






简介
LRU(Least Recently Used)即最近最久未使用,是一种常用的缓存淘汰算法。LRU的主要目的是在有限的缓存空间里进行缓存的更新和维护,将最近最久未使用的缓存数据淘汰,替换为新的缓存数据。
原理
LRU维护一个双向链表,越靠近表头的位置表明缓存数据离现在越近的时间使用过,越靠近表尾的位置表明缓存数据越久未使用过,表尾的数据则是所有缓存数据中最久未使用过的。
通过维护这个链表,确保始终能够找出最近最久未使用的缓存数据。当新的缓存数据插入时,如果缓存空间不足,则将位于表尾的缓存数据删除,腾出一个空间供新的缓存数据存储,并将新数据插入至表头。
图解
0.LRU的数据结构如下
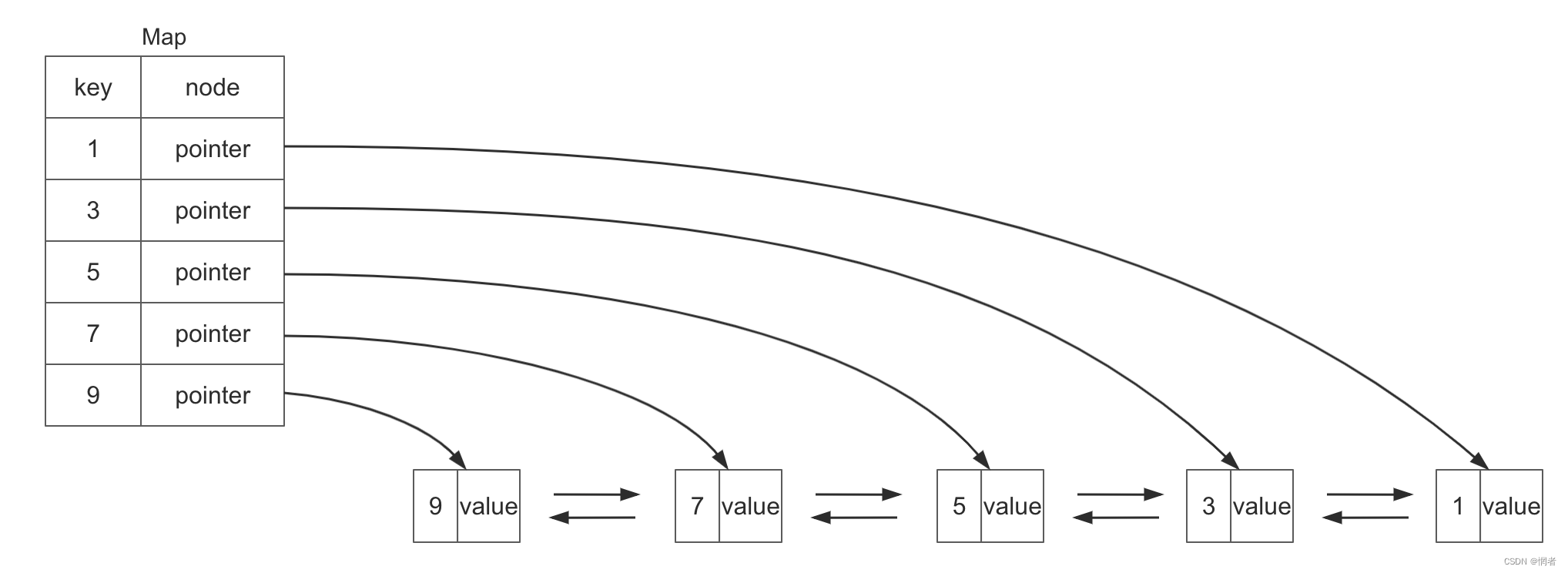
由一个双向链表和一个hash表组成,hash表通过key能够获取到双向链表中的每个节点的引用。这一设计主要是为了在O(1)的时间复杂度下可以直接定位目标节点。
1.查找缓存数据
如果缓存数据存在,所命中的缓存则是最新使用的,需要从双向链表中移出,并移动到表头。

首先通过hash表直接获取到目标节点
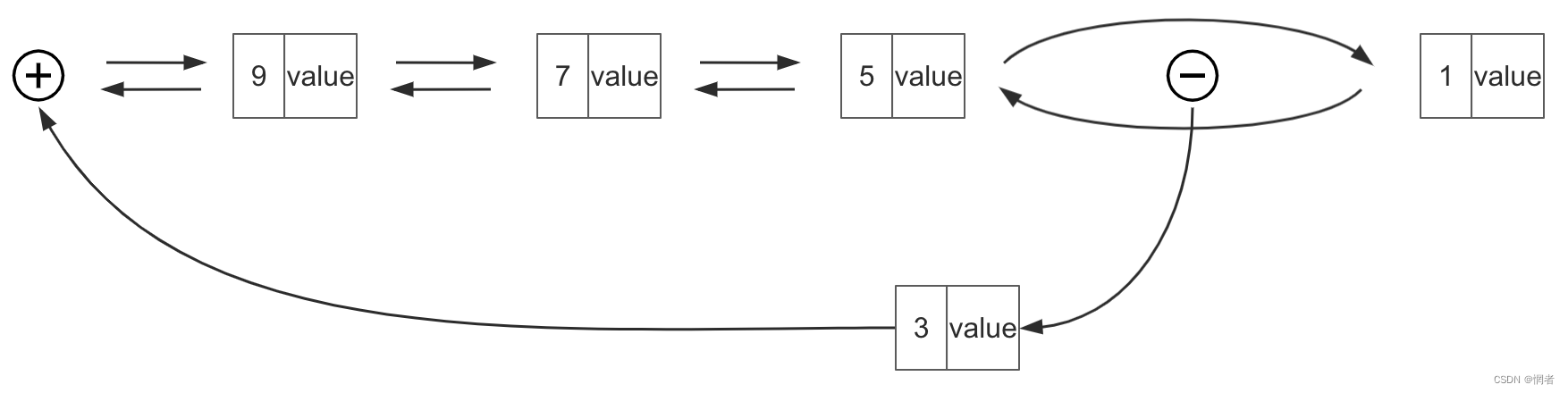
然后将目标节点从双向链表中移出,维护相邻节点的指针,并将目标节点添加至表头。保证整个链表的语义正确性。
返回该节点存储的value即可。
2.新插入缓存数据
这里我们假设当前LRU的最大容量为5,当链表长度未达到最大容量时,直接将新的缓存数据添加到双向链表的表头。并记录在hash表中即可,不再赘述。
当链表长度已经达到最大容量,此时添加新的数据就会超出容量,因此必须把位于表尾的最近最久未使用的缓存数据删除掉。
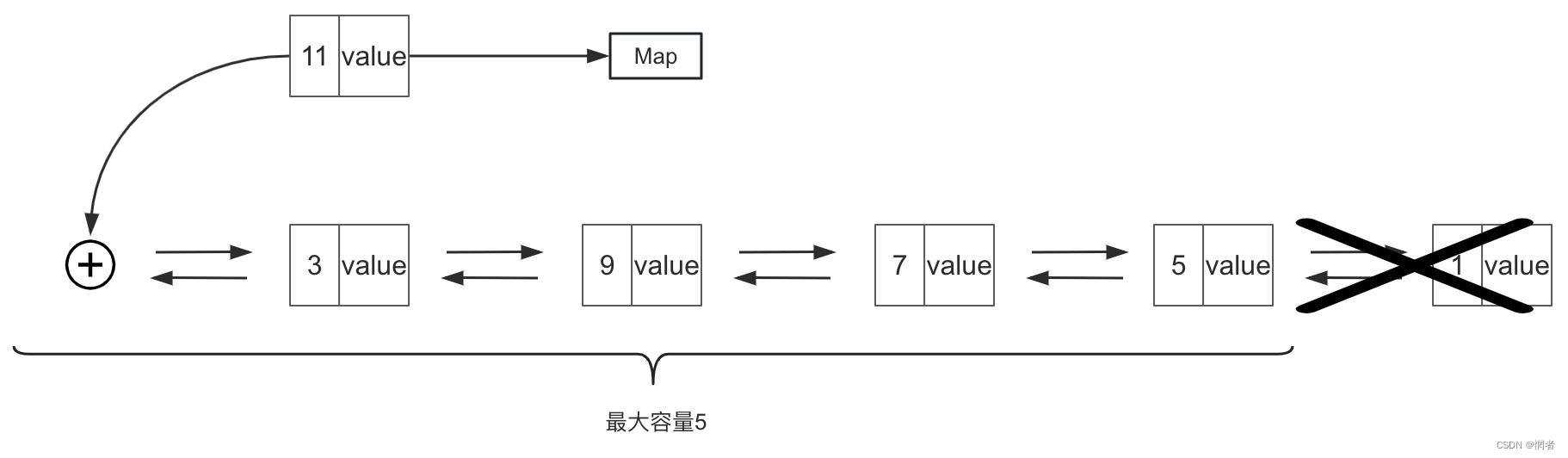
3.删除和修改
删除和修改节点不涉及到节点移动,都是通过hash表直接定位到目标节点,如果是删除则解相邻节点引用。如果是修改则直接修改节点的value值。
代码
public class LRUCache<K, V> {
@AllArgsConstructor
class Node {
Node prev;
Node next;
K key;
V value;
}
private Node head;
private Node tail;
private final Map<K, Node> map;
private final int capacity;
public LRUCache(int capacity) {
map = new HashMap<>();
this.capacity = capacity;
}
public V get(K key) {
if (map.containsKey(key)) {
