







本篇文章将带你使用ocr识别通过人机验证码
豆瓣很骚,莫名其妙就总会出来人机验证,用了代理也过不去,感觉是通过cookies识别你是否为爬虫,一识别就出404弹个人机验证,为了防止爆人机,也想了很多方法,随机ip,随机ua,延时,能试的都试了,看过有些大佬是在爆人机之后就清空cookie,不使用cookie请求然后拿到最新的cookie,一直重复此步骤,太麻烦了!咱们直接暴力干验证码。
现在ocr识别的很多,国内就有大佬弄了用于识别验证码,我们直接用大佬造好的轮子就好啦,ddddocr,支持后期训练提高精度,还是非常好用的。
先正常的写程序,我们这里直接干电影区,爬电影的标题分类还有id啥的,趁他不注意先白嫖一波数据。非常的奇怪,只爬首页倒是不人机我了,但是经常爆一个gbk编码错误的错不知道是什么原因,咱们再多爬点试试。
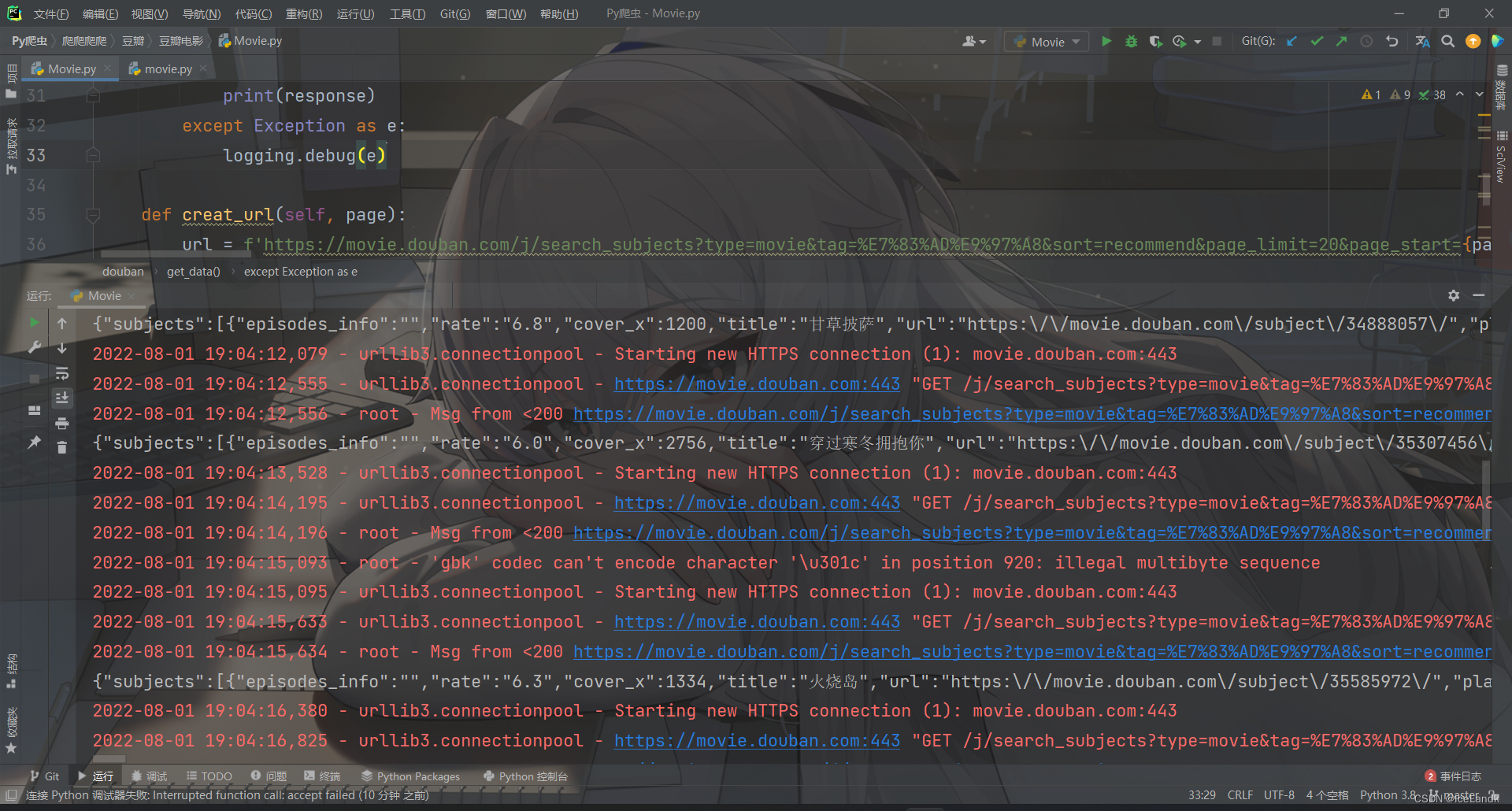
来了来了!!!!
