







大数据
按顺序给出数据存储单位:bit 、 Byte 、 KB、 MB 、 GB 、 TB 、 PB 、 EB 、 ZB 、 YB 、BB 、 NB 、 DB 。1Byte = 8bit 1K = 1024Byte 1MB = 1024K1G = 1024M 1T = 1024G1P = 1024T
Hadoop
分布式处理是指:比如有100T的大量数据,不存储在一台服务器上,分别存储在3台服务器上,就叫分布式处理。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
Hadoop为海量数据提供 存储 + 计算 的一个软件框架,旨在处理大规模数据集。主要解决海量数据的存储和计算问题。
Hadoop三大核心组件:
- HDFS(分布式文件系统) -—— 实现将文件分布式存储在集群服务器上
- Hadoop分布式文件系统(HDFS):HDFS是Hadoop的存储组件,它是一个分布式文件系统,设计用于存储大规模数据集。它将数据分割成块并在集群中的多个节点上复制,以提供高可用性和容错性。
- MAPREDUCE(分布式运算编程框架) —— 实现在集群服务器上分布式并行运算
- MapReduce是Hadoop的计算模型,用于处理分布式数据处理任务。它包括两个主要阶段,即"Map"和"Reduce"。"Map"阶段负责将输入数据映射到中间键/值对,而"Reduce"阶段负责对这些中间结果进行聚合和分析。
- YARN(分布式资源调度系统) —— 帮用户调度大量的 MapReduce 程序,并合理分配运算资源(CPU和内存)
- YARN是Hadoop的资源管理器,负责集群资源的分配和管理。它允许多个应用程序同时在同一个Hadoop集群上运行,从而提高了资源利用率。
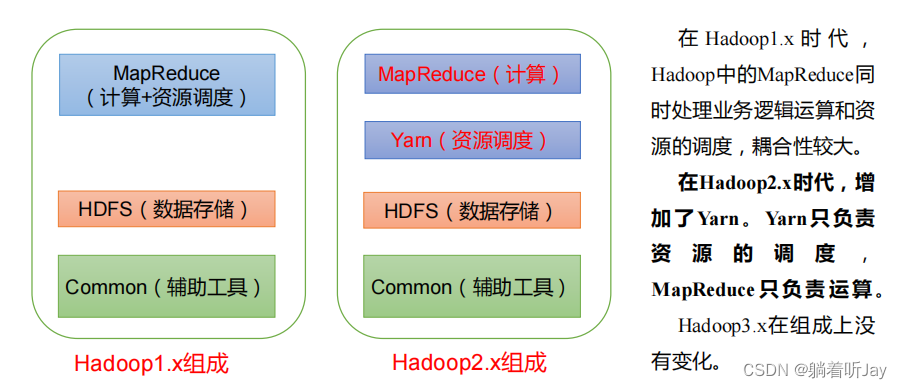
Hadoop四个优点
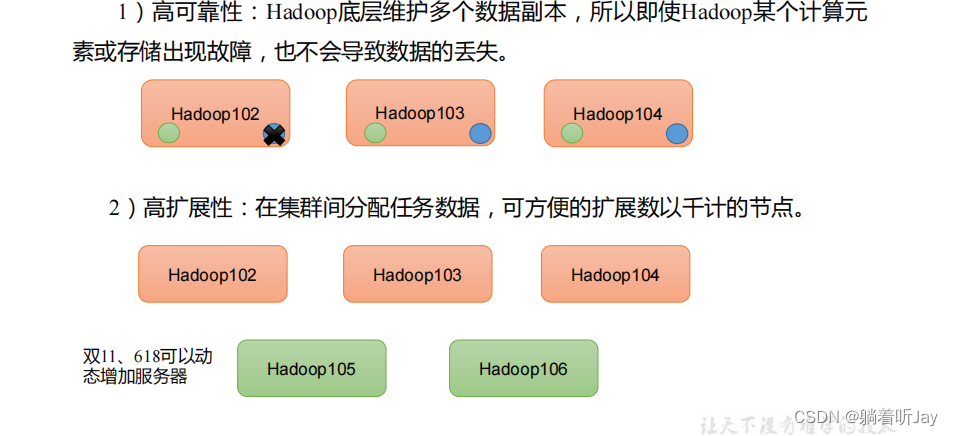
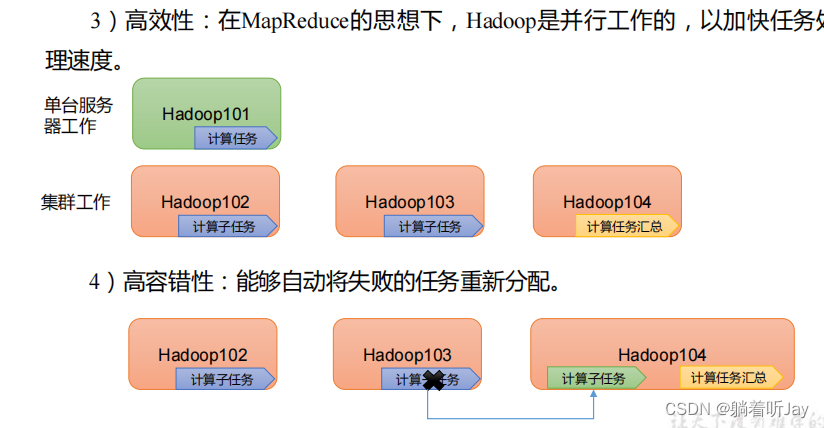
Hadoop三大组件
HDFS 分布式文件系统
实现将文件(数据)分布式的存储起来
HDFS架构:NameNode + DataNode +Secondary NameNode(2nn)

NameNode(nn)
