






1.前言
本文利用LSTM(长短期记忆网络)模型对某只股票的历史数据进行回测,使用2005年至2024年1月17日的全部数据,预测2024年1月18日该股票的走势。该段代码具有较强的通用性,不仅适用于本次研究所选股票,还可以灵活应用于其他股票的走势预测,为股票市场的量化分析提供了一种有效的方法。通过对模型的训练和验证,该方法能够捕捉数据中的时间序列特征,从而对未来走势作出合理预测。这种基于深度学习的预测手段在金融数据分析中具有广阔的应用前景。
2.代码实现
2.1.加载数据
raw_data = pd.read_csv('*.csv', index_col = 0, parse_dates = True)
raw_data.drop(index = raw_data[raw_data.volume == 0].index, inplace=True)
raw_data['close_open_return'] = (raw_data.close / raw_data.open - 1) * 10
raw_data['close_return'] = raw_data.close.pct_change() * 10
raw_data['open_return'] = raw_data.open.pct_change() * 10
raw_data['high_return'] = raw_data.high.pct_change() * 10
raw_data['low_return'] = raw_data.low.pct_change() * 10
feature_list = raw_data.columns[-5:]
total_model_data = raw_data[feature_list].clip(-1, 1)
feature_num = len(feature_list)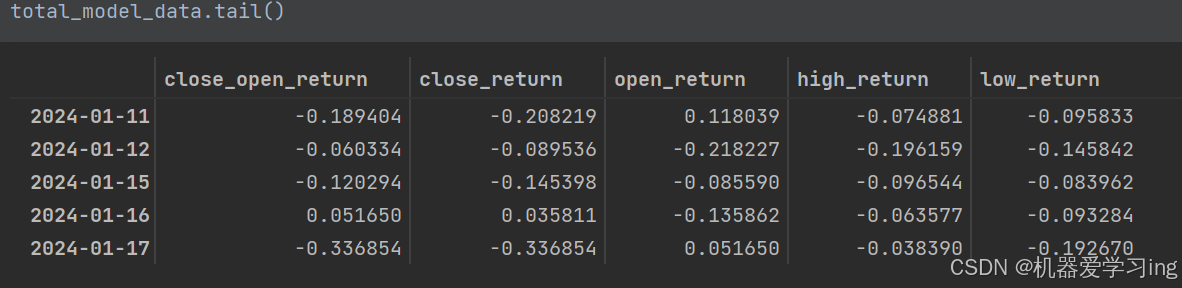
2.2搭建LSTM模型
class LSTMnet(nn.Module):
def __init__(self, input_dim, hidden_dim, layer_dim, output_dim, dropout = 0.5):
super().__init__()
self.hidden_dim = hidden_dim
self.layer_dim = layer_dim
self.dropout = dropout
self.lstm = nn.LSTM(input_dim, hidden_dim, layer_dim, batch_first = True, dropout = dropout)
self.fc1 = nn.Linear(hidden_dim, output_dim)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
out, h_n = self.lstm(x, None) # None代表,h0=0
# out = self.fc1(self.dropout(out[:,-1,:]))
out = self.fc1(out[:,-1,:])
return out2.3数据加载器
n_steps = 10
lag_num = 5
val_num = 10
step_ahead = 1
input_dim = feature_num
hidden_dim = 96
layer_dim = 2
epochs = 10
# output_dim = check_num + step_ahead
output_dim = lag_num + step_ahead
result_summary = pd.DataFrame()
sample_num = 1250
# sample_num = 1000
batch_size = 125
lr = 0.005
epochs = 50
loss_func = nn.L1Loss().cuda()
# loss_func = nn.MSELoss().cuda()
drop = 0.5
result_summary = pd.DataFrame()
date = datetime.date.today()
total_num = val_num + n_steps + sample_num
model_data = total_model_data.tail(total_num)
X = []
Y = []
for k in range(n_steps, len(model_data)):
X.append(model_data.iloc[k - n_steps:k, :])
Y.append(model_data.iloc[k-lag_num:k+1, 0])