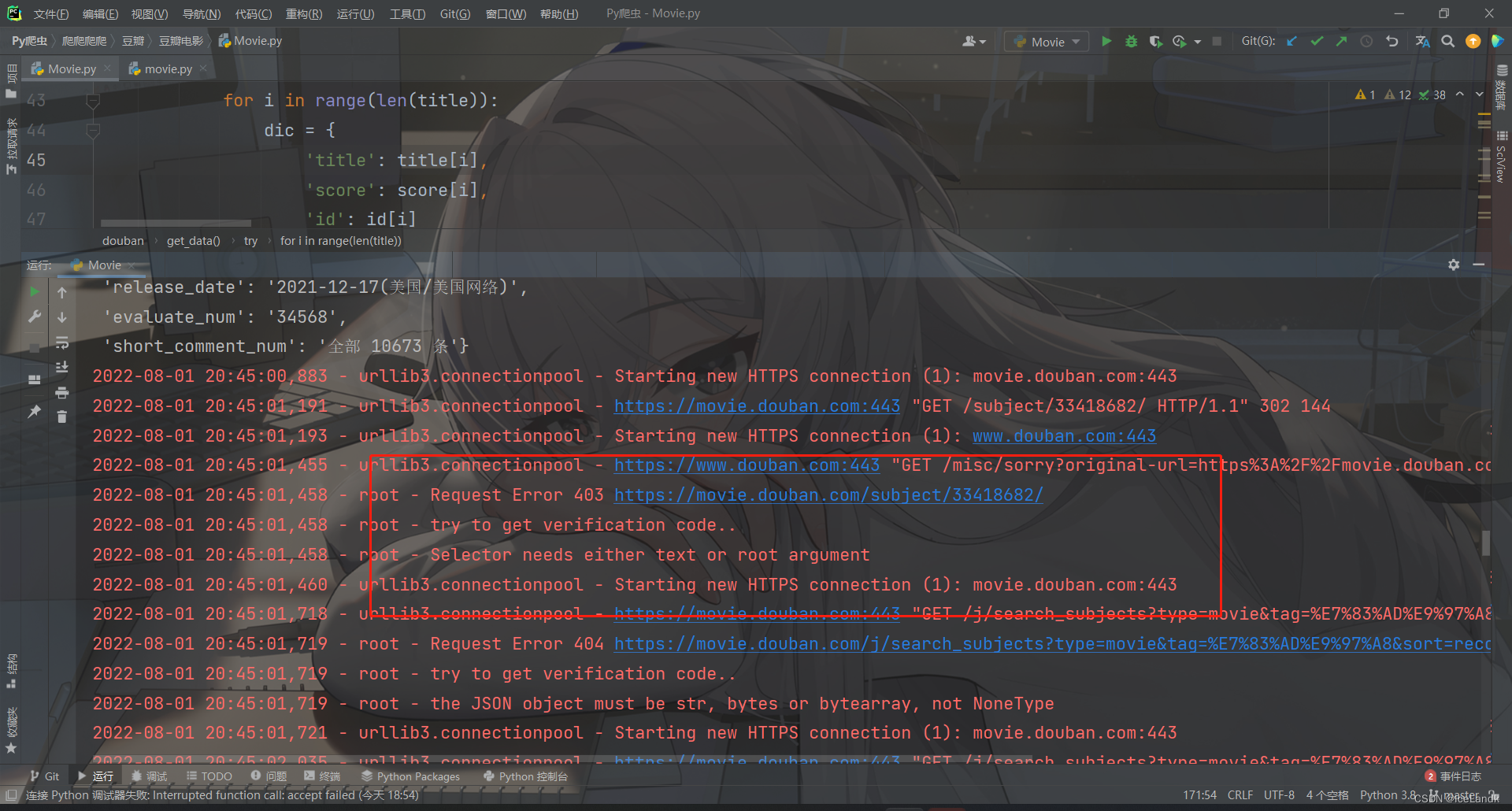
被人机检测的时候就会给我们返回403,404的状态码,接着开始进入我们的正题,该如何通过验证码?