简单理解是:存储数据存在哪里呀什么的,比如说前面1T存在Hadoop100上。存储文件(数据)的 元数据 ,如 文件名,文件目录结构,文件属性 (生成时间、副本数、 文件权限),以及每个文件的 块列表 和 块所在的 DataNode 等。

DataNode
是具体存数据的服务器节点,一台服务器就是一个DataNode。

NameNode安装服务也有可能宕机掉,这时候2nn就可以上去顶替nn的作用了。所以2nn每隔一段时间就会对nn中的数据进行备份同步。
MapReduce
负责海量数据的计算,计算的过程分为Map和Reduce两个过程。
Map是将海量的数据分成一个一个小模块处理,从而提高数据的处理效率,map就是负责将数据分块并行处理。
Reduce负责将map阶段分模块处理的结果都汇集起来。
YARN
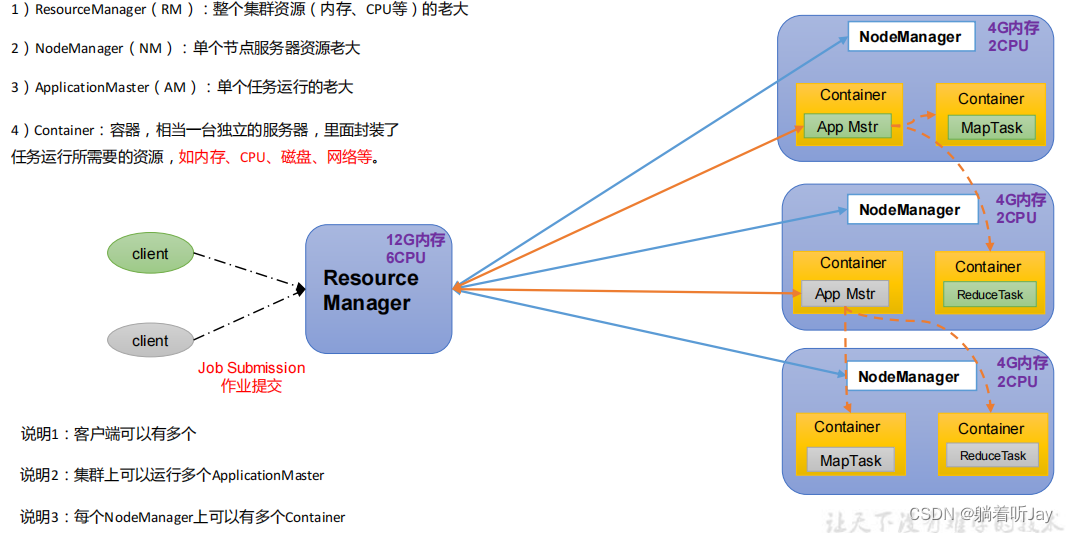
三大组件联系
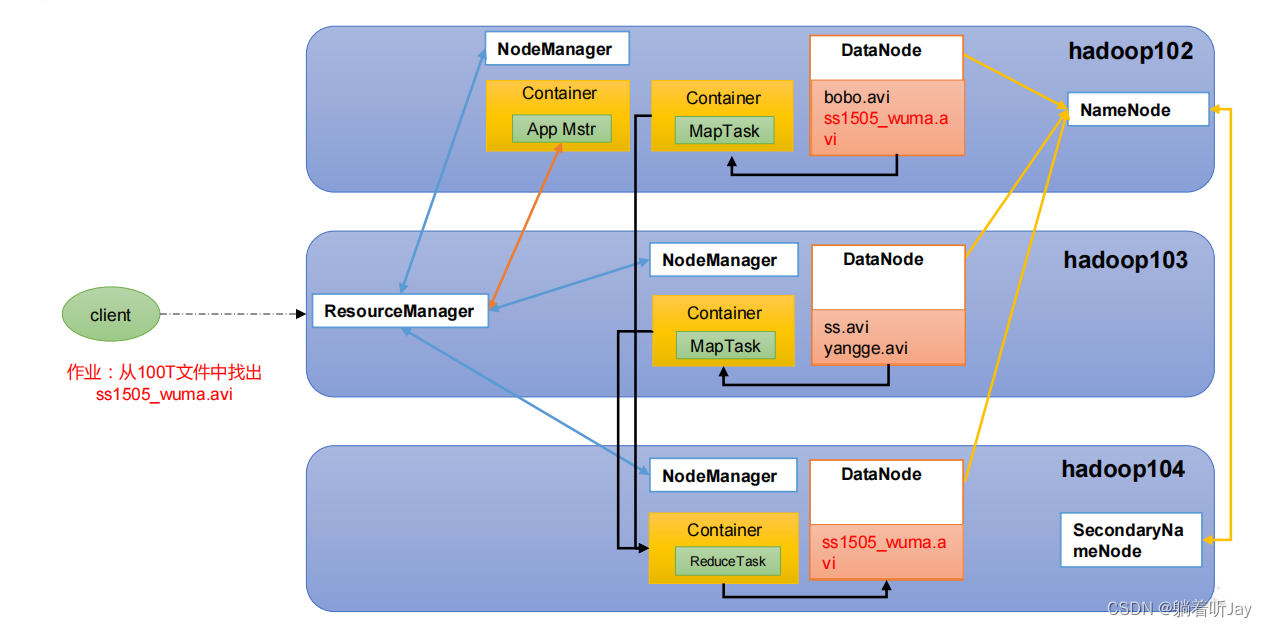 这100T文件都已经存好了,然后ResourceManager会创建一个总的APP Mtr,AppMtr告诉ResourceManager说这个任务总共需要10G内存,8个CPU,然后ResourceManager就在集群中看,发现Hadoop102 103就够了,就在这个两个上创建了两个Container来处理任务,然后Map就将这个100T的数据分成了两个MapTask分别并行处理,处理的结果由Reduce Task汇总到Hadoop104中。
这100T文件都已经存好了,然后ResourceManager会创建一个总的APP Mtr,AppMtr告诉ResourceManager说这个任务总共需要10G内存,8个CPU,然后ResourceManager就在集群中看,发现Hadoop102 103就够了,就在这个两个上创建了两个Container来处理任务,然后Map就将这个100T的数据分成了两个MapTask分别并行处理,处理的结果由Reduce Task汇总到Hadoop104中。
hadoop安装部署
1)集群部署规划
注意:NameNode和SecondaryNameNode不要安装在同一台服务器
注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| hadoop100 | hadoop101 | hadoop102 | |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
