



全国计算机等级考试二级笔试样卷C语言程序设计-解答
样卷在这里!
以下内容均为个人答案,如有错误请联系我修正!谢谢~
正在学习中…
选择题答案(没有学习过数据结构,8-10题未做):
1~10 DADBD CD BA
21~40 DACBC DBCAC BB…
11~20 ADDAD CDAAC
填空题答案:
(1)
(2)程序调试
(3)元组(记录)
(4)栈
(5)线性结构
(6)123
(7)12 11
(8)
(9)1 1
(10)n/=10
(11)第一空x+8第二空sin(x)
(12)
(13)18
一、选择题((1)~(10)、(21)~(40)每题2分,(11)~(20)每题2分,共70分)
(1)下列选项中不符合良好程序设计风格的是(D)
A) 源程序要文档化
B) 数据说明的次序要规范化
C) 避免滥用goto语句
D) 模块设计要保证高耦合、高内聚
-
B项数据说明的次序应当规范化,编写任何代码都需要遵循一定的规范并且也要写出有自己风格的一套规范来,比如Java这种具有很强的逻辑性的语言一定要有逻辑!
-
C项正确,goto语句的坏处之前有讲过!
-
具体就是这样滴:
三,C语言中不允许使用goto语句?
不是不允许,是不提倡,最好不用;
goto使用注意(来自csdn):
不加限制地使用goto:破坏了清晰的程序结构,使程序的可读性变差,甚至成为不可维护的"面条代码"。经常带来错误或隐患,比如它可能跳过了某些对象的构造、变量的初始化、重要的计算等语句。
关于使用goto语句的原则:
(1)使用goto语句只能goto到同一函数内,而不能从一个函数里goto到另外一个函数里。
(2)使用goto语句在同一函数内进行goto时,goto的起点应是函数内一段小功能的结束处,goto的目的label处应是函数内另外一段小功能的开始处。
(3)不能从一段复杂的执行状态中的位置goto到另外一个位置,比如,从多重嵌套的循环判断中跳出去就是不允许的。
(4)应该避免向两个方向跳转。这样最容易导致"面条代码"。
- D项应为高耦合、低内聚!
- 原因:
以下内容来自CSDN:
https://blog.csdn.net/villainy13579/article/details/93507954
模块就是从系统层次去分成不同的部分,每个部分就是一个模块,分而治之, 将大型系统的复杂问题,分成不同的小模块,去处理问题。
耦合:
主要是讲模块与模块之间的联系
模块与模块之间有写操作是有关联的, 如果改动一个模块其他的模块都有可能受到影响,模块与模块之间的关系越是紧密,独立性就越不好。
例如:如果模块1直接操作了模块2红的数据,这种操作模块与模块之间就为强耦合,甚至可以认为这种情况之下基本算没有分模块!如果1只是通过数据与2模块交互,这种称之为弱耦合。
微服务独立的模块,方便去维护,或者写单元测试等等…如果模块之间的依赖非常严重,将会非常不易于维护。
内聚:
内聚主要指的是模块内部【东西聚合在一起形成了一个模块】例如方法,变量,对象,或者是功能模块
模块内部的代码, 相互之间的联系越强,内聚就越高, 模块的独立性就越好。
一个模块应该尽量的独立,去完成独立的功能!如果有代码非得引入到独立的模块,建议拆分成多模块!低内聚的代码,不好维护,代码也不够健壮。【代码必须要有健壮性噢~】
以下这些接口设计原则,就是参考低耦合高内聚
设计模式一般参照六大设计原则,许多的设计模式,包括一些框架,都是参考高内聚低耦合这个点的。
- 单一职责原则:一个类值负责一个功能的职责
- 开闭原则:扩展开放,修改关闭。
- 里氏代换原则:使用父类的地方都能使用子类对象
- 依赖倒转原则:针对接口编程,
- 接口隔离原则:针对不同部分用专门接口,不用总接口,需要哪些接口就用哪些接口
- 迪米特法则: 软件实体类,尽量不与其他实体类发生关系相互作用,对外都统一的暴露接口就行了
- 关于这道题的理解可以看看这个,写的很好!
