






北京大学曹建老师的Tensorflow课程
神经网络计算
1.反向传播 梯度下降使损失函数减小 参数更新的过程
import tensorflow as tf
w=tf.Variable(tf.constant(5,dtype=tf.float32))
lr=0.2
epoch=40
for epoch in range(epoch):
with tf.GradientTape() as tape:#
loss = tf.square(w+1)
grads = tape.gradient(loss,w)
w.assign_sub(lr*grads)# w-=lr*grads
print("after %s epoch,w is %f,loss is %f"%(epoch,w.numpy(),loss))2.创建一个张量
import tensorflow as tf
import numpy as np
a=tf.constant([1,5],dtpye=tf.int64)#constant(张量内容,dtype=数据类型)
a=np.arrang(0,5)
b=tf.convert_to_tensor(a,dtype=tf.int64)#把numpy格式a编程tensor格式b
tf.zeros(维度)# 创建全为0的张量
tf.ones(维度)#创建全为1的张量
tf.fill(维度,指定值)#创建全为指定值的张量
tf.random.normal(维度,mean=均值,stddev=标准差)#生产正态分布的随机数
tf.random.truncated_normal(维度,mean=均值,stddev=标准差)
tf.random.uniform(维度,minval=最小值,maxval=最大值)#生产最小值和最大值之间的均匀分布随机数
3.TF2常用函数
tf.cast(张量名,dtype=数据类型)#强制tensor转换为该数据类型
tf.reduce_min(张量名)#计算张量维度上元素的最小值
tf.reduce_max(张量名)#计算张量维度上元素的最大值
#axis=0对列操作,=1对行操作
tf.reduce_mean(张量名,axis=操作轴)#计算平均值
tf.reduce_sum(张量名,axis=操作轴)#计算和
tf.Variable(tf.random.normal([2,2],mean=0,stddev=1))#将变量标记为可训练
tf.add(张量1,张量2)#实现两个张量对应元素相加
tf.subtract(张量1,张量2)#实现两个张量对应元素相减
tf.multiply(张量1,张量2)#实现两个张量对应元素相乘
tf.divide(张量1,张量2)#实现两个张量对应元素相除
tf.square(张量名)#平方
tf.pow(张量名,n次方数)#次方
tf.sqrt(张量名)#开方
tf.matmul(矩阵1,矩阵2)#两个矩阵相乘
tf.data.Dataset.from_tensor_slices((输入特征,标签))#把特征与标签配对4.TF2常用函数2
seq=['one','two','three']
for i,element in enumerate(seq): #enumerate 组合为:索引 元素
print(i,element)
#输出结果为:0 one
1 two
2 three
tf.one_hot(待转换数据,depth=几分类)#独热码
tf.nn.softmax(x)#softmax函数
w.assign_sub(w要减的内容) # w-= w要减的内容
tf.argmax(张量名,axis=操作轴) # 返回张量沿指定维度最大值得索引5.鸢尾花数据集读入
from pandas import DataFame
import pandas as pd
x_data= datasets.load_iris().data # data返回iris数据集所有输入特征
y_data= datasets.load_iris().target # target返回iris数据集所有标签
print("x_data from datasets:\n", x_data)
print("y_data from datasets:\n", y_data)6.神经网络实现鸢尾花分类
import os
from sklearn import datasets
from matplotlib import pyplot as plt
import tensorflow as tf
import numpy as np
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 1.1 数据集读入
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
# 1.2 数据集乱序
np.random.seed(116) # 使用相同种子得到相同随机数,使x_data,y_data对应的起来
np.random.shuffle(x_data)
np.random.seed(116)
np.random.shuffle(y_data)
tf.random.set_seed(116)
# 1.3 生成训练集和测试集
x_train = x_data[:-30]
y_train = y_data[:-30]
x_test = x_data[-30:]
y_test = y_data[-30:]
# 转换x的数据类型,否则后面矩阵相乘会因数据类型不一致报错
x_train = tf.cast(x_train, tf.float32)
x_test = tf.cast(x_test, tf.float32)
# 1.4 配成[输入特征, 标签]对,每次喂一小撮(batch)
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
# 2.1 定义神经网络中所有可训练参数
w1 = tf.Variable(tf.random.truncated_normal([4, 3], stddev=0.1, seed=1))
b1 = tf.Variable(tf.random.truncated_normal([3], stddev=0.1, seed=1))
# 定义超参数及画图用的两个存数据的空列表
lr = 0.1
train_loss_results = []
test_acc = []
epoch = 500
loss_all = 0 # 每轮训练分120/32=4个step, loss_all用于记录四个step生成的loss和
# 3.1 参数优化,嵌套循环迭代,with结构更新参数,显示当前loss
for epoch in range(epoch): # 数据集级别迭代
for step, (x_train, y_train) in enumerate(train_db): # batch级别迭代
with tf.GradientTape() as tape: # 记录梯度信息
y = tf.matmul(x_train, w1) + b1
y = tf.nn.softmax(y)
y_ = tf.one_hot(y_train, depth=3)
loss = tf.reduce_mean(tf.square(y_ - y))
loss_all += loss.numpy() # 将计算出的tf格式的loss转为numpy格式
grads = tape.gradient(loss, [w1, b1])
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
print("Epoch{}, loss:{}".format(epoch, loss_all / 4))
train_loss_results.append(loss_all / 4)
loss_all = 0
# 4.1 计算当前参数前向传播后的准确率,显示当前acc
total_correct, total_number = 0, 0 # 预测对的个数,测试样本总数
for x_test, y_test in test_db:
# 使用更新后的参数进行预测
y = tf.matmul(x_test, w1) + b1
y = tf.nn.softmax(y)
pred = tf.argmax(y, axis=1) # 返回y中最大值的索引,代表预测的分类
pred = tf.cast(pred, dtype=y_test.dtype)
correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32) # 值相同为1,反之为0;并把bool转换为int32
correct = tf.reduce_sum(correct) # 将每个batch的correct数加起来
total_correct += int(correct)
total_number += x_test.shape[0] # 样本总数即x_test的行数
acc = total_correct / total_number
test_acc.append(acc)
print("Test_acc:", acc)
print("-------------------------------")
# 5.1 acc/loss可视化
plt.title('Acc Curve')
plt.xlabel('Epoch')
plt.ylabel('Acc')
plt.plot(test_acc, label="$Accuracy$") # 逐点画出test_acc值并连线
plt.legend()
plt.show()
plt.title('Loss Function Curve')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.plot(train_loss_results, label="$Loss$") # 逐点画出test_acc值并连线
plt.legend()
plt.show()
神经网络优化
1.预备知识
tf.where(条件语句,真返回A,假返回B)#判断条件语句是否为真,是真的返回A假的返回B
np.random.RandomState.rand(维度) # 返回[0,1)之间的随机数
np.vstack(数组1,数组2) # 将两个数组按垂直方向叠加
np.mgrid[起始值:结束值:步长,起始值:结束值:步长,....] #返回若干组维度相同的等差数组
x.ravel[数组] #将数组变为一维数组
np.c_[数组1,数组2,...] #使返回的间隔数值点配对2.复杂度学习率
#可以先用较大的学习率,快速找到较优解,然后逐渐减小学习率,使模型在训练后期稳定
#指数衰减学习率= 初试学习率*学习率衰减率^(当前轮数/多少轮衰减一次)
epoch = 40
LR_BASE = 0.2
LR_DECAY = 0.99
LR_STEP = 1
for epoch in range(epoch)
lr = LR_BASE*LR_DECAY ** (epoch/LR_STEP)
with tf.GradientTape() as tape:
loss = tf.square(w + 1)
grads = tape.gradient(loss,w)
w.assign_sub(lr * grads)
print("After %s epoch,w is %f,loss is %f,lr is %f" % (epoch, w.numpy(), loss,lr))3.激活函数
#激活函数(Activation Function),就是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。
#介绍的激活函数有:sigmoid函数, Relu函数, Leaky Relu函数
tf.nn.sigmoid(x)
tf.nn.relu(x)
tf.nn.leaky_relu(x) 4.损失函数
#损失函数是预测值与已知答案的差距
#主要三种方法:MSE(均分误差),自定义,CE(交叉熵)。
loss_mse= tf.reduce_mean(tf.square(y_-y)) # MSE
tf.losses.categorical_crossentropy(y_,y) #CE:表示两个概率分布之间的距离
c1=tf.losses.categorical_crossentropy([1,0],[0.6,0.4]) #c1=0.510
c2=tf.losses.categorical_crossentropy([1,0],[0.8,0.2]) #c2=0.223
