






在很多领域都用到了多模态推荐,但是很多时候构建多模态模型所需要的数据量是非常大的,所以在实现多模态推荐前,我们可以使用相似推荐来过渡。
多模态是包括文本,音频,图片,视频等模态的。
这里我做的是将文本和图片模态做一个简单融合。
根据难度,从相似推荐开始,再到多模态推荐。
以下是大致的流程:
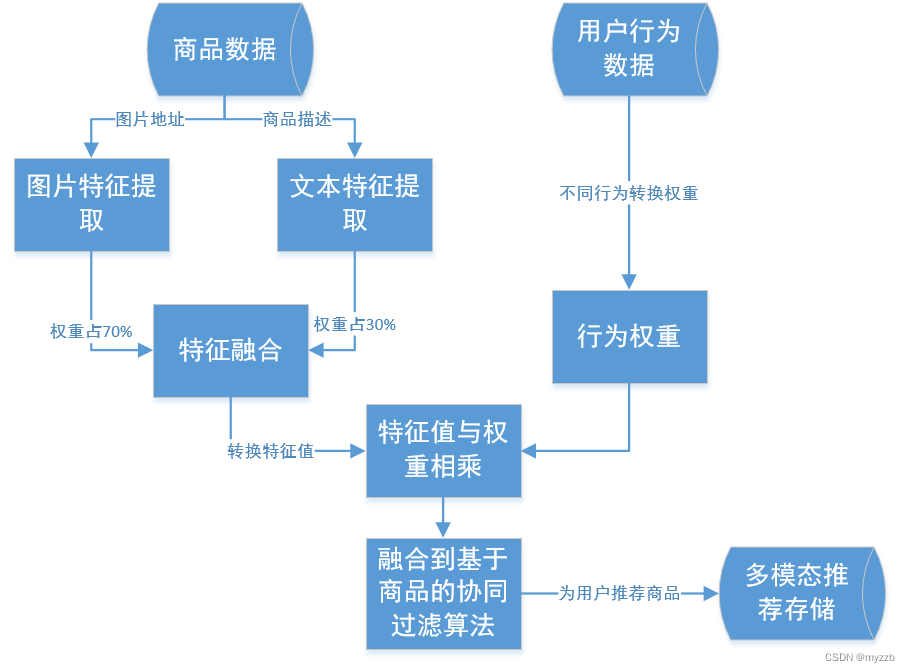
在这里是我自己制作的电商数据,包括物品的文本描述,与物品的图片,还有推荐算法的基本要素,即用户对物品的交互,其中包括购买,加入购物车,还有收藏,喜欢。
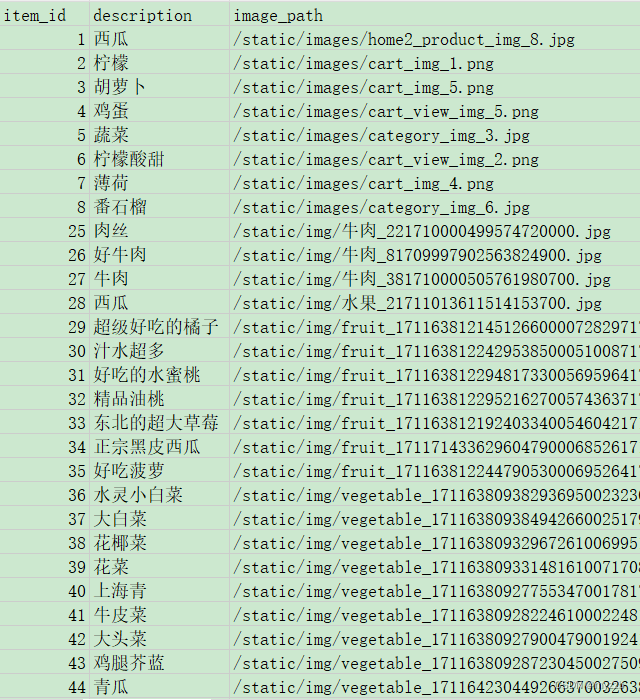
以下是物品数据:
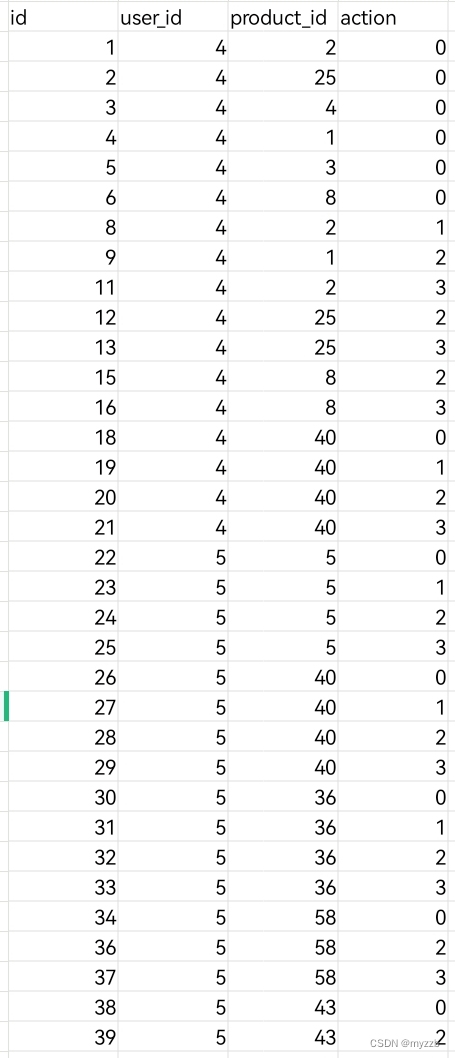
以下是用户交互数据:
其中ACTION = ( (0, '点击'), (1, '收藏'), (2, '加入购物车'), (3, '购买'), )
相似推荐,考虑的是物品与物品之间的相似,所以要对物品文本描述和物品图片做相似度处理。
每一个单独的物品,都有文本描述和物品图片。
图片通过自己训练的神经网络模型,去除最后一层,即得到提取的特征值数据。
文本描述同理,但是这里采用的是借用别人的。
融合之后,我们通过对每一个物品做相似度处理,则得到一个相似度的值,通过相似度值作为评分,来作为物品对物品推荐。
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import load_model
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Flatten
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.metrics.pairwise import cosine_similarity
import pandas as pd
import os
import random
cnn = load_model("K:/photo/cnn_model.h5")
# CSV文件列:'item_id', 'description', 'image_path','tag'
data = pd.read_csv('K:/下载/product_data.csv', encoding='utf-8', sep=',')
input_layer = cnn.input
# 获取最后一个全连接层之前的层,作为特征层
# 最后一个全连接层之前有一个Flatten层
# 找到正确的特征层
for layer in cnn.layers:
if isinstance(layer, Flatten):
feature_layer = layer.output
break
# 构建特征提取器模型
cnn = Model(input_layer, feature_layer)
# 文本特征提取
tfidf_vectorizer = TfidfVectorizer()
text_features = tfidf_vectorizer.fit_transform(data['description'])
address = r'K:/django/Item/app01'
# 图像特征提取
image_features = []
#图片提取特征值
for image_path in data['image_path']:
img = image.load_img(address+image_path, target_size=(50, 50))