Node node = map.get(key);
this.move2Head(node);
return node.value;
}
return null;
}
public void push(K key, V value) {
Node node = new Node(null, this.head, key, value);
if (this.head != null) {
this.head.prev = node;
}
this.head = node;
map.put(key, node);
// 如果list为空 尾节点也和头节点一样指向node
if (this.tail == null) {
this.tail = node;
}
// 溢出,删除尾节点(最久未使用的节点)
if (map.size() > this.capacity) {
map.remove(this.tail.key);
this.tail.prev.next = null;
this.tail = this.tail.prev;
}
}
public void move2Head(Node node) {
if (node.prev == null) { // 头节点不必动
return;
}
this.remove(node);
node.prev = null;
node.next = this.head;
if (this.head != null) {
this.head.prev = node;
}
this.head = node;
}
public void remove(Node node) {
if (node.prev != null) {
node.prev.next = node.next;
} else { // 如果是头节点要更新头节点标记
this.head = node.next;
}
if (node.next != null) {
node.next.prev = node.prev;
} else { // 如果是尾节点要更新尾节点标记
this.tail = node.prev;
}
}
public void remove(K key) {
if (map.containsKey(key)) {
Node node = map.get(key);
this.remove(node);
this.map.remove(key);
}
}
public void showList() {
Node t = this.head;
while (t != null) {
System.out.println("key: " + t.key + " value: " + t.value);
t = t.next;
}
if (this.head != null) {
