







目录
一、Apache Hive介绍
(1)Hive概述
对数据进行统计分析可以使用两类工具,一类是编程语言(python、java),一类是SQL语言。从目前来讲,SQL在数据统计分析方面更具有优势,但是前面所学的Hadoop MapReduce分布式计算框架是基于编程语言的,不支持SQL。Apache Hive是一款分布式SQL计算工具,它可以实现将SQL语句翻译成MapReduce程序运行,既程序编写时用简单的SQL写,执行时是MapReduce程序,因此Hive就像翻译官一样,为用户提供了分布式SQL计算的能力。

问题:为什么SQL在数据统计分析方面有优势呢?
回答:使用MapReduce等不支持SQL语言的工具时,需要掌握复杂的java,python等编程语言的语法,且编程语言实现复杂查询逻辑开发难度大。使用SQL简单,易上手,逻辑清晰。
总结:分布式SQL计算就是以分布式的形式,执行SQL语句,进行数据统计分析
MapReduce开发:程序员写复杂的java、python代码---->得到数据分析的结果
Hive开发:程序员写简单的SQL代码------>得到和上述一致的数据分析结果
底层都是MapReduce在运行,但Hive的使用更简单
(2)分布式SQL计算的核心组件
假设让我们设计Hive这款软件,需要实现哪些功能呢?
支持用户编写SQL语句
自动将SQL转换为MapReduce程序并提交给YARN运行
处理HDFS上的结构化数据(表格)
例如有如下结构化文本数据存储在HDFS中,现在要使用SQL语言实现城市人口计数的功能。