#C1>C2 C2更准
tf.nn.softmax_cross_entropy_with_logits(y_,y) # 输出先过softmax函数,在计算损失函数。
#softmax函数将k个数值按照数字大小的比例转化为k个相加为一的数值 例如[1,2,3,4]经过计算后得出[0.1,0.2,0.3,0.4]
5.缓解过拟合
#欠拟合:对现有数据集学习不彻底
#过拟合:对现有当前数据拟合太好了,但对新的数据难以作出正确判断
#正则化缓解过拟合
loss=loss(y与y_)+REGULARIZER*loss(w)
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
#读入数据/标签 生成x_train y_train
df=pd.read_csv("dot.csv")
x_data=np.array(df[['x1','x2']])
y_data=np.array(df['y_c'])
x_train=np.vstack(x_data).reshape(-1,2)#-1是任意行数
y_train=np.vstack(y_data).reshape(-1,1)
Y_c=[['red' if y else 'blue']for y in y_train]
x_train=tf.cast(x_train,tf.float32)
y_train=tf.cast(y_train,tf.float32)
train_db=tf.data.Dataset.from_tensor_slices((x_train,y_train)).batch(32)
w1=tf.Variable(tf.random.normal([2,11]),dtype=tf.float32)
b1=tf.Variable(tf.constant(0.01,shape=[1]))
w2=tf.Variable(tf.random.normal([11,1]),dtype=tf.float32)
b2=tf.Variable(tf.constant(0.01,shape=[1]))
lr=0.005
epoch=800
for epoch in range(epoch):
for step,(x_train,y_train) in enumerate(train_db):
with tf.GradientTape() as tape:
h1=tf.matmul(x_train,w1)+b1
h1=tf.nn.relu(h1)
y=tf.matmul(h1,w2)+b2
#采用均方误差
loss=tf.reduce_mean(tf.square(y_train-y))
variables=[w1,b1,w2,b2]
grads=tape.gradient(loss,variables)
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
if epoch % 20 == 0:
print('epoch',epoch,'loss',float(loss))
xx,yy=np.mgrid[-3:3:.1,-3:3:.1] #将xx,yy拉直,并合并配对为二维张量,生成二位坐标点
grid=np.c_[xx.ravel(),yy.ravel()]
grid=tf.cast(grid,tf.float32)
probs=[]
for x_test in grid:
h1=tf.matmul([x_test],w1)+b1
h1=tf.nn.relu(h1)
y=tf.matmul(h1,w2)+b2
probs.append(y)
x1=x_data[:,0]#取第0列给x1
x2=x_data[:,1]#取第1列给x2
probs=np.array(probs).reshape(xx.shape)
plt.scatter(x1,x2,color=np.squeeze(Y_c))
plt.contour(xx,yy,probs,levels=[.5])
plt.show()
6.优化器
# 优化器
# wt+1=wt-lr*(loss对wt求导)
#SGD 常用的梯度下降法
w1.assign_sub(lr*grads[0])
b1.assign_sub(lr*grads[1])
#SGDM 在SGD基础上增加一阶动量
#mt=β*mt-1 +(1-β)*gt
m_W,m_b=0,0
beta=0.9
m_w = beta*m_w + (1-beta) * grads[0]
m_b = beta*m_b + (1-beta) * grads[1]
w1.assign_sub(lr*m_W)
b1.assign_sub(lr*m_b)
#Adagrad 在SGD基础上增加 二阶动量
m_W,m_b=0,0
v_w += tf.square(grads[0])
v_b += tf.square(grads[1])
w1.assign_sub(lr* grads[0] / tf.sqrt(v_w))
b1.assign_sub(lr* grads[1] / tf.sqrt(v_b))
#RMSProp SGD基础上增加二阶动量
#mt=gt vt=β * vt-1 + (1-β)*gt^2
v_W,v_b=0,0
beta=0.9
v_w = beta*v_w + (1-beta) * tf.square(grads[0])
v_b = beta*v_b + (1-beta) * tf.square(grads[1])
w1.assign_sub(lr* grads[0] / tf.sqrt(v_w))
b1.assign_sub(lr* grads[1] / tf.sqrt(v_b))
#Adam 同时结合SGDM一阶动量和RMSProp二阶动量
m_W,m_b=0,0
v_W,v_b=0,0
beta1,beta2=0.9 , 0.999
delta_w,delta_b = 0 , 0
global_step = 0
m_w = beta*m_w + (1-beta) * grads[0]
m_b = beta*m_b + (1-beta) * grads[1]
v_w = beta*v_w + (1-beta) * tf.square(grads[0])
v_b = beta*v_b + (1-beta) * tf.square(grads[1])
m_w_correction = m_w +(1- tf.pow (beta1, int(global_step)))
m_b_correction = m_b +(1- tf.pow (beta1, int(global_step)))
v_w_correction = v_w +(1- tf.pow (beta2, int(global_step)))
v_w_correction = v_w +(1- tf.pow (beta2, int(global_step)))
w1.assign_sub(lr * m_w_correction / tf.sqrt(v_w_correction))
b1.assign_sub(lr * m_b_correction / tf.sqrt(v_b_correction))
网络神经八股
1.搭建网络神经八股
#六步法: import 、 train,test 、 model=tf.keras.models.Sequential、 model.compile、model.fit、 model.summary
tf.keras.layers.Flatten() #拉直层
tf.keras.layels.Dense(神经元个数,activation="激活函数",kernel_regularize=哪种正则化)#全连接层
tf.keras.layers.Conv2D(filters=卷积核个数,kernel_size=卷积核尺寸,
strides=卷积步长,padding="vaild"or"same")
tf.keras.layers.LSTM()# LSTM层
model.compile(optimizer = 优化器,
loss = 损失函数
metrics=["准确率"])
#精准度可选择:'accuracy':y_和y都是数值
'categorical_accuracy':y_和y都是独热码
#'sparse_categorical_accuracy':y_是数值,y是独热码
model.fit(训练集的输入特征,训练集的标签,
batch_size=, epoch=,
validation_data=(测试集的输入特征,测试集的标签),
validation_split=从训练集划分多少比例给测试集,
validation_freq=多少次epoch测试一次)
model.summary()
2.搭建网络八股class
class MyModel(Model):# 继承了model类
def_init_(self):
super(MyModel, self)._init_()
def call(self,x):
teturn y
model=MyModel()
class IrisModel(Model):
def_init_(self):
super(IrisModel, self)._init_()
self.d1=Dense(3)
def call(self,x):
y=self.d1(x)
teturn y
model = IrisModel()3.MNIST数据集
#导入MNIST数据集:
import tensorflow as tf
from matplotlib import pyplot as plt
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 可视化训练集输入特征的第一个元素
plt.imshow(x_train[0], cmap='gray') # 绘制灰度图
plt.show()
# 打印出训练集输入特征的第一个元素
print("x_train[0]:\n", x_train[0])
# 打印出训练集标签的第一个元素
print("y_train[0]:\n", y_train[0])
# 打印出整个训练集输入特征形状
print("x_train.shape:\n", x_train.shape)
# 打印出整个训练集标签的形状
print("y_train.shape:\n", y_train.shape)
# 打印出整个测试集输入特征的形状
print("x_test.shape:\n", x_test.shape)
# 打印出整个测试集标签的形状
print("y_test.shape:\n", y_test.shape)
#用Squential的方法
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
#用类实现
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras import Model
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class MnistModel(Model):
def __init__(self):
super(MnistModel, self).__init__()
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.flatten(x)
x = self.d1(x)
y = self.d2(x)
return y
model = MnistModel()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
网络八股扩展
1.搭建网络八股总览
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train,y_train),(x_test,y_test)= mnist.load_data()
x_train,x_test=x_train/255.0,x_test/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),# 拉直
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10,activation='softmax')
])
model.compile(optimizer='adam', # 优化器
