







数据类型
1. Redis的数据类型
常见的有五种:
String、Hash、List、Set、ZSet
String
String是最基本的key-value结构,key是唯一标识,value是具体的值。value的值可以为数字或者字符串
内部实现
- 底层的数据结构的实现主要是int和SDS(简单动态字符串)
没有使用c语言的字符串表示,因为SDS相比于c的原生字符串
- SDS可以保存文本数据和二进制数据
- SDS获取字符串长度的时间复杂度是O(1),使用len的属性记录字符串长度
- Redis的SDS API是安全的,拼接字符串不会造成缓冲区溢出,会在拼接字符串之前检查空间是否满足要求,空间不够自动扩容
-
字符串对象的内部编码有3种:int、raw、embstr
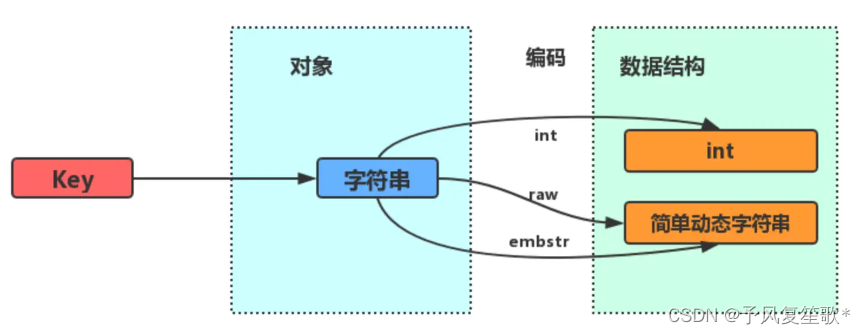
-
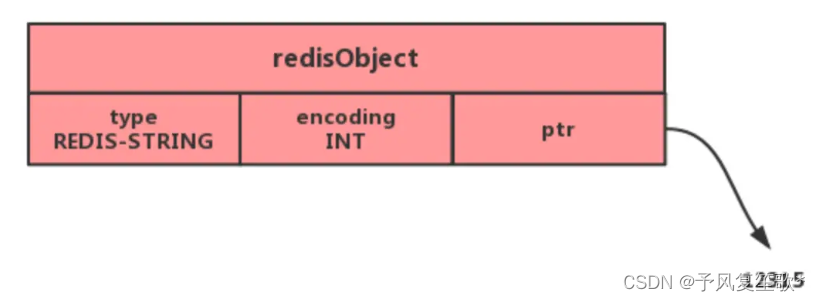
保存的是整数值:整数值用long类型表示,保存在字符串对象结构的ptr属性里面,并将编码设置为int
-
保存的是字符串:
- 长度<= 32字节,使用SDS保存,编码方式设置为embstr
- 长度 >32字节,使用SDS保存,编码方式设置为raw
embstr和raw的区别:
embstr会通过一次内存分配函数来分配一块连续的内存空间来保存redisObject和SDS;raw会通过调用两次内存分配函数来分配两块空间保存redisObject和SDS
好处:
embstr的内存分配和调用只需要一次,所有数据都在一块连续的内存中可以更好利用CPU缓存提升性能
缺点:
embstr编码的字符串对象是只读的,没有任何相应的修改程序。进行修改的时候,会先将对象的编码从embstr转换成raw,再修改。
-
常用指令:
/* 普通基本操作 */
// 设置key-value类型的值
set name lin
//根据key获取对应的value值
get name
//判断某个key是否存在
exists name
//返回key所储存的字符串值的长度
strlen name
//删除某个key对应的值
del name
/* 批量设置 */
//批量设置key-value类型的值
mset key1 value1 key2 value2
//批量获取多个key对应的value
mget key1 key2
/* 计数器(当字符串的内容为整数时) */
set number 0
incr number 10
decr number 10
/* 过期(默认永不过期) */
//设置key在60秒之后过期
expire name 60
//查看数据还有多久过期
