







目录
Numpy介绍

Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组。
Numpy支持常见的数组和矩阵操作。对于同样的数值计算任务,使用Numpy比直接使用Python要简洁
的多。
Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
ndarray介绍
NumPy提供了一个N维数组类型ndarray,它描述了相同类型的“items”的集合。
ndarray与Python原生list运算效率对比
在这里我们通过一段代码运行来体会到ndarray的好处
import random
import time
import numpy as np
a = []
for i in range(100000000):
a.append(random.random())
# 通过%time魔法方法, 查看当前行的代码运行一次所花费的时间
%time sum1=sum(a)
b=np.array(a)
%time sum2=np.sum(b)
其中第一个时间显示的是使用原生Python计算时间,第二个内容是使用numpy计算时间:
CPU times: user 852 ms, sys: 262 ms, total: 1.11 s
Wall time: 1.13 s
CPU times: user 133 ms, sys: 653 μs, total: 133 ms
Wall time: 134 ms
从中我们看到ndarray的计算速度要快很多,节约了时间。
机器学习的最大特点就是大量的数据运算
ndarray的优势(了解)
1 内存块风格
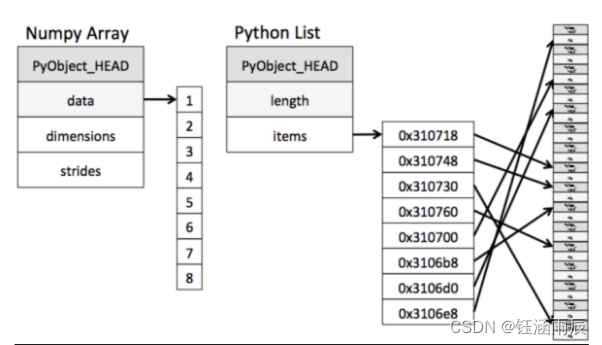
从图中我们可以看出ndarray在存储数据的时候,数据与数据的地址都是连续的,这样就给使得批量操作数组元素时速度更快。
这是因为ndarray中的所有元素的类型都是相同的,而Python列表中的元素类型是任意的,所以ndarray在存储元素时内存可以连续,而python原生list就只能通过寻址方式找到下一个元素,这虽然也导致了在通用性能方面Numpy的ndarray不及Python原生list,但在科学计算中,Numpy的ndarray就可以省掉很多循环语句,代码使用方面比Python原生list简单的多。
2 ndarray支持并行化运算(向量化运算)
numpy内置了并行运算功能,当系统有多个核心时,做某种计算时,numpy会自动做并行计算
3 效率远高于纯Python代码
Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释
器的限制,所以,其效率远高于纯Python代码
小结1
numpy介绍【了解】
一个开源的Python科学计算库
计算起来要比python简洁高效
Numpy使用ndarray对象来处理多维数组
ndarray介绍【了解】
NumPy提供了一个N维数组类型ndarray,它描述了相同类型的“items”的集合。
生成numpy对象:np.array()
ndarray的优势【掌握】
内存块风格
list -- 分离式存储,存储内容多样化
ndarray -- 一体式存储,存储类型必须一样
ndarray支持并行化运算(向量化运算)
ndarray底层是用C语言写的,效率更高,释放了GIL
N维数组-ndarray
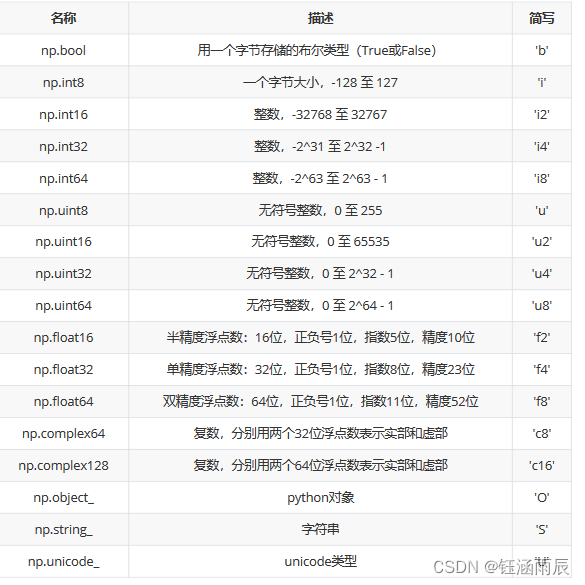
ndarray的属性 数组属性反映了数组本身固有的信息。
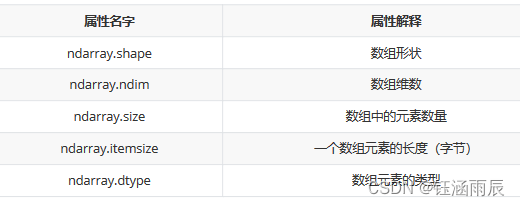
ndarray的类型
创建数组的时候指定类型
>>> a = np.array([[1, 2, 3],[4, 5, 6]], dtype=np.float32)
>>> a.dtype
dtype('float32'
生成数组的方法
生成0和1的数组
np.ones(shape, dtype)
np.ones_like(a, dtype)
np.zeros(shape, dtype)
np.zeros_like(a, dtype)
ones = np.ones([4,8])
ones
返回结果:
array([[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.]])
np.zeros_like(ones)
返回结果:
array([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
从现有数组生成
生成方式
np.array(object, dtype)
np.asarray(a, dtype)
array和asarray的不同
生成固定范围的数组
1,np.linspace (start, stop, num, endpoint)
创建等差数组 — 指定数量
参数:
start:序列的起始值
stop:序列的终止值
num:要生成的等间隔样例数量,默认为50
endpoint:序列中是否包含stop值,默认为ture
# 生成等间隔的数组
np.linspace(0, 100, 11)
返回结果:
array([ 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., 100.])
2, np.arange(start,stop, step, dtype)
创建等差数组 — 指定步长
参数
step:步长,默认值为1
np.arange(10, 50, 2)
返回结果:
array([10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42,
44, 46, 48])
3, np.logspace(start,stop, num)
创建等比数列
参数:
num:要生成的等比数列数量,默认为50
# 生成10^x
np.logspace(0, 2, 3)
返回结果:
array([ 1., 10., 100.])
生成随机数组
使用模块介绍(np.random模块)
正态分布创建方式
np.random.randn(d0, d1, ..., dn)
功能:从标准正态分布中返回一个或多个样本值
np.random.normal(loc=0.0, scale=1.0, size=None)
loc:float
此概率分布的均值(对应着整个分布的中心centre)
scale:float