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])#from_logits询问是否原始输出
model.fit(x_train,y_train,batch_size=32,epoch=5,validation_data=(x_test,y_test),validation_freq=1)
model.summary() #显示神经网络模型的结构和参数统计信息。2.自制数据集
def generateds(path, txt): #给入路径和文本
f= open( txt,'r')
contents= f.readlines()
f.close()
x, y_ =[], []
for content in contents:
value = content.split() #空格处做分割得出照片名和照片标签
img_path = path +value[0] #路径+照片名
img= Image.open(img_path) #打开照片
img= np.array(img.convert('L')) #照片改为八位像素黑白,并变为数组
img= img/255. #数据归一化
x.append(img)
y_.append(value[1])
print('loading:'+content)
x= np.array(x)
y= np.array(y)
y_=y_.astype(np.int64)
return x,y_3.数据增强
#数据增强(增大数据量)
from tensorflow.keras.preprossing.image import IamgeDataGenerator
image_gen_train=tf.keras.preprocessing.image.ImageDataGenerator(
rescale=所有数据将乘以该数据
rotation_range=随机旋转角度数范围
width_shift_range=随机宽度偏移量
height_shift_range=随机高度偏移量
水平翻转:horizontal_flip=是否随机水平翻转
随机缩放: zoom_range=随机缩放的范围[1-n,1+n] )
image_gen_train.fit(x_train) #fit需要输入四维数据
4.断点续训
#断点续训 存取模型
#读取模型:
#load_weights(路径文件名)
例:
checkpoint_save_path= "./checkpoint/mnist.ckpt" #先定义出存放模型的路径和文件名 为ckpt文件 同步生产索引表
if os.path.exists(checkpoint_save_path + '.index'): #判断是否有索引表
print('-------------load the model--------')
model.load_weights(checkpoint_save_path) # 读取
#保存模型
tf.keras.callbacks.ModelCheckpoint(
filepath=路径文件名,
save_weight_only=True/False,
save_best_only=True/False)
history=model.fit(callbacks=[cp_callback])
例:
cpcallback=tf.keras.callback.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=Ture,
save_best_only=True)
history= model.fit(x_train,y_train,batch_size=32,epochs=5,
validation_data=(x_test,y_test),validation_freq=1,
callbacks=[cp_callback])5.参数提取
#参数提取,把参数存入文本
#在程序末端加入
model.trainable_variables 返回模型中可训练的参数
np.set_printoptions(threshold=超过多少省略显示)# np.inf表示无限放大
np.set_printoptions(threshold=np.inf) # np.inf表示无限大
#可以直接print 但是直接print中间数据会被省略号代替
print(model.trainable_variables)
file=open('./weights.txt','w')
for x in model.trainable_variables:
file.write(str(v.name)+'\n')
file.write(str(v.shape)+'\n')
file.write(str(v.numpy())+'\n')
file.close
6.acc&loss可视化
#将准确率上升损失函数下降可视化出来
#history=model.fit(训练集的输入特征,训练集的标签,
# batch_size=, epoch=,
# validation_data=(测试集的输入特征,测试集的标签),
# validation_split=从训练集划分多少比例给测试集,
# validation_freq=多少次epoch测试一次)
#model.fit计算中记录:
#训练集loss: loss
#测试集loss: val_loss
#训练集准确率: sparse_categorical_accuracy
#测试集准确率: val_sparse_categorical_accuracy
#可以用hhistory.history提取出
acc=history.history['sparse_categorical_accuracy']
val_acc=history.history['val_sparse_categorical_accuracy']
loss=history.history['loss']
val_loss=history.history['val_loss']
#加入画图模块
from matplotlib import pyplot as plt
plt.subplot(1,2,1) #将图像分为一行两列 画出第一列
plt.plot(acc,lable='Training Accuracy') #画出acc 和val_acc数据
plt.plot(val_acc,lable='Validation Accuracy')
plt.title('Training and Validation Accuracy') #画出图标题
plt.legent() #画出图例
plt.subplot(1,2,2)
plt.plot(loss,lable='Training loss')
plt.plot(val_loss,lable='Validation loss')
plt.title('Training and Validation loss')
plt.legent()
plt.show()
7.给图识物
#predict(输入特征,batch_size=整数)
model=tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10,activation='sotfmax')])
model.load_weights(model_save_path) #加载参数
result=model.predict(x_predict) #预测结果
from PIL import Image
import numpy as np
import tensorflow as tf
model_save_path = './checkpoint/mnist.cspt'
model=tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10,activation='sotfmax')])
model.load_weights(model_save_path) #加载参数
preNum = int(imput("input the number of test pictures:"))#询问要执行多少次图像识别任务
for i in range(preNum):
image_path = input("the path of test picture:")
imge = Image.open(image_path)
img=img.resize((28,28),Image.ANTIALIAS) #28行28列
img_arr=np.array(img.convet('L')) #转换为灰度图
img_arr = 255-img_arr #白底黑字换为黑底白字 (颜色取反)
img_arr=img_arr/255.0
x_predict=img_arr(tf.newaxis,...) #增加一个维度
result= model.predict(x_predict)
pred=tf.argmax(result,axis=1)
print('\n')
tf.print(pred)
卷积神经网络
是一种有效提取图像特征的方法
借助卷积核提取特征后,送入全连接网络 主要模块有:
卷积,批标准化,激活,池化,全连接 CBAPD
1.感受野
感受野:卷积神经网络各输出特征图中的每个像素点,在原始输入图片上映射区域的大小。
2.TF描述卷积计算层
tf.keras.layers.Conv2D(
filters=卷积核个数
kernel_size=卷积核尺寸,横纵向相同写步长整数,或(核高h,核宽w)
strides=滑动步长,横纵向相同写步长整数,或(纵向步长h,横向步长w),默认是1
padding="same or valid",使用全零填充是same不使用是valid
activation="relu"or"sigmoid"or"tanh"or"softmax"等
input_shape=(高,宽,通道数) 输入特征图维度,可 省略
)
model=tf.keras.Sequential([
Conv2D(6,5,padding='valid',activation='sigmoid'),
MaxPool2D(2,2),
Conv2D(6,(5,5),padding='valid',activation='sigmoid'),
MaxPool2D(2,(2,2)),
Conv2D(filters=6,kernel_size=(5,5),padding='valid',activation='signoid'),
MaxPool2D(pool_size=(2,2),strides=2),
Flatten(),
Dense(10,activation='softmax')
])3. 批标准化
把偏移的数据拉回0附近(使数据符合0均值,1为标准差的分布)
tf.keras.layers.BatchNormalization()
model=tf.keras.models.Sequential([
Conv2D(filters=6,kernel_size=(5,5),padding='same'),#卷积层
BatchNormalization(), #BN层
Activation('relu'), #激活层
MaxPool2D(pool_size=(2,2),strides=2,padding='same'), #池化层
Dropout(0.2), #dropout层
])4.池化
用于减少特征数据量,最大池化可以提取图片纹理,均值池化可以保留背景特征。
TF描述池化
tf.keras.layers.MaxPool2D(
pool_size=池化核尺寸, #正方形写核长整数,或(核高h,核宽w)
strides=池化步长,#步长整数,或(纵向步长h,横向步长w),默认为pool_size
padding='valid'or'same'#使用全零填充是“same”不使用是valid
)
tf.keras.layers.AveragePooling2D(
pool_size=池化核尺寸,
strides=池化步长
padding='valid'or'same'
)
model=tf.keras.models.Sequential([
Conv2D(filters=6,kernel_size=(5,5),padding='same'),#卷积层
BatchNormalization(), #BN层
Activation('relu'), #激活层
MaxPool2D(pool_size=(2,2),strides=2,padding='same'), #池化层
Dropout(0.2), #dropout层
])5.舍弃