ttl name
/* 不存在就插入 */
setnx key value
应用场景
-
缓存对象:
-
直接缓存整个对象的JSON
SET user:1 '{"name":"xiaolin", "age":18}' -
将key进行分离为 user:ID:属性
MSET user:1:name xiaolin user:1:age 18 user:2:name xiaomei user:2:age 20
-
-
常规计数
Redis处理命令是单线程,执行命令的过程是原子的,所以String数据类型可以用来进行计数
# 初始化文章的阅读量 > SET aritcle:readcount:1001 0 OK #阅读量+1 > INCR aritcle:readcount:1001 (integer) 1 #阅读量+1 > INCR aritcle:readcount:1001 (integer) 2 #阅读量+1 > INCR aritcle:readcount:1001 (integer) 3 # 获取对应文章的阅读量 > GET aritcle:readcount:1001 "3" -
分布式锁
set命令中的nx参数可以实现key不存在才插入,所以可以用来实现分布式锁
- key不存在,则显示插入成功,表示加锁成功
- key存在,显示插入失败,表示加锁失败
-
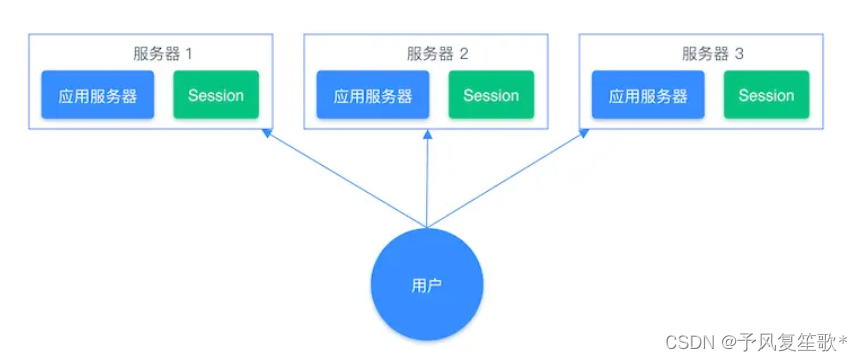
共享session信息
使用session在服务端保存用户的会话状态,但只适用于单系统,多系统时就不再适用。
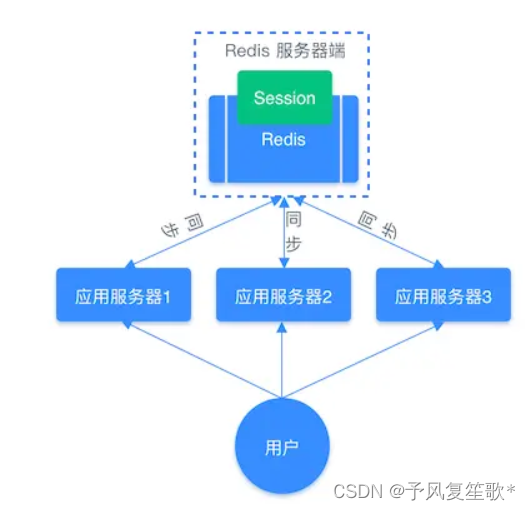
借助Redis对session信息进行统一的存储和管理,无论请求到哪台服务器都可以先去Redis获取相关的Session信息
转变为:
List
List列表是简单的字符串列表,按照插入顺序排序,可以从头部或尾部向List列表添加元素。
内部实现:
底层数据结构是双向链表或压缩列表实现:
列表的元素个数小于512,列表每个元素的值都小于64字节,Redis会使用压缩列表作为List类型的底层数据结构
否则使用双向链表作为List类型的底层数据结构
Redis 3.2版本之后,底层由quicklist实现,替代了双向链表和压缩链表。
常用命令:
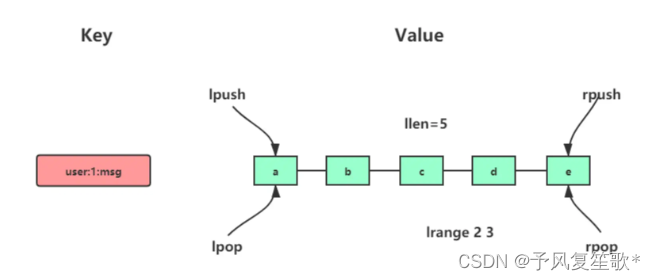
//将一个或者多个值插入到key列表的表头,最后的值在最前面 最左边
lpush key value [value...]
//将一个或者多个值插入到key列表的表尾 最右边
rpush key value [value...]
