-1]:], skip_special_tokens=True)
print("\nAssistant Response:", response)
4.2 使用 bitnet.cpp
BitNet b1.58-2B-4T 的高效实现需要使用专门的 C++ 实现(bitnet.cpp)。以下是使用步骤:
-
安装依赖:参考 bitnet.cpp GitHub 仓库的编译步骤。
-
运行推理:使用命令行选项进行推理。
五、注意事项
5.1 效率声明
-
使用标准 transformers 库时,无法获得 BitNet 的效率优势,因为 transformers 的执行路径未包含专门优化的计算内核。
-
要实现论文中展示的效率优势,必须使用 bitnet.cpp 实现。
5.2 许可与免责声明
-
模型权重和代码在 MIT 许可下发布。
-
该模型适用于研究和开发目的,尽管经过 SFT 和 DPO 对齐,但仍可能生成意外、有偏见或不准确的输出。请谨慎使用。
六、总结
BitNet b1.58-2B-4T 作为首个开源的原生 1 位大规模语言模型,在性能和效率方面展现了显著优势。其创新的量化策略和高效实现为大规模语言模型的部署提供了新的可能性。然而,用户在使用时需注意其适用场景和实现方式,以充分发挥其潜力。

















 186
186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