在神经网络计算时,将一部分神经元按照一定概率从神经网络中暂时舍弃。神经网络使用时,被舍弃的神经元恢复连接。
tf.keras.layers.Dropout(舍弃的概率)#随机舍弃神经元
model=tf.keras.models.Sequential([
Conv2D(filters=6,kernel_size=(5,5),padding='same'),#卷积层
BatchNormalization(), #BN层
Activation('relu'), #激活层
MaxPool2D(pool_size=(2,2),strides=2,padding='same'), #池化层
Dropout(0.2), #dropout层
])6.CIFAR10数据集
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
np.set_printoptions(threshold-np.inf)
cifar10 = tf.keras.datesets.cifar10
(x_train,y_train),(x_test,y_test) = cifar.load_data()
#可视化训练集输入特征的第一个元素
plt.imshow(x_train[0])
plt.show()
#打印出训练集输入特征的第一个元素
print("x_train[0]:\n",x_train[0])
#打印出训练集标签的第一个元素
print("y_train[0]:\n",y_train[0])
#打印出整个训练集输入特征形状
print("x_train.shape:\n",x_train.shape)
#打印出整个训练集标签的形状
print("y_train.shape:\n",y_train.shape)
#打印出整个测试集输入特征的形状
print("x_test.shape:\n",x_test.shape)
#打印出整个测试集标签的形状
print("y_test.shape:\n",y_test.shape)7. 卷积神经网络搭建
class Baseline(Model):
def _init_(self):
super(Baseline, self)._init_()
self.c1=Conv2D(filters=6 , kernel_size=(5,5), padding='same')
self.b1=BatchNormalization()
self.a1=Activation('relu')
self.p1=MaxPool2D(pool_size=(2,2),strides=2,padding='same')
self.d1=Dropout(0.2)
self.flatten=Flatten()
self.f1=Dense(128,activation='relu')
self.d2=Dropout(0.2)
self.f2=Dense(10,activation='softmax')
def call(self,x):
x=self.c1(x)
x=self.b1(x)
x=self.a1(x)
x=self.p1(x)
x=self.d1(x)
x=self.flatten(x)
x=self.f1(x)
x=self.d2(x)
y=self.f2(x)
return y8.LeNet
两层卷积,三层全连接
class LeNet5(Model):
def _init_(self):
super(LeNet5,self)._init_()
self.c1=Conv2D(filters=6,kernel_size=(5,5), #6个5*5的卷积核
activation='sigmoid')
self.p1=MaxPool2D(pool_size=(2,2),strides=2)
self.c2=Conv2D(filters=16,kernel_size=(5,5),
activation='sigmoid')
self.p2=MaxPool2D(pool_size=(2,2),strides=2)
self.flatten= Flatten()
self.f1=Dense(120,activation='sigmoid')
self.f2=Dense(84,activation='sigmoid')
self.f3=Dense(10,activation='softmax')9.AlexNet
五层卷积,三层全连接
class AlexNet8(Model):
def _init__(self):
super(AlexNet8,self). _init_()
self.c1=Conv2D(filters=96,kernel_size=(3,3))
self.b1=BatchNormalization()
self.a1=Activation('relu')
self.p1=MaxPool2D(pool_size=(3,3),strides=2)
self.c2=Conv2D(filters=256,kernel_size=(3,3))
self.b2=BatchNormalization()
self.a2=Activation('relu')
self.p2=MaxPool2D(pool_size=(3,3),strides=2)
self.c3=Conv2D(filters=384,kernel_size=(3,3),padding='same',activation='relu')
self.c4=Conv2D(filters=384,kernel_size=(3,3),padding='same',activation='relu')
self.c5=Conv2D(filters=256,kernel_size=(3,3),padding='same',activation='relu')
self.p3=MaxPool2D(pool_size=(3,3),strides=2)
self.flatten=Flatten()
self.f1=Dense(2048,activation='relu')
self.d1=Dropout(0.5)
self.f2=Dense(2048,activation='relu')
self.d2=Dropout(0.5)
self.f3=Dense(10,activation='softmax')
10.VGGNet
class VGG16(Model):
def __init__(self):
super(VGG16, self).__init__()
self.c1 = Conv2D(filters=64, kernel_size=(3, 3), padding='same') # 卷积层1
self.b1 = BatchNormalization() # BN层1
self.a1 = Activation('relu') # 激活层1
self.c2 = Conv2D(filters=64, kernel_size=(3, 3), padding='same', )
self.b2 = BatchNormalization() # BN层1
self.a2 = Activation('relu') # 激活层1
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d1 = Dropout(0.2) # dropout层
self.c3 = Conv2D(filters=128, kernel_size=(3, 3), padding='same')
self.b3 = BatchNormalization() # BN层1
self.a3 = Activation('relu') # 激活层1
self.c4 = Conv2D(filters=128, kernel_size=(3, 3), padding='same')
self.b4 = BatchNormalization() # BN层1
self.a4 = Activation('relu') # 激活层1
self.p2 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d2 = Dropout(0.2) # dropout层
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b5 = BatchNormalization() # BN层1
self.a5 = Activation('relu') # 激活层1
self.c6 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b6 = BatchNormalization() # BN层1
self.a6 = Activation('relu') # 激活层1
self.c7 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b7 = BatchNormalization()
self.a7 = Activation('relu')
self.p3 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d3 = Dropout(0.2)
self.c8 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b8 = BatchNormalization() # BN层1
self.a8 = Activation('relu') # 激活层1
self.c9 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b9 = BatchNormalization() # BN层1
self.a9 = Activation('relu') # 激活层1
self.c10 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b10 = BatchNormalization()
self.a10 = Activation('relu')
self.p4 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d4 = Dropout(0.2)
self.c11 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b11 = BatchNormalization() # BN层1
self.a11 = Activation('relu') # 激活层1
self.c12 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b12 = BatchNormalization() # BN层1
self.a12 = Activation('relu') # 激活层1
self.c13 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b13 = BatchNormalization()
self.a13 = Activation('relu')
self.p5 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d5 = Dropout(0.2)
self.flatten = Flatten()
self.f1 = Dense(512, activation='relu')
self.d6 = Dropout(0.2)
self.f2 = Dense(512, activation='relu')
self.d7 = Dropout(0.2)
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p1(x)
x = self.d1(x)
x = self.c3(x)
x = self.b3(x)
x = self.a3(x)
x = self.c4(x)
x = self.b4(x)
x = self.a4(x)
x = self.p2(x)
x = self.d2(x)
x = self.c5(x)
x = self.b5(x)
x = self.a5(x)
x = self.c6(x)
x = self.b6(x)
x = self.a6(x)
x = self.c7(x)
x = self.b7(x)
x = self.a7(x)
x = self.p3(x)
x = self.d3(x)
x = self.c8(x)
x = self.b8(x)
x = self.a8(x)
