







一、感知机
感知机是一个二分类的单层网络模型。
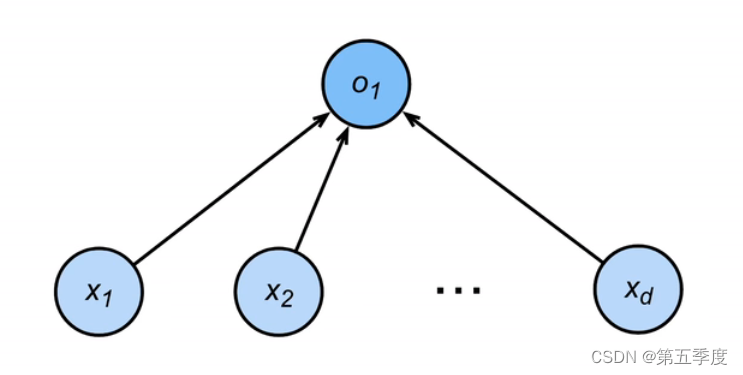
感知机模型的表达式为:
o
^
=
{
1
,
<
ω
⃗
,
x
⃗
>
+
b
>
0
0
,
<
ω
⃗
,
x
⃗
>
+
b
≤
0
\hat{o}=\begin{cases}1,<\vec{\omega},\vec{x}>+b>0\\0,<\vec{\omega},\vec{x}>+b\le 0\end{cases}
o^={1,<ω,x>+b>00,<ω,x>+b≤0可以看出,感知机的特点是输出只有0和1,输出的是离散值,感知机的损失函数为:
ι
(
ω
⃗
,
b
)
=
{
1
,
−
o
^
×
o
>
0
0
,
−
o
^
×
o
≤
0
\iota(\vec{\omega},b)=\begin{cases}1,-\hat{o}\times o>0\\0,-\hat{o}\times o\le 0\end{cases}
ι(ω,b)={1,−o^×o>00,−o^×o≤0其中,
o
⃗
\vec{o}
o 是真实标签。损失函数相当于拿计算的结果与真实的标签作比较,发现符号相反就输出1(分类失败),发现符号相同就输出0(分类成功)。之后,对损失函数求偏导进行梯度下降更新权重和偏差,损失函数就会一直往0去下降,从而令判断越来越准确。
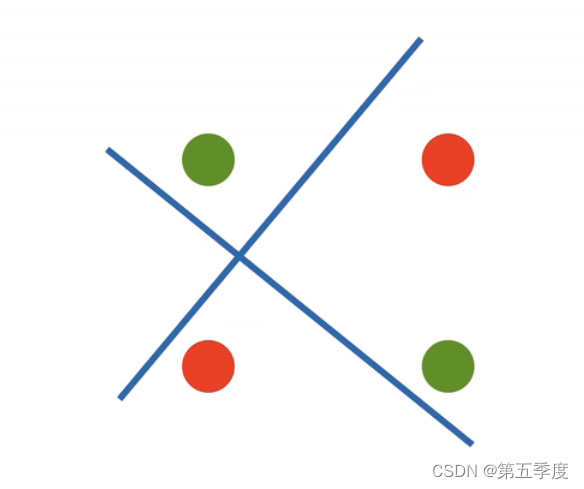
但是,这种单层的感知机有一个致命的问题,它只能分割线性空间(从表达式中也可以看出来),如果样本按照XOR(异或)函数的样子进行分布,是无法分割开来的。(假设样本有二维的特征,那么下图中的样本分布,感知机是无法分割的。无论怎么分割都无法用一条线将红色和绿色分开)。 这种缺陷使得1969年感知机被提出之后一直不被重视。
二、多层感知机
十多年之后,多层感知机被提出,才解决了单层感知机不能拟合XOR函数的问题。
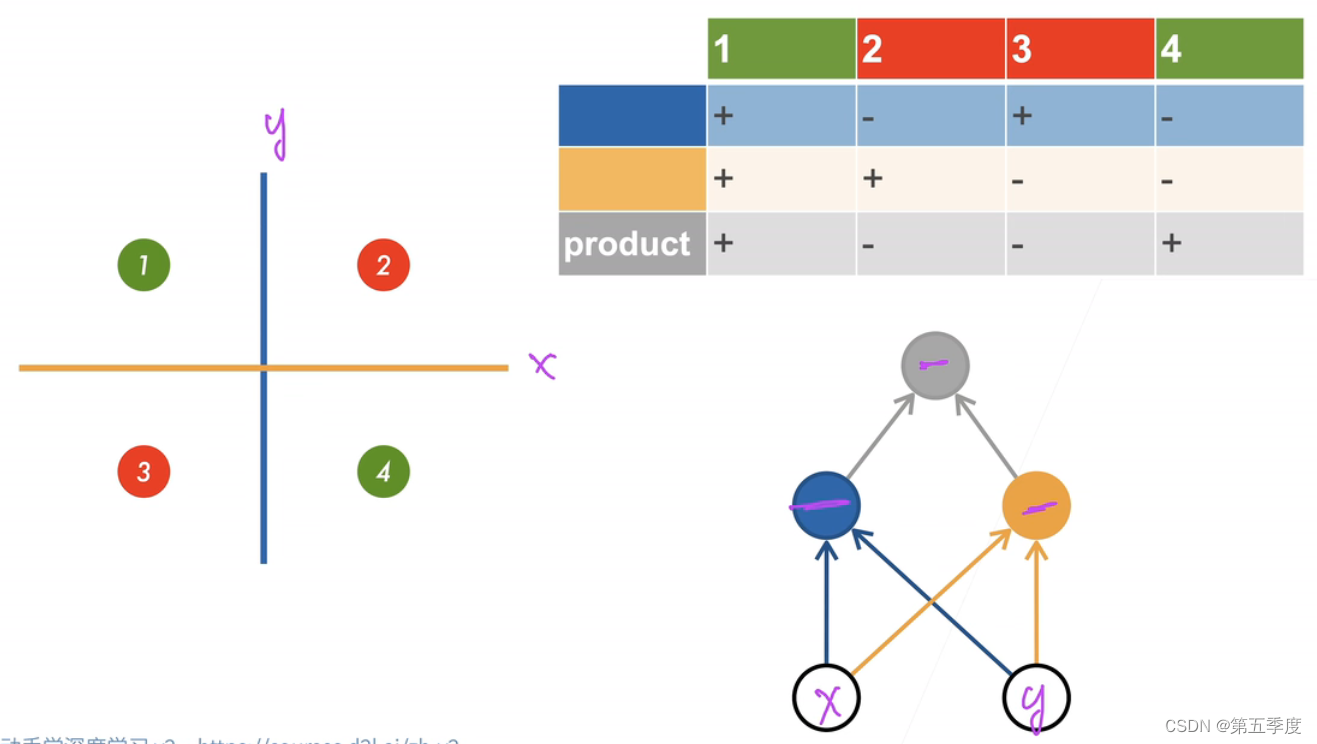
还是假设样本有两个特征。既然单层感知机只能分割出一个平面,那就构造两个单层感知机,这样就能分割出两个平面,这两个平面共同作用(这种作用不能是线性组合,而是另外的非线性作用)得到一个最终的结果,这个结果就可以表示XOR。如图所示。可以看到,网络的第一层分别是两个单层感知机。第二层将两个单层感知机的结果进行了组合。将第一层称为隐藏层。每个隐藏层的大小是一个超参数,隐藏层的数量也是一个超参数。多层感知机经过感知机的叠加,能够划分出非线性空间。但是这种叠加不是普通的线性叠加。下面来解释激活函数就能够明白。
2.1、激活函数
所谓激活,就是将输入隐藏层的线性组合的结果利用非线性函数转化一下再进行输出,非线性函数就被称为激活函数。为什么隐藏层中要使用激活函数进行激活呢?因为如果不激活,隐藏层输出的将会是一个线性组合,整个网络拟合出的函数还是一个线性空间。试想一个网络,添加了很多个隐藏层,但是都没有激活,最终的输出结果还是一个线性组合!那么隐藏层相当于没加(这种现象叫做层数坍塌)。这个网络还是最简单的线性分割,是无法划分非线性空间的。
上边的多层感知机,隐藏层输出之前,会经过激活函数(阶跃函数)的变换,这样隐藏层神经单元输出的值再次进行线性组合即可拟合出XOR函数。
详解:异或运算的运算规则完全可以由与运算和或运算代替:
x ⊕ y = x × y ‾ + x ‾ × y x\oplus y=x\times \overline{y}+\overline{x}\times y x⊕y=x×y+x×y加号代表或运算,乘号代表与运算。单层感知机的结果经过阶跃函数的激活是可以拟合出与运算的,而两个与运算进行线性组合又可以表示或运算。 多层感知机经过反复输出预测值、计算损失、梯度下降之后,第一层的两个单层感知机就会逐渐变成与运算,而第二层会逐渐变成或运算。这就是多层感知机能够拟合出XOR函数的本质。
除了阶跃函数之外,还有以下函数是非常常见的激活函数:
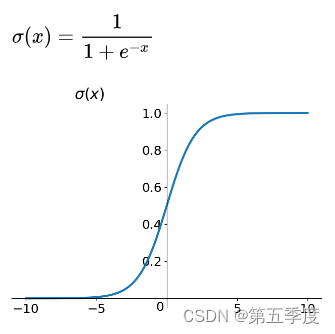
sigmoid函数
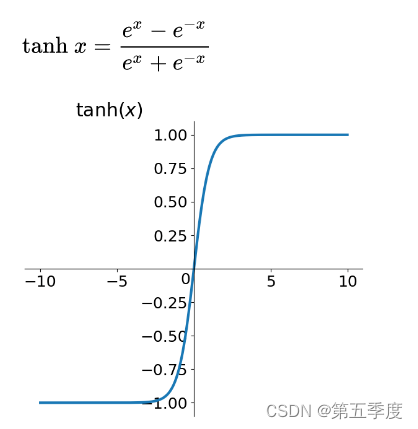
tanh函数
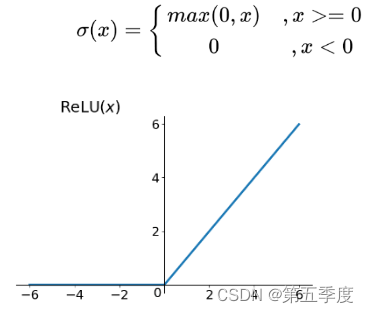
ReLU函数
softmax函数
softmax函数在我写的上一篇文章中有详细介绍。
三、实战——pytorch实现多层感知机解决多分类问题
接下来,我们使用构建拥有一层隐藏层的多层感知机,并使用ReLU作为激活函数,训练一个多层感知机模型来解决多分类问题。
import torch
import matplotlib.pyplot as plt
import numpy as np
from torch.utils import data
from torchvision import datasets
from torchvision import transforms
from torch import nn
def get_train_test_loader(image_size=28, train_batch_size=10, test_batch_size=10, num_workers=0, is_download=True):
"""
获得训练数据生成器和验证数据生成器,这个数据集总共有10个类别(即10个标签)
:param image_size: 图片的大小,取28
:param train_batch_size: 数据生成器的批量大小
:param num_workers: 数据生成器每次读取时调用的线程数量
:param is_download: 是否要下载数据集(如果还未下载设置为True)
:return: 训练数据生成器和验证数据生成器
"""
data_transform = transforms.Compose([
# 设置图片大小
transforms.Resize(image_size),
# 转化为tensor张量
transforms.ToTensor()
])
train_data = datasets.FashionMNIST(root='../data', train=True, download=is_download, transform=data_transform)
test_data = datasets.FashionMNIST(root='../data', train=False, download=is_download, transform=data_transform)
train_loader = data.DataLoader(train_data, batch_size=train_batch_size, shuffle=True, num_workers=num_workers,