1. 解析网页,获取图片验证码
这里我们之前已经写好了,直接把注释解掉用就行,就是使用xpath把验证码图片提取出来然后保存至本地就行,豆瓣的人机验证url永远都是这一个https://www.douban.com/misc/sorry?original-url=https%3A%2F%2Fmovie.douban.com%2Fsubject%2F33418682%2F
后面的subject参数可以不要,直接丢弃。注意请求人机验证页面时记得把之前使用的cookie带上。
随机填入123456看看是哪个发送了表单进行验证,初次猜测是这一个,我们自行手动发包看看,直接把表单里的参数都扣下来。,然后把验证码captcha-solution参数修改成和图片一样的验证码,提交请求。
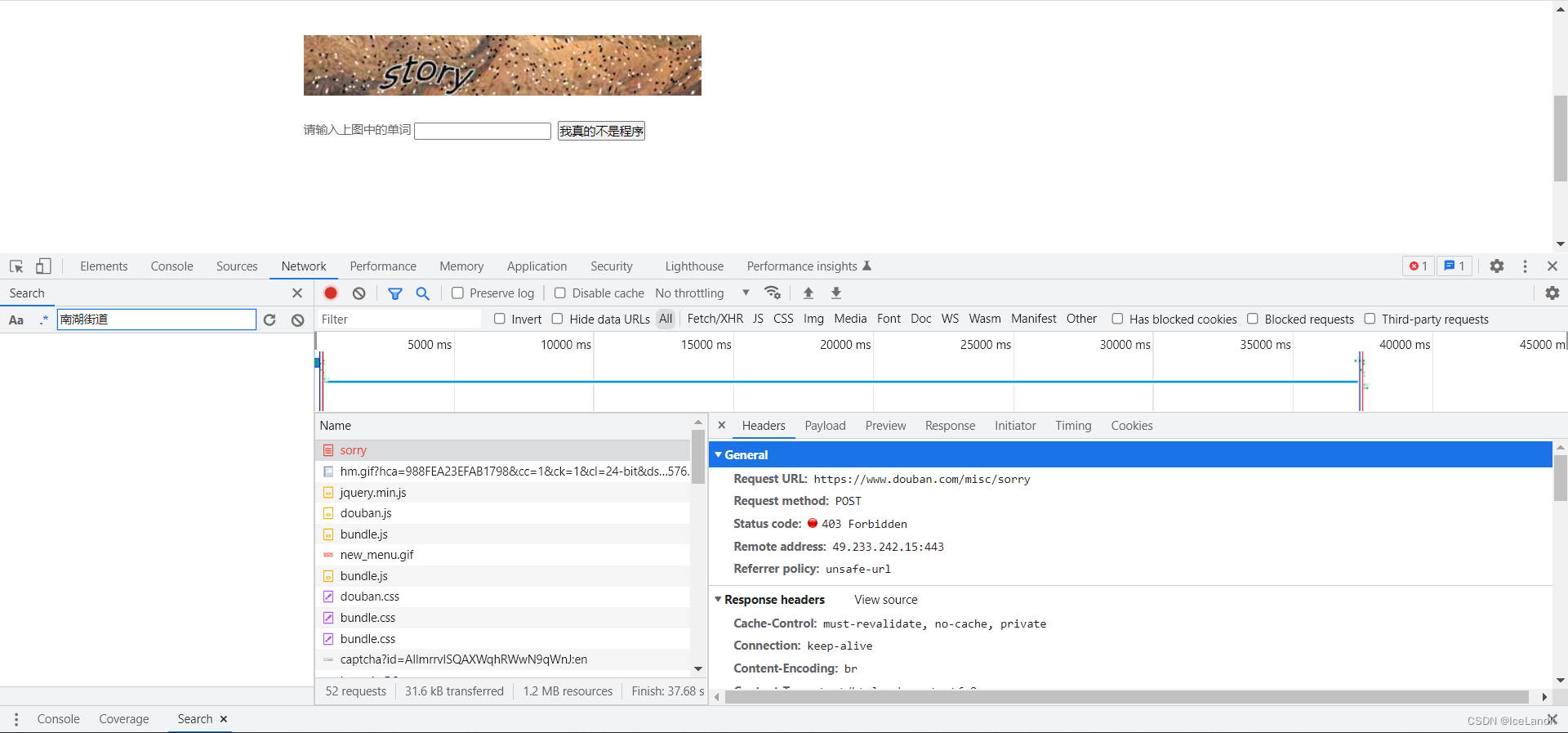
发现还是和原来一样,验证未通过,证明我们的表单参数不正确,咱们再看一下
