






目录
启动Hadoop集群
/usr/local/hadoop/bin/hdfs namenode -format
显示信息内若包含以下内容,则说明成功格式化:
2.然后启动全部进程:进入hadoop目录下
sbin/start-all.sh
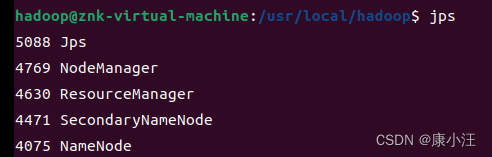
3.jps
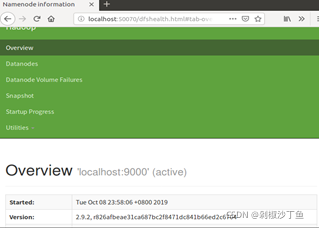
3.成功启动后,可以通过web浏览器访问http://localhost:50070,可以看到如下界面:
成功!

命令行访问HDFS
输入hadoop fs -help命令获取每个命令的详细帮助
1.对文件和目录的操作
所有操作前加./bin
例如:./bin/hadoop fs -ls
![]()
hadoop fs -ls <path> #列出文件或目录内容
hadoop fs -lsr <path> #递归列出目录内容
hadoop fs -dr <path> #查看目录的使用情况
hadoop fs -du <path> #显示目录中所有文件及目录大小
hadoop fs -touchz <path> #创建一个路径为<path>的0字节的HDFS的空文件
hadoop fs -mkdir <path> #在HDFS上创建路径为<path>的目录
hadoop fs -rm [-skipTrash] <path>#将HDFS上路径为<path>的文件移动到回收站,加上-skipTrash则直接删除
hadoop fs -rmr [-skipTrash] <path>#将HDFS上路径为<path>的文件及目录下的文件移动到回收站,加上-skipTrash则直接删除
hadoop fs -moveFromLocal <localsrc>...<dst> #将<localsrc>本地文件移动到HDFS的<dst>目录下
hadoop fs -moveToLocal[-crc]<src><localdst> #将HDFS上路径为<src>的文件移动到本地<localdst>路径下
hadoop fs -put <localsrc>...<dst> #将本地文件系统中复制单个或多个源路径到目标文件系统
hadoop fs -cat <src> #浏览HDFS路径为<src>的文件的内容2.修改权限或用户组
hadoop fs -chmod [-R] <MODE [,MODE]... |OCTALMODE> PATH... #改变HDFS上路径为PATH的文件的权限,-R选项表示递归执行该操作
例如:hadoop fs -chomd -R +r /user/test,表示将/user/test目录下的所有文件赋予读的权限
hadoop fs -chown [-R][OWNER][:[GROUP]]PATH... #改变HDFS上路径为PATH的文件的所属用户,-R选项表示递归执行该操作
例如:hadoop fs -chown -R hadoop:hadoop /user/test,表示将/user/test目录下的所有文件的所属用户和所属组别改为hadoop
hadoop fs -chgrp [-R] GROUP PATH... #改变HDFS路径为PATH的文件的所属组别,-R选项表示递归执行该操作
例如:hadoop fs -chgrp -R hadoop /user/test,表示将/user/test目录下所有文件的所属组别改为hadoop3.其他命令
hadoop fs -tail [-f]<file> #显示HDFS上路径为<file>的文件的最后1kb的字节,-f会使显示的内容随着文件内容更新而更新
例如:hadoop fs -tail -f /user/test.txt
hadoop fs -stat[format]<path> #显示HDFS上路径为<path>的文件或目录的统计信息。