drop_last=True)
test_loader = data.DataLoader(test_data, batch_size=test_batch_size, shuffle=False, num_workers=num_workers,
drop_last=True)
return train_loader, test_loader
def accuracy(y_hat, y):
"""模型训练完成后,判断预测结果的准确率"""
if y_hat.shape[0] < 2 and y_hat.shape[1] < 2:
raise ValueError("dimesion error")
# 得到预测的y_hat每一行中最大概率所在的索引(索引即类别)
y_hat = y_hat.argmax(axis=1)
# 判断预测类别是否与实际类别相等
judge = y_hat.type(y.dtype) == y
# 现在cmp是一个bool类型的向量,转成0和1,统计1的数量
return float(judge.type(y.dtype).sum()) / len(y)
def init_weights(m):
"""将网络中每一个线性层的所有权重都利用标准差为0.01的正态分布进行初始化,b没有初始化,所以初始为0"""
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
# 学习率
lr = 0.03
# 批量大小
batch_size = 100
test_batch_size = 10000
# 最开始一个展平层用来给输入的x整形,接下来第一层是线性层,结果经过RuLU激活之后,进入下一个线性层,之后结果进行输出。隐藏层共有392个神经元
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 392), nn.ReLU(), nn.Linear(392, 10))
# apply会将net中的每一层都作为参数进入init_weights,当发现是线性层,会对线性层的w自动初始化
net.apply(init_weights)
# 损失函数是交叉熵函数,参数是y_hat和y,注意,会对传入的y_hat先进行一次softmax处理
loss = nn.CrossEntropyLoss()
# 梯度下降
trainer = torch.optim.SGD(net.parameters(), lr=lr)
# 获取数据生成器以及数据
train_loader, test_loader = get_train_test_loader(train_batch_size=batch_size, test_batch_size=test_batch_size,
is_download=False)
train_loader_test, _ = get_train_test_loader(train_batch_size=60000, is_download=False)
# 学习代数
num_epoch = 10
# 用来正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False
# 交互模式
plt.ion()
