






 本文详细介绍了数据清洗的过程,包括观察和处理数据缺失、异常值、冗余以及格式不一致的问题。在化学信息学和QSAR建模研究中,数据清洗尤为重要,涉及无机物和混合物的筛选、带电荷分子和盐类的处理、化学结构规范化以及重复化合物的删除。文章还强调了人工检查在确保数据质量中的关键作用。
本文详细介绍了数据清洗的过程,包括观察和处理数据缺失、异常值、冗余以及格式不一致的问题。在化学信息学和QSAR建模研究中,数据清洗尤为重要,涉及无机物和混合物的筛选、带电荷分子和盐类的处理、化学结构规范化以及重复化合物的删除。文章还强调了人工检查在确保数据质量中的关键作用。
主要参考 数据缺失、混乱、重复怎么办?最全数据清洗指南 和 论化学结构整理在化学信息学和QSAR建模研究中的重要性 及一些实践
文章目录
1.一般数据处理
1.1.观察数据
- 查看数据集大小,数据类型等
# read the data
df = pd.read_csv('sberbank.csv')
# shape and data types of the data
print(df.shape)
print(df.dtypes)
# select numeric columns
df_numeric = df.select_dtypes(include=[np.number])
numeric_cols = df_numeric.columns.values
print(numeric_cols)
# select non numeric columns
df_non_numeric = df.select_dtypes(exclude=[np.number])
non_numeric_cols = df_non_numeric.columns.values
print(non_numeric_cols)
1.2.数据缺失
- 可以用数据热图,缺失数据百分比,缺失数据直方图等观察
cols = df.columns[:30] # first 30 columns
colours = ['#000099', '#ffff00'] # specify the colours - yellow is missing. blue is not missing.
sns.heatmap(df[cols].isnull(), cmap=sns.color_palette(colours))
# if it's a larger dataset and the visualization takes too long can do this.
# % of missing.
for col in df.columns:
pct_missing = np.mean(df[col].isnull())
print('{} - {}%'.format(col, round(pct_missing*100)))
# first create missing indicator for features with missing data
for col in df.columns:
missing = df[col].isnull()
num_missing = np.sum(missing)
if num_missing > 0:
print('created missing indicator for: {}'.format(col))
df['{}_ismissing'.format(col)] = missing
# then based on the indicator, plot the histogram of missing values
ismissing_cols = [col for col in df.columns if 'ismissing' in col]
df['num_missing'] = df[ismissing_cols].sum(axis=1)
df['num_missing'].value_counts().reset_index().sort_values(by='index').plot.bar(x='index', y='num_missing')
- 可以根据实际需求处理缺失数据,比如删除包含缺失值的行或列,填充某个量 或 特殊值
# drop rows with a lot of missing values.
ind_missing = df[df['num_missing'] > 35].index
df_less_missing_rows = df.drop(ind_missing, axis=0)
# hospital_beds_raion has a lot of missing.
# If we want to drop.
cols_to_drop = ['hospital_beds_raion']
df_less_hos_beds_raion = df.drop(cols_to_drop, axis=1)
# impute the missing values and create the missing value indicator variables for each numeric column.
df_numeric = df.select_dtypes(include=[np.number])
numeric_cols = df_numeric.columns.values
for col in numeric_cols:
missing = df[col].isnull()
num_missing = np.sum(missing)
if num_missing > 0: # only do the imputation for the columns that have missing values.
print('imputing missing values for: {}'.format(col))
df['{}_ismissing'.format(col)] = missing
med = df[col].median()
df[col] = df[col].fillna(med)
# impute the missing values and create the missing value indicator variables for each non-numeric column.
df_non_numeric = df.select_dtypes(exclude=[np.number])
non_numeric_cols = df_non_numeric.columns.values
for col in non_numeric_cols:
missing = df[col].isnull()
num_missing = np.sum(missing)
if num_missing > 0: # only do the imputation for the columns that have missing values.
print('imputing missing values for: {}'.format(col))
df['{}_ismissing'.format(col)] = missing
top = df[col].describe()['top'] # impute with the most frequent value.
df[col] = df[col].fillna(top)
# categorical
df['sub_area'] = df['sub_area'].fillna('_MISSING_')
# numeric
df['life_sq'] = df['life_sq'].fillna(-999)
1.3.异常值
- 针对某个特征观察其数据分布,或者通过聚类,散点图等方法检测异常值,用PyOD工具库进行「异常检测」
# histogram of life_sq.
df['life_sq'].hist(bins=100)