假设程序员写了一句SQL:select city, count(*) from t_user group by city; 在将其翻译成MapReduce程序时,会遇到那些问题呢?
数据文件在哪里? # 写SQL时,只会给出从t_user表中查找,并没有具体给出
t_user文件在HDFS的什么地方。
那些列可以作为city使用? # 在HDFS上存储的表格数据,只会记录表格的内容,其他
信息不会记录。
city列是什么数据类型?
使用什么符号作为列的分隔符? # 没有指定分隔符,计算机并不认识“,”,它会将“,”
作为文本的内容去处理
想要实现SQL语句向MapReduce程序的转化,不单单要提供SQL语句,上述问题所需的信息都必须要额外提供。因此我们需要额外记录一些信息,并将这些信息保存起来,方便后续使用。
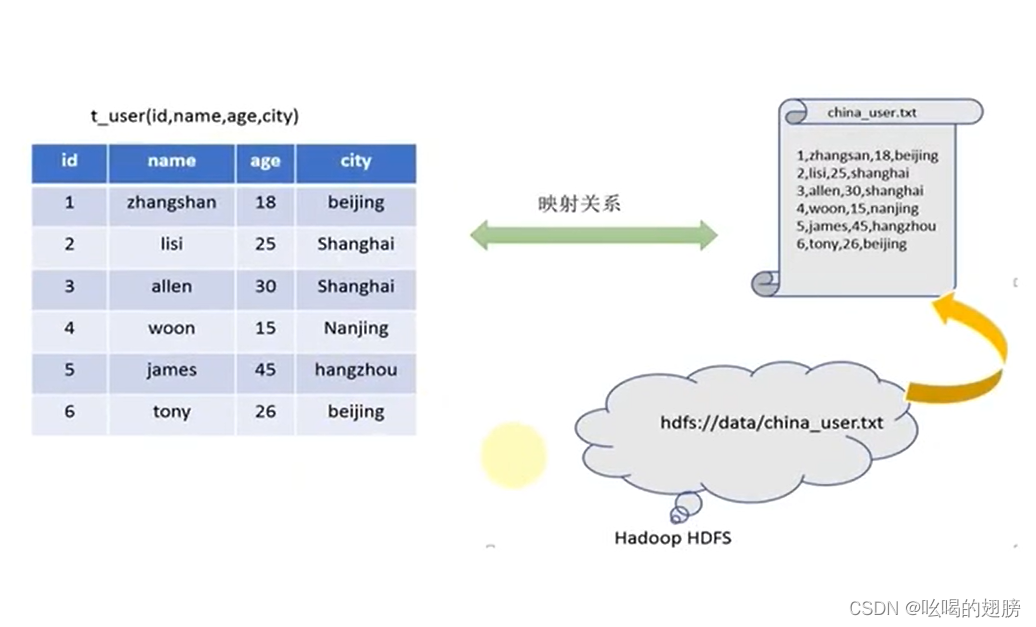
首先将HDFS中的文件与数据库中创建的表t_user建立映射关系,然后记录HDFS文件的具体位置信息hdfs://data/china_user.txt,最后将这些信息保存在数据库中,这些额外记录的信息我们将其称为元数据。
元数据管理的功能就是对数据位置信息,数据结构信息,数据描述信息进行记录,它是分布式SQL计算的一个核心组件。
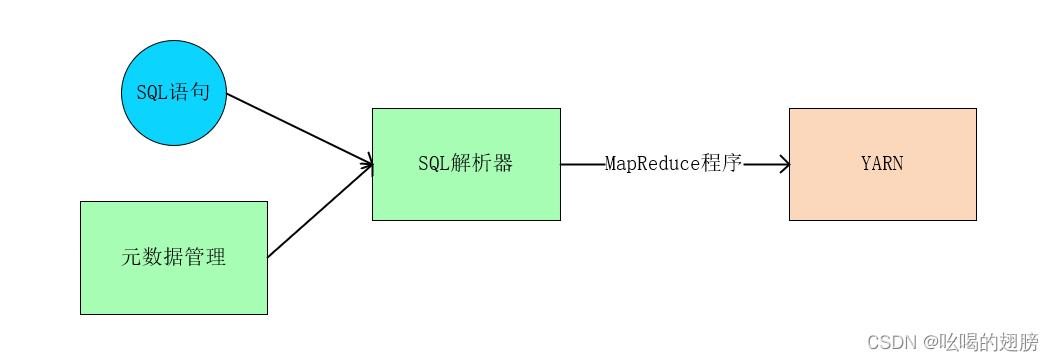
元数据管理提供了在SQL向MapReduce转换过程中的辅助信息,显然只有元数据管理是不够的,目前只是准备工作做完了,还缺少一个能实现SQL到MapReduce转换的解析器------SQL解析器------分布式计算的核心组件。
SQL解析器功能:
SQL分析,检查其语法。
SQL到MapReduce程序的转换
提交MapReduce程序在YARN中运行并收集执行结果

总结:分布式SQL计算的核心组件是:
元数据管理:帮助记录各种元数据
SQL解析器:完成SQL到MapReduce程序的转换
(3)Hive的基础架构
Hive作为一款很火的分布式SQL计算工具,同样由元数据管理组件,SQL解析器组件以及其他一些小功能组件组成。

1)红框为元数据管理组件
Hive提供了Metastore服务进程实现元数据的记录,并将记录保存到数据库中。
2)黄框为SQL解析器
结合元数据和SQL代码,完成语法解析、执行计划编排、最终代码优化、并将转换后的程序提交到YARN中运行。
3)篮框为一些小功能组件(用户接口)
提供命令行接口,使用户可以在命令行中实现SQL开发;提供WEB接口,使用户在WEB上完成对Hive的控制。这些小功能组件主要用于方面用户去使用Hive的一系列工具。
注意:Hive框架是单机运行的,只需要在一台服务器上部署即可,经Hive产生的MapReduce程序的运行是分布式的。
二、Apache Hive部署
规划:

(1)在Vmware Workstation上部署Hive
1)安装MySQL
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
yum -y install mysql-community-server
systemctl start mysqld
systemctl enable mysqld
systemctl status mysqld
grep 'temporary password' /var/log/mysqld.log
mysql -uroot -p
set global validate_password_policy=LOW;
set global validate_password_length=4;
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
grant all privileges on *.* to root@"IP地址/%" identified by '123456' with grant option;
flush privileges;
exit
2)配置Hadoop代理
Hive的运行依赖于Hadoop的HDFS、MapReduce和YARN,在运行过程中会涉及到HDFS文件系统的访问,因此需要设置Hadoop的代理用户,既设置hadoop用户允许那些用户代理。只有这样Hive才有权限去访问HDFS。
在core-site.xml中增加如下内容,并分发到其他节点,且重启HDFS:
#配置该hadoop用户允许通过代理访问的主机节点
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
# 配置该hadoop用户允许代理的用户所属组
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
3)Hive安装
# 下载Hive安装包
http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /export/server/
ln -s /export/server/apache-hive-3.1.3-bin /export/server/hive
# 下载MySQL驱动包
https://repo1/maven.org/maven2/mysql/mysql-connector-java/5.1.34/mysql-connector-
java-5.1.34.jar
mv mysql-connector-java-5.1.34.jar /export/server/hive/lib/
4)Hive配置
在Hive的conf目录中(都是一些模板文件),新建hive-env.sh文件(conf文件中会有hive-env.sh.template模板文件,将其改名即可mv hive-env.sh.template hive-env.sh),并写入:
export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
在Hive的conf目录中,新建hive-site.xml文件,并写入:

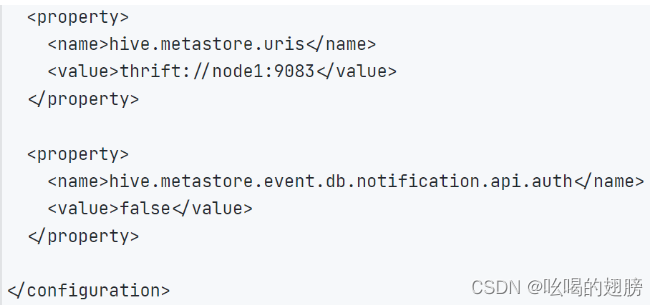
Hive中记录的元数据会保存到MySQL数据库中,因此Hive会与MySQL建立联系
javax.jdo.option.ConnectionURL : 设置MySQL的连接地址
javax.jdo.option.ConnectionDriverName : 指明MySQL驱动
javax.jdo.option.ConnectionUserName : 连接MySQL的账号与密码
javax.jdo.option.ConnectionPassword
hive.metastore.uris : 设置Hive的元数据服务绑定
上述配置完成后,需要初始化Hive所需的元数据库(与HDFS的第一次启动一样需要初始化NameNode)
create database hive charset utf8;
cd /export/server/hive
bin/schematool -initSchema -dbType mysql -verbos
初始化完成后,会在MySQL的hive库中新建74张元数据管理的表。
5)启动Hive
chown -R hadoop:hadoop apache-hive-3.1.3-bin hive
su - hadoop
mkdir /export/server/hive/logs
# 启动元数据管理服务
hive --service metastore # 前台启动
nohup hive --service metastore >> logs/metastore.log 2>&1 & # 后台启动
# 启动客户端(启动Hive)
Hive Shell方式(可以直接写SQL) : bin/hive
Hive ThriftServer方式(不能直接写SQL,需要外部客户端连接使用): bin/hive --service
hiveserver2
(2)在阿里云上部署Hive
阿里云平台上会提供关系型数据库服务RDS(云数据库),因此我们无需手动搭建MySQL服务,只需要花钱租一个云数据库即可。