img_data = image.img_to_array(img)
img_data = np.expand_dims(img_data, axis=0)
features = cnn.predict(img_data)
image_features.append(features.flatten())
#转换
image_features = np.array(image_features)
#标准化
scaler_text = StandardScaler()#标准差标准化
# scaler_text = MinMaxScaler()#最大最小标准化
text_features_scaled = scaler_text.fit_transform(text_features.toarray())
# text_features_scaled = text_features.toarray()#没有标准化
scaler_image = StandardScaler()#标准差标准化
# scaler_image = MinMaxScaler()#最大最小标准化
image_features_scaled = scaler_image.fit_transform(image_features)
# print(text_features)
# print(image_features)
# text_features_scaled = image_features#没有标准化
# 分配权重,因为两者权重问题,所以在处理时候不应该标准差标准化,应该最大最小标准化
text_weight = 0.3
image_weight = 0.7
random.seed()
# 加权特征融合
weighted_text_features = text_features_scaled * text_weight
weighted_image_features = image_features_scaled * image_weight
# 合并加权后的特征
combined_features_weighted = np.hstack((weighted_text_features, weighted_image_features))
# 计算余弦相似度
similarity_matrix = cosine_similarity(combined_features_weighted)
# print(similarity_matrix)
# 用户的历史交互列表用户喜欢的商品ID
# 推荐函数
def recommend_items(user_history, similarity_matrix, item_ids):
# 确保 user_history 中的项目都在 item_ids 中
user_history = [item for item in user_history if item in item_ids]
# print(user_history)
# 获取用户历史项目的索引
user_item_indices = [item_ids.index(item) for item in user_history]
# 确保我们找到了所有用户历史项目的索引
if len(user_item_indices) != len(user_history):
raise ValueError("Some items in user history are not in the item_ids list.")
