







原本是想抽取arxiv上面论文中的参考文献信息,但是PDF文件难以解析。固想到用该论文的信息去其他数据库中检索。semantic scholar上面的论文就可以显示出文章的参考文献信息,固调用API实现此目的。总体的流程就是:
- 根据arxiv-id获取semantic scholar - id
- 通过semantic scholar - id获取该文章的参考文献信息(title、author、time、id)
数据准备
之前已经爬取好了arxiv上关于GCN的论文元数据,见文章👉python爬取arXiv论文元数据
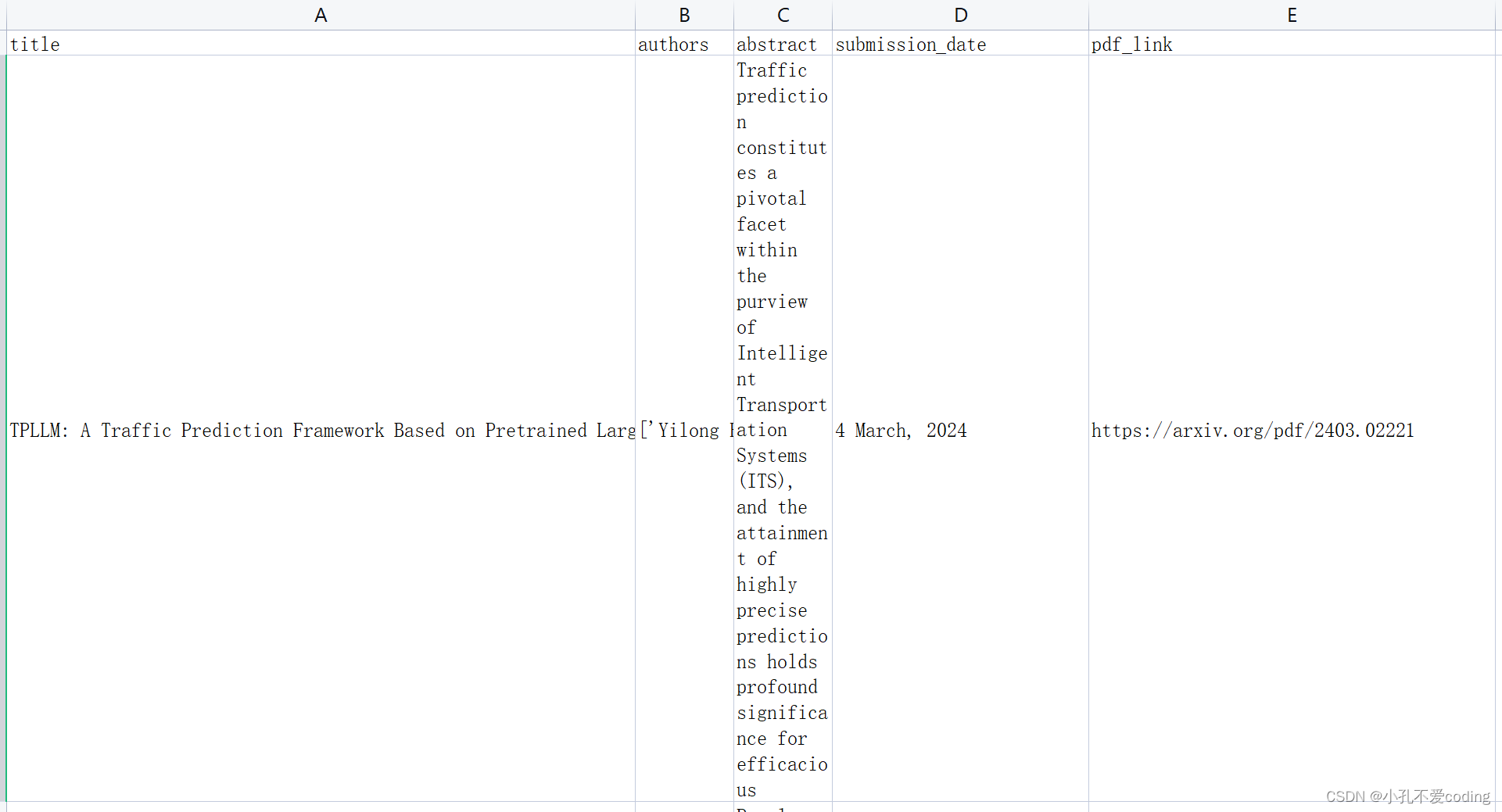
例如论文链接https://arxiv.org/pdf/2403.02221的最后一串数字2403.02221就是该篇文章的arxiv-id。
根据文章arxiv-id获取semantic scholar - id
import requests
# 设置 arXiv ID
arxiv_id = "2403.00825"
# 构造请求的 URL,使用 arXiv ID 作为参数
url = f"https://api.semanticscholar.org/v1/paper/arXiv:{
arxiv_id}"
# 发起请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 解析响应的 JSON 数据
data = response.json()
# 获取并打印 Semantic Scholar 的 ID
semantic_scholar_id = data.get("paperId")
print(f"Semantic Scholar ID: {
semantic_scholar_id}")
else:
print(f"请求失败,状态码:{
response.status_code}")
运行代码后输出:Semantic Scholar ID: f15a2d6878429c395e31d738a481fb39e98ca7e2
通过semantic scholar - id 获取该篇文章的参考文献信息(标题、作者、年份和ID)
import requests
semantic_scholar_id = "075f320d8e82673b51204a768d831a17f9999c02"
# 构造请求的URL
url = f"https://api.semanticscholar.org/v1/paper/{
semantic_scholar_id}"
# 发起请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
data = response.json()
# 检查是否有引用文献
if "references" in data and len(data["references"]) > 0:
# 打印引用文献的信息,例如标题、作者、时间和Semantic Scholar-ID
for reference in data["references"]:
print(f"Title: {
reference.get('title', 'No title available')}")
# 打印每个引用的作者,如果有的话
if "authors" in reference:
authors = ", ".join([author.get("name", "N/A") for author in reference["authors"]])</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1510
1510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









