







《推荐系统开发实战》学习笔记
《推荐系统开发实战》作者高阳团
第二章 搭建第一个推荐系统
搭建推荐系统的步骤
1.准备数据:不仅有要推荐物品的数据还要有用户的行为日志。
2.选择算法
3.模型训练:训练前的数据处理包括:归一化、空值处理;数据集较大时抽样虽小数据集。
4.效果评估:常见的模型评估包括准确率、召回率、F1-Score等。
第三章 推荐系统常用数据集
数据决定天花板?
3.1 MovieLens数据集
关于电影评分的数据集:https://grouplens.org/datasets/movielens/
书中使用的是 ml-1m.zip
解压之后有四个文件
3.1.1 README:对数据集的介绍
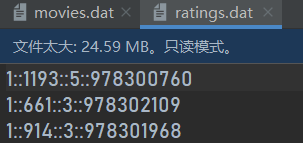
3.1.2ratings.dat:用户对电影的评分文件
个人感觉和.csv文件差不多
面临问题是如何把他导入到SQL server数据库中,并且能用python调用
列对应的是:UserID::MovieID::Rating::Timestamp
第一行表示ID为1的用户在978300760时间戳对ID为1193的电影打五分
下面用代码对这个数据进行一下简单的分析:
# 3-1评分记录数据查看
import pandas as pd
import matplotlib.pyplot as plt
#用来正常显示中文标签
plt.rcParams["font.sans-serif"] = ["SimHei"]
#用来正常显示负号
plt.rcParams["axes.unicode_minus"] = False
def getRatings(file_path):
rates = pd.read_table(
file_path,
header=None,
sep="::",
names=["userID","movieID","rate","timestamp"],
engine = 'python'
)
print("userID的范围为:<{},{}>".format(min(rates["userID"]),max(rates["userID"])))
print("movieID的范围为:<{},{}>".format(min(rates["movieID"]), max(rates["movieID"])))
print("rate的范围为:<{},{}>".format(min(rates["rate"]), max(rates["rate"])))
print("数据总条数为:\n{}".format(rates.count())) #统计了rates的总数
print("数据前5条记录为:\n{}".format(rates.head(5)))
df = rates["userID"].groupby(rates["userID"])
print("用户评分记录最少的条数为:{}".format(df.count().min()))
#制作一个条形图
scores = rates["rate"].groupby(rates["rate"]).count()
#在图上添加数字
for x,y in zip(scores.keys(),scores.values):
plt.text(x, y+2, "%.0f" % y, ha="center", va="bottom", fontsize=12)
plt.bar(scores.keys(),scores.values, fc="r", tick_label=scores.keys())
#给条形图加横纵标签和大title
plt.xlabel("评分分数")
plt.ylabel("对应人数")
plt.title("评分分数对应人数表")
plt.show()
if __name__ == "__main__":
getRatings("ratings.dat")
遇到的问题:
1.userID打成了userID;movieID打成了moviesID;太粗心了,这个错误还挺难找的,一点点找出来改了。
2.程序可以运行但是会报下面这个错误:
ParserWarning: Falling back to the ‘python’ engine because the ‘c’ engine does not support regex separators (separators > 1 char and different from ‘\s+’ are interpreted as regex); you can avoid this warning by specifying engine=‘python’.
return read_csv(**locals())

解决方法:加上 engine=‘python’
rates = pd.read_table(
file_path,
header=None,
sep="::",
names=["userID","movieID","rate","timestamp"],
engine = 'python'#加上这个就好了
)
转载于:https://www.cnblogs.com/kimbo/p/6347148.html
经历一番磨难代码终于跑起来了
以下是代码运行效果:


总算是看到了其中一个文件的统计结果,今天先结束吧















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