//移除并返回key列表的头元素
lpop key
//移除并返回key列表的尾元素
rpop key
//返回列表key中指定区间内的元素,区间以偏移量start和stop指定
lrange key start stop
//从key列表表头弹出一个元素,没有就阻塞timeout秒,如果timeout=0则一直阻塞
blpop key [key...] timeout
//从key列表表尾弹出一个元素,没有就阻塞timeout秒,如果timeout=0则一直阻塞
brpop key [key...] timeout
应用场景
-
消息队列
在存取消息时,要保障消息保序、处理重复的消息和保证消息可靠性
-
消息保序
按照先进先出的顺序对数据进行存取,所以可以满足消息保序需求。
使用lpush+rpop(或者rpush + lpop)命令实现消息队列
- 生产者使用lpush key value[value…]将消息插入到队列的头部,如果key不存在则会创建一个空的队列再插入消息
- 消费者在使用rpop key依次读取队列的消息,先进先出
生产者向List中写入消息的时候,不会主动通知消费者有新的消息写入,消费者需要一直调用rpop命令,有新消息写入,rpop命令会返回结果。
一直调用会导致消费者程序的CPU一直消耗在执行rpop命令上,使用brpop命令,也称为阻塞式读取,客户端没有读到数据会自动阻塞,直到有新的数据写入,再开始读取新的数据。
-
重复的消息
判断重复消息:
每个消息都有一个全局的ID。
消费者记录已经处理过的消息的ID,收到消息之后,对比收到的消息ID和记录已处理过的消息ID,已经处理过了那么就不再进行处理。
List不会为每个消息生成ID号,需要自行为每个消息生成一个全局唯一ID
-
保证消息可靠性
消费者从List中读取一条消息之后,List不会留存这条消息,如果消费者在处理消息的时候出现宕机或者故障,导致消费没有处理完,此时无法从List中读取消息。
为留存消息,提供BRPOPLPUSH命令,让消费者程序从一个List中读取消息,同时也会把它插入到另一个List留存。
-
-
缺点:
List不支持多个消费者消费同一条消息
List不支持消费组(多个消费者组成一个消费者)的实现
Hash
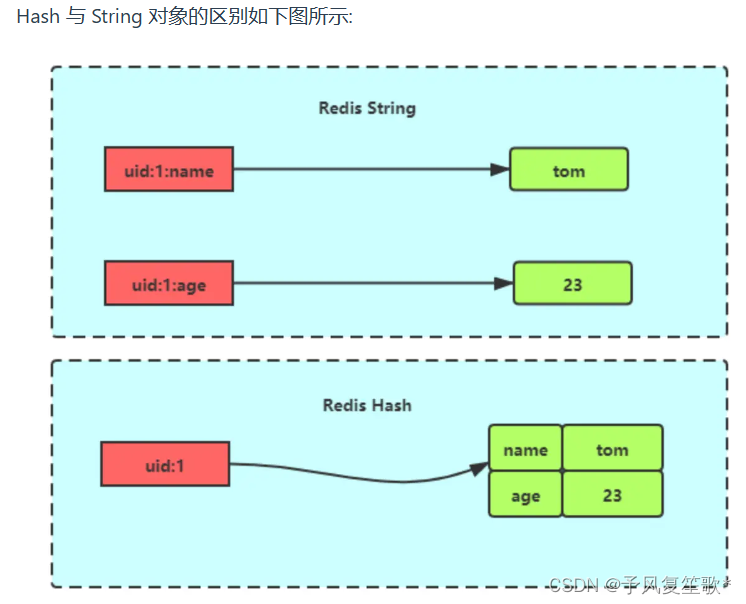
键值对集合,value的形式为value=[{field1,value1},...[fieldN,valueN]]。Hash适合存储对象
内部实现:
底层数据结构:压缩列表或哈希表实现
- 哈希类型元素个数小于512个,所有值小于64字节,Redis使用压缩列表作为底层数据结构
- 否则使用哈希表作为Hash类型的底层数据结构
常用命令:
//存储一个哈希表key的键值
hset key field value
//获取哈希表key对应的field键值
hget key field
//在一个哈希表key中存储多个键值对
hmset key field value [field value...]
//批量获取哈希表key中多个field键值
hmget key field [field...]
//删除哈希表key中的field键值
hdel key field [field...]
