






简介
跳表是一种采用了多级有序链表的数据结构。跳表通过多级索引达到在有序链表中快速跳跃的能力,加速了对于数据的增删改查的效率,保证平均时间复杂度为O(logN)。
图解
有序链表
这里是一个普通的有序链表

链表上的操作一般都与查询效率挂钩,只要确定了节点,那么执行增删改操作都是一次O(1)的
保证链表有序的意义在于,假如我们需要在上述链表中查找元素2,那么当遍历到3时即可确定不存在目标节点,省去了遍历整张链表的时间。但这一操作并非能够显著提升链表的查询效率。可知时间复杂度仍然是O(n)级别的。
在有序数组中,我们为了提升查询效率,通常会引入二分查找的思想,每次缩减一半的查询范围,使得时间复杂度降低至O(logN)。那么在有序链表中是否能套用同样的思路呢。
跳表
跳表完美的解决了这个问题,以O(logN)的空间复杂度为代价,将时间复杂度降低至O(logN)。
这是一个普通的跳表
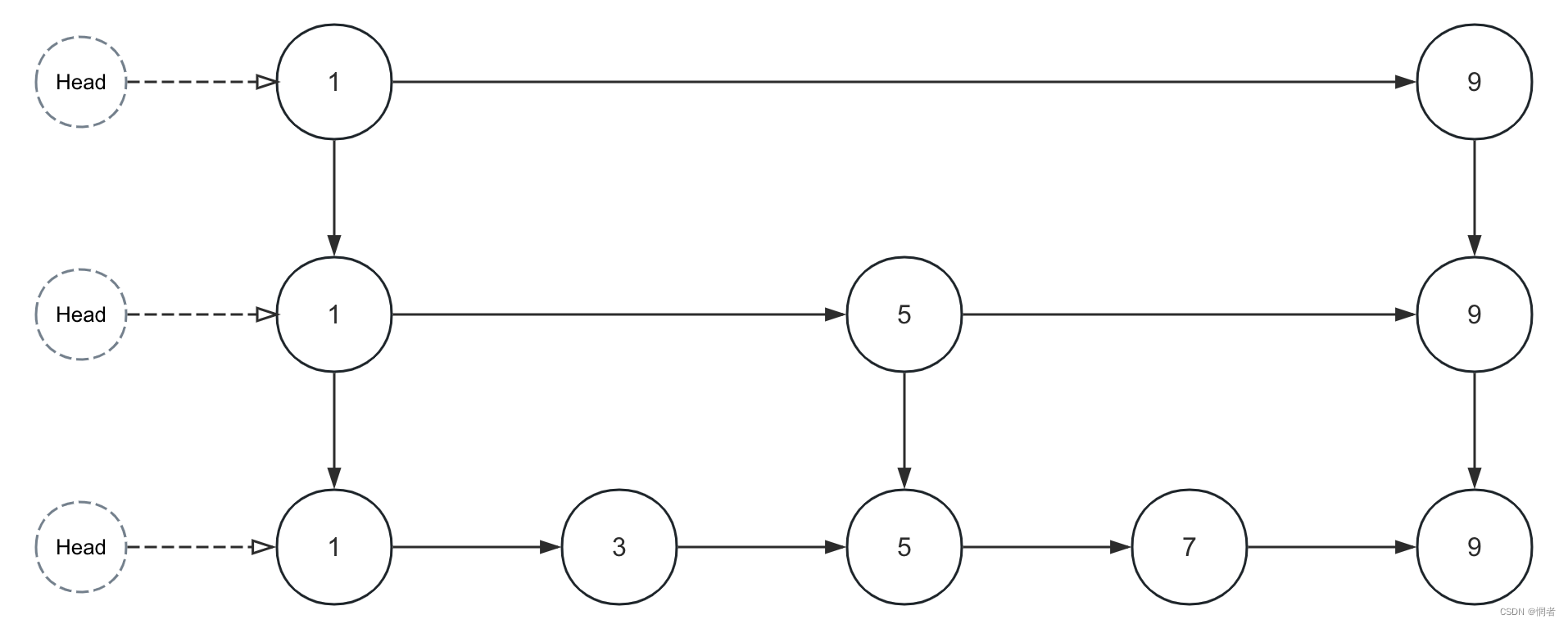
查找
在查找时通常从最上层头节点开始遍历,如果目标节点可能在当前节点和后继节点之间,就迭代到当前节点的下层节点。如果目标节点不可能在当前节点和后继节点之间,那么就向后继节点迭代。
例如,我们要查找7
- 从最上层1开始,通过比对7和9得出7可能出现在1到9中间的,上层未显示的某个节点中,因此需要向下迭代。
- 到达第二层的1,通过对比7和5得出7不出现在1到5中的某个节点,因此向第二层节点1的后继5迭代。
- 到达第二层的5,通过对比7和9确定了可能存在于该区间,向下迭代。
- 到达第三层的5,通过对比5的后继查找到了7。(若此时查找的是6可得出不存在的结论)
插入
通过上述查找过程,我们能够确定节点在最底层链表中所处的位置,可以直接进行插入。如果直接这样进行插入,在数据量变大后,上层索引得不到维护,那么整张跳表会退化为链表(如图)。因此,上层索引是否同样插入,插入几层,这仍然需要解决。