https://blog.csdn.net/weixin_43319713/article/details/106591337?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161572593716780262599373%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=161572593716780262599373&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-106591337.first_rank_v2_pc_rank_v29&utm_term=%E6%BA%90%E7%A8%8B%E5%BA%8F%E6%96%87%E6%A1%A3%E5%8C%96
- 具体:
程序设计风格
源程序文档化:
- 标识符的命名
- 安排注释
- 程序的视觉组织
数据说明:
- 数据说明的次序应当规范化
- 当多个变量名在 一个语句中说明时,按字母顺序排列;
- 应当对过程和函数的形参排列有序:输入参数在前,输出参数在后;整型参数在前,实型参数次之,其他参数在后
结构化程序设计
强调使用几种基本控制结构、由粗到细,一步步展开
- 主要原则:
- 使用语言中的顺序、选择、重复等有限的基本控制结构表示程序逻辑。
- 选用的控制结构只准许有一个入口和一个出口
- 复杂结构应该用基本控制结构进行组合嵌套来实现
自顶向下,逐步细化的过程
(2)从工程管理角度,软件设计一般分为两步完成,它们是(A)
A) 概要设计与详细设计
B) 数据设计与接口设计
C) 软件结构设计与数据设计
D) 过程设计与数据设计
- 就是概设和详设!
(以下内容来自CSDN):
https://blog.csdn.net/jiangbqing/article/details/114122781?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161572652516780271547430%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=161572652516780271547430&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-114122781.first_rank_v2_pc_rank_v29&utm_term=%E8%BD%AF%E4%BB%B6%E8%AE%BE%E8%AE%A1%E4%B8%80%E8%88%AC%E5%88%86%E4%B8%BA%E4%B8%A4%E6%AD%A5%E5%AE%8C%E6%88%90
- 解析
- 设计阶段的主要目的是设计如何把已经确定的需求转换成实际的软件。
- 软件设计一般分为概要设计和详细设计两阶段。
- 概要设计也称为总体设计,其基本目标是能够对软件需求分析中提出的一系列软件问题,概要的回答问题如何解决,例如,软件系统将采用什么样的体系架构,需要创建哪些功能模块,模块之间的关系如何,数据结构如何,软件系统需要提供什么样的网络环境提供者支持,需要采用什么类型的后台数据库等。
- 经过概要设计阶段的工作,已经确定了软件的模块结构和接口描述,但每个模块如何实现仍不清晰,详细设计阶段的根本目标是确定如何具体的实现所要求的系统,也就是说,经过这个阶段的设计工作,应该得出对目标系统的精确描述,因此,详细设计的结果基本上决定了最终程序代码的质量。
- 以下内容来自CSDN:
https://blog.csdn.net/weixin_39889788/article/details/111157584?ops_request_misc=&request_id=&biz_id=102&utm_term=%E8%BD%AF%E4%BB%B6%E8%AE%BE%E8%AE%A1%E4%B8%80%E8%88%AC%E5%88%86%E4%B8%BA%E4%B8%A4%E6%AD%A5%E5%AE%8C%E6%88%90&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-8-111157584.first_rank_v2_pc_rank_v29
软件设计的基本概念
软件设计是确定系统的物理模型。
软件设计是开发阶段最重要的步骤,是将需求准确地转化为完整的软件产品或系统的唯一途径。
从技术观点上看,软件设计包括软件结构设计、数据设计、接口设计、过程设计。
(1)结构设计定义软件系统各主要部件之间的关系;
(2)数据设计将分析时创建的模型转化为数据结构的定义;
(3)接口设计是描述软件内部、软件和协作系统之间以及软件与人之间如何通信;
(4)过程设计则是把系统结构部件转换为软件的过程性描述。
从工程管理角度来看,软件设计分两步完成:概要设计和详细设计。
(1)概要设计将软件需求转化为软件体系结构、确定系统级接口、全局数据结构或数据库模式;
(2)详细设计确立每个模块的实现算法和局部数据结构,用适当方法表示算法和数据结构的细节。
(3)下列选项中不属于软件生命周期开发阶段任务的是(D)
A)软件测试 B)概要设计 C)软件维护 D)详细设计
软件生命周期
- 定义:
https://baike.baidu.com/item/%E8%BD%AF%E4%BB%B6%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F/861455?fr=aladdin- 它是指软件产品从提出、实现、使用维护到停止使用退役的整个过程。可分为软件定义,软件开发及软件维护3个阶段。软件生命周期中,能够准确确定软件系统必须做什么和必须具备哪些功能的阶段是:需求分析。
- 详细解释:
内容来自:https://zhidao.baidu.com/question/319031139.html- 软件生命周期分为问题定义、可行性研究、需求分析、开发阶段、维护这5个阶段。各个阶段的主要任务是:
1、问题定义
要求系统分析员与用户进行交流,弄清“用户需要计算机解决什么问题”然后提出关于“系统目标与范围的说明”,提交用户审查和确认。
2、可行性研究
一方面在于把待开发的系统的目标以明确的语言描述出来,另一方面从经济、技术、法律等多方面进行可行性分析。
3、需求分析
弄清用户对软件系统的全部需求,编写需求规格说明书和初步的用户手册,提交评审。
4、开发阶段
开发阶段由四个阶段组成:概要设计、详细设计、实现、测试(两个设计)
5、维护
维护包括四个方面:
(1)改正性维护:在软件交付使用后,由于开发测试时的不彻底、不完全、必然会有一部分隐藏的错误被带到运行阶段,这些隐藏的错误在某些特定的使用环境下就会暴露。
(2)适应性维护:是为适应环境的变化而修改软件的活动。
(3)完善性维护:是根据用户在使用过程中提出的一些建设性意见而进行的维护活动。
(4)预防性维护:是为了进一步改善软件系统的可维护性和可靠性,并为以后的改进奠定基础。
- 可以知道软件维护是开发以外的另一个阶段!