System.out.println("this.head:" + this.head.key + " this.tail:" + this.tail.key);
}
System.out.println("===========");
}
public static void main(String[] args) {
LRUCache<String, String> cache = new LRUCache<>(3);
// 初始化添加
cache.push("a", "hello");
cache.push("b", "world");
cache.push("c", "apple");
cache.showList();
// 最大容量添加测试
cache.push("d", "code");
cache.showList();
// 查找测试
String c = cache.get("c");
System.out.println("get c: " + c);
cache.showList();
//修改测试
cache.push("a","aloha");
cache.showList();
//删除测试
cache.remove("d");
cache.showList();
}
}
运行结果如下:
key: c value: apple
key: b value: world
key: a value: hello
this.head:c this.tail:a
===========
key: d value: code
key: c value: apple
key: b value: world
this.head:d this.tail:b
===========
get c: apple
key: c value: apple
key: d value: code
key: b value: world
this.head:c this.tail:b
===========
key: a value: aloha
key: c value: apple
key: d value: code
this.head:a this.tail:d
===========
key: a value: aloha
key: c value: apple
this.head:a this.tail:c
===========
这段LRU算法的简易实现代码,定义了一个 LRUCache<K, V> 结构,可以通过泛型选择缓存的key和value的类型。在测试中,选择了String作为缓存的key和value。















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