//返回哈希表key中field的数量
hlen key
//返回哈希表key中所有的键值
hgetall key
//为哈希表key中field键的值加上增量n
hincrby key field n
应用场景:
-
缓存对象
Hash类型的(key、field、value)的结构与对象的(对象id、属性、值)结构相似,也可以用存储对象。
# 存储一个哈希表uid:1的键值 HMSET uid:1 name Tom age 15 # 存储一个哈希表uid:2的键值 HMSET uid:2 name Jerry age 13 # 获取哈希表用户id为1中所有的键值 HGETALL uid:1 "name" "Tom" "age" "15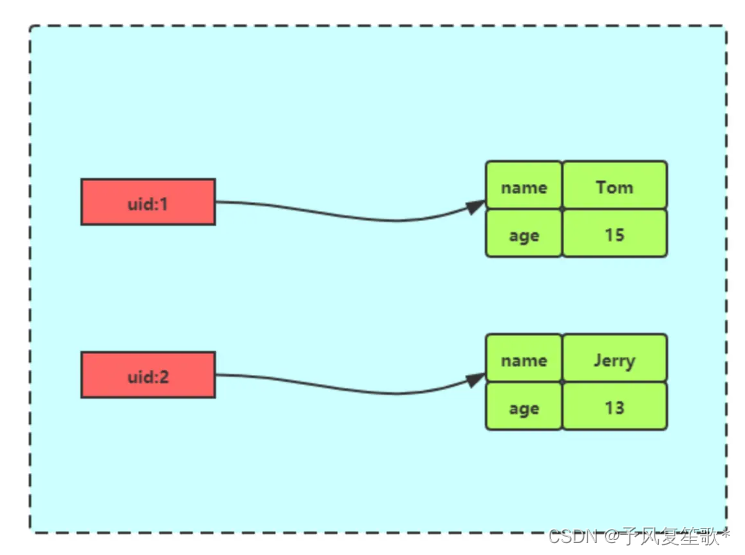
一般对象用String + JSON 存储,对象中某些频繁变化的属性可以使用Hash类型存储。
-
购物车
用户id为key,商品id为field,商品数量为value
//添加商品 hset cart:{用户id} {商品id} 1 //添加数量 hincrby cart:{用户id} {商品id} 1 //商品总数 hlen cart:{用户id} //删除商品 hdel cart:{用户id}{商品id} //获取购物车所有商品 hgetall cart:{用户id}只是将商品ID存储到Redis中,在回显商品具体信息的时候,还需要拿着商品id查询一次数据库,获取完整的商品的信息
Set
是一个无序并唯一的键值集合,存储顺序不会按照插入的先后顺序进行存储
一个集合最多可以存储2^32-1个元素,支持集合内的增删改查、多个集合的交集、并集、差集。
Set类型和List类型的区别:
- List可以存储重复元素、Set只能存储非重复元素
- List按照元素先后顺序存储元素,Set无序方式存储元素
内部实现:
底层数据结构是由哈希表或整数集合实现:
- 集合中的元素都是整数,且元素个数小于512,Redis使用整数集合作为Set类型的底层数据结构
- 否则使用哈希表作为底层数据结构
常用命令:
Set常用操作:
# 往集合key中存入元素,元素存在则忽略,若key不存在则新建
SADD key member [member ...]
# 从集合key中删除元素
SREM key member [member ...]
# 获取集合key中所有元素
SMEMBERS key
# 获取集合key中的元素个数
SCARD key
# 判断member元素是否存在于集合key中
SISMEMBER key member
# 从集合key中随机选出count个元素,元素不从key中删除
SRANDMEMBER key [count]
# 从集合key中随机选出count个元素,元素从key中删除
SPOP key [count]
Set运算操作
# 交集运算
SINTER key [key ...]
# 将交集结果存入新集合destination中
SINTERSTORE destination key [key ...]
# 并集运算
SUNION key [key ...]
# 将并集结果存入新集合destination中
SUNIONSTORE destination key [key ...]
# 差集运算
SDIFF key [key ...]
# 将差集结果存入新集合destination中
SDIFFSTORE destination key [key ...]