- 解析:内容来自
https://www.cnblogs.com/137point5/p/13701119.html
软件生命周期开发的五个阶段:
第一阶段:计划和需求分析(Planning and Requirement Analysis)
第二阶段:设计项目构架(Project Archiecture)
第三阶段:开发和编程(Development and coding)
第四阶段:测试(Testing)
第五阶段:部署(Deployment)
(4)在数据库系统中,用户所见的数据模式为(B)
A) 概念模式 B)外模式 C)内模式 D)物理模式
解释:
内容来自:
https://blog.csdn.net/liaohong940908/article/details/51906697/?ops_request_misc=&request_id=&biz_id=102&utm_term=%E6%95%B0%E6%8D%AE%E5%BA%93%E7%B3%BB%E7%BB%9F%E4%B8%AD%E7%94%A8%E6%88%B7%E6%89%80%E8%A7%81%E6%95%B0%E6%8D%AE%E6%A8%A1%E5%BC%8F&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-51906697.first_rank_v2_pc_rank_v29
外模式(External Schema)
定义:也称子模式(Subschema)或用户模式,是数据库用户(包括应用程序员和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。
理解:
① 一个数据库可以有多个外模式;
② 外模式就是用户视图;
③ 外模式是保证数据安全性的一个有力措施。
外模式(External Schema)
是用户的数据视图,亦即是用户所见到的模式的一个部分,它由概念模式推导而出,概念模式给出了系统全局的数据描述而外模式则给出每个用户的局部描述。一个概念模式可以有若干个外模式,每个用户只关心与它有关的模式,这样可以屏蔽大量无关信息且有利于数据保护,因此对用户极为有利。在一般的DBMS中都提供有相关的外模式描述语言(外模式DDL)。
(5)数据库设计的四个阶段是:需求分析、概念设计、逻辑设计和(D)
A) 编码设计 B) 测试阶段 C)运行阶段 D)物理设计
解释:
数据库设计分为四个阶段:
1)需求分析阶段:编写软件规格说明书及初步的用户手册,提交评审。
2)概念设计(概要设计)阶段:E-R图设计阶段。
3)逻辑设计阶段:主要是E_R转换成关系模式。
4)物理设计阶段。
参考:
https://blog.csdn.net/k3108001263/article/details/87073831
https://blog.csdn.net/Edraw_Max/article/details/108871488?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161572798416780262541683%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=161572798416780262541683&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-4-108871488.first_rank_v2_pc_rank_v29&utm_term=%E6%95%B0%E6%8D%AE%E5%BA%93%E8%AE%BE%E8%AE%A1%E7%9A%84%E5%9B%9B%E4%B8%AA%E9%98%B6%E6%AE%B5
https://blog.csdn.net/sinat_21312425/article/details/51105252?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161572798416780262541683%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=161572798416780262541683&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-5-51105252.first_rank_v2_pc_rank_v29&utm_term=%E6%95%B0%E6%8D%AE%E5%BA%93%E8%AE%BE%E8%AE%A1%E7%9A%84%E5%9B%9B%E4%B8%AA%E9%98%B6%E6%AE%B5
(6)设有如下三个关系表

下列操作中正确的是(C)
A)T=R∩S B)T=R∪S
C)T=R×S D)T=R/S
这个不懂,猜的~
(7)下列叙述中正确的是(D)
A)一个算法的空间复杂度大,则其时间复杂度也必定大
B)一个算法的空间复杂度大,则其时间复杂度必定小
C)一个算法的时间复杂度大,则其空间复杂度必定小
D)上述三种说法都不对
解释:
内容来自:
https://blog.csdn.net/sunstars2009918/article/details/6755965?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161572840116780262570816%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=161572840116780262570816&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~baidu_landing_v2~default-2-6755965.first_rank_v2_pc_rank_v29&utm_term=%E7%AE%97%E6%B3%95%E7%9A%84%E7%A9%BA%E9%97%B4%E5%A4%8D%E6%9D%82%E5%BA%A6%E5%92%8C%E6%97%B6%E9%97%B4%E5%A4%8D%E6%9D%82%E5%BA%A6%E7%9A%84%E5%85%B3%E7%B3%BB
有“必定”的话不对。因为对一些特殊情况存在特例有高的时空复杂度或同时为低的时空复杂度。但对一般情况下给定存储空间如给定65535K的内存但不限定时间时,就存在时间空间的负相关关系。对于既不限定时间,也不限定空间的程序,算法的时间复杂度和空间复杂度可以同时很大,也可以同时很小。如T(n)=O(n)且S(n)=O(1)的情况比如一个for(i=0;i<N;i++),若循环体中为一个与问题规模无关的变量变化,则其S(n)=O(1),而T(n)=O(n)是随着N的变化而变化的,这时可以说时间复杂度较小而空间复杂度很小。
参考:
https://blog.csdn.net/zolalad/article/details/11848739?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161572830116780269837828%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=161572830116780269837828&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-11848739.first_rank_v2_pc_rank_v29&utm_term=%E7%AE%97%E6%B3%95%E7%9A%84%E7%A9%BA%E9%97%B4%E5%A4%8D%E6%9D%82%E5%BA%A6%E5%92%8C%E6%97%B6%E9%97%B4%E5%A4%8D%E6%9D%82%E5%BA%A6
*(8)在长度为64的有序线性表中进行顺序查找,最坏情况下需要比较的次数为
A)63 B)64 C)6 D)7
*(9)数据库技术的根本目标是要解决数据的(B)
A)存储问题 B)共享问题 C)安全问题 D)保护问题
解释:
数据库系统是由数据库(数据),数据库管理系统(软件),计算机硬件,操作系统及数据库管理员组成。作为处理数据库的系统,数据库技术的主要目的就是解决数据的共享问题
*(10)对下列二叉树
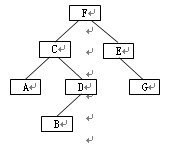
进行中序遍历的结果是(A)
A)ACBDFEG B)ACBDFGE C)ABDCGEF D)FCADBEG
解释:
本小白只会用排除法,不过考的是公共基础部分的内容,不会考数据结构的困难部分,所以简单的理解就好~
详细解析:
来自CSDNhttps://blog.csdn.net/u013834525/article/details/80421684
一棵二叉树由根结点、左子树和右子树三部分组成,若规定 D、L、R 分别代表遍历根结点、遍历左子树、遍历右子树,则二叉树的遍历方式有 6 种:DLR、DRL、LDR、LRD、RDL、RLD。由于先遍历左子树和先遍历右子树在算法设计上没有本质区别,所以,只讨论三种方式:
- DLR–前序遍历(根在前,从左往右,一棵树的根永远在左子树前面,左子树又永远在右子树前面 )【根–左子树–右子树】
- LDR–中序遍历(根在中,从左往右,一棵树的左子树永远在根前面,根永远在右子树前面)【左子树–根--右子树】
- LRD–后序遍历(根在后,从左往右,一棵树的左子树永远在右子树前面,右子树永远在根前面)【左子树–根--右子树】
(11)下列叙述中错误的是(A)
A)一个C语言程序只能实现一种算法
B)C程序可以由多个程序文件组成
C)C程序可以由一个或多个函数组成
D)一个C函数可以单独作为一个C程序文件存在
解释:
A:一个C语言程序可以实现多种算法
D:不只是main函数,其他函数也能作为单独文件形式存在——
其实函数和文件没有直接关系。将main函数作为单独文件只是因为程序简单等原因没有特意给主文件命名。任何一个函数只要你愿意都可以单独成一个文件,反过来,main函数所在的文件除main函数之外还可以有其他函数
放在同一个项目里面,在头文件里面include这个函数所在文件就可以了
(12)下列叙述中正确的是(D)
A)每个C程序文件中都必须要有一个main()函数
B)在C程序中main()函数的位置是固定的
C)C程序中所有函数之间都可以相互调用,与函数所在位置无关
D)在C程序的函数中不能定义另一个函数
解释:
A:C程序中并不是所有文件里面都需要main函数。
C程序中最多只能有一个main函数
B:C程序中main函数的位置不是固定的。
C:必须要有声明噢~
成立应该有一个前提,就是与声明的位置有关,和子函数代码的位置无关。
在main前面写子函数代码的时候,是不用在main中声明的,但是在main后面写子函数代码的时候,一定要在main里面声明,不然会出错。
如果所有函数都可以相互调用的话…main函数估计不能被其他函数调用。
声明为extern的函数不能被其他文件的函数所调用
D:嵌套定义不被允许,but之前有讲过!