此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)
size:int or tuple of ints
输出的shape,默认为None,只输出一个值
np.random.standard_normal(size=None)
返回指定形状的标准正态分布的数组
举例1:生成均值为1.75,标准差为1的正态分布数据,100000000个
x1 = np.random.normal(1.75, 1, 100000000)
返回结果:
array([2.90646763, 1.46737886, 2.21799024, ..., 1.56047411, 1.87969135,
0.9028096 ])
股票涨跌幅数据的创建
# 创建符合正态分布的4只股票5天的涨跌幅数据
stock_change = np.random.normal(0, 1, (4, 5))
stock_change
返回结果:
array([[ 0.0476585 , 0.32421568, 1.50062162, 0.48230497, -0.59998822],
[-1.92160851, 2.20430374, -0.56996263, -1.44236548, 0.0165062 ],
[-0.55710486, -0.18726488, -0.39972172, 0.08580347, -1.82842225],
[-1.22384505, -0.33199305, 0.23308845, -1.20473702, -0.31753223]])
均匀分布
np.random.rand(d0, d1, ..., dn)
返回[0.0,1.0)内的一组均匀分布的数。
np.random.uniform(low=0.0, high=1.0, size=None)
功能:从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含
high.
参数介绍:
low: 采样下界,float类型,默认值为0;
high: 采样上界,float类型,默认值为1;
size: 输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k), 则输出mnk个样本,
缺省时输出1个值。
返回值:ndarray类型,其形状和参数size中描述一致。
np.random.randint(low, high=None, size=None)
从一个均匀分布中随机采样,生成一个整数或N维整数数组,
取数范围:若high不为None时,取[low,high)之间随机整数,否则取值[0,low)之间随机整
数。
# 生成均匀分布的随机数
x2 = np.random.uniform(-1, 1, 100000000)
返回结果:
array([ 0.22411206, 0.31414671, 0.85655613, ..., -0.92972446,
0.95985223, 0.23197723]
数组的索引、切片
一维、二维、三维的数组如何索引?
直接进行索引,切片
对象[:, :] -- 先行后列
二维数组索引方式:
举例:获取第一个股票的前3个交易日的涨跌幅数据
# 二维的数组,两个维度
stock_change[0, 0:3]
返回结果:
array([-0.03862668, -1.46128096, -0.75596237])
三维数组索引方式:
# 三维
a1 = np.array([ [[1,2,3],[4,5,6]], [[12,3,34],[5,6,7]]])
# 返回结果
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[12, 3, 34],
[ 5, 6, 7]]])
# 索引、切片
>>> a1[0, 0, 1] # 输出: 2
形状修改
ndarray.reshape(shape)
返回一个具有相同数据域,但shape不一样的新的数组
# 在转换形状的时候,一定要注意数组的元素匹配
stock_change.reshape([5, 4])
stock_change.reshape([-1,10]) # 数组的形状被修改为: (2, 10), -1: 表示通过待计算
ndarray.resize(new_shape)
修改数组本身的形状(需要保持元素个数前后相同)
stock_change.resize([5, 4])
# 查看修改后结果
stock_change.shape
(5, 4)
ndarray.T
数组的转置,即将数组的行、列进行互换,返回新的数组
stock_change.T.shape
(4, 5)
类型修改
ndarray.astype(type)
返回修改了类型之后的数组
stock_change.astype(np.int32)
数组的去重
np.unique()
temp = np.array([[1, 2, 3, 4],[3, 4, 5, 6]])
>>> np.unique(temp)
array([1, 2, 3, 4, 5, 6])
小结2
创建数组【掌握】
生成0和1的数组
np.ones()
np.ones_like()
从现有数组中生成
np.array -- 深拷贝
np.asarray -- 浅拷贝
生成固定范围数组
np.linspace()
nun -- 生成等间隔的多少个
np.arange()
step -- 每间隔多少生成数据
np.logspace()
生成以10的N次幂的数据
生层随机数组
正态分布
里面需要关注的参数:均值:u, 标准差:σ
u -- 决定了这个图形的左右位置
σ -- 决定了这个图形是瘦高还是矮胖
np.random.randn()
np.random.normal(0, 1, 100)
均匀
np.random.rand()
np.random.uniform(0, 1, 100)
np.random.randint(0, 10, 10)
数组索引【知道】
直接进行索引,切片
对象[:, :] -- 先行后列
数组形状改变【掌握】
对象.reshape()
没有进行行列互换,新产生一个ndarray
对象.resize()
没有进行行列互换,修改原来的ndarray
对象.T
进行了行列互换
数组去重【知道】
np.unique(对象)















 6961
6961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