2)将hadoop安装包拉进来

3)进入到Hadoop安装包路径下
[atguigu@hadoop102 ~]$ cd /opt/software/
4)解压安装文件到/opt/module下面
[atguigu@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
5)查看是否解压成功
[atguigu@hadoop102 software]$ ls /opt/module/hadoop-3.1.3
6)重命名
[atguigu@hadoop102 software]$ mv /opt/module/hadoop-3.1.3 /opt/module/hadoop
7)将Hadoop添加到环境变量
(1)获取Hadoop安装路径
[atguigu@hadoop102 hadoop]$ pwd
/opt/module/hadoop
(2)打开/etc/profile.d/my_env.sh文件
[atguigu@hadoop102 hadoop]$ sudo vim /etc/profile.d/my_env.sh
在profile文件末尾添加JDK路径:(shitf+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
(3)保存后退出
:wq
(4)分发环境变量文件
[atguigu@hadoop102 hadoop]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
(5)source 是之生效(3台节点)
[atguigu@hadoop102 module]$ source /etc/profile.d/my_env.sh
[atguigu@hadoop103 module]$ source /etc/profile.d/my_env.sh
[atguigu@hadoop104 module]$ source /etc/profile.d/my_env.sh
报错
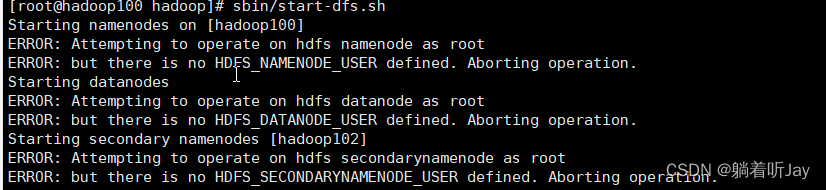
1、启动hdfs时报错:
but there is no HDFS_NAMENODE_USER defined. Aborting operation.