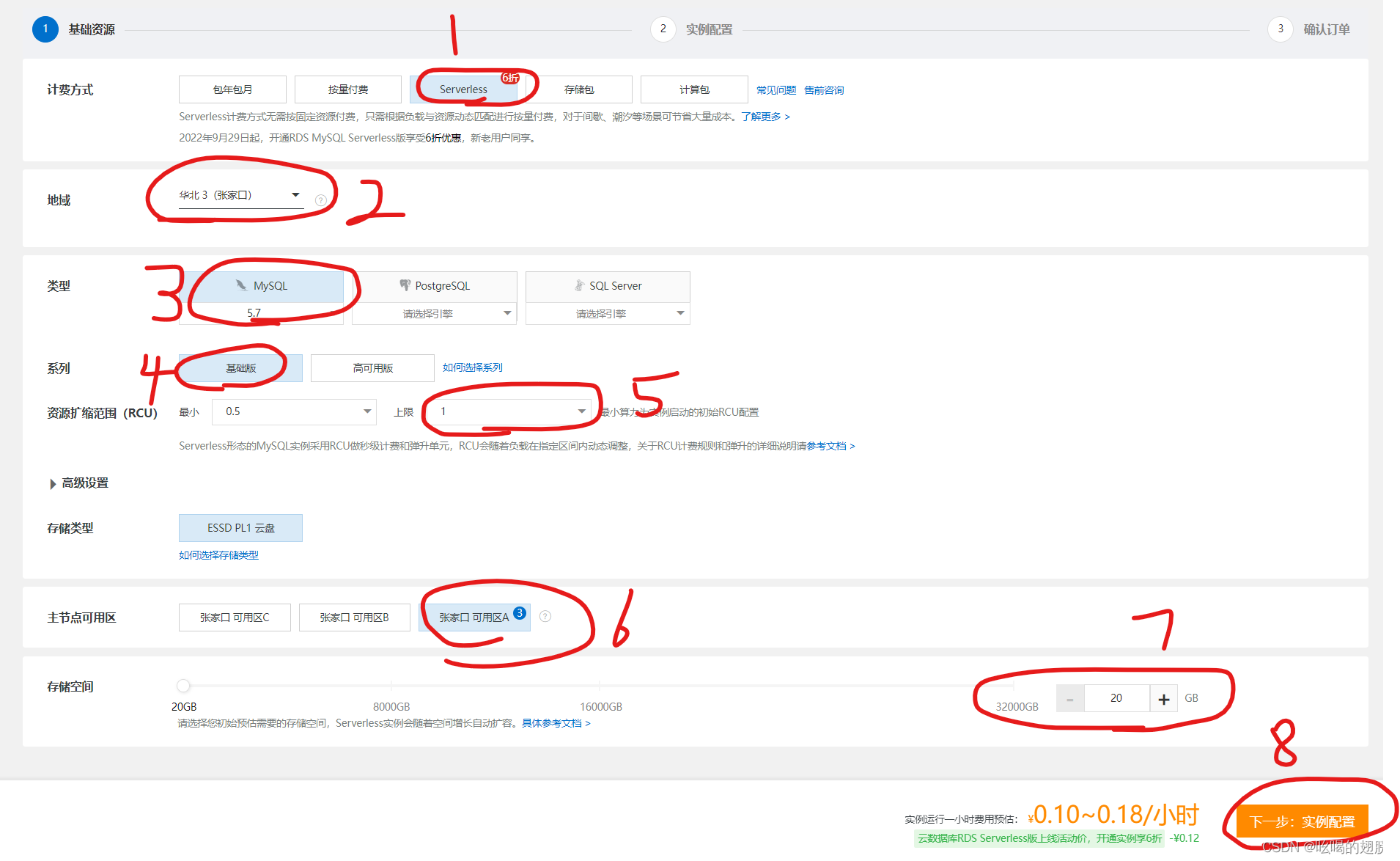
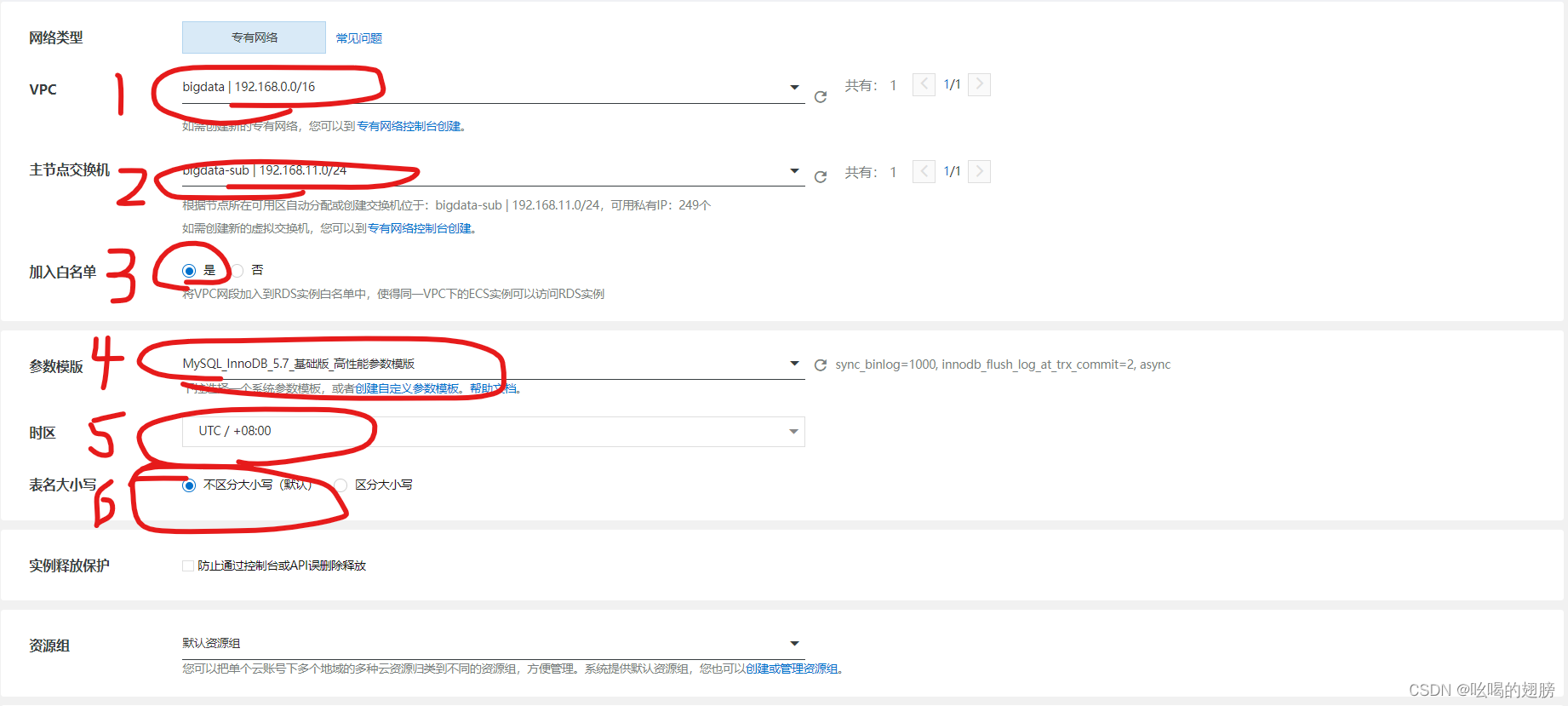