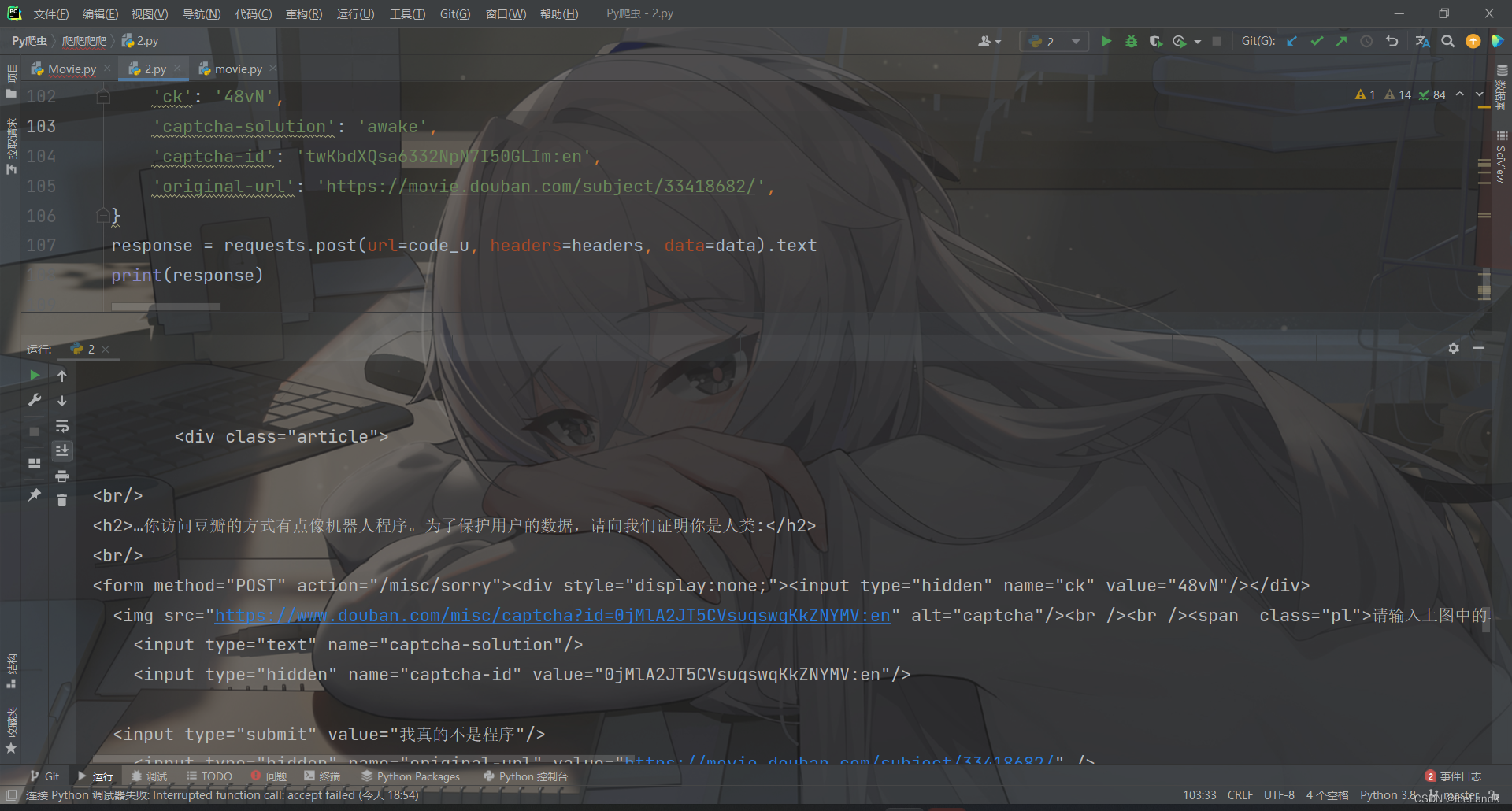
这里很明显,豆瓣不止验证了captcha-solution这个参数,同时还验证了captcha-id,这俩个参数都和加载出来的图片有关系,captcha-solution我们能够确定是图片中的验证码,那captcha-id是啥呢?在这边包之前并未返回其他的包,所以可以基本肯定这个参数是在某个小黑屋加密后返回的值。

Other ?

看到other我们直接去前端页面的代码里头找,绝对能找到加密的位置,直接复制这个url后边的尾缀misc/sorry到前端代码搜索去,不搜不知道,一搜吓一跳!
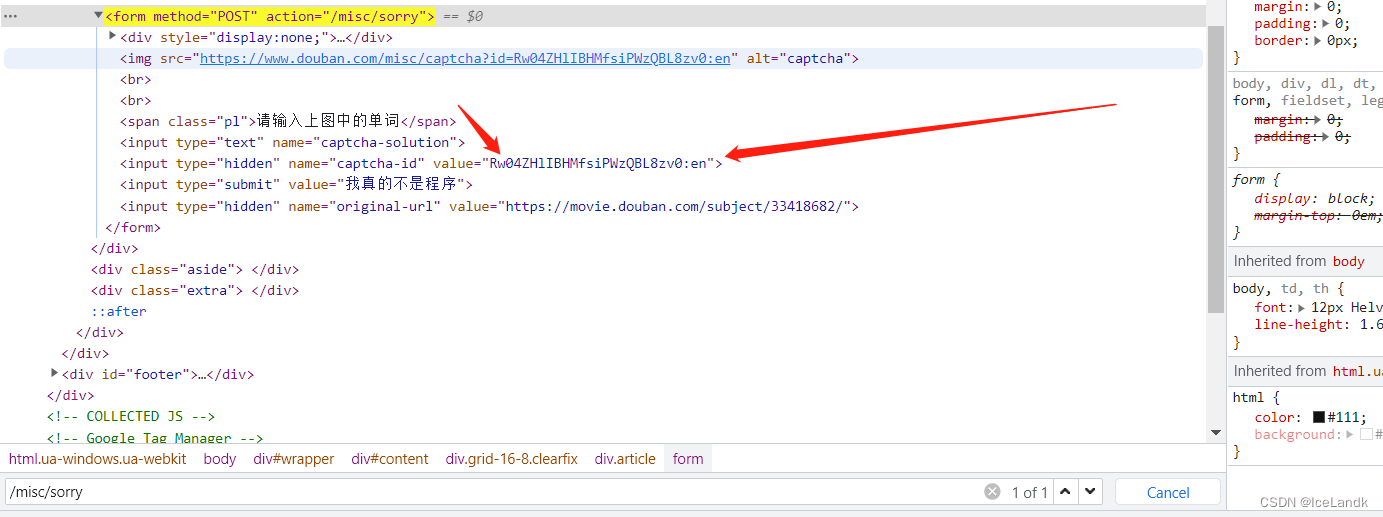
这是什么xdm ,直接能拿到数值,太爱豆瓣了

这和git的登入一模一样哇,相信弄过github的模拟登入都知道。直接把这个值用xpath扣下来,填到我们的表单当中,发送请求!!!
