






流处理和批处理的区别

无界流和有界流
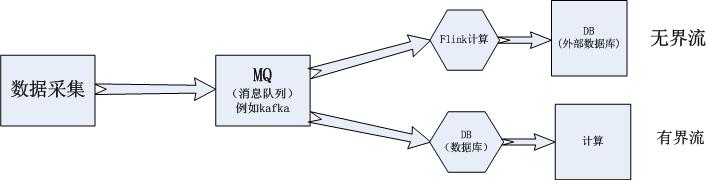
因为Flink想要实现流批统一,所以提出了无界流和有界流这俩个概念,这俩个概念就相当于前文所说的流处理和批处理。
任何类型的数据都是作为事件流产生的。再互联网上的所有数据都可以作为流生成
无界流有一个开始但没有定义的结束。他们不会再生成时终止并提供数据。必须持续处理无界流,,即必须再摄取事件后立即处理实践。无法等待所有输入数据到达,因为输入是无界的,并且再任何时间点都不会有完成状态。处理无界流数据通常要求以特定顺序(例如事件发生的顺序)摄取事件,以便能够推断结果的完整性
有界流具有定义的开始和结束。可以在执行任何计算之前通过摄取所有的数据来处理有界流。处理有界流不需要有序摄取,因为可以始终对有界数据集进行排序。有界流的处理也称为批处理
有界流:bounded stream
无界流:unbounded stream

由这张图我们可以看出,有界流是无界流的特例
离线计算和实时计算
有界流适合离线计算,无界流适合实时计算
特点:

实时计算面临的挑战
1、数据处理的唯一性
如何保证数据只处理一次?至少一次?最多一次?
2、数据处理的及时性
采集的实时数据量太大的话可能会导致短时间内处理不过来,如何保证数据能够及时的处理,不出现数据堆积?
3、数据处理层和存储层的可扩展性
如何根据采集的实时数据量的大小提供动态的扩容缩容?
4、数据处理层和存储层的容错性
如何保证数据处理层和存储层高可用,出现故障时数据处理层和存储层服务依旧可用
什么是Flink
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算
Flink的特点

1、支持高吞吐、低延迟、高i性能的流处理
2、支持带有事件时间的窗口(Windows)操作
3、支持有状态计算的Exactly-once语义
4、支持高度灵活的窗口操作,支持基于time、count、session,以及data-dirven的窗口操作
5、支持具有反压功能的持续流模型
6、支持基于轻量级分布式快照实现的容错
7、一个运行时同时支持批处理和流处理
8、Flink在JVM内部实现了自己的内存管理,避免出现oom(所以Flink基本不会出现内存溢出)
9、支持迭代计算
10、支持程序自动优化:避免特定情况下shuffle、排序等昂贵操作,中间结果有必要进行缓存
spark和flink的区别

1、Spark可以在map端预聚合,而Flink不行
因为Spark有预聚合,所以有延迟,而Flink是数据直接发送到下游,每一条数据都会处理
2、Spark先maptask后reducetask,而Flink是maptask和reducetask一起启动,等待数据过来
spark是mapreduce模型
Flink是持续流模型

















 796
796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