x = self.c9(x)
x = self.b9(x)
x = self.a9(x)
x = self.c10(x)
x = self.b10(x)
x = self.a10(x)
x = self.p4(x)
x = self.d4(x)
x = self.c11(x)
x = self.b11(x)
x = self.a11(x)
x = self.c12(x)
x = self.b12(x)
x = self.a12(x)
x = self.c13(x)
x = self.b13(x)
x = self.a13(x)
x = self.p5(x)
x = self.d5(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d6(x)
x = self.f2(x)
x = self.d7(x)
y = self.f3(x)
return y11.InceptionNet

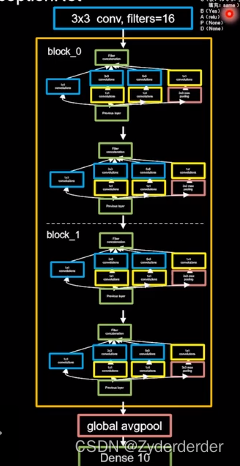
class Inception10(Model):
def __init__(self, num_blocks, num_classes, init_ch=16, **kwargs):
super(Inception10, self).__init__(**kwargs)
self.in_channels = init_ch
self.out_channels = init_ch
self.num_blocks = num_blocks
self.init_ch = init_ch
self.c1 = ConvBNRelu(init_ch)
self.blocks = tf.keras.models.Sequential()
for block_id in range(num_blocks):
for layer_id in range(2):
if layer_id == 0:
block = InceptionBlk(self.out_channels, strides=2)
else:
block = InceptionBlk(self.out_channels, strides=1)
self.blocks.add(block)
# enlarger out_channels per block
self.out_channels *= 2 #通道数加倍
self.p1 = GlobalAveragePooling2D()
self.f1 = Dense(num_classes, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
model = Inception10(num_blocks=2, num_classes=10)12.ResNet
发现 50层的高于20层的错误率 单纯堆叠会使网络模型退化 前面的特征直接接到后面 对应元素相加
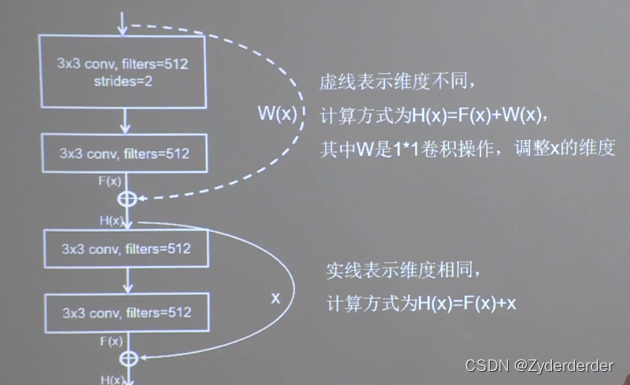
class ResnetBlock(Model):
def _init_(self,filters,strides=1,residual_path=False):
super(ResnetBlock,self). _init_()
self.filters=filters
self.strides=strides
self.residual_path=residual_path
self.c1=Conv2D(filters,(3,3),strides=strides,padding='same',use_bias=False)
self.b1=BatchNormalization()
self.a1=Activation('relu')
self.c2=Conv2D(filters,(3,3),strides=1,padding='same',use_bias=False)
self.b2=BatchNormalization()
if residual_path:
self.down_c1=Conv2D(filters,(1,1),strides=strides,padding='same',
use_bias=False)
self.down_b1=BatchNormalization()
self.a2=Activation('relu')
def call(self,inputs):
residual = inputs
x=self.c1(inputs)
x=self.b1(x)
x=self.a1(x)
x=self.c2(x)
y=self.b2(x)
if self.residual_path:
residual = self.down_c1(inputs)
residual = self.down_b1(residual)
out= self.a2(y+residual)
return out
class ResNet18(Model):
def _init_(self,block_list,initial_filters=64):
super(ResNet18,self). _init_()
self.num_blocks=len(block_list)
self.block_list=block_list
self.out.filters=initial_filters
self.c1=Conv2D(self.out_filters,(3,3),strides=1,padding='same',use_bias=False,
kernel_initializer ='he_normal')
self.b1=tf.keras.layers.BatchNormalization()
self.a1=Activation('relu')
self.blocks=tf.keras.models.Sequential()
#构建ResNet网络构建
for layer_id in range(block_list[block_id]):#第几个卷积层
for layer_id in range(block_list[block_id]):
if block_id != 0 and layer_id == 0:
block = ResnetBlock(self.out_filters, strides=2, residual_path=True)
else:
block = ResnetBlock(self.out_filters,residual_path=False)
self.blocks.add(block)
self.out_filters*=2
self.p1=tf.keras.layers.GlobalAveragePooling2D()
self.f1=tf.keras.layers.Dense(10)
def call(self,inputs):
x = self.c1(inputs)
x = self.b1(x)
x=self.a1(x)
x=self.blocks(x)
x=self.p1(x)
y=self.f1(x)
return y
model= ResNet18([2,2,2,2])
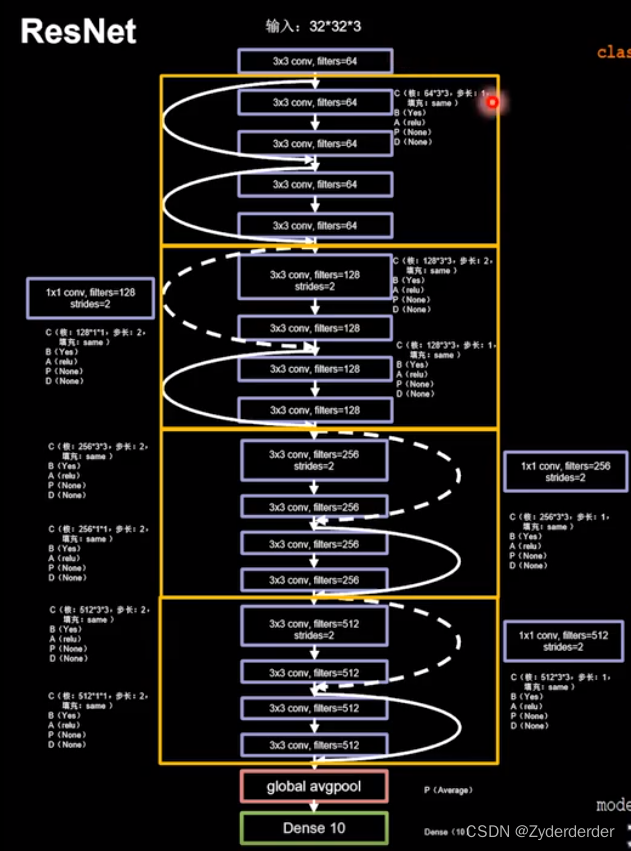 12.小结
12.小结
LeNet:卷积网络开篇之作,共享卷积核,减少网络参数
VGGNet:小尺寸卷积核减少参数,网络结构规整,适合并行加速
AlexNet:使用relu激活函数,提升训练速度,使用Drpout,缓解过拟合
InceptionNet:一层内使用不同尺寸卷积核,提升感知力使用批标准化,缓解梯度消失
ResNet:层间残差跳连,引入前方信息,缓解模型退化,使神经网络层加深成为可能
循环神经网络
借助循环核提取时间特征后,送入全连接网络
1.循环核
参数时间共享,循环曾提取时间信息。循环核具有记忆力,通过不同时刻的参数共享,实现了对时间序列的信息提取
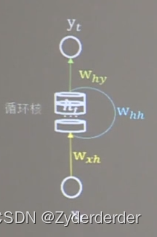

记忆体内存储着每个时刻的状态信息ht,当前时刻循环核的输出特征yt
2.TF描述循环计算层
tf.keras.layers.SimpleRNN(记忆体个数,activation='激活函数',
return_sequences=是否每个时刻输出ht到下一层)
activation='激活函数'(不写默认tanh)
return_sequences=True 各时间步输出ht
return_sequences=False 仅最后时间步输出ht(默认)
API要求送入数据是三维
【送入样品数,循环核时间展开步数,每个时间步输入特征个数 】
3.字母预测
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dense, SimpleRNN
import matplotlib.pyplot as plt
import os
input_word = "abcde"
w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4} # 单词映射到数值id的词典
id_to_onehot = {0: [1., 0., 0., 0., 0.], 1: [0., 1., 0., 0., 0.], 2: [0., 0., 1., 0., 0.], 3: [0., 0., 0., 1., 0.],
4: [0., 0., 0., 0., 1.]} # id编码为one-hot
x_train = [id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']],
id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']]]
y_train = [w_to_id['b'], w_to_id['c'], w_to_id['d'], w_to_id['e'], w_to_id['a']]
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
# 使x_train符合SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。
# 此处整个数据集送入,送入样本数为len(x_train);输入1个字母出结果,循环核时间展开步数为1; 表示为独热码有5个输入特征,每个时间步输入特征个数为5
x_train = np.reshape(x_train, (len(x_train), 1, 5))
y_train = np.array(y_train)
model = tf.keras.Sequential([
SimpleRNN(3),
Dense(5, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/rnn_onehot_1pre1.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
monitor='loss') # 由于fit没有给出测试集,不计算测试集准确率,根据loss,保存最优模型
history = model.fit(x_train, y_train, batch_size=32, epochs=100, callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w') # 参数提取
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
loss = history.history['loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.title('Training Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.title('Training Loss')
plt.legend()
plt.show()
############### predict #############
preNum = int(input("input the number of test alphabet:"))
for i in range(preNum):
alphabet1 = input("input test alphabet:")
alphabet = [id_to_onehot[w_to_id[alphabet1]]]