这下直接跳出验证码的页面了,给我返回了个登入页面的信息。我们去网站手动刷新看看是否已经跳出人机验证的页面了。
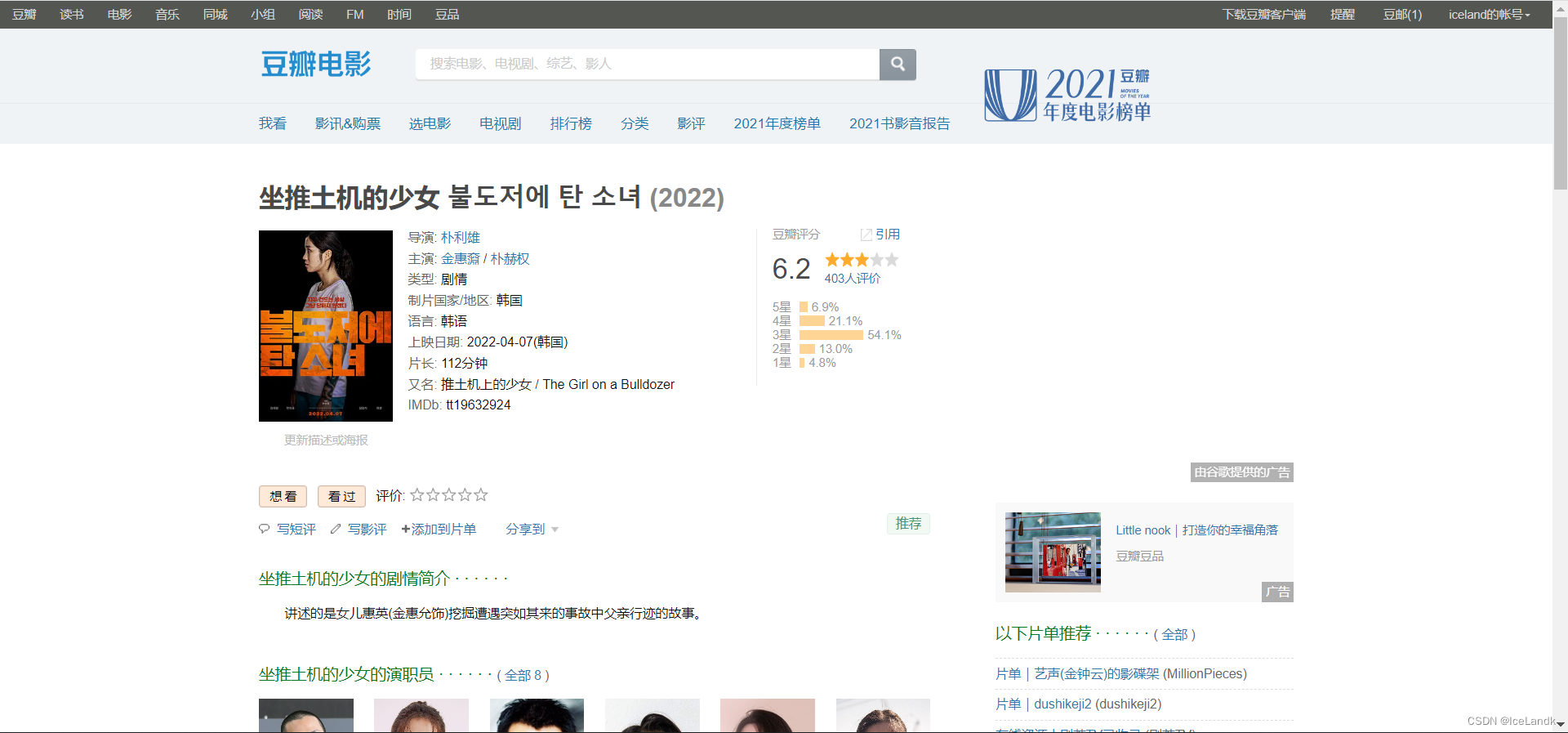
没有任何问题,那我们在运行之前的代码呢?