格式:%b 文件大小 %n 文件名 %r 复制银子 %y,%Y 修改日期
例如:hadoop fs -stat %b %n %o %r /user/test
hadoop fs -put <localsrc>... <dst> #将<localsrc>本地文件上传到HDFS的<dst>目录下
例如:hadoop fs -put /home/hadoop./test.txt /user/hadoop
hadoop fs -count[-q] <path> #将显示<path>下的目录数及文件数,输出格式为 “目录数 文件数 大小 文件名”,加上-q可以查看文件索引的情况
例如:hadoop fs -count /
hadoop fs -get [-ignoreCrc][-crc]<src><localdst> #将HDFS上<src>的文件下载到本地的<localdst>目录,可用-ignoreCrc选项复制CRC校验失败的文件,使用-crc选项复制文件以及CRC信息
例如:hadoop fs -get /user/hadoop/a.txt /home/hadoop
hadoop fs -getmerge <src><localdst>[addnl] #将HDFS上<src>目录下的所有文件按文件名排序并合并成一个文件输出到本地的<localdst>目录,addnl是可选的,用于指定在每个文件结尾添加一个换行符
例如:hadoop fs -getmerge /user/test /home/hadoop/o
hadoop fs -test -[ezd]<path> #检查HDFS上路径为<path>的文件。-e检查文件是否存在,若存在返回0.
-z检查文件是否是0字节,若是返回0. -d检查路径是否是目录,若是目录返回1,否则返回0.
例如:hadoop fs -test -e /user/test.txt下载和安装Scala IDE for Eclipse
进入Scala IDE for Eclipse官网,选择Linux GTK 64 bit,下载到自己的笔记本电脑中。
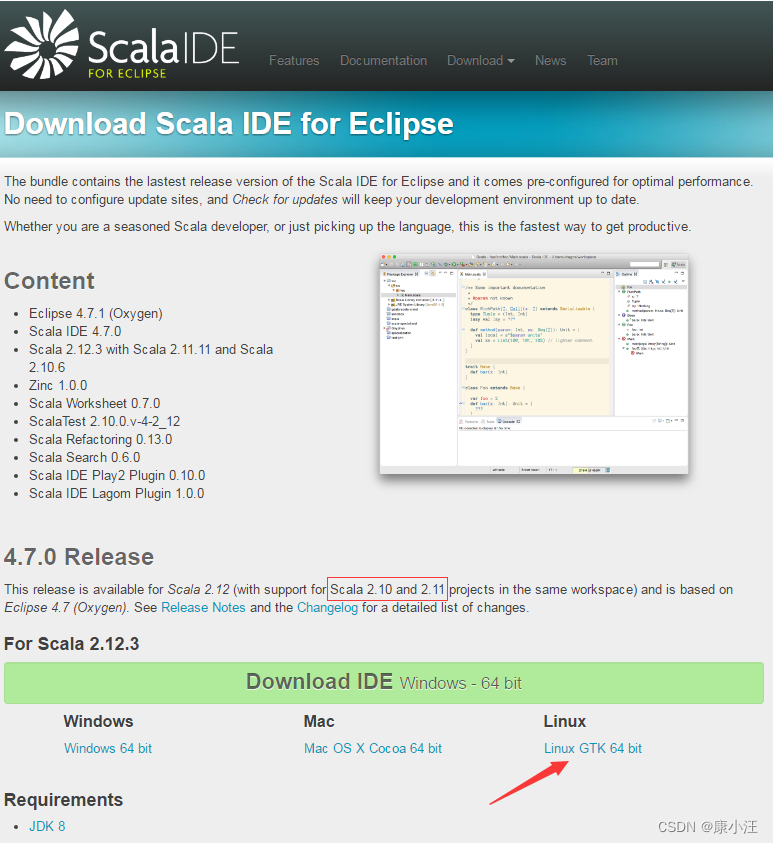
或者,也可以直接在自己的笔记本电脑中,点击这里访问百度云盘下载scala-SDK-4.7.0-vfinal-2.12-linux.gtk.x86_64.tar.gz文件(提取码:gx0b),下载到自己笔记本电脑,然后使用FTP软件上传到阿里云ECS实例的Ubuntu系统的“/home/linziyu/Downloads”目录下(点击这里阅读FTP连接ECS的方法)。
接下来,在自己的笔记本电脑中,使用VNC Viewer软件连接到阿里云ECS实例的Ubuntu系统(阅读VNC使用方法),在远程的Ubuntu系统中打开一个命令行终端(假设当前登录用户为linziyu),然后,执行如下命令解压安装包到/usr/local下,并测试运行Eclipse:
cd ~
sudo tar -zxvf ~/Downloads/scala-SDK-4.7.0-vfinal-2.12-linux.gtk.x86_64.tar.gz -C /usr/local
cd /usr/local
ls #可以看到当前目录下已经出现一个eclipse子目录
cd eclipse
//运行eclipse
./eclipse然后,会弹出如下界面,请在界面中点击“Launch”按钮。
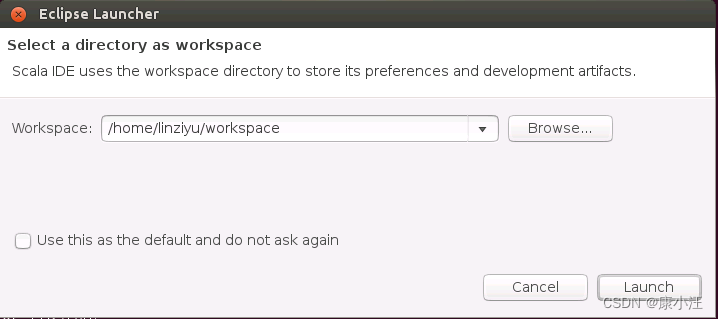 然后,Eclipse会启动进入如下工程开发界面:
然后,Eclipse会启动进入如下工程开发界面:
二、在eclipse中创建项目
(1)第一次打开Eclipse,需要填写workspace(工作空间),用来保存程序所在的位置,这里可以按照默认,不需要改动。
点击“OK”按钮,进入Eclipse软件。
成功启动后的界面。
(2)创建Java工程