# 获取用户历史项目的相似度行
user_similarities = similarity_matrix[user_item_indices, :]
# 初始化推荐项目得分字典
item_scores = {item_id: 0 for item_id in item_ids}
# 累加用户历史项目与其他项目的相似度
for idx, sim_row in zip(user_item_indices, user_similarities):
# 累加除了用户已经交互过的项目之外的相似度
for jdx, score in enumerate(sim_row):
item_id = item_ids[jdx]
item_scores[item_id] += score
# 根据得分推荐项目
sorted_scores = sorted(item_scores.items(), key=lambda x: x[1], reverse=True)
# 指定数量的推荐
return sorted_scores
df = pd.DataFrame(columns=['product_mian', 'product_id', 'score'])
for i in list(data["item_id"]):
product = []
product.append(i)
# 用商品来推荐商品
# 输出推荐结果
recommendations = recommend_items(product, similarity_matrix, data["item_id"].tolist())
for item_id, score in recommendations:
df = df.append(
{'product_main': i, 'product_id': str(item_id), 'score': score}, ignore_index=True)
# 将新的DataFrame保存到CSV文件
df.to_csv('product_recommendations.csv', index=False, encoding='utf-8', sep=',')
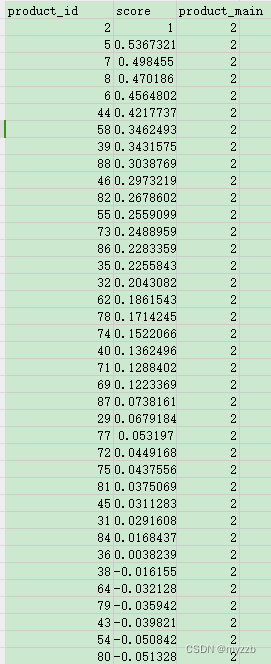
其实可以发现物品之间相似度是有负数的,这就说明物品与物品之间存在负相关。
通过这两个模态融合做一个模型,就得到了相似推荐。
这种推荐模式,是基于物品图片和物品文本来推荐的,与用户交互无关,但后面我们会加入进去融合起来。
———————————————————————————————————————————
相似推荐之后就是融合行为进去,做成多模态推荐算法。
处理用户行为权重
ACTION = (
(0, '点击'),
(1, '收藏'),
(2, '加入购物车'),
(3, '购买'),
)
分别给不同行为不同的权重。
import pandas as pd
# 读取数据
df = pd.read_csv('K:/下载/user_actions.csv')
# 定义行为权重
action_weights = {0: 1, 1: 2, 2: 3, 3: 5}
# 转换action字段为权重
df['weight'] = df['action'].map(action_weights)
# 按照用户ID和商品ID对数据进行分组,并计算每个组的权重总和
grouped = df.groupby(['user_id', 'product_id'])['weight'].sum().reset_index()
# 将结果重命名为更有意义的列名
grouped = grouped.rename(columns={'weight': 'total_weight'})
# 写入CSV文件
grouped.to_csv('user_product_weights.csv', index=False)
print(grouped)
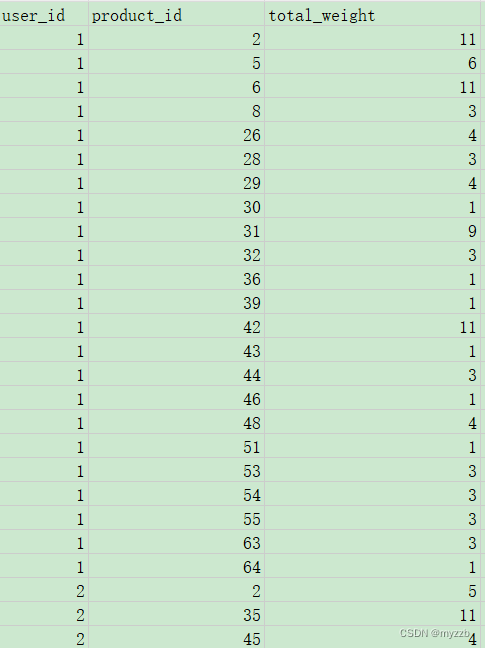
我们从用户喜欢的物品之中,计算所有之外的物品的相似度,然后实现对用户所有的交互的物品对未知的物品的可能好感,这里是不包含用户行为的。
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import load_model
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Flatten
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.metrics.pairwise import cosine_similarity
import pandas as pd
import os
import random
cnn = load_model("K:/photo/cnn_model.h5")