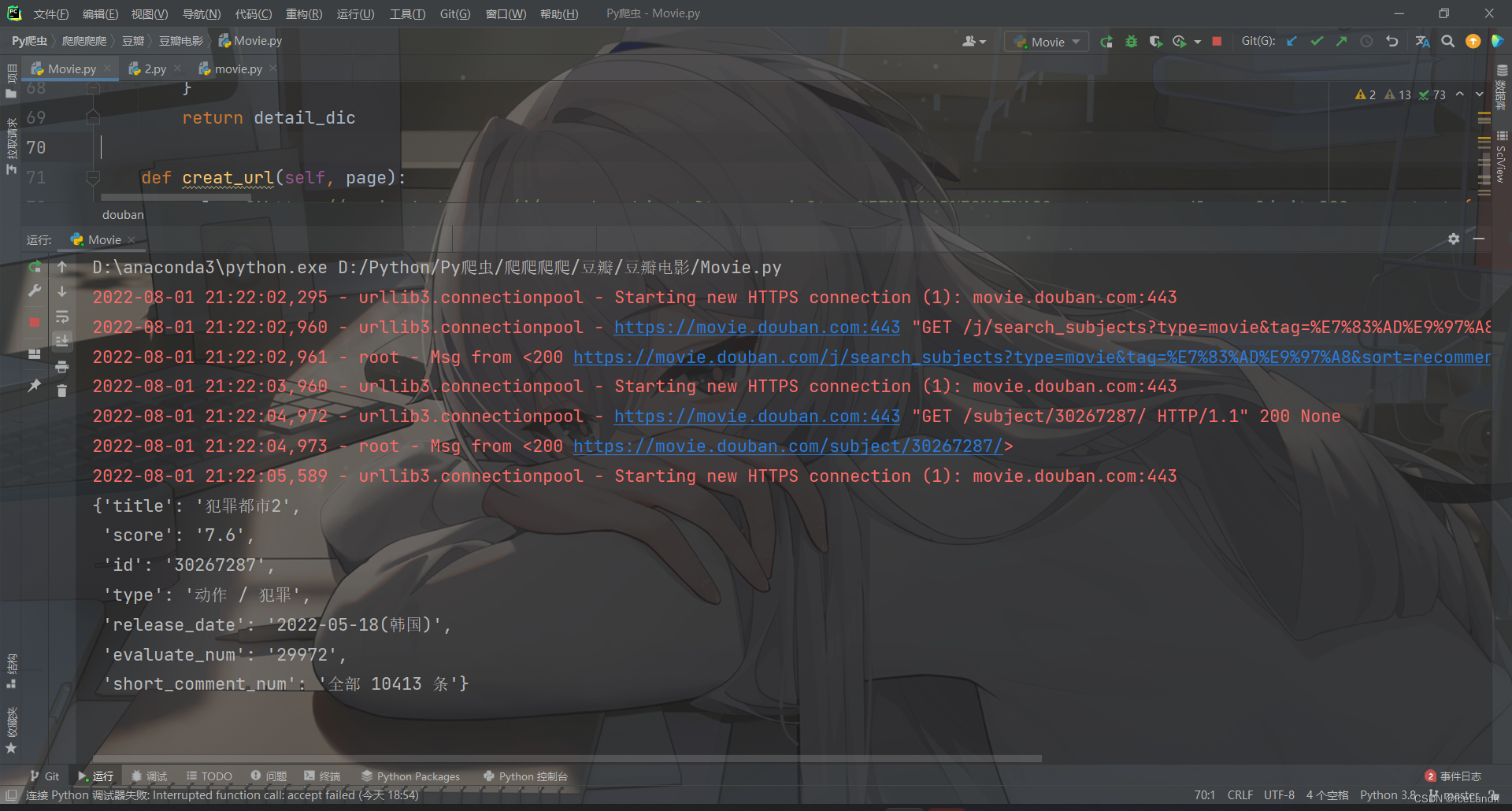 也是没有任何问题的!现在我们基本的思路已经了解了,但是我们刚刚是手动模拟的获取验证码发包请求,接下来我们将配合ddddocr识别图片中的验证码然后填入表单当中 。
也是没有任何问题的!现在我们基本的思路已经了解了,但是我们刚刚是手动模拟的获取验证码发包请求,接下来我们将配合ddddocr识别图片中的验证码然后填入表单当中 。
2. 保存验证码图片配合ocr识别出图中的验证码
pip install ddddocr
老方法,先下载ddddocr,我们先需要了解这个ddddocr该如何使用,这里先从豆瓣那下载一张验证码至本地,我们去试试识别的精度如何。
import ddddocr
ocr = ddddocr.DdddOcr()
with open('captcha.jpg', 'rb') as f:
img_bytes = f.read()
code = ocr.classification(img_bytes)
print(code)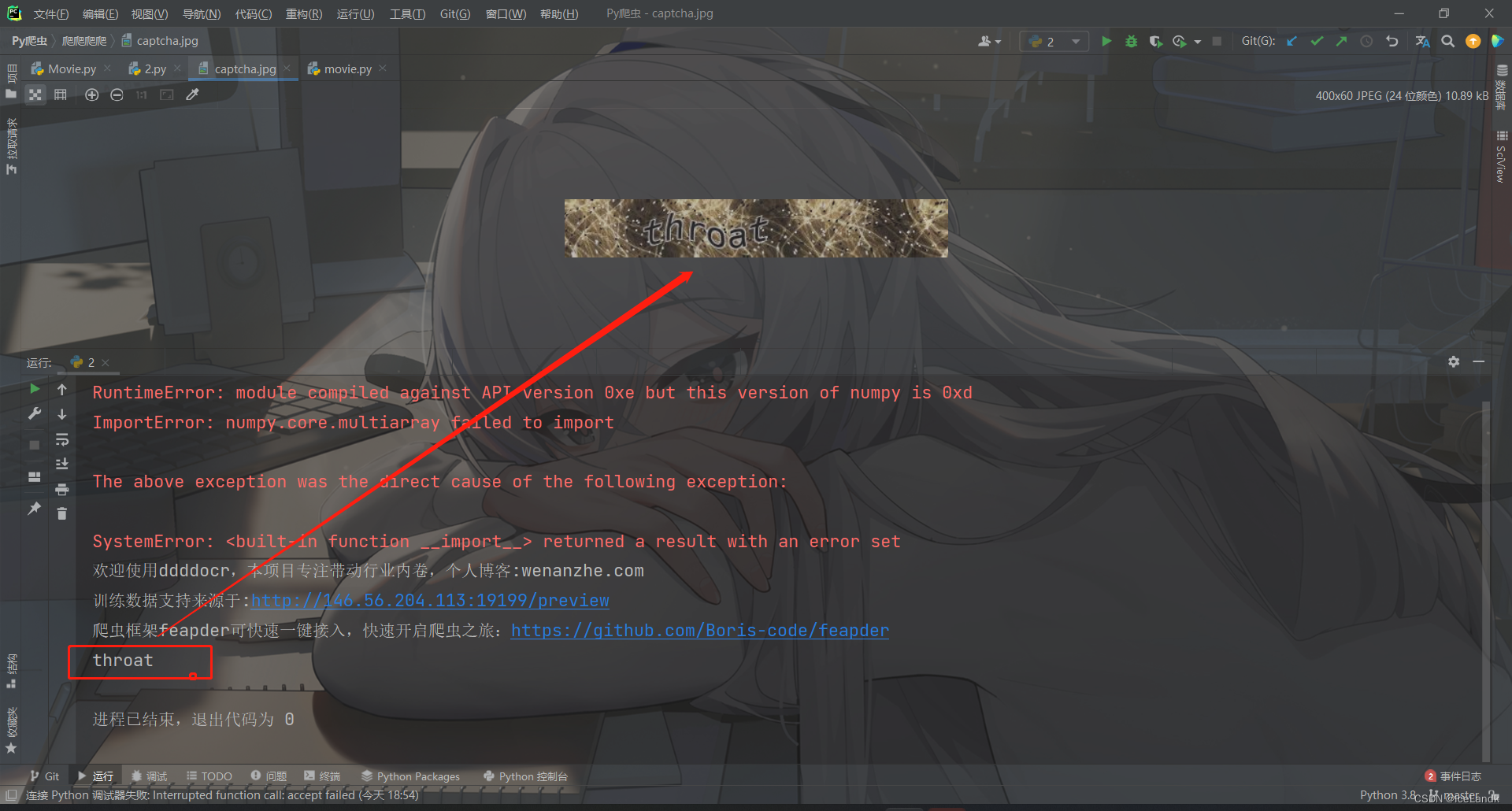
还是非常的牛,识别的精度非常高,我们套入我们的程序当中试试。
# -*- coding: utf-8 -*-
import parsel
import requests
import time
import json
import jsonpath
import pprint
import random
from fake_useragent import UserAgent
import logging
import ddddocr
class douban:
def get_response(self, url):
headers = {
'Referer': 'https://movie.douban.com/',
'Cookie': 'bid=c3hhB5BZTeE; ll="118311"; __utmc=30149280; __utmc=223695111; Hm_lvt_eaa57ca47dacb4ad4f5a257001a3457c=1659264694; push_noty_num=0; push_doumail_num=0; _vwo_uuid_v2=D3E63167E67E933D563C28FE20D40D966|e5620e84ad8118c0437e96a4f2d8e662; __utmv=30149280.25709; ct=y; dbcl2="257094860:4ts0vmOwNK8"; ck=48vN; __gads=ID=944a8ab8e3222a77-22c156a667d500ed:T=1659339507:RT=1659339507:S=ALNI_MbLs_abyRgTlqyBhLduonUlCgbiNw; __gpi=UID=00000825b9ac2801:T=1659339507:RT=1659339507:S=ALNI_MbJSf4zVEN8KzWJexZpvYLYydg73A; __utma=30149280.1742231113.1659264694.1659339501.1659339785.11; __utmz=30149280.1659339785.11.11.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1659350491%2C%22https%3A%2F%2Fwww.douban.com%2Fmisc%2Fsorry%3Foriginal-url%3Dhttps%253A%252F%252Fmovie.douban.com%252F%22%5D; _pk_ses.100001.4cf6=*; __utma=223695111.524410821.1659264694.1659339785.1659350491.12; __utmb=223695111.0.10.1659350491; __utmz=223695111.1659350491.12.12.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/misc/sorry; __utmb=30149280.36.10.1659339785; _pk_id.100001.4cf6=0d61f344e82c2272.1659264694.9.1659351438.1659347955.; Hm_lpvt_eaa57ca47dacb4ad4f5a257001a3457c=1659351438',
'user-agent': UserAgent().random
}
try:
response = requests.get(url=url, headers=headers)
if response.status_code in [403, 404]:
logging.debug('Request Error {} {}'.format(response.status_code, url))
logging.info('try to get verification code...')