具体:
二十,在c程序中,函数可能嵌套定义,也可以嵌套调用(F); //不能嵌套定义,但可以嵌套调用
(13)下列定义变量的语句中错误的是(D)
A)int _int; B)double int_; C)char For; D)float US$;
解释:
不能包含有特殊字符$.
(14)若变量x、y已正确定义并赋值,以下符合C语言语法的表达式是(A)
A)++x,y=x-- B)x+1=y C)x=x+10=x+y D)double(x)/10
解释:
B:在C语言的赋值表达式中,赋值对象必须是一个变量,而选项B中子表达式x+1代表的是一个临时常量,因此不能将y赋给x+1。
C:这是未定义行为,C语言标准没有规定这样的表达式求值顺序应该是什么,而x的值与求值顺序直接相关,因而x的值是多少也是不能确定的。这种表达式是十分糟糕的。C中由于“=”运算符是从右至左运算的,即原表达式相当于x=(x+10=x+y),所以也犯了对一个临时常量赋值的错误。
D:将 x强制转换为double类型的表达式应该为(double)x。
(15)以下关于逻辑运算符两侧运算对象的叙述中正确的是(D)
A)只能是整数0或1 B)只能是整数0或非0整数
C)可以是结构体类型的数据 D)可以是任意合法的表达式
(16)若有定义int x,y; 并已正确给变量赋值,则以下选项中与表达式(x-y)?(x++) : (y++)中的条件表达式(x-y) 等价的是(C)
A)(x-y>0) B)(x-y<0) C)(x-y<0||x-y>0) D)(x-y==0)
解释:
原表达式含义:x-y为真则执行表达式一x++,为假则执行表达式二y++。
不等于零就是真哒!
(17)有以下程序
main()
{ int x, y, z;
x=y=1;
z=x++,y++,++y;
printf("%d,%d,%d\n",x,y,z);
}
程序运行后的输出结果是(D)
A)2,3,3 B)2,3,2 C)2,3,1 D)2,2,1
(18)设有定义:int a; float b; 执行 scanf("%2d%f",&a,&b); 语句时,若从键盘输入876 543.0<回车>,a和b的值分别是(A)
A)876和543.000000 B)87和6.000000
C)87和543.000000 D)76和543.000000
(19)有以下程序
main()
{ int a=0, b=0;
a=10; /* 给a赋值
b=20; 给b赋值 */
printf("a+b=%d\n",a+b); /* 输出计算结果 */
}
程序运行后的输出结果是(A)
A)a+b=10 B)a+b=30 C)30 D)出错
(20)在嵌套使用if语句时,C语言规定else总是(C)
A)和之前与其具有相同缩进位置的if配对
B)和之前与其最近的if配对
C)和之前与其最近的且不带else的if配对
D)和之前的第一个if配对
(21)下列叙述中正确的是(D)
A)break语句只能用于switch语句
B)在switch语句中必须使用default
C)break语句必须与switch语句中的case配对使用
D)在switch语句中,不一定使用break语句
(22)有以下程序
#include<stdio.h>
int main()
{
int k=5;
while(--k) //为真即不为零时进入循环!
/*--k为4,3,2,1;0不会进入循环*/
//注意下一次进入循环的会是执行输出表达式中语句后的k值!!!
{
printf("%d",k -= 3); //k=k-3,即输出的值为1
}
//显然只输出一次之后结果就为零了!
//所以执行结果为1~
printf("\n");
return 0;
}
执行后的输出结果是(A)
A)1 B)2 C)4 D)死循环
(23)有以下程序
#include <stdio.h>
int main()
{
//i从1-40循环(都可取)
for(int i=1;i<=40;i++)
{
//满足第一个if才会执行第二个if
if((i++)%5==0)
{ //%左结合,i++为5、10、15、20、25、30、35、40,i为4、9、14、19、24、29、34、39
//满足第一个if的数字i执行下一步骤前i已经+1!!!