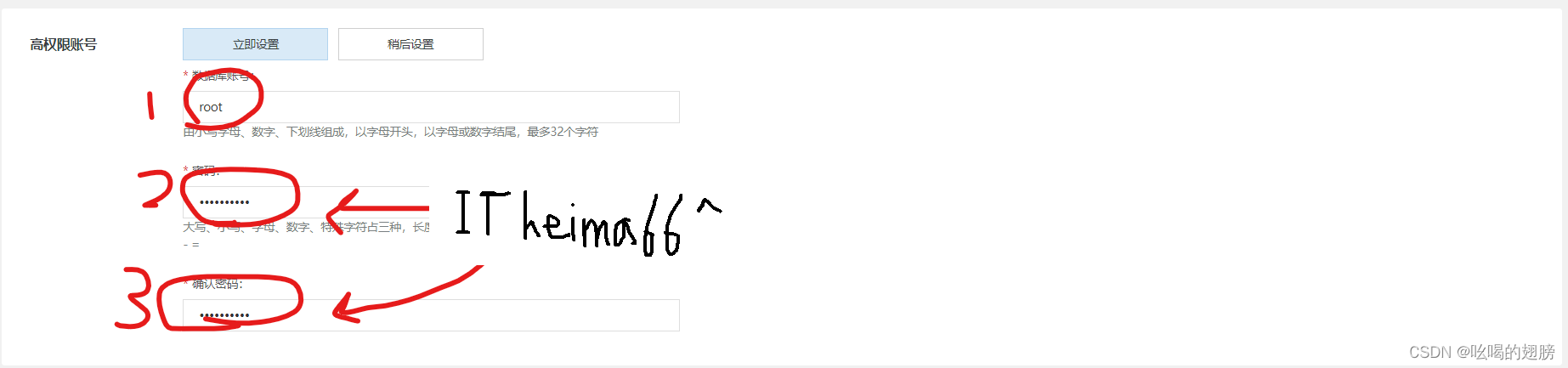