# 使alphabet符合SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。此处验证效果送入了1个样本,送入样本数为1;输入1个字母出结果,所以循环核时间展开步数为1; 表示为独热码有5个输入特征,每个时间步输入特征个数为5
alphabet = np.reshape(alphabet, (1, 1, 5))
result = model.predict([alphabet])
pred = tf.argmax(result, axis=1)
pred = int(pred)
tf.print(alphabet1 + '->' + input_word[pred])
4.循环计算过程二
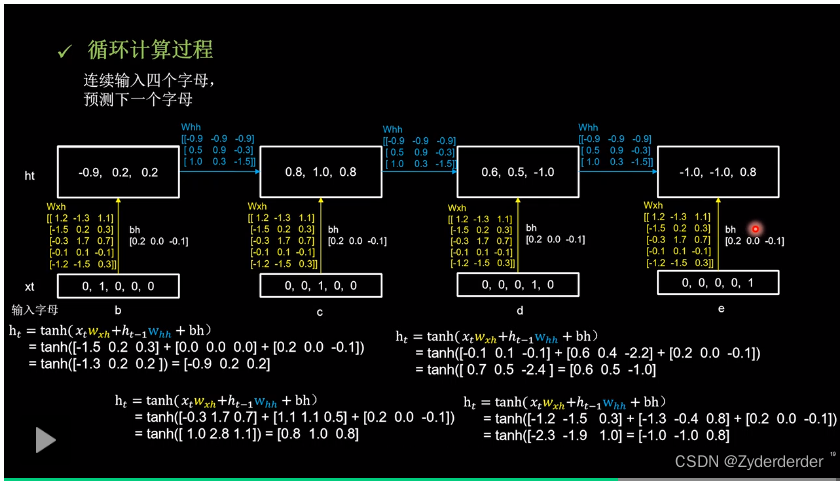
5.连续输入四个字母进行预测
import numpy as np
import tensorflow as tf
import tensorflow.keras.layers import Dense,simpleRNN
import matplotlib.pyplot as plt
import os
input_word="abcde"
w_to_id={'a':0,'b':1,'c':2,'d':3,'e':4}
id_to_onehot={0:[1.,0.,0.,0.,0.],1:[0.,1.,0.,0.,0.],2:[0.,0.,1.,0.,0.],3:[0.,0.,0.,1.,0.],
4:[0.,0.,0.,0.,1.]}
x_train=[
[id_to_onehot[w_to_id['a']], [id_to_onehot[w_to_id['b']], [id_to_onehot[w_to_id['c']], [id_to_onehot[w_to_id['d']],
[id_to_onehot[w_to_id['b']], [id_to_onehot[w_to_id['c']], [id_to_onehot[w_to_id['d']], [id_to_onehot[w_to_id['e']],
[id_to_onehot[w_to_id['c']], [id_to_onehot[w_to_id['d']], [id_to_onehot[w_to_id['e']], [id_to_onehot[w_to_id['a']],
[id_to_onehot[w_to_id['d']], [id_to_onehot[w_to_id['e']], [id_to_onehot[w_to_id['a']], [id_to_onehot[w_to_id['b']],
[id_to_onehot[w_to_id['e']], [id_to_onehot[w_to_id['a']], [id_to_onehot[w_to_id['b']], [id_to_onehot[w_to_id['c']],
]
y_train=w[w_to_id['e'],w_to_id['a'],w_to_id['b'],w_to_id['c'],w_to_id['d']]
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
x_train = np.reshape(x_train, (len(x_train), 4, 5))
y_train = np.array(y_train)
model = tf.keras.Sequential([
SimpleRNN(3),
Dense(5, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/rnn_onehot_1pre1.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
monitor='loss') # 由于fit没有给出测试集,不计算测试集准确率,根据loss,保存最优模型
history = model.fit(x_train, y_train, batch_size=32, epochs=100, callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w') # 参数提取
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
loss = history.history['loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.title('Training Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.title('Training Loss')
plt.legend()
plt.show()
############### predict #############
preNum = int(input("input the number of test alphabet:"))
for i in range(preNum):
alphabet1 = input("input test alphabet:")
alphabet = [id_to_onehot[w_to_id[alphabet1]] for a in alphabet1]
# 使alphabet符合SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。此处验证效果送入了1个样本,送入样本数为1;输入1个字母出结果,所以循环核时间展开步数为1; 表示为独热码有5个输入特征,每个时间步输入特征个数为5
alphabet = np.reshape(alphabet, (1, 4, 5))
result = model.predict([alphabet])
pred = tf.argmax(result, axis=1)
pred = int(pred)
tf.print(alphabet1 + '->' + input_word[pred])
6.Embedding编码
独热码:数据量过大,过于稀疏,映射之间是独立的,没有表现出关联性
Embedding:是一种单词编码方式,用低维向量实现了编码,这种编码通过神经网络训练优化,能表达出单词间的相关性。
tf.keras.layers.Embedding(词汇表大小,编码维度)
编码维度就是用几个数字表达一个单词
要求输入数据是二维【送入样本数,循环核时间展开步数】
7.在字母预测中用Embedding的编码方式
import numpy as np
import tensorflow as tf
import tensorflow.keras.layers import Dense,simpleRNN
import matplotlib.pyplot as plt
import os
input_word="abcde"
w_to_id={'a':0,'b':1,'c':2,'d':3,'e':4}
x_train=[w_to_id['a'],w_to_id['b'],w_to_id['c'],w_to_id['d'],w_to_id['e']]
y_train=[w_to_id['b'],w_to_id['c'],w_to_id['d'],w_to_id['e'],w_to_id['a']]
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
#使x_train符合Embedding输入要求:【送入样本数,循环核时间展开步数】,
#此处整个数据集送入所以送入,送入样本为len(x_train):输入1个字母出结果,循环核时间展开步数为1
x_train = np.reshape(x_train, (len(x_train), 1))
y_train = np.array(y_train)
model = tf.keras.Sequential([
Embedding(5,2),#5行两列的参数矩阵
SimpleRNN(3),
Dense(5, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/rnn_onehot_1pre1.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
monitor='loss') # 由于fit没有给出测试集,不计算测试集准确率,根据loss,保存最优模型
history = model.fit(x_train, y_train, batch_size=32, epochs=100, callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w') # 参数提取
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
loss = history.history['loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.title('Training Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.title('Training Loss')
plt.legend()
plt.show()
############### predict #############
preNum = int(input("input the number of test alphabet:"))
for i in range(preNum):
alphabet1 = input("input test alphabet:")
alphabet = [w_to_id[alphabet1]]
alphabet = np.reshape(alphabet, (1, 1))
result = model.predict([alphabet])
pred = tf.argmax(result, axis=1)
pred = int(pred)
tf.print(alphabet1 + '->' + input_word[pred])8.在连续输入四个字母预测中用Embedding的编码方式
import numpy as np
import tensorflow as tf
import tensorflow.keras.layers import Dense,simpleRNN
import matplotlib.pyplot as plt
import os
input_word="abcdefghijklmnopqrstuvwxyz"
w_to_id={'a':0,'b':1,'c':2,'d':3,'e':4,
'f':5,'g':6,'h':7,'i':8,'j':9,
'k':10,'l':11,'m':12,'n':13,'o':14,
'p':15,'q':16,'r':17,'s':18,'t':19,
'u':20,'v':21,'w':22,'x':23,'y':24,'z':25}
training_set_scaled=[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25]
x_train=[]
y_train=[]
for i in range(4,26):
x_train.append(training_set_scaled[i - 4:i])
y_train.append(training_set_scaled[i])
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
#使x_train符合Embedding输入要求:【送入样本数,循环核时间展开步数】,
#此处整个数据集送入所以送入,送入样本为len(x_train):输入1个字母出结果,循环核时间展开步数为1
x_train = np.reshape(x_train, (len(x_train), 4))
y_train = np.array(y_train)
model = tf.keras.Sequential([
Embedding(26,2),#26行两列的参数矩阵
SimpleRNN(10),#10个记忆体
Dense(26 , activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/rnn_onehot_1pre1.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