/*i=5、10、15、20、25、30、35、40;*/
//执行此步骤前i再次+1!!!
/*i=6、11、16、21、26、31、36、41*/
if((++i)%8==0)
{
//++i为8、16、24、32、40,i为7、15、23、31、39 /*重合项i=31,++i=32*/
//两种情况必须都满足才会输出,此时i=39
printf("%d ",i);
}
}
}
printf("\n");
return 0;
}
报错解析:
[Error] stray ‘\241’ in program
含有非法字符或非法空格
执行后的输出结果是(C)
A)5 B)24 C)32 D)40
(24)以下选项中,值为1的表达式是(B)
A)1 –'0' B)1 - '\0' C)'1' -0 D)'\0' - '0'
解释:
A为-47;字符'0'的ascii码值为48!
B为1;字符'\0的ascii码值为0!
C为49;数值型1和字符型1的ascii码输出后都为49!
D为-48;
字符型变量用于存储一个单一字符,在 C 语言中用 char 表示,其中每个字符变量都会占用 1 个字节(8位二进制数)。
整型int在内存中占用空间为四个字节(32位二进制数)
字符’0’:char c = ‘0’; 它的ASCII码实际上是48。内存中存放表示:00110000
字符’\0’:ASCII码为0,表示一个字符串结束的标志。这是转义字符(整体视为一个字符)。由于内存中存储字符,依然是存储的是对应字符集的字符编码;所以内存中的表现形式为00000000
整数0 :内存中表示为:00000000 00000000 00000000
00000000;虽然都是0,但是跟上面字符’\0’存储占用长度是不一样的;
(25)有以下程序
#include <stdio.h>
//求两数之和的函数fun定义
fun(int x, int y)
{ return (x+y); }
//主函数main
int main()
{
int a=1, b=2, c=3, sum;
sum=fun((a++,b++,a+b),c++); //fun函数的第一个参数是(2,3,5),逗号表达式从左向右结合,即值为3,第二个参数值为3,所以调用函数求得和为8
printf("%d\n",sum);
return 0;
}
执行后的输出结果是(C)
A)6 B)7 C)8 D)9
(26)有以下程序
#include <stdio.h>
int main()
{
char s[]="abcde"; //定义字符串数组s[6]并初始化为abcde\0
s+=2; //??? 字符数组+2代表什么???
printf("%d\n",s[0]);
return 0;
}
执行后的结果是(D)
A)输出字符a的ASCII码 B)输出字符c的ASCII码
C)输出字符c D)程序出错
解释:
程序报错:
[Error] incompatible types in assignment of ‘int’ to ‘char [6]’
[错误]在将’int’分配给’char [6]'时使用了不兼容的类型
参考:
来自csdnhttps://blog.csdn.net/cloud323/article/details/75530482
(27)有以下程序
#include <stdio.h>
int fun(int x, int y)
{
static int m=0, i=2; //静态局部变量m、i
i+=m+1; //右结合,即i=i+(m+1) ,i=2+1=3 //i=3+6=9
m=i+x+y; //m=3+x+y //m=9+1+1
return m;
}
int main()
{
int j=1, m=1, k; //局部变量j、m、k
k=fun(j,m); //参数(1,1) ,函数调用作为表达式! 值传给k
printf("%d,",k); //5,
k=fun(j,m);
printf("%d\n",k); //第二次调用函数m的值已经改变,为11
return 0; //输出结果为5,11换行
}
执行后的输出结果是(B)
A)5, 5 B)5, 11 C)11, 11 D)11, 5
(28)有以下程序
#include<stdio.h>
int fun(int x)
{
int p;
if(x==0||x==1)
return(3); //两个return语句,如果进入if语句,执行到第一个就会退出被调函数
p=x-fun(x-2); //7-fun(5),7-(5-fun(3)),7-(5-(3-fun(1)),7-(5-(3-3))=2
return p;
}
int main()
{
printf("%d\n",fun(7)); //函数的递归调用,减小运算规模
return 0;
}
执行后的输出结果是(C)
A)7 B)3 C)2 D)0
(29)在16位编译系统上,若有定义int a[]={10,20,30}, *p=&a;,当执行p++;后,下列说法错误的是(A)
A)p向高地址移了一个字节 B)p向高地址移了一个存储单元
C)p向高地址移了两个字节 D)p与a+1等价
解释:
16位编译系统:整数int占2个字节(16位)的C编译系统,如TC。
*p=&(a+1),p=a+1
(30)有以下程序
#include <stdio.h>
int main()
{
int a=1, b=3, c=5;
int *p1=&a, *p2=&b, *p=&c; //*p如果不赋值,就是指向不明,这样不太好!