fig = plt.figure()
ax = fig.add_subplot()
ax.grid(True, axis="y")
epoch_x, validate_accuracy_y, test_accuracy_y, loss_y = [], [], [], []
line_validate, = ax.plot(epoch_x,validate_accuracy_y,color='black',linestyle="--",label="训练集准确率")
line_test, = ax.plot(epoch_x,test_accuracy_y,color='blue',label="测试集准确率")
line_loss, = ax.plot(epoch_x,loss_y,color='red',label="损失函数")
ax.set(xticks=np.arange(0,12,1),xlim=(0,11),yticks=np.arange(0,1.1,0.1),ylim=(0,1))
ax.legend()
for i in range(num_epoch):
epoch_x.append(i + 1)
for x, y in train_loader:
# 模型得到预测值
y_hat = net(x)
# 损失函数
l = loss(y_hat, y)
print(f"\r{batch_size}个批量样本损失为{l}", end="", flush=True)
trainer.zero_grad()
# 求偏导
l.backward()
# 梯度下降
trainer.step()
with torch.no_grad():
for x, y in train_loader_test:
y_hat = net(x)
l = loss(y_hat, y)
loss_y.append(l)
print(f"\n第{i}代,所有训练样本损失为{l}")
validate_accuracy = accuracy(y_hat, y)
print(f"验证集预测正确率:{validate_accuracy}")
validate_accuracy_y.append(validate_accuracy)
for x, y in test_loader:
test_accuracy = accuracy(net(x), y)
print(f"测试集预测正确率:{test_accuracy}")
test_accuracy_y.append(test_accuracy)
print("=" * 25)
line_validate.set_data(epoch_x,validate_accuracy_y)
line_test.set_data(epoch_x,test_accuracy_y)
line_loss.set_data(epoch_x,loss_y)
plt.draw()
plt.pause(0.1)
plt.ioff()
plt.show()
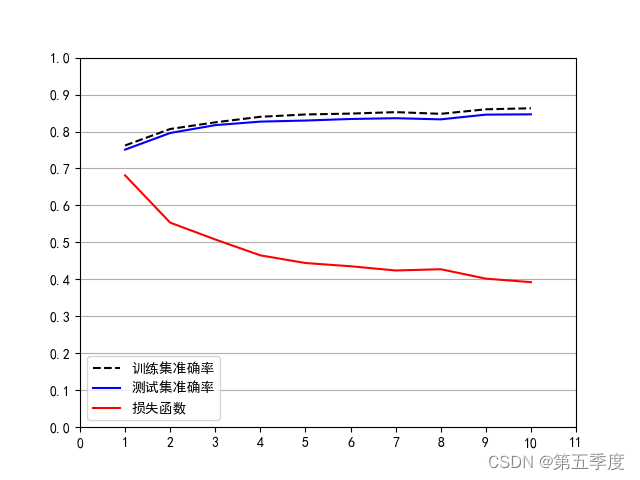
效果如图所示:














 1072
1072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