# box plot.
df.boxplot(column=['life_sq'])
df['life_sq'].describe()
# bar chart - distribution of a categorical variable
df['ecology'].value_counts().plot.bar()
- 对异常值处理也可以丢弃,替换或保留
1.4.冗余
- 不必要的冗余数据包括数据重复,数据不相关,数据复制。当完全确定这些数据提供不了任何信息的时候可以将其删除
num_rows = len(df.index)
low_information_cols = []
for col in df.columns:
cnts = df[col].value_counts(dropna=False)
top_pct = (cnts/num_rows).iloc[0]
if top_pct > 0.95: #所在列的95%的值都一样
low_information_cols.append(col)
print('{0}: {1:.5f}%'.format(col, top_pct*100))
print(cnts)
print()
df_dedupped = df.drop('id', axis=1).drop_duplicates()
1.5.格式不一致
- 特征相同,但是字符串的大小写不一样;时间数据不统一;类别标签不统一;地址数据混乱等。需要根据实际情况考察
2.化学数据处理
- 来自文章 Trust, but verify: on the importance of chemical structure curation in cheminformatics and QSAR modeling research,细节很多推荐看看原文
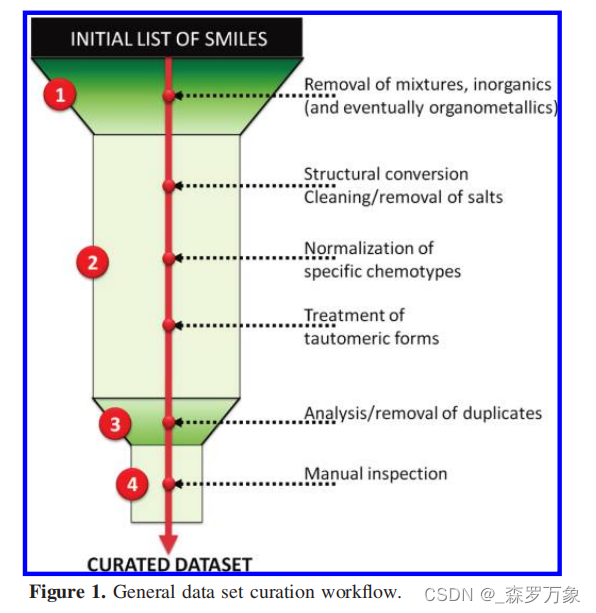
- 关于代码实现可以看看 iANP-EC: Identifying Anticancer Natural Products Using Ensemble
Learning Incorporated with Evolutionary Computation ,涉及到数据清洗过程如下,rdkit实现的开源在这里(有时间可以分析一下抽离出来)
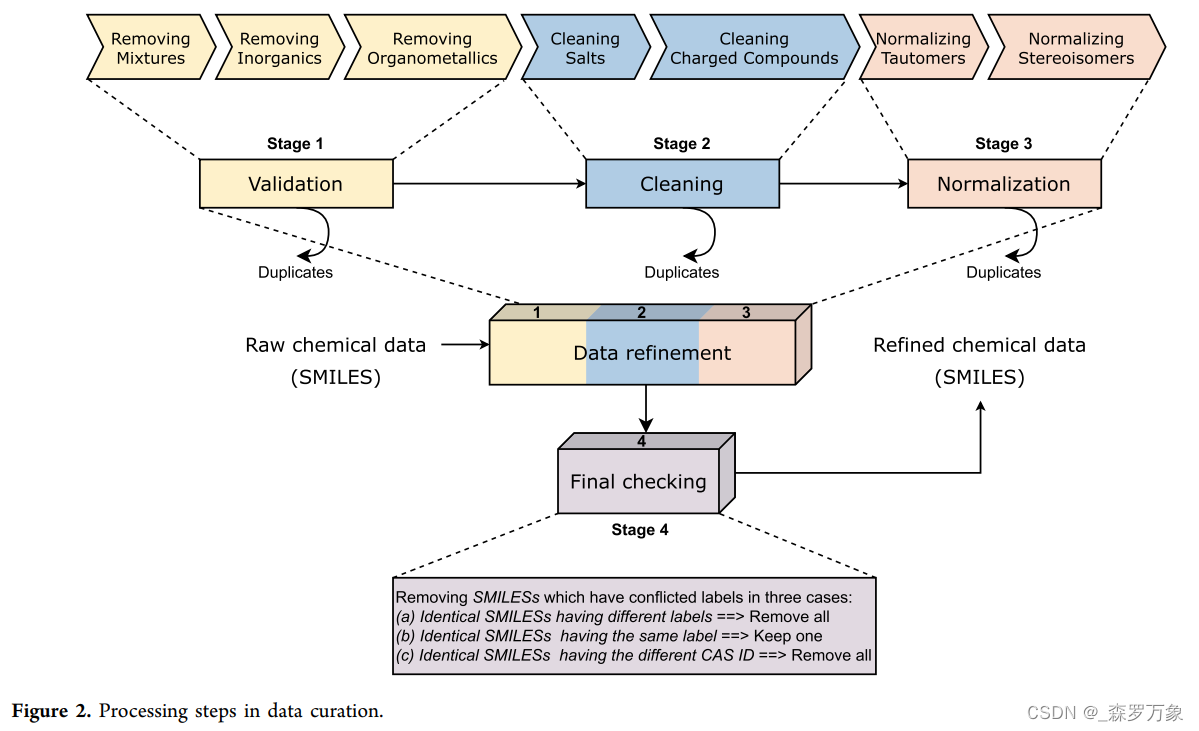
2.1.无机物和混合物
-
通过识别是否包含 C,H,O,N,S,Cl,Br,P 元素,删去包含其他元素的化合物,也可以根据具体情况过滤不需要的元素
-
一个SMILES字符串可以代表多个分子,使其无法直接计算描述符。通常的做法是保留混合物中分子量最大或原子数最多的成分。然而,最好的选择是在计算描述符之前删除混合物的记录。
2.2.带电荷分子和盐类,处理显性/隐性氢原子
2.3.化学结构规范化
- 官能团表示的规范化和同分异构体表示
2.4.重复化合物
- 同一个化合物可能由不同的 SMILES 表示,需要删去完全一致的化合物
2.5.人工检查
- 针对具体问题进行更细致的人工检查



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