douban().get_code()
if response.status_code == 200:
logging.info('Msg from <{} {}>'.format(response.status_code, url))
time.sleep(random.uniform(0.5, 1))
if response:
return response.text
else:
pass
except Exception as e:
logging.debug(e)
def get_data(self, page):
try:
response = douban().creat_url(page)
json_data = json.loads(response)
title = jsonpath.jsonpath(json_data, '$..title')
score = jsonpath.jsonpath(json_data, '$..rate')
id = jsonpath.jsonpath(json_data, '$..id')
for i in range(len(title)):
dic = {
'title': title[i],
'score': score[i],
'id': id[i]
}
detail_dic = douban().get_detail_data(id[i])
dic.update(detail_dic)
print(str(dic).replace(',', ',\n'))
except Exception as e:
logging.debug(e)
def get_detail_data(self, id):
url = f'https://movie.douban.com/subject/{id}/'
detail_response = douban().get_response(url)
selector = parsel.Selector(detail_response)
type = selector.xpath('//*[@property="v:genre"]/text()').getall()
release_date = selector.xpath('//*[@property="v:initialReleaseDate"]/text()').get()
evaluate_num = selector.xpath('//*[@class="rating_people"]/span/text()').get()
short_comment_num = selector.xpath('//*[@class="mod-hd"]/h2/span/a/text()').get()
detail_dic = {
'type': ' / '.join(type),
'release_date': release_date,
'evaluate_num': evaluate_num,
'short_comment_num': short_comment_num
}
return detail_dic
def creat_url(self, page):
url = f'https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start={page}'
return douban().get_response(url)
def get_code(self):
code_url = 'https://www.douban.com/misc/sorry?original-url=https%3A%2F%2Fmovie.douban.com%2F'
headers = {
'Cookie': 'bid=c3hhB5BZTeE; ll="118311"; __utmc=30149280; __utmc=223695111; Hm_lvt_eaa57ca47dacb4ad4f5a257001a3457c=1659264694; push_noty_num=0; push_doumail_num=0; _vwo_uuid_v2=D3E63167E67E933D563C28FE20D40D966|e5620e84ad8118c0437e96a4f2d8e662; __utmv=30149280.25709; ct=y; dbcl2="257094860:4ts0vmOwNK8"; ck=48vN; __gads=ID=944a8ab8e3222a77-22c156a667d500ed:T=1659339507:RT=1659339507:S=ALNI_MbLs_abyRgTlqyBhLduonUlCgbiNw; __gpi=UID=00000825b9ac2801:T=1659339507:RT=1659339507:S=ALNI_MbJSf4zVEN8KzWJexZpvYLYydg73A; __utma=30149280.1742231113.1659264694.1659339501.1659339785.11; __utmz=30149280.1659339785.11.11.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1659350491%2C%22https%3A%2F%2Fwww.douban.com%2Fmisc%2Fsorry%3Foriginal-url%3Dhttps%253A%252F%252Fmovie.douban.com%252F%22%5D; _pk_ses.100001.4cf6=*; __utma=223695111.524410821.1659264694.1659339785.1659350491.12; __utmb=223695111.0.10.1659350491; __utmz=223695111.1659350491.12.12.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/misc/sorry; __utmb=30149280.36.10.1659339785; _pk_id.100001.4cf6=0d61f344e82c2272.1659264694.9.1659351438.1659347955.; Hm_lpvt_eaa57ca47dacb4ad4f5a257001a3457c=1659351438',
'User-Agent': UserAgent().random
}
code_res = requests.get(url=code_url, headers=headers).text
selector = parsel.Selector(code_res)
captcha_id = selector.xpath('//*[@name="captcha-id"]/@value').get()
code_pic = selector.xpath('//*[@action="/misc/sorry"]/img/@src').get()
logging.info(captcha_id)
img_data = requests.get(url=code_pic, headers=headers).content
with open('captcha\\captcha.jpg', mode='wb') as f:
f.write(img_data)
time.sleep(1)
logging.info('captcha dowmload success: %s', captcha_id)
f.close()
captcha_code = douban().get_captcha_code()
data = {
'ck': '48vN',
'captcha-solution': captcha_code,
'captcha-id': captcha_id,
'original-url': 'https://movie.douban.com/',
}
# try:
captcha_response = requests.post(url=code_url, headers=headers, data=data)
if captcha_response.status_code == 200:
logging.info('success pass human verification')
else:
logging.debug('validation error, will try again...')
# except Exception as e:
# logging.debug(e)
def get_captcha_code(self):
ocr = ddddocr.DdddOcr()
with open('captcha\\captcha.jpg', 'rb') as f:
img_bytes = f.read()
code = ocr.classification(img_bytes)
logging.info('captcha code is: %s', code)
time.sleep(1)
return code
def main(self):
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(name)s - %(message)s')
[douban().get_data(page) for page in range(0, 200 * 20, 20)]
if __name__ == '__main__':
douban().main()
识别的精度非常的高,测试了两三次人机都通过了,这下可以安安心心的采豆瓣了,不要因为有了验证码识别就疯狂采集不加延时,豆瓣对于请求过多次数的ip还是会封禁一段时间的,当然配合ip代理池使用会更香些。合理使用爬虫早已成为每个爬虫程序猿的基本守则,切忌使用爬虫进行非法交易。

不知道为啥加入ocr识别后爆人机的次数少了,在测试的过程当中好久都没看到403和404。
仍有代码不足之处,大佬们自行修改。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