monitor='loss') # 由于fit没有给出测试集,不计算测试集准确率,根据loss,保存最优模型
history = model.fit(x_train, y_train, batch_size=32, epochs=100, callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w') # 参数提取
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
loss = history.history['loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.title('Training Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.title('Training Loss')
plt.legend()
plt.show()
############### predict #############
preNum = int(input("input the number of test alphabet:"))
for i in range(preNum):
alphabet1 = input("input test alphabet:")
alphabet = [w_to_id[a] for a in alphabet1]
alphabet = np.reshape(alphabet, (1, 4))
result = model.predict([alphabet])
pred = tf.argmax(result, axis=1)
pred = int(pred)
tf.print(alphabet1 + '->' + input_word[pred])9.RNN实现股票预测
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dropout, Dense, SimpleRNN
import matplotlib.pyplot as plt
import os
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
import math
maotai = pd.read_csv('./SH600519.csv') # 读取股票文件
training_set = maotai.iloc[0:2426 - 300, 2:3].values # 前(2426-300=2126)天的开盘价作为训练集,表格从0开始计数,2:3 是提取[2:3)列,前闭后开,故提取出C列开盘价
test_set = maotai.iloc[2426 - 300:, 2:3].values # 后300天的开盘价作为测试集
# 归一化
sc = MinMaxScaler(feature_range=(0, 1)) # 定义归一化:归一化到(0,1)之间
training_set_scaled = sc.fit_transform(training_set) # 求得训练集的最大值,最小值这些训练集固有的属性,并在训练集上进行归一化
test_set = sc.transform(test_set) # 利用训练集的属性对测试集进行归一化
x_train = []
y_train = []
x_test = []
y_test = []
# 测试集:csv表格中前2426-300=2126天数据
# 利用for循环,遍历整个训练集,提取训练集中连续60天的开盘价作为输入特征x_train,第61天的数据作为标签,for循环共构建2426-300-60=2066组数据。
for i in range(60, len(training_set_scaled)):
x_train.append(training_set_scaled[i - 60:i, 0])
y_train.append(training_set_scaled[i, 0])
# 对训练集进行打乱
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
# 将训练集由list格式变为array格式
x_train, y_train = np.array(x_train), np.array(y_train)
# 使x_train符合RNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。
# 此处整个数据集送入,送入样本数为x_train.shape[0]即2066组数据;输入60个开盘价,预测出第61天的开盘价,循环核时间展开步数为60; 每个时间步送入的特征是某一天的开盘价,只有1个数据,故每个时间步输入特征个数为1
x_train = np.reshape(x_train, (x_train.shape[0], 60, 1))
# 测试集:csv表格中后300天数据
# 利用for循环,遍历整个测试集,提取测试集中连续60天的开盘价作为输入特征x_train,第61天的数据作为标签,for循环共构建300-60=240组数据。
for i in range(60, len(test_set)):
x_test.append(test_set[i - 60:i, 0])
y_test.append(test_set[i, 0])
# 测试集变array并reshape为符合RNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]
x_test, y_test = np.array(x_test), np.array(y_test)
x_test = np.reshape(x_test, (x_test.shape[0], 60, 1))
model = tf.keras.Sequential([
SimpleRNN(80, return_sequences=True),
Dropout(0.2),
SimpleRNN(100),
Dropout(0.2),
Dense(1)
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 损失函数用均方误差
# 该应用只观测loss数值,不观测准确率,所以删去metrics选项,一会在每个epoch迭代显示时只显示loss值
checkpoint_save_path = "./checkpoint/rnn_stock.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
monitor='val_loss')
history = model.fit(x_train, y_train, batch_size=64, epochs=50, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
file = open('./weights.txt', 'w') # 参数提取
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
################## predict ######################
# 测试集输入模型进行预测
predicted_stock_price = model.predict(x_test)
# 对预测数据还原---从(0,1)反归一化到原始范围
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
# 对真实数据还原---从(0,1)反归一化到原始范围
real_stock_price = sc.inverse_transform(test_set[60:])
# 画出真实数据和预测数据的对比曲线
plt.plot(real_stock_price, color='red', label='MaoTai Stock Price')
plt.plot(predicted_stock_price, color='blue', label='Predicted MaoTai Stock Price')
plt.title('MaoTai Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('MaoTai Stock Price')
plt.legend()
plt.show()
##########evaluate##############
# calculate MSE 均方误差 ---> E[(预测值-真实值)^2] (预测值减真实值求平方后求均值)
mse = mean_squared_error(predicted_stock_price, real_stock_price)
# calculate RMSE 均方根误差--->sqrt[MSE] (对均方误差开方)
rmse = math.sqrt(mean_squared_error(predicted_stock_price, real_stock_price))
# calculate MAE 平均绝对误差----->E[|预测值-真实值|](预测值减真实值求绝对值后求均值)
mae = mean_absolute_error(predicted_stock_price, real_stock_price)
print('均方误差: %.6f' % mse)
print('均方根误差: %.6f' % rmse)
print('平均绝对误差: %.6f' % mae)
10.用LSTM实现股票预测

import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dropout, Dense, LSTM
import matplotlib.pyplot as plt
import os
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
import math
maotai = pd.read_csv('./SH600519.csv') # 读取股票文件
training_set = maotai.iloc[0:2426 - 300, 2:3].values # 前(2426-300=2126)天的开盘价作为训练集,表格从0开始计数,2:3 是提取[2:3)列,前闭后开,故提取出C列开盘价
test_set = maotai.iloc[2426 - 300:, 2:3].values # 后300天的开盘价作为测试集
# 归一化
sc = MinMaxScaler(feature_range=(0, 1)) # 定义归一化:归一化到(0,1)之间
training_set_scaled = sc.fit_transform(training_set) # 求得训练集的最大值,最小值这些训练集固有的属性,并在训练集上进行归一化
test_set = sc.transform(test_set) # 利用训练集的属性对测试集进行归一化
x_train = []
y_train = []
x_test = []
y_test = []
# 测试集:csv表格中前2426-300=2126天数据
# 利用for循环,遍历整个训练集,提取训练集中连续60天的开盘价作为输入特征x_train,第61天的数据作为标签,for循环共构建2426-300-60=2066组数据。
for i in range(60, len(training_set_scaled)):
x_train.append(training_set_scaled[i - 60:i, 0])
y_train.append(training_set_scaled[i, 0])
# 对训练集进行打乱
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
# 将训练集由list格式变为array格式
x_train, y_train = np.array(x_train), np.array(y_train)
# 使x_train符合RNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。
# 此处整个数据集送入,送入样本数为x_train.shape[0]即2066组数据;输入60个开盘价,预测出第61天的开盘价,循环核时间展开步数为60; 每个时间步送入的特征是某一天的开盘价,只有1个数据,故每个时间步输入特征个数为1
x_train = np.reshape(x_train, (x_train.shape[0], 60, 1))