# CSV文件列:'item_id', 'description', 'image_path','tag'
data = pd.read_csv('K:/下载/product_data.csv', encoding='utf-8', sep=',')
input_layer = cnn.input
# 获取最后一个全连接层之前的层,作为特征层
# 最后一个全连接层之前有一个Flatten层
# 找到正确的特征层
for layer in cnn.layers:
if isinstance(layer, Flatten):
feature_layer = layer.output
break
# 构建特征提取器模型
cnn = Model(input_layer, feature_layer)
# 文本特征提取
tfidf_vectorizer = TfidfVectorizer()
text_features = tfidf_vectorizer.fit_transform(data['description'])
address = r'K:/django/Item/app01'
# 图像特征提取
image_features = []
#图片提取特征值
for image_path in data['image_path']:
img = image.load_img(address+image_path, target_size=(50, 50))
img_data = image.img_to_array(img)
img_data = np.expand_dims(img_data, axis=0)
features = cnn.predict(img_data)
image_features.append(features.flatten())
#转换
image_features = np.array(image_features)
#标准化
scaler_text = StandardScaler()#标准差标准化
# scaler_text = MinMaxScaler()#最大最小标准化
text_features_scaled = scaler_text.fit_transform(text_features.toarray())
# text_features_scaled = text_features.toarray()#没有标准化
scaler_image = StandardScaler()#标准差标准化
# scaler_image = MinMaxScaler()#最大最小标准化
image_features_scaled = scaler_image.fit_transform(image_features)
# print(text_features)
# print(image_features)
# text_features_scaled = image_features#没有标准化
# 分配权重,因为两者权重问题,所以在处理时候不应该标准差标准化,应该最大最小标准化
text_weight = 0.3
image_weight = 0.7
random.seed()
# 加权特征融合
weighted_text_features = text_features_scaled * text_weight
weighted_image_features = image_features_scaled * image_weight
# 合并加权后的特征
combined_features_weighted = np.hstack((weighted_text_features, weighted_image_features))
# 计算余弦相似度
similarity_matrix = cosine_similarity(combined_features_weighted)
# print(similarity_matrix)
# 用户的历史交互列表用户喜欢的商品ID
# 推荐函数
def recommend_items(user_history, similarity_matrix, item_ids):
# 确保 user_history 中的项目都在 item_ids 中
user_history = [item for item in user_history if item in item_ids]
# print(user_history)
# 获取用户历史项目的索引
user_item_indices = [item_ids.index(item) for item in user_history]
# print(user_item_indices)
# print(item_ids)
# 确保我们找到了所有用户历史项目的索引
if len(user_item_indices) != len(user_history):
raise ValueError("Some items in user history are not in the item_ids list.")