应用场景:
适合数据去重和保障数据唯一性,也可用来做集合运算。
Set的集合运算复杂度较高,在数据量较大时,直接执行会导致Redis实例阻塞,所以一般选择一个从库完成聚合统计,或者把数据返回给客户端,由客户端完成聚合统计。
-
点赞
set集合可以保证一个用户只能点一个赞
-
共同关注
set类型支持交集运算,可以用来计算共同关注的好友、公众号等
-
抽奖活动
可以保证同一个用户不会中奖两次
Zset
相比于set类型多个了一个排序属性score,每个存储元素相当于有两个值组成,一个是有序集合的元素值,一个是排序值
有序集合保证了不能有重复成员的特性,但可以进行排序。
内部实现:
底层由压缩列表或跳表实现
- 元素个数小于128,并且每个元素的值小于64字节时,可以使用压缩列表作为底层数据结构
- 否则使用跳表作为底层数据结构
常用命令:
-
Zset常用操作
# 往有序集合key中加入带分值元素 ZADD key score member [[score member]...] # 往有序集合key中删除元素 ZREM key member [member...] # 返回有序集合key中元素member的分值 ZSCORE key member # 返回有序集合key中元素个数 ZCARD key # 为有序集合key中元素member的分值加上increment ZINCRBY key increment member # 正序获取有序集合key从start下标到stop下标的元素 ZRANGE key start stop [WITHSCORES] # 倒序获取有序集合key从start下标到stop下标的元素 ZREVRANGE key start stop [WITHSCORES] # 返回有序集合中指定分数区间内的成员,分数由低到高排序。 ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] # 返回指定成员区间内的成员,按字典正序排列, 分数必须相同。 ZRANGEBYLEX key min max [LIMIT offset count] # 返回指定成员区间内的成员,按字典倒序排列, 分数必须相同 ZREVRANGEBYLEX key max min [LIMIT offset count] -
Zset运算操作(不支持差集运算):
# 并集计算(相同元素分值相加),numberkeys一共多少个key,WEIGHTS每个key对应的分值乘积 ZUNIONSTORE destkey numberkeys key [key...] # 交集计算(相同元素分值相加),numberkeys一共多少个key,WEIGHTS每个key对应的分值乘积 ZINTERSTORE destkey numberkeys key [key...]
应用场景:
可以根据元素的权重来排序,可以自己决定每个元素的权重值。
在需要展示最新列表、排行榜等场景时,数据更新频繁或者需要分页显示,可以优先考虑使用Sorted Set。
-
排行榜
从高到底进行排序
-
电话、姓名排序
2. Redis数据结构
指数据类型底层实现的方式
SDS
String数据类型的底层数据结构是SDS。
C语言字符串的不足:
- 字符串中不能含有"\0",导致C语言的字符串只能保存文本数据,不能保存图片、音频、视频文化等这样的二进制数据。
- 获取字符串长度的时间复杂度为O(n)
- 操作函数不高效且不安全,缓冲区可能会溢出
因此,SDS的数据结构如下:
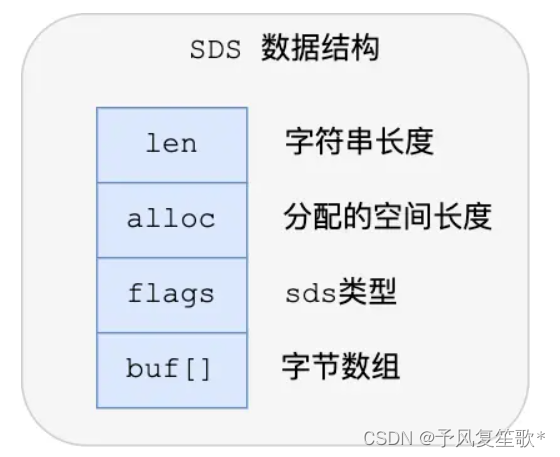
- len:记录字符串长度
- alloc:已经分配给字符数组的空间长度
- flags:表示sds类型,sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64
- buf[]:字符数组,用来保存实际数据
这样设计可以:
-
O(1)复杂度获取字符串长度
-
二进制安全,使用len来记录字符串长度,所以可以存储"\0"
