







python爬取百度图片总体来说是比较简单的。爬虫一个网站,爬取百度图片的思路也是很有迹可循的。思路分为两大部分。第一部分(对百度图片的网页分析):百度图片是一个动态网页,怎么判断一个网页是动态网页或者说是个静态网页。也比较简单,网络上的资源也很多。简单说:如果你想爬取的内容,在页面源代码中很少(不全or没有),网址带有标志性的?。基本上就是动态网页。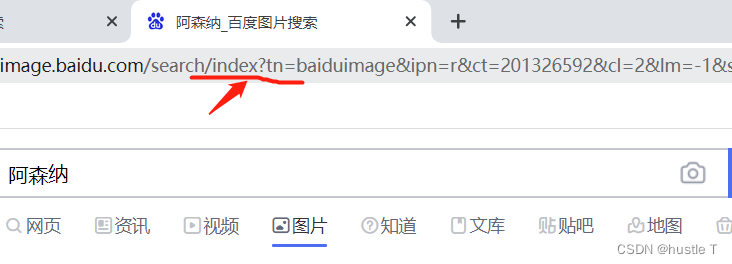
所以基本判断百度图片的网页是一个动态网页。这种与数据库不断交互的动态网页。我们在页面源代码中是拿不到照片地址的,或者说可能有20张的图吧(在有些网站中)。而静态网页是基本上全部内容我们在页面源代码都可以找到。所以第一部分的思路分析完成即我们针对动态网页进行爬取。
思路第二部分(代码实现爬取图片):首先打开浏览器的开发者工具(F12),然后锁定network(网络),再锁定fetch/xhr后。json中,就藏着一个个图像的相关信息。上图吧!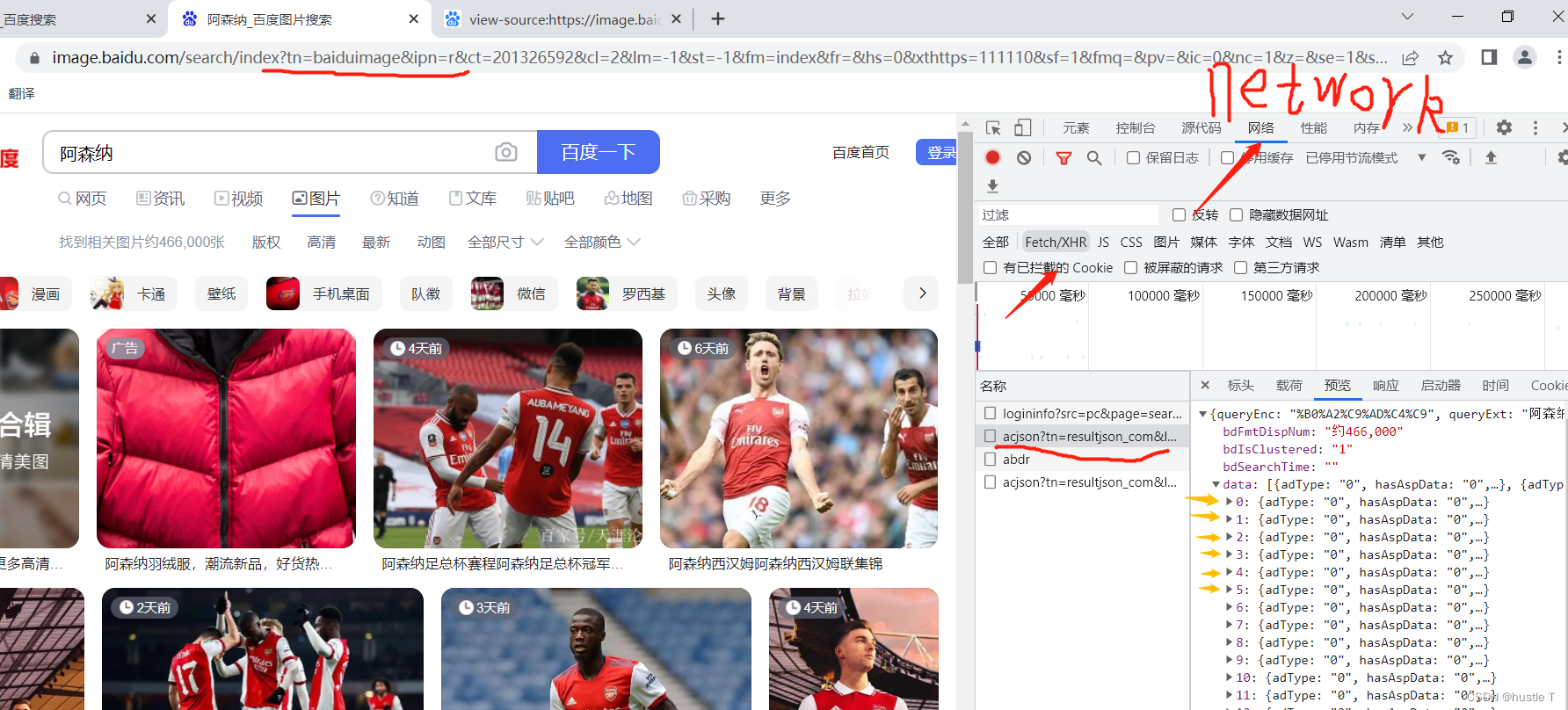
每当你访问你继续访问更多的照片,那么它又会传入一个新的以acjson开头的文件,,这就能很形象的感觉到动态了。而再这些以acjson开头的文件中,其页面源代码包含了其新的照片的访问地址,你只需要让程序去访问acjson的网页里面的源代码
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