*p =*p1*(*p2); //第三个*代表乘号;*p=*p1*(*p2)就代表*p=a*b=3,因为*p=&c,所以p=c,所以c=3
printf("%d\n",c); //3
}
执行后的输出结果是(C)
A)1 B)2 C)3 D)4
(31)若有定义:int w[3][5]; ,则以下不能正确表示该数组元素的表达式是【注意是元素,不是地址】:(B)
A)*(*w+3) B)*(w+1)[4] C)*(*(w+1)) D)*(&w[0][0]+1)
解释:
A:*(*w+3)表示w[0][3];
B:*(w+1)不表示w[1],它表示的是一个内容,(*w+1)表示w[1],是一个地址,中括号[ ]是转换地址的一个符号。
*(*(w+1)+4)是二维数组中的w[1][4],它表示的是一个数组元素。
*(w+1)[4] 正确的写法(*w+1)[4],表示w[1][4];
C:*(w+1)表示w[1],*(*w+1)等价于*(*(w+1))表示w[0][1];
D: *(&w[0][0]+1)表示w[0][1];字面意思就是w[0][0]右移一位即加一为w[0][1],&取地址,*取内容,所以还是w[0][1]。
参考——
来自:https://wenda.so.com/q/1534481635213608
(32)若有以下函数首部
int fun(double x[10], int *n)
则下面针对此函数的函数声明语句中正确的是(B)
A)int fun(double x, int *n); B)int fun(double , int );
C)int fun(double *x, int n); D)int fun(double *, int *);
解释:
- 函数声明用于函数定义在main函数之后时;
- 函数声明可以不加形参变量名,无实际意义,但一般会加;
- 声明其实是定义的第一行加了一个分号,所以类型是不允许发生变化的。
- D项无法区分double类型是数组还是指针,不如不加(个人理解…)
*(33)有以下程序
#include <stdio.h>
void change(int k[]) //无返回值函数,空类型
{
k[0]=k[5];
}
int main()
{
int x[10]={1,2,3,4,5,6,7,8,9,10},n=0;
while( n<=4 ) //n=0,1,2,3,4都会执行!
{
change( &x[n]);
n++;
}
for(n=0; n<5; n++)
printf("%d ",x[n]); //输出数组的前五个元素:6 7 8 9 10
printf("\n");
}
程序运行后输出的结果是
A)6 7 8 9 10 B)1 3 5 7 9 C)1 2 3 4 5 D)6 2 3 4 5
(34)有以下程序
main()
{ int x[3][2]={0}, i;
for(i=0; i<3; i++) scanf("%d",x[i]);
printf("%3d%3d%3d\n",x[0][0],x[0][1],x[1][0]);
}
若运行时输入:2 4 6<回车>,则输出结果为
A)2 0 0 B)2 0 4 C)2 4 0 D)2 4 6
(35)有以下程序
int add( int a,int b){ return (a+b); }
main()
{ int k, (*f)(), a=5,b=10;
f=add;
…
}
则以下函数调用语句错误的是
A)k=(*f)(a,b); B)k=add(a,b);
C)k= *f(a,b); D)k=f(a,b);
(36)有以下程序
#include
main( int argc, char *argv[ ])
{ int i=1,n=0;
while (i
printf("%d\n",n);
}
该程序生成的可执行文件名为:proc.exe。若运行时输入命令行:
proc 123 45 67
则程序的输出结果是
A)3 B)5 C)7 D)11
(37)有以下程序
# include
# define N 5
# define M N+1
# define f(x) (x*M)
main()
{ int i1, i2;
i1 = f(2) ;
i2 = f(1+1) ;
printf("%d %d\n", i1, i2);
}
程序的运行结果是
A)12 12 B)11 7 C)11 11 D)12 7
(38)有以下结构体说明、变量定义和赋值语句:
struct STD
{ char name[10];
int age;
char sex;
} s[5],*ps;
ps=&s[0];
则以下scanf函数调用语句中错误引用结构体变量成员的是
A)scanf("%s",s[0].name); B)scanf("%d",&s[0].age);
C)scanf("%c",&(ps->sex)); D)scanf("%d",ps->age);
(39)若有以下定义和语句
union data
{ int i; char c; float f; } x;
int y;
则以下语句正确的是
A)x=10.5; B)x.c=101; C)y=x; D)printf("%d\n",x);
(40)有以下程序
#include
main()
{ FILE *fp;
int i;
char ch[]="abcd",t;