train_x = X[:sample_num]
train_y = Y[:sample_num]
val_x = X[sample_num:]
val_y = Y[sample_num:]
val_xt = torch.from_numpy(np.array(val_x).astype(np.float32)).cuda()
val_yt = torch.from_numpy(np.array(val_y).astype(np.float32)).cuda()
pred_x_data = torch.from_numpy(model_data.tail(n_steps).values.astype(np.float32)).view(1, n_steps, input_dim).cuda()
train_x_bs = np.array(batch_shuffle(train_x, batch_size)).reshape(-1, n_steps, feature_num) # bs -> batch_shuffle
train_y_bs = np.array(batch_shuffle(train_y, batch_size)).reshape(-1, output_dim)
train_xt = torch.from_numpy(np.array(train_x_bs).astype(np.float32)).cuda()
train_yt = torch.from_numpy(np.array(train_y_bs).astype(np.float32)).cuda()
train_data = Data.TensorDataset(train_xt, train_yt)
train_loader = Data.DataLoader(dataset = train_data,
batch_size = batch_size,
shuffle = False,
num_workers = 0)
model = LSTMnet(input_dim, hidden_dim, layer_dim, output_dim, drop).cuda()
optimizer = torch.optim.Adam(model.parameters(), lr = lr)
train_acc_list = []
val_acc_list = []
pred_list = []
max_val_acc = 0
for epoch in range(100):
model.train()
for step, (b_x, b_y) in enumerate(train_loader):
output = model(b_x)
loss = loss_func(output, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
epoch_train_acc = round((((model(train_xt)[:, -1] >= 0) == (train_yt[:, -1] >= 0)).sum() / len(train_xt)).item(), 2)
epoch_val_acc = round((((model(val_xt)[:, -1] >= 0) == (val_yt[:, -1] >= 0)).sum() / len(val_xt)).item(), 2)
val_acc_list.append(epoch_val_acc)
train_acc_list.append(epoch_train_acc)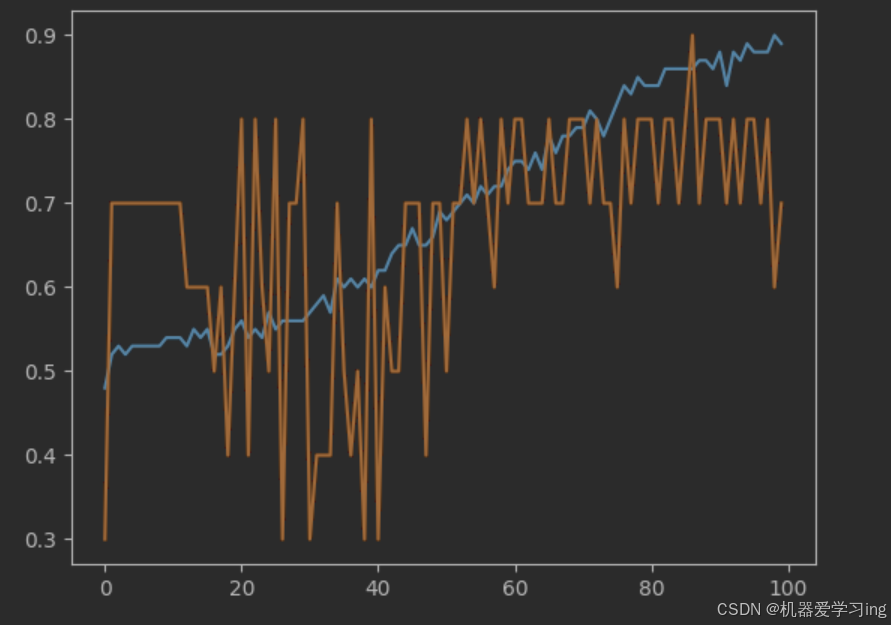 2.4训练预测和结果呈现
2.4训练预测和结果呈现
state = '训练'
up_count, down_count, fail_count = 0, 0, 0
while state == '训练':
train_x_bs = np.array(batch_shuffle(train_x, batch_size)).reshape(-1, n_steps, feature_num) # bs -> batch_shuffle
train_y_bs = np.array(batch_shuffle(train_y, batch_size)).reshape(-1, output_dim)
train_xt = torch.from_numpy(np.array(train_x_bs).astype(np.float32)).cuda()
train_yt = torch.from_numpy(np.array(train_y_bs).astype(np.float32)).cuda()
train_data = Data.TensorDataset(train_xt, train_yt)