# 测试集:csv表格中后300天数据
# 利用for循环,遍历整个测试集,提取测试集中连续60天的开盘价作为输入特征x_train,第61天的数据作为标签,for循环共构建300-60=240组数据。
for i in range(60, len(test_set)):
x_test.append(test_set[i - 60:i, 0])
y_test.append(test_set[i, 0])
# 测试集变array并reshape为符合RNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]
x_test, y_test = np.array(x_test), np.array(y_test)
x_test = np.reshape(x_test, (x_test.shape[0], 60, 1))
model = tf.keras.Sequential([
LSTM(80, return_sequences=True),
Dropout(0.2),
LSTM(100),
Dropout(0.2),
Dense(1)
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 损失函数用均方误差
# 该应用只观测loss数值,不观测准确率,所以删去metrics选项,一会在每个epoch迭代显示时只显示loss值
checkpoint_save_path = "./checkpoint/rnn_stock.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
monitor='val_loss')
history = model.fit(x_train, y_train, batch_size=64, epochs=50, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
file = open('./weights.txt', 'w') # 参数提取
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
################## predict ######################
# 测试集输入模型进行预测
predicted_stock_price = model.predict(x_test)
# 对预测数据还原---从(0,1)反归一化到原始范围
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
# 对真实数据还原---从(0,1)反归一化到原始范围
real_stock_price = sc.inverse_transform(test_set[60:])
# 画出真实数据和预测数据的对比曲线
plt.plot(real_stock_price, color='red', label='MaoTai Stock Price')
plt.plot(predicted_stock_price, color='blue', label='Predicted MaoTai Stock Price')
plt.title('MaoTai Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('MaoTai Stock Price')
plt.legend()
plt.show()
##########evaluate##############
# calculate MSE 均方误差 ---> E[(预测值-真实值)^2] (预测值减真实值求平方后求均值)
mse = mean_squared_error(predicted_stock_price, real_stock_price)
# calculate RMSE 均方根误差--->sqrt[MSE] (对均方误差开方)
rmse = math.sqrt(mean_squared_error(predicted_stock_price, real_stock_price))
# calculate MAE 平均绝对误差----->E[|预测值-真实值|](预测值减真实值求绝对值后求均值)
mae = mean_absolute_error(predicted_stock_price, real_stock_price)
print('均方误差: %.6f' % mse)
print('均方根误差: %.6f' % rmse)
print('平均绝对误差: %.6f' % mae)
11.GRU实现股票预测

import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dropout, Dense, GRU
import matplotlib.pyplot as plt
import os
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
import math
maotai = pd.read_csv('./SH600519.csv') # 读取股票文件
training_set = maotai.iloc[0:2426 - 300, 2:3].values # 前(2426-300=2126)天的开盘价作为训练集,表格从0开始计数,2:3 是提取[2:3)列,前闭后开,故提取出C列开盘价
test_set = maotai.iloc[2426 - 300:, 2:3].values # 后300天的开盘价作为测试集
# 归一化
sc = MinMaxScaler(feature_range=(0, 1)) # 定义归一化:归一化到(0,1)之间
training_set_scaled = sc.fit_transform(training_set) # 求得训练集的最大值,最小值这些训练集固有的属性,并在训练集上进行归一化
test_set = sc.transform(test_set) # 利用训练集的属性对测试集进行归一化
x_train = []
y_train = []
x_test = []
y_test = []
# 测试集:csv表格中前2426-300=2126天数据
# 利用for循环,遍历整个训练集,提取训练集中连续60天的开盘价作为输入特征x_train,第61天的数据作为标签,for循环共构建2426-300-60=2066组数据。
for i in range(60, len(training_set_scaled)):
x_train.append(training_set_scaled[i - 60:i, 0])
y_train.append(training_set_scaled[i, 0])
# 对训练集进行打乱
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
# 将训练集由list格式变为array格式
x_train, y_train = np.array(x_train), np.array(y_train)
# 使x_train符合RNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。
# 此处整个数据集送入,送入样本数为x_train.shape[0]即2066组数据;输入60个开盘价,预测出第61天的开盘价,循环核时间展开步数为60; 每个时间步送入的特征是某一天的开盘价,只有1个数据,故每个时间步输入特征个数为1
x_train = np.reshape(x_train, (x_train.shape[0], 60, 1))
# 测试集:csv表格中后300天数据
# 利用for循环,遍历整个测试集,提取测试集中连续60天的开盘价作为输入特征x_train,第61天的数据作为标签,for循环共构建300-60=240组数据。
for i in range(60, len(test_set)):
x_test.append(test_set[i - 60:i, 0])
y_test.append(test_set[i, 0])
# 测试集变array并reshape为符合RNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]
x_test, y_test = np.array(x_test), np.array(y_test)
x_test = np.reshape(x_test, (x_test.shape[0], 60, 1))
model = tf.keras.Sequential([
GRU(80, return_sequences=True),
Dropout(0.2),
GRU(100),
Dropout(0.2),
Dense(1)
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 损失函数用均方误差
# 该应用只观测loss数值,不观测准确率,所以删去metrics选项,一会在每个epoch迭代显示时只显示loss值
checkpoint_save_path = "./checkpoint/rnn_stock.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
monitor='val_loss')
history = model.fit(x_train, y_train, batch_size=64, epochs=50, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
file = open('./weights.txt', 'w') # 参数提取
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
################## predict ######################
# 测试集输入模型进行预测
predicted_stock_price = model.predict(x_test)
# 对预测数据还原---从(0,1)反归一化到原始范围
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
# 对真实数据还原---从(0,1)反归一化到原始范围
real_stock_price = sc.inverse_transform(test_set[60:])
# 画出真实数据和预测数据的对比曲线
plt.plot(real_stock_price, color='red', label='MaoTai Stock Price')
plt.plot(predicted_stock_price, color='blue', label='Predicted MaoTai Stock Price')
plt.title('MaoTai Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('MaoTai Stock Price')
plt.legend()
plt.show()
##########evaluate##############
# calculate MSE 均方误差 ---> E[(预测值-真实值)^2] (预测值减真实值求平方后求均值)
mse = mean_squared_error(predicted_stock_price, real_stock_price)
# calculate RMSE 均方根误差--->sqrt[MSE] (对均方误差开方)
rmse = math.sqrt(mean_squared_error(predicted_stock_price, real_stock_price))
# calculate MAE 平均绝对误差----->E[|预测值-真实值|](预测值减真实值求绝对值后求均值)
mae = mean_absolute_error(predicted_stock_price, real_stock_price)
print('均方误差: %.6f' % mse)
print('均方根误差: %.6f' % rmse)
print('平均绝对误差: %.6f' % mae)















 3360
3360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