fp=fopen("abc.dat","wb+");
for(i=0; i<4; i++) fwrite(&ch[i],1,1,fp);
fseek(fp,-2L,SEEK_END); //重定位
fread(&t,1,1,fp); //
fclose(fp); //
printf("%c\n",t);
}
程序执行后的输出结果是
A)d B)c C)b D)a
二、填空题(每空2分,共30分)
(1)下列软件系统结构图的宽度为 【1】 。
(2) 【程序调试】 的任务是诊断和改正程序中的错误。
(3)一个关系表的行称为 【元组】(记录) 。
(4)按“先进后出”原则组织数据的数据结构是 【栈】 。
(5)数据结构分为线性结构和非线性结构,带链的队列属于 【线性结构】 。
解释:
队列就是线性的,什么队列都是线性的。
(6)设有定义:float x=123.4567;,则执行以下语句后的输出结果是 【123】 。
printf("%f\n",(int)(x*100+0.5)/100.0); //转为int类型:12345.67,12346.17,123.4617,123
(7)以下程序运行后的输出结果是 【12 11】 。
main()
{ int m=011,n=11; //八进制011,变为10进制0*10e2+1*10e1+1*10e0=11;
printf("%d %d\n",++m, n++); //12,11
}
(8)以下程序运行后的输出结果是 【8】 。
main()
{ int x,a=1,b=2,c=3,d=4;
x=(a x=(x x=(d>x) ? x : d;
printf("%d\n",x);
}
(9)有以下程序,若运行时从键盘输入:18,11<回车>,则程序的输出结果是 【1 1 】 。
main()
{ int a,b;
printf("Enter a,b:");
scanf("%d,%d",&a,&b);
while(a!=b)
{
while(a>b) a -= b;
while(b>a) b -= a;
}
printf("%3d%3d\n",a,b);
}
(10)以下程序的功能是:将输入的正整数按逆序输出。例如:若输入135则输出531。请填空。
#include <stdio.h>
//正整数逆序输出
int main()
{
int n,s;
printf("Enter a number : ");
scanf("%d",&n);
printf("Output: ");
do
{
s=n%10;
printf("%d",s); //输出原最后一位数,现在的第一位数
n/=10; //这里是那个空空的地方
}while(n!=0);
printf("\n");
return 0;
}
(11)以下程序中,函数fun的功能是计算x2-2x+6,主函数中将调用fun函数计算,填空空:
//y1=(x+8)2-2(x+8)+6
//y2=sin2(x)-2sin(x)+6
#include <stdio.h>
#include "math.h"
double fun(double x)
{
return (x*x-2*x+6);
//观察发现符合y1的式子,将x换为(x+8)
//观察发现符合y2的式子,将x换为sin(x)
}
int main()
{
double x,y1,y2;
printf("Enter x:");
scanf("%lf",&x);
y1=fun(x+8);
y2=fun(sin(x));
printf("y1=%lf,y2=%lf\n",y1,y2);
}
(12)下面程序的功能是:将N行N列二维数组中每一行的元素进行排序,第0行从小到大排序,第1行从大到小排序,第2行从小到大排序,第3行从大到小排序,例如:
//偶数升序,奇数降序排序
#define N 4 //4行,0,1,2,3,4列,0,2,4升序,1,3降序
void sort(int a[][N])
{
int i, j, k, t;
for (i=0; i<N;i++)
for (j=0; j<N-1;j++)
for (k= () ; k<N;k++)
/*判断行下标是否为偶数来确定按升序或降序来排序*/
if ( (j%2==0)? a[i][j]<a[i][k]:a[i][j]>a[i][k])
{
t = a[i][j];
a[i][j]=a[i][k];
a[i][k] = t;
}
}
/*以矩阵的形式输出二维数组*/
//编写函数
void outarr(int a[N][N])
{
/*TODO--*/
printf("二维矩阵为:\n");
for(int m=0;m<N;m++)
{
for(int n=0;n<N;n++)
{
printf("%d",aa[N][N]);
}
}
}
main()
//定义二维数组N行N列
{
int aa[N][N]={{2,3,4,1},{8,6,5,7},{11,12,10,9},{15,14,16,13}};
//输出原二维数组
outarr(aa); /*以矩阵的形式输出二维数组*/
//给二维数组排序
sort(aa);
//输出排序后的二维数组
outarr(aa);
}


















 255
255



 到【灌水乐园】发言
到【灌水乐园】发言