# 获取用户历史项目的相似度行
user_similarities = similarity_matrix[user_item_indices, :]
# 初始化推荐项目得分字典
item_scores = {item_id: 0 for item_id in item_ids}
# 累加用户历史项目与其他项目的相似度
for idx, sim_row in zip(user_item_indices, user_similarities):
# 累加除了用户已经交互过的项目之外的相似度
for jdx, score in enumerate(sim_row):
item_id = item_ids[jdx]
item_scores[item_id] += score
# 根据得分推荐项目
sorted_scores = sorted(item_scores.items(), key=lambda x: x[1], reverse=True)
# 指定数量的推荐
return sorted_scores
df = pd.read_csv('K:/下载/user_actions.csv', encoding='utf-8', sep=',')
user_product_mapping = df.groupby('user_id')['product_id'].apply(lambda x: list(set(x))).reset_index(name='product_id')
df = pd.DataFrame(columns=['user_id', 'product_id', 'score'])
for i in range(len(user_product_mapping)):
# print(user_product_mapping.iloc[i])
# print(user_product_mapping.iloc[i]['product_id'])
# 打乱列表顺序,确保随机性
list_items = user_product_mapping.iloc[i]['product_id']
user_history = user_product_mapping.iloc[i]['product_id']
user_recommendations = recommend_items(user_history, similarity_matrix, data["item_id"].tolist())
# 将推荐的项目ID和得分分离
user_id = user_product_mapping.iloc[i]["user_id"]
recommended_items = [item_id for item_id, score in user_recommendations]
for item_id, score in user_recommendations:
df = df.append(
{'user_id': user_id, 'product_id': str(item_id), 'score': score}, ignore_index=True)
# 将新的DataFrame保存到CSV文件
df.to_csv('user_recommendations.csv', index=False, encoding='utf-8', sep=',')
如图所示:
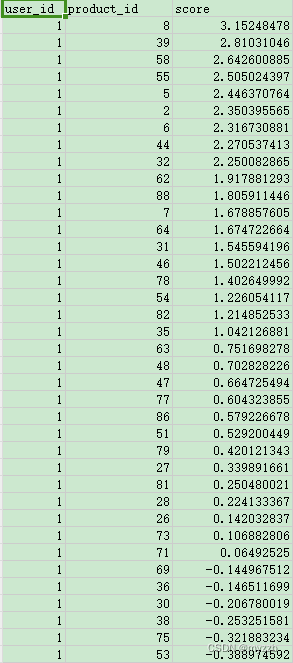
我们要将用户行为加入进去,简单的融合方法就是得出的数值相乘:
import pandas as pd
# 第一个CSV文件
df1 = pd.read_csv('user_product_weights.csv')
# 第二个CSV文件
df2 = pd.read_csv('user_recommendations.csv')
# 基于user_id和product_id合并两个DataFrame
merged_df = pd.merge( df1,df2,on=['user_id', 'product_id'], how='outer')
# 填充缺失值,例如用0替换NaN
merged_df.fillna(0, inplace=True)
merged_df['weighted_score'] = merged_df['score'] * merged_df['total_weight']
# 将结果保存到新的CSV文件
merged_df.to_csv('merged.csv', index=False)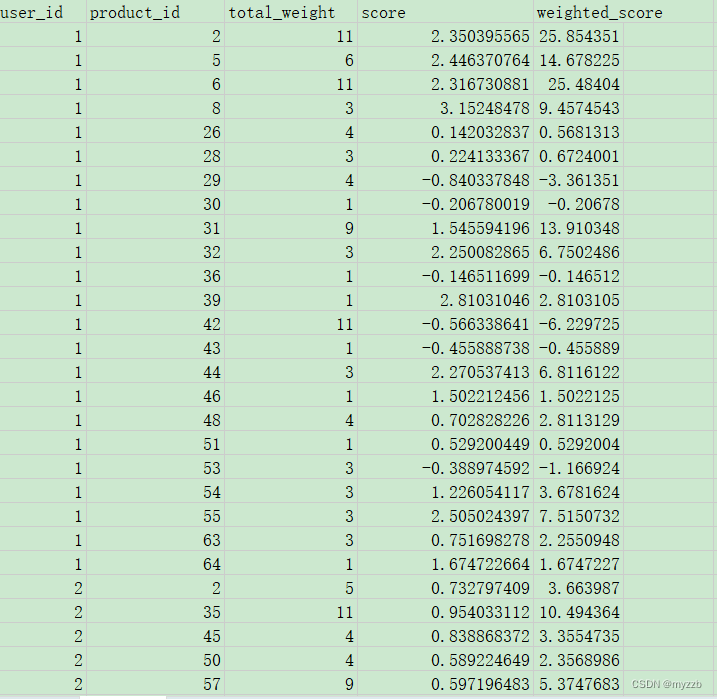
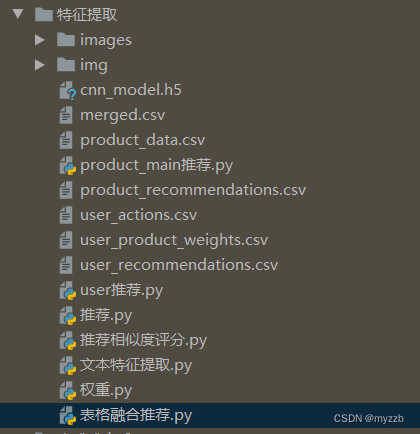
我将全部的一些代码和训练模型打包,放到同站免费下载。
但是要对地址做一些处理。
文件参考如下:
资源:https://download.csdn.net/download/weixin_52810349/89511066















 233
233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