等待一会MySQL云数据库就创建好了。
接下来就可以在云上配置Hive了,步骤与在虚拟机上的一样,不同的是在hive-site.xml中配置MySQL连接地址和账户密码的时候,需要和创建的云数据库一致。
查看已创建的云数据库内网地址:

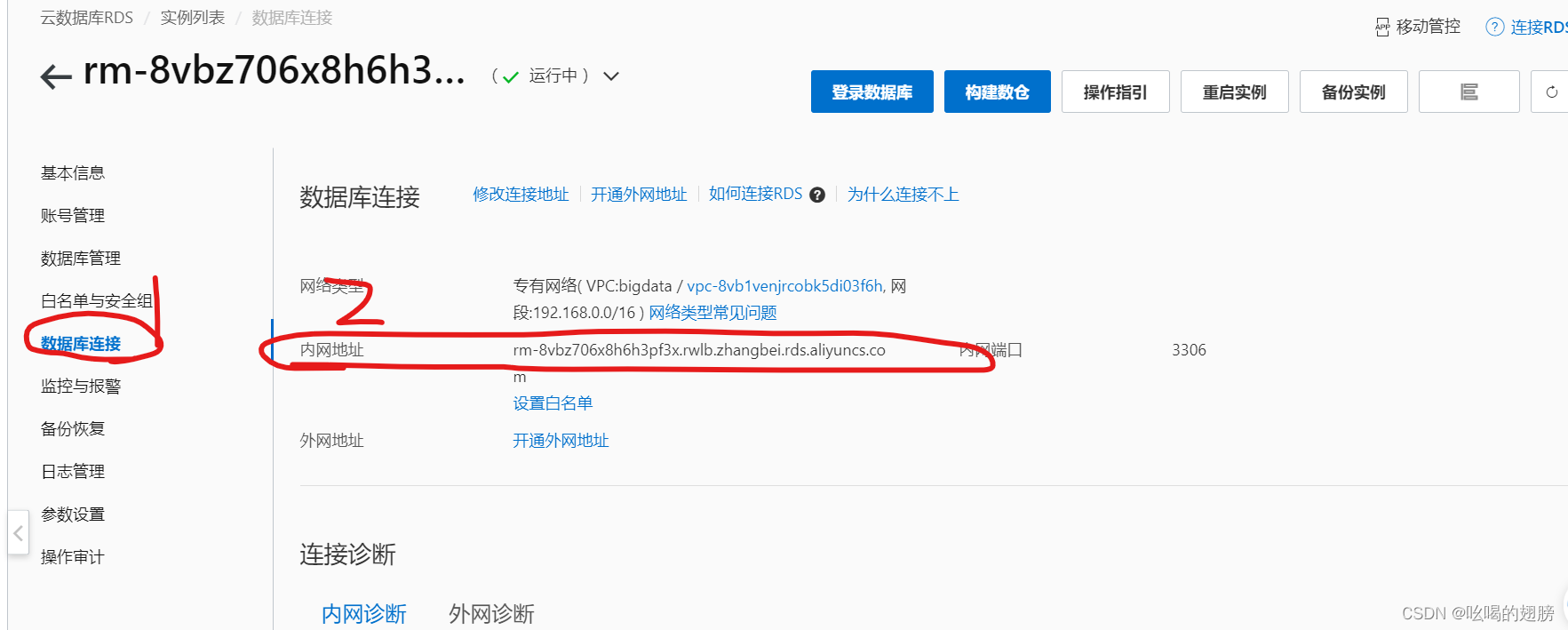
配置Hive:
hive-site.xml文件:

配置好后需要初始化MySQL云数据库,但是该数据库并不在node11服务器上,直接使用mysql -uroot -p无法登录,因此需要在node11上安装MySQL的客户端(类似与pycharm),然后利用云数据库的内外地址进行远程连接。
yum install -y mysql
mysql -uroot -p -h 内网地址
进入到MySQL云数据库后就可以初始化了。后续操作与虚拟机一样。
(3)在Ucloud上部署Hive
在Ucloud云平台上有UDB(Ucloud database)与阿里云的RDS一样。




利用该IP地址实现远程连接(同阿里云中的内网地址),后续操作与阿里云一样
三、Apache Hive初体验
首先进入到Hive的Shell环境中(在Hive Shell中对中文不太友好,且写SQL语句极其不方便)
create table test(id int, name string, gender string);
进入Hive后默认会有一个default数据库,如果我们的操作没有指定数据库,系统会自动在
default数据库中执行。
insert into test values(1, '王力宏', '男');
在mysql中执行上述插入语句几乎一瞬间就能完成,但是在Hive中执行怎么简单的插入语句却用了很长时间。


可以看出在Hive上,SQL语句是以MapReduce程序的方式运行的,上述insert语句首先经Hive转换为MapReduce程序,然后将其提交到YARN中运行,因此运行起来会很慢很慢。
insert into test values(2, '周杰伦', '男'),(3, '林俊杰', '女');
在Hive中不是所有的SQL都会先转化为MapReduce,然后在执行,太简单的SQL会直接输出,例如全表查询:
select * from test;
但是只要SQL语句中有计算过程稍微复杂点就会走MapReduce程序例如:
select gender, count(*) as cnt from test group by gender;
在YARN的WEB UI界面我们也可以看到上述运行的MapReduce程序(node11:8088)

注意:看起开Hive在运行时使用的是default数据库中test表的数据,实际上test表的数据会自动存储到HDFS文件系统的/user/hive/warehouse目录下,Hive使用的数据是HDFS文件系统中的数据。

SQL在运行过程中使用的元数据保存在MySQL数据库的hive数据库的74个表中,这些表分别记录了各种不同的元数据。

四、Apache Hive的客户端
(1)HiveServer2&Beeline
前面我们提到Hive的启动方式有两种:
bin/hive # Hive Shell方式启动Hive,可以直接写SQL
bin/hive --service hiveserver2 # 启动hiveserver2服务,不能直接写SQL
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
Hiveserver2是Hive内置的一个ThriftServer服务,提供Thrift端口供其他客户端连接Hive。Hiveserver2就像一个中介一样,将客户端与Hive建立联系。
例如:Hive内置的beeline客户端工具(命令行工具),第三方的图形化SQL工具DataGrip,DBeaver,Navicat等都可以通过Hiveserver2服务连接到Hive。


步骤:
1)后台启动metastore服务,后台启动hiveserver2服务,启动完成后输入jps会看到两个
Runjar进程17878为metastore服务,19687为hiveserver2服务
netstat -anp|grep 10000

10000端口就是hiveserver2提供的Thrift端口,客户端可以通过该端口连接Hive。
2)启动beeline
beeline同样是Hive内置的,因此直接运行/expoert/server/hive/bin/beeline命令就可以
启动它

3)连接10000端口,即连接hiveserver2服务
!connect jdbc:hive2://node11:10000
输入登录用户hadoop
连接成功:(之后就可以在beeline中写SQL语句了)

(2)DataGrip&DBeaver
1)DataGrip连接Hive
首先开启metastore与hiveserver2服务
打开DataGrip,新建一个project


2)DBeaver
首先开启metastore与hiveserver2服务
打开DBeaver


添加新库,DBeaver内置的库有问题
![]()
测试连接,然后确定,就连接成功了。














 6638
6638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