-
不会发生缓冲区溢出
当判断缓冲区大小不够用时,会自动扩大SDS空间大小
- sds长度 < 1MB,翻倍扩容
- sds长度 > 1MB, 长度 + 1MB
可以有效减少分配次数
设置多个sds类型原因:
设计五种类型的区别在于:数据结构中的len、alloc成员变量的数据类型不同。
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len;
uint16_t alloc;
unsigned char flags;
char buf[];
};
- uint16_t表示字符数组长度和分配空间大小不能超过2的16次方
- attribute ((packed))表示告诉编译器取消结构体在编译过程中的优化对齐,按照实际占用字节数进行对齐,节省内存空间
链表
是List对象的底层实现
链表节点的结构:
typedef struct listNode {
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
} listNode;
//在listNode结构体基础上封装list数据结构
typedef struct list {
//链表头节点
listNode *head;
//链表尾节点
listNode *tail;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void (*free)(void *ptr);
//节点值比较函数
int (*match)(void *ptr, void *key);
//链表节点数量
unsigned long len;
} list;
这样设计的好处:
- 获取表头表尾节点的时间复杂度为O(1)
- 通过list结构的dup、free、match函数可以设置节点类型特定的函数,保存各种不同类型的值
不足:
- 节点在内存中的存储是不连续的,导致无法很好利用CPU缓存
- 每个节点都保存一个节点结构头的分配,内存开销较大
压缩列表
设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,可以利用CPU缓存,且会针对不同长度的数据,进行编码,节省开销。
存储结构:

- zlbyte:记录整个压缩列表占用内存字节数
- zltail:列表尾的偏移量
- zllen:记录压缩列表中包含的节点数量
- zlend:标记压缩列表的结束点
在压缩列表中,可以直接定位查找第一个和最后一个元素,但查找其他元素只能逐个查找,时间复杂度是O(n)
每一个压缩列表的节点结构如下:
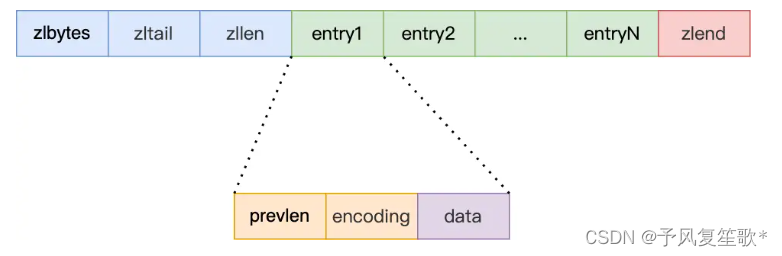
- prevlen:记录前一个节点的长度,实现从后向前遍历
- encoding:记录当前节点实际数据的类型(字符串、整数)和长度
- data:记录当前节点的实际数据
不同数据类型的大小,会分配不同空间大小的prevlen和encoding,并不是固定大小。
prevlen:
- 如果前一个节点的长度小于254字节,则使用1字节的空间来保存这个长度值
- 如果前一个节点的长度大于254字节,则使用5字节来保存这个长度值
encoding:
- 当前节点的数据是整数,会使用1字节的空间进行编码
- 当前节点的数据是字符串,会根据字符串的长度大小,会使用1字节/2字节/5字节的空间进行编码
连锁更新:
当压缩列表中新增某个元素或者添加某个元素的时候,导致后续元素的prevlen占用空间都发生变化,引起连锁更新问题,导致每个元素的空间都要重新分配,性能下降。
缺点:
- 不能保存过多的元素
- 新增或修改某个元素时,压缩列表占用的内存空间可能需要重新分配,引发连锁更新的问题
哈希表
保存键值对key-value的数据结构,key值唯一,能以O(1)的复杂度快速查询数据。
因为哈希表是数组存储,key通过Hash函数的计算,就可以定位数据在表中的位置。