train_loader = Data.DataLoader(dataset = train_data,
batch_size = batch_size,
shuffle = False,
num_workers = 0)
model = LSTMnet(input_dim, hidden_dim, layer_dim, output_dim, drop).cuda()
optimizer = torch.optim.Adam(model.parameters(), lr = lr)
train_acc_list = []
val_acc_list = []
pred_list = []
max_val_acc = 0
for epoch in range(130):
model.train()
for step, (b_x, b_y) in enumerate(train_loader):
output = model(b_x)
loss = loss_func(output, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
epoch_train_acc = round((((model(train_xt)[:, -1] >= 0) == (train_yt[:, -1] >= 0)).sum() / len(train_xt)).item(), 2)
epoch_val_acc = round((((model(val_xt)[:, -1] >= 0) == (val_yt[:, -1] >= 0)).sum() / len(val_xt)).item(), 2)
pred = round(model(pred_x_data)[0][-1].item() * 10, 2)
max_val_acc = max(max_val_acc, epoch_val_acc)
if epoch_train_acc >= 0.6 and epoch_val_acc >= 0.8 and abs(pred) > 0.05:
train_acc_list.append(epoch_train_acc)
val_acc_list.append(epoch_val_acc)
pred_list.append(pred)
display.clear_output(wait=True)
print(pred_list)
if len(pred_list) < 3:
fail_count += 1
else:
if (np.array(pred_list) >= 0).sum() > (np.array(pred_list) < 0).sum():
up_count += 1
elif (np.array(pred_list) >= 0).sum() < (np.array(pred_list) < 0).sum():
down_count += 1
else:
fail_count += 1
result_summary.loc[date, 'up_count'] = up_count
result_summary.loc[date, 'down_count'] = down_count
result_summary.loc[date, 'fail_count'] = fail_count
print(result_summary)
if up_count - down_count >= 5:
result_summary.loc[date, 'pred'] = int(1)
state = '训练结束'
elif up_count - down_count <= -5:
result_summary.loc[date, 'pred'] = int(0)
state = '训练结束'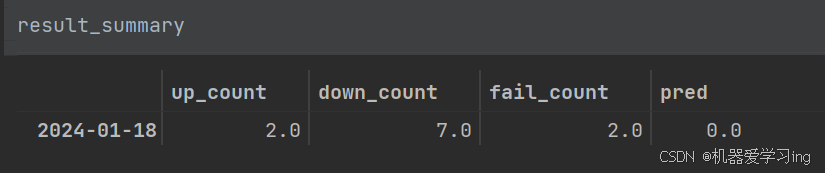
3.总结
这是我首次在CSDN平台上撰写博客,因时间有限,本文并未进行过多的文字描述。如果您对内容有疑问或想法,欢迎通过后台私信与我联系,我非常期待与大家交流与探讨。
自2023年起,我开始从事深度学习领域的研究,主要专注于医疗图像处理方向。该领域充满了挑战和机遇,我对如何通过深度学习技术提升医疗诊断的效率与准确性充满热情。在今后的博客中,我将持续更新我的研究进展,与大家分享我在医疗图像领域的研究成果,涵盖多示例学习、多任务学习、多模态融合等方向,以及在科研过程中的心得体会。
希望这个博客能成为我与大家交流学习的桥梁,期待在这里记录我的成长,同时也为对深度学习感兴趣的朋友提供一些思路与启发。感谢大家的关注和支持!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