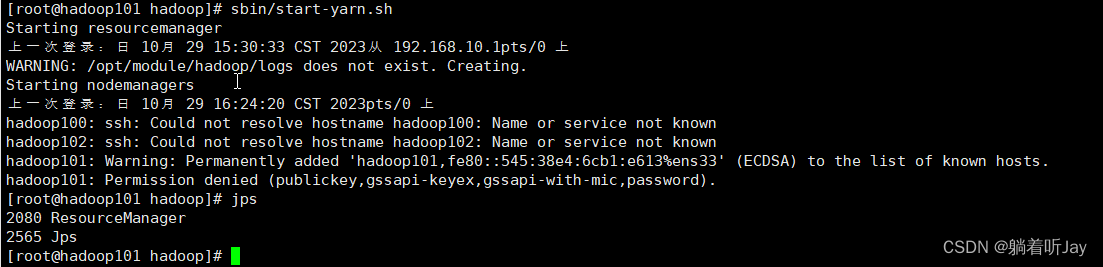
2、启动yarn报错
这里ResourceManager和NodeManager是安装在hadoop101上,看起来是ResourceManager启动成功了,NodeManager启动失败,看起来好像是需要ssh登录到hadoop100和102上,那就配置一下免密登录。
3、访问hadoop102的2nn页面报错
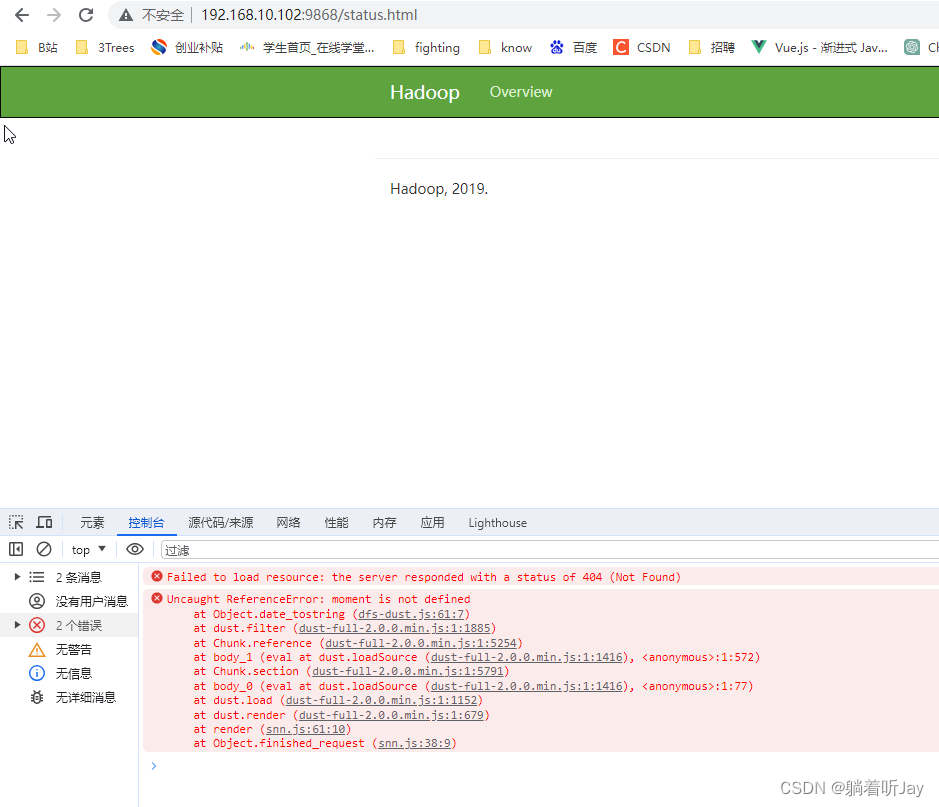
解决方案:hadoop3.13 SecondaryNameNode 页面报 moment is not defined-CSDN博客
















 394
394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