选择“File->New->Java Project”菜单,开始创建一个Java工程,会弹出如下图所示的界面。
在“Project name”后面输入工程名称“HDFSExample”,选中“Use default location”,让这个Java工程的所有文件都保存到“/home/hadoop/workspace/HDFSExample”目录下。在“JRE”这个选项卡中,可以选择当前的Linux系统中已经安装好的JDK,比如java-8-openjdk-amd64。然后,点击界面底部的“Next>”按钮,进入下一步的设置。
三、为项目添加所需要的JAR包

需要在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了可以访问HDFS的Java API。这些JAR包都位于Linux系统的Hadoop安装目录下。
就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External
JARs…”按钮。
上面的一排目录按钮(即“usr”、“local”、“hadoop”、“share”、“hadoop”、“mapreduce”和“lib”),当点击某个目录按钮时,就会在下面列出该目录的内容。
为了编写一个能够与HDFS交互的Java应用程序,一般需要向Java工程中添加以下JAR包:
(1)”/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar;
(2)/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的haoop-hdfs-2.7.1.jar和haoop-hdfs-nfs-2.7.1.jar;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
比如,如果要把“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar添加到当前的Java工程中,可以在界面中点击目录按钮,进入到common目录,然后,界面会显示出common目录下的所有内容,如下图:

在界面中用鼠标点击选中hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar,然后点击界面右下角的“确定”按钮,就可以把这两个JAR包增加到当前Java工程中,出现的界面如下所示:

可以看出,hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar已经被添加到当前Java工程中。然后,按照类似的操作方法,可以再次点击“Add External JARs…”按钮,把剩余的其他JAR包都添加进来。需要注意的是,当需要选中某个目录下的所有JAR包时,可以使用“Ctrl+A”组合键进行全选操作。全部添加完毕以后,就可以点击界面右下角的“Finish”按钮,完成Java工程HDFSExample的创建。
四、编写Java应用程序代码
编写一个Java应用程序,用来检测HDFS中是否存在一个文件:
在Eclipse工作界面左侧的“Package Explorer”面板中,找到刚才创建好的工程名称“HDFSExample”,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择“New->Class”菜单。

在该界面中,只需要在“Name”后面输入新建的Java类文件的名称,这里采用名称“HDFSFileIfExist”,其他都可以采用默认设置,然后,点击界面右下角“Finish”按钮,出现下图所示界面:

可以看出,Eclipse自动创建了一个名为“HDFSFileIfExist.java”的源代码文件,在该文件中输入以下代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSFileIfExist {
public static void main(String[] args){
try{
String fileName = "test";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(fileName))){
System.out.println("文件存在");
}else{
System.out.println("文件不存在");
}
}catch (Exception e){
e.printStackTrace();
}
}
}
该程序用来测试HDFS中是否存在一个文件。
其中的String fileName = “test”
这行代码给出了需要被检测的文件名称是“test”,没有给出路径全称,表示是采用了相对路径,实际上就是测试当前登录Linux系统的用户hadoop,在HDFS中对应的用户目录下是否存在test文件,也就是测试HDFS中的“/user/hadoop/”目录下是否存在test文件。
五、编译运行程序
在开始编译运行程序之前,一定要确保Hadoop已经启动运行,如果还没有启动,需要打开一个Linux终端,输入以下命令启动Hadoop:
cd /usr/local/hadoop
sbin/start-all.sh
然后就可以编译运行上面第(四)点编写的代码。可以直接点击Eclipse工作界面上部的运行程序的快捷按钮,当把鼠标移动到该按钮上时,在弹出的菜单中选择“Run As”,继续在弹出来的菜单中选择“Java Application”,如下图所示。

然后,会弹出如下图所示的界面:

在该界面中,需要在“Select type”下面的文本框中输入“HDFSFileIfExist”,Eclipse就会自动找到相应的类“HDFSFileIfExist-(default package)”(注意:这个类在后面的导出JAR包操作中的Launch configuration中会被用到),然后,点击界面右下角的“OK”按钮,开始运行程序。程序运行结束后,会在底部的“Console”面板中显示运行结果信息。由于目前HDFS的“/user/hadoop”目录下还没有test文件,因此,程序运行结果是“文件不存在”。同时,“Console”面板中还会显示一些类似“log4j:WARN…”的警告信息,可以不用理会。
六、应用程序的配置
即如何把Java应用程序生成JAR包,部署到Hadoop平台上运行。首先,在Hadoop安装目录下新建一个名称为myapp的目录,用来存放我们自己编写的Hadoop应用程序,可以在Linux的终端中执行如下命令:
cd /usr/local/hadoop
mkdir myapp

然后,在Eclipse工作界面左侧的“Package Explorer”面板中,在工程名称“HDFSExample”上点击鼠标右键,在弹出的菜单中选择“Export”,如下图所示。

然后,会弹出如下图所示的界面:

在该界面中,选择“Runnable JAR file”,然后,点击“Next>”按钮,弹出如下图所示的界面:

在该界面中,“Launch configuration”用于设置生成的JAR包被部署启动时运行的主类,需要在下拉列表中选择刚才配置的类“HDFSFileIfExist-HDFSExample”。在“Export destination”中需要设置JAR包要输出保存到哪个目录,比如,这里设为“/usr/local/hadoop/myapp/HDFSExample.jar”。在“Library handling”下面选择“Extract required libraries into generated
JAR”。然后,点击“Finish”按钮,会出现如下图所示的界面:

可以忽略该界面的信息,直接点击界面右下角的“OK”按钮,启动打包过程。打包过程结束后,会出现一个警告信息界面,如下图所示:

可以忽略该界面的信息,直接点击界面右下角的“OK”按钮。至此,已经顺利把HDFSExample工程打包生成了HDFSExample.jar。可以到Linux系统中查看一下生成的HDFSExample.jar文件,可以在Linux的终端中执行如下命令:
cd /usr/local/hadoop/myapp
ls
可以看到,“/usr/local/hadoop/myapp”目录下已经存在一个HDFSExample.jar文件。现在,就可以在Linux系统中,使用hadoop jar命令运行程序,命令如下:
cd /usr/local/hadoop
hadoop jar ./myapp/HDFSExample.jar
或者也可以使用如下命令运行程序:
cd /usr/local/hadoop
java -jar ./myapp/HDFSExample.jar
命令执行结束后,会在屏幕上显示执行结果“文件不存在”。
至此,检测HDFS文件是否存在的程序,就顺利部署完成了。
读取文件
创建一个新的Java class文件,命名为“HDFSFileIfRead”并输入以下代码:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
public class HDFSFileIfRead{
public static void main(String[] args) {
try {
Configuration
conf = new Configuration(); conf.set("fs.defaultFS","hdfs://localhost:9000"); conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs =
FileSystem.get(conf);
Path file = new Path("test");
FSDataInputStream getIt =
fs.open(file);
BufferedReader
d = new BufferedReader(new InputStreamReader(getIt));
String content
= d.readLine(); //读取文件一行
System.out.println(content);
d.close(); //关闭文件
fs.close(); //关闭hdfs
} catch (Exception e) {
e.printStackTrace();
}
}
}
在eclipse里面编译运行:

将这个java程序打包成jar包,部署到Hadoop平台上运行。

进入 “/usr/local/hadoop/myapp”,查看是否存在对应的jar包:

在终端用hadoop命令运行jar包:

使用Java API 访问HDFS
FileSystem类是与Hdoop的文件系统进行交互的API,也是使用最为频繁的API。
1.使用Hdoop URL读取数据
要从Hadoop文件系统读取数据,最简单的方法是使用java.net.URL对象打开数据流,从中读取数据。
inputStream in=null;
try{
in=new URL("hdfs://host/path").openStream();
}finally{
IOUtils.closeStream(in);
}让Java程序能够识别Hadoop 的HDFS URL方案还需要一些额外的工作,这里采用的方法是通过 org.apache.hadoop.fs.FsUrlStreamHandlerFactor 实例调用javanet.URL 对象setURLStreamHandleiFactory 实例方法。每个Java 虚拟机只能调用一次这个方法,因此通常在静态方法中调用。下述范例展示的程序以标准输出方式显示 Hadoop 文件系统中的文件,类似于 UNIX 中的 cat 命令。
package bigdata.ch03.hdfsclient;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils;
public class URLcat[
static{
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[]args) throws
MalformedURLException,IOException{
InputStream in =null;
try{
in = new URL(args[0]).openStream();
IOUtils.copyBytes(in,System.out,4096,false);
}finally{
IOutils.closeStream(in);
}
}
}编译代码,导出为URLcat.jar 文件,执行命令:
hadoop jar URLcat.jar hdfs://master:9000/user/hadoop/test
执行完成后,屏幕上输出HDFS 文件/user/hadoop/test 中的内容。该程序是从HDFS读取文件的最简单的方式,即用java.net.URL对象打开数据流。其中,第8~10行静态代码块的作用是设置URI类能够识别 hadoop 的HDFS url。第 16行IOUtils 是 hadoop 中定义的类,调用其静态方法 copyBytes实现从HDFS 文件系统拷贝文件到标准输出流。4096 表示用来拷贝的缓冲区大小,false 表明拷贝完成后并不关闭拷贝源。
2.通过 FileSystem API读取数据
在实际开发中,访问 HDFS 最常用的类是 FileSystem 类。Hadoop 文件系统中通过 Hadoop Path对象来定位文件。可以将路径视为一个 Hadoop 文件系统 URI,如 hdfs://localhost/user/tom/test.txt。FileSystem 是一个通用的文件系统API,获取 FileSystem 实例有下面几个静态方法:
public static FileSystem get(Configuration conf) throws IOExceptionpublic static FileSystem get(URI uri,Configuration conf) throws IOException
public static FileSystem get(URI uri,Configuration conf,String user) throw IOException
第一个方法返回的是默认文件系统;第二个方法通过给定的 URI方案和权限来确定要使用的文件系统,如果给定 URI 中没有指定方案,则返回默认文件系统;第三个方法作为给定用户来访问文件系统,对安全来说是至关重要。下面分别给出几个常用操作的代码示例。
(1) 读取文件
代码示例如下:
package bigdata.ch03.hdfsclient;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class FileSystemCat{
public static void main(String[] args) throws IOException{
String uri="hdfs://master:9000/user/hadoop/test";
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create(uri),conf);
Inputstream in=null;
try{
in = fs.open(new Path(uri));
IOUtils.copyBytes(in,System.out,4096,false);
}finally{
IOUtils.closeStream(in);
}
}
}上述代码直接使用 FileSystem 以标准输出格式显示 Hadoop 文件系统中的文件。
第12行产生一个 Configruation 类的实例,代表了 Hadoop 平台的配置信息,并在第13 行作为引用传递到 FileSystem 的静态方法 get 中,产生 FileSystem 对象。
第17行与上例类似,调用Hadoop 中IOUtils 类,并在finally 字中关闭数据流,同时也可以在输入流和输出流之间复制数据。copyBytes 方法的最后两个参数,第一个设置用于复制的缓冲区大小,第二个设置复制结束后是否关闭数据流。
(2)写入文件
代码示例如下:
package bigdata.ch03.hdfsclient;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class FileCopyFromLocal(
public static void main(String[] args) throws IOException {
String source="/home/hadoop/test";
String destination = "hdfs://master:9000/user/hadoop/test2";
InputStream in = new BufferedInputStream(new FileInputStream(source));
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get (URI.create (destination),conf);
Outputstream out=fs,create(new Path(destination));
IOUtils.copyBytes(in,out,4096,true);
}
}上述代码显示了如何将本地文件复制到 Hadoop 文件系统,每次 Hadoop 调用 progress0方法时也就是每次将 64KB 数据包写入 DataNode 后,打印一个时间点来显示整个运行过程。
(3)创建HDFS 目录
代码示例如下:
package bigdata.ch03.hdfsclient;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreateDir(
public static void main(String[] args){
String uri="hdfs://master:9000/user/test";
Configuration conf=new Configuration();
try{
FileSystem fs=FileSystem.get(URI.create(uri),conf);
Path dfs=new Path("hdfs://master:9000/user/test");
fs.mkdirs(dfs);
}catch (IOException e) {
e.printstackTrace();
}
}
}Filesystem实例提供了创建目录的方法:
public boolean mkdir(Path f) throws IOException这个方法可以一次性新建所有必要但还没有的父目录,就像 java.io.File类的mkdirs0方法。如果目录都已经创建成功,则返回 true。通常,你不需要显示创建一个目录,因为调用 create0方法写入文件时会自动创建父目录。
(4)删除 HDFS 上的文件或目录
示例代码如下:
package bigdata.ch03,hdfsclient;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class DeleteFile{
public static void main(String[] args){
String uri="hdfs://master:9000/user/hadoop/test";
Configuration conf = new Configuration();
try{
FileSystem fs = FileSystem.get(URI.create(uri),conf);
Path delef=new Path("Path://master:9000/user/hadoop");
boolean isDeleted=fs.delete(delef,true);
System.out.println(isDeleted) ;
} catch (IOException e){
e.printStackTrace();
}
}
}使用FileSystem的 delete0方法可以永久性删除文件或目录。如果需要递归删除文件夹,则需要将fs.delete(arg0,argl)方法的第二个参数设为 true。
(5)列出目录下的文件或目录名称
示例代码如下:
package bigdata,ch03,hdfsclient;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path
public class ListFiles{
public static void main(String[] args){
String uri="hdfs://master:9000/user";
Configuration conf=new Configuration();
try{
FileSystem fs=FileSystem.get(URI.create (uri),conf);
Path path=new Path(uri);
FileStatus stats[]=fs.liststatus(path);
for(int i=0;i<stats.length;i++){
System.out.printIn(stats[i].getPath.tostring());
}
fs.close();
} catch (IOException e) {
e.printstackTrace();
}
}
}文件系统的重要特性是提供浏览和检索其目录结构下所存文件与目录相关信息的功能FileStatus 类封装了文件系统中文件和目录的元数据,例如,文件长度、块大小、副本、修改时间所有者以及权限信息等。编译运行上述代码后,控制台将会打印出/user 目录下的名称或者文件名。















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









