







 该项目设计爬虫获取中草药图片构建数据集,用数据增广等方法提升质量。经实验选定ResNeSt50模型,调整学习率、损失函数等参数提升训练效果。设计网站,用户可上传图像,后端用模型识别并保存数据,系统能识别18种中草药,测试集准确率达97.8%。
该项目设计爬虫获取中草药图片构建数据集,用数据增广等方法提升质量。经实验选定ResNeSt50模型,调整学习率、损失函数等参数提升训练效果。设计网站,用户可上传图像,后端用模型识别并保存数据,系统能识别18种中草药,测试集准确率达97.8%。
项目设计
- 设计爬虫程序获取中草药图片构建数据集,采用多种数据增广和图像增强方法提升训练集质量;
- 通过实验比较并调整参数,选定ResNeSt50模型;采用CosineAnnealingLR学习率调整策略减少模型参数陷入局部最优解的概率,调整损失函数为Focal Loss + Contrastive Loss,修改激活函数为LeakyReLU及其他参数提升模型训练效果;
- 设计网站,用户可通过Web前端上传中草药图像,后端利用深度学习模型进行识别,并实时保存数据库数据。
项目展示
实现功能
用户可通过 Web 前端上传中草药图像;前端将图像发送至后端,后端通过深度学习模型进行识别;随后,后端将预测结果(包括中草药种类及相关信息)返回给前端,供用户查看。整个过程中,数据库数据将被实时调用和保存。系统现在可以识别18种中草药植株,在测试集上的准确率达到97.8%。
功能展示
打开网站,点击选择需要识别的中草药图片。
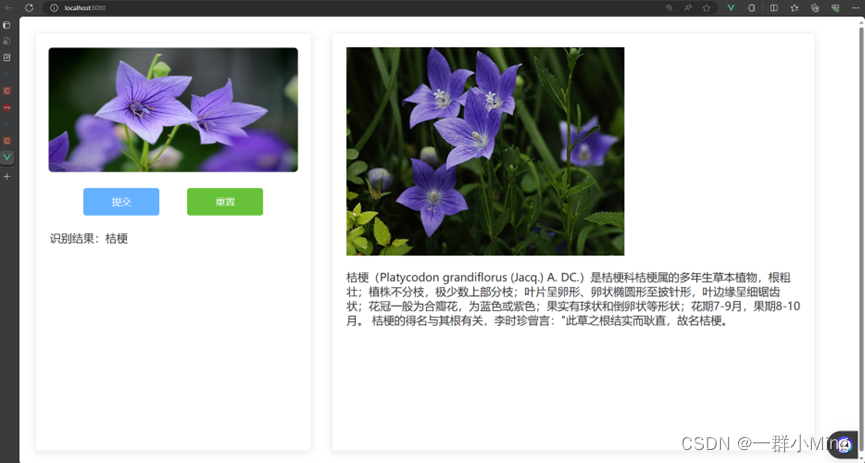
点击提交,返回识别结果。
后端运行过程:
源代码展示
图像增广函数
def process_images(folder_path):
# 遍历文件夹中的所有文件和子文件夹
for root, dirs, files in os.walk(folder_path):
# 只处理二级文件夹
if len(root.split(os.sep)) - len(folder_path.split(os.sep)) == 1:
# 遍历文件夹中的所有文件
for file in files:
# 检查文件是否为图片(根据文件扩展名)
if file.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp')):
# 构建图片文件的完整路径
image_path = os.path.join(root, file)
# 打开图片文件
image = Image.open(image_path)
# 对图片进行操作(这里需要根据具体需求编写代码)
# 镜像
image_mirror = image.transpose(Image.FLIP_LEFT_RIGHT)
image_mirror.save(os.path.join(root, 'mirror_' + file))
# 缩放
image_scale = image.resize((image.width // 2, image.height // 2))
image_scale.save(os.path.join(root, 'scale_' + file))
# 平移
image_shift = ImageChops.offset(image, 50, 50)
image_shift.save(os.path.join(root, 'shift_' + file))
# 左旋
image_rotate_left = image.rotate(90)
image_rotate_left.save(os.path.join(root, 'rotate_left_' + file))
# 右旋
image_rotate_right = image.rotate(-90)
image_rotate_right.save(os.path.join(root, 'rotate_right_' + file))
# 裁剪
image_crop = image.crop((100, 100, 300, 300))
image_crop.save(os.path.join(root, 'crop_' + file))
# 亮度和对比度调整
enhancer = ImageEnhance.Brightness(image)
image_enhanced = enhancer.enhance(1.5)
enhancer = ImageEnhance.Contrast(image_enhanced)
image_enhanced = enhancer.enhance(1.5)
image_enhanced.save(os.path.join(root, 'enhanced_' + file))
# 关闭图片文件
image.close()
训练代码
import time
import os
from tqdm import tqdm
import pandas as pd
import numpy as np
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
%matplotlib inline
import torch.optim as optim
from resnest.torch import resnest50
import warnings
warnings.filterwarnings("ignore")
# 获取计算硬件
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
from torchvision import transforms
# 训练集图像预处理:缩放裁剪、图像增强、转 Tensor、归一化
train_transform = transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 测试集图像预处理-RCTN:缩放、裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









