







前言
最近看到一些博主在讲解加密字体的破解方式,大体的解决方式是分析网页源代码,通过请求查看自定义字体,然后经过数据抓取完成需求。
这个方法确实很不错,但是对于我这种不太会爬虫的小白来说就与一些超纲了。另外这种爬虫在一定程度上可能会造成律师函警告,为此本次将向大家展示另一种全新的获取数据方式,对爬取的网站不起到任何“破解”行为。
1、需求分析
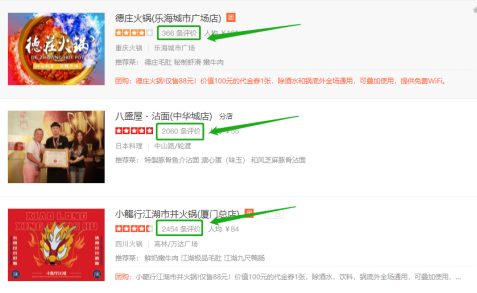
获取某某网站火锅主页的商户评价数据信息,如下图绿色箭头所示:
![]()
我们通过F12查看一下评价数据:
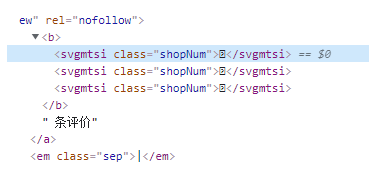
![]() 可以看出这个数据是被字体加密的,无法直接获取。
可以看出这个数据是被字体加密的,无法直接获取。
接下来就开始我的表演。
2、自动化打开网址
自动化打开网址使用的是subprocess和uiautomation来完成的,注意parameter和startmax两个参数的作用:
import subprocess
import uiautomation as auto
def show_index_window():
print('root Control:', auto.GetRootControl())
chromePath = "C:\\Users\\TH\\AppData\\Local\\Google\\Chrome\\Application\\chrome.exe"
url = r'http://www.dianping.com/xiamen/ch10/g110'
parameter = '--force-renderer-accessibility'
startmax = '-start-maximized'
run_cmd = chromePath + ' ' + url + ' ' + parameter + ' ' + startmax
subprocess.Popen(run_cmd)
mainWindow = auto.DocumentControl(ClassName='Chrome_RenderWidgetHostHWND')
print('mainWindow Name:',mainWindow.Name)
show_index_window()
3、获取评价数据截图文件
在此之后,我们打开控件识别工具 Inspect.exe工具(可从网上下载)来查看元素情况,我使用的是另一个工具,各个元素的分层情况就显而易见了:

![]()
可以看出,多少条评价也是隐藏的。从元素层级上来看,可以从文档元素->列表元素->列表项目元素的大体思路找到目标元素。也就是"XXXX条评论<链接>"这个元素,定位这个元素之后,就获取这个元素的大小,然后截图保存。具体的代码如下:
import time
import uiautomation as auto
# 获取每一个商户根元素
def get_root_control():
documentControl = auto.DocumentControl(ClassName='Chrome_RenderWidgetHostHWND')
# 层层搜索找到目标元素
documentControl_f_son_control = documentControl.GetChildren()[0]
# 子元素列表
f_son_control = documentControl_f_son_control.GetChildren()
target_list_control = None
for each_control in f_son_control:
son_control = each_control.GetChildren()
if len(son_control) == 1:
# 元素属性ControlTypeName为ListControl
if son_control[0].ControlTypeName == 'ListControl':
target_list_control = son_control[0]
break
return target_list_control
# 获取数据截图
def get_comment_pic():
mainWindow = auto.PaneControl(ClassName='Chrome_WidgetWin_1')
print('mainWindow Name:', mainWindow.Name)
# 窗口存在,切换窗口
if mainWindow.Exists(3, 1):
handle = mainWindow.NativeWindowHandle
auto.SwitchToThisWindow(handle)
target_list_control = get_root_control()
# 当前页面展示的商户的数量
business_num = len(target_list_control.GetChildren()) - 1
print('business_num:', business_num)
# 当前数据所在页数
PageNum = 0
# 获取xxxx评价元素的大小并截图
for i in range(business_num):
# 第一层,第二层,第三层数据
layer_1_ele = tar
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 656
656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