随着数据的不断增多,哈希冲突的风险也会增加,Redis采用链式哈希来解决哈希冲突。
typedef struct dictht {
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
unsigned long sizemask;
//该哈希表已有的节点数量
unsigned long used;
} dictht;
哈希表是一个数组,数组中的每一个元素是指向哈希表节点的指针,如下图:
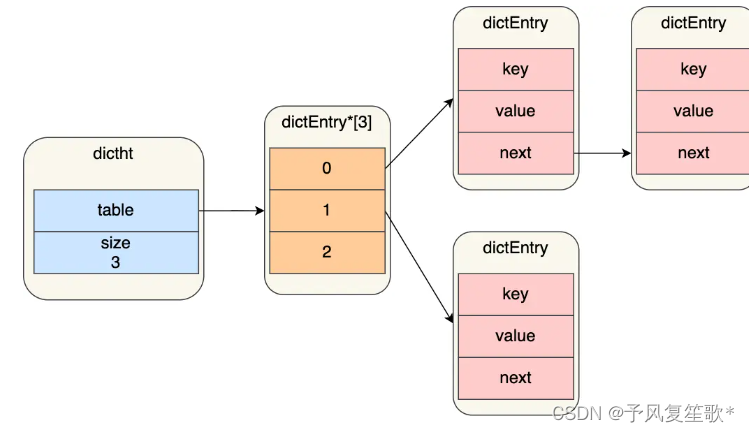
哈希表节点结构:
typedef struct dictEntry {
//键值对中的键
void *key;
//键值对中的值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
//指向下一个哈希表节点,形成链表,解决哈希冲突
struct dictEntry *next;
} dictEntry;
补充:dictEntry结构里键值对中的值是由联合体定义的,所以可以存放实际的值,也可以存放指向值的指针。当值是整数或者浮点数的时候,可以将值的数据内嵌在结构里,不需要通过指针,可以节省空间。
哈希冲突
Redis采用链式哈希来解决哈希冲突,被分配到同一个哈希值上的节点,使用链表连接,但当链表的长度增加时,查询在这一位置上的数据耗时会增加。
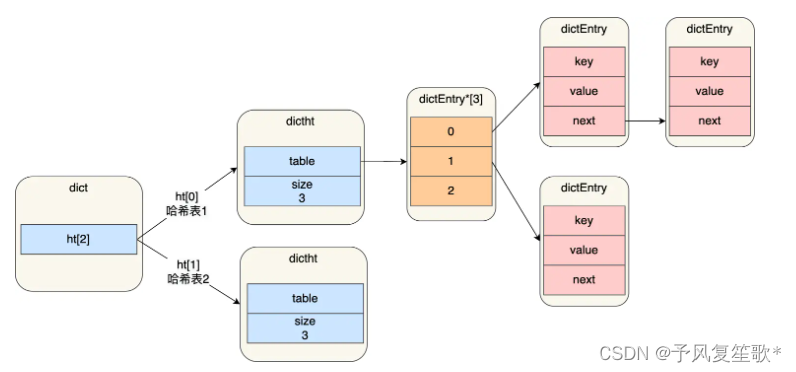
rehash
定义了两个哈希表
过程:
- 在正常服务器请求阶段,数据都会插入到哈希表1,哈希表2没有被分配空间
- 当数据量达到一定程度时,哈希表2会被分配空间,大小是哈希表1的两倍
- 将哈希表1的数据复制到哈希表2中,释放掉哈希表1的控件,将哈希表2修改为哈希表1,哈希表2新创建一个空白的哈希表
- 继续循环上述操作
当数据量过大时,会涉及大量的数据拷贝,可能会导致Redis阻塞,无法处理其他请求。
渐进式rehash:
避免数据量太大造成的问题,对数据的迁移分成多次完成。
- 同时为两个哈希表分配空间
- 在rehash期间,每次进行增删改查操作时,除过完成指定操作,还会将哈希表1数据的一部分转移到哈希表2
- 随着请求操作的执行,最终在某个时间节点上,所有哈希表1的值都会转移到哈希表2
由于增删改等操作会在两个哈希表中进行,所以查找时如果第一个哈希表中没有找到,会在第二个哈希表中进行查找。
整数集合
是Set对象的底层实现之一,当一个Set对象只包含整数值元素,且元素数量不大时,就会使用整数集作为底层实现。
整数集合结构设计
本质上是一块连续内存空间
typedef struct intset {
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
} intset
- contents数组的真正类型取决于intset结构体里的encoding属性的值
整数集合的升级操作:
将新元素加入到整数集合时,如果新元素的类型比整数集合现有的所有元素的类型都要长时,整数集合需要先进行升级,然后才能将新的元素加入到整数集合中。节省内存资源,只有出现更长类型的数据时,才会进行升级操作。 但不支持降级操作
跳表
Redis只有Zset对象的底层用到了跳表,支持平均O(logN)复杂度的节点查找。
zset结构体中有两个数据结构:跳表和哈希表。
在执行数据插入或数据更新过程中,会依次在跳表和哈希表中插入或更新相应的数据,保证跳表和哈希表中记录的信息一致。
Zset 对象能支持范围查询(如 ZRANGEBYSCORE 操作),这是因为它的数据结构设计采用了跳表,而又能以常数复杂度获取元素权重(如 ZSCORE 操作),这是因为它同时采用了哈希表进行索引。
跳表结构设计
在链表的基础上改进,实现了一种多层的有序链表。跳表是一个带有层级关系的链表,每一层级可以包含多个节点,节点之间通过指针来连接。
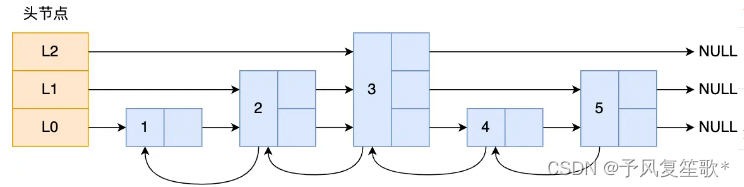
typedef struct zskiplistNode {