为了解决这个问题,引入了跳表的升级概念,使用一个变量记录当前跳表的层数,每当跳表的元素达到一定阈值时,将跳表进行升级,增加一层。并且在每次插入的过程中,维护每层的索引。
那么插入时到底应该需要维护几层索引?如果直接拉满还是会退化成链表(并且相当占内存)。这个问题最终交由了概率决定。跳表插入时维护的层级数是随机分配的,通过合理的概率设计,可以在大多数情况下避免退化为链表的情况。
通常,跳表的层级分配采用以下方式:
- 每个插入节点有50%的概率提升到更高一层
- 并且在提升后仍然有50%的概率继续提升,不能超过限定的最大层数。
这种概率设计使得每一层的节点数量大约是下一层节点数量的一半。每次向下层迭代大约可以缩小一半的范围,因此可以近似看作是二分查找。
通常我们会定义一个随机层数函数来确定,代码如下
private int randomLevel() { // 插入的层数
int res = 0;
while (res < maxLevel) {
if (Math.random() < 0.5) {
return res;
}
res++;
}
return res;
}
删除
删除操作可视作在查找的基础上增加了原本节点的引用修改。只需要将待删除节点的前驱节点指向后继节点即可。
代码
可以基于以上理论模拟出一套跳表的基本代码。
public class SkipList<K extends Comparable<? super K>, V> {
int maxLevel;
int length;
Node head;
@AllArgsConstructor
class Node {
K key;
V value;
Node next;
Node down;
}
public SkipList() {
this.maxLevel = 0;
this.length = 0;
this.head = new Node(null, null, null, null);
}
private int randomLevel() { // 插入的层数
int res = 0;
while (res < maxLevel) {
if (Math.random() < 0.5) {
return res;
}
res++;
}
return res;
}
public void push(K key, V value) {
this.remove(key);
int level = this.randomLevel();
Node t = this.head;
Node last = new Node(key, value, null, null);
while (t != null) {
if (t.next != null && t.next.key.compareTo(key) <= 0) { // 存在下个节点,且不会插入在当前位置
t = t.next;
} else { // 已找到插入位置,或没有后续节点时插在最后
if (maxLevel - level <= 0) { //只对下面level层进行插入
last.next = t.next;
t.next = last;
last.down = new Node(key, value, null, null);
last = last.down;
}
level++;
t = t.down;
}
}
// 插入后判断是否需要升级
this.length++;
if (length > Math.pow(2, maxLevel)) {
levelUp();
}
}
public void remove(K key) {
Node t = head;
boolean isDone = false;
while (t != null) {
if (t.next != null && t.next.key.compareTo(key) <= 0) {
if (t.next.key.equals(key)) {
t.next = t.next.next;
t = t.down;
isDone = true;
continue;
}
t = t.next;
} else {
t = t.down;
}
}
if (isDone) { // 降级
this.length--;
if (length <= Math.pow(2, maxLevel - 1)) {
levelDown();
}
}
}
public V get(K key) {
Node t = head;
while (t != null) {
if (t.next != null && t.next.key.compareTo(key) <= 0) { // 迭代后移
if (t.next.key.equals(key)) { // 定位到,直接返回
return t.next.value;
}
t = t.next;
} else {
t = t.down;
}
}
return null;
}
public void levelUp() {
this.maxLevel++;
this.head = new Node(this.head.key, this.head.value, null, this.head);
}
public void levelDown() {
this.maxLevel--;
this.head = this.head.down;
}
public void print() {
Node layer = head;
Node t = layer;
while (layer != null) {
while (t != null) {
// System.out.print("(idx:" + t.key +"/next:"+(t.next==null?"x":t.next.key)+"/down:"+(t.down==null?"x":t.down.key)+")" + ": " + t.value + " | ");
System.out.print(t.key + " | ");
t = t.next;
}
System.out.println();
layer = layer.down;
t = layer;
}
System.out.println("=====================");
}
public static void main(String[] args) {
SkipList<Integer, String> skipList = new SkipList<>();
for (int i = 100; i > 0; i -= 2) {
int v = (int) (Math.random() * 100) + 1;
skipList.push(v, v + "x");
}
skipList.print();
for (int i = 500; i > 0; i -= 2) {
int v = (int) (Math.random() * 100) + 1;
skipList.remove(v);
}
skipList.print();
}
}
对于节点对照上述分析进行了定义,定义了一个头节点指向第一层的头节点,作为每次遍历的开始标记。length则记录了底层总共插入了多少数据,maxLevel记录当前跳表的层数。
同时,为了使得跳表能够存储对象,我们将其改造为键值对结构,以key作为跳表中存储的标识,以value作为映射的值。使得可以通过跳表实现Map结构,用作缓存等用途。
在测试中,随机插入了一批数据并随机删除了一批数据。并且分别测试打印了跳表结构。















 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