//Zset 对象的元素值
sds ele;
//元素权重值
double score;
//后向指针
struct zskiplistNode *backward;
//节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
level数组中的每一个元素代表跳表的一层,zskiplistLevel 结构体里定义了指向下一个跳表节点的指针和跨度,跨度用于记录两个节点之间的距离。

查询过程:
跳表从头节点的最高层开始,逐层遍历,遍历某一层的跳表时,会用跳表节点中的SDS类型的元素和元素的权重来进行判断,有两个判断条件:
- 当前节点的权重 < 要查找的权重,访问该层上的下一个节点
- 当前节点的权重 = 要查找的权重时,且当前节点的SDS类型数据 < 要查找的数据时,跳表会访问该层上的下一个节点
- 两个条件都不满足时或下一个节点为空时,跳表会使用目前遍历到的节点的level数组里的下一层指针,沿下一层指针继续查找
跳表层数设置:
相邻两层节点数量的比例会影响跳表的查找性能,最理想的比例是2:1,复杂度可以降低到O(logN)
但在跳表新建节点的时候,会随机生成每个节点的层数,具体做法是:
每次生成一个新的节点,都会生成范围[0-1]的一个随机数,如果这个数小于0.25,则层数+1,继续生成,直到该数大于0.25,此时结束,确定该节点的层数。
层数越高,概率越低
为什么使用跳表而不使用平衡树:
- 内存占用:跳表会比平衡树更加灵活
- 范围查找时,跳表比平衡树操作简单
- 跳表比平衡树的实现简单
quicklist
是双向链表+压缩列表的组合。
由于压缩列表可能会存在连锁更新的问题,所以quicklist在其基础上,控制每个链表节点中压缩列表的大小或者元素的个数,规避连锁更新的问题。
结构设计:
typedef struct quicklist {
//quicklist的链表头
quicklistNode *head; //quicklist的链表头
//quicklist的链表尾
quicklistNode *tail;
//所有压缩列表中的总元素个数
unsigned long count;
//quicklistNodes的个数
unsigned long len;
...
} quicklist;
typedef struct quicklistNode {
//前一个quicklistNode
struct quicklistNode *prev; //前一个quicklistNode
//下一个quicklistNode
struct quicklistNode *next; //后一个quicklistNode
//quicklistNode指向的压缩列表的指针
unsigned char *zl;
//压缩列表的的字节大小
unsigned int sz;
//压缩列表的元素个数
unsigned int count : 16; //ziplist中的元素个数
....
} quicklistNode;
插入的时候:先检查插入位置的压缩列表是否能容纳该元素,如果可以直接插入;如果不行,才会新建一个quicklistNode节点。
listpack
代替压缩列表,每一个节点中不再包含前一个节点的长度。
结构设计:
使用一块连续的内容空间来紧凑保存内存数据,节省内存开销。
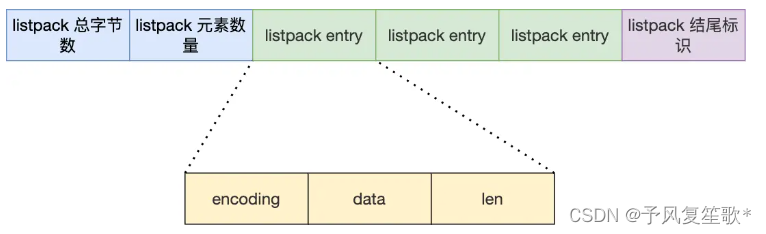
- encoding:定义元素的编码类型,会对不同长度的整数和字符串进行编码
- data:实际存放的数据
- len:encoding + data的总长度
listpack没有记录前一个节点长度的字段,取而代之记录的是当前节点长度,所以在增加新的元素的时候,不会影响其他节点的长度字段。















 6488
6488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









